

Replace the NVRAM module or NVRAM DIMMs - FAS9000
 Suggest changes
Suggest changes
The NVRAM module consists of the NVRAM10 and DIMMs and up to two NVMe SSD Flash Cache modules (Flash Cache or caching modules) per NVRAM module. You can replace a failed NVRAM module or the DIMMs inside the NVRAM module.
To replace a failed NVRAM module, you must remove it from the chassis, remove the Flash Cache module or modules from the NVRAM module, move the DIMMs to the replacement module, reinstall the Flash Cache module or modules, and install the replacement NVRAM module into the chassis.
Because the system ID is derived from the NVRAM module, if replacing the module, disks belonging to the system are reassigned to the new system ID.
-
All disk shelves must be working properly.
-
If your system is in an HA pair, the partner node must be able to take over the node associated with the NVRAM module that is being replaced.
-
This procedure uses the following terminology:
-
The impaired node is the node on which you are performing maintenance.
-
The healthy node is the HA partner of the impaired node.
-
-
This procedure includes steps for automatically or manually reassigning disks to the controller module associated with the new NVRAM module. You must reassign the disks when directed to in the procedure. Completing the disk reassignment before giveback can cause issues.
-
You must replace the failed component with a replacement FRU component you received from your provider.
-
You cannot change any disks or disk shelves as part of this procedure.
Step 1: Shut down the impaired controller
Shut down or take over the impaired controller using one of the following options.
Take over and halt the impaired controller so that the healthy controller continues to serve data from the impaired controller's storage. To do this, you suppress automatic case creation in AutoSupport, disable automatic giveback, and bring the impaired controller to the LOADER prompt. The LOADER prompt is the safe halted state from which you can replace the FRU.
-
If you have a SAN system, you must have checked event messages (
cluster kernel-service show) for the impaired controller SCSI blade. Thecluster kernel-service showcommand (from priv advanced mode) displays the node name, quorum status of that node, availability status of that node, and operational status of that node.Each SCSI-blade process should be in quorum with the other nodes in the cluster. Any issues must be resolved before you proceed with the replacement.
-
If you have a cluster with more than two nodes, it must be in quorum. If the cluster is not in quorum or a healthy controller shows false for eligibility and health, you must correct the issue before shutting down the impaired controller; see Synchronize a node with the cluster.
-
If AutoSupport is enabled, suppress automatic case creation by invoking an AutoSupport message:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hThis prevents automatic support cases from being opened during your planned maintenance window. The maximum suppression duration is 72 hours. If your maintenance completes early, you can re-enable case creation by invoking an AutoSupport message with
MAINT=END. For more information, see How to suppress automatic case creation during scheduled maintenance windows.The following AutoSupport message suppresses automatic case creation for two hours:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Disable automatic giveback:
-
Enter the following command from the console of the healthy controller:
storage failover modify -node impaired_node_name -auto-giveback false -
Enter
ywhen you see the prompt Do you want to disable auto-giveback?
-
-
Take the impaired controller to the LOADER prompt:
If the impaired controller is displaying… Then… The LOADER prompt
Go to the next step.
Waiting for giveback…
Press Ctrl-C, and then respond
ywhen prompted.System prompt or password prompt
Take over or halt the impaired controller from the healthy controller:
storage failover takeover -ofnode impaired_node_name -halt trueThe -halt true parameter brings you to the LOADER prompt.
To shut down the impaired controller, you must determine the status of the controller and, if necessary, switch over the controller so that the healthy controller continues to serve data from the impaired controller storage.
-
You must leave the power supplies turned on at the end of this procedure to provide power to the healthy controller.
-
Check the MetroCluster status to determine whether the impaired controller has automatically switched over to the healthy controller:
metrocluster show -
Depending on whether an automatic switchover has occurred, proceed according to the following table:
If the impaired controller… Then… Has automatically switched over
Proceed to the next step.
Has not automatically switched over
Perform a planned switchover operation from the healthy controller:
metrocluster switchoverHas not automatically switched over, you attempted switchover with the
metrocluster switchovercommand, and the switchover was vetoedReview the veto messages and, if possible, resolve the issue and try again. If you are unable to resolve the issue, contact technical support.
-
Resynchronize the data aggregates by running the
metrocluster heal -phase aggregatescommand from the surviving cluster.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
If the healing is vetoed, you have the option of reissuing the
metrocluster healcommand with the-override-vetoesparameter. If you use this optional parameter, the system overrides any soft vetoes that prevent the healing operation. -
Verify that the operation has been completed by using the metrocluster operation show command.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Check the state of the aggregates by using the
storage aggregate showcommand.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Heal the root aggregates by using the
metrocluster heal -phase root-aggregatescommand.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
If the healing is vetoed, you have the option of reissuing the
metrocluster healcommand with the -override-vetoes parameter. If you use this optional parameter, the system overrides any soft vetoes that prevent the healing operation. -
Verify that the heal operation is complete by using the
metrocluster operation showcommand on the destination cluster:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
On the impaired controller module, disconnect the power supplies.
Step 2: Replace the NVRAM module
To replace the NVRAM module, locate it in slot 6 in the chassis and follow the specific sequence of steps.
-
If you are not already grounded, properly ground yourself.
-
Move the Flash Cache module from the old NVRAM module to the new NVRAM module:
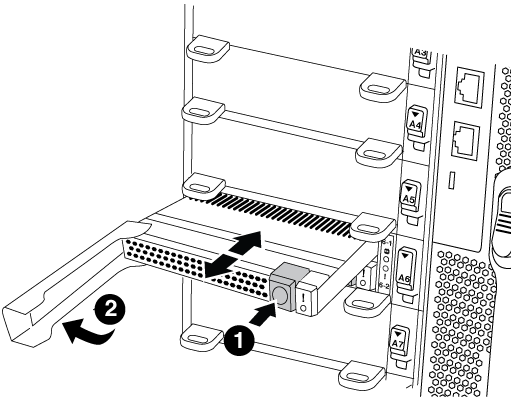

Orange release button (gray on empty Flash Cache modules)

Flash Cache cam handle
-
Press the orange button on the front of the Flash Cache module.

The release button on empty Flash Cache modules is gray. -
Swing the cam handle out until the module begins to slide out of the old NVRAM module.
-
Grasp the module cam handle and slide it out of the NVRAM module and insert it into the front of the new NVRAM module.
-
Gently push the Flash Cache module all the way into the NVRAM module, and then swing the cam handle closed until it locks the module in place.
-
-
Remove the target NVRAM module from the chassis:
-
Depress the lettered and numbered cam button.
The cam button moves away from the chassis.
-
Rotate the cam latch down until it is in a horizontal position.
The NVRAM module disengages from the chassis and moves out a few inches.
-
Remove the NVRAM module from the chassis by pulling on the pull tabs on the sides of the module face.
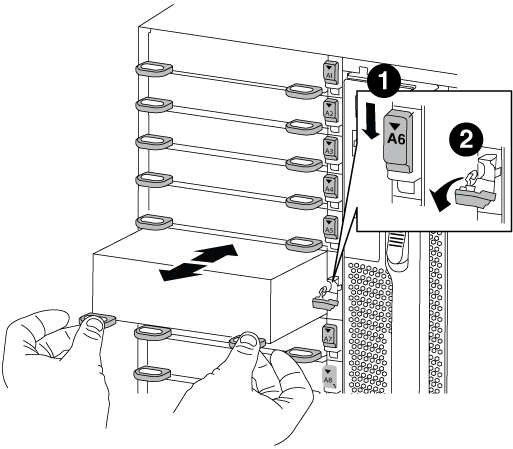
Lettered and numbered I/O cam latch
I/O latch completely unlocked
-
-
Set the NVRAM module on a stable surface and remove the cover from the NVRAM module by pushing down on the blue locking button on the cover, and then, while holding down the blue button, slide the lid off the NVRAM module.
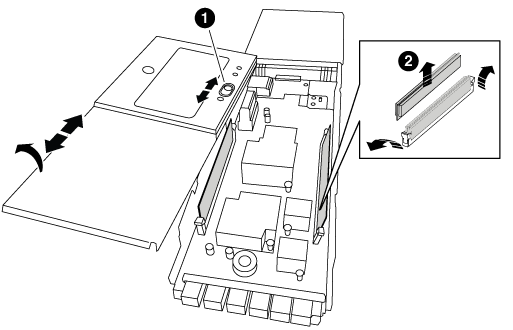
Cover locking button
DIMM and DIMM ejector tabs
-
Remove the DIMMs, one at a time, from the old NVRAM module and install them in the replacement NVRAM module.
-
Close the cover on the module.
-
Install the replacement NVRAM module into the chassis:
-
Align the module with the edges of the chassis opening in slot 6.
-
Gently slide the module into the slot until the lettered and numbered I/O cam latch begins to engage with the I/O cam pin, and then push the I/O cam latch all the way up to lock the module in place.
-
Step 3: Replace a NVRAM DIMM
To replace NVRAM DIMMs in the NVRAM module, you must remove the NVRAM module, open the module, and then replace the target DIMM.
-
If you are not already grounded, properly ground yourself.
-
Remove the target NVRAM module from the chassis:
-
Depress the lettered and numbered cam button.
The cam button moves away from the chassis.
-
Rotate the cam latch down until it is in a horizontal position.
The NVRAM module disengages from the chassis and moves out a few inches.
-
Remove the NVRAM module from the chassis by pulling on the pull tabs on the sides of the module face.
Lettered and numbered I/O cam latch
I/O latch completely unlocked
-
-
Set the NVRAM module on a stable surface and remove the cover from the NVRAM module by pushing down on the blue locking button on the cover, and then, while holding down the blue button, slide the lid off the NVRAM module.
Cover locking button
DIMM and DIMM ejector tabs
-
Locate the DIMM to be replaced inside the NVRAM module, and then remove it by pressing down on the DIMM locking tabs and lifting the DIMM out of the socket.
-
Install the replacement DIMM by aligning the DIMM with the socket and gently pushing the DIMM into the socket until the locking tabs lock in place.
-
Close the cover on the module.
-
Install the replacement NVRAM module into the chassis:
-
Align the module with the edges of the chassis opening in slot 6.
-
Gently slide the module into the slot until the lettered and numbered I/O cam latch begins to engage with the I/O cam pin, and then push the I/O cam latch all the way up to lock the module in place.
-
Step 4: Reboot the controller after FRU replacement
After you replace the FRU, you must reboot the controller module.
-
To boot ONTAP from the LOADER prompt, enter
bye.
Step 5: Reassign disks
Depending on whether you have an HA pair or two-node MetroCluster configuration, you must either verify the reassignment of disks to the new controller module or manually reassign the disks.
Select one of the following options for instructions on how to reassign disks to the new controller.
You must confirm the system ID change when you boot the replacement node and then verify that the change was implemented.

|
Disk reassignment is only needed when replacing the NVRAM module and does not apply to NVRAM DIMM replacement. |
-
If the replacement node is in Maintenance mode (showing the
*>prompt, exit Maintenance mode and go to the LOADER prompt:halt -
From the LOADER prompt on the replacement node, boot the node, entering
yif you are prompted to override the system ID due to a system ID mismatch.boot_ontap byeThe node will reboot, if autoboot is set.
-
Wait until the
Waiting for giveback…message is displayed on the replacement node console and then, from the healthy node, verify that the new partner system ID has been automatically assigned:storage failover showIn the command output, you should see a message that the system ID has changed on the impaired node, showing the correct old and new IDs. In the following example, node2 has undergone replacement and has a new system ID of 151759706.
node1> `storage failover show` Takeover Node Partner Possible State Description ------------ ------------ -------- ------------------------------------- node1 node2 false System ID changed on partner (Old: 151759755, New: 151759706), In takeover node2 node1 - Waiting for giveback (HA mailboxes) -
From the healthy node, verify that any coredumps are saved:
-
Change to the advanced privilege level:
set -privilege advancedYou can respond
Ywhen prompted to continue into advanced mode. The advanced mode prompt appears (*>). -
Save any coredumps:
system node run -node local-node-name partner savecore -
Wait for the `savecore`command to complete before issuing the giveback.
You can enter the following command to monitor the progress of the savecore command:
system node run -node local-node-name partner savecore -s -
Return to the admin privilege level:
set -privilege admin
-
-
Give back the node:
-
From the healthy node, give back the replaced node's storage:
storage failover giveback -ofnode replacement_node_nameThe replacement node takes back its storage and completes booting.
If you are prompted to override the system ID due to a system ID mismatch, you should enter
y.
If the giveback is vetoed, you can consider overriding the vetoes. -
After the giveback has been completed, confirm that the HA pair is healthy and that takeover is possible:
storage failover showThe output from the
storage failover showcommand should not include theSystem ID changed on partnermessage.
-
-
Verify that the disks were assigned correctly:
storage disk show -ownershipThe disks belonging to the replacement node should show the new system ID. In the following example, the disks owned by node1 now show the new system ID, 1873775277:
node1> `storage disk show -ownership` Disk Aggregate Home Owner DR Home Home ID Owner ID DR Home ID Reserver Pool ----- ------ ----- ------ -------- ------- ------- ------- --------- --- 1.0.0 aggr0_1 node1 node1 - 1873775277 1873775277 - 1873775277 Pool0 1.0.1 aggr0_1 node1 node1 1873775277 1873775277 - 1873775277 Pool0 . . .
-
If the system is in a MetroCluster configuration, monitor the status of the node:
metrocluster node showThe MetroCluster configuration takes a few minutes after the replacement to return to a normal state, at which time each node will show a configured state, with DR Mirroring enabled and a mode of normal. The
metrocluster node show -fields node-systemidcommand output displays the old system ID until the MetroCluster configuration returns to a normal state. -
If the node is in a MetroCluster configuration, depending on the MetroCluster state, verify that the DR home ID field shows the original owner of the disk if the original owner is a node on the disaster site.
This is required if both of the following are true:
-
The MetroCluster configuration is in a switchover state.
-
The replacement node is the current owner of the disks on the disaster site.
-
-
If your system is in a MetroCluster configuration, verify that each node is configured:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Verify that the expected volumes are present for each node:
vol show -node node-name -
If you disabled automatic takeover on reboot, enable it from the healthy node:
storage failover modify -node replacement-node-name -onreboot true
In a two-node MetroCluster configuration running ONTAP, you must manually reassign disks to the new controller's system ID before you return the system to normal operating condition.
This procedure applies only to systems in a two-node MetroCluster configuration running ONTAP.
You must be sure to issue the commands in this procedure on the correct node:
-
The impaired node is the node on which you are performing maintenance.
-
The replacement node is the new node that replaced the impaired node as part of this procedure.
-
The healthy node is the DR partner of the impaired node.
-
If you have not already done so, reboot the replacement node, interrupt the boot process by entering
Ctrl-C, and then select the option to boot to Maintenance mode from the displayed menu.You must enter
Ywhen prompted to override the system ID due to a system ID mismatch. -
View the old system IDs from the healthy node:
`metrocluster node show -fields node-systemid,dr-partner-systemid`In this example, the Node_B_1 is the old node, with the old system ID of 118073209:
dr-group-id cluster node node-systemid dr-partner-systemid ----------- --------------------- -------------------- ------------- ------------------- 1 Cluster_A Node_A_1 536872914 118073209 1 Cluster_B Node_B_1 118073209 536872914 2 entries were displayed.
-
View the new system ID at the Maintenance mode prompt on the impaired node:
disk showIn this example, the new system ID is 118065481:
Local System ID: 118065481 ... ... -
Reassign disk ownership (for FAS systems), by using the system ID information obtained from the disk show command:
disk reassign -s old system IDIn the case of the preceding example, the command is:
disk reassign -s 118073209You can respond
Ywhen prompted to continue. -
Verify that the disks were assigned correctly:
disk show -aVerify that the disks belonging to the replacement node show the new system ID for the replacement node. In the following example, the disks owned by system-1 now show the new system ID, 118065481:
*> disk show -a Local System ID: 118065481 DISK OWNER POOL SERIAL NUMBER HOME ------- ------------- ----- ------------- ------------- disk_name system-1 (118065481) Pool0 J8Y0TDZC system-1 (118065481) disk_name system-1 (118065481) Pool0 J8Y09DXC system-1 (118065481) . . .
-
From the healthy node, verify that any coredumps are saved:
-
Change to the advanced privilege level:
set -privilege advancedYou can respond
Ywhen prompted to continue into advanced mode. The advanced mode prompt appears (*>). -
Verify that the coredumps are saved:
system node run -node local-node-name partner savecoreIf the command output indicates that savecore is in progress, wait for savecore to complete before issuing the giveback. You can monitor the progress of the savecore using the
system node run -node local-node-name partner savecore -s command.</info>. -
Return to the admin privilege level:
set -privilege admin
-
-
If the replacement node is in Maintenance mode (showing the *> prompt), exit Maintenance mode and go to the LOADER prompt:
halt -
Boot the replacement node:
boot_ontap -
After the replacement node has fully booted, perform a switchback:
metrocluster switchback -
Verify the MetroCluster configuration:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Verify the operation of the MetroCluster configuration in Data ONTAP:
-
Check for any health alerts on both clusters:
system health alert show -
Confirm that the MetroCluster is configured and in normal mode:
metrocluster show -
Perform a MetroCluster check:
metrocluster check run -
Display the results of the MetroCluster check:
metrocluster check show -
Run Config Advisor. Go to the Config Advisor page on the NetApp Support Site at support.netapp.com/NOW/download/tools/config_advisor/.
After running Config Advisor, review the tool's output and follow the recommendations in the output to address any issues discovered.
-
-
Simulate a switchover operation:
-
From any node's prompt, change to the advanced privilege level:
set -privilege advancedYou need to respond with
ywhen prompted to continue into advanced mode and see the advanced mode prompt (*>). -
Perform the switchback operation with the -simulate parameter:
metrocluster switchover -simulate -
Return to the admin privilege level:
set -privilege admin
-
Step 6: Return the failed part to NetApp
Return the failed part to NetApp, as described in the RMA instructions shipped with the kit. See the Part Return and Replacements page for further information.