

Banco de dados do modo Eon usando NetApp StorageGRID como armazenamento comunitário
 Sugerir alterações
Sugerir alterações
Por Angela Cheng
Este guia descreve o procedimento para criar um banco de dados do modo Vertica Eon com armazenamento comunitário no NetApp StorageGRID.
Introdução
Vertica é um software de gerenciamento de banco de dados analítico. É uma plataforma de armazenamento colunar projetada para lidar com grandes volumes de dados, o que permite um desempenho de consulta muito rápido em um cenário tradicionalmente intensivo. Um banco de dados Vertica é executado em um dos dois modos: EON ou Enterprise. Você pode implantar os dois modos no local ou na nuvem.
Os modos EON e Enterprise diferem principalmente no local onde armazenam dados:
-
As bases de dados do modo EON utilizam armazenamento comunitário para os seus dados. Isso é recomendado pela Vertica.
-
Os bancos de dados do modo empresarial armazenam dados localmente no sistema de arquivos de nós que compõem o banco de dados.
Arquitetura do modo EON
O modo EON separa os recursos computacionais da camada de armazenamento comum do banco de dados, o que permite que a computação e o armazenamento sejam dimensionados separadamente. O Vertica no modo Eon é otimizado para lidar com cargas de trabalho variáveis e isolá-las umas das outras usando recursos de computação e armazenamento separados.
O modo EON armazena dados em um armazenamento de objetos compartilhado chamado armazenamento comunitário - um bucket do S3, hospedado no local ou no Amazon S3.
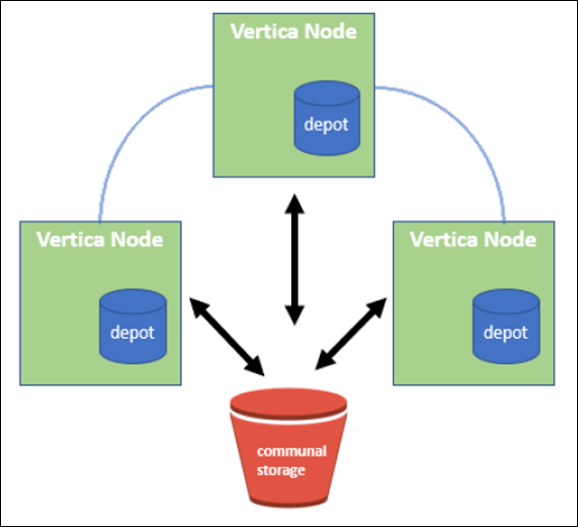
Armazenamento comunitário
Em vez de armazenar dados localmente, o modo Eon usa um único local de armazenamento comunitário para todos os dados e o catálogo (metadados). O armazenamento comum é o local de armazenamento centralizado do banco de dados, compartilhado entre os nós do banco de dados.
O armazenamento comunitário tem as seguintes propriedades:
-
O armazenamento comum na nuvem ou no local de objetos é mais resiliente e menos suscetível à perda de dados devido a falhas de armazenamento do que armazenamento em disco em máquinas individuais.
-
Todos os dados podem ser lidos por qualquer nó usando o mesmo caminho.
-
A capacidade não é limitada pelo espaço de disco nos nós.
-
Como os dados são armazenados em comunidade, você pode dimensionar elasticamente seu cluster para atender às demandas em constante mudança. Se os dados fossem armazenados localmente nos nós, adicionar ou remover nós exigiria a movimentação de quantidades significativas de dados entre nós para movê-los dos nós que estão sendo removidos ou para nós recém-criados.
O depósito
Uma desvantagem do armazenamento comunitário é a sua velocidade. Acessar dados de um local compartilhado na nuvem é mais lento do que lê-los a partir do disco local. Além disso, a conexão com o armazenamento comunitário pode se tornar um gargalo se muitos nós estiverem lendo dados de uma só vez. Para melhorar a velocidade de acesso aos dados, os nós em um banco de dados do modo Eon mantêm um cache de dados de disco local chamado de depósito. Ao executar uma consulta, os nós primeiro verificam se os dados de que precisam estão no depósito. Se for, então ele termina a consulta usando a cópia local dos dados. Se os dados não estiverem no depósito, o nó buscará os dados do armazenamento comunitário e salvará uma cópia no depósito.
Recomendações do NetApp StorageGRID
Vertica armazena dados de banco de dados para armazenamento de objetos como milhares (ou milhões) de objetos compatados (o tamanho observado é de 200 a 500MB por objeto. Quando um usuário executa consultas de banco de dados, o Vertica recupera o intervalo de dados selecionado desses objetos compatados em paralelo usando a chamada DE RECEBIMENTO DE intervalo de bytes. Cada intervalo de bytes GET é de aproximadamente 8KB.
Durante o teste de consultas de usuários do 10TBo depósito do banco de dados, 4.000 a 10.000 solicitações GET (byte-range GET) por segundo foram enviadas para a grade. Ao executar esse teste usando dispositivos SG6060, embora a % de utilização de CPU por nó de appliance seja baixa (cerca de 20% a 30%), 2/3x do tempo de CPU está aguardando a e/S. Uma porcentagem muito pequena (0% a 0,5%) de espera de e/S é observada no SGF6024.
Devido à alta demanda de IOPS pequenos com requisitos de latência muito baixos (a média deve ser inferior a 0,01 segundos), a NetApp recomenda o uso do SFG6024 para serviços de storage de objetos. Se o SG6060 for necessário para tamanhos de banco de dados muito grandes, o cliente deve trabalhar com a equipe de contas Vertica no dimensionamento do depósito para oferecer suporte ao conjunto de dados ativamente consultado.
Para o nó Admin e o nó API Gateway, o cliente pode usar o SG100 ou o SG1000. A escolha depende do número de solicitações de consulta dos usuários em paralelo e tamanho do banco de dados. Se o cliente preferir usar um balanceador de carga de terceiros, a NetApp recomenda um balanceador de carga dedicado para workloads de demanda de alta performance. Para dimensionamento do StorageGRID, consulte a equipe de conta do NetApp.
Outras recomendações de configuração do StorageGRID incluem:
-
Topologia de grade. Não misture o SGF6024 com outros modelos de dispositivos de armazenamento no mesmo local da grade. Se você preferir usar o SG6060 para proteção de arquivo de longo prazo, mantenha o SGF6024 com um balanceador de carga de grade dedicado em seu próprio local de grade (local físico ou lógico) para um banco de dados ativo para melhorar o desempenho. Misturar diferentes modelos de aparelho no mesmo local reduz o desempenho geral no local.
-
Proteção de dados. Use cópias replicadas para proteção. Não use codificação de apagamento para um banco de dados ativo. O cliente pode usar a codificação de apagamento para proteção a longo prazo de bancos de dados inativos.
-
Não ative a compressão da grade. Vertica compacta objetos antes de armazenar em armazenamento de objetos. Ativar a compressão de grade não economiza ainda mais o uso de armazenamento e reduz significativamente o desempenho DA faixa de bytes.
-
* Conexão de endpoint HTTP versus HTTPS S3*. Durante o teste de benchmark, observamos uma melhoria de desempenho de cerca de 5% ao usar uma conexão HTTP S3 do cluster Vertica para o ponto de extremidade do balanceador de carga StorageGRID. Esta escolha deve basear-se nos requisitos de segurança do cliente.
As recomendações para uma configuração Vertica incluem:
-
As configurações padrão do depósito do banco de dados Vertica estão ativadas (valor de 1) para operações de leitura e gravação. A NetApp recomenda fortemente que essas configurações do depósito estejam ativadas para aprimorar o desempenho.
-
Desativar limitações de streaming. Para obter detalhes de configuração, consulte a secção Desativação das limitações de streaming.
Instalação do modo Eon no local com armazenamento comunitário no StorageGRID
As seções a seguir descrevem o procedimento para instalar o modo Eon no local com armazenamento comunitário no StorageGRID. O procedimento para configurar o armazenamento de objetos compatível com o Simple Storage Service (S3) no local é semelhante ao procedimento no guia Vertica, "Instale um banco de dados do modo Eon no local".
A seguinte configuração foi usada para o teste funcional:
-
StorageGRID 11.4.0.4
-
Vertica 10.1.0
-
Três máquinas virtuais (VMs) com CentOS 7.x os para nós Vertica formarem um cluster. Esta configuração é apenas para o teste funcional, não para o cluster de banco de dados de produção Vertica.
Esses três nós são configurados com uma chave Secure Shell (SSH) para permitir SSH sem uma senha entre os nós dentro do cluster.
Informações necessárias da NetApp StorageGRID
Para instalar o modo Eon no local com armazenamento comunitário no StorageGRID, você deve ter as seguintes informações pré-requisitos.
-
Endereço IP ou nome de domínio totalmente qualificado (FQDN) e número da porta do endpoint StorageGRID S3. Se você estiver usando HTTPS, use uma autoridade de certificação personalizada (CA) ou um certificado SSL autoassinado implementado no endpoint do StorageGRID S3.
-
Nome do intervalo. Ele deve pré-existir e estar vazio.
-
Acesse o ID da chave e a chave de acesso secreta com acesso de leitura e gravação ao bucket.
Criando um arquivo de autorização para acessar o endpoint S3
Os pré-requisitos a seguir se aplicam ao criar um arquivo de autorização para acessar o endpoint S3:
-
Vertica está instalado.
-
Um cluster está configurado, configurado e pronto para criação de banco de dados.
Para criar um arquivo de autorização para acessar o endpoint S3, siga estas etapas:
-
Faça login no nó Vertica onde você será executado
admintoolspara criar o banco de dados do modo Eon.O usuário padrão é
dbadmin, criado durante a instalação do cluster Vertica. -
Use um editor de texto para criar um arquivo sob o
/home/dbadmindiretório. O nome do arquivo pode ser o que você quiser, por exemplosg_auth.conf, . -
Se o endpoint S3 estiver usando uma porta HTTP 80 padrão ou uma porta HTTPS 443, ignore o número da porta. Para usar HTTPS, defina os seguintes valores:
-
awsenablehttps = 1, caso contrário, defina o valor como0. -
awsauth = <s3 access key ID>:<secret access key> -
awsendpoint = <StorageGRID s3 endpoint>:<port>Para usar uma CA personalizada ou um certificado SSL autoassinado para a conexão HTTPS de endpoint do StorageGRID S3, especifique o caminho completo do arquivo e o nome do arquivo do certificado. Esse arquivo deve estar no mesmo local em cada nó Vertica e ter permissão de leitura para todos os usuários. Ignore esta etapa se o certificado SSL do StorageGRID S3 for assinado pela CA publicamente conhecida.
− awscafile = <filepath/filename>Por exemplo, veja o seguinte arquivo de exemplo:
awsauth = MNVU4OYFAY2xyz123:03vuO4M4KmdfwffT8nqnBmnMVTr78Gu9wANabcxyz awsendpoint = s3.england.connectlab.io:10443 awsenablehttps = 1 awscafile = /etc/custom-cert/grid.pem
+

Em um ambiente de produção, o cliente deve implementar um certificado de servidor assinado por uma CA publicamente conhecida em um endpoint do balanceador de carga do StorageGRID S3. -
Escolhendo um caminho de depósito em todos os nós Vertica
Escolha ou crie um diretório em cada nó para o caminho do storage de depósito. O diretório que você fornece para o parâmetro caminho do storage de depósito deve ter o seguinte:
-
O mesmo caminho em todos os nós do cluster (por exemplo,
/home/dbadmin/depot) -
Seja legível e gravável pelo usuário dbadmin
-
Armazenamento suficiente
Por padrão, o Vertica usa 60% do espaço do sistema de arquivos que contém o diretório para armazenamento de depósito. Você pode limitar o tamanho do depósito usando o
--depot-sizeargumento nocreate_dbcomando. "Dimensionamento do seu cluster Vertica para um banco de dados do modo Eon"consulte o artigo para obter diretrizes gerais de dimensionamento Vertica ou consulte o seu gerente de conta Vertica.A
admintools create_dbferramenta tenta criar o caminho do depósito para você se não existir um.
Criando o banco de dados Eon on-premises
Para criar o banco de dados Eon on-premises, siga estas etapas:
-
Para criar o banco de dados, use a
admintools create_dbferramenta.A lista a seguir fornece uma breve explicação dos argumentos usados neste exemplo. Consulte o documento Vertica para obter uma explicação detalhada de todos os argumentos necessários e opcionais.
-
-x caminho/nome do ficheiro de autorização criado em "Criando um arquivo de autorização para acessar o endpoint S3" >.
Os detalhes da autorização são armazenados no banco de dados após a criação bem-sucedida. Você pode remover esse arquivo para evitar expor a chave secreta S3.
-
--communal-storage-localização inferior a s3://StorageGRID bucketname>
-
Lista separada por vírgulas de nós Vertica a serem usados para este banco de dados>
-
-d nome do banco de dados a ser criado>
-
a palavra-passe a ser definida para esta nova base de dados>. Por exemplo, veja o seguinte comando de exemplo:
admintools -t create_db -x sg_auth.conf --communal-storage-location=s3://vertica --depot-path=/home/dbadmin/depot --shard-count=6 -s vertica-vm1,vertica-vm2,vertica-vm3 -d vmart -p '<password>'
A criação de um novo banco de dados leva vários minutos de duração, dependendo do número de nós para o banco de dados. Ao criar banco de dados pela primeira vez, você será solicitado a aceitar o Contrato de Licença.
-
Por exemplo, veja o seguinte arquivo de autorização de exemplo e create db comando:
[dbadmin@vertica-vm1 ~]$ cat sg_auth.conf
awsauth = MNVU4OYFAY2CPKVXVxxxx:03vuO4M4KmdfwffT8nqnBmnMVTr78Gu9wAN+xxxx
awsendpoint = s3.england.connectlab.io:10445
awsenablehttps = 1
[dbadmin@vertica-vm1 ~]$ admintools -t create_db -x sg_auth.conf --communal-storage-location=s3://vertica --depot-path=/home/dbadmin/depot --shard-count=6 -s vertica-vm1,vertica-vm2,vertica-vm3 -d vmart -p 'xxxxxxxx'
Default depot size in use
Distributing changes to cluster.
Creating database vmart
Starting bootstrap node v_vmart_node0007 (10.45.74.19)
Starting nodes:
v_vmart_node0007 (10.45.74.19)
Starting Vertica on all nodes. Please wait, databases with a large catalog may take a while to initialize.
Node Status: v_vmart_node0007: (DOWN)
Node Status: v_vmart_node0007: (DOWN)
Node Status: v_vmart_node0007: (DOWN)
Node Status: v_vmart_node0007: (UP)
Creating database nodes
Creating node v_vmart_node0008 (host 10.45.74.29)
Creating node v_vmart_node0009 (host 10.45.74.39)
Generating new configuration information
Stopping single node db before adding additional nodes.
Database shutdown complete
Starting all nodes
Start hosts = ['10.45.74.19', '10.45.74.29', '10.45.74.39']
Starting nodes:
v_vmart_node0007 (10.45.74.19)
v_vmart_node0008 (10.45.74.29)
v_vmart_node0009 (10.45.74.39)
Starting Vertica on all nodes. Please wait, databases with a large catalog may take a while to initialize.
Node Status: v_vmart_node0007: (DOWN) v_vmart_node0008: (DOWN) v_vmart_node0009: (DOWN)
Node Status: v_vmart_node0007: (DOWN) v_vmart_node0008: (DOWN) v_vmart_node0009: (DOWN)
Node Status: v_vmart_node0007: (DOWN) v_vmart_node0008: (DOWN) v_vmart_node0009: (DOWN)
Node Status: v_vmart_node0007: (DOWN) v_vmart_node0008: (DOWN) v_vmart_node0009: (DOWN)
Node Status: v_vmart_node0007: (UP) v_vmart_node0008: (UP) v_vmart_node0009: (UP)
Creating depot locations for 3 nodes
Communal storage detected: rebalancing shards
Waiting for rebalance shards. We will wait for at most 36000 seconds.
Installing AWS package
Success: package AWS installed
Installing ComplexTypes package
Success: package ComplexTypes installed
Installing MachineLearning package
Success: package MachineLearning installed
Installing ParquetExport package
Success: package ParquetExport installed
Installing VFunctions package
Success: package VFunctions installed
Installing approximate package
Success: package approximate installed
Installing flextable package
Success: package flextable installed
Installing kafka package
Success: package kafka installed
Installing logsearch package
Success: package logsearch installed
Installing place package
Success: package place installed
Installing txtindex package
Success: package txtindex installed
Installing voltagesecure package
Success: package voltagesecure installed
Syncing catalog on vmart with 2000 attempts.
Database creation SQL tasks completed successfully. Database vmart created successfully.
| Tamanho do objeto (byte) | Caminho completo da chave do balde/objeto |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Desativação das limitações de streaming
Este procedimento é baseado no guia Vertica para outro armazenamento de objetos no local e deve ser aplicável ao StorageGRID.
-
Depois de criar o banco de dados, desative o
AWSStreamingConnectionPercentageparâmetro de configuração definindo-o como0. Esta configuração é desnecessária para uma instalação no local do modo Eon com armazenamento comunitário. Este parâmetro de configuração controla o número de conexões ao armazenamento de objetos que o Vertica usa para leituras de streaming. Em um ambiente de nuvem, essa configuração ajuda a evitar que os dados de streaming do armazenamento de objetos usem todas as alças de arquivo disponíveis. Ele deixa algumas alças de arquivo disponíveis para outras operações de armazenamento de objetos. Devido à baixa latência de armazenamentos de objetos no local, essa opção é desnecessária. -
Use uma
vsqlinstrução para atualizar o valor do parâmetro. A senha é a senha do banco de dados que você definiu em "criando o banco de dados on-premises Eon". Por exemplo, veja a seguinte saída de amostra:
[dbadmin@vertica-vm1 ~]$ vsql
Password:
Welcome to vsql, the Vertica Analytic Database interactive terminal.
Type: \h or \? for help with vsql commands
\g or terminate with semicolon to execute query
\q to quit
dbadmin=> ALTER DATABASE DEFAULT SET PARAMETER AWSStreamingConnectionPercentage = 0; ALTER DATABASE
dbadmin=> \q
Verificando as configurações do depósito
As configurações padrão de depósito do banco de dados Vertica são ativadas (valor de 1) para operações de leitura e gravação. A NetApp recomenda fortemente que essas configurações do depósito estejam ativadas para aprimorar o desempenho.
vsql -c 'show current all;' | grep -i UseDepot DATABASE | UseDepotForReads | 1 DATABASE | UseDepotForWrites | 1
Carregamento de dados de amostra (opcional)
Se este banco de dados for para teste e será removido, você pode carregar dados de amostra para este banco de dados para teste. O Vertica vem com um conjunto de dados de amostra, VMart, encontrado em /opt/vertica/examples/VMart_Schema/ cada nó Vertica. Você pode encontrar mais informações sobre este conjunto de "aqui"dados de amostra .
Siga estes passos para carregar os dados de amostra:
-
Faça login como dbadmin em um dos nós Vertica: cd /opt/vertica/examples/VMart_Schema/
-
Carregue dados de amostra para o banco de dados e insira a senha do banco de dados quando solicitado nas subetapas c e d:
-
cd /opt/vertica/examples/VMart_Schema -
./vmart_gen -
vsql < vmart_define_schema.sql -
vsql < vmart_load_data.sql
-
-
Existem várias consultas SQL predefinidas, você pode executar algumas delas para confirmar que os dados de teste são carregados com sucesso no banco de dados. Por exemplo:
vsql < vmart_queries1.sql
Onde encontrar informações adicionais
Para saber mais sobre as informações descritas neste documento, consulte os seguintes documentos e/ou sites:
Histórico de versões
| Versão | Data | Histórico de versões do documento |
|---|---|---|
Versão 1,0 |
Setembro de 2021 |
Lançamento inicial. |
Por Angela Cheng