

NetApp StorageGRID e big data analytics
 Sugerir alterações
Sugerir alterações
Casos de uso do NetApp StorageGRID
A solução de storage de objetos da NetApp StorageGRID oferece escalabilidade, disponibilidade de dados, segurança e alta performance. Organizações de todos os tamanhos e em vários setores usam o StorageGRID S3 para uma ampla variedade de casos de uso. Vamos explorar alguns cenários típicos:
Análise de big data: o StorageGRID S3 é frequentemente usado como data Lake, onde as empresas armazenam grandes quantidades de dados estruturados e não estruturados para análise usando ferramentas como o Apache Spark, o Splunk Smartstore e o Dremio.
Disposição em camadas de dados: os clientes do NetApp usam o recurso FabricPool do ONTAP para mover dados automaticamente entre um nível local de alto desempenho para o StorageGRID. A disposição em camadas libera storage flash caro para dados ativos enquanto mantém os dados inativos prontamente disponíveis no storage de objetos de baixo custo. Isto maximiza o desempenho e as poupanças.
Backup de dados e recuperação de desastres: as empresas podem usar o StorageGRID S3 como uma solução confiável e econômica para fazer backup de dados críticos e recuperá-los em caso de desastre.
-
Armazenamento de dados para aplicativos:* o StorageGRID S3 pode ser usado como um back-end de armazenamento para aplicativos, permitindo que os desenvolvedores armazenem e recuperem arquivos, imagens, vídeos e outros tipos de dados facilmente.
Entrega de conteúdo: o StorageGRID S3 pode ser usado para armazenar e entregar conteúdo estático do site, arquivos de Mídia e downloads de software para usuários em todo o mundo, aproveitando a distribuição geográfica e o namespace global da StorageGRID para entrega de conteúdo rápida e confiável.
Arquivo de dados: o StorageGRID oferece diferentes tipos de armazenamento e suporta a disposição em camadas em opções públicas de armazenamento de baixo custo a longo prazo, tornando-o uma solução ideal para arquivamento e retenção de dados a longo prazo que precisam ser mantidos para fins de conformidade ou históricos.
Casos de uso de armazenamento de objetos
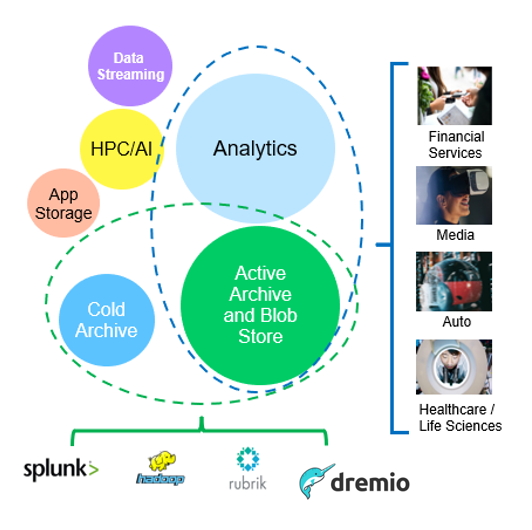
Entre as opções acima, o Big Data Analytics é um dos principais casos de uso e seu uso está em alta.
Por que escolher a StorageGRID para data Lakes?
-
Maior colaboração - enorme alocação compartilhada de vários locais e alocação a vários clientes com acesso à API padrão do setor
-
Custos operacionais reduzidos: Simplicidade operacional de uma única arquitetura automatizada e com autorrecuperação
-
Escalabilidade - diferentemente das soluções tradicionais de Hadoop e data warehouse, o storage de objetos StorageGRID S3 separa o storage da computação e dos dados, permitindo que as empresas escalem suas necessidades de storage à medida que crescem.
-
Durabilidade e confiabilidade - o StorageGRID oferece 99,999999999% de durabilidade, o que significa que os dados armazenados são altamente resistentes à perda de dados. Ele também oferece alta disponibilidade, garantindo que os dados estejam sempre acessíveis.
-
Segurança - o StorageGRID oferece vários recursos de segurança, incluindo criptografia, política de controle de acesso, gerenciamento do ciclo de vida dos dados, bloqueio de objetos e controle de versão para proteger os dados armazenados nos buckets do S3
Lagos de dados StorageGRID S3
Benchmarking Data Warehouses e Lakehouses com armazenamento de objetos S3: Um estudo comparativo
Este artigo apresenta um benchmark abrangente de vários ecossistemas de data warehouse e lakehouse utilizando NetApp StorageGRID. O objetivo é determinar qual sistema apresenta o melhor desempenho com S3 object storage. Consulte este "Apache Iceberg: O Guia definitivo" para saber mais sobre arquiteturas de data warehouse/lakehouse e formatos de tabela (Parquet e Iceberg).
-
Ferramenta de benchmark - TPC-DS - https://www.tpc.org/tpcds/
-
Ecossistemas de Big Data
-
Cluster de VMs, cada uma com 128G GB de RAM e 24 vCPU, armazenamento SSD para disco do sistema
-
Hadoop 3.3.5 com Hive 3.1.3 (1 nó de nome e 4 nós de dados)
-
Delta Lake com Spark 3.2.0 (1 master e 4 workers) e Hadoop 3.3.5
-
Dremio v25,2 (1 coordenador e 5 executores)
-
Trino v438 (1 coordenador e 5 trabalhadores)
-
Starburst v453 (1 coordenador e 5 trabalhadores)
-
-
Storage de objetos
-
NetApp StorageGRID 11,8 com 3 x SG6060 e 1x SG1000 balanceador de carga
-
Proteção de objetos - 2 cópias (o resultado é semelhante ao EC 2-1)
-
-
Tamanho do banco de dados 1000GB
-
O cache foi desativado em todos os ecossistemas para cada teste de consulta usando o formato Parquet. Para o formato Iceberg, comparamos o número de solicitações GET S3 e o tempo total de consulta entre cenários desabilitados em cache e habilitados para cache.
TPC-DS inclui 99 consultas SQL complexas projetadas para benchmarking. Medimos o tempo total necessário para executar todas as 99 consultas e realizamos uma análise detalhada examinando o tipo e o número de S3 solicitações. Nossos testes compararam a eficiência de dois formatos de tabela populares: Parquet e Iceberg.
Resultado da consulta TPC-DS com formato de tabela Parquet
| Ecossistema | Colmeia | Delta Lake | Dremio | Trino | Starburst |
|---|---|---|---|---|---|
TPCDS 99 consultas e total de minutos |
1084 1 |
55 |
36 |
32 |
28 |
S3 pedidos de divisão |
OBTER |
1.117.184 |
2.074.610 |
3.939.690 |
1.504.212 |
1.495.039 |
Observação: Toda a gama GANHA |
Alcance de 80% de 2KB a 2MB de 32MB objetos, 50 a 100 solicitações/seg |
Alcance de 73% abaixo de 100KB de 32MB objetos, 1000 - 1400 solicitações/seg |
90% 1M byte range get de 256MB objetos, 2500 - 3000 solicitações/seg |
Alcance obter tamanho: 50% abaixo de 100KB, 16% em torno de 1MB, 27% 2MB-9MB, 3500 - 4000 solicitações/seg |
Obter tamanho: 50% abaixo de 100KB, 16% em torno de 1MB, 27% 2MB-9MB, 4000 - 5000 solicitação/seg |
Listar objetos |
312.053 |
24.158 |
120 |
509 |
512 |
CABEÇA (objeto inexistente) |
156.027 |
12.103 |
96 |
0 |
0 |
CABEÇA (objeto existente) |
982.126 |
922.732 |
0 |
0 |
0 |
Total de solicitações |
2.567.390 |
3.033.603 |
3.939,906 |
1.504.721 |
1 não é possível concluir a consulta número 72
Resultado da consulta TPC-DS com formato de tabela Iceberg
| Ecossistema | Dremio | Trino | Starburst |
|---|---|---|---|
Consultas TPCDS 99 e total de minutos (cache desativado) |
22 |
28 |
22 |
TPCDS 99 consultas e total de minutos 2 (cache ativado) |
16 |
28 |
21,5 |
S3 pedidos de divisão |
Obter (cache desativado) |
1.985.922 |
938.639 |
931.582 |
Obter (cache ativado) |
611.347 |
30.158 |
3.281 |
Observação: Toda a gama GANHA |
Alcance obter tamanho: 67% 1MB, 15% 100KB, 10% 500KB, 3500 - 4500 solicitações/seg |
Alcance obter tamanho: 42% abaixo de 100KB, 17% em torno de 1MB, 33% 2MB-9MB, 3500 - 4000 solicitações/seg |
Alcance obter tamanho: 43% abaixo de 100KB, 17% em torno de 1MB, 33% 2MB-9MB, 4000 - 5000 solicitações/seg |
Listar objetos |
1465 |
0 |
0 |
CABEÇA (objeto inexistente) |
1464 |
0 |
0 |
CABEÇA (objeto existente) |
3.702 |
509 |
509 |
Total de solicitações (cache desativado) |
1.992.553 |
939.148 |
2 o desempenho do Trino/Starburst é prejudicado por recursos de computação; adicionar mais RAM ao cluster reduz o tempo total de consulta.
Como mostrado na primeira tabela, o Hive é significativamente mais lento do que outros ecossistemas modernos de lakehouse de dados. Observamos que o Hive enviou um grande número de solicitações de list-objects S3, que normalmente são lentas em todas as plataformas de armazenamento de objetos, especialmente quando se trata de buckets contendo muitos objetos. Isso aumenta significativamente a duração geral da consulta. Além disso, os ecossistemas modernos do lago podem enviar um grande número de SOLICITAÇÕES GET em paralelo, variando de 2.000 a 5.000 solicitações por segundo, em comparação com as de 50 a 100 solicitações da Hive por segundo. O sistema de arquivos padrão mimetismo por Hive e Hadoop S3A contribui para a lentidão do Hive ao interagir com o armazenamento de objetos S3D.
O uso do Hadoop (em armazenamento de objetos HDFS ou S3) com o Hive ou Spark requer um amplo conhecimento do Hadoop e do Hive/Spark, bem como uma compreensão de como as configurações de cada serviço interagem. Juntos, eles têm mais de 1.000 configurações, muitas das quais estão inter-relacionadas e não podem ser alteradas independentemente. Encontrar a combinação ideal de configurações e valores requer uma quantidade enorme de tempo e esforço.
Comparando os resultados do Parquet e do Iceberg, notamos que o formato da tabela é um fator de desempenho importante. O formato da tabela Iceberg é mais eficiente do que o Parquet em termos do número de solicitações S3, com 35% a 50% menos solicitações em comparação com o formato Parquet.
O desempenho de Dremio, Trino ou Starburst é impulsionado principalmente pelo poder de computação do cluster. Embora todos os três usem o conetor S3A para conexão de armazenamento de objetos S3, eles não exigem Hadoop, e a maioria das configurações fs.s3a do Hadoop não são usadas por esses sistemas. Isso simplifica o ajuste de desempenho, eliminando a necessidade de aprender e testar várias configurações do Hadoop S3A.
A partir desse resultado de benchmark, podemos concluir que o sistema de análise de Big Data otimizado para workloads baseados em S3 é um fator de desempenho importante. As casas de repouso modernas otimizam a execução de consultas, utilizam metadados de forma eficiente e fornecem acesso contínuo a dados S3, resultando em melhor desempenho em comparação com o Hive ao trabalhar com armazenamento S3.
Consulte esta "página" secção para configurar a fonte de dados do Dremio S3 com o StorageGRID.
Visite os links abaixo para saber mais sobre como o StorageGRID e o Dremio trabalham juntos para fornecer uma infraestrutura de data Lake moderna e eficiente e como a NetApp migrou do Hive e do HDFS para o Dremio e o StorageGRID para aprimorar drasticamente a eficiência analítica de big data.