

Hadoop S3A调整
 建议更改
建议更改
作者:郑安杰
Hadoop S3A连接器有助于在基于Hadoop的应用程序和S3对象存储之间实现无缝交互。在使用S3对象存储时、要优化性能、必须调整Hadoop S3A Connector。在深入介绍调整详细信息之前、我们先大致了解一下Hadoop及其组件。
什么是Hadoop?
Hadoop 是一个功能强大的开源框架,专为处理大规模数据处理和存储而设计。它支持跨多个计算机集群进行分布式存储和并行处理。
Hadoop的三个核心组件是:
-
Hadoop HDFS (Hadoop分布式文件系统):用于处理存储、将数据拆分为块并在节点之间分布。
-
Hadoop MapReredget:负责将任务划分为较小的区块并并行执行来处理数据。
-
Hadoop yar (Yet Another Resource Neotiator): "高效管理资源并计划任务"
Hadoop HDFS和S3A连接器
HDFS是Hadoop生态系统的重要组成部分、在高效处理大数据方面发挥着关键作用。HDFS可实现可靠的存储和管理。它可确保并行处理和优化数据存储、从而加快数据访问和分析速度。
在大数据处理方面、HDFS在为大型数据集提供容错存储方面表现出色。它通过数据复制来实现这一点。它可以在数据仓库环境中存储和管理大量结构化和非结构化数据。此外、它还可以与领先的大数据处理框架无缝集成、例如Apache Spark、Hive、Pig和Flink、从而实现可扩展的高效数据处理。它与基于Unix (Linux)的操作系统兼容、因此对于更喜欢使用基于Linux的环境进行大数据处理的组织来说、它是理想的选择。
随着数据量逐渐增长、使用自己的计算和存储向Hadoop集群添加新计算机的方法变得效率低下。线性扩展为高效使用资源和管理基础架构带来了挑战。
为了应对这些挑战、Hadoop S3A连接器可针对S3对象存储提供高性能I/O。使用S3A实施Hadoop工作流有助于将对象存储用作数据存储库、并将计算和存储分开、进而使您能够独立扩展计算和存储。分离计算和存储还可以让您将适当数量的资源专用于计算作业、并根据数据集大小提供容量。因此、您可以降低Hadoop工作流的总体TCO。
Hadoop S3A连接器调整
S3的行为与HDFS不同、某些尝试保留文件系统外观的行为也明显欠佳。要最高效地利用S3资源、必须仔细调整/测试/试验。
本文档中的Hadoop选项基于Hadoop 3.3.5、请参见 "Hadoop 3.3.5 core-site.xml" 所有可用选项。
注意—某些Hadoop FS.S3a设置的默认值在每个Hadoop版本中都不同。请务必查看特定于当前Hadoop版本的默认值。如果未在Hadoop core-site.xml中指定这些设置、则会使用默认值。您可以使用Spark或Hive配置选项在运行时覆盖此值。
您必须访问此页面 "Apache Hadoop页面" 了解每个FS.S3A选项。如果可能、请在非生产Hadoop集群中对其进行测试、以查找最佳值。
您应阅读 "在使用S3A连接器时最大限度地提高性能" 了解其他调整建议。
让我们来探讨一些关键注意事项:
-
。数据压缩*
请勿启用StorageGRID数据压缩。大多数大数据系统都使用字节范围GET、而不是检索整个对象。对压缩对象使用字节范围GET会显著降低GET性能。
-
。S3a提交人*
一般情况下、建议使用magic S3A提交器。请参见此部分 "通用S3A提交器选项页面" 更好地了解Magic committer及其相关的S3A设置。
魔力委员会:
Magic Commonter特别依靠S3Guard在S3对象存储上提供一致的目录列表。
借助一致的S3 (现在是这种情况)、Magic Comm캯 풱 믡 可以安全地与任何S3存储分段配合使用。
选择和实验:
根据您的使用情形、您可以在Staging Commenter (依赖于集群HDFS文件系统)和Magic Commenter之间进行选择。
尝试这两种方法、确定哪种方法最适合您的工作负载和要求。
总之、S3A委员会为应对持续、高性能和可靠的S3输出承诺这一根本性挑战提供了解决方案。其内部设计可确保高效的数据传输、同时保持数据完整性。
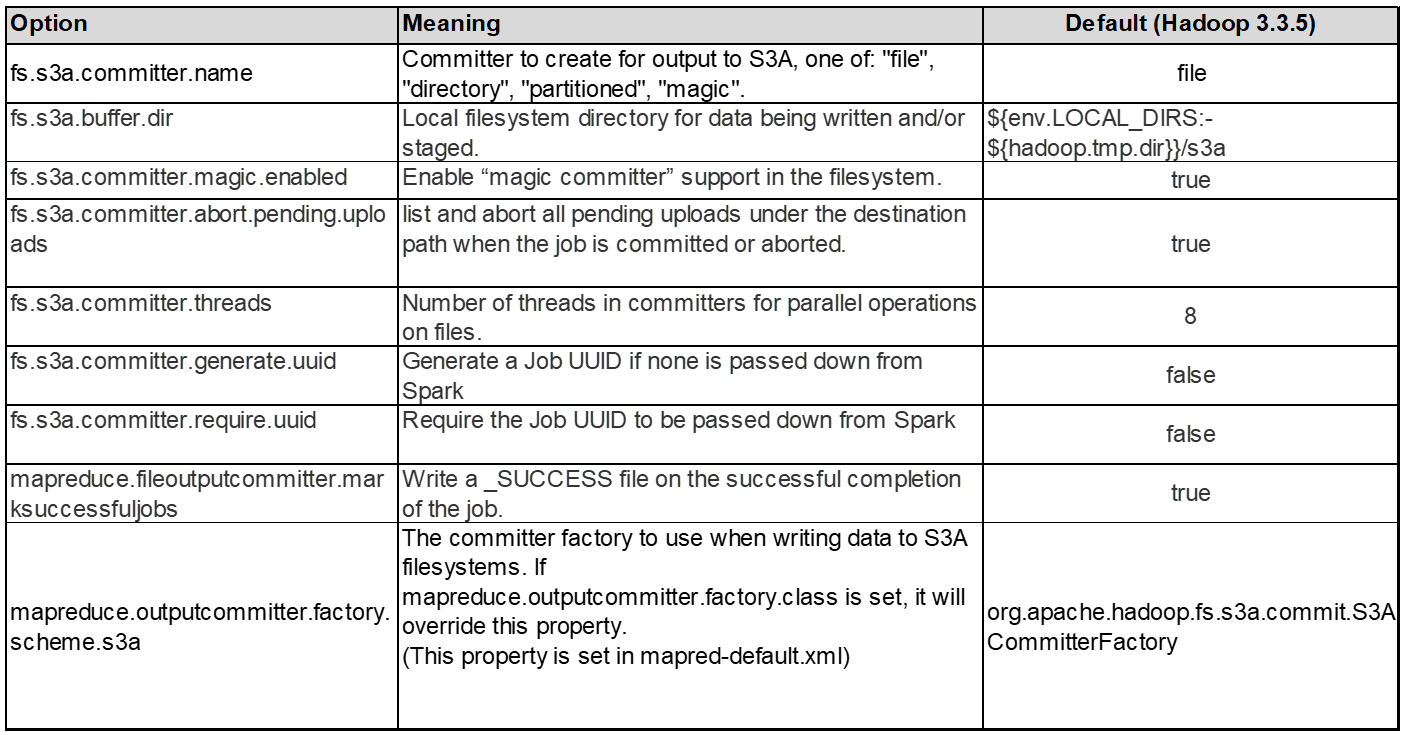
3.线程、连接池大小和块大小
-
与单个存储分段交互的每个*S3A*客户端都有自己的专用池,其中包含用于上传和复制操作的开放HTTP 1.1连接和线程。
-
将数据上传到S3时、数据会划分为多个块。默认块大小为32 MB。您可以通过设置FS.S3a.block.size属性来自定义此值。
-
较大的块大小可通过减少上传期间管理多部件的开销来提高大型数据上传的性能。对于大型数据集、建议值为256 MB或以上。
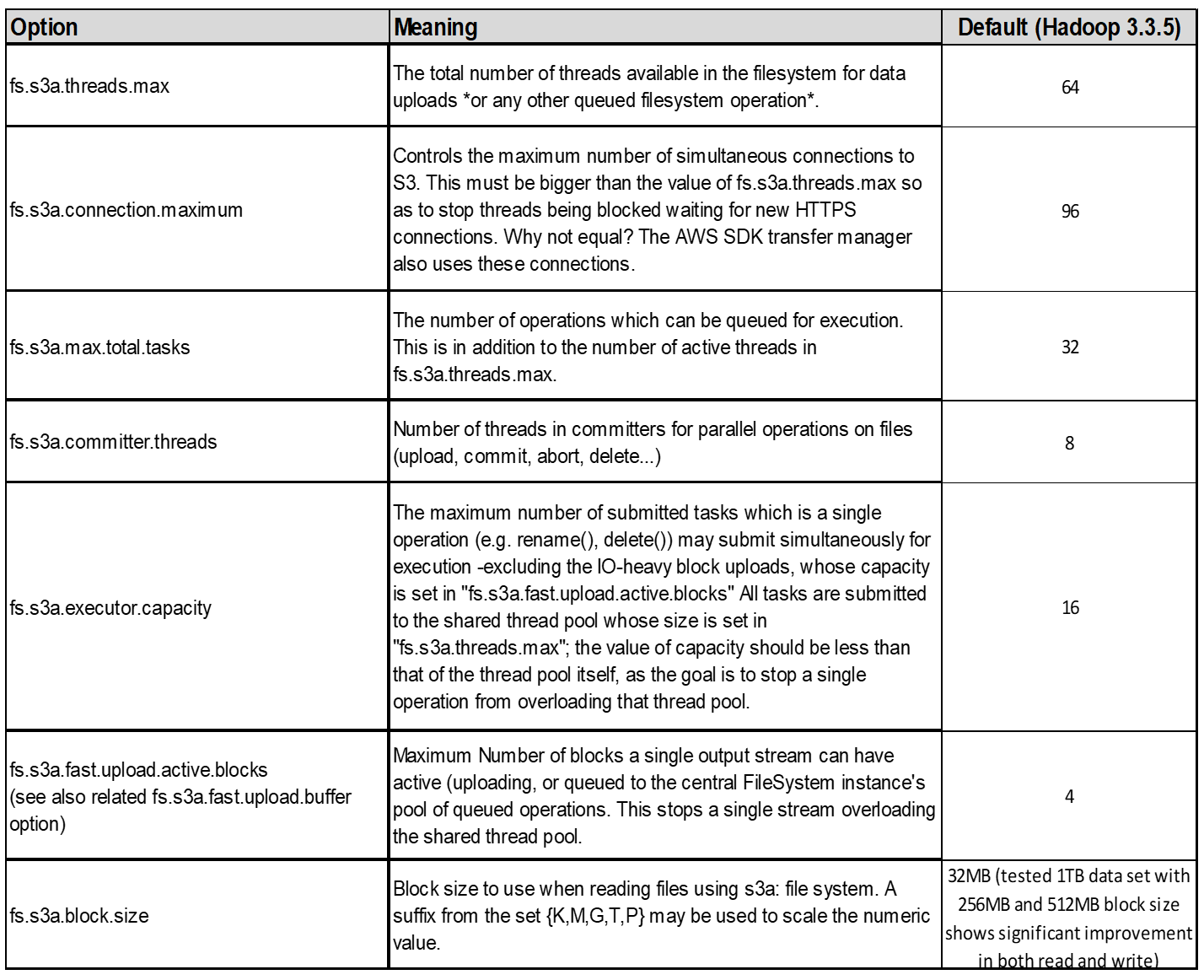
4.多部分上传
S3A提交者*始终*使用MPU (多部分上传)将数据上传到S3存储分段。这是在以下情况下所必需的:任务失败、任务的推测性执行以及提交前作业中止。以下是与多部件上传相关的一些关键规格:
-
最大对象大小:5 TiB (TB)。
-
每次上传的最大部件数:10、000。
-
部件号:范围为1到10、000 (含1到10、000)。
-
部件大小:介于5 MiB和5 GiB之间。值得注意的是、多部分上传的最后一部分没有最小大小限制。
对S3多部件上传使用较小的部件大小既有优点也有缺点。
优势:
-
从网络问题中快速恢复:当您上传较小的部分时、由于网络错误而重新启动失败的上传所产生的影响将降至最低。如果某个部件出现故障、您只需要重新上传该特定部件、而不是整个对象。
-
更好的并行处理:利用多线程或并发连接、可以并行上传更多部件。这种并行处理可提高性能、尤其是在处理大型文件时。
缺点:
-
网络开销:部件较小意味着要上传的部件较多、每个部件都需要自己的HTTP请求。HTTP请求越多、启动和完成单个请求的开销就越大。管理大量小部件可能会影响性能。
-
复杂性:管理订单、跟踪部件和确保上传成功可能会非常繁琐。如果需要中止上传、则需要跟踪并清除已上传的所有部件。
对于Hadoop、建议对fs.s3a.multipart.size使用256MB或以上的部件大小。请始终将FS.S3a.mutlpart.threshold"值设置为2 x FS.S3a.multipart.size值。例如、如果fs.s3a.multipart.size = 256M、则fs.s3a.mutlifpart.threshold"应为512M。
对大型数据集使用较大的零件大小。根据您的特定使用情形和网络条件、选择一个能够平衡这些因素的部件大小非常重要。
多部分上传是 "三步流程":
-
上传已启动、StorageGRID将返回一个上传ID.
-
对象部件将使用上载-id进行上载。
-
上传所有对象部件后、发送包含上传id的完整多部分上传请求。StorageGRID根据上传的部分构建对象、客户端可以访问该对象。
如果未成功发送完整的多部件上传请求、则这些部件将保留在StorageGRID中、不会创建任何对象。作业中断、失败或中止时会发生这种情况。这些部件将保留在网格中、直到多部件上传完成或中止、或者如果上传启动后15天、StorageGRID会清除这些部件。如果一个存储分段中有许多(几百到几百万个)正在进行的多部分上传、则当Hadoop发送‘list-multipart-Uploads’(此请求不按上传ID筛选)时、此请求可能需要很长时间才能完成、或者最终超时。您可以考虑使用适当的FS.S3a.mutlpart.purge值将FS.S3a.multipart.purge.age设置为true (例如、5到7天、不要使用默认值86400、即1天)。或者联系NetApp支持部门调查情况。
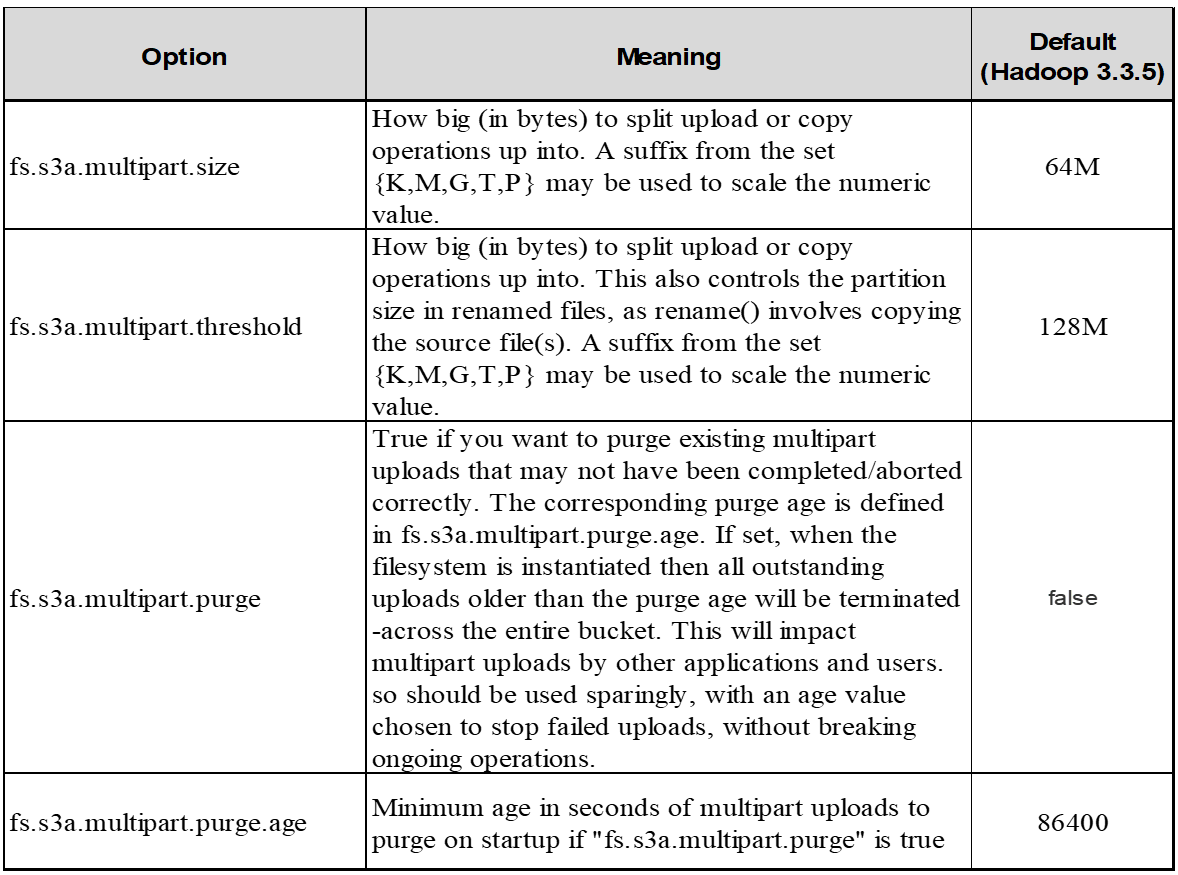
5.缓冲区写入数据存储在内存中
为了提高性能、您可以在将写入数据上传到S3之前将其缓冲在内存中。这样可以减少小型写入次数并提高效率。

请记住、S3和HDFS的工作方式各不相同。要最有效地利用S3资源、必须仔细调整/测试/实验。