

NetApp StorageGRID和大数据分析
 建议更改
建议更改
NetApp StorageGRID用例
NetApp StorageGRID对象存储解决方案可提供可扩展性、数据可用性、安全性和高性能。各种规模和各行各业的组织都在广泛的使用情形中使用StorageGRID S3。让我们来了解一些典型场景:
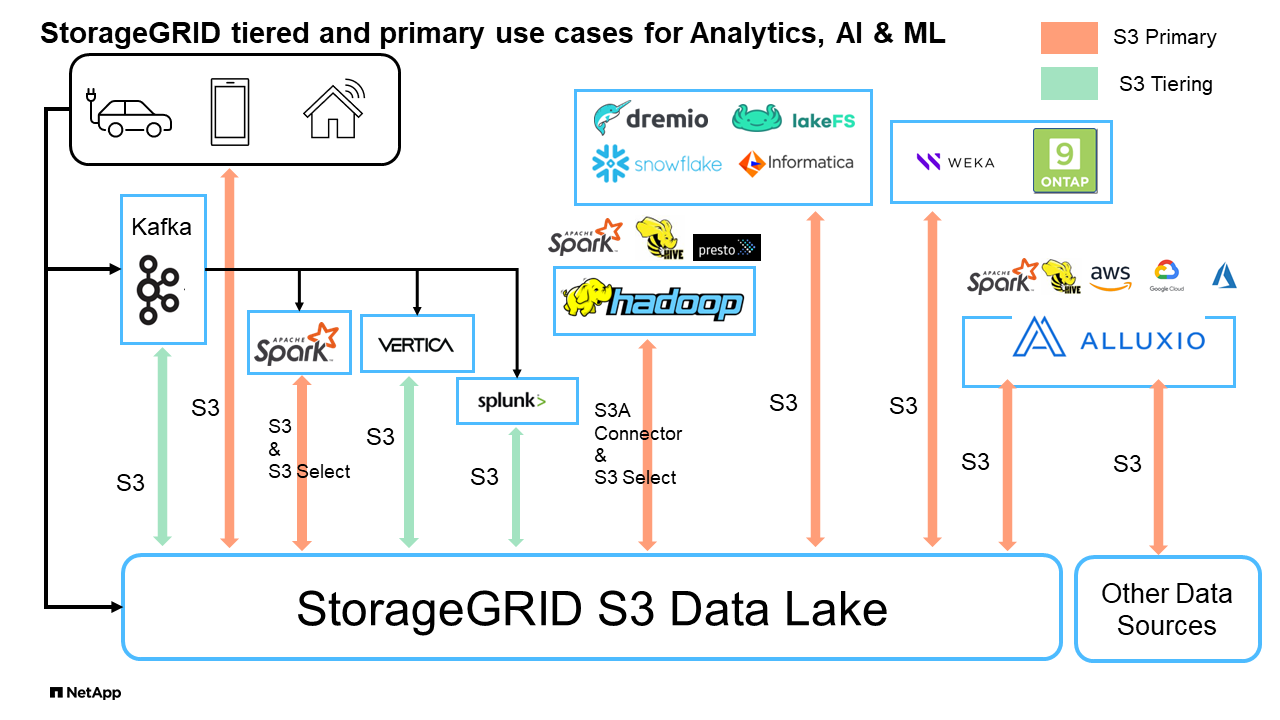
大数据分析: StorageGRID S3常用作数据湖、企业可在其中存储大量结构化和非结构化数据、以便使用Apache Spark、Splunk Smartstore和DREMIO等工具进行分析。
数据分层: NetApp客户使用ONTAP的FabricPool功能在高性能本地层之间自动将数据移动到StorageGRID。在将冷数据保留在低成本对象存储上的同时、将昂贵的闪存存储释放出来、以存储热数据。这样可以最大限度地提高性能并节省成本。
*数据备份和灾难恢复:*企业可以使用StorageGRID S3作为可靠且经济高效的解决方案来备份关键数据并在发生灾难时进行恢复。
应用程序的数据存储: StorageGRID S3可用作应用程序的存储后端,使开发人员能够轻松地存储和检索文件、图像、视频和其他类型的数据。
内容交付: StorageGRID S3可用于存储静态网站内容、媒体文件和软件下载并提供给全球用户、利用StorageGRID的地区分布和全局命名空间实现快速可靠的内容交付。
数据归档: StorageGRID提供不同的存储类型、并支持分层到公共长期低成本存储选项、使其成为出于合规性或历史目的需要保留的数据归档和长期保留的理想解决方案。
对象存储用例
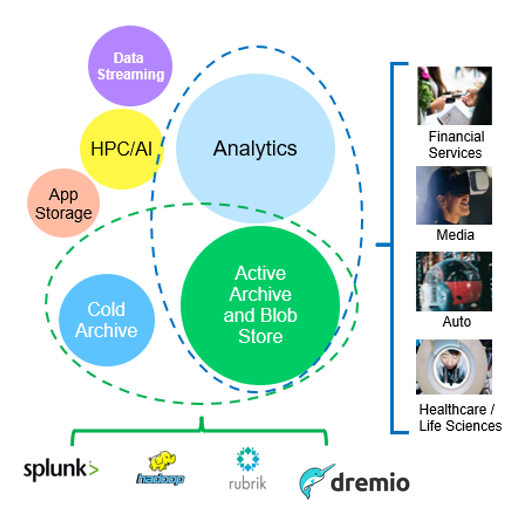
在上述情形中、大数据分析是最热门的使用情形之一、其使用量呈上升趋势。
为什么选择StorageGRID解决数据湖问题?
-
增强协作—利用行业标准API访问实现大规模共享多站点、多租户
-
降低运营成本—通过一个自我修复型自动化横向扩展架构简化运营
-
可扩展性—与传统的Hadoop和数据仓库解决方案不同、StorageGRID S3对象存储可将存储与计算和数据分离、从而使企业能够随着增长扩展存储需求。
-
耐用性和可靠性—StorageGRID的耐用性高达99.9999999%、这意味着存储的数据能够高度抵御数据丢失。它还提供高可用性、确保数据始终可访问。
-
安全性—StorageGRID提供各种安全功能、包括加密、访问控制策略、数据生命周期管理、对象锁定和版本控制、以保护S3存储分段中存储的数据
-
StorageGRID S3数据湖*
《使用S3对象存储对数据仓库和湖屋进行基准测试:比较研究》
本文使用 NetApp StorageGRID 对各种数据仓库和湖仓生态系统进行了全面的基准测试。目标是确定哪个系统在 S3 对象存储方面表现最佳。请参阅此https://hello.dremio.com/wp-apache-iceberg-the-definitive-guide-reg.html["Apache iceberg:权威指南"]以了解有关数据仓库/湖仓架构和表格格式(Parquet 和 Iceberg)的更多信息。
-
基准测试工具- TPC-DS - https://www.tpc.org/tpcds/
-
大数据生态系统
-
VM集群、每个VM具有128 G RAM和24个vCPU、用于系统磁盘的SSD存储
-
采用Hive 3.1.3的Hadoop 3.3.5 (1个名称节点+ 4个数据节点)
-
采用Spark 3.2.0 (1个主服务器+ 4个员工)和Hadoop 3.3.5的Delta Lake
-
d不良 者v25.2 (1名协调员+ 5名执行者)
-
Trino v438 (1名协调员+ 5名工作人员)
-
Starburst v453 (1名协调员+ 5名员工)
-
-
对象存储
-
NetApp® StorageGRID® 11.8(3 x SG6060+1x SG1000负载平衡器)
-
对象保护-2个副本(结果与EC 2+1类似)
-
-
数据库大小为1000 GB
-
对于使用镶木地板格式的每个查询测试、在所有生态系统中禁用了缓存。对于icerberg格式、我们比较了禁用缓存和启用缓存的情形之间的S3获取请求数量和总查询时间。
TPC-DS包括99个为基准测试而设计的复杂SQL查询。我们测量了执行所有99个查询所需的总时间、并通过检查S3请求的类型和数量进行了详细分析。我们的测试对两种常见的表格格式(镶木地板和冰山一角)的效率进行了比较。
镶木地板表格式的TPC-DS查询结果
| 生态系统 | 配置 | 三角洲湖 | Dremio | Trino | 星突发 |
|---|---|---|---|---|---|
TPCDS 99查询+ |
1084 1 |
55 |
36 |
32 |
28 |
S3请求细分 |
获取 |
1、117184 |
2、074、610 |
3,939,690 |
1,504,212 |
1,495,039 |
观察:+ |
从32 MB对象中获取2 KB到2 MB的80%范围、每秒50到100个请求 |
73%的范围从32 MB对象开始低于100 KB、每秒1000到1400个请求 |
从256MB对象获取90% 1M字节范围、2500到3000个请求/秒 |
范围获取大小:100 KB以下50%、1 MB左右16%、27% 2 MB到9 MB、3500到4000次请求/秒 |
范围获取大小:100 KB以下50%、1 MB左右16%、27% 2 MB到9 MB、4000到5000个请求/秒 |
列出对象 |
312、053 |
24、158 |
120 |
509 |
512 |
头部+ |
156、027 |
12、103 |
96 |
0 |
0 |
头部+ |
982、126 |
922732 |
0 |
0 |
0 |
请求总数 |
2. |
3、033、603 |
3,939.906 |
1,504,721 |
1 Hive无法完成查询编号72
TPC-DS查询结果,带icerberg表格格式
| 生态系统 | Dremio | Trino | 星突发 |
|---|---|---|---|
TPCDS 99查询+总分钟数(缓存已禁用) |
22 |
28 |
22 |
TPCDS 99次查询+总分钟数2(启用缓存) |
16. |
28 |
21.5 |
S3请求细分 |
GET (缓存已禁用) |
1,985,922 |
938,639 |
931,582 |
GET (已启用缓存) |
611,347 |
30,158 |
3,281 |
观察:+ |
范围获取大小:67% 1MB、15% 100KB、10% 500KB、3500 - 4500次请求/秒 |
范围获取大小:100 KB以下42%、1 MB左右17%、33% 2 MB到9 MB、3500到4000次请求/秒 |
范围获取大小:100 KB以下43%、1 MB左右17%、33% 2 MB到9 MB、4000到5000个请求/秒 |
列出对象 |
1465 |
0 |
0 |
头部+ |
1464 |
0 |
0 |
头部+ |
3,702 |
509 |
509 |
请求总数(缓存已禁用) |
1,992,553 |
939,148 |
2 Trino/Starburst性能会因计算资源而出现瓶颈;向集群添加更多RAM可缩短总查询时间。
如第一个表所示、Hive的速度明显低于其他现代数据数据库生态系统。我们发现、Hive发送了大量S3列表对象请求、这些请求在所有对象存储平台上通常都很慢、尤其是在处理包含许多对象的分段时。这会显著增加整体查询持续时间。此外、现代的温室生态系统可以并行发送大量GET请求、每秒从2000到5、000个不等、而Hive的每秒请求数为50到100个。Hive和Hadoop S3A的标准文件系统模拟导致Hive在与S3对象存储交互时运行的很小。
要将Hadoop (无论是在HDFS还是S3对象存储上)与Hive或Spark结合使用、需要掌握Hadoop和Hive或Spark的丰富知识、并了解每个服务的设置如何进行交互。它们共有1、000多种设置、其中许多设置相互关联、无法单独更改。要找到设置和值的最佳组合、需要花费大量时间和精力。
通过比较镶木地板和冰山一角的结果、我们发现表格格式是一个主要的性能因素。在S3请求数量方面、iciceberg表格格式比镶木地板更高效、与镶木地板格式相比、请求数量减少了35%到50%。
但是、集群的性能主要取决于集群的计算能力。虽然这三个系统都使用S3A连接器建立S3对象存储连接、但它们不需要Hadoop、并且这些系统不会使用Hadoop的大多数FS.S3A设置。这样可以简化性能调整、无需学习和测试各种Hadoop S3A设置。
根据此基准测试结果、我们可以得出结论、针对基于S3的工作负载优化的大数据分析系统是一个主要性能因素。现代的温室可优化查询执行、高效利用元数据并提供对S3数据的无缝访问、从而在使用S3存储时获得比Hive更高的性能。
请参见此指南 "页面。"以使用StorageGRID配置drefio S3数据源。
请访问以下链接、详细了解StorageGRID和德莱米奥如何协同工作来提供现代化且高效的数据湖基础架构、以及NetApp如何从Hive + HDFS迁移到德莱米奥+ StorageGRID来显著提高大数据分析效率。