

Decommission disconnected grid nodes
 Suggest changes
Suggest changes
You might need to decommission a node that is not currently connected to the grid (one whose Health is Unknown or Administratively Down).
-
You understand the requirements and considerations for decommissioning grid nodes.
-
You have obtained all prerequisite items.
-
You have ensured that no data repair jobs are active. See Check data repair jobs.
-
You have confirmed that Storage Node recovery is not in progress anywhere in the grid. If it is, you must wait until any Cassandra rebuild performed as part of the recovery is complete. You can then proceed with decommissioning.
-
You have ensured that other maintenance procedures will not be run while the node decommission procedure is running, unless the node decommission procedure is paused.
-
The Decommission Possible column for the disconnected node or nodes you want to decommission includes a green check mark.
-
You have the provisioning passphrase.
You can identify disconnected nodes by looking for Unknown (blue) or Administratively Down (gray) icons in the Health column. In the example, the Storage Node named DC1-S4 is disconnected; all of the other nodes are connected.
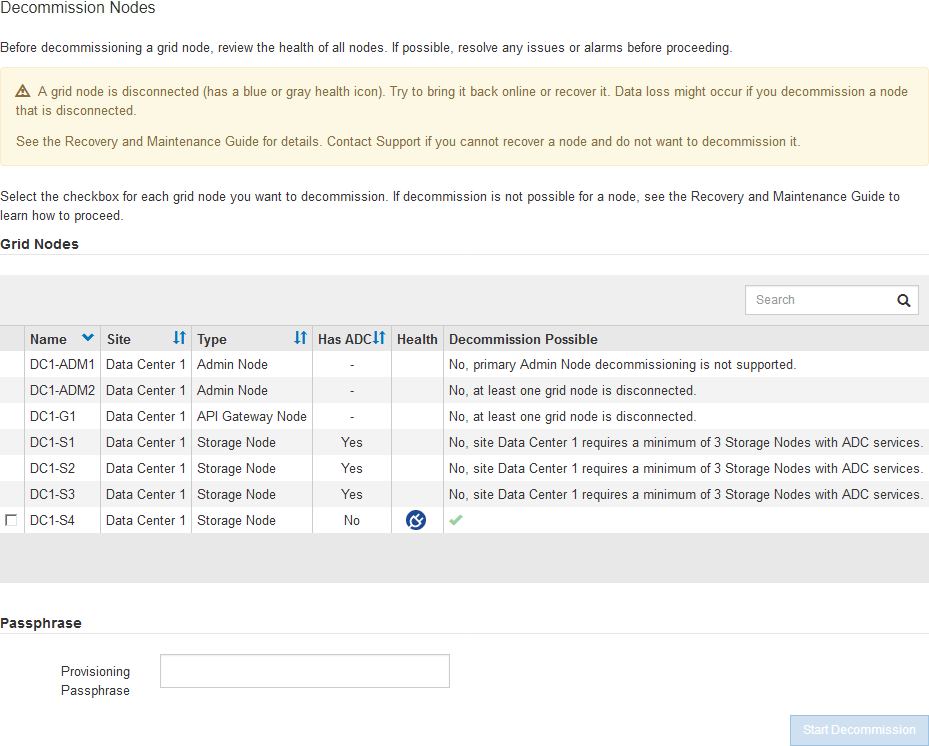
Before decommissioning any disconnected node, note the following:
-
This procedure is primarily intended for removing a single disconnected node. If your grid contains multiple disconnected nodes, the software requires you to decommission them all at the same time, which increases the potential for unexpected results.

Be careful when decommissioning more than one disconnected grid node at a time, especially if you are selecting multiple disconnected Storage Nodes. -
If a disconnected node can't be removed (for example, a Storage Node that is required for the ADC quorum), no other disconnected node can be removed.
Before decommissioning a disconnected Storage Node, note the following
-
You should never decommission a disconnected Storage Node unless you are sure it can't be brought online or recovered.
If you believe that object data can still be recovered from the node, don't perform this procedure. Instead, contact technical support to determine if node recovery is possible. -
If you decommission more than one disconnected Storage Node, data loss might occur. The system might not be able to reconstruct data if not enough object copies, erasure-coded fragments, or object metadata remain available.
If you have more than one disconnected Storage Node that you can't recover, contact technical support to determine the best course of action. -
When you decommission a disconnected Storage Node, StorageGRID starts data repair jobs at the end of the decommissioning process. These jobs attempt to reconstruct the object data and metadata that was stored on the disconnected node.
-
When you decommission a disconnected Storage Node, the decommission procedure completes relatively quickly. However, the data repair jobs can take days or weeks to run and aren't monitored by the decommission procedure. You must manually monitor these jobs and restart them as needed. See Check data repair jobs.
-
If you decommission a disconnected Storage Node that contains the only copy of an object, the object will be lost. The data repair jobs can only reconstruct and recover objects if at least one replicated copy or enough erasure-coded fragments exist on Storage Nodes that are currently connected.
Before decommissioning a disconnected Admin Node or Gateway Node, note the following:
-
When you decommission a disconnected Admin Node, you will lose the audit logs from that node; however, these logs should also exist on the primary Admin Node.
-
You can safely decommission a Gateway Node while it is disconnected.
-
Attempt to bring any disconnected grid nodes back online or to recover them.
See the recovery procedures for instructions.
-
If you are unable to recover a disconnected grid node and you want to decommission it while it is disconnected, select the checkbox for that node.

If your grid contains multiple disconnected nodes, the software requires you to decommission them all at the same time, which increases the potential for unexpected results.
Be careful when choosing to decommission more than one disconnected grid node at a time, especially if you are selecting multiple disconnected Storage Nodes. If you have more than one disconnected Storage Node that you can't recover, contact technical support to determine the best course of action. -
Enter the provisioning passphrase.
The Start Decommission button is enabled.
-
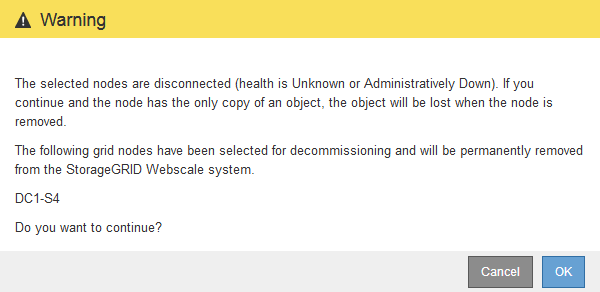
Click Start Decommission.
A warning appears, indicating that you have selected a disconnected node and that object data will be lost if the node has the only copy of an object.
-
Review the list of nodes, and click OK.
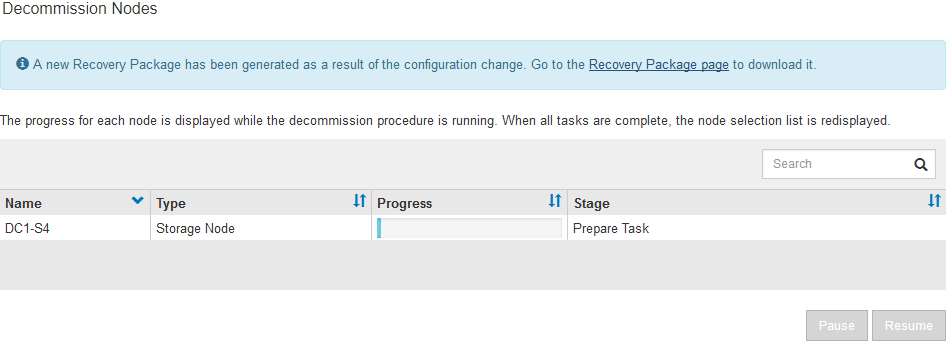
The decommission procedure starts, and the progress is displayed for each node. During the procedure, a new Recovery Package is generated containing the grid configuration change.
-
As soon as the new Recovery Package is available, click the link or select MAINTENANCE > System > Recovery package to access the Recovery Package page. Then, download the
.zipfile.See the instructions for downloading the Recovery Package.
Download the Recovery Package as soon as possible to ensure you can recover your grid if something goes wrong during the decommission procedure.
The Recovery Package file must be secured because it contains encryption keys and passwords that can be used to obtain data from the StorageGRID system. -
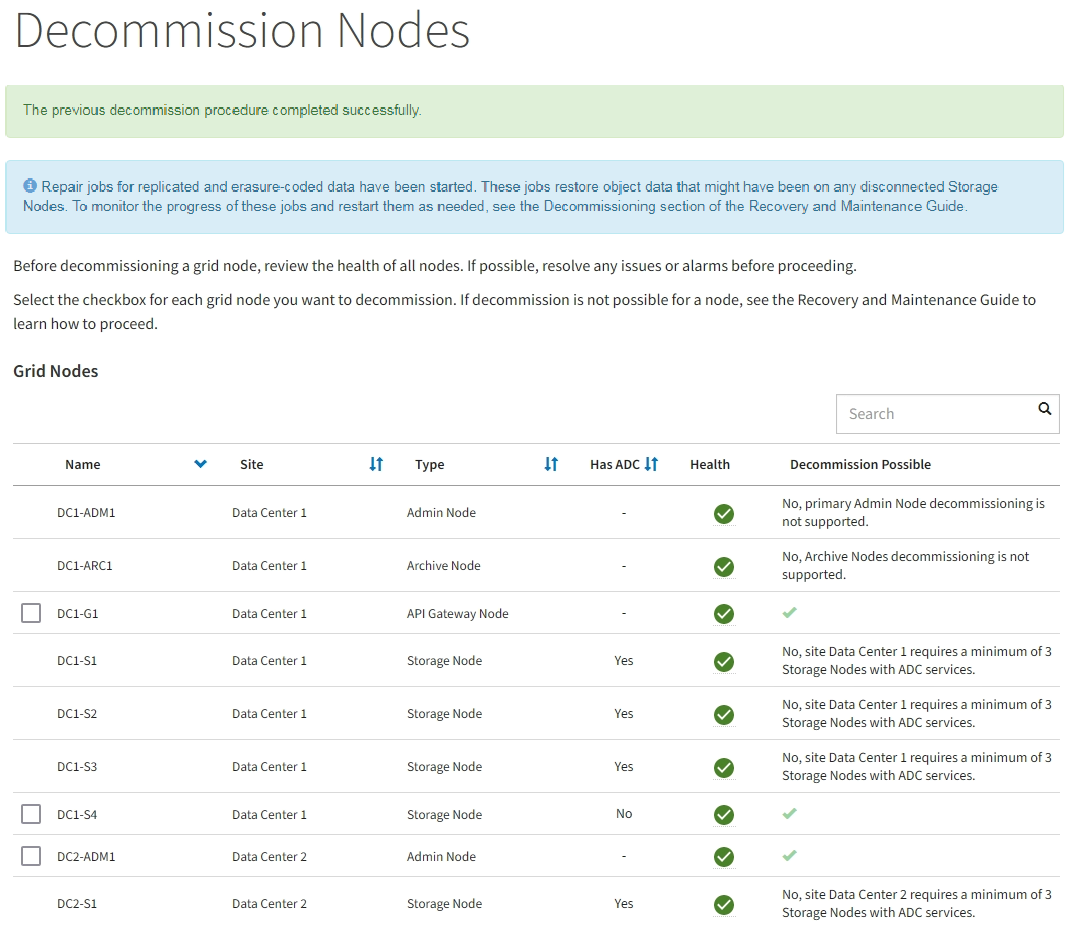
Periodically monitor the Decommission page to ensure that all selected nodes are decommissioned successfully.
Storage Nodes can take days or weeks to decommission. When all tasks are complete, the node selection list is redisplayed with a success message. If you decommissioned a disconnected Storage Node, an information message indicates that the repair jobs have been started.
-
After the nodes have shut down automatically as part of the decommission procedure, remove any remaining virtual machines or other resources that are associated with the decommissioned node.
Don't perform this step until the nodes have shut down automatically. -
If you are decommissioning a Storage Node, monitor the status of the replicated data and erasure-coded (EC) data repair jobs that are automatically started during the decommissioning process.
-
To get an estimated percent completion for the replicated repair, add the
show-replicated-repair-statusoption to the repair-data command.repair-data show-replicated-repair-status -
To determine if repairs are complete:
-
Select NODES > Storage Node being repaired > ILM.
-
Review the attributes in the Evaluation section. When repairs are complete, the Awaiting - All attribute indicates 0 objects.
-
-
To monitor the repair in more detail:
-
Select SUPPORT > Tools > Grid topology.
-
Select grid > Storage Node being repaired > LDR > Data Store.
-
Use a combination of the following attributes to determine, as well as possible, if replicated repairs are complete.
Cassandra inconsistencies might be present, and failed repairs aren't tracked. -
Repairs Attempted (XRPA): Use this attribute to track the progress of replicated repairs. This attribute increases each time a Storage Node tries to repair a high-risk object. When this attribute does not increase for a period longer than the current scan period (provided by the Scan Period — Estimated attribute), it means that ILM scanning found no high-risk objects that need to be repaired on any nodes.
High-risk objects are objects that are at risk of being completely lost. This does not include objects that don't satisfy their ILM configuration. -
Scan Period — Estimated (XSCM): Use this attribute to estimate when a policy change will be applied to previously ingested objects. If the Repairs Attempted attribute does not increase for a period longer than the current scan period, it is probable that replicated repairs are done. Note that the scan period can change. The Scan Period — Estimated (XSCM) attribute applies to the entire grid and is the maximum of all node scan periods. You can query the Scan Period — Estimated attribute history for the grid to determine an appropriate time frame.
-
-
To monitor the repair of erasure-coded data and retry any requests that might have failed:
-
Determine the status of erasure-coded data repairs:
-
Select SUPPORT > Tools > Metrics to view the estimated time to completion and the completion percentage for the current job. Then, select EC Overview in the Grafana section. Look at the Grid EC Job Estimated Time to Completion and Grid EC Job Percentage Completed dashboards.
-
Use this command to see the status of a specific
repair-dataoperation:repair-data show-ec-repair-status --repair-id repair ID -
Use this command to list all repairs:
repair-data show-ec-repair-statusThe output lists information, including
repair ID, for all previously and currently running repairs.
-
-
If the output shows that the repair operation failed, use the
--repair-idoption to retry the repair.This command retries a failed node repair, using the repair ID 6949309319275667690:
repair-data start-ec-node-repair --repair-id 6949309319275667690This command retries a failed volume repair, using the repair ID 6949309319275667690:
repair-data start-ec-volume-repair --repair-id 6949309319275667690
As soon as the disconnected nodes have been decommissioned and all data repair jobs have been completed, you can decommission any connected grid nodes as required.
Then, complete these steps after you complete the decommission procedure:
-
Ensure that the drives of the decommissioned grid node are wiped clean. Use a commercially available data wiping tool or service to permanently and securely remove data from the drives.
-
If you decommissioned an appliance node and the data on the appliance was protected using node encryption, use the StorageGRID Appliance Installer to clear the key management server configuration (Clear KMS). You must clear the KMS configuration if you want to add the appliance to another grid. For instructions, see Monitor node encryption in maintenance mode.