主要的 AI、ML 和 DL 用例和架构
 建议更改
建议更改
主要的 AI、ML 和 DL 用例和方法可分为以下几部分:
Spark NLP 管道和 TensorFlow 分布式推理
以下列表包含数据科学界在不同发展水平下采用的最流行的开源 NLP 库:
-
"自然语言工具包(NLTK)" 。所有 NLP 技术的完整工具包。它自 21 世纪初以来一直得到维护。
-
"文本块" 。基于 NLTK 和 Pattern 构建的易于使用的 NLP 工具 Python API。
-
"斯坦福核心 NLP" 。斯坦福 NLP 小组开发的 Java NLP 服务和包。
-
"Gensim" 。人类主题建模最初是捷克数字数学图书馆项目的 Python 脚本集合。
-
"SpaCy" 。使用 Python 和 Cython 实现端到端工业 NLP 工作流程,并为 Transformer 提供 GPU 加速。
-
"快文" 。Facebook 的 AI 研究 (FAIR) 实验室创建的免费、轻量级、开源 NLP 库,用于学习词嵌入和句子分类。
Spark NLP 是针对所有 NLP 任务和要求的单一、统一的解决方案,可为实际生产用例提供可扩展、高性能和高精度的 NLP 软件。它利用迁移学习并在研究和跨行业中实施最新的最先进的算法和模型。由于 Spark 缺乏对上述库的全面支持,Spark NLP 建立在 "Spark 机器学习"利用 Spark 的通用内存分布式数据处理引擎作为关键任务生产工作流的企业级 NLP 库。它的注释器利用基于规则的算法、机器学习和 TensorFlow 来支持深度学习的实现。这涵盖了常见的 NLP 任务,包括但不限于标记化、词形还原、词干提取、词性标注、命名实体识别、拼写检查和情感分析。
来自 Transformer 的双向编码器表示 (BERT) 是一种基于 Transformer 的 NLP 机器学习技术。它推广了预训练和微调的概念。 BERT 中的 Transformer 架构源自机器翻译,它比基于循环神经网络 (RNN) 的语言模型更好地模拟长期依赖关系。它还引入了掩蔽语言建模 (MLM) 任务,其中随机 15% 的所有标记被掩蔽,并且模型对其进行预测,从而实现真正的双向性。
由于该领域的专业语言和缺乏标记数据,金融情绪分析具有挑战性。 FinBERT 是一种基于预训练 BERT 的语言模型,已在以下领域进行了调整: "路透社 TRC2" ,一个金融语料库,并使用标记数据进行微调( "金融短语库" ) 用于金融情绪分类。研究人员从包含金融术语的新闻文章中提取了 4,500 个句子。然后,16位具有金融背景的专家和硕士生将这些句子标记为肯定、中性和否定。我们构建了一个端到端的 Spark 工作流程,使用 FinBERT 和其他两个预先训练的流程来分析 2016 年至 2020 年纳斯达克十大公司收益电话会议记录的情绪, "解释文档 DL" )来自 Spark NLP。
Spark NLP 的底层深度学习引擎是 TensorFlow,这是一个端到端的开源机器学习平台,可以轻松构建模型、在任何地方进行强大的 ML 生产以及进行强大的研究实验。因此,在 Spark 中执行管道时 `yarn cluster`模式,我们本质上是在运行分布式 TensorFlow,数据和模型在一个主节点和多个工作节点上并行化,并在集群上安装网络附加存储。
Horovod分布式训练
与 MapReduce 相关的性能的核心 Hadoop 验证是使用 TeraGen、TeraSort、TeraValidate 和 DFSIO(读写)执行的。 TeraGen 和 TeraSort 验证结果如下 "NetApp E系列Hadoop解决方案"以及AFF的“存储分层”部分。
根据客户要求,我们认为使用 Spark 进行分布式训练是各种用例中最重要的用例之一。在本文档中,我们使用了 "Spark 上的 Hovorod"使用NetApp All Flash FAS (AFF) 存储控制器、 Azure NetApp Files和StorageGRID来验证 Spark 与NetApp本地、云原生和混合云解决方案的性能。
Horovod on Spark 包为 Horovod 提供了一个便捷的包装器,使得在 Spark 集群中运行分布式训练工作负载变得简单,从而实现了紧密的模型设计循环,其中数据处理、模型训练和模型评估都在训练和推理数据所在的 Spark 中完成。
有两个用于在 Spark 上运行 Horovod 的 API:高级 Estimator API 和低级 Run API。尽管两者都使用相同的底层机制在 Spark 执行器上启动 Horovod,但 Estimator API 抽象了数据处理、模型训练循环、模型检查点、指标收集和分布式训练。我们使用 Horovod Spark Estimators、TensorFlow 和 Keras 进行端到端数据准备和分布式训练工作流程,基于 "Kaggle Rossmann 商店销售"竞赛。
脚本 `keras_spark_horovod_rossmann_estimator.py`可以在以下部分找到"每个主要用例的 Python 脚本。"它包含三个部分:
-
第一部分对 Kaggle 提供并由社区收集的一组初始 CSV 文件执行各种数据预处理步骤。输入数据被分成一个训练集, `Validation`子集和测试数据集。
-
第二部分定义了一个具有对数 S 型激活函数和 Adam 优化器的 Keras 深度神经网络 (DNN) 模型,并使用 Spark 上的 Horovod 对模型进行分布式训练。
-
第三部分使用最小化验证集总体平均绝对误差的最佳模型对测试数据集进行预测。然后创建一个输出 CSV 文件。
请参阅"机器学习"用于各种运行时比较结果。
使用 Keras 进行多任务深度学习以进行 CTR 预测
随着机器学习平台和应用的最新进展,人们将大量注意力放在了大规模学习上。点击率(CTR)定义为每百次在线广告展示的平均点击次数(以百分比表示)。它被广泛采用为各个行业垂直领域和用例的关键指标,包括数字营销、零售、电子商务和服务提供商。有关 CTR 和分布式训练性能结果的应用的更多详细信息,请参阅"CTR预测性能的深度学习模型"部分。
在本技术报告中,我们使用了 "Criteo Terabyte 点击日志数据集"(参见 TR-4904)用于多工作者分布式深度学习,使用 Keras 构建具有深度和交叉网络 (DCN) 模型的 Spark 工作流,并将其对数损失误差函数方面的性能与基线 Spark ML 逻辑回归模型进行比较。 DCN 有效地捕获有界度的有效特征交互,学习高度非线性交互,不需要手动特征工程或穷举搜索,并且计算成本低。
网络规模推荐系统的数据大多是离散的和分类的,导致特征空间庞大且稀疏,这对于特征探索来说是一个挑战。这使得大多数大型系统仅限于逻辑回归等线性模型。然而,识别经常预测的特征并同时探索看不见的或罕见的交叉特征是做出良好预测的关键。线性模型简单、可解释、易于扩展,但其表达能力有限。
另一方面,交叉特征已被证明对提高模型的表现力具有重要意义。不幸的是,通常需要手动特征工程或详尽搜索来识别这些特征。推广到看不见的特征交互通常很困难。使用像 DCN 这样的交叉神经网络可以通过以自动方式明确应用特征交叉来避免特定于任务的特征工程。交叉网络由多层组成,其中最高程度的交互可由层深度决定。每一层都会在现有交互的基础上产生更高阶的交互,并保留前几层的交互。
深度神经网络 (DNN) 有望捕捉跨特征的非常复杂的交互。然而,与 DCN 相比,它需要的参数几乎多一个数量级,无法明确地形成交叉特征,并且可能无法有效地学习某些类型的特征交叉。交叉网络内存效率高并且易于实现。联合训练交叉和 DNN 组件可以有效地捕获预测特征交互并在 Criteo CTR 数据集上提供最先进的性能。
DCN 模型从嵌入和堆叠层开始,然后并行连接交叉网络和深度网络。接下来是最终的组合层,它将两个网络的输出组合在一起。您的输入数据可以是具有稀疏和密集特征的向量。在 Spark 中,库包含类型 SparseVector。因此,用户区分两者并在调用各自的函数和方法时要小心,这一点很重要。在 CTR 预测等网络规模推荐系统中,输入大多是分类特征,例如 'country=usa'。这些特征通常被编码为独热向量,例如, '[0,1,0, …]' 。独热编码(OHE) `SparseVector`在处理词汇不断变化和增长的真实世界数据集时很有用。我们修改了示例 "深度点击率"处理大型词汇表,在 DCN 的嵌入和堆叠层中创建嵌入向量。
这 "Criteo 展示广告数据集"预测广告点击率。它有 13 个整数特征和 26 个分类特征,其中每个类别都有很高的基数。对于该数据集,由于输入规模较大,对数损失 0.001 的改进实际上具有显著意义。对于庞大的用户群,预测准确度的微小提升都可能带来公司收入的大幅增加。该数据集包含 7 天内 11GB 的用户日志,相当于约 4100 万条记录。我们使用了 Spark `dataFrame.randomSplit()function`随机分割数据用于训练(80%)、交叉验证(10%),剩余 10% 用于测试。
DCN 是使用 Keras 在 TensorFlow 上实现的。使用DCN实现模型训练过程主要有四个部分:
-
*数据处理和嵌入。*通过应用对数变换对实值特征进行规范化。对于分类特征,我们将特征嵌入到维度为 6×(类别基数)1/4 的密集向量中。连接所有嵌入将产生一个维度为 1026 的向量。
-
*优化。*我们利用 Adam 优化器进行了小批量随机优化。批次大小设置为 512。对深度网络进行批量归一化,梯度裁剪范数设为100。
-
*正则化。*我们采用了提前停止的方法,因为 L2 正则化或 dropout 被发现无效。
-
超参数。我们报告基于对隐藏层数量、隐藏层大小、初始学习率和交叉层数量的网格搜索的结果。隐藏层的数量范围为 2 至 5,隐藏层大小范围为 32 至 1024。对于DCN,交叉层的数量为1至6。初始学习率从 0.0001 调整到 0.001,增量为 0.0001。所有实验均在训练步骤 150,000 时提前停止,超过该步骤后就会开始出现过度拟合。
用于验证的架构
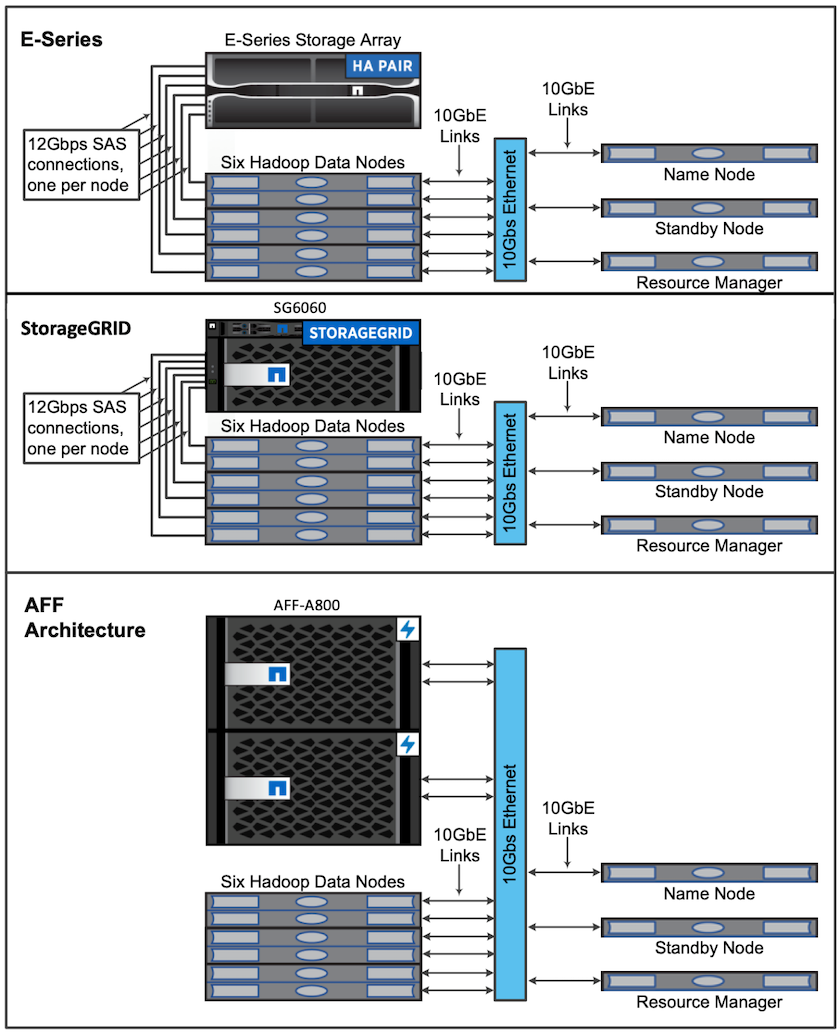
为了进行此验证,我们使用了四个工作节点和一个主节点以及一个AFF-A800 HA 对。所有集群成员都通过 10GbE 网络交换机连接。
为了验证NetApp Spark 解决方案,我们使用了三种不同的存储控制器:E5760、E5724 和AFF-A800。 E系列存储控制器通过12Gbps SAS连接连接到五个数据节点。 AFF HA 对存储控制器通过 10GbE 连接向 Hadoop 工作节点提供导出的 NFS 卷。 Hadoop 集群成员通过 E 系列、 AFF和StorageGRID Hadoop 解决方案中的 10GbE 连接进行连接。