

执行同步分布式 AI 工作负载
 建议更改
建议更改
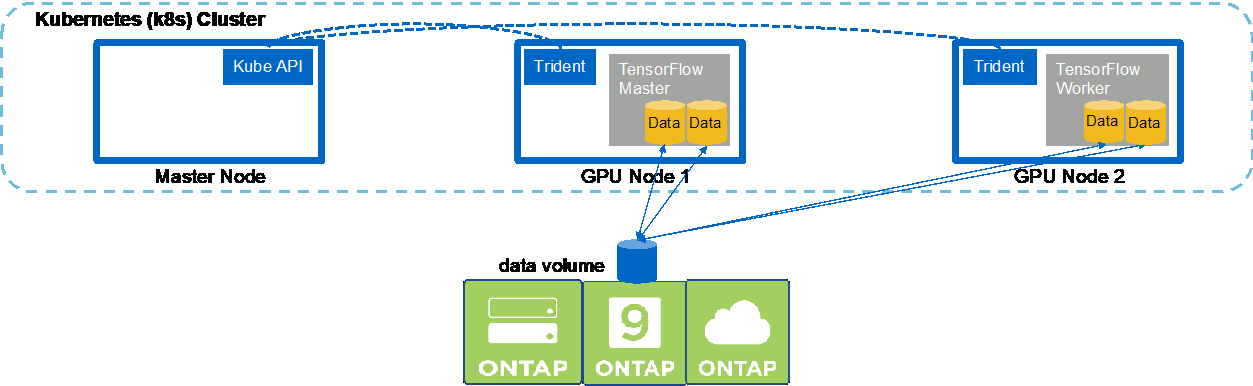
要在 Kubernetes 集群中执行同步多节点 AI 和 ML 作业,请在部署跳转主机上执行以下任务。此过程使您能够利用存储在NetApp卷上的数据,并使用比单个工作节点所能提供的更多的 GPU。请参阅下图了解同步分布式 AI 作业的描述。

|
与异步分布式作业相比,同步分布式作业可以帮助提高性能和训练准确性。关于同步作业与异步作业的优缺点的讨论超出了本文档的范围。 |
-
以下示例命令显示了如何创建一个工作器,该工作器参与本节示例中在单个节点上执行的同一 TensorFlow 基准测试作业的同步分布式执行"执行单节点 AI 工作负载"。在这个特定的例子中,只部署了一个工作器,因为作业是在两个工作器节点上执行的。
此示例工作器部署请求八个 GPU,因此可以在具有八个或更多 GPU 的单个 GPU 工作器节点上运行。如果您的 GPU 工作节点具有超过 8 个 GPU,为了最大限度地提高性能,您可能需要将此数字增加到等于您的工作节点所具有的 GPU 数量。有关 Kubernetes 部署的更多信息,请参阅 "Kubernetes 官方文档"。
在此示例中创建了 Kubernetes 部署,因为这个特定的容器化工作程序永远无法自行完成。因此,使用 Kubernetes 作业构造来部署它是没有意义的。如果您的工作者被设计或编写为自行完成,那么使用作业构造来部署您的工作者可能是有意义的。
此示例部署规范中指定的 pod 被赋予
hostNetwork`的价值 `true。此值意味着 pod 使用主机工作节点的网络堆栈,而不是 Kubernetes 通常为每个 pod 创建的虚拟网络堆栈。在这种情况下使用此注释,因为特定的工作负载依赖于 Open MPI、NCCL 和 Horovod 以同步分布式方式执行工作负载。因此,它需要访问主机网络堆栈。有关 Open MPI、NCCL 和 Horovod 的讨论超出了本文档的范围。不管这是否 `hostNetwork: true`注释是否必要取决于您正在执行的特定工作负载的要求。有关 `hostNetwork`字段,请参阅 "Kubernetes 官方文档"。$ cat << EOF > ./netapp-tensorflow-multi-imagenet-worker.yaml apiVersion: apps/v1 kind: Deployment metadata: name: netapp-tensorflow-multi-imagenet-worker spec: replicas: 1 selector: matchLabels: app: netapp-tensorflow-multi-imagenet-worker template: metadata: labels: app: netapp-tensorflow-multi-imagenet-worker spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["bash", "/netapp/scripts/start-slave-multi.sh", "22122"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-worker.yaml deployment.apps/netapp-tensorflow-multi-imagenet-worker created $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 4s -
确认您在步骤 1 中创建的工作程序部署已成功启动。以下示例命令确认已为部署创建了一个工作程序 pod(如部署定义中所示),并且该 pod 当前正在其中一个 GPU 工作程序节点上运行。
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 60s 10.61.218.154 10.61.218.154 <none> $ kubectl logs netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 22122
-
为主服务器创建一个 Kubernetes 作业,该主服务器启动、参与并跟踪同步多节点作业的执行。以下示例命令创建一个主服务器,该主服务器启动、参与并跟踪在本节示例中在单个节点上执行的相同 TensorFlow 基准测试作业的同步分布式执行"执行单节点 AI 工作负载"。
此示例主作业请求八个 GPU,因此可以在具有八个或更多 GPU 的单个 GPU 工作节点上运行。如果您的 GPU 工作节点具有超过 8 个 GPU,为了最大限度地提高性能,您可能需要将此数字增加到等于您的工作节点所具有的 GPU 数量。
此示例作业定义中指定的主 Pod 被赋予 `hostNetwork`的价值 `true`就像工作舱被赋予了 `hostNetwork`的价值 `true`在步骤 1 中。有关为什么需要此值的详细信息,请参阅步骤 1。
$ cat << EOF > ./netapp-tensorflow-multi-imagenet-master.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-tensorflow-multi-imagenet-master spec: backoffLimit: 5 template: spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["python", "/netapp/scripts/run.py", "--dataset_dir=/mnt/mount_0/dataset/imagenet", "--port=22122", "--num_devices=16", "--dgx_version=dgx1", "--nodes=10.61.218.152,10.61.218.154"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true restartPolicy: Never EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-master.yaml job.batch/netapp-tensorflow-multi-imagenet-master created $ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 0/1 25s 25s -
确认您在步骤 3 中创建的主作业正在正确运行。以下示例命令确认已为该作业创建了一个主 pod(如作业定义中所示),并且该 pod 当前正在其中一个 GPU 工作节点上运行。您还应该看到,您在步骤 1 中最初看到的工作 pod 仍在运行,并且主 pod 和工作 pod 在不同的节点上运行。
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-master-ppwwj 1/1 Running 0 45s 10.61.218.152 10.61.218.152 <none> netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 26m 10.61.218.154 10.61.218.154 <none>
-
确认您在步骤 3 中创建的主作业已成功完成。以下示例命令确认作业已成功完成。
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 9m18s $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 9m38s netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 35m $ kubectl logs netapp-tensorflow-multi-imagenet-master-ppwwj [10.61.218.152:00008] WARNING: local probe returned unhandled shell:unknown assuming bash rm: cannot remove '/lib': Is a directory [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 Total images/sec = 12881.33875 ================ Clean Cache !!! ================== mpirun -allow-run-as-root -np 2 -H 10.61.218.152:1,10.61.218.154:1 -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" bash -c 'sync; echo 1 > /proc/sys/vm/drop_caches' ========================================= mpirun -allow-run-as-root -np 16 -H 10.61.218.152:8,10.61.218.154:8 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -x NCCL_IB_HCA=mlx5 -x NCCL_NET_GDR_READ=1 -x NCCL_IB_SL=3 -x NCCL_IB_GID_INDEX=3 -x NCCL_SOCKET_IFNAME=enp5s0.3091,enp12s0.3092,enp132s0.3093,enp139s0.3094 -x NCCL_IB_CUDA_SUPPORT=1 -mca orte_base_help_aggregate 0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" python /netapp/tensorflow/benchmarks_190205/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=256 --device=gpu --force_gpu_compatible=True --num_intra_threads=1 --num_inter_threads=48 --variable_update=horovod --batch_group_size=20 --num_batches=500 --nodistortions --num_gpus=1 --data_format=NCHW --use_fp16=True --use_tf_layers=False --data_name=imagenet --use_datasets=True --data_dir=/mnt/mount_0/dataset/imagenet --datasets_parallel_interleave_cycle_length=10 --datasets_sloppy_parallel_interleave=False --num_mounts=2 --mount_prefix=/mnt/mount_%d --datasets_prefetch_buffer_size=2000 -- datasets_use_prefetch=True --datasets_num_private_threads=4 --horovod_device=gpu > /tmp/20190814_161609_tensorflow_horovod_rdma_resnet50_gpu_16_256_b500_imagenet_nodistort_fp16_r10_m2_nockpt.txt 2>&1
-
当您不再需要工作部署时,请删除它。以下示例命令显示删除在步骤 1 中创建的工作程序部署对象。
当您删除工作部署对象时,Kubernetes 会自动删除任何关联的工作容器。
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 43m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 17m netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 43m $ kubectl delete deployment netapp-tensorflow-multi-imagenet-worker deployment.extensions "netapp-tensorflow-multi-imagenet-worker" deleted $ kubectl get deployments No resources found. $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 18m
-
*可选:*清理主作业工件。以下示例命令显示删除在步骤 3 中创建的主作业对象。
当您删除主作业对象时,Kubernetes 会自动删除任何关联的主 pod。
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 19m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 19m $ kubectl delete job netapp-tensorflow-multi-imagenet-master job.batch "netapp-tensorflow-multi-imagenet-master" deleted $ kubectl get jobs No resources found. $ kubectl get pods No resources found.