

在 ONTAP 中配置 MetroCluster FC 软件
 建议更改
建议更改
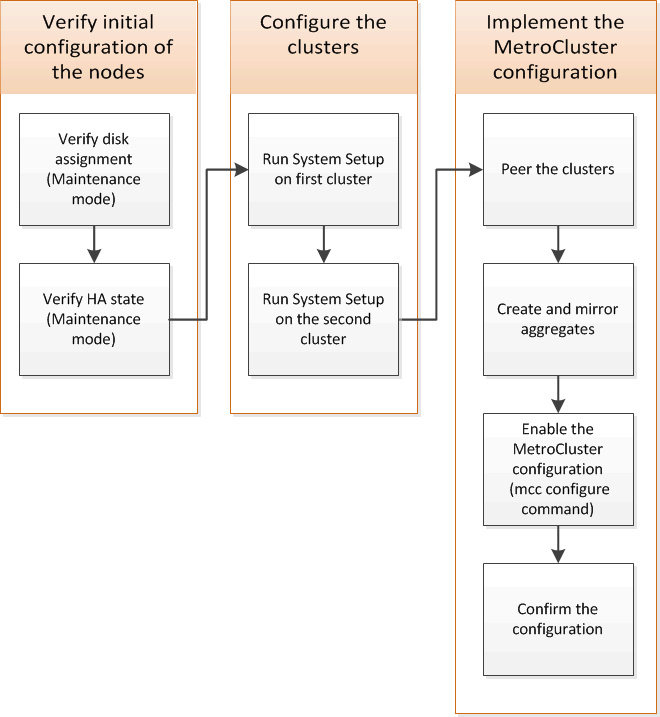
您必须在 ONTAP 中设置 MetroCluster FC 配置中的每个节点,包括节点级配置和将节点配置到两个站点中。您还必须实现两个站点之间的 MetroCluster 关系。
收集所需信息
在开始配置过程之前,您需要收集控制器模块所需的 IP 地址。
站点 A 的 IP 网络信息工作表
在配置系统之前,您必须从网络管理员处获取第一个 MetroCluster 站点(站点 A )的 IP 地址和其他网络信息。
站点 A 交换机信息(交换集群)
在为系统布线时,您需要为每个集群交换机提供主机名和管理 IP 地址。如果您使用的是双节点无交换机集群或双节点 MetroCluster 配置(每个站点一个节点),则不需要此信息。
集群交换机 |
主机名 |
IP 地址 |
网络掩码 |
默认网关 |
互连 1 |
||||
互连 2. |
||||
管理 1. |
||||
管理 2. |
站点 A 集群创建信息
首次创建集群时,您需要以下信息:
信息类型 |
您的价值 |
集群名称 此操作步骤中使用的示例: site_A |
|
DNS 域 |
|
DNS 名称服务器 |
|
位置 |
|
管理员密码 |
站点 A 节点信息
对于集群中的每个节点,您都需要一个管理 IP 地址,一个网络掩码和一个默认网关。
节点 |
端口 |
IP 地址 |
网络掩码 |
默认网关 |
节点 1 此操作步骤中使用的示例: controller_A_1 |
||||
节点 2 如果使用双节点 MetroCluster 配置(每个站点一个节点),则不需要此配置。 此操作步骤中使用的示例: controller_A_2 |
用于集群对等的站点 A LIF 和端口
对于集群中的每个节点,您需要两个集群间 LIF 的 IP 地址,包括网络掩码和默认网关。集群间 LIF 用于为集群建立对等关系。
节点 |
端口 |
集群间 LIF 的 IP 地址 |
网络掩码 |
默认网关 |
节点 1 IC LIF 1 |
||||
节点 1 IC LIF 2 |
||||
节点 2 IC LIF 1 双节点 MetroCluster 配置不需要(每个站点一个节点)。 |
||||
节点 2 IC LIF 2 双节点 MetroCluster 配置不需要(每个站点一个节点)。 |
站点 A 时间服务器信息
您必须同步时间,这需要一个或多个 NTP 时间服务器。
节点 |
主机名 |
IP 地址 |
网络掩码 |
默认网关 |
NTP 服务器 1. |
||||
NTP 服务器 2. |
站点A nbsp;AutoSupport 信息
您必须在每个节点上配置 AutoSupport ,这需要以下信息:
信息类型 |
您的价值 |
|
发件人电子邮件地址 |
邮件主机 |
|
IP 地址或名称 |
传输协议 |
|
HTTP , HTTPS 或 SMTP |
代理服务器 |
|
收件人电子邮件地址或分发列表 |
完整长度的消息 |
|
简洁的消息 |
||
站点A nbsp;SP信息
您必须启用对每个节点的服务处理器( Service Processor , SP )的访问以进行故障排除和维护,这要求每个节点具有以下网络信息:
节点 |
IP 地址 |
网络掩码 |
默认网关 |
节点 1 |
|||
节点 2 双节点 MetroCluster 配置不需要(每个站点一个节点)。 |
站点 B 的 IP 网络信息工作表
在配置系统之前,您必须从网络管理员处获取第二个 MetroCluster 站点(站点 B )的 IP 地址和其他网络信息。
站点 B 交换机信息(交换集群)
在为系统布线时,您需要为每个集群交换机提供主机名和管理 IP 地址。如果您使用的是双节点无交换机集群或具有双节点 MetroCluster 配置(每个站点一个节点),则不需要此信息。
集群交换机 |
主机名 |
IP 地址 |
网络掩码 |
默认网关 |
互连 1 |
||||
互连 2. |
||||
管理 1. |
||||
管理 2. |
站点 B 集群创建信息
首次创建集群时,您需要以下信息:
信息类型 |
您的价值 |
集群名称 此过程中使用的示例:site_B |
|
DNS 域 |
|
DNS 名称服务器 |
|
位置 |
|
管理员密码 |
站点 B 节点信息
对于集群中的每个节点,您都需要一个管理 IP 地址,一个网络掩码和一个默认网关。
节点 |
端口 |
IP 地址 |
网络掩码 |
默认网关 |
节点 1 此过程中使用的示例:controller_B_1 |
||||
节点 2 双节点 MetroCluster 配置不需要(每个站点一个节点)。 本过程中使用的示例:controller_B_2 |
用于集群对等的站点 B LIF 和端口
对于集群中的每个节点,您需要两个集群间 LIF 的 IP 地址,包括网络掩码和默认网关。集群间 LIF 用于为集群建立对等关系。
节点 |
端口 |
集群间 LIF 的 IP 地址 |
网络掩码 |
默认网关 |
节点 1 IC LIF 1 |
||||
节点 1 IC LIF 2 |
||||
节点 2 IC LIF 1 双节点 MetroCluster 配置不需要(每个站点一个节点)。 |
||||
节点 2 IC LIF 2 双节点 MetroCluster 配置不需要(每个站点一个节点)。 |
站点 B 时间服务器信息
您必须同步时间,这需要一个或多个 NTP 时间服务器。
节点 |
主机名 |
IP 地址 |
网络掩码 |
默认网关 |
NTP 服务器 1. |
||||
NTP 服务器 2. |
站点B nbsp AutoSupport信息
您必须在每个节点上配置 AutoSupport ,这需要以下信息:
信息类型 |
您的价值 |
|
发件人电子邮件地址 |
||
邮件主机 |
IP 地址或名称 |
|
传输协议 |
HTTP , HTTPS 或 SMTP |
|
代理服务器 |
收件人电子邮件地址或分发列表 |
|
完整长度的消息 |
简洁的消息 |
|
合作伙伴 |
||
站点B nbsp信息
您必须启用对每个节点的服务处理器( Service Processor , SP )的访问以进行故障排除和维护,这要求每个节点具有以下网络信息:
节点 |
IP 地址 |
网络掩码 |
默认网关 |
节点 1 ( controller_B_1 ) |
|||
节点 2 ( controller_B_2 ) 双节点 MetroCluster 配置不需要(每个站点一个节点)。 |
标准集群和 MetroCluster 配置之间的相似之处和不同之处
在 MetroCluster 配置中,每个集群中的节点配置与标准集群中的节点配置类似。
MetroCluster 配置基于两个标准集群构建。在物理上,配置必须对称,每个节点都具有相同的硬件配置,并且所有 MetroCluster 组件都必须进行布线和配置。但是, MetroCluster 配置中节点的基本软件配置与标准集群中节点的基本软件配置相同。
配置步骤 |
标准集群配置 |
MetroCluster 配置 |
在每个节点上配置管理,集群和数据 LIF 。 |
这两种类型的集群都相同 |
|
配置根聚合。 |
这两种类型的集群都相同 |
|
将集群中的节点配置为 HA 对 |
这两种类型的集群都相同 |
|
在集群中的一个节点上设置集群。 |
这两种类型的集群都相同 |
|
将另一个节点加入集群。 |
这两种类型的集群都相同 |
|
创建镜像根聚合。 |
可选 |
必需 |
为集群建立对等关系。 |
可选 |
必需 |
启用 MetroCluster 配置。 |
不适用 |
必需 |
在维护模式下验证和配置组件的 HA 状态
在MetroCluster FC配置中配置存储系统时、必须确保控制器模块和机箱组件的高可用性(HA)状态为MCC或MCC-2n、以便这些组件可以正常启动。尽管此值应在从工厂收到的系统上进行预配置、但您仍应验证设置、然后再继续。

|
如果控制器模块和机箱的HA状态不正确、则必须重新初始化节点、才能配置MetroCluster。您必须使用此过程更正设置、然后使用以下过程之一初始化系统:
|
验证系统是否处于维护模式。
-
在维护模式下,显示控制器模块和机箱的 HA 状态:
ha-config show正确的 HA 状态取决于您的 MetroCluster 配置。
MetroCluster配置类型
所有组件的HA状态…
八节点或四节点MetroCluster FC配置
MCC
双节点 MetroCluster FC 配置
MCC-2n
八节点或四节点MetroCluster IP配置
mccip
-
如果为控制器显示的系统状态不正确、请在控制器模块上为您的配置设置正确的HA状态:
MetroCluster配置类型
命令
八节点或四节点MetroCluster FC配置
ha-config modify controller mcc双节点 MetroCluster FC 配置
ha-config modify controller mcc-2n八节点或四节点MetroCluster IP配置
ha-config modify controller mccip -
如果为机箱显示的系统状态不正确、请为机箱上的配置设置正确的HA状态:
MetroCluster配置类型
命令
八节点或四节点MetroCluster FC配置
ha-config modify chassis mcc双节点 MetroCluster FC 配置
ha-config modify chassis mcc-2n八节点或四节点MetroCluster IP配置
ha-config modify chassis mccip -
将节点启动至 ONTAP :
boot_ontap -
重复此整个过程以验证MetroCluster配置中每个节点上的HA状态。
还原系统默认值并在控制器模块上配置 HBA 类型
要确保 MetroCluster 安装成功,请重置和还原控制器模块上的默认值。
只有使用 FC-SAS 网桥的延伸型配置才需要执行此任务。
-
在 LOADER 提示符处,将环境变量返回到其默认设置:
set-defaults -
将节点启动至维护模式,然后为系统中的任何 HBA 配置设置:
-
启动至维护模式:
boot_ontap maint -
检查端口的当前设置:
ucadmin show -
根据需要更新端口设置。
如果您具有此类型的 HBA 和所需模式 …
使用此命令 …
CNA FC
ucadmin modify -m fc -t initiator adapter_nameCNA 以太网
ucadmin modify -mode cna adapter_nameFC 目标
fcadmin config -t target adapter_nameFC 启动程序
fcadmin config -t initiator adapter_name -
-
退出维护模式:
halt运行此命令后,请等待,直到节点停留在 LOADER 提示符处。
-
将节点重新启动至维护模式,以使配置更改生效:
boot_ontap maint -
验证所做的更改:
如果您使用的是此类型的 HBA…
使用此命令 …
CNA
ucadmin showFC
fcadmin show -
退出维护模式:
halt运行此命令后,请等待,直到节点停留在 LOADER 提示符处。
-
将节点启动至启动菜单:
boot_ontap 菜单运行此命令后,请等待,直到显示启动菜单为止。
-
在启动菜单提示符处键入 "`wipeconfig` " 以清除节点配置,然后按 Enter 键。
以下屏幕将显示启动菜单提示符:
Please choose one of the following:
(1) Normal Boot.
(2) Boot without /etc/rc.
(3) Change password.
(4) Clean configuration and initialize all disks.
(5) Maintenance mode boot.
(6) Update flash from backup config.
(7) Install new software first.
(8) Reboot node.
(9) Configure Advanced Drive Partitioning.
Selection (1-9)? wipeconfig
This option deletes critical system configuration, including cluster membership.
Warning: do not run this option on a HA node that has been taken over.
Are you sure you want to continue?: yes
Rebooting to finish wipeconfig request.
在 FAS8020 系统上的 X1132A-R6 四端口卡上配置 FC-VI 端口
如果在 FAS8020 系统上使用 X1132A-R6 四端口卡,则可以进入维护模式来配置 1a 和 1b 端口以供 FC-VI 和启动程序使用。从工厂收到的 MetroCluster 系统不需要执行此操作,这些端口已根据您的配置进行了相应设置。
此任务必须在维护模式下执行。

|
只有 FAS8020 和 AFF 8020 系统才支持使用 ucadmin 命令将 FC 端口转换为 FC-VI 端口。任何其他平台均不支持将 FC 端口转换为 FCVI 端口。 |
-
禁用端口:
s存储禁用适配器 1as存储禁用适配器 1b*> storage disable adapter 1a Jun 03 02:17:57 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1a. Host adapter 1a disable succeeded Jun 03 02:17:57 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1a is now offline. *> storage disable adapter 1b Jun 03 02:18:43 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1b. Host adapter 1b disable succeeded Jun 03 02:18:43 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1b is now offline. *>
-
验证端口是否已禁用:
ucadmin show*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - - offline 1b fc initiator - - offline 1c fc initiator - - online 1d fc initiator - - online -
将 a 和 b 端口设置为 FC-VI 模式:
ucadmin modify -adapter 1a -type fcvi命令会在端口对 1a 和 1b 中的两个端口上设置模式(即使在命令中仅指定 1a )。
*> ucadmin modify -t fcvi 1a Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1a. Reboot the controller for the changes to take effect. Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1b. Reboot the controller for the changes to take effect.
-
确认此更改处于待定状态:
ucadmin show*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - fcvi offline 1b fc initiator - fcvi offline 1c fc initiator - - online 1d fc initiator - - online -
关闭控制器,然后重新启动到维护模式。
-
确认配置更改:
ucadmin show localNode Adapter Mode Type Mode Type Status ------------ ------- ------- --------- ------- --------- ----------- ... controller_B_1 1a fc fcvi - - online controller_B_1 1b fc fcvi - - online controller_B_1 1c fc initiator - - online controller_B_1 1d fc initiator - - online 6 entries were displayed.
验证八节点或四节点配置中维护模式下的磁盘分配
在将系统完全启动到 ONTAP 之前,您可以选择启动到维护模式并验证节点上的磁盘分配。应分配这些磁盘以创建完全对称的主动 - 主动配置,其中每个池分配的磁盘数量相等。
新的 MetroCluster 系统在发货前已完成磁盘分配。
下表显示了 MetroCluster 配置的池分配示例。磁盘会按磁盘架分配给池。
-
站点 A 的磁盘架 *
磁盘架( sample_shelf_name ) … |
属于 … |
并分配给该节点的 … |
磁盘架 1 ( shelf_A_1_1 ) |
节点 A 1. |
池 0 |
磁盘架 2 ( shelf_A_1_3 ) |
||
磁盘架 3 ( shelf_B_1_1 ) |
节点 B 1 |
池 1 |
磁盘架 4 ( shelf_B_1_3 ) |
||
磁盘架 5 ( shelf_A_2_1 ) |
节点 A 2. |
池 0 |
磁盘架 6 ( shelf_A_2_3 ) |
||
磁盘架 7 ( shelf_B_2_1 ) |
节点 B 2. |
池 1 |
磁盘架 8 ( shelf_B_2_3 ) |
||
磁盘架 1 ( shelf_A_3_1 ) |
节点 A 3. |
池 0 |
磁盘架 2 ( shelf_A_3_3 ) |
||
磁盘架 3 ( shelf_B_3_1 ) |
节点 B 3. |
池 1 |
磁盘架 4 ( shelf_B_3_3 ) |
||
磁盘架 5 ( shelf_A_4_1 ) |
节点 A 4. |
池 0 |
磁盘架 6 ( shelf_A_4_3 ) |
||
磁盘架 7 ( shelf_B_4_1 ) |
节点 B 4. |
池 1 |
磁盘架 8 ( shelf_B_4_3 ) |
-
站点 B 的磁盘架 *
磁盘架( sample_shelf_name ) … |
属于 … |
并分配给该节点的 … |
磁盘架 9 ( shelf_B_1_2 ) |
节点 B 1 |
池 0 |
磁盘架 10 ( shelf_B_1_4 ) |
磁盘架 11 ( shelf_A_1_2 ) |
节点 A 1. |
池 1 |
磁盘架 12 ( shelf_A_1_4 ) |
磁盘架 13 ( shelf_B_2_2 ) |
节点 B 2. |
池 0 |
磁盘架 14 ( shelf_B_2_4 ) |
磁盘架 15 ( shelf_A_2_2 ) |
节点 A 2. |
池 1 |
磁盘架 16 ( shelf_A_2_4 ) |
磁盘架 1 ( shelf_B_3_2 ) |
节点 A 3. |
池 0 |
磁盘架 2 ( shelf_B_3_4 ) |
磁盘架 3 ( shelf_A_3_2 ) |
节点 B 3. |
池 1 |
磁盘架 4 ( shelf_A_3_4 ) |
磁盘架 5 ( shelf_B_4_2 ) |
节点 A 4. |
池 0 |
磁盘架 6 ( shelf_B_4_4 ) |
磁盘架 7 ( shelf_A_4_2 ) |
节点 B 4. |
-
确认磁盘架分配:
d展示– v -
如有必要,明确将所连接磁盘架上的磁盘分配给相应的池:
d磁盘分配通过在命令中使用通配符,您可以使用一个命令分配磁盘架上的所有磁盘。您可以使用
storage show disk -x命令来确定每个磁盘的磁盘架 ID 和托架。
在非 AFF 系统中分配磁盘所有权
如果 MetroCluster 节点未正确分配磁盘,或者您在配置中使用的是 DS460C 磁盘架,则必须按磁盘架为 MetroCluster 配置中的每个节点分配磁盘。您将创建一种配置,其中每个节点的本地和远程磁盘池中的磁盘数相同。
存储控制器必须处于维护模式。
如果您的配置不包括 DS460C 磁盘架,则在从工厂收到磁盘时,如果磁盘已正确分配,则无需执行此任务。
|
|
池 0 始终包含与拥有磁盘的存储系统位于同一站点的磁盘。 池 1 中的磁盘始终位于拥有这些磁盘的存储系统的远程位置。 |
如果您的配置包含 DS460C 磁盘架,则应按照以下准则为每个 12 磁盘抽盒手动分配磁盘:
在抽盒中分配这些磁盘 … |
到此节点和池 … |
0 - 2 |
本地节点的池 0 |
3 - 5 |
HA 配对节点的池 0 |
6 - 8. |
本地节点的池 1 的 DR 配对节点 |
9 - 11 |
HA 配对节点池 1 的 DR 配对节点 |
此磁盘分配模式可确保在抽盒脱机时聚合受到的影响最小。
-
如果尚未启动,请将每个系统启动至维护模式。
-
将磁盘架分配给位于第一个站点(站点 A )的节点:
与节点位于同一站点的磁盘架分配给池 0 ,而位于配对站点的磁盘架分配给池 1 。
您应为每个池分配相同数量的磁盘架。
-
在第一个节点上,系统地将本地磁盘架分配给池 0 ,并将远程磁盘架分配给池 1 :
dassign -shelf local-switch-name : shelf-name.port -p pool如果存储控制器 Controller_A_1 有四个磁盘架,则问题描述以下命令:
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1
-
对本地站点的第二个节点重复此过程,系统地将本地磁盘架分配给池 0 ,并将远程磁盘架分配给池 1 :
dassign -shelf local-switch-name : shelf-name.port -p pool如果存储控制器 Controller_A_2 有四个磁盘架,则问题描述以下命令:
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1
-
-
将磁盘架分配给位于第二个站点(站点 B )的节点:
与节点位于同一站点的磁盘架分配给池 0 ,而位于配对站点的磁盘架分配给池 1 。
您应为每个池分配相同数量的磁盘架。
-
在远程站点的第一个节点上,系统地将本地磁盘架分配给池 0 ,并将远程磁盘架分配给池 1 :
dassign -shelf local-switch-namelf-name -p pool如果存储控制器 Controller_B_1 有四个磁盘架,则问题描述以下命令:
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1
-
对远程站点的第二个节点重复此过程,系统地将其本地磁盘架分配给池 0 ,并将其远程磁盘架分配给池 1 :
dassign -shelf shelf-name -p pool如果存储控制器 Controller_B_2 有四个磁盘架,则问题描述以下命令:
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1
-
-
确认磁盘架分配:
s存储显示磁盘架 -
退出维护模式:
halt -
显示启动菜单:
boot_ontap 菜单 -
在每个节点上,选择选项 * 。 4* 以初始化所有磁盘。
在 AFF 系统中分配磁盘所有权
如果在具有镜像聚合的配置中使用 AFF 系统,并且节点未正确分配磁盘( SSD ),则应将每个磁盘架上一半的磁盘分配给一个本地节点,另一半磁盘分配给其 HA 配对节点。您应创建一种配置,使每个节点在其本地和远程磁盘池中具有相同数量的磁盘。
存储控制器必须处于维护模式。
这不适用于具有未镜像聚合,主动 / 被动配置或本地和远程池中磁盘数量不等的配置。
如果从工厂收到磁盘时已正确分配磁盘,则不需要执行此任务。
|
|
池 0 始终包含与拥有磁盘的存储系统位于同一站点的磁盘。 池 1 中的磁盘始终位于拥有这些磁盘的存储系统的远程位置。 |
-
如果尚未启动,请将每个系统启动至维护模式。
-
将磁盘分配给位于第一个站点(站点 A )的节点:
您应为每个池分配相同数量的磁盘。
-
在第一个节点上,系统地将每个磁盘架上一半的磁盘分配给池 0 ,而将另一半磁盘分配给 HA 配对节点的池 0 :
disk assign -shelf <shelf-name> -p <pool> -n <number-of-disks>如果存储控制器 Controller_A_1 有四个磁盘架,每个磁盘架具有 8 个 SSD ,则您可以问题描述执行以下命令:
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1 -n 4
-
对本地站点的第二个节点重复此过程,系统地将每个磁盘架上一半的磁盘分配给池 1 ,另一半磁盘分配给 HA 配对节点的池 1 :
dassign -disk disk-name -p pool如果存储控制器 Controller_A_1 有四个磁盘架,每个磁盘架具有 8 个 SSD ,则您可以问题描述执行以下命令:
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4
-
-
将磁盘分配给位于第二个站点(站点 B )的节点:
您应为每个池分配相同数量的磁盘。
-
在远程站点的第一个节点上,系统地将每个磁盘架上一半的磁盘分配给池 0 ,而将另一半磁盘分配给 HA 配对节点的池 0 :
dassign -disk disk-name -p pool如果存储控制器 Controller_B_1 有四个磁盘架,每个磁盘架具有 8 个 SSD ,则您可以问题描述执行以下命令:
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1 -n 4
-
对远程站点的第二个节点重复此过程,系统地将每个磁盘架上一半的磁盘分配给池 1 ,另一半磁盘分配给 HA 配对节点的池 1 :
dassign -disk disk-name -p pool如果存储控制器 Controller_B_2 有四个磁盘架,每个磁盘架具有 8 个 SSD ,则您可以问题描述执行以下命令:
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1 -n 4
-
-
确认磁盘分配:
storage show disk -
退出维护模式:
halt -
显示启动菜单:
boot_ontap 菜单 -
在每个节点上,选择选项 * 。 4* 以初始化所有磁盘。
验证双节点配置中维护模式下的磁盘分配
在将系统完全启动到 ONTAP 之前,您可以选择将系统启动到维护模式并验证节点上的磁盘分配。应分配磁盘以创建完全对称的配置,其中两个站点都拥有自己的磁盘架并提供数据,其中每个节点和每个池都分配了相同数量的镜像磁盘。
系统必须处于维护模式。
新的 MetroCluster 系统在发货前已完成磁盘分配。
下表显示了 MetroCluster 配置的池分配示例。磁盘会按磁盘架分配给池。
磁盘架(示例名称) … |
在站点 … |
属于 … |
并分配给该节点的 … |
磁盘架 1 ( shelf_A_1_1 ) |
站点 A |
节点 A 1. |
池 0 |
磁盘架 2 ( shelf_A_1_3 ) |
|||
磁盘架 3 ( shelf_B_1_1 ) |
节点 B 1 |
池 1 |
|
磁盘架 4 ( shelf_B_1_3 ) |
|||
磁盘架 9 ( shelf_B_1_2 ) |
站点 B |
节点 B 1 |
池 0 |
磁盘架 10 ( shelf_B_1_4 ) |
|||
磁盘架 11 ( shelf_A_1_2 ) |
节点 A 1. |
池 1 |
|
磁盘架 12 ( shelf_A_1_4 ) |
如果您的配置包含 DS460C 磁盘架,则应按照以下准则为每个 12 磁盘抽盒手动分配磁盘:
在抽盒中分配这些磁盘 … |
到此节点和池 … |
1 - 6 |
本地节点的池 0 |
7 - 12 |
DR 配对节点的池 1 |
此磁盘分配模式可最大限度地减少抽盒脱机对聚合的影响。
-
如果系统是从工厂收到的,请确认磁盘架分配:
d展示– v -
如有必要,您可以使用 disk assign 命令明确地将所连接磁盘架上的磁盘分配给相应的池。
与节点位于同一站点的磁盘架分配给池 0 ,而位于配对站点的磁盘架分配给池 1 。您应为每个池分配相同数量的磁盘架。
-
如果尚未启动,请将每个系统启动至维护模式。
-
在站点 A 的节点上,系统地将本地磁盘架分配给池 0 ,并将远程磁盘架分配给池 1 :
dassign -shelf disk_shelf_name -p pool如果存储控制器 node_A_1 有四个磁盘架,则问题描述以下命令:
*> disk assign -shelf shelf_A_1_1 -p 0 *> disk assign -shelf shelf_A_1_3 -p 0 *> disk assign -shelf shelf_A_1_2 -p 1 *> disk assign -shelf shelf_A_1_4 -p 1
-
在远程站点(站点 B )的节点上,系统地将本地磁盘架分配给池 0 ,并将远程磁盘架分配给池 1 :
dassign -shelf disk_shelf_name -p pool如果存储控制器 node_B_1 有四个磁盘架,则问题描述以下命令:
*> disk assign -shelf shelf_B_1_2 -p 0 *> disk assign -shelf shelf_B_1_4 -p 0 *> disk assign -shelf shelf_B_1_1 -p 1 *> disk assign -shelf shelf_B_1_3 -p 1
-
显示每个磁盘的磁盘架 ID 和托架:
d展示– v
-
设置 ONTAP
您必须在每个控制器模块上设置 ONTAP 。
如果需要通过网络启动新控制器,请参见 "通过网络启动新控制器模块" 在 _RAID MetroCluster 升级,过渡和扩展指南中。
在双节点 MetroCluster 配置中设置 ONTAP
在双节点 MetroCluster 配置中,您必须在每个集群上启动节点,退出集群设置向导,然后使用 cluster setup 命令将节点配置为单节点集群。
您不能事先配置服务处理器。
此任务适用于使用原生 NetApp 存储的双节点 MetroCluster 配置。
必须对 MetroCluster 配置中的两个集群执行此任务。
有关设置ONTAP 的更多常规信息、请参见 "设置 ONTAP"。
-
打开第一个节点的电源。
您必须在灾难恢复( DR )站点的节点上重复此步骤。 节点将启动,然后在控制台上启动集群设置向导,通知您 AutoSupport 将自动启用。
::> Welcome to the cluster setup wizard. You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the cluster setup wizard. Any changes you made before quitting will be saved. You can return to cluster setup at any time by typing "cluster setup". To accept a default or omit a question, do not enter a value. This system will send event messages and periodic reports to NetApp Technical Support. To disable this feature, enter autosupport modify -support disable within 24 hours. Enabling AutoSupport can significantly speed problem determination and resolution, should a problem occur on your system. For further information on AutoSupport, see: http://support.netapp.com/autosupport/ Type yes to confirm and continue {yes}: yes Enter the node management interface port [e0M]: Enter the node management interface IP address [10.101.01.01]: Enter the node management interface netmask [101.010.101.0]: Enter the node management interface default gateway [10.101.01.0]: Do you want to create a new cluster or join an existing cluster? {create, join}: -
创建新集群:
创建 -
选择是否将此节点用作单节点集群。
Do you intend for this node to be used as a single node cluster? {yes, no} [yes]: -
按 Enter 接受系统默认值
yes,或者键入no并按 Enter 输入您自己的值。 -
按照提示完成 * 集群设置 * 向导,按 Enter 接受默认值,或者键入您自己的值,然后按 Enter 。
默认值将根据您的平台和网络配置自动确定。
-
完成 * 集群设置 * 向导并退出后,请验证集群是否处于活动状态且第一个节点是否运行正常: `
cluster show以下示例显示了一个集群,其中第一个节点( cluster1-01 )运行状况良好且符合参与条件:
cluster1::> cluster show Node Health Eligibility --------------------- ------- ------------ cluster1-01 true true
如果需要更改为管理 SVM 或节点 SVM 输入的任何设置,您可以使用 cluster setup 命令访问集群设置向导。
在八节点或四节点 MetroCluster 配置中设置 ONTAP
启动每个节点后,系统会提示您运行 System Setup 工具来执行基本节点和集群配置。配置集群后,您可以返回到 ONTAP 命令行界面以创建聚合并创建 MetroCluster 配置。
您必须已为 MetroCluster 配置布线。
此任务适用于使用原生 NetApp 存储的八节点或四节点 MetroCluster 配置。
新的 MetroCluster 系统已预先配置;您无需执行这些步骤。但是,您应配置 AutoSupport 工具。
必须对 MetroCluster 配置中的两个集群执行此任务。
此操作步骤使用系统设置工具。如果需要,可以改用 CLI 集群设置向导。
-
如果尚未启动,请启动每个节点并让其完全启动。
如果系统处于维护模式,请使用问题描述 halt 命令退出维护模式,然后问题描述从 LOADER 提示符处运行以下命令:
boot_ontap输出应类似于以下内容:
Welcome to node setup You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the setup wizard. Any changes you made before quitting will be saved. To accept a default or omit a question, do not enter a value. . . .
-
按照系统提供的说明启用 AutoSupport 工具。
-
响应提示以配置节点管理接口。
这些提示类似于以下内容:
Enter the node management interface port: [e0M]: Enter the node management interface IP address: 10.228.160.229 Enter the node management interface netmask: 225.225.252.0 Enter the node management interface default gateway: 10.228.160.1
-
确认节点已配置为高可用性模式:
s存储故障转移 show -fields mode如果不是,则必须在每个节点上执行问题描述以下命令并重新启动节点:
storage failover modify -mode ha -node localhost此命令可配置高可用性模式,但不会启用存储故障转移。如果稍后在配置过程中执行 MetroCluster 配置,则会自动启用存储故障转移。
-
确认已将四个端口配置为集群互连:
network port show以下示例显示了 cluster_A 的输出:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ node_A_1 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 node_A_2 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
如果要创建双节点无交换机集群(没有集群互连交换机的集群),请启用无交换机集群网络模式:
-
更改为高级权限级别:
set -privilege advanced
系统提示您继续进入高级模式时,您可以回答
y。此时将显示高级模式提示符( * > )。-
启用无交换机集群模式:
network options switchless-cluster modify -enabled true -
返回到管理权限级别:
set -privilege admin
-
-
按照首次启动后系统控制台上显示的信息启动 System Setup 工具。
-
使用 System Setup 工具配置每个节点并创建集群,但不创建聚合。
您可以在稍后的任务中创建镜像聚合。
返回到 ONTAP 命令行界面,并通过执行以下任务完成 MetroCluster 配置。
将集群配置为 MetroCluster 配置
您必须对集群建立对等关系,镜像根聚合,创建镜像数据聚合,然后问题描述命令以实施 MetroCluster 操作。
运行前 metrocluster configure、未启用HA模式和DR镜像、您可能会看到与此预期行为相关的错误消息。稍后在运行命令时启用HA模式和DR镜像 metrocluster configure 以实施配置。
为集群建立对等关系
MetroCluster 配置中的集群必须处于对等关系中,以便它们可以彼此通信并执行对 MetroCluster 灾难恢复至关重要的数据镜像。
配置集群间 LIF
您必须在用于 MetroCluster 配对集群之间通信的端口上创建集群间 LIF 。您可以使用专用端口或也具有数据流量的端口。
在专用端口上配置集群间 LIF
您可以在专用端口上配置集群间 LIF 。这样做通常会增加复制流量的可用带宽。
-
列出集群中的端口:
network port show有关完整的命令语法,请参见手册页。
以下示例显示了 "cluster01" 中的网络端口:
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
确定哪些端口可专用于集群间通信:
network interface show -fields home-port , curr-port有关完整的命令语法,请参见手册页。
以下示例显示尚未为端口 e0e 和 e0f 分配 LIF :
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
为专用端口创建故障转移组:
network interface failover-groups create -vserver system_svm -failover-group failover_group -targets physical_or_logical_ports以下示例将端口 "e0e" 和 "e0f" 分配给系统 "SVMcluster01" 上的故障转移组 intercluster01 :
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
验证是否已创建故障转移组:
network interface failover-groups show有关完整的命令语法,请参见手册页。
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
在系统 SVM 上创建集群间 LIF 并将其分配给故障转移组。
ONTAP 9.6 及更高版本network interface create -vserver system_svm -lif LIF_name -service-policy default-intercluster -home-node node-home-port port -address port_ip -netmask netmask -failover-group failover_groupONTAP 9.5 及更早版本network interface create -vserver system_svm -lif LIF_name -role intercluster -home-node node-home-port port -address port_ip -netmask netmask -failover-group failover_group有关完整的命令语法,请参见手册页。
以下示例将在故障转移组 "intercluster01" 中创建集群间 LIF "cluster01_icl01" 和 "cluster01_icl02" :
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
验证是否已创建集群间 LIF :
ONTAP 9.6 及更高版本运行命令:
network interface show -service-policy default-interclusterONTAP 9.5 及更早版本运行命令:
network interface show -role intercluster有关完整的命令语法,请参见手册页。
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
验证集群间 LIF 是否冗余:
ONTAP 9.6 及更高版本运行命令:
network interface show -service-policy default-intercluster -failoverONTAP 9.5 及更早版本运行命令:
network interface show -role intercluster -failover有关完整的命令语法,请参见手册页。
以下示例显示 SVM "e0e" 端口上的集群间 LIF"cluster01_icl01" 和 "cluster01_icl02" 将故障转移到 "e0f" 端口。
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
在确定使用专用端口进行集群间复制是否是正确的集群间网络解决方案时,您应考虑 LAN 类型,可用 WAN 带宽,复制间隔,更改率和端口数等配置和要求。
在共享数据端口上配置集群间 LIF
您可以在与数据网络共享的端口上配置集群间 LIF 。这样可以减少集群间网络连接所需的端口数量。
-
列出集群中的端口:
network port show有关完整的命令语法,请参见手册页。
以下示例显示了 cluster01 中的网络端口:
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
在系统 SVM 上创建集群间 LIF :
ONTAP 9.6 及更高版本运行命令:
network interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmaskONTAP 9.5 及更早版本运行命令:
network interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmask有关完整的命令语法,请参见手册页。以下示例将创建集群间 LIF cluster01_icl01 和 cluster01_icl02 :
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
验证是否已创建集群间 LIF :
ONTAP 9.6 及更高版本运行命令:
network interface show -service-policy default-interclusterONTAP 9.5 及更早版本运行命令:
network interface show -role intercluster有关完整的命令语法,请参见手册页。
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
验证集群间 LIF 是否冗余:
ONTAP 9.6 及更高版本运行命令:
network interface show –service-policy default-intercluster -failoverONTAP 9.5 及更早版本运行命令:
network interface show -role intercluster -failover有关完整的命令语法,请参见手册页。
以下示例显示 "e0c" 端口上的集群间 LIF"cluster01_icl01" 和 "cluster01_icl02" 将故障转移到 "e0d" 端口。
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
创建集群对等关系
您必须在 MetroCluster 集群之间创建集群对等关系。
您可以使用 cluster peer create 命令在本地和远程集群之间创建对等关系。创建对等关系后,您可以在远程集群上运行 cluster peer create ,以便向本地集群进行身份验证。
-
您必须已在要建立对等关系的集群中的每个节点上创建集群间 LIF 。
-
集群必须运行 ONTAP 9.3 或更高版本。
-
在目标集群上,创建与源集群的对等关系:
cluster peer create -generate-passphrase -offer-expiration MM/DD/YYYY HH : MM : SS|1…7 天 |1…168 小时 _ -peer-Addrs _peer_LIF_IP -IPspace _IPspace _IPspace _如果同时指定 ` generate-passphrase` 和 ` -peer-addrs` ,则只有在 ` -peer-addrs` 中指定了集群间 LIF 的集群才能使用生成的密码。
如果您不使用自定义 IP 空间,则可以忽略 ` -ipspace` 选项。有关完整的命令语法,请参见手册页。
以下示例将在未指定的远程集群上创建集群对等关系:
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
在源集群上,将源集群身份验证到目标集群:
cluster peer create -peer-addrs peer_LIF_ips -ipspace IPspace有关完整的命令语法,请参见手册页。
以下示例将本地集群通过集群间 LIF IP 地址 "192.140.112.101" 和 "192.140.112.102" 的远程集群进行身份验证:
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.出现提示时,输入对等关系的密码短语。
-
验证是否已创建集群对等关系:
cluster peer show -instancecluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster2 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Address Family of Relationship: ipv4 Authentication Status Administrative: no-authentication Authentication Status Operational: absent Last Update Time: 02/05 21:05:41 IPspace for the Relationship: Default -
检查对等关系中节点的连接和状态:
集群对等运行状况显示cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
创建集群对等关系( ONTAP 9.2 及更早版本)
您可以使用 cluster peer create 命令在本地和远程集群之间启动对等关系请求。在本地集群请求建立对等关系后,您可以在远程集群上运行 cluster peer create 来接受此关系。
-
您必须已在要建立对等关系的集群中的每个节点上创建集群间 LIF 。
-
集群管理员必须已就每个集群用于向另一集群进行身份验证的密码短语达成一致。
-
在数据保护目标集群上,与数据保护源集群创建对等关系:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace _ipspace_s如果您不使用自定义 IP 空间,则可以忽略 -IPSpace 选项。有关完整的命令语法,请参见手册页。
以下示例将与集群间 LIF IP 地址为 "192.168.2.201" 和 "192.168.2.202" 的远程集群创建集群对等关系:
cluster02::> cluster peer create -peer-addrs 192.168.2.201,192.168.2.202 Enter the passphrase: Please enter the passphrase again:
出现提示时,输入对等关系的密码短语。
-
在数据保护源集群上,对目标集群的源集群进行身份验证:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace _ipspace_s有关完整的命令语法,请参见手册页。
以下示例将本地集群通过集群间 LIF IP 地址 192.140.112.203 和 192.140.112.204 进行身份验证:
cluster01::> cluster peer create -peer-addrs 192.168.2.203,192.168.2.204 Please confirm the passphrase: Please confirm the passphrase again:
出现提示时,输入对等关系的密码短语。
-
验证是否已创建集群对等关系:
cluster peer show – instance有关完整的命令语法,请参见手册页。
cluster01::> cluster peer show –instance Peer Cluster Name: cluster01 Remote Intercluster Addresses: 192.168.2.201,192.168.2.202 Availability: Available Remote Cluster Name: cluster02 Active IP Addresses: 192.168.2.201,192.168.2.202 Cluster Serial Number: 1-80-000013
-
检查对等关系中节点的连接和状态:
集群对等运行状况显示`有关完整的命令语法,请参见手册页。
cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
镜像根聚合
您必须镜像根聚合以提供数据保护。
默认情况下,根聚合创建为 RAID-DP 类型的聚合。您可以将根聚合从 RAID-DP 更改为 RAID4 类型的聚合。以下命令修改 RAID4 类型聚合的根聚合:
storage aggregate modify –aggregate aggr_name -raidtype raid4
|
|
在非 ADP 系统上,可以在镜像聚合之前或之后将聚合的 RAID 类型从默认 RAID-DP 修改为 RAID4 。 |
-
镜像根聚合:
s存储聚合镜像 aggr_name以下命令镜像 controller_A_1 的根聚合:
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
此操作会镜像聚合,因此它包含一个本地丛和一个位于远程 MetroCluster 站点的远程丛。
-
对 MetroCluster 配置中的每个节点重复上述步骤。
在每个节点上创建镜像数据聚合
您必须在 DR 组中的每个节点上创建镜像数据聚合。
-
您应了解新聚合将使用哪些驱动器。
-
如果系统中有多种驱动器类型(异构存储),则应了解如何确保选择正确的驱动器类型。
-
驱动器由特定节点拥有;创建聚合时,该聚合中的所有驱动器都必须由同一节点拥有,该节点将成为该聚合的主节点。
-
聚合名称应符合您在规划 MetroCluster 配置时确定的命名方案。请参见 "磁盘和聚合管理"。
-
聚合名称必须在 MetroCluster 站点中唯一。这意味着您不能在站点 A 和站点 B 上具有相同名称的两个不同聚合。
-
显示可用备件列表:
storage disk show -spare -owner node_name -
使用 storage aggregate create -mirror true 命令创建聚合。
如果您已通过集群管理界面登录到集群,则可以在集群中的任何节点上创建聚合。要确保在特定节点上创建聚合,请使用 ` -node` 参数或指定该节点所拥有的驱动器。
您可以指定以下选项:
-
聚合的主节点(即在正常操作下拥有聚合的节点)
-
要添加到聚合的特定驱动器的列表
-
要包含的驱动器数量
在最低支持配置中,可用驱动器数量有限,您必须使用 force-Small-aggregate选项创建三磁盘 RAID-DP 聚合。-
要用于聚合的校验和模式
-
要使用的驱动器类型
-
要使用的驱动器大小
-
要使用的驱动器速度
-
聚合上 RAID 组的 RAID 类型
-
可包含在 RAID 组中的最大驱动器数
-
是否允许使用 RPM 不同的驱动器
有关这些选项的详细信息,请参见
storage aggregate create手册页。以下命令将创建包含 10 个磁盘的镜像聚合:
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
验证新聚合的 RAID 组和驱动器:
storage aggregate show-status -aggregate aggregate-name
创建未镜像的数据聚合
您可以选择为不需要 MetroCluster 配置提供的冗余镜像的数据创建未镜像数据聚合。
-
确认您知道新聚合中将使用哪些驱动器。
-
如果系统中有多种驱动器类型(异构存储),则应了解如何验证是否选择了正确的驱动器类型。

|
在 MetroCluster FC 配置中,只有当聚合中的远程磁盘可访问时,未镜像聚合才会在切换后联机。如果 ISL 发生故障,本地节点可能无法访问未镜像远程磁盘中的数据。聚合故障可能会导致本地节点重新启动。 |
-
驱动器由特定节点拥有;创建聚合时,该聚合中的所有驱动器都必须由同一节点拥有,该节点将成为该聚合的主节点。
|
|
未镜像聚合必须位于其所属节点的本地。 |
-
聚合名称应符合您在规划 MetroCluster 配置时确定的命名方案。
-
Disks and aggregates management 包含有关镜像聚合的详细信息。
-
显示可用备件列表:
storage disk show -spare -owner node_name -
创建聚合:
s存储聚合创建如果您已通过集群管理界面登录到集群,则可以在集群中的任何节点上创建聚合。要验证是否已在特定节点上创建聚合,应使用 ` -node` 参数或指定该节点所拥有的驱动器。
您可以指定以下选项:
-
聚合的主节点(即在正常操作下拥有聚合的节点)
-
要添加到聚合的特定驱动器的列表
-
要包含的驱动器数量
-
要用于聚合的校验和模式
-
要使用的驱动器类型
-
要使用的驱动器大小
-
要使用的驱动器速度
-
聚合上 RAID 组的 RAID 类型
-
可包含在 RAID 组中的最大驱动器数
-
是否允许使用 RPM 不同的驱动器
有关这些选项的详细信息,请参见 storage aggregate create 手册页。
以下命令将创建一个包含 10 个磁盘的未镜像聚合:
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
验证新聚合的 RAID 组和驱动器:
storage aggregate show-status -aggregate aggregate-name
实施 MetroCluster 配置
要在 MetroCluster 配置中启动数据保护,必须运行 MetroCluster configure 命令。
-
每个集群上应至少有两个非根镜像数据聚合。
其他数据聚合可以是镜像聚合,也可以是未镜像聚合。
您可以使用
storage aggregate show命令进行验证。
如果要使用单个镜像数据聚合,请参见 第 1 步 有关说明,请参见。 -
控制器和机箱的 ha-config 状态必须为 "mcc" 。
您可以在任何节点上问题描述一次 MetroCluster configure 命令,以启用 MetroCluster 配置。您无需在每个站点或节点上对命令执行问题描述,也无需选择对哪个节点或站点执行问题描述命令。
MetroCluster configure 命令会自动将两个集群中每个集群中系统 ID 最低的两个节点配对,作为灾难恢复( DR )配对节点。在四节点 MetroCluster 配置中,存在两个 DR 配对节点对。第二个 DR 对是从系统 ID 较高的两个节点创建的。
|
|
在运行命令`MetroCluster configure`之前、您必须*不*配置板载密钥管理器(OKM)或外部密钥管理。 |
-
【第 1 步 _aggr]] 按照以下格式配置 MetroCluster :
如果您的 MetroCluster 配置 …
然后执行此操作 …
多个数据聚合
从任何节点的提示符处,配置 MetroCluster :
MetroCluster configure node-name一个镜像数据聚合
-
在任何节点的提示符处,更改为高级权限级别:
set -privilege advanced当系统提示您继续进入高级模式且您看到高级模式提示符( * > )时,您需要使用
y进行响应。 -
使用 ` -allow-with-one-aggregate true` 参数配置 MetroCluster :
MetroCluster configure -allow-with-one-aggregate true node-name -
返回到管理权限级别:
set -privilege admin
最佳实践是具有多个数据聚合。如果第一个 DR 组只有一个聚合,而您要添加一个具有一个聚合的 DR 组,则必须将元数据卷从单个数据聚合中移出。有关此操作步骤的详细信息,请参见 "在 MetroCluster 配置中移动元数据卷"。 以下命令将在包含 controller_A_1 的 DR 组中的所有节点上启用 MetroCluster 配置:
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
验证站点 A 上的网络连接状态:
network port show以下示例显示了四节点 MetroCluster 配置中的网络端口使用情况:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
从 MetroCluster 配置中的两个站点验证 MetroCluster 配置。
-
从站点 A 验证配置:
MetroCluster showcluster_A::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
从站点 B 验证配置:
MetroCluster show
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
在 ONTAP 软件上配置帧的按顺序交付或无序交付
您必须根据光纤通道( FC )交换机配置来配置帧的按顺序交付( IOD )或无序交付( OOD )。
如果为 FC 交换机配置了 IOD ,则必须为 ONTAP 软件配置 IOD 。同样,如果为 FC 交换机配置了 OOD ,则必须为 ONTAP 配置 OOD 。
|
|
要更改配置、必须重新启动控制器。 |
-
将 ONTAP 配置为运行帧的 IOD 或 OOD 。
-
默认情况下, ONTAP 中会启用帧的 IOD 。要检查配置详细信息,请执行以下操作:
-
进入高级模式:
set advanced -
验证设置:
MetroCluster 互连适配器 show
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
-
要配置帧的 OOD ,必须对每个节点执行以下步骤:
-
进入高级模式:
set advanced -
验证 MetroCluster 配置设置:
MetroCluster 互连适配器 showmcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
在节点
mCC4-B1和节点mCC4-B2上启用 OOD :MetroCluster 互连适配器 modify -node node_name -is-ood-enabled true
mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b1 -is-ood-enabled true mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b2 -is-ood-enabled true
-
通过双向执行高可用性(HA)接管来重新启动控制器。
-
验证设置:
MetroCluster 互连适配器 show
-
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up true 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up true 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up true 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up true 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
在 MetroCluster FC 配置中配置 SNMPv3
交换机和 ONTAP 系统上的身份验证和隐私协议必须相同。
ONTAP 目前支持使用 AES-128 进行隐私保护(加密),使用 SHA-256 进行身份验证。
|
|
|
-
在控制器提示符处为每个交换机创建一个 SNMP 用户:
s安全性登录 createController_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10.10.10.10
-
根据需要在您的站点上响应以下提示:
对于 EngineID,按 ENTER 分配默认值。 Enter the authoritative entity's EngineID [remote EngineID]: Which authentication protocol do you want to choose (none, md5, sha, sha2-256) [none]: sha Enter the authentication protocol password (minimum 8 characters long): Enter the authentication protocol password again: Which privacy protocol do you want to choose (none, des, aes128) [none]: aes128 Enter privacy protocol password (minimum 8 characters long): Enter privacy protocol password again:
可以将同一用户名添加到具有不同 IP 地址的不同交换机。 -
为其余交换机创建 SNMP 用户。
以下示例显示了如何为 IP 地址为 10.10.10.11 的交换机创建用户名。
Controller_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10. 10.10.11
-
检查每个交换机是否有一个登录条目:
ssecurity login showController_A_1::> security login show -user-or-group-name snmpv3user -fields remote-switch-ipaddress vserver user-or-group-name application authentication-method remote-switch-ipaddress ------------ ------------------ ----------- --------------------- ----------------------- node_A_1 SVM 1 snmpv3user snmp usm 10.10.10.10 node_A_1 SVM 2 snmpv3user snmp usm 10.10.10.11 node_A_1 SVM 3 snmpv3user snmp usm 10.10.10.12 node_A_1 SVM 4 snmpv3user snmp usm 10.10.10.13 4 entries were displayed.
-
从交换机提示符处为交换机配置 SNMPv3 :
Brocade 交换机(FOS 9.x)snmpconfig --add snmpv3 -index <index> -user <user_name> -groupname <rw/ro> -auth_proto <auth_protocol> -auth_passwd <auth_password> -priv_proto <priv_protocol> -priv_passwd <priv_password>Brocade交换机(FOS 8.x 及更早版本)snmpconfig —设置 SNMPv3该示例显示如何配置只读用户。如果需要,您可以调整 RW 用户。如果需要 RO 访问权限,请在“用户 (ro):”后指定“snmpv3user”。
Switch-A1:admin> snmpconfig --set snmpv3 SNMP Informs Enabled (true, t, false, f): [false] true SNMPv3 user configuration(snmp user not configured in FOS user database will have physical AD and admin role as the default): User (rw): [snmpadmin1] Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [3] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [2] Engine ID: [00:00:00:00:00:00:00:00:00] User (ro): [snmpuser2] snmpv3user Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [2] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [3]
Cisco switchessnmp-server user <user_name> auth [md5/sha/sha-256] <auth_password> priv (aes-128) <priv_password>
您还应在未使用的帐户上设置密码,以保护这些帐户的安全,并使用 ONTAP 版本中提供的最佳加密方法。 -
根据需要在站点上的其余交换机用户上配置加密和密码。
配置 MetroCluster 组件以进行运行状况监控
在监控 MetroCluster 配置中的组件之前,必须执行一些特殊的配置步骤。
|
|
为了提高安全性、NetApp建议您配置SNMPv2或SNMPv3以监控交换机运行状况。 |
这些任务仅适用于具有 FC-SAS 网桥的系统。
从 Fabric OS 9.0.1 开始,Brocade 交换机上的运行状况监控不支持 SNMPv2,必须改用 SNMPv3。如果使用 SNMPv3,则必须在 ONTAP 中配置 SNMPv3,然后再继续执行以下部分。有关更多详细信息,请参见在 MetroCluster FC 配置中配置 SNMPv3。
|
|
|
NetApp仅支持使用以下工具监控MetroCluster FC配置中的组件:
-
Brocade Network Advisor ( BNA )
-
Brocade SANNAV
-
Active IQ Config Advisor
-
NetApp运行状况监控(ONTAP)
-
MetroCluster数据收集器(MC_DC)
配置 MetroCluster FC 交换机以进行运行状况监控
在光纤连接的 MetroCluster 配置中,您必须执行一些额外的配置步骤来监控 FC 交换机。
|
|
从ONTAP 9.8开始,此 storage switch`命令将替换为 `system switch fibre-channel。以下步骤显示了 `storage switch`命令、但如果您运行的是ONTAP 9.8或更高版本、 `system switch fibre-channel`则首选使用命令。
|
-
将具有 IP 地址的交换机添加到每个 MetroCluster 节点:
您运行的命令取决于您使用的是SNMPv2还是SNMPv3。
使用SNMPv3添加交换机:storage switch add -address <ip_adddress> -snmp-version SNMPv3 -snmp-community-or-username <SNMP_user_configured_on_the_switch>使用SNMPv2添加交换机:s存储交换机 add -address ipaddress必须对 MetroCluster 配置中的所有四个交换机重复执行此命令。
运行状况监控支持 Brocade 7840 FC 交换机和所有警报,但 NoISLPresent_Alert 除外 以下示例显示了用于添加 IP 地址为 10.10.10.10 的交换机的命令:
controller_A_1::> storage switch add -address 10.10.10.10
-
验证是否已正确配置所有交换机:
s存储开关显示由于轮询间隔为 15 分钟,可能需要长达 15 分钟才能反映所有数据。
以下示例显示了用于验证是否已配置 MetroCluster FC 交换机的命令:
controller_A_1::> storage switch show Fabric Switch Name Vendor Model Switch WWN Status ---------------- --------------- ------- ------------ ---------------- ------ 1000000533a9e7a6 brcd6505-fcs40 Brocade Brocade6505 1000000533a9e7a6 OK 1000000533a9e7a6 brcd6505-fcs42 Brocade Brocade6505 1000000533d3660a OK 1000000533ed94d1 brcd6510-fcs44 Brocade Brocade6510 1000000533eda031 OK 1000000533ed94d1 brcd6510-fcs45 Brocade Brocade6510 1000000533ed94d1 OK 4 entries were displayed. controller_A_1::>
如果显示了交换机的全球通用名称( WWN ),则 ONTAP 运行状况监控器可以联系并监控 FC 交换机。
配置 FC-SAS 网桥以进行运行状况监控
在运行 ONTAP 9.8 之前版本的系统中,您必须执行一些特殊的配置步骤来监控 MetroCluster 配置中的 FC-SAS 网桥。
-
FibreBridge 网桥不支持第三方 SNMP 监控工具。
-
从 ONTAP 9.8 开始,默认情况下, FC-SAS 网桥通过带内连接进行监控,不需要进行其他配置。
|
|
从 ONTAP 9.8 开始, storage bridge 命令将替换为 ssystem bridge 。以下步骤显示了 storage bridge 命令,但如果您运行的是 ONTAP 9.8 或更高版本,则首选使用 ssystem bridge 命令。
|
-
在 ONTAP 集群提示符处,将此网桥添加到运行状况监控:
-
使用适用于您的 ONTAP 版本的命令添加网桥:
ONTAP 版本
命令
9.5 及更高版本
storage bridge add -address 0.0.0.0 -managed-by in-band -name bridge-name9.4 及更早版本
storage bridge add -address bridge-ip-address -name bridge-name -
验证是否已添加此网桥并已正确配置:
storage bridge show由于轮询间隔,可能需要长达 15 分钟才能反映所有数据。如果 "Status" 列中的值为 "ok" ,并且显示了其他信息,例如全球通用名称( WWN ),则 ONTAP 运行状况监控器可以联系并监控网桥。
以下示例显示已配置 FC-SAS 网桥:
controller_A_1::> storage bridge show Bridge Symbolic Name Is Monitored Monitor Status Vendor Model Bridge WWN ------------------ ------------- ------------ -------------- ------ ----------------- ---------- ATTO_10.10.20.10 atto01 true ok Atto FibreBridge 7500N 20000010867038c0 ATTO_10.10.20.11 atto02 true ok Atto FibreBridge 7500N 20000010867033c0 ATTO_10.10.20.12 atto03 true ok Atto FibreBridge 7500N 20000010867030c0 ATTO_10.10.20.13 atto04 true ok Atto FibreBridge 7500N 2000001086703b80 4 entries were displayed controller_A_1::>
-
正在检查 MetroCluster 配置
您可以检查 MetroCluster 配置中的组件和关系是否工作正常。
您应在初始配置后以及对 MetroCluster 配置进行任何更改后执行检查。您还应在协商(计划内)切换或切回操作之前执行检查。
如果在任一集群或同时在这两个集群上短时间内发出 MetroCluster check run 命令两次,则可能发生冲突,并且此命令可能无法收集所有数据。后续的 MetroCluster check show 命令不会显示预期输出。
-
检查配置:
MetroCluster check run此命令作为后台作业运行,可能无法立即完成。
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
显示最近的
MetroCluster check run命令的更详细结果:MetroCluster check aggregate showMetroCluster check cluster showMetroCluster check config-replication showMetroCluster check lif showMetroCluster check node show
MetroCluster check show命令可显示最新的MetroCluster check run命令的结果。在使用MetroCluster check show命令之前,应始终运行MetroCluster check run命令,以使显示的信息为最新信息。以下示例显示了运行正常的四节点 MetroCluster 配置的
MetroCluster check aggregate show命令输出:cluster_A::> metrocluster check aggregate show Last Checked On: 8/5/2014 00:42:58 Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.以下示例显示了运行正常的四节点 MetroCluster 配置的
MetroCluster check cluster show命令输出。它表示集群已准备好在必要时执行协商切换。Last Checked On: 9/13/2017 20:47:04 Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
使用 Config Advisor 检查 MetroCluster 配置错误
您可以访问 NetApp 支持站点并下载 Config Advisor 工具以检查常见配置错误。
Config Advisor 是一款配置验证和运行状况检查工具。您可以将其部署在安全站点和非安全站点上,以便进行数据收集和系统分析。
|
|
对 Config Advisor 的支持是有限的,并且只能联机使用。 |
-
转到 Config Advisor 下载页面并下载此工具。
-
运行 Config Advisor ,查看该工具的输出并按照输出中的建议解决发现的任何问题。
验证本地 HA 操作
如果您使用的是四节点 MetroCluster 配置,则应验证 MetroCluster 配置中本地 HA 对的运行情况。对于双节点配置,不需要执行此操作。
双节点 MetroCluster 配置不包含本地 HA 对,此任务不适用。
此任务中的示例使用标准命名约定:
-
cluster_A
-
controller_A_1
-
controller_A_2
-
-
集群 B
-
controller_B_1
-
controller_B_2
-
-
在 cluster_A 上,双向执行故障转移和交还。
-
确认已启用存储故障转移:
s存储故障转移显示输出应指示两个节点均可进行接管:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed. -
从 controller_A_1 接管 controller_A_2 :
s存储故障转移接管 controller_A_2您可以使用
storage failover show-takeover命令监控接管操作的进度。 -
确认接管已完成:
s存储故障转移显示输出应指示 controller_A_1 处于接管状态,表示它已接管其 HA 配对节点:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ----------------- controller_A_1 controller_A_2 false In takeover controller_A_2 controller_A_1 - Unknown 2 entries were displayed. -
交还 controller_A_2 :
s存储故障转移交还 controller_A_2您可以使用
storage failover show-giveback命令监控交还操作的进度。 -
确认存储故障转移已恢复正常状态:
s存储故障转移显示输出应指示两个节点均可进行接管:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed.-
重复上述子步骤,这次从 controller_A_2 接管 controller_A_1 。
-
-
对 cluster_B 重复上述步骤
验证切换,修复和切回
您应验证 MetroCluster 配置的切换,修复和切回操作。
-
使用中所述的协商切换,修复和切回过程 "从灾难中恢复"。
保护配置备份文件
您可以通过指定一个远程 URL ( HTTP 或 FTP )来为集群配置备份文件提供额外保护,除了本地集群中的默认位置之外,还可以将配置备份文件上传到该远程 URL 。
-
为配置备份文件设置远程目标的 URL :
s系统配置备份设置 modify _url-of-destination_s。 "使用 CLI 进行集群管理" 在 _Manag管理 配置备份 _ 一节下包含追加信息。