

Use o conetor Cloudera Hadoop S3A com StorageGRID
 Sugerir alterações
Sugerir alterações
Por Angela Cheng
Hadoop tem sido um favorito dos cientistas de dados há algum tempo. O Hadoop permite o processamento distribuído de grandes conjuntos de dados entre clusters de computadores usando estruturas de programação simples. O Hadoop foi projetado para escalar de servidores únicos para milhares de máquinas, com cada máquina possuindo computação e armazenamento locais.
Por que usar o S3A para fluxos de trabalho Hadoop?
À medida que o volume de dados cresceu com o tempo, a abordagem de adicionar novas máquinas com sua própria computação e storage tornou-se ineficiente. O dimensionamento linear cria desafios para o uso eficiente de recursos e o gerenciamento da infraestrutura.
Para lidar com esses desafios, o cliente Hadoop S3A oferece e/S de alto desempenho em relação ao storage de objetos S3. A implementação de um fluxo de trabalho do Hadoop com o S3A ajuda você a utilizar o storage de objetos como repositório de dados e permite separar a computação e o storage, o que, por sua vez, permite escalar a computação e o storage de forma independente. A dissociação da computação e do storage também permite que você dedique a quantidade certa de recursos para suas tarefas de computação e forneça capacidade com base no tamanho do conjunto de dados. Portanto, você pode reduzir o TCO geral para workflows do Hadoop.
Configure o conetor S3A para usar o StorageGRID
Pré-requisitos
-
Um URL de endpoint do StorageGRID S3, uma chave de acesso do locatário S3 e uma chave secreta para o teste de conexão do Hadoop S3A.
-
Um cluster Cloudera e uma permissão root ou sudo para cada host no cluster para instalar o pacote Java.
Em abril de 2022, o Java 11.0.14 com Cloudera 7.1.7 foi testado contra o StorageGRID 11,5 e 11,6. No entanto, o número da versão Java pode ser diferente no momento de uma nova instalação.
Instale o pacote Java
-
Verifique a "Matriz de suporte Cloudera"para a versão do JDK compatível.
-
Faça o download do "Pacote Java 11.x" que corresponde ao sistema operacional do cluster Cloudera. Copie este pacote para cada host no cluster. Neste exemplo, o pacote rpm é usado para o CentOS.
-
Faça login em cada host como root ou usando uma conta com permissão sudo. Execute as seguintes etapas em cada host:
-
Instale o pacote:
$ sudo rpm -Uvh jdk-11.0.14_linux-x64_bin.rpm
-
Verifique onde o Java está instalado. Se várias versões estiverem instaladas, defina a versão recém-instalada como padrão:
alternatives --config java There are 2 programs which provide 'java'. Selection Command ----------------------------------------------- +1 /usr/java/jre1.8.0_291-amd64/bin/java 2 /usr/java/jdk-11.0.14/bin/java Enter to keep the current selection[+], or type selection number: 2
-
Adicione esta linha ao final
/etc/profiledo . O caminho deve corresponder ao caminho da seleção acima:export JAVA_HOME=/usr/java/jdk-11.0.14
-
Execute o seguinte comando para que o perfil entre em vigor:
source /etc/profile
-
Configuração Cloudera HDFS S3A
Passos
-
Na GUI do Cloudera Manager, selecione clusters > HDFS e selecione Configuração.
-
NA CATEGORIA, selecione Avançado e role para baixo para localizar
Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml. -
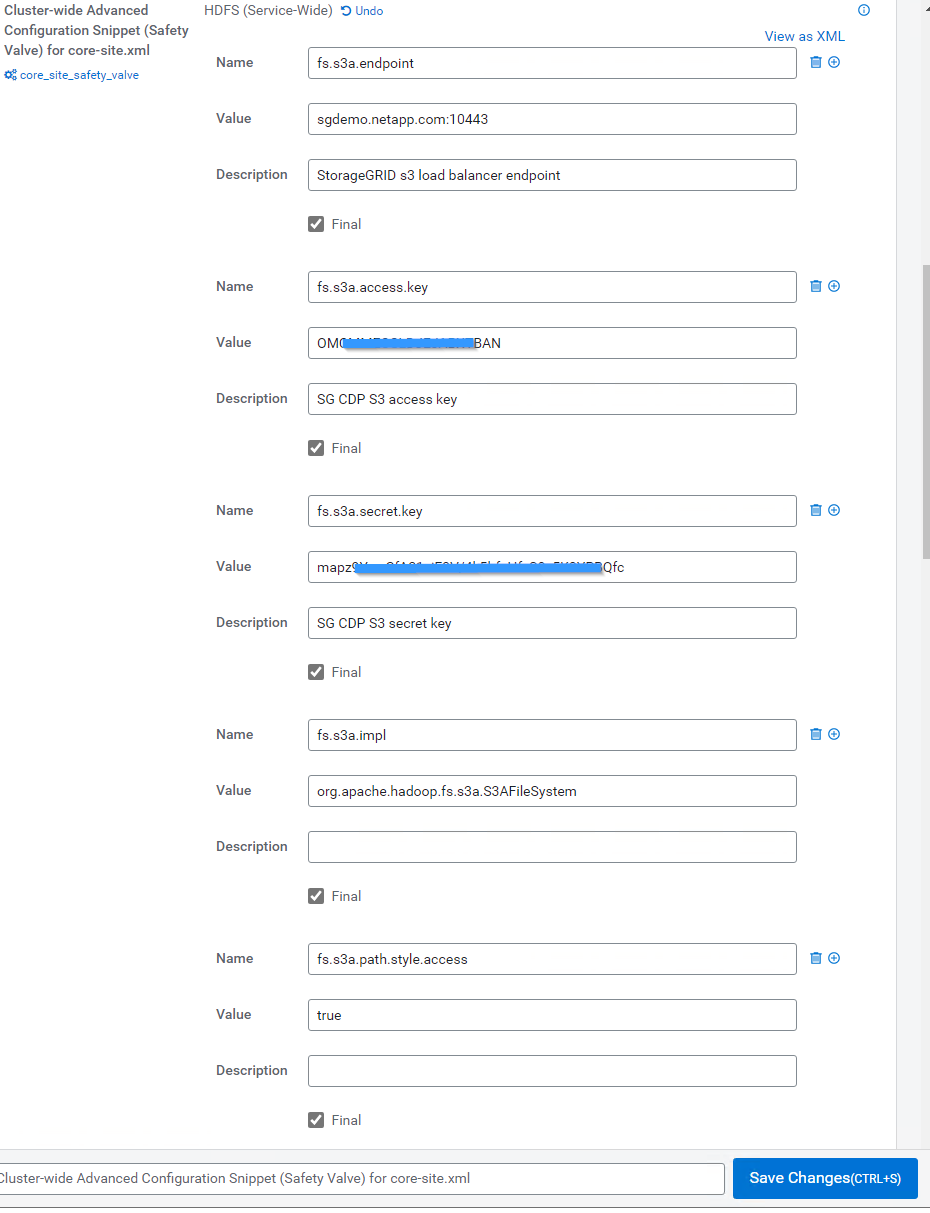
Clique no sinal e adicione os seguintes pares de valores.
Nome Valor fs.s3a.access.key
_ Chave de acesso S3 do cliente a partir de StorageGRID>_
fs.s3a.secret.key
_ Chave secreta do cliente S3 da StorageGRID>_
fs.s3a.connection.ssl.enabled
[true ou false] (o padrão é https se esta entrada estiver ausente)
fs.s3a.endpoint
_ Endpoint do cliente StorageGRID S3:port>_
fs.s3a.impl
org.apache.hadoop.fs.s3a.S3AFileSystem
fs.s3a.path.style.access
[verdadeiro ou falso] (o padrão é o estilo de host virtual se essa entrada estiver ausente)
Captura de tela de amostra
-
Clique no botão Salvar alterações. Selecione o ícone Configuração obsoleta na barra de menus do HDFS, selecione Reiniciar Serviços obsoletos na próxima página e selecione Reiniciar agora.
Teste a conexão S3A com o StorageGRID
Execute o teste básico de conexão
Faça login em um dos hosts no cluster Cloudera e `hadoop fs -ls s3a://<bucket-name>/`digite .
O exemplo a seguir usa syle de caminho com um bucket de teste hdfs pré-existente e um objeto de teste.
[root@ce-n1 ~]# hadoop fs -ls s3a://hdfs-test/ 22/02/15 18:24:37 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/02/15 18:24:37 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/02/15 18:24:37 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/02/15 18:24:37 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS Found 1 items -rw-rw-rw- 1 root root 1679 2022-02-14 16:03 s3a://hdfs-test/test 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete.
Solução de problemas
Cenário 1
Use uma conexão HTTPS com o StorageGRID e obtenha um handshake_failure erro após um tempo limite de 15 minutos.
Motivo: versão antiga do JRE/JDK usando pacote de codificação TLS desatualizado ou não suportado para conexão com o StorageGRID.
-
Exemplo de mensagem de erro*
[root@ce-n1 ~]# hadoop fs -ls s3a://hdfs-test/ 22/02/15 18:52:34 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/02/15 18:52:34 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/02/15 18:52:34 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/02/15 18:52:35 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete. 22/02/15 19:04:51 WARN fs.FileSystem: Failed to initialize fileystem s3a://hdfs-test/: org.apache.hadoop.fs.s3a.AWSClientIOException: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: Received fatal alert: handshake_failure: Unable to execute HTTP request: Received fatal alert: handshake_failure ls: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: Received fatal alert: handshake_failure: Unable to execute HTTP request: Received fatal alert: handshake_failure
Resolução: Certifique-se de que o JDK 11.x ou posterior esteja instalado e definido como padrão a biblioteca Java. Consulte Instale o pacote Javaa secção para obter mais informações.
Cenário 2:
Falha ao se conetar ao StorageGRID com mensagem de erro Unable to find valid certification path to requested target .
Razão: o certificado do servidor de endpoint StorageGRID S3 não é confiável pelo programa Java.
Exemplo de mensagem de erro:
[root@hdp6 ~]# hadoop fs -ls s3a://hdfs-test/ 22/03/11 20:58:12 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/03/11 20:58:13 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/03/11 20:58:13 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/03/11 20:58:13 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete. 22/03/11 21:12:25 WARN fs.FileSystem: Failed to initialize fileystem s3a://hdfs-test/: org.apache.hadoop.fs.s3a.AWSClientIOException: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target: Unable to execute HTTP request: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
Resolução: a NetApp recomenda o uso de um certificado de servidor emitido por uma autoridade pública de assinatura de certificado conhecida para garantir que a autenticação seja segura. Como alternativa, adicione uma CA personalizada ou certificado de servidor ao armazenamento de confiança Java.
Siga as etapas a seguir para adicionar uma CA personalizada do StorageGRID ou um certificado de servidor ao armazenamento de confiança do Java.
-
Faça backup do arquivo Java cacerts padrão existente.
cp -ap $JAVA_HOME/lib/security/cacerts $JAVA_HOME/lib/security/cacerts.orig
-
Importe o cert de endpoint do StorageGRID S3 para o armazenamento de confiança Java.
keytool -import -trustcacerts -keystore $JAVA_HOME/lib/security/cacerts -storepass changeit -noprompt -alias sg-lb -file <StorageGRID CA or server cert in pem format>
Dicas de solução de problemas
-
Aumente o nível de log do hadoop para DEPURAR.
export HADOOP_ROOT_LOGGER=hadoop.root.logger=DEBUG,console -
Execute o comando e direcione as mensagens de log para error.log.
hadoop fs -ls s3a://<bucket-name>/ &>error.log
Por Angela Cheng