

Identify the problem and perform corrective actions for a failed protection job
 Suggest changes
Suggest changes
You review the job failure error message in the Cause field on the Event details page and determine that the job failed because of a Snapshot copy error. You then proceed to the Volume / Health details page to gather more information.
You must have the Application Administrator role.
The error message provided in the Cause field on the Event details page contains the following text about the failed job:
Protection Job Failed. Reason: (Transfer operation for relationship 'cluster2_src_svm:cluster2_src_vol2->cluster3_dst_svm: managed_svc2_vol3' ended unsuccessfully. Last error reported by Data ONTAP: Failed to create Snapshot copy 0426cluster2_src_vol2snap on volume cluster2_src_svm:cluster2_src_vol2. (CSM: An operation failed due to an ONC RPC failure.) Job Details
This message provides the following information:
-
A backup or mirror job did not complete successfully.
The job involved a protection relationship between the source volume
cluster2_src_vol2on the virtual servercluster2_src_svmand the destination volumemanaged_svc2_vol3on the virtual server namedcluster3_dst_svm. -
A Snapshot copy job failed for
0426cluster2_src_vol2snapon the source volumecluster2_src_svm:/cluster2_src_vol2.
In this scenario, you can identify the cause and potential corrective actions of the job failure. However, resolving the failure requires that you access either the System Manager web UI or the ONTAP CLI commands.
-
You review the error message and determine that a Snapshot copy job failed on the source volume, indicating that there is probably a problem with your source volume.
Optionally, you could click the Job Details link at the end of the error message, but for the purposes of this scenario, you choose not to do that.
-
You decide that you want to try to resolve the event, so you do the following:
-
Click the Assign To button and select Me from the menu.
-
Click the Acknowledge button so that you do not continue to receive repeat alert notifications, if alerts were set for the event.
-
Optionally, you can also add notes about the event.
-
-
Click the Source field in the Summary pane to see details about the source volume.
The Source field contains the name of the source object: in this case, the volume on which the Snapshot copy job was scheduled.
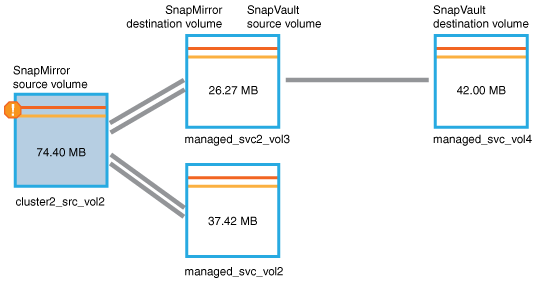
The Volume / Health details page displays for
cluster2_src_vol2, showing the content of the Protection tab. -
Looking at the protection topology graph, you see an error icon associated with the first volume in the topology, which is the source volume for the SnapMirror relationship.
You also see the horizontal bars in the source volume icon, indicating the warning and error thresholds set for that volume.
-
You place your cursor over the error icon to see the pop-up dialog box that displays the threshold settings and see that the volume has exceeded the error threshold, indicating a capacity issue.
-
Click the Capacity tab.
Capacity information about volume
cluster2_src_vol2displays. -
In the Capacity panel, you see that there is an error icon in the bar graph, again indicating that the volume capacity has surpassed the threshold level set for the volume.
-
Below the capacity graph, you see that volume autogrow has been disabled and that a volume space guarantee has been set.
You could decide to enable autogrow, but for the purposes of this scenario, you decide to investigate further before making a decision about how to resolve the capacity problem.
-
You scroll down to the Events list and see that Protection Job Failed, Volume Days Until Full, and Volume Space Full events were generated.
-
In the Events list, you click the Volume Space Full event to get more information, having decided that this event seems most relevant to your capacity issue.
The Event details page displays the Volume Space Full event for the source volume.
-
In the Summary area, you read the Cause field for the event:
The full threshold set at 90% is breached. 45.38 MB (95.54%) of 47.50 MB is used. -
Below the Summary area, you see Suggested Corrective Actions.

The Suggested Corrective Actions display only for some events, so you do not see this area for all types of events.
You click through the list of suggested actions that you might perform to resolve the Volume Space Full event:
-
Enable autogrow on this volume.
-
Resize the volume.
-
Enable and run deduplication on this volume.
-
Enable and run compression on this volume.
-
-
You decide to enable autogrow on the volume, but to do so, you must determine the available free space on the parent aggregate and the current volume growth rate:
-
Look at the parent aggregate,
cluster2_src_aggr1, in the Related Devices pane.
You can click the name of the aggregate to get further details about the aggregate.
You determine that the aggregate has sufficient space to enable volume autogrow.
-
At the top of the page, look at the icon indicating a critical incident and review the text below the icon.
You determine that "Days to Full: Less than a day | Daily Growth Rate: 5.4%".
-
-
Go to System Manager or access the ONTAP CLI to enable the
volume autogrowoption.
Make note of the names of the volume and aggregate so you have them available when enabling autogrow.
-
After resolving the capacity issue, return to the Unified Manager Event details page and mark the event as resolved.