

Ajuste do Hadoop S3A
 Sugerir alterações
Sugerir alterações
Por Angela Cheng
O conetor Hadoop S3A facilita a interação perfeita entre aplicativos baseados em Hadoop e o armazenamento de objetos S3. Ajustar o conetor Hadoop S3A é essencial para otimizar o desempenho ao trabalhar com storage de objetos S3. Antes de entrarmos em detalhes de ajuste, vamos ter uma compreensão básica do Hadoop e de seus componentes.
O que é Hadoop?
Hadoop é uma poderosa estrutura de código aberto projetada para lidar com Data Processing e armazenamento em larga escala. Ele permite o armazenamento distribuído e o processamento paralelo entre clusters de computadores.
Os três componentes principais do Hadoop são:
-
Hadoop HDFS (Hadoop Distributed File System): Trata o armazenamento, quebrando dados em blocos e distribuindo-os entre nós.
-
Hadoop MapReduce: Responsável pelo processamento de dados dividindo tarefas em blocos menores e executando-as em paralelo.
-
Hadoop YARN (mais um negociador de recursos): "Gerencia recursos e agenda tarefas de forma eficiente"
Hadoop HDFS e conetor S3A
O HDFS é um componente vital do ecossistema do Hadoop, desempenhando um papel crítico em Big Data Processing eficientes. O HDFS permite armazenamento e gerenciamento confiáveis. Ele garante processamento paralelo e armazenamento de dados otimizado, resultando em acesso e análise mais rápidos dos dados.
No Big Data Processing, a HDFS se destaca em fornecer armazenamento tolerante a falhas para grandes conjuntos de dados. Ele consegue isso por meio da replicação de dados. Ele pode armazenar e gerenciar grandes volumes de dados estruturados e não estruturados em um ambiente de data warehouse. Além disso, ele se integra perfeitamente aos principais frameworks de Data Processing, como Apache Spark, Hive, Pig e Flink, permitindo Data Processing escalável e eficiente. Ele é compatível com sistemas operacionais baseados em Unix (Linux), tornando-o uma escolha ideal para organizações que preferem usar ambientes baseados em Linux para seus grandes Data Processing.
À medida que o volume de dados cresceu com o tempo, a abordagem de adicionar novas máquinas ao cluster Hadoop com sua própria computação e storage tornou-se ineficiente. O dimensionamento linear cria desafios para o uso eficiente de recursos e o gerenciamento da infraestrutura.
Para lidar com esses desafios, o conector Hadoop S3A oferece e/S de alto desempenho em relação ao storage de objetos S3. A implementação de um fluxo de trabalho do Hadoop com o S3A ajuda você a utilizar o storage de objetos como repositório de dados e permite separar a computação e o storage, o que, por sua vez, permite escalar a computação e o storage de forma independente. A dissociação da computação e do storage também permite que você dedique a quantidade certa de recursos para suas tarefas de computação e forneça capacidade com base no tamanho do conjunto de dados. Portanto, você pode reduzir o TCO geral para workflows do Hadoop.
Ajuste do conetor Hadoop S3A
O S3 se comporta de forma diferente do HDFS, e algumas tentativas de preservar a aparência de um sistema de arquivos são agressivamente subótimas. Ajustes/testes/experiências cuidadosos são necessários para fazer o uso mais eficiente dos recursos do S3.
As opções do Hadoop neste documento são baseadas no Hadoop 3,3.5, "Hadoop 3.3.5 core-site.xml" consulte para obter todas as opções disponíveis.
Observação – o valor padrão de algumas configurações do Hadoop fs.s3a é diferente em cada versão do Hadoop. Certifique-se de verificar o valor padrão específico para sua versão atual do Hadoop. Se essas configurações não forem especificadas no Hadoop core-site.xml, o valor padrão será usado. Você pode substituir o valor no tempo de execução usando as opções de configuração Spark ou Hive.
Você deve ir a isso "Página do Apache Hadoop" para entender cada fs.s3a opções. Se possível, teste-os no cluster Hadoop que não é de produção para encontrar os valores ideais.
Você deve ler "Maximizar o desempenho ao trabalhar com o conetor S3A" para outras recomendações de ajuste.
Vamos explorar algumas considerações principais:
1. Compressão de dados
Não ative a compressão StorageGRID. A maioria dos sistemas de big data usa o intervalo de bytes get em vez de recuperar todo o objeto. Usar o intervalo de bytes Get com objetos compatados degradam significativamente o desempenho DO GET.
2. S3A committers
Em geral, Magic s3a committer é recomendado. Consulte isso "Página de opções comuns do committer S3A" para obter uma melhor compreensão do committer mágico e suas configurações s3a relacionadas.
Committer mágico:
O committer Magic depende especificamente do S3Guard para oferecer listas de diretórios consistentes no armazenamento de objetos S3.
Com S3 consistente (que agora é o caso), o committer Magic pode ser usado com segurança com qualquer bucket S3.
Escolha e experimentação:
Dependendo do seu caso de uso, você pode escolher entre o committer Staging (que depende de um sistema de arquivos HDFS de cluster) e o committer Magic.
Faça experimentos com ambos para determinar o que melhor se adapta à sua carga de trabalho e aos requisitos.
Em resumo, os committers S3A fornecem uma solução para o desafio fundamental do compromisso de produção consistente, de alto desempenho e confiável para S3. Seu design interno garante transferência eficiente de dados, mantendo a integridade dos dados.
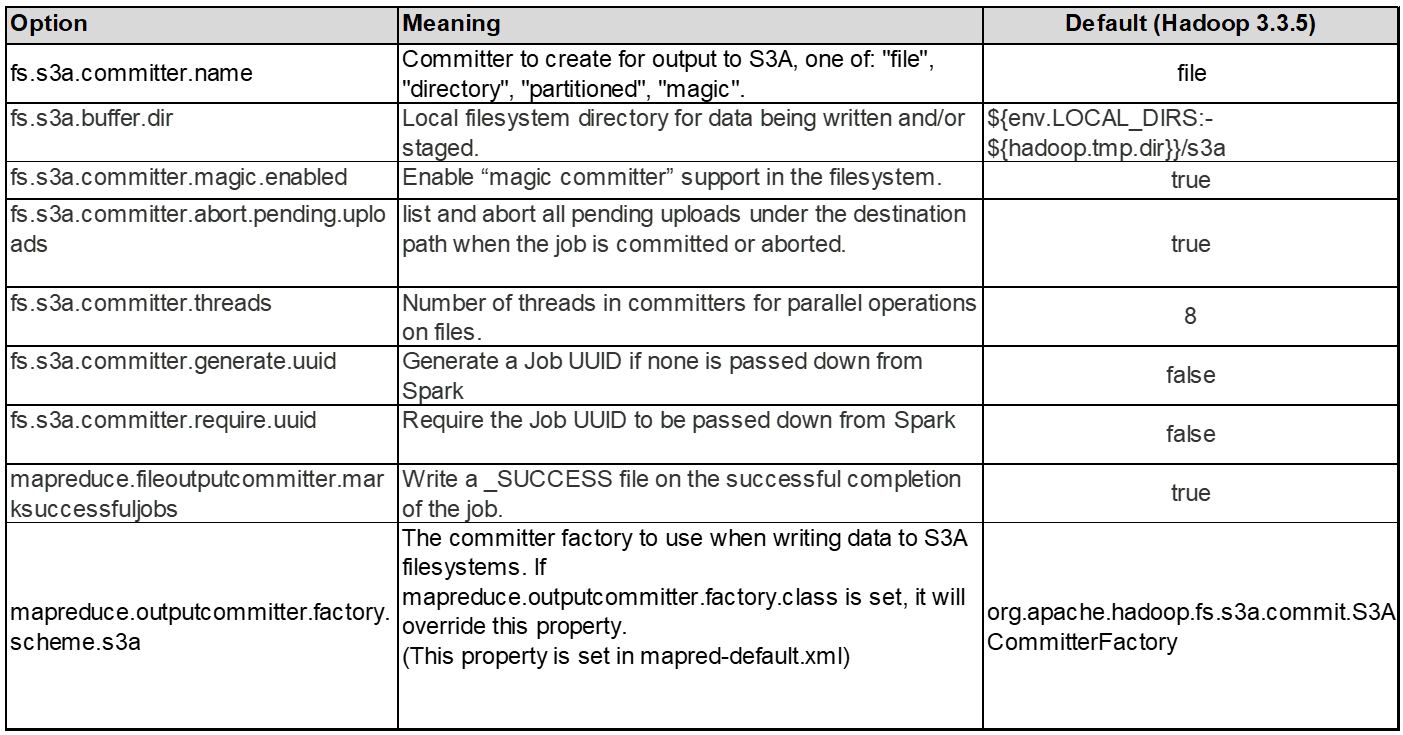
3. Thread, tamanhos do pool de conexão e tamanho do bloco
-
Cada cliente S3A interagindo com um único bucket tem seu próprio pool dedicado de conexões HTTP 1,1 abertas e threads para operações de upload e cópia.
-
Ao carregar dados para S3, ele é dividido em blocos. O tamanho padrão do bloco é de 32 MB. Você pode personalizar esse valor definindo a propriedade fs.s3a.block.size.
-
Tamanhos de bloco maiores podem melhorar o desempenho para grandes carregamentos de dados, reduzindo a sobrecarga de gerenciamento de peças multipeças durante o upload. O valor recomendado é de 256 MB ou superior para um conjunto de dados grande.
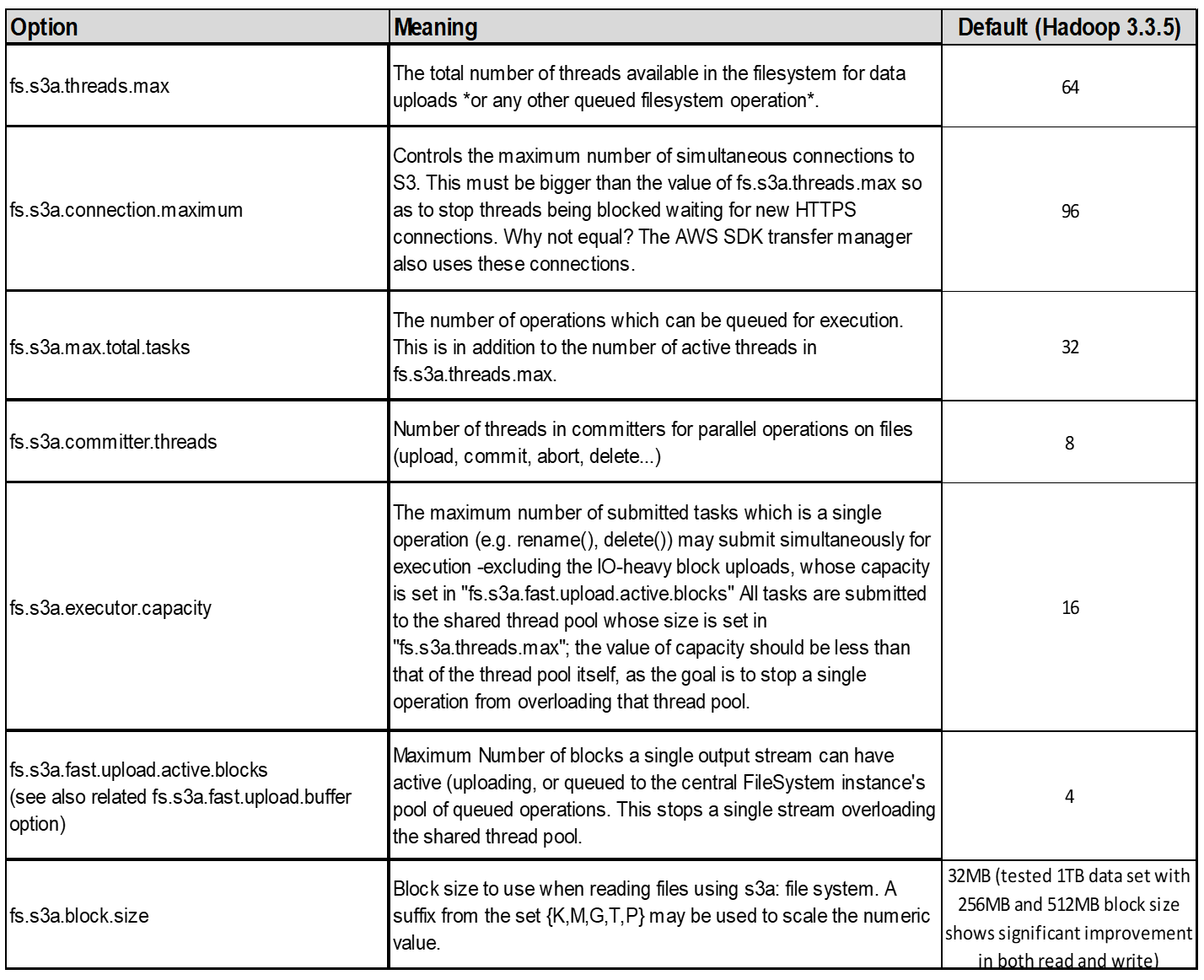
4. Carregamento multipart
s3a committers Always Use MPU (multipart upload) para carregar dados para o bucket S3. Isso é necessário para permitir: Falha de tarefa, execução especulativa de tarefas e abortos de trabalho antes de cometer. Aqui estão algumas especificações-chave relacionadas a carregamentos de várias partes:
-
Tamanho máximo do objeto: 5 TIB (terabytes).
-
Número máximo de peças por upload: 10.000.
-
Números de peça: Variando de 1 a 10.000 (inclusive).
-
Tamanho da peça: Entre 5 MIB e 5 GiB. Notavelmente, não há limite mínimo de tamanho para a última parte do upload de várias partes.
Usar um tamanho de peça menor para uploads S3 multipart tem vantagens e desvantagens.
Vantagens:
-
Recuperação rápida de problemas de rede: Quando você carrega partes menores, o impactos de reiniciar um upload com falha devido a um erro de rede é minimizado. Se uma peça falhar, você só precisa fazer o upload dessa peça específica em vez de todo o objeto.
-
Melhor Parallelization: Mais partes podem ser carregadas em paralelo, aproveitando-se de conexões simultâneas ou multithreading. Essa paralelização melhora o desempenho, especialmente ao lidar com arquivos grandes.
Desvantagem:
-
Sobrecarga de rede: Tamanho de peça menor significa mais partes para carregar, cada parte requer sua própria solicitação HTTP. Mais solicitações HTTP aumentam a sobrecarga de iniciar e concluir solicitações individuais. Gerenciar um grande número de peças pequenas pode afetar o desempenho.
-
Complexidade: Gerenciar a ordem, rastrear peças e garantir que os uploads bem-sucedidos possam ser complicados. Se o upload precisar ser abortado, todas as peças que já foram carregadas precisam ser rastreadas e removidas.
Para Hadoop, 256MB ou acima do tamanho da peça é recomendado para fs.s3a.multipart.size. Sempre defina o valor fs.s3a.mutlipart.threshold para 2 x fs.s3a.multipart.size. Por exemplo, se fs.s3a.multipart.size for 256M, fs.s3a.mutlipart.threshold deve ser 512M.
Use um tamanho de peça maior para um conjunto de dados grande. É importante escolher um tamanho de peça que equilibre esses fatores com base em seu caso de uso específico e condições de rede.
Um upload multipart é "processo de três etapas" um :
-
O upload é iniciado, o StorageGRID retorna um ID de upload.
-
As partes do objeto são carregadas usando o upload-id.
-
Uma vez que todas as partes do objeto são carregadas, envia a solicitação de upload de várias partes completa com upload-id. O StorageGRID constrói o objeto a partir das partes carregadas, e o cliente pode acessar o objeto.
Se a solicitação completa de upload de várias peças não for enviada com sucesso, as peças permanecem no StorageGRID e não criam nenhum objeto. Isto acontece quando os trabalhos são interrompidos, falhados ou abortados. As peças permanecem na grade até que o upload de várias partes seja concluído ou abortado ou o StorageGRID apague essas peças se decorrerem 15 dias desde que o upload foi iniciado. Se houver muitos (algumas centenas de milhares a milhões) uploads em andamento em várias partes em um bucket, quando o Hadoop enviar 'list-multipart-uploads' (essa solicitação não filtra pelo ID de upload), a solicitação pode levar muito tempo para ser concluída ou, eventualmente, acabar. Você pode considerar definir fs.s3a.mutlipart.purge como true com um valor adequado fs.s3a.multipart.purge.age (por exemplo, 5 a 7 dias, não use o valor padrão de 86400 ou seja, 1 dia). Ou acione o suporte do NetApp para investigar a situação.
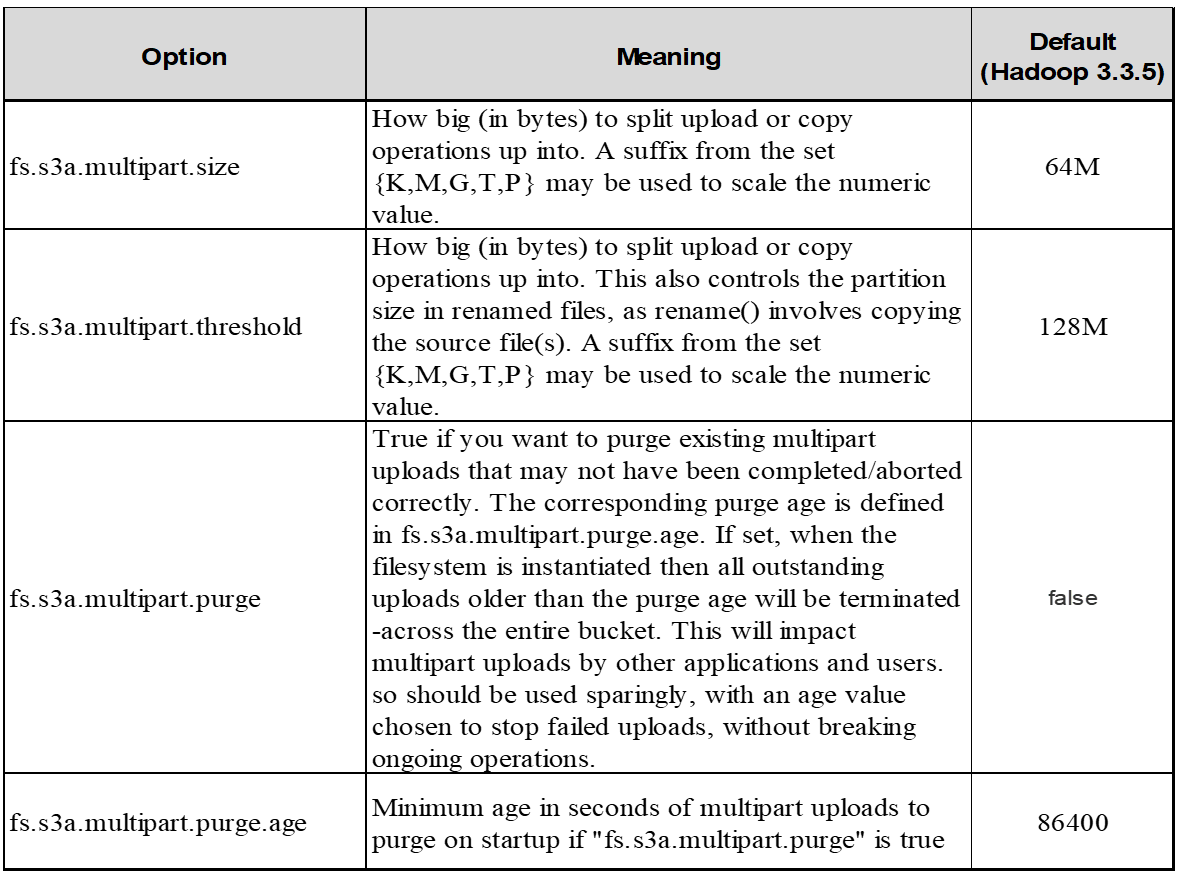
5. Memória intermédia de gravação de dados na memória
Para melhorar o desempenho, você pode armazenar dados de gravação em buffer na memória antes de enviá-los para S3. Isso pode reduzir o número de pequenas gravações e melhorar a eficiência.

Lembre-se de que o S3 e o HDFS funcionam de maneiras distintas. O ajuste cuidadoso/teste/experiência é necessário para fazer o uso mais eficiente dos recursos do S3.