简体中文版经机器翻译而成,仅供参考。如与英语版出现任何冲突,应以英语版为准。
用例 3:在现有 Hadoop 数据上启用 DevTest
贡献者

 建议更改
建议更改
在这种用例中,客户的要求是基于现有的 Hadoop 集群快速高效地构建新的 Hadoop/Spark 集群,该集群包含大量用于同一数据中心和远程位置的开发测试和报告目的的分析数据。
场景
在这种情况下,从本地以及灾难恢复位置的大型 Hadoop 数据湖实现构建多个 Spark/Hadoop 集群。
要求和挑战
此用例的主要要求和挑战包括:
-
为 DevTest、QA 或任何其他需要访问相同生产数据的目的创建多个 Hadoop 集群。这里的挑战是以非常节省空间的方式瞬间多次克隆一个非常大的 Hadoop 集群。
-
将 Hadoop 数据同步到 DevTest 和报告团队以提高运营效率。
-
在生产和新集群中使用相同的凭据分发 Hadoop 数据。
-
使用调度策略高效地创建QA集群,而不影响生产集群。
解决方案
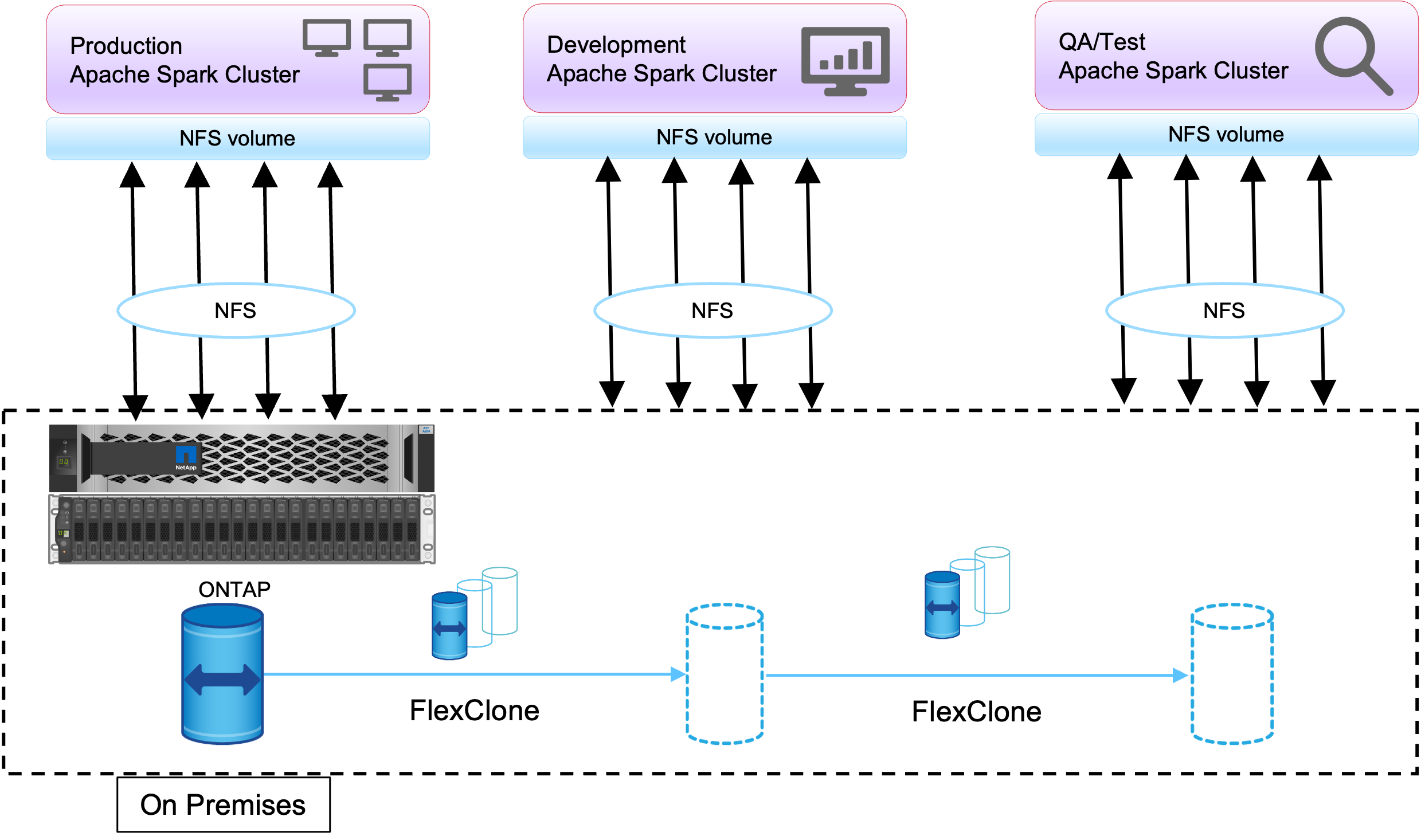
FlexClone技术用于满足刚才描述的要求。 FlexClone技术是 Snapshot 副本的读/写副本。它从父 Snapshot 副本数据中读取数据,并且仅为新/修改的块消耗额外的空间。它速度快并且节省空间。
首先,使用NetApp一致性组创建现有集群的 Snapshot 副本。
NetApp系统管理器或存储管理提示中的快照副本。一致性组Snapshot副本是应用程序一致性组Snapshot副本, FlexClone卷是基于一致性组Snapshot副本创建的。值得一提的是, FlexClone卷继承了父卷的 NFS 导出策略。创建 Snapshot 副本后,必须安装一个新的 Hadoop 集群以用于 DevTest 和报告目的,如下图所示。来自新 Hadoop 集群的克隆 NFS 卷访问 NFS 数据。
此图显示了 DevTest 的 Hadoop 集群。