

Select Start Recovery to configure non-primary Admin Node
 Suggest changes
Suggest changes
After replacing a non-primary Admin Node, you must select Start Recovery in the Grid Manager to configure the new node as a replacement for the failed node.
-
You must be signed in to the Grid Manager using a supported web browser.
-
You must have the Maintenance or Root Access permission.
-
You must have the provisioning passphrase.
-
You must have deployed and configured the replacement node.
-
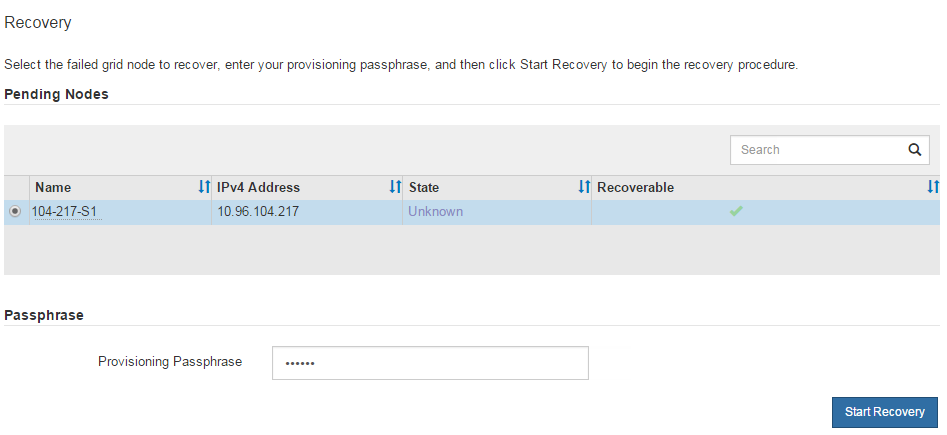
From the Grid Manager, select MAINTENANCE > Tasks > Recovery.
-
Select the grid node you want to recover in the Pending Nodes list.
Nodes appear in the list after they fail, but you cannot select a node until it has been reinstalled and is ready for recovery.
-
Enter the Provisioning Passphrase.
-
Click Start Recovery.
-
Monitor the progress of the recovery in the Recovering Grid Node table.

While the recovery procedure is running, you can click Reset to start a new recovery. An Info dialog box appears, indicating that the node will be left in an indeterminate state if you reset the procedure. 
If you want to retry the recovery after resetting the procedure, you must restore the node to a pre-installed state, as follows:
-
VMware: Delete the deployed virtual grid node. Then, when you are ready to restart the recovery, redeploy the node.
-
Linux: Restart the node by running this command on the Linux host:
storagegrid node force-recovery node-name -
Appliance: If you want to retry the recovery after resetting the procedure, you must restore the appliance node to a pre-installed state by running
sgareinstallon the node.
-
-
If single sign-on (SSO) is enabled for your StorageGRID system and the relying party trust for the Admin Node you recovered was configured to use the default management interface certificate, update (or delete and recreate) the node's relying party trust in Active Directory Federation Services (AD FS). Use the new default server certificate that was generated during the Admin Node recovery process.
To configure a relying party trust, see the instructions for administering StorageGRID. To access the default server certificate, log in to the command shell of the Admin Node. Go to the /var/local/mgmt-apidirectory, and select theserver.crtfile.