

Remontar e reformatar volumes de armazenamento do appliance StorageGRID (etapas manuais)
 Sugerir alterações
Sugerir alterações
É necessário executar manualmente dois scripts para remontar volumes de storage preservados e reformatar os volumes de storage com falha. O primeiro script remonta volumes que são formatados corretamente como volumes de armazenamento StorageGRID. O segundo script reformata quaisquer volumes não montados, reconstrói o banco de dados Cassandra, se necessário, e inicia os serviços.
-
Você já substituiu o hardware para quaisquer volumes de armazenamento com falha que você sabe que precisam ser substituídos.
A execução
sn-remount-volumesdo script pode ajudá-lo a identificar volumes de armazenamento com falha adicionais. -
Você verificou se o descomissionamento do nó de armazenamento não está em andamento ou pausou o procedimento de descomissionamento do nó. (No Grid Manager, selecione Manutenção > Tarefas > Desativação.)
-
Você verificou que não há nenhuma expansão em andamento. (No Grid Manager, selecione Manutenção > Tarefas > Expansão.)

|
Entre em contato com o suporte técnico se mais de um nó de armazenamento estiver offline. Não execute o sn-recovery-postinstall.sh roteiro.
|
Para concluir este procedimento, execute estas tarefas de alto nível:
-
Faça login no nó de armazenamento recuperado.
-
Execute
sn-remount-volumeso script para remontar volumes de armazenamento devidamente formatados. Quando este script é executado, ele faz o seguinte:-
Monta e desmonta cada volume de armazenamento para reproduzir o diário XFS.
-
Executa uma verificação de consistência de arquivo XFS.
-
Se o sistema de arquivos for consistente, determina se o volume de armazenamento é um volume de armazenamento StorageGRID formatado corretamente.
-
Se o volume de armazenamento estiver formatado corretamente, remonta o volume de armazenamento. Todos os dados existentes no volume permanecem intactos.
-
-
Revise a saída do script e resolva quaisquer problemas.
-
Execute
sn-recovery-postinstall.sho script. Quando este script é executado, ele faz o seguinte.
Não reinicie um nó de armazenamento durante a recuperação antes de executar sn-recovery-postinstall.sh(etapa 4) para reformatar os volumes de armazenamento com falha e restaurar os metadados de objetos. A reinicialização do nó de armazenamento antessn-recovery-postinstall.shda conclusão causa erros para serviços que tentam iniciar e faz com que os nós do dispositivo StorageGRID saiam do modo de manutenção.-
Reformata todos os volumes de armazenamento que o
sn-remount-volumesscript não pôde montar ou que foram encontrados para serem formatados incorretamente.
Se um volume de armazenamento for reformatado, todos os dados nesse volume serão perdidos. Você deve executar um procedimento adicional para restaurar dados de objetos de outros locais na grade, assumindo que as regras ILM foram configuradas para armazenar mais de uma cópia de objeto. -
Reconstrói o banco de dados Cassandra no nó, se necessário.
-
Inicia os serviços no nó de storage.
-
-
Faça login no nó de storage recuperado:
-
Introduza o seguinte comando:
ssh admin@grid_node_IP -
Introduza a palavra-passe listada no
Passwords.txtficheiro. -
Digite o seguinte comando para mudar para root:
su - -
Introduza a palavra-passe listada no
Passwords.txtficheiro.
Quando você estiver conetado como root, o prompt mudará de
$para#. -
-
Execute o primeiro script para remontar quaisquer volumes de armazenamento devidamente formatados.
Se todos os volumes de armazenamento forem novos e precisarem ser formatados, ou se todos os volumes de armazenamento tiverem falhado, você poderá pular esta etapa e executar o segundo script para reformatar todos os volumes de armazenamento não montados. -
Execute o script:
sn-remount-volumesEsse script pode levar horas para ser executado em volumes de armazenamento que contêm dados.
-
À medida que o script é executado, revise a saída e responda a quaisquer prompts.
Conforme necessário, você pode usar o tail -fcomando para monitorar o conteúdo do arquivo de log do script (/var/local/log/sn-remount-volumes.log) . O arquivo de log contém informações mais detalhadas do que a saída da linha de comando.root@SG:~ # sn-remount-volumes The configured LDR noid is 12632740 ====== Device /dev/sdb ====== Mount and unmount device /dev/sdb and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sdb: Mount device /dev/sdb to /tmp/sdb-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12632740, volume number 0 in the volID file Attempting to remount /dev/sdb Device /dev/sdb remounted successfully ====== Device /dev/sdc ====== Mount and unmount device /dev/sdc and checking file system consistency: Error: File system consistency check retry failed on device /dev/sdc. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policies. Don't continue to the next step if you believe that the data remaining on this volume can't be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sdd ====== Mount and unmount device /dev/sdd and checking file system consistency: Failed to mount device /dev/sdd This device could be an uninitialized disk or has corrupted superblock. File system check might take a long time. Do you want to continue? (y or n) [y/N]? y Error: File system consistency check retry failed on device /dev/sdd. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policies. Don't continue to the next step if you believe that the data remaining on this volume can't be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sde ====== Mount and unmount device /dev/sde and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sde: Mount device /dev/sde to /tmp/sde-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12000078, volume number 9 in the volID file Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
Na saída de exemplo, um volume de armazenamento foi remontado com sucesso e três volumes de armazenamento tiveram erros.
-
/dev/sdbPassou a verificação de consistência do sistema de arquivos XFS e teve uma estrutura de volume válida, então foi remontada com sucesso. Os dados em dispositivos que são remontados pelo script são preservados. -
/dev/sdcFalha na verificação de consistência do sistema de arquivos XFS porque o volume de armazenamento era novo ou corrompido. -
/dev/sddnão foi possível montar porque o disco não foi inicializado ou o superbloco do disco estava corrompido. Quando o script não consegue montar um volume de armazenamento, ele pergunta se você deseja executar a verificação de consistência do sistema de arquivos.-
Se o volume de armazenamento estiver conetado a um novo disco, responda N ao prompt. Você não precisa verificar o sistema de arquivos em um novo disco.
-
Se o volume de armazenamento estiver conetado a um disco existente, responda Y ao prompt. Você pode usar os resultados da verificação do sistema de arquivos para determinar a origem da corrupção. Os resultados são guardados no
/var/local/log/sn-remount-volumes.logficheiro de registo.
-
-
/dev/sdePassou a verificação de consistência do sistema de ficheiros XFS e tinha uma estrutura de volume válida; no entanto, a ID do nó LDR novolIDficheiro não correspondia à ID deste nó de armazenamento (aconfigured LDR noidapresentada na parte superior). Esta mensagem indica que este volume pertence a outro nó de armazenamento.
-
-
-
Revise a saída do script e resolva quaisquer problemas.
Se um volume de armazenamento falhou na verificação de consistência do sistema de arquivos XFS ou não pôde ser montado, revise cuidadosamente as mensagens de erro na saída. Você deve entender as implicações da execução sn-recovery-postinstall.shdo script nesses volumes.-
Verifique se os resultados incluem uma entrada para todos os volumes esperados. Se algum volume não estiver listado, execute novamente o script.
-
Reveja as mensagens de todos os dispositivos montados. Certifique-se de que não existem erros que indiquem que um volume de armazenamento não pertence a este nó de armazenamento.
No exemplo, a saída para /dev/sde inclui a seguinte mensagem de erro:
Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
Se um volume de armazenamento for comunicado como pertencente a outro nó de armazenamento, contacte o suporte técnico. Se você executar sn-recovery-postinstall.sho script, o volume de armazenamento será reformatado, o que pode causar perda de dados. -
Se não for possível montar qualquer dispositivo de armazenamento, anote o nome do dispositivo e repare ou substitua o dispositivo.
Deve reparar ou substituir quaisquer dispositivos de armazenamento que não possam ser montados. Você usará o nome do dispositivo para procurar o ID do volume, que é a entrada necessária quando você executar
repair-datao script para restaurar os dados do objeto para o volume (o próximo procedimento). -
Depois de reparar ou substituir todos os dispositivos não montáveis, execute o
sn-remount-volumesscript novamente para confirmar que todos os volumes de armazenamento que podem ser remontados foram remontados.
Se um volume de armazenamento não puder ser montado ou for formatado incorretamente e você continuar para a próxima etapa, o volume e quaisquer dados no volume serão excluídos. Se você tiver duas cópias de dados de objeto, você terá apenas uma única cópia até concluir o próximo procedimento (restaurando dados de objeto).
Não execute sn-recovery-postinstall.sho script se você acredita que os dados restantes em um volume de armazenamento com falha não podem ser reconstruídos de outro lugar na grade (por exemplo, se sua política de ILM usar uma regra que faça apenas uma cópia ou se os volumes tiverem falhado em vários nós). Em vez disso, entre em Contato com o suporte técnico para determinar como recuperar seus dados. -
-
Execute
sn-recovery-postinstall.sho script:sn-recovery-postinstall.shEste script reformata quaisquer volumes de armazenamento que não puderam ser montados ou que foram encontrados para serem formatados incorretamente; reconstrói o banco de dados Cassandra no nó, se necessário; e inicia os serviços no nó Storage Node.
Tenha em atenção o seguinte:
-
O script pode levar horas para ser executado.
-
Em geral, você deve deixar a sessão SSH sozinha enquanto o script estiver sendo executado.
-
Não pressione Ctrl C enquanto a sessão SSH estiver ativa.
-
O script será executado em segundo plano se ocorrer uma interrupção da rede e terminar a sessão SSH, mas você pode visualizar o progresso da página recuperação.
-
Se o nó de armazenamento usar o serviço RSM, o script pode parecer parar por 5 minutos à medida que os serviços do nó são reiniciados. Este atraso de 5 minutos é esperado sempre que o serviço RSM arranca pela primeira vez.
O serviço RSM está presente nos nós de storage que incluem o serviço ADC.
Alguns procedimentos de recuperação do StorageGRID usam o Reaper para lidar com reparos do Cassandra. As reparações ocorrem automaticamente assim que os serviços relacionados ou necessários tiverem sido iniciados. Você pode notar saída de script que menciona "Reaper" ou "Cassandra repair". Se aparecer uma mensagem de erro indicando que a reparação falhou, execute o comando indicado na mensagem de erro. -
-
À medida que o
sn-recovery-postinstall.shscript é executado, monitore a página recuperação no Gerenciador de Grade.A barra de progresso e a coluna Estágio na página recuperação fornecem um status de alto nível
sn-recovery-postinstall.shdo script.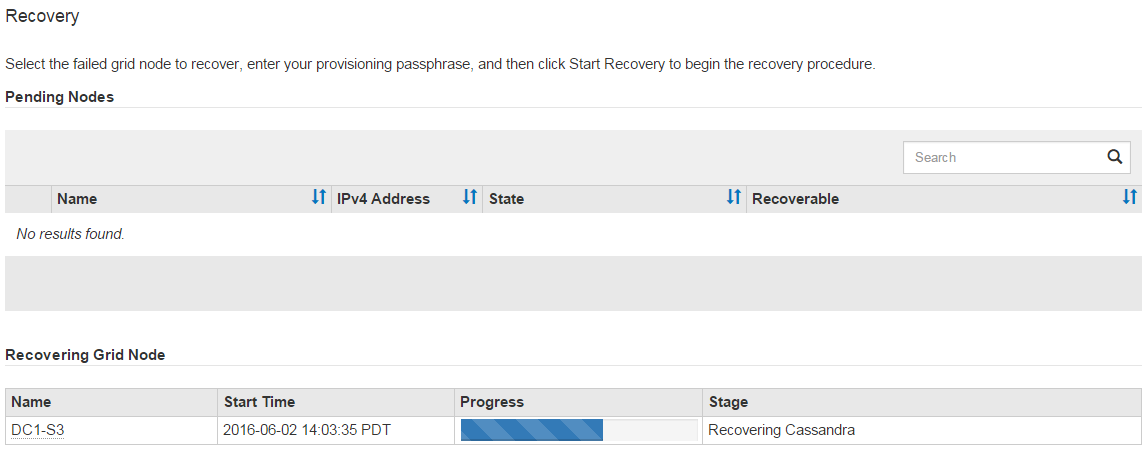
-
Depois que o
sn-recovery-postinstall.shscript iniciar os serviços no nó, você pode restaurar os dados do objeto para qualquer volume de armazenamento formatado pelo script.O script pergunta se você deseja usar o processo de restauração de volume do Gerenciador de Grade.
-
Na maioria dos casos, você deve "Restaure dados de objetos usando o Gerenciador de Grade". Resposta
ypara usar o Gerenciador de Grade. -
Em casos raros, como quando instruído pelo suporte técnico ou quando você souber que o nó de substituição tem menos volumes disponíveis para storage de objetos do que o nó original, você deve "restaure os dados do objeto manualmente" usar o
repair-datascript. Se um desses casos se aplicar, respondan.
Se você responder
nao uso do processo de restauração de volume do Gerenciador de Grade (restaurar dados de objeto manualmente):-
Não é possível restaurar dados de objetos usando o Gerenciador de Grade.
-
Você pode monitorar o progresso dos trabalhos de restauração manual usando o Gerenciador de Grade.
Depois de fazer sua seleção, o script é concluído e os próximos passos para recuperar dados de objeto são mostrados. Depois de rever estes passos, prima qualquer tecla para regressar à linha de comando.
-
-