

NetApp AIPod Mini - 利用NetApp和 Intel 进行企业 RAG 推理
 建议更改
建议更改
本文介绍了NetApp AIPod for Enterprise RAG 的经过验证的参考设计,该设计采用了 Intel Xeon 6 处理器和NetApp数据管理解决方案的技术和组合功能。该解决方案演示了下游 ChatQnA 应用程序利用大型语言模型,为并发用户提供准确、上下文相关的响应。这些响应是通过隔离的 RAG 推理管道从组织的内部知识库中检索的。

Sathish Thyagarajan、Michael Oglesby、Arpita Mahajan,NetApp
内容提要
越来越多的组织正在利用检索增强生成 (RAG) 应用程序和大型语言模型 (LLM) 来解释用户提示并生成响应,以提高生产力和业务价值。这些提示和响应可以包括从组织的内部知识库、数据湖、代码库和文档库中检索到的文本、代码、图像甚至治疗性蛋白质结构。本文介绍了 NetApp AIPod Mini 解决方案的参考设计,该解决方案包括 NetApp AFF 存储和配备 Intel Xeon 6 处理器的服务器。它包括与 Intel Advanced Matrix Extensions (Intel AMX) 相结合的 NetApp ONTAP 数据管理软件,以及基于 Open Platform for Enterprise AI (OPEA) 构建的 Intel® AI for Enterprise RAG 软件。用于企业 RAG 的 NetApp AIPod Mini 使组织能够将公共 LLM 扩展为私有生成式 AI (GenAI) 推理解决方案。该解决方案在企业规模上展示了高效且具有成本效益的 RAG 推理,旨在提高可靠性,并为您提供更好的专有信息控制。
英特尔存储合作伙伴验证
搭载英特尔至强 6 处理器的服务器专为处理要求苛刻的 AI 推理工作负载而设计,并使用英特尔 AMX 实现最佳性能。为了实现最佳的存储性能和可扩展性,该解决方案已使用NetApp ONTAP成功验证,使企业能够满足 RAG 应用程序的需求。该验证是在配备 Intel Xeon 6 处理器的服务器上进行的。英特尔和NetApp建立了强大的合作伙伴关系,致力于提供优化、可扩展且符合客户业务需求的 AI 解决方案。
使用NetApp运行 RAG 系统的优势
RAG 应用程序涉及从公司的文档存储库中检索各种类型的知识,例如 PDF、文本、CSV 或 Excel。这些数据通常存储在 S3 对象存储或 NFS 本地等解决方案中,作为数据源。NetApp 一直是边缘、数据中心和云生态系统中数据管理、数据移动、数据治理和数据安全技术的领导者。NetApp ONTAP 数据管理提供企业级存储,以支持各种类型的人工智能工作负载,包括批处理和实时推理,并提供以下一些好处:
-
速度和可扩展性。您可以高速处理大型数据集以进行版本控制,并能够独立扩展性能和容量。
-
数据访问。多协议支持允许客户端应用程序使用 S3、NFS 和 SMB 文件共享协议读取数据。 ONTAP S3 NAS 存储桶可以促进多模式 LLM 推理场景中的数据访问。
-
可靠性和保密性。 ONTAP提供数据保护、内置NetApp自主勒索软件保护 (ARP) 和动态存储配置,并提供基于软件和硬件的加密以增强机密性和安全性。 ONTAP 的所有 SSL 连接均符合 FIPS 140-2 标准。
目标受众
本文档适用于希望利用为提供企业 RAG 和 GenAI 解决方案而构建的基础设施的 AI 决策者、数据工程师、业务领导者和部门主管。对 AI 推理、LLM、Kubernetes 以及网络及其组件的先前了解将有助于实施阶段。
技术要求
硬件
Intel® AI 技术
使用 Xeon 6 作为主机 CPU,加速系统可受益于高单线程性能;更高的内存带宽;更高的可靠性、可用性和可服务性 (RAS);以及更多的 I/O 通道。英特尔 AMX 加速了 INT8 和 BF16 的推理,并支持 FP16 训练模型,INT8 每核每周期最多可进行 2,048 次浮点运算,BF16/FP16 每核每周期最多可进行 1,024 次浮点运算。要使用 Xeon 6 处理器部署 RAG 解决方案,通常建议至少使用 250GB 的 RAM 和 500GB 的磁盘空间。然而,这在很大程度上取决于 LLM 模型的大小。欲了解更多信息,请参阅英特尔 "Xeon 6处理器"产品简介。
图 1 - 搭载 Intel Xeon 6 处理器的计算服务器
NetApp AFF 存储系统
入门级和中级NetApp AFF A 系列系统提供更强大的性能、密度和更高的效率。 NetApp AFF A20、 AFF A30 和AFF A50 系统提供真正的统一存储,支持块、文件和对象,基于单一操作系统,可以以最低的成本在混合云中无缝管理、保护和调动 RAG 应用程序的数据。
图 2 - NetApp AFF A 系列系统。
| 硬件 | 数量 | 评论 |
|---|---|---|
Intel Xeon 第 6 代(Granite Rapids) |
2 |
RAG 推理节点—配备双插槽 Intel Xeon 6900-series(96 核)或 Intel Xeon 6700-series(64 核)处理器和 250GB 至 3TB RAM,配备 DDR5(6400MHz)或 MRDIMM(8800MHz)。2U 服务器。 |
带有英特尔处理器的控制平面服务器 |
1 |
Kubernetes 控制平面/1U 服务器。 |
100Gb 以太网交换机的选择 |
1 |
数据中心交换机。 |
NetApp AFF A20(或AFF A30; AFF A50) |
1 |
最大存储容量:9.3PB。注意:网络:10/25/100 GbE 端口。 |
为了验证此参考设计,我们使用了 Supermicro 的 Intel Xeon 6 处理器服务器(222HA-TN-OTO-37)和 Arista 的 100GbE 交换机(7280R3A)。
图 3 - AIPod Mini 部署架构 
软件
企业AI开放平台
企业 AI 开放平台 (OPEA) 是由英特尔与生态系统合作伙伴共同主导的一项开源计划。它提供了一个可组合构建块的模块化平台,旨在加速尖端生成 AI 系统的开发,重点关注 RAG。 OPEA 包括一个综合框架,该框架具有 LLM、数据存储、提示引擎、RAG 架构蓝图以及基于性能、特性、可信度和企业准备度评估生成式 AI 系统的四步评估方法。
OPEA 的核心包括两个关键部分:
-
GenAIComps:由微服务组件组成的基于服务的工具包
-
GenAIExamples:可立即部署的解决方案,例如 ChatQnA,可展示实际用例
有关详细信息,请参阅 "OPEA项目文档"
Intel® AI for Enterprise RAG 由 OPEA 提供支持
OPEA for Intel® AI for Enterprise RAG 简化了将企业数据转化为可操作的见解的过程。它由 Intel Xeon 处理器提供支持,集成了来自行业合作伙伴的组件,为部署企业解决方案提供了简化的方法。它通过成熟的协调框架无缝扩展,为您的企业提供所需的灵活性和选择。
在 OPEA 的基础上,Intel® AI for Enterprise RAG 扩展了这一基础,具有增强可扩展性、安全性和用户体验的关键功能。这些功能包括与现代基于服务的架构无缝集成的服务网格功能、管道可靠性的生产就绪验证,以及用于 RAG 即服务的功能丰富的用户界面,可轻松管理和监控工作流程。此外,Intel 和合作伙伴支持提供对广泛的解决方案生态系统的访问,结合集成的身份和访问管理 (IAM) 与 UI 和应用程序,以实现安全和合规的操作。可编程的护栏可对管道行为进行精细控制,实现自定义的安全性和合规性设置。
NetApp ONTAP
NetApp ONTAP是 NetApp 关键数据存储解决方案的基础技术。 ONTAP包含各种数据管理和数据保护功能,例如针对网络攻击的自动勒索软件保护、内置数据传输功能和存储效率功能。这些优势适用于一系列架构,从本地到 NAS、SAN、对象和 LLM 部署的软件定义存储中的混合多云。您可以在ONTAP集群中使用ONTAP S3 对象存储服务器来部署 RAG 应用程序,从而利用通过授权用户和客户端应用程序提供的ONTAP的存储效率和安全性。有关详细信息,请参阅 "了解ONTAP S3 配置"
NetApp Trident
NetApp Trident软件是一款开源且完全受支持的存储编排器,适用于容器和 Kubernetes 发行版,包括 Red Hat OpenShift。 Trident可与整个NetApp存储产品组合配合使用,包括NetApp ONTAP ,并且还支持 NFS 和 iSCSI 连接。有关详细信息,请参阅 "Git 上的NetApp Trident"
| 软件 | 版本 | 评论 |
|---|---|---|
OPEA - Intel® AI for Enterprise RAG |
2.0 |
基于OPEA微服务的企业RAG平台 |
容器存储接口(CSI驱动程序) |
NetApp Trident 25.10 |
支持动态配置、 NetApp Snapshot 副本和卷。 |
Ubuntu |
22.04.5 |
双节点集群上的操作系统。 |
容器编排 |
Kubernetes 1.31.9 (由 Enterprise RAG 基础架构 playbook 安装) |
运行 RAG 框架的环境 |
ONTAP |
ONTAP 9.16.1P4 或更高版本 |
AFF A20 上的存储操作系统。 |
解决方案部署
软件堆栈
该解决方案部署在由基于 Intel Xeon 的应用节点组成的 Kubernetes 集群上。至少需要三个节点才能实现 Kubernetes 控制平面的基本高可用性。我们使用以下集群布局验证了该解决方案。
表 3 - Kubernetes 集群布局
| 节点 | 角色 | 数量 |
|---|---|---|
配备 Intel Xeon 6 处理器和 1TB RAM 的服务器 |
应用节点、控制平面节点 |
2 |
通用服务器 |
控制平面节点 |
1 |
下图描述了该解决方案的“软件堆栈视图”。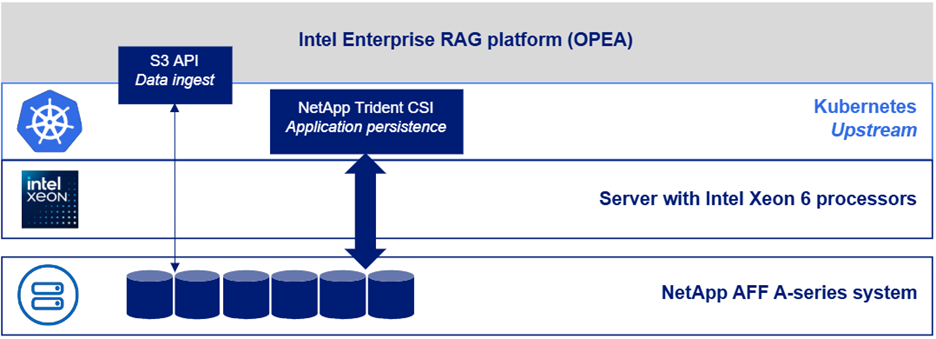
部署步骤
部署ONTAP存储设备
部署和配置您的NetApp ONTAP存储设备。请参阅 "ONTAP硬件系统文档"了解详情。
配置ONTAP SVM 以进行 NFS 和 S3 访问
在 Kubernetes 节点可访问的网络上配置ONTAP存储虚拟机 (SVM) 以进行 NFS 和 S3 访问。
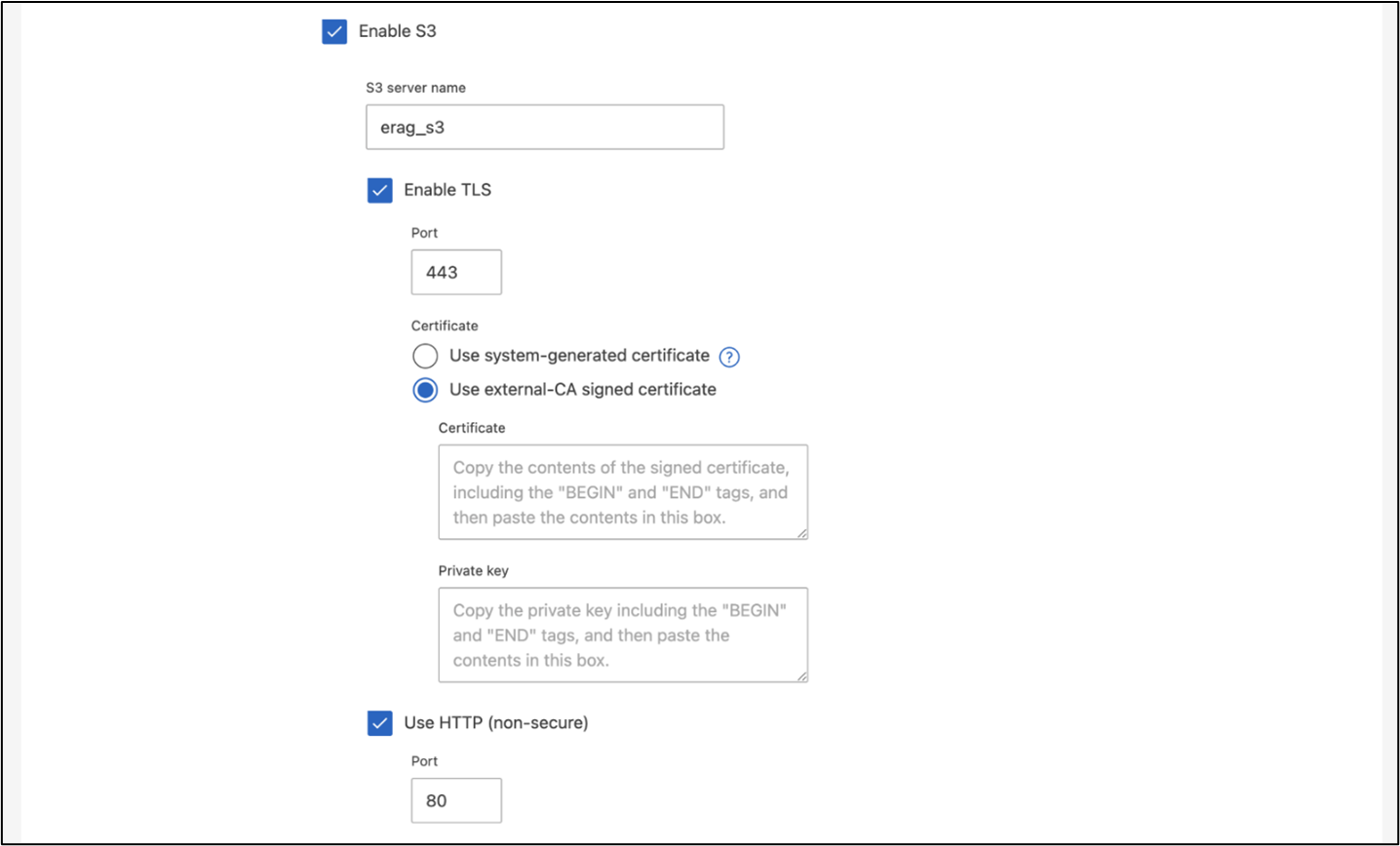
要使用ONTAP系统管理器创建 SVM,请导航到“存储”>“存储虚拟机”,然后单击“+ 添加”按钮。为您的 SVM 启用 S3 访问时,请选择使用外部 CA(证书颁发机构)签名的证书,而不是系统生成的证书。您可以使用自签名证书或由公众信任的 CA 签名的证书。有关更多详细信息,请参阅 "ONTAP文档。"
以下屏幕截图展示了使用ONTAP系统管理器创建 SVM 的过程。根据您的环境根据需要修改详细信息。
图 5 - 使用 ONTAP System Manager 创建 SVM。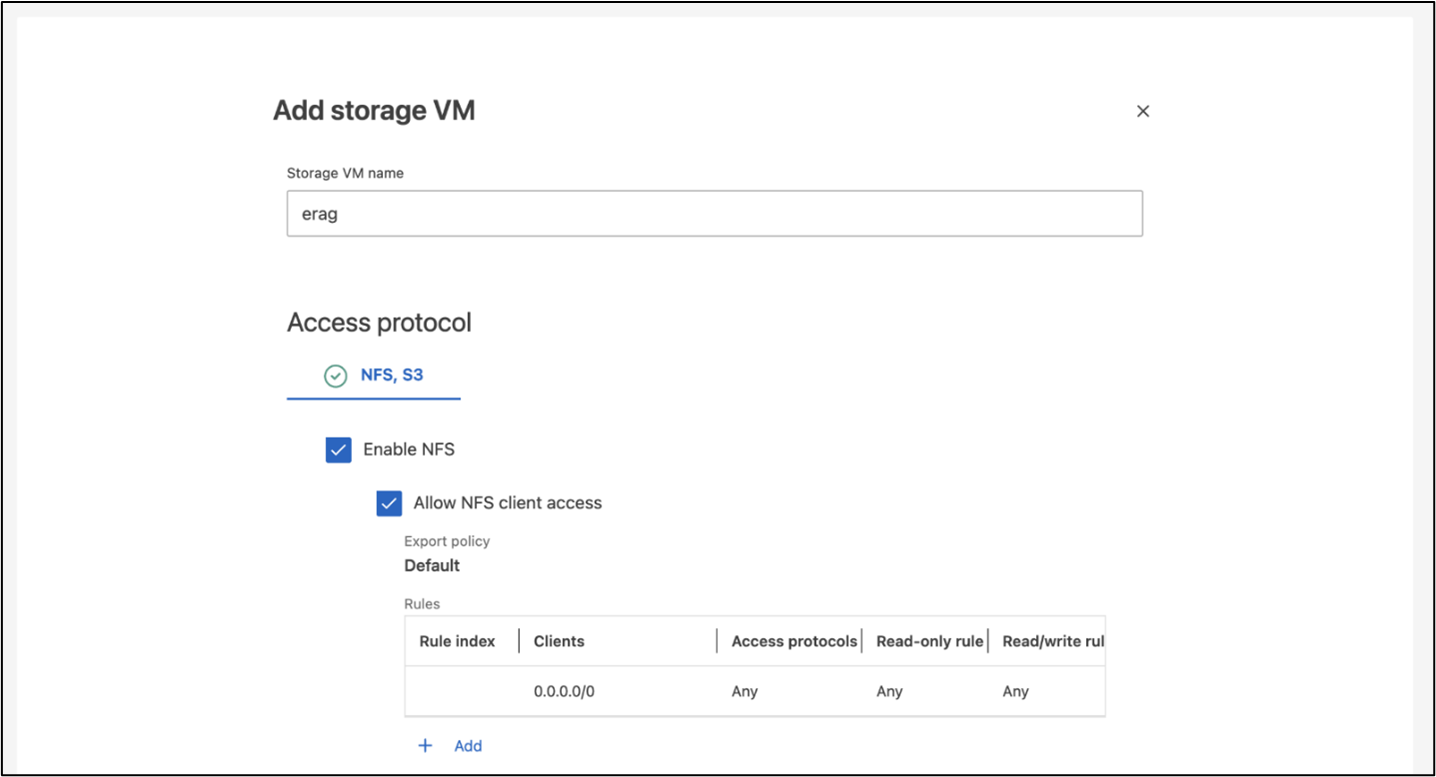
配置 S3 权限
为您在上一步中创建的 SVM 配置 S3 用户/组设置。确保您拥有对该 SVM 的所有 S3 API 操作具有完全访问权限的用户。有关详细信息,请参阅ONTAP S3 文档。
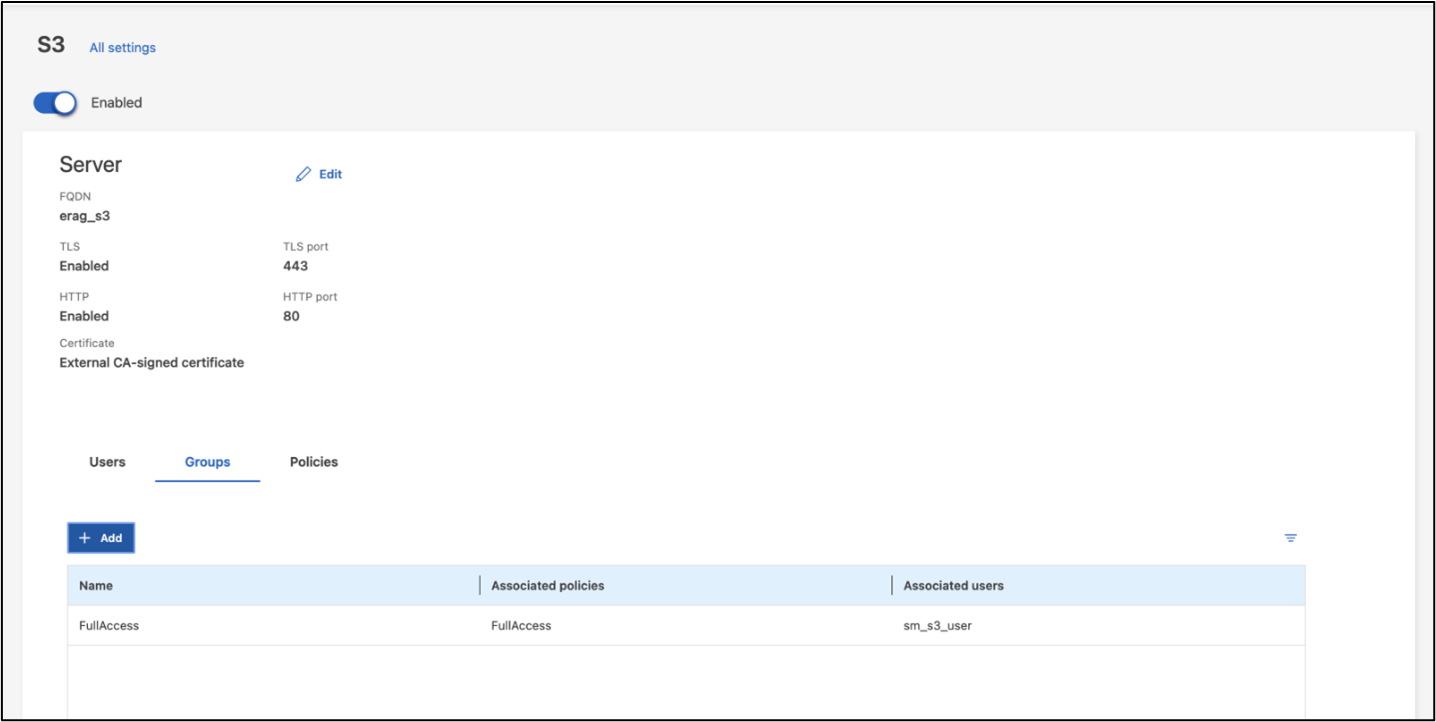
注意:Intel® AI for Enterprise RAG 应用程序的数据提取服务将需要此用户。如果您使用 ONTAP System Manager 创建了 SVM,System Manager 将在您创建 SVM 时自动创建一个名为 `sm_s3_user`的用户和一个名为 `FullAccess`的策略,但不会向 `sm_s3_user`分配任何权限。
要编辑此用户的权限,请导航至“存储”>“存储虚拟机”,单击您在上一步中创建的 SVM 的名称,单击“设置”,然后单击“S3”旁边的铅笔图标。给予 `sm_s3_user`拥有所有 S3 API 操作的完全访问权限,创建一个关联 `sm_s3_user`与 `FullAccess`策略如下面的屏幕截图所示。
图 6 - S3 权限。
创建 S3 存储桶
在您之前创建的 SVM 内创建一个 S3 存储桶。要使用ONTAP系统管理器创建 SVM,请导航到“存储”>“存储桶”,然后单击“+ 添加”按钮。有关更多详细信息,请参阅ONTAP S3 文档。
以下屏幕截图展示了使用ONTAP系统管理器创建 S3 存储桶的过程。
图 7 - 创建 S3 存储桶。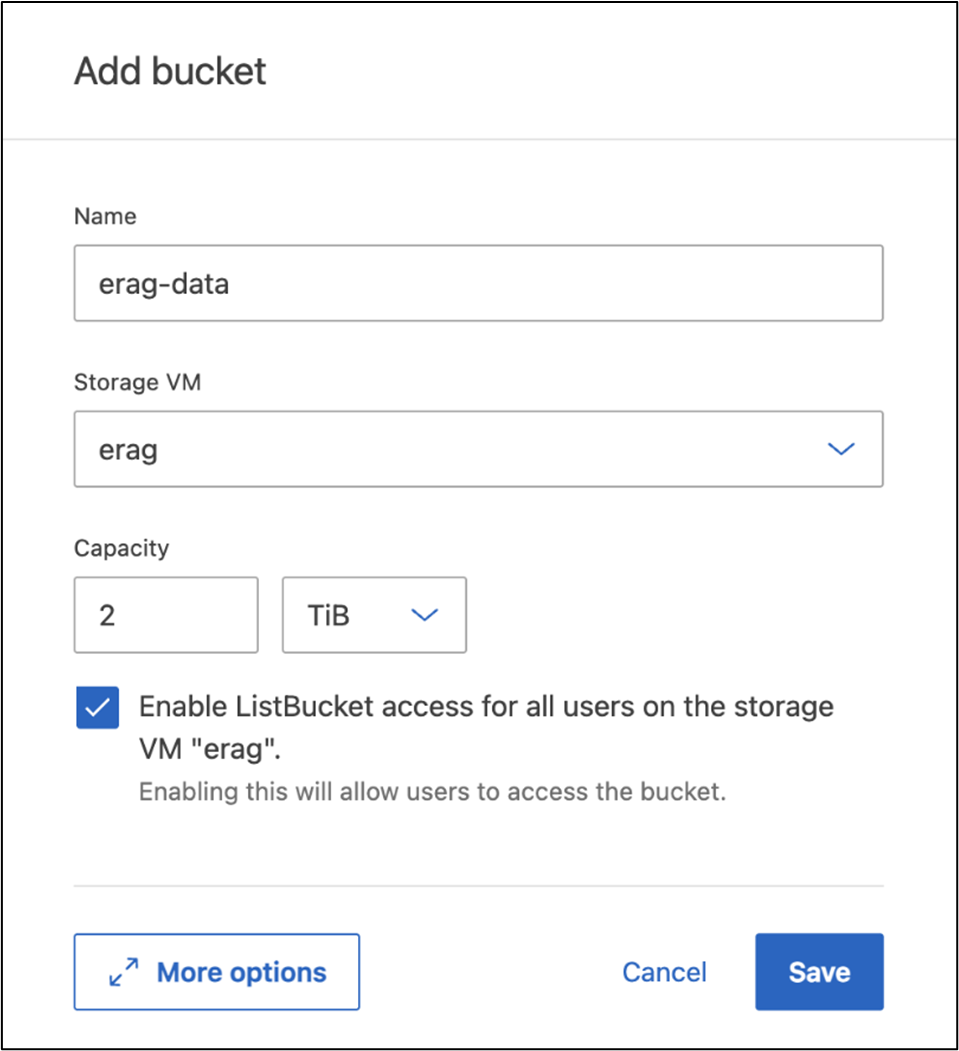
配置 S3 存储桶权限
为您在上一步中创建的 S3 存储桶配置权限。确保您在上一步中配置的用户具有以下权限: GetObject, PutObject, DeleteObject, ListBucket, GetBucketAcl, GetObjectAcl, ListBucketMultipartUploads, ListMultipartUploadParts, GetObjectTagging, PutObjectTagging, DeleteObjectTagging, GetBucketLocation, GetBucketVersioning, PutBucketVersioning, ListBucketVersions, GetBucketPolicy, PutBucketPolicy, DeleteBucketPolicy, PutLifecycleConfiguration, GetLifecycleConfiguration, GetBucketCORS, PutBucketCORS.
要使用ONTAP系统管理器编辑 S3 存储桶权限,请导航到“存储”>“存储桶”,单击存储桶的名称,单击“权限”,然后单击“编辑”。请参阅 "ONTAP S3 文档"了解更多详细信息。
以下屏幕截图展示了ONTAP系统管理器中必要的存储桶权限。
图 8 - S3 存储桶权限。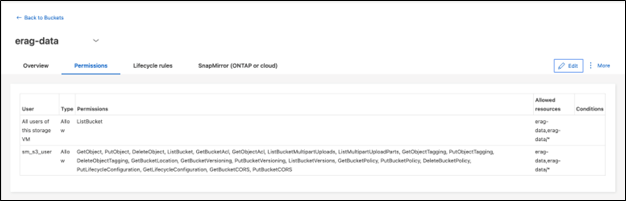
创建 bucket 跨域资源共享规则
使用ONTAP CLI,为您在上一步中创建的存储桶创建存储桶跨域资源共享 (CORS) 规则:
ontap::> bucket cors-rule create -vserver erag -bucket erag-data -allowed-origins *erag.com -allowed-methods GET,HEAD,PUT,DELETE,POST -allowed-headers *此规则允许 OPEA for Intel® AI for Enterprise RAG Web 应用程序从 Web 浏览器中与存储桶进行交互。
部署服务器
部署您的服务器并在每台服务器上安装 Ubuntu 22.04 LTS。安装 Ubuntu 后,在每台服务器上安装 NFS 实用程序。要安装 NFS 实用程序,请运行以下命令:
apt-get update && apt-get install nfs-common部署企业 RAG 2.0
有关完整的分步部署工作流程,请参阅以下文档:NetApp AIPod Mini for ERAG - 部署步骤 以上部署指南中记录了所有先决条件、基础架构准备、配置参数和部署过程。
访问适用于 Intel® AI for Enterprise RAG UI 的 OPEA
访问 OPEA for Intel® AI for Enterprise RAG UI。有关详细信息,请参见 "Intel® AI for Enterprise RAG 部署文档"。
图 9 - 适用于 Intel® AI for Enterprise RAG UI 的 OPEA。
为 RAG 提取数据
您现在可以提取文件以包含在基于 RAG 的查询扩充中。有多种提取文件的选项。根据您的需要选择适当的选项。
注意:文件被摄取后,OPEA for Intel® AI for Enterprise RAG 应用程序会自动检查文件的更新并相应地摄取更新。
*选项 1:直接上传到您的 S3 存储桶 要一次接收多个文件,我们建议您使用您选择的 S3 客户端将文件上传到您的 S3 存储桶(您之前创建的存储桶)。流行的 S3 客户端包括 AWS CLI、适用于 Python 的 Amazon SDK(Boto3)、s3cmd、S3 Browser、Cyberduck 和 Commander One。如果文件是受支持的类型,则上传到 S3 存储桶的任何文件都将由 OPEA for Intel® AI for Enterprise RAG 应用程序自动摄取。
注意:在撰写本文时,支持以下文件类型:PDF、HTML、TXT、DOC、DOCX、ADOC、PPT、PPTX、MD、XML、JSON、JSONL、YAML、XLS、XLSX、CSV、TIFF、JPG、JPEG、PNG 和 SVG。
您可以使用 OPEA for Intel® AI for Enterprise RAG UI 来确认您的文件已正确摄取。有关详细信息,请参阅 Intel® AI for Enterprise RAG UI 文档。请注意,应用程序可能需要一段时间才能接收大量文件。
*选项 2:使用 UI 上传如果您只需要摄取少量文件,则可以使用 OPEA for Intel® AI for Enterprise RAG UI 来摄取它们。有关详细信息,请参阅 Intel® AI for Enterprise RAG UI 文档。
图 10 - 数据摄取 UI。
执行聊天查询
现在,您可以通过随附的聊天界面与 OPEA for Intel® AI for Enterprise RAG 应用程序"聊天"。在响应您的查询时,应用程序会使用您摄取的文件执行 RAG。这意味着应用程序会自动在您摄取的文件中搜索相关信息,并在回复您的查询时纳入这些信息。
尺寸指南
作为验证工作的一部分,我们与英特尔合作进行了性能测试。此次测试得出了下表中列出的尺寸指导。
| 特征 | 值 | 注释 |
|---|---|---|
模型尺寸 |
200亿个参数 |
Llama-8B、Llama-13B、Mistral 7B、Qwen 14B、DeepSeek Distill 8B |
输入尺寸 |
约2000个代币 |
约4页 |
输出尺寸 |
约2000个代币 |
约4页 |
并发用户 |
32 |
“并发用户”是指同时提交查询的提示请求。 |
_注:上述规模调整指导基于使用 96 核 Intel Xeon 6 处理器收集的性能验证和测试结果。对于具有相似 I/O 令牌和模型大小要求的客户,我们建议使用具有 96 核 Xeon 6 处理器的服务器。有关规模调整指南的更多详细信息,请参阅 "Intel® AI for Enterprise RAG 规模调整指南"
结束语
企业 RAG 系统和 LLM 是一种协同工作的技术,可帮助组织提供准确的情境感知响应。这些响应涉及基于大量私人和内部企业数据的信息检索。通过使用 RAG、API、矢量嵌入和高性能存储系统来查询包含公司数据的文档存储库,可以更快、更安全地处理数据。NetApp AIPod Mini 将 NetApp 智能数据基础设施与 ONTAP 数据管理功能和 Intel Xeon 6 处理器、Intel® AI for Enterprise RAG 以及 OPEA 软件堆栈相结合,以帮助部署高性能 RAG 应用程序,并使组织走上 AI 领导者的道路。
致谢
本文档由 NetApp 解决方案工程团队成员 Sathish Thyagarajan、Michael Oglesby 和 Arpita Mahajan 撰写。作者还要感谢 Intel 企业 AI 产品团队的 Ajay Mungara、Mikolaj Zyczynski、Igor Konopko、Ramakrishna Karamsetty、Michal Prostko、Anna Alberska、Maciej Cichocki、Shreejan Mistry、Nicholas Rago 和 Ned Fiori,以及 NetApp 的其他团队成员 Lawrence Bunka、Bobby Oommen 和 Jeff Liborio,感谢他们在解决方案验证过程中提供的持续支持和帮助。
物料清单
以下是用于该解决方案功能验证的BOM,可供参考。可以使用符合以下配置的任何服务器或网络组件(甚至是最好具有 100GbE 带宽的现有网络)。
对于应用服务器:
| 零件编号 | 产品描述 | 数量 |
|---|---|---|
222HA-TN-OTO-37 |
超级服务器 SYS-222HA-TN /2U |
2 |
P4X-GNR6972P-SRPL2-UC |
Intel® Xeon® 6972P 处理器 96 核 2.40GHz 480MB 缓存(500W) |
4 |
RAM |
MEM-DR564MC-ER64(x16)64GB DDR5-6400 2RX4 (16Gb) ECC RDIMM |
32 |
HDS-M2N4-960G0-E1-TXD-NON-080(x2) SSD M.2 NVMe PCIe4 960GB 1DWPD TLC D,80 毫米 |
2 |
|
WS-1K63A-1R(x2)1U 692W/1600W 冗余单输出电源。散热量为 2361 BTU/Hr,最高温度为 59 C(约) |
4 |
对于控制服务器:
零件编号 |
产品描述 |
数量 |
511R-M-OTO-17 |
优化了 1U X13SCH-SYS、CSE-813MF2TS-R0RCNBP、PWS-602A-1R |
1 |
RPL-E 6369P IP 8C/16T 3.3G 24MB 95W 1700 BO |
1 |
|
RAM |
MEM-DR516MB-EU48(x2)16GB DDR5-4800 1Rx8 (16Gb) ECC UDIMM |
1 |
HDS-M2N4-960G0-E1-TXD-NON-080(x2) SSD M.2 NVMe PCIe4 960GB 1DWPD TLC D,80 毫米 |
2 |
对于网络交换机:
零件编号 |
产品描述 |
数量 |
DCS-7280CR3A |
Arista 7280R3A 28x100 GbE |
1 |
NetApp AFF存储:
零件编号 |
产品描述 |
数量 |
AFF-A20A-100-C |
AFF A20 HA 系统,-C |
1 |
X800-42U-R6-C |
跳线 Crd,驾驶室内,C13-C14,-C |
2 |
X97602A-C |
电源,1600W,钛金,-C |
2 |
X66211B-2-N-C |
电缆,100GbE,QSFP28-QSFP28,铜,2米,-C |
4 |
X66240A-05-N-C |
电缆,25GbE,SFP28-SFP28,铜,0.5米,-C |
2 |
X5532A-N-C |
导轨,4 柱,薄,圆形/方孔,小,可调节,24-32,-C |
1 |
X4024A-2-A-C |
驱动器包 2X1.92TB,NVMe4,SED,-C |
6 |
X60130A-C |
IO 模块,2PT,100GbE,-C |
2 |
X60132A-C |
IO 模块,4PT,10/25GbE,-C |
2 |
SW-ONTAPB-FLASH-A20-C |
SW、 ONTAP基础包、每 TB、闪存、A20、-C |
23 |
基础设施准备情况核对清单
请参见 NetApp AIPod Mini - 基础架构就绪 了解详细信息。
在哪里可以找到更多信息
要了解有关本文档中描述的信息的更多信息,请查看以下文档和/或网站:
"OPEA Enterprise RAG 部署手册" == 版本历史记录
| 版本 | 日期 | 文档版本历史记录 |
|---|---|---|
1.0 版 |
2025 年 9 月 |
初始发布 |
2.0 版 |
2026 年 2 月 |
使用 OPEA-Intel® AI for Enterprise RAG 2.0 更新 |