TR-4920: FlexPod Datacenter with NetApp SnapMirror Business Continuity and ONTAP 9.10
 Suggest changes
Suggest changes
Jyh-shing Chen, NetApp
Introduction
FlexPod solution
FlexPod is a best-practice converged-infrastructure data center architecture that includes the following components from Cisco and NetApp:
-
Cisco Unified Computing System (Cisco UCS)
-
Cisco Nexus and MDS families of switches
-
NetApp FAS, NetApp AFF, and NetApp All SAN Array (ASA) systems
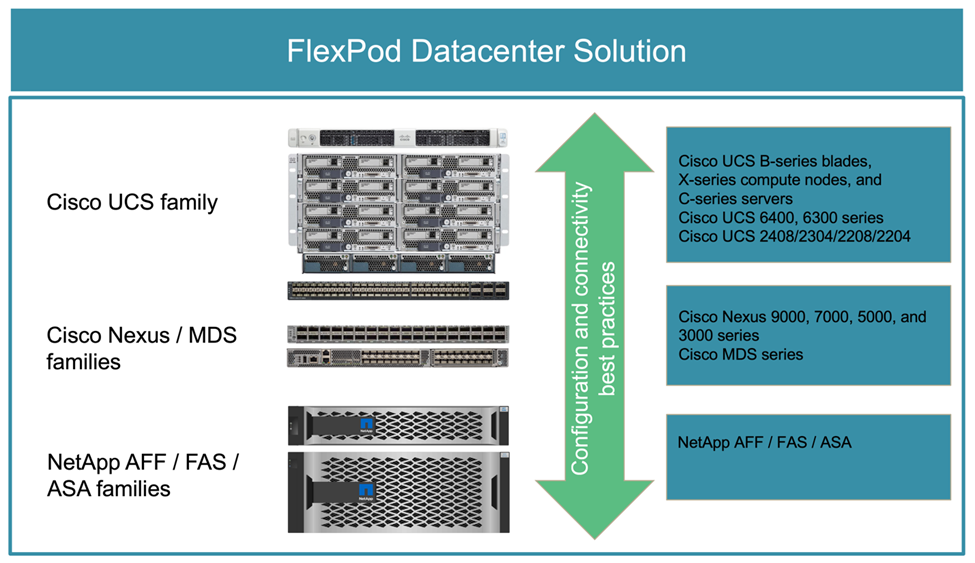
The following figure depicts some of the components used for creating FlexPod solutions. These components are connected and configured according to the best practices of both Cisco and NetApp to provide an ideal platform for running a variety of enterprise workloads with confidence.
A large portfolio of Cisco Validated Designs (CVDs) and NetApp Verified Architectures (NVAs) are available. These CVDs and NVAs cover all major data center workloads and are the result of continued collaborations and innovations between NetApp and Cisco on FlexPod solutions.
Incorporating extensive testing and validations in their creation process, FlexPod CVDs and NVAs provide reference solution architecture designs and step-by-step deployment guides to help partners and customers deploy and adopt FlexPod solutions. By using these CVDs and NVAs as guides for design and implementation, businesses can reduce risks; reduce solution downtime; and increase the availability, scalability, flexibility, and security of the FlexPod solutions they deploy.
Each of the FlexPod component families shown (Cisco UCS, Cisco Nexus/MDS switches, and NetApp storage) offers platform and resource options to scale the infrastructure up or down, while supporting the features and functionality that are required under the configuration and connectivity best practices of FlexPod. FlexPod can also scale out for environments that require multiple consistent deployments by rolling out additional FlexPod stacks.
Disaster recovery and business continuity
There are various methods that companies can adopt to make sure that they can quickly recover their application and data services from disasters. Having a disaster recovery (DR) and business continuity (BC) plan, implementing a solution which meets the business objectives, and performing regular testing of the disaster scenarios enables companies to recover from a disaster and continue critical business services after a disaster situation occurs.
Companies might have different DR and BC requirements for different types of application and data services. Some applications and data might not be needed during an emergency or disaster situation, while others might need to be continuously available to support business requirements.
For mission- critical application and data services that could disrupt your business when they are not available, a careful evaluation is needed to answer questions such as what kind of maintenance and disaster scenarios the business needs to consider, how much data the business can afford to lose in case of a disaster, and how quickly the recovery can and should take place.
For businesses that rely on data services for revenue generation, the data services might need to be protected by a solution that can withstand not only various single-point-of-failure scenarios but also a site outage disaster scenario to provide continuous business operations.
Recovery point objective and recovery time objective
The recovery point objective (RPO) measures how much data, in terms of time, you can afford to lose, or the point up to which you can recover your data. With a daily backup plan, a company might lose a day’s worth of data because the changes made to the data since the last backup could be lost in a disaster. For business-critical and mission-critical data services, you might require a zero RPO and an associated plan and infrastructures to protect data without any data loss.
The recovery time objective (RTO) measures how much time you can afford to not have the data available, or how quickly data services must be brought back up. For example, a company might have a backup and recovery implementation that uses traditional tapes for certain data sets due to its size. As a result, to restore the data from the backup tapes, it might take several hours, or even days if there is an infrastructure failure. Time considerations must also include time to bring the infrastructure back up in addition to restoring data. For mission-critical data services, you might require a very low RTO and thus can only tolerate a failover time of seconds or minutes to quickly bring the data services back online for business continuity.
SM-BC
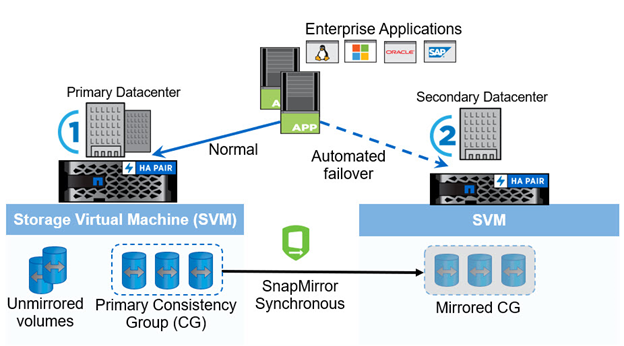
Beginning with ONTAP 9.8, you can protect SAN workloads for transparent application failover with NetApp SM-BC. You can create consistency group relationships between two AFF clusters or two ASA clusters for data replication to achieve zero RPO and near zero RTO.
The SM-BC solution replicates data by using the SnapMirror Synchronous technology over an IP network. It provides application-level granularity and automatic failover to protect your business-critical data services such as Microsoft SQL Server, Oracle, and so on with iSCSI or FC protocol-based SAN LUNs. An ONTAP Mediator deployed at a third site monitors the SM-BC solution and enables automatic failover upon a site disaster.
A consistency group (CG) is a collection of FlexVol volumes that provides a write order consistency guarantee for the application workload which needs to be protected for business continuity. It enables simultaneous crash-consistent Snapshot copies of a collection of volumes at a point in time. A SnapMirror relationship, also known as a CG relationship, is established between a source CG and a destination CG. The group of volumes picked to be part of a CG can be mapped to an application instance, a group of applications instances, or for an entire solution. In addition, the SM-BC consistency group relationships can be created or deleted on demand based on business requirements and changes.
As illustrated in the following figure, the data in the consistency group is replicated to a second ONTAP cluster for disaster recovery and business continuity. The applications have connectivity to the LUNs in both ONTAP clusters. I/O is normally served by the primary cluster and automatically resumes from the secondary cluster if a disaster happens at the primary. When designing a SM-BC solution, the supported object counts for the CG relationships (for example, a maximum of 20 CGs and maximum of 200 endpoints) must be observed to avoid exceeding the supported limits.