

矢量数据库性能验证
 建议更改
建议更改
本节重点介绍在矢量数据库上执行的性能验证。
性能验证
性能验证在矢量数据库和存储系统中都起着至关重要的作用,是确保最佳运行和高效资源利用的关键因素。矢量数据库以处理高维数据和执行相似性搜索而闻名,需要保持高性能水平才能快速准确地处理复杂查询。性能验证有助于识别瓶颈、微调配置并确保系统能够处理预期负载而不会降低服务质量。同样,在存储系统中,性能验证对于确保数据高效存储和检索至关重要,不会出现可能影响整体系统性能的延迟问题或瓶颈。它还有助于对存储基础设施的必要升级或变更做出明智的决策。因此,性能验证是系统管理的一个重要方面,对维持高服务质量、运行效率和整体系统可靠性有重要贡献。
在本节中,我们旨在深入研究矢量数据库(例如 Milvus 和 pgvecto.rs)的性能验证,重点关注它们的存储性能特征,例如 I/O 配置文件和 NetApp 存储控制器在 LLM 生命周期内支持 RAG 和推理工作负载的行为。当这些数据库与ONTAP存储解决方案结合时,我们将评估并识别任何性能差异因素。我们的分析将基于关键性能指标,例如每秒处理的查询数(QPS)。
请检查下面用于 milvus 和进度的方法。
详细信息 |
Milvus(单机和集群) |
Postgres(pgvecto.rs)# |
version |
2.3.2 |
0.2.0 |
Filesystem |
iSCSI LUN 上的 XFS |
|
工作负载生成器 |
"VectorDB-Bench"– v0.0.5 |
|
数据集 |
LAION 数据集 * 1000 万个嵌入 * 768 个维度 * 数据集大小约为 300GB |
|
存储控制器 |
AFF 800 * 版本 — 9.14.1 * 4 x 100GbE — 用于 milvus,2x 100GbE 用于 postgres * iscsi |
带有 Milvus 独立集群的 VectorDB-Bench
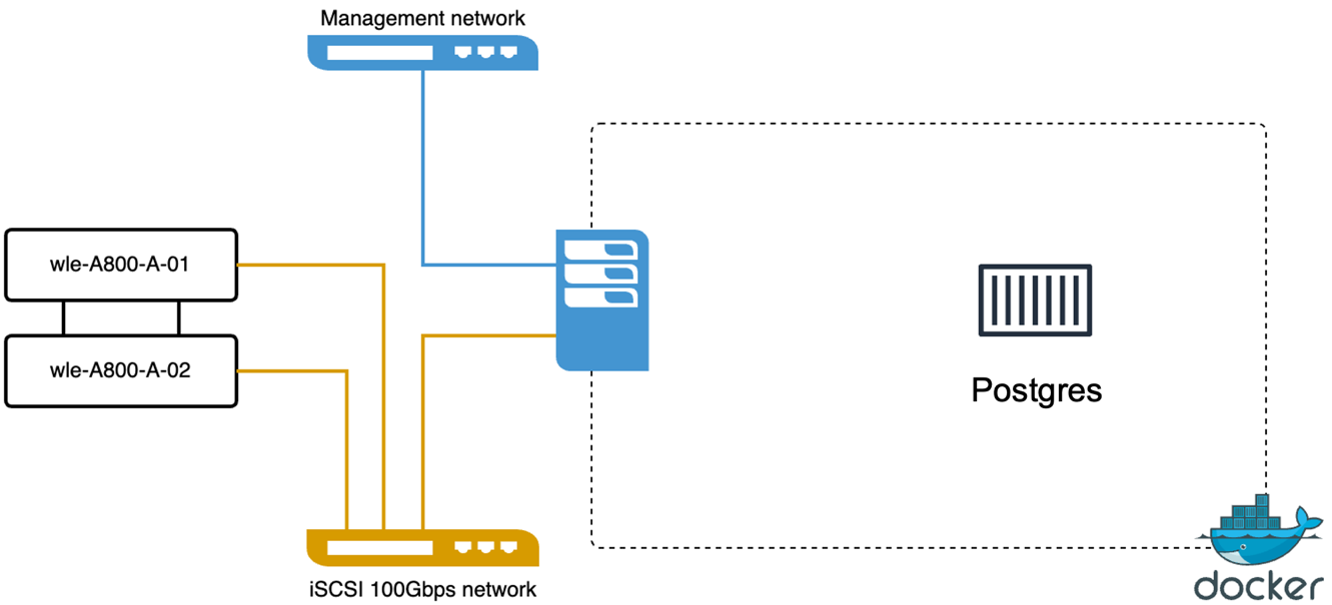
我们使用vectorDB-Bench在milvus独立集群上进行了以下性能验证。 milvus 独立集群的网络和服务器连接如下。
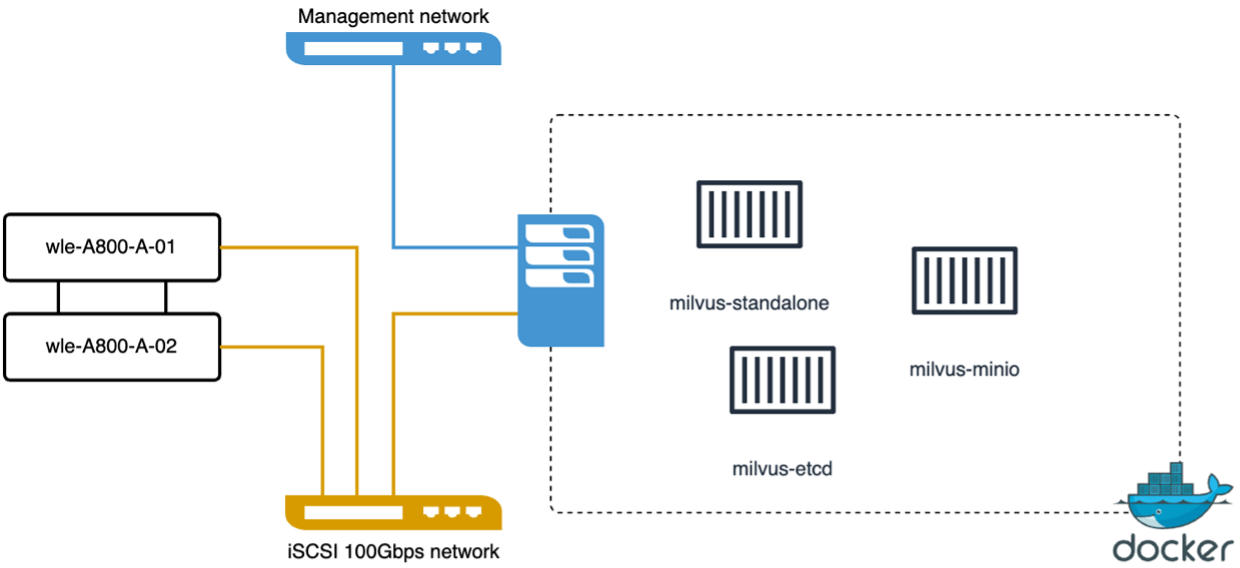
在本节中,我们分享测试 Milvus 独立数据库的观察和结果。。我们选择 DiskANN 作为这些测试的索引类型。。提取、优化和创建大约 100GB 数据集的索引大约需要 5 个小时。在此持续时间的大部分时间里,配备 20 个内核(启用超线程时相当于 40 个 vCPU)的 Milvus 服务器都以其最大 CPU 容量 100% 运行。我们发现 DiskANN 对于超过系统内存大小的大型数据集尤为重要。。在查询阶段,我们观察到每秒查询次数 (QPS) 为 10.93,召回率为 0.9987。查询的第 99 个百分位延迟测量为 708.2 毫秒。
从存储角度来看,数据库在摄取、插入后优化和索引创建阶段发出大约 1,000 个操作/秒。在查询阶段,它要求每秒 32,000 次操作。
以下部分介绍存储性能指标。
| 工作负载阶段 | 指标 | 值 |
|---|---|---|
数据提取和插入后优化 |
IOPS |
< 1,000 |
延迟 |
< 400 微秒 |
|
工作量 |
读/写混合,主要是写入 |
|
IO 大小 |
64 KB |
|
查询 |
IOPS |
峰值为32,000 |
延迟 |
< 400 微秒 |
|
工作量 |
100% 缓存读取 |
|
IO 大小 |
主要为8KB |
VectorDB-bench 结果如下。
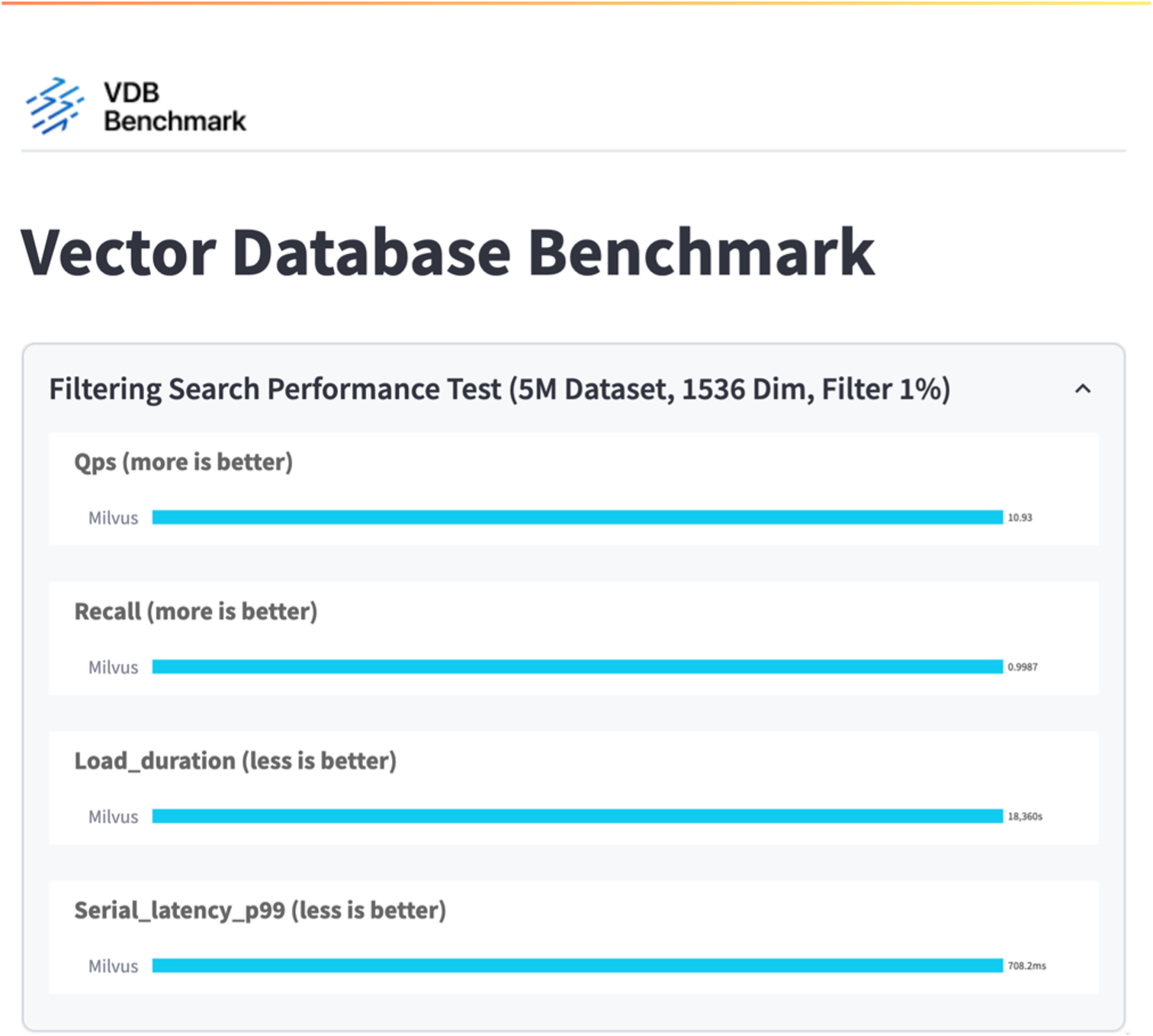
从独立 Milvus 实例的性能验证来看,当前的设置不足以支持 500 万个向量、维度为 1536 的数据集。我们已确定存储拥有足够的资源,不会构成系统的瓶颈。
带有 milvus 集群的 VectorDB-Bench
在本节中,我们讨论在 Kubernetes 环境中部署 Milvus 集群。此 Kubernetes 设置构建于 VMware vSphere 部署之上,该部署托管 Kubernetes 主节点和工作节点。
以下部分介绍 VMware vSphere 和 Kubernetes 部署的详细信息。
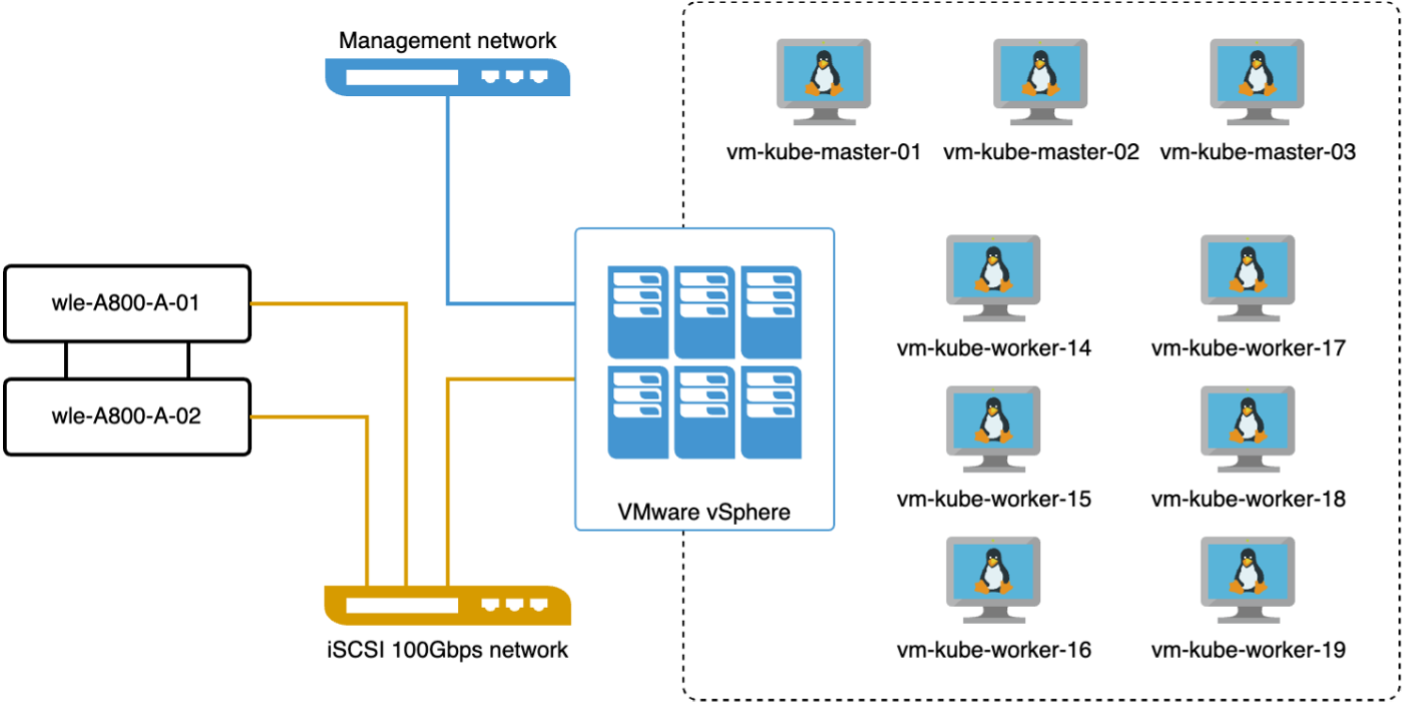
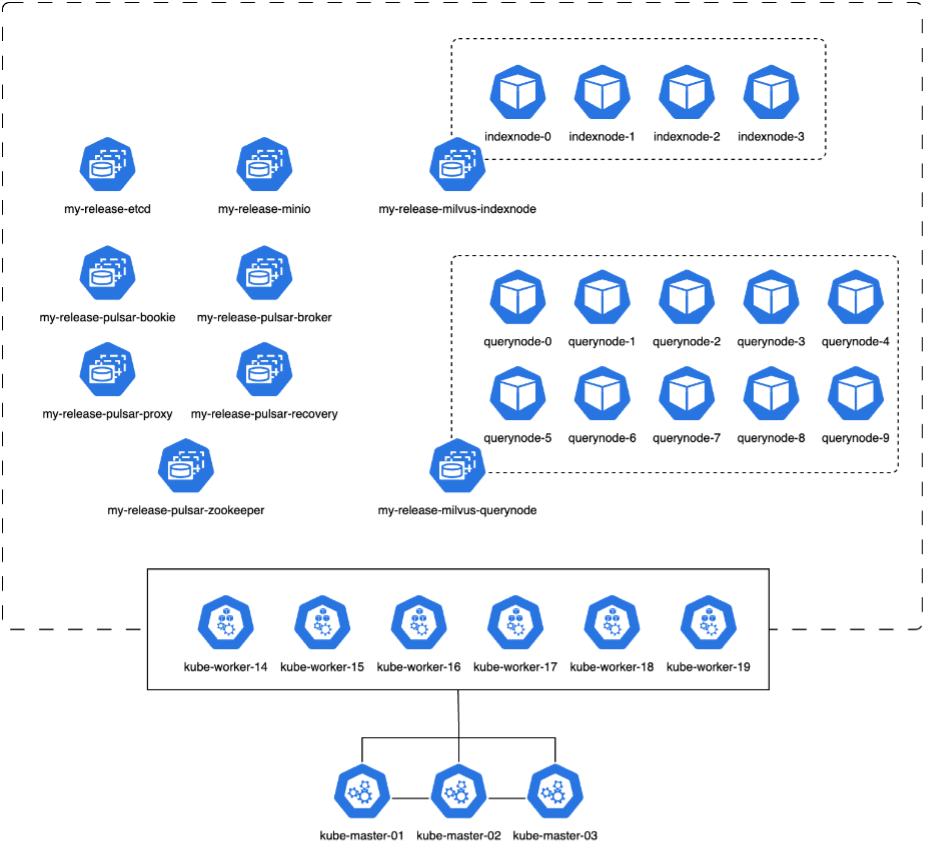
在本节中,我们介绍了测试 Milvus 数据库的观察结果和结果。 * 使用的索引类型是 DiskANN。 * 下表比较了在处理 500 万个向量(维度为 1536)时独立部署和集群部署的差异。我们观察到,在集群部署中,数据提取和插入后优化所需的时间较短。与独立设置相比,集群部署中查询的第 99 个百分位延迟减少了六倍。 * 尽管集群部署中的每秒查询数 (QPS) 率较高,但并未达到预期水平。

下图提供了各种存储指标的视图,包括存储集群延迟和总 IOPS(每秒输入/输出操作)。
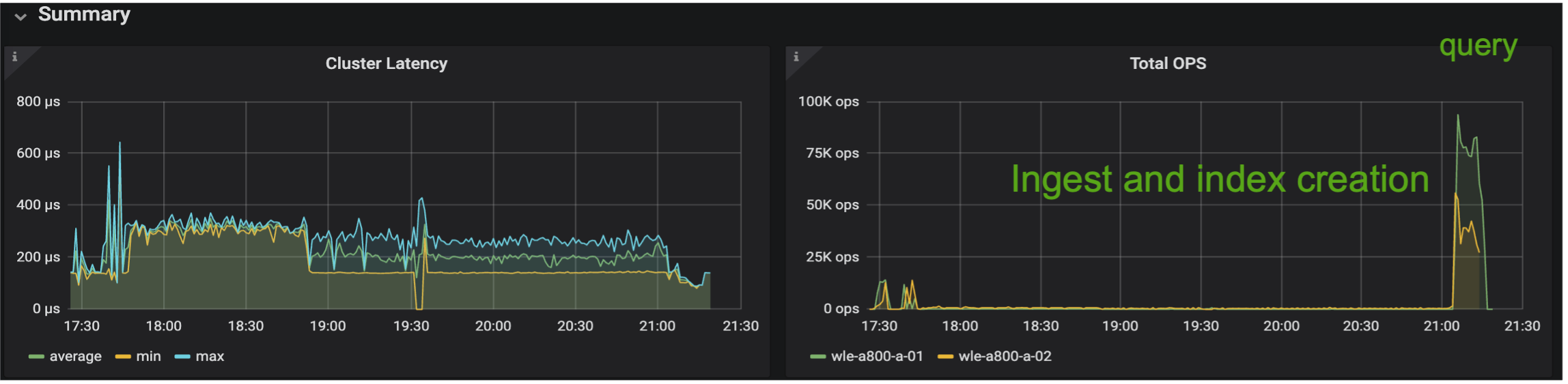
以下部分介绍关键的存储性能指标。
| 工作负载阶段 | 指标 | 值 |
|---|---|---|
数据提取和插入后优化 |
IOPS |
< 1,000 |
延迟 |
< 400 微秒 |
|
工作量 |
读/写混合,主要是写入 |
|
IO 大小 |
64 KB |
|
查询 |
IOPS |
峰值为147,000 |
延迟 |
< 400 微秒 |
|
工作量 |
100% 缓存读取 |
|
IO 大小 |
主要为8KB |
基于独立 Milvus 和 Milvus 集群的性能验证,我们展示了存储 I/O 配置文件的详细信息。 * 我们观察到 I/O 配置文件在独立部署和集群部署中保持一致。 * 峰值 IOPS 的观察到的差异可以归因于集群部署中的客户端数量较多。
带有 Postgres 的vectorDB-Bench(pgvecto.rs)
我们使用 VectorDB-Bench 对 PostgreSQL(pgvecto.rs)进行了如下操作:PostgreSQL(具体来说,pgvecto.rs)的网络和服务器连接详情如下:
在本节中,我们分享测试 PostgreSQL 数据库(特别是使用 pgvecto.rs)的观察和结果。 * 我们选择 HNSW 作为这些测试的索引类型,因为在测试时,DiskANN 不适用于 pgvecto.rs。 * 在数据提取阶段,我们加载了 Cohere 数据集,该数据集包含 1000 万个向量,维度为 768。该过程大约耗时 4.5 小时。 * 在查询阶段,我们观察到每秒查询次数 (QPS) 为 1,068,召回率为 0.6344。查询的第 99 个百分位延迟测量为 20 毫秒。在大部分运行时间内,客户端 CPU 都以 100% 的容量运行。
下图提供了各种存储指标的视图,包括存储集群延迟总 IOPS(每秒输入/输出操作)。

The following section presents the key storage performance metrics. image:pgvecto-storage-perf-metrics.png["该图显示输入/输出对话框或表示书面内容"]
milvus 与 postgres 在 Vector DB Bench 上的性能对比
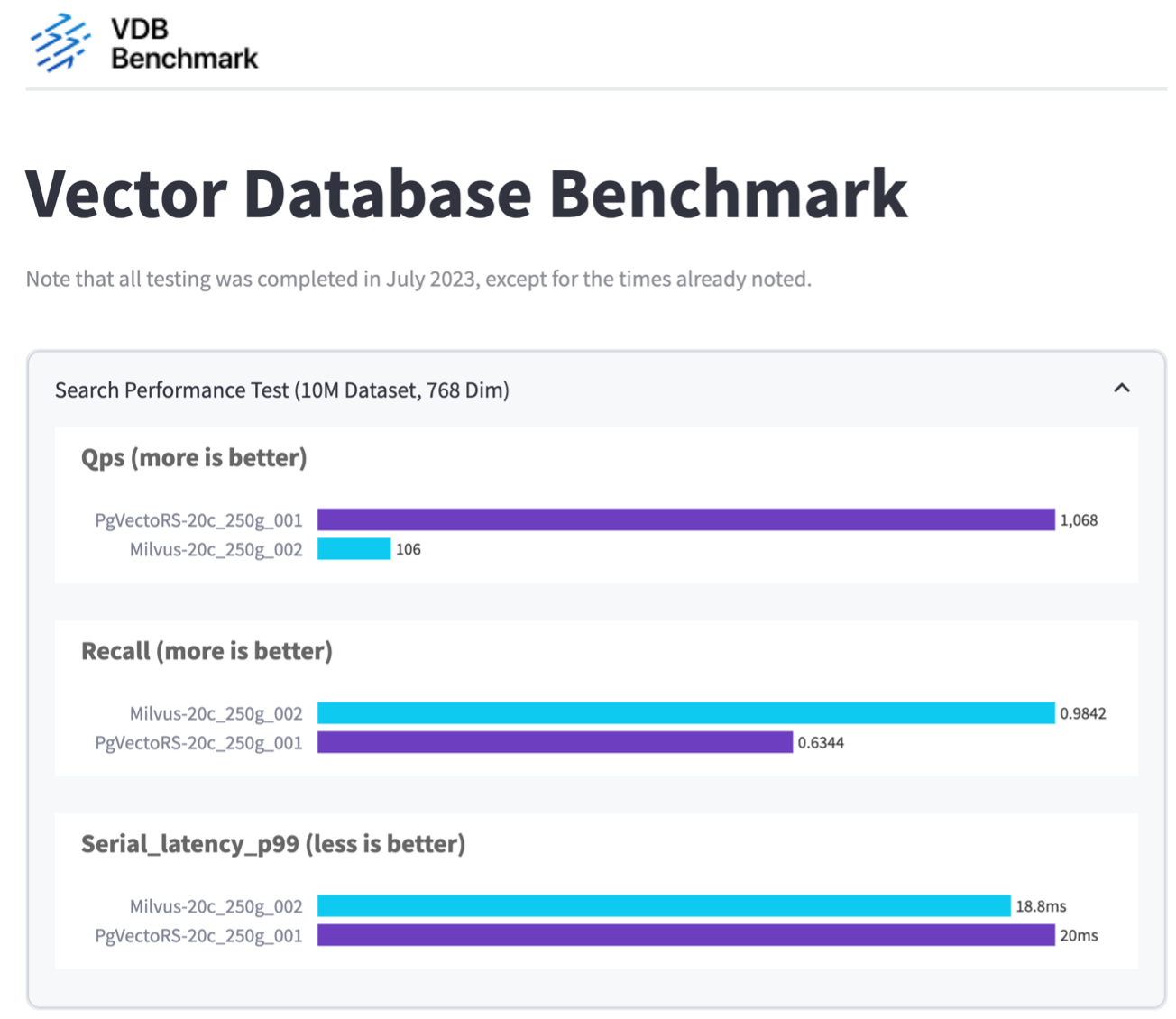
根据我们使用 VectorDBBench 对 Milvus 和 PostgreSQL 进行的性能验证,我们观察到以下情况:
-
索引类型:HNSW
-
数据集:包含 768 个维度的 1000 万个向量
我们发现 pgvecto.rs 的每秒查询数 (QPS) 达到 1,068,召回率为 0.6344,而 Milvus 的每秒查询数 (QPS) 达到 106,召回率为 0.9842。
如果您优先考虑查询的高精度,那么 Milvus 的性能优于 pgvecto.rs,因为它在每个查询中检索到更高比例的相关项目。但是,如果每秒查询次数是一个更关键的因素,那么 pgvecto.rs 就超过了 Milvus。但值得注意的是,通过 pgvecto.rs 检索的数据质量较低,大约 37% 的搜索结果是不相关的项目。
根据我们的性能验证得出的观察结果:
根据我们的性能验证,我们做出了以下观察:
在 Milvus 中,I/O 配置文件与 OLTP 工作负载非常相似,例如 Oracle SLOB 中的工作负载。基准测试包括三个阶段:数据提取、后优化和查询。初始阶段主要以 64KB 写入操作为特征,而查询阶段主要涉及 8KB 读取。我们希望ONTAP能够熟练地处理 Milvus I/O 负载。
PostgreSQL I/O 配置文件不会带来具有挑战性的存储工作负载。鉴于目前正在进行的内存实现,我们在查询阶段没有观察到任何磁盘 I/O。
DiskANN 成为存储区分的关键技术。它使得向量数据库搜索能够超越系统内存边界进行有效扩展。然而,不太可能通过内存中的向量数据库索引(例如 HNSW)建立存储性能差异。
还值得注意的是,当索引类型为 HSNW 时,存储在查询阶段并不起关键作用,而查询阶段是支持 RAG 应用的矢量数据库最重要的操作阶段。这里的含义是存储性能不会显著影响这些应用程序的整体性能。