

Achieving zero RPO with StorageGRID - A Comprehensive Guide to Multi-Site Replication
 Suggest changes
Suggest changes
This technical report provides a comprehensive guide to implementing StorageGRID replication strategies to achieve a Recovery Point Objective (RPO) of zero in the event of a site failure. The document details various deployment options for StorageGRID, including multi-site synchronous replication and multi-grid asynchronous replication. It explains how StorageGRID Information Lifecycle Management (ILM) policies can be configured to ensure data durability and availability across multiple locations.
Additionally, the report covers performance considerations, failure scenarios, and recovery processes to maintain uninterrupted client operations. The goal of this document is to provide information to ensure that data remains accessible and consistent, even in the event of a complete site failure, by leveraging both synchronous and asynchronous replication techniques.
StorageGRID Overview
NetApp StorageGRID is an object-based storage system that supports the industry-standard Amazon Simple Storage Service (Amazon S3) API.
StorageGRID provides a single namespace across multiple locations with variable levels of service driven by information lifecycle management policies (ILM). With these lifecycle policies you can optimize where your data lives throughout its lifecycle.
StorageGRID allows for configurable durability and availability of your data in local and geo-distributed solutions. Whether your data is on premises or in a public cloud, integrated hybrid cloud workflows allow your business to leverage cloud services like Amazon Simple Notification Service (Amazon SNS), Google Cloud, Microsoft Azure Blob, Amazon S3 Glacier, Elasticsearch, and more.
StorageGRID scale
A minimal StorageGRID deployment consists of an Admin node and 3 Storage nodes in a single site. A single grid can grow up to 220 nodes.
StorageGRID can be deployed as a single site or extended to 16 sites.
The Admin node contains the management interface, a central point for metrics and logging, and maintains the configuration of the StorageGRID components. The Admin node also contains an integrated load balancer for S3 API access.
StorageGRID can be deployed as software-only, as VMware virtual machine appliances, or as purpose-built appliances.
A Storage node can be deployed as:
-
A metadata only node maximizing object count
-
An object storage only node maximizing object space
-
A combined metadata and object storage node adding both object count and object space
Each Storage node can scale to multi-petabyte capacity for object storage allowing for a single namespace in the hundreds of petabytes. StorageGRID also provides an integrated load balancer for S3 API operations called a gateway node.
StorageGRID consists of a collection of nodes placed into a site topology. A site in StorageGRID can be a unique physical location or reside in a shared physical location as other sites in the grid as a logical construct. A StorageGRID site should not span multiple physical locations. A site represents a shared local area network (LAN) infrastructure and failure domain.
StorageGRID and failure domains
StorageGRID contains multiple layers of failure domains to be considered in deciding how to architect your solution, how to store your data and where your data should be stored to mitigate the risks of failures.
-
Grid level - A grid consisting of multiple sites can have site failures or isolation and the accessible site(s) can continue operating as the grid.
-
Site level - Failures within a site may impact operations of that site but will not impact the rest of the grid.
-
Node level - A node failure will not impact the operation of the site.
-
Disk level - a disk failure will not impact operation of the node.
Object data and metadata
With object storage, the unit of storage is an object, rather than a file or a block. Unlike the tree-like hierarchy of a file system or block storage, object storage organizes data in a flat, unstructured layout. Object storage decouples the physical location of the data from the method used to store and retrieve that data.
Each object in an object-based storage system has two parts: object data and object metadata.
-
Object data represents the actual underlying data, for example, a photograph, a movie, or a medical record.
-
Object metadata is any information that describes an object.
StorageGRID uses object metadata to track the locations of all objects across the grid and to manage each object's lifecycle over time.
Object metadata includes information such as the following:
-
System metadata, including a unique ID for each object, the object name, the name of the S3 bucket, the tenant account name or ID, the logical size of the object, the date and time the object was first created, and the date and time the object was last modified.
-
The current storage location of each object's replicate copy or erasure-coded fragment.
-
Any custom user metadata key-value pairs associated with the object.
-
For S3 objects, any object tag key-value pairs associated with the object
-
For segmented objects and multipart objects, segment identifiers, and data sizes.
Object metadata is customizable and expandable, making it flexible for applications to use. For detailed information about how and where StorageGRID stores object metadata, go to Manage object metadata storage.
StorageGRID's Information lifecycle management (ILM) system is used to orchestrate the placement, duration, and ingest behavior for all object data in your StorageGRID system. ILM rules determine how StorageGRID stores objects over time using replicas of the objects or erasure coding the object across nodes and sites. This ILM system is responsible for the object data consistency within a grid.
Erasure coding
StorageGRID provides the ability to erasure code data at node level and the drive level. With StorageGRID appliances we erasure code the data stored on each node across all the drives within the node providing local protection against multiple disk failures causing data loss or interruptions. Rebuilds from drive failures are local to the node and do not require data replicated over the network.
Additionally, StorageGRID appliances use erasure coding schemes to store object data across the nodes within a site or spread across 3 or more sites in the StorageGRID system though StorageGRID's ILM rules protecting against node failure.
Erasure coding provides a storage layout that is resilient to node and site failures with a lower overhead than replication. All StorageGRID erasure coding schemes are deployable in a single site provided the minimum number of nodes required to store the data chunks are met. This means for an EC scheme of 4+2 there needs to be a minimum of 6 nodes available to receive the data.
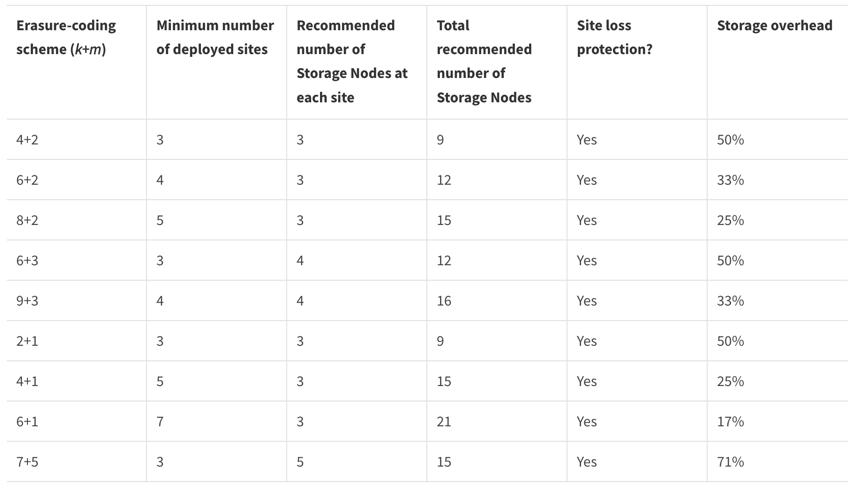
Metadata consistency
In StorageGRID, metadata is typically stored with three replicas per site to ensure consistency and availability. This redundancy helps maintain data integrity and accessibility even in the event of a failure.
The default consistency is defined at a grid wide level. Users can change the consistency at the bucket level at any time.
The bucket consistency options available in StorageGRID are:
-
All: Provides the highest level of consistency. All nodes in the grid receive the data immediately, or the request will fail.
-
Strong-global:
-
Legacy Strong Global: Guarantees read-after-write consistency for all client requests across all sites.
-
This is the default behavior for all systems upgraded from 11.9 or older to 12.0 without manually changing to the new Quorum Strong Global.
-
-
Quorum Strong-global: Guarantees read-after-write consistency for all client requests across all sites. Offers consistency for multiple nodes or even a site failure if metadata replica quorum is achievable.
-
This is the default behavior for all systems newly installed at 12.0 or higher.
-
QUORUM consistency is defined as a quorum of Storage Node metadata replicas, where each site has 3 metadata replicas. It may be calculated as follows: 1+((N*3)/2) where N is the total number of sites
-
For example, a minimum of 5 replicas must be made from a 3-site grid with a maximum of 3 replicas within a site.
-
-
-
Strong-site: Guarantees read-after-write consistency for all client requests within a site.
-
Read-after-new-write(default): Provides read-after-write consistency for new objects and eventual consistency for object updates. Offers high availability and data protection guarantees. Recommended for most cases.
-
Available: Provides eventual consistency for both new objects and object updates. For S3 buckets, use only as required (for example, for a bucket that contains log values that are rarely read, or for HEAD or GET operations on keys that don't exist). Not supported for S3 FabricPool buckets.
Object data consistency
While metadata is automatically replicated within and across sites, object data storage placement decisions are up to you. Object data can be stored in replicas within and across sites, erasure coded within or across sites, or a combination or replicas and erasure coded storage schemes. ILM rules can apply to all objects, or be filtered to only apply to certain objects, buckets, or tenants. ILM rules define how objects are stored, replicas and/or erasure coded, how long objects are stored in those locations, if the number of replicas or erasure coding scheme should change, or locations should change over time.
Each ILM rule will be configured with one of three ingest behaviors for protecting objects: Dual commit, balanced or strict.
The dual commit option will make two copies on any two different storage nodes in the grid immediately and return the request to be successful to the client. The node selection will be tried within the site of the request but may use nodes of another site in some circumstances. The object is added to the ILM queue to be evaluated and placed according to the ILM rules.
The balanced option evaluates the object against the ILM policy immediately and places the object synchronously before returning the request to be successful to the client. If the ILM rule cannot be met immediately due to an outage or inadequate storage to meet the placement requirements, then dual commit will be used instead. Once the issue is resolved, ILM will automatically place the object based on the defined rule.
The strict option evaluates the object against the ILM policy immediately and places the object synchronously before returning the request to be successful to the client. If the ILM rule cannot be met immediately due to an outage or inadequate storage to meet the placement requirements, then the request will fail, and the client will need to retry.
Load balancing
StorageGRID can be deployed with client access through the integrated gateway nodes, an external 3rd party load balancer, DNS round robin, or directly to a storage node. Multiple gateway nodes can be deployed in a site and configured in high availability groups providing automated failover and fail back in the event of a gateway node outage. You can combine load balancing methods in a solution to provide a single point of access for all sites in a solution.
The gateway nodes will balance the load between the storage nodes in the site where the gateway node resides by default. StorageGRID can be configured to allow the gateway nodes to balance load using nodes from multiple sites. This configuration would add the latency between those sites to the response latency to the client's requests. This should only be configured if the total latency is acceptable to the clients.
Ensuring an RTO of zero can be achieved with a combination of local and global load balancing. Ensuring uninterrupted client access requires load balancing of client requests. A StorageGRID solution can contain many gateway nodes and high availability groups in each site. To provide uninterrupted access for clients in any site even in a site failure, you should configure an external load balancing solution in combination with StorageGRID Gateway nodes. Configure Gateway node high availability groups that manage the load within each site and use the external load balancer to balance the load across the high availability groups. The external load balancer must be configured to perform a health check to ensure requests are sent only to operational sites. For more information on load balancing with StorageGRID please see the StorageGRID load balancer technical report.
Requirements for Zero RPO with StorageGRID
To achieve zero Recovery Point Objective (RPO) in an object storage system, it is crucial that at the time of failure:
-
Both metadata and object contents are in sync and considered consistent
-
Object content remain accessible despite the failure.
For a multi-site deployment, Quorum Strong Global is the preferred consistency model to ensure metadata is synchronized across all sites, making it essential for meeting the zero RPO requirement.
Objects in the storage system are stored based on Information Lifecycle Management (ILM) rules, which dictate how and where data is stored throughout its lifecycle. For synchronous replication, one can consider between Strict execution or Balanced Execution.
-
Strict execution of these ILM rules is necessary for zero RPO because it ensures that objects are placed in the defined locations without any delay or fallback, maintaining data availability and consistency.
-
StorageGRID's ILM balance ingest behavior provides a balance between high availability and resiliency, allowing users to continue ingesting data even in the event of a site failure.
Synchronous Deployments across multiple sites
Multi-site solutions: StorageGRID allows you to replicate objects across multiple sites within the grid synchronously. By setting up Information Lifecycle Management (ILM) rules with balance or strict behavior, objects are placed immediately in the specified locations. Configuring bucket consistency level to Quorum Strong Global will ensure synchronous metadata replication as well. StorageGRID uses a single global namespace, storing object placement locations as metadata, so every node knows where all copies or erasure coded pieces are located. If an object can't be retrieved from the site where the request was made, it will be automatically retrieved from a remote site without needing failover procedures.
Once the failure is resolved, no manual failback efforts are required. The replication performance depends on the site with the lowest network throughput, highest latency, and lowest performance. A site's performance is based on the number of nodes, CPU core count and speed, memory, drive quantity, and drive types.
Multi-grid solutions: StorageGRID can replicate tenants, users, and buckets between multiple StorageGRID systems using Cross-Grid replication (CGR). CGR can extend select data to more than 16 sites, increase the usable capacity of your object store, and provide disaster recovery. The replication of buckets with CGR includes objects, object versions, and metadata, and can be bi-directional or one-way. The recovery point objective (RPO) depends on the performance of each StorageGRID system and the network connections between them.
Summary:
-
Intra-grid replication includes both synchronous and asynchronous replication, configurable using ILM ingest behavior and metadata consistency control.
-
Inter-grid replication is asynchronous only.
A Single Grid Multi-site deployment
In the following scenarios the StorageGRID solutions are configured with an optional external load balancer managing requests to the integrated load balancer high availability groups. This will achieve an RTO of zero in addition to an RPO of zero. ILM is configured with Balanced ingest protection for synchronous placement. Each bucket is configured with the Quorum version of Strong Global consistency model for grids of 3 or more sites and the Legacy version of Strong Global consistency for 2 sites.
Scenario 1:
In a two site StorageGRID solution, there are at least two replicas of every object and 6 replicas of all metadata. Upon failure recovery, updates from the outage will synchronize to the recovered site/nodes automatically. With only 2 sites it is not likely to achieve a zero RPO in failure scenarios beyond a full site loss.
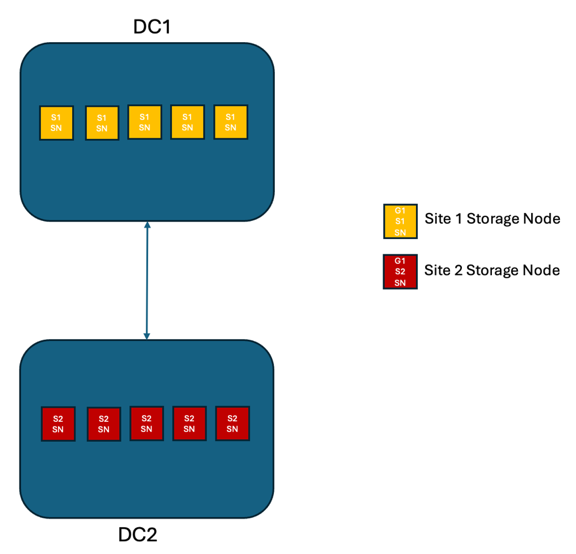
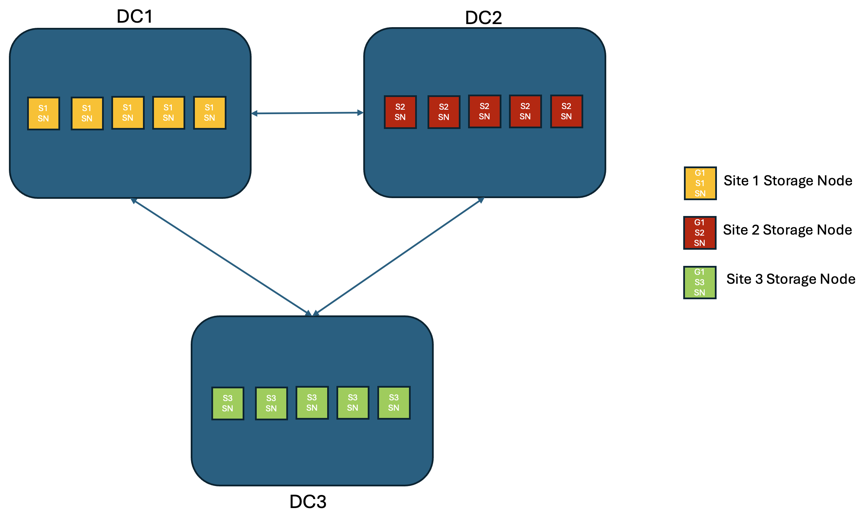
Scenario 2:
In a StorageGRID solution of three or more sites, there are at least 3 replicas or 3 EC chunks of every object and 9 replicas of all metadata. Upon failure recovery, updates from the outage will synchronize to the recovered site/nodes automatically. With three or more sites it is possible to achieve a zero RPO.
Multi-site failure scenarios
| Failure | 2-site Outcome Legacy Strong Global |
3 or more sites outcome Quorum Strong Global |
|---|---|---|
Single node drive failure |
Each appliance uses multiple disk groups and can sustain at least 1 drive per group failing without interruption or data loss. |
Each appliance uses multiple disk groups and can sustain at least 1 drive per group failing without interruption or data loss. |
Single node failure in one site |
No interruption to operations or data loss. |
No interruption to operations or data loss. |
Multiple node failure in one site |
Disruption to client operations directed to this site but no data loss. Operations directed to the other site remain uninterrupted and no data loss. |
Operations are directed to all other sites and remain uninterrupted and no data loss. |
Single node failure at multiple sites |
No disruption or data loss if:
Operations disrupted and risk of data loss if:
|
No disruption or data loss if:
Operations disrupted and risk of data loss if:
|
Single site failure |
Some client operations will be interrupted until the failure is resolved. |
No interruption to operations or data loss. |
Single site plus single node failures |
Some client operations will be interrupted until either the failure is resolved. |
No interruption to operations or data loss. |
Single site plus a node from each remaining site |
Only two sites exist. |
Operations will be disrupted If metadata replica quorum cannot be met. |
Multi-site failure |
No operational sites remain. |
Operations will be disrupted If metadata replica quorum cannot be met. |
Network isolation of a site |
client operations will be interrupted until either the failure is resolved. |
Operations will be disrupted for the isolated site, but no data loss. |
A multi-site multi-grid deployment
To add an extra layer of redundancy, this scenario will employ two StorageGRID Clusters and use cross-grid replication to keep them in sync. For this solution each StorageGRID clusters will have three sites. Two sites will be used for object storage and metadata while the third site will be used solely for metadata. Both systems will be configured with a balanced ILM rule to synchronously store the objects using erasure coding in each of the two data sites. Buckets will be configured with the Quorum Strong Global consistency model. Each grid will be configured with bi-directional cross-grid replication on every bucket. This provides the asynchronous replication between the regions. Optionally a global load balancer can be implemented to manage requests to the integrated load balancer high availability groups of both StorageGRID systems to achieve a zero RPO.
The solution will use four locations equally divided into two regions. Region 1 will contain the 2 storage sites of grid 1 as the primary grid of the region and the metadata site of grid 2. Region 2 will contain the 2 storage sites of grid 2 as the primary grid of the region and the metadata site of grid 1. In each region the same location can house the storage site of the primary grid of the region as well as the metadata only site of the other regions grid. Using metadata only nodes as the third site will provide the consistency required for the metadata and not duplicate the storage of objects in that location.
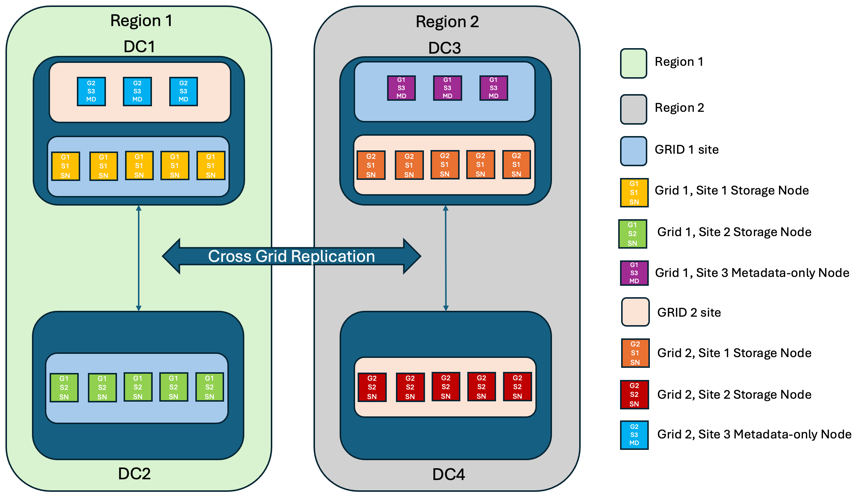
This solution with four separate locations provides complete redundancy of two separate StorageGRID systems maintaining an RPO of 0 and will make use of both multi-site synchronous replication, and multi-grid asynchronous replication. Any single site can fail while maintaining uninterrupted client operations on both StorageGRID systems.
In this solution, there are four erasure coded copies of every object and 18 replicas of all metadata. This allows for multiple failure scenarios without client operations impact. Upon failure recovery updates from the outage will synchronize to the failed site/nodes automatically.
Multisite, multi-grid failure scenarios
| Failure | Outcome |
|---|---|
Single node drive failure |
Each appliance uses multiple disk groups and can sustain at least 1 drive per group failing without interruption or data loss. |
Single node failure in one site in a grid |
No interruption to operations or data loss. |
Single node failure in one site in each grid |
No interruption to operations or data loss. |
Multiple node failure in one site in a grid |
No interruption to operations or data loss. |
Multiple node failure in one site in each grid |
No interruption to operations or data loss. |
Single node failure at multiple sites in a grid |
No interruption to operations or data loss. |
Single node failure at multiple sites in each grid |
No interruption to operations or data loss. |
Single site failure in a grid |
No interruption to operations or data loss. |
Single site failure in each grid |
No interruption to operations or data loss. |
Single site plus single node failures in a grid |
No interruption to operations or data loss. |
Single site plus a node from each remaining site in a single grid |
No interruption to operations or data loss. |
Single location failure |
No interruption to operations or data loss. |
Single location failure in each grid DC1 & DC3 |
Operations will be disrupted until either the failure is resolved, or the bucket consistency is lowered; each grid has lost 2 sites All data still exists at 2 locations |
Single location failure in each grid DC1 & DC4 or DC2 & DC3 |
No interruption to operations or data loss. |
Single location failure in each grid DC2 & DC4 |
No interruption to operations or data loss. |
Network isolation of a site |
Operations will be disrupted for the isolated site but no data will be lost No disruption to operations in the remaining sites or data loss. |
Conclusion
Achieving zero Recovery Point Objective (RPO) with StorageGRID is a critical goal for ensuring data durability and availability in the event of site failures. By leveraging StorageGRID's robust replication strategies, including multi-site synchronous replication and multi-grid asynchronous replication, organizations can maintain uninterrupted client operations and ensure data consistency across multiple locations. The implementation of Information Lifecycle Management (ILM) policies and the use of metadata-only nodes further enhance the system's resilience and performance. With StorageGRID, businesses can confidently manage their data, knowing that it remains accessible and consistent even in the face of complex failure scenarios. This comprehensive approach to data management and replication underscores the importance of meticulous planning and execution in achieving zero RPO and safeguarding valuable information.