主要的 AI、ML 和 DL 用例和架構
 建議變更
建議變更
主要的 AI、ML 和 DL 用例和方法可分為以下幾部分:
Spark NLP 管道和 TensorFlow 分散式推理
以下列表包含資料科學界在不同發展層次下採用的最受歡迎的開源 NLP 庫:
-
"自然語言工具包(NLTK)" 。所有 NLP 技術的完整工具包。它自 21 世紀初以來一直得到維護。
-
"文字區塊" 。基於 NLTK 和 Pattern 建立的易於使用的 NLP 工具 Python API。
-
"史丹佛核心 NLP" 。史丹佛 NLP 小組開發的 Java NLP 服務和套件。
-
"Gensim" 。人類主題建模最初是捷克數位數學圖書館計畫的 Python 腳本集合。
-
"SpaCy" 。使用 Python 和 Cython 實現端對端工業 NLP 工作流程,並為 Transformer 提供 GPU 加速。
-
"快文" 。Facebook 的 AI 研究 (FAIR) 實驗室創建的免費、輕量級、開源 NLP 庫,用於學習單字嵌入和句子分類。
Spark NLP 是針對所有 NLP 任務和要求的單一、統一的解決方案,可為實際生產用例提供可擴展、高效能和高精度的 NLP 軟體。它利用遷移學習並在研究和跨行業中實施最新的最先進的演算法和模型。由於 Spark 缺乏對上述函式庫的全面支持,Spark NLP 建立在 "Spark 機器學習"利用 Spark 的通用記憶體分散式資料處理引擎作為關鍵任務生產工作流程的企業級 NLP 庫。它的註釋器利用基於規則的演算法、機器學習和 TensorFlow 來支援深度學習的實作。這涵蓋了常見的 NLP 任務,包括但不限於標記化、詞形還原、詞幹提取、詞性標註、命名實體識別、拼字檢查和情緒分析。
來自 Transformer 的雙向編碼器表示 (BERT) 是一種基於 Transformer 的 NLP 機器學習技術。它推廣了預訓練和微調的概念。 BERT 中的 Transformer 架構源自機器翻譯,它比基於循環神經網路 (RNN) 的語言模型更好地模擬長期依賴關係。它還引入了掩蔽語言建模 (MLM) 任務,其中隨機 15% 的所有標記被掩蔽,並且模型對其進行預測,從而實現真正的雙向性。
由於該領域的專業語言和缺乏標記數據,金融情緒分析具有挑戰性。 FinBERT 是一種基於預訓練 BERT 的語言模型,已在以下領域進行了調整: "路透社 TRC2" ,一個金融語料庫,並使用標記資料進行微調( "金融短語庫" ) 用於金融情緒分類。研究人員從包含金融術語的新聞文章中提取了 4,500 個句子。然後,16位具有金融背景的專家和碩士生將這些句子標記為肯定、中性和否定。我們建立了一個端到端的 Spark 工作流程,使用 FinBERT 和其他兩個預先訓練的流程來分析 2016 年至 2020 年納斯達克十大公司收益電話會議記錄的情緒, "解釋文檔 DL" )來自 Spark NLP。
Spark NLP 的底層深度學習引擎是 TensorFlow,這是一個端到端的開源機器學習平台,可以輕鬆建立模型、在任何地方進行強大的 ML 生產以及進行強大的研究實驗。因此,在 Spark 中執行管道時 `yarn cluster`模式,我們本質上是在運行分散式 TensorFlow,資料和模型在一個主節點和多個工作節點上並行化,並在叢集上安裝網路附加儲存。
Horovod分散式訓練
與 MapReduce 相關的效能的核心 Hadoop 驗證是使用 TeraGen、TeraSort、TeraValidate 和 DFSIO(讀寫)執行的。 TeraGen 和 TeraSort 驗證結果如下 "NetApp E系列Hadoop解決方案"以及AFF的「儲存分層」部分。
根據客戶要求,我們認為使用 Spark 進行分散式訓練是各種用例中最重要的用例之一。在本文檔中,我們使用了 "Spark 上的 Hovorod"使用NetApp All Flash FAS (AFF) 儲存控制器、 Azure NetApp Files和StorageGRID來驗證 Spark 與NetApp本地端、雲端原生和混合雲端解決方案的效能。
Horovod on Spark 套件為 Horovod 提供了一個便捷的包裝器,使得在 Spark 叢集中運行分散式訓練工作負載變得簡單,從而實現了緊密的模型設計循環,其中資料處理、模型訓練和模型評估都在訓練和推理資料所在的 Spark 中完成。
有兩個用於在 Spark 上運行 Horovod 的 API:高級 Estimator API 和低階 Run API。儘管兩者都使用相同的底層機制在 Spark 執行器上啟動 Horovod,但 Estimator API 抽象化了資料處理、模型訓練循環、模型檢查點、指標收集和分散式訓練。我們使用 Horovod Spark Estimators、TensorFlow 和 Keras 進行端到端資料準備和分散式訓練工作流程,基於 "Kaggle Rossmann 商店銷售"競賽。
腳本 `keras_spark_horovod_rossmann_estimator.py`可以在以下部分找到"每個主要用例的 Python 腳本。"它包含三個部分:
-
第一部分對 Kaggle 提供並由社群收集的一組初始 CSV 檔案執行各種資料預處理步驟。輸入資料被分成一個訓練集, `Validation`子集和測試資料集。
-
第二部分定義了一個具有對數 S 型激活函數和 Adam 優化器的 Keras 深度神經網路 (DNN) 模型,並使用 Spark 上的 Horovod 對模型進行分散式訓練。
-
第三部分使用最小化驗證集總體平均絕對誤差的最佳模型對測試資料集進行預測。然後創建一個輸出 CSV 檔案。
請參閱"機器學習"用於各種運行時比較結果。
使用 Keras 進行多任務深度學習以進行 CTR 預測
隨著機器學習平台和應用的最新進展,人們將大量注意力放在了大規模學習上。點擊率(CTR)定義為每百次線上廣告展示的平均點擊次數(以百分比表示)。它被廣泛採用為各行業垂直領域和用例的關鍵指標,包括數位行銷、零售、電子商務和服務提供者。有關 CTR 和分佈式訓練表現結果的應用的更多詳細信息,請參閱"CTR預測表現的深度學習模型"部分。
在本技術報告中,我們使用了 "Criteo Terabyte 點選日誌資料集"(參見 TR-4904)用於多工作者分散式深度學習,使用 Keras 建立具有深度和交叉網路 (DCN) 模型的 Spark 工作流程,並將其對數損失誤差函數方面的效能與基線 Spark ML 邏輯回歸模型進行比較。 DCN 有效地捕捉有界度的有效特徵交互,學習高度非線性交互,不需要手動特徵工程或窮舉搜索,且計算成本低。
網路規模推薦系統的資料大多是離散的和分類的,導致特徵空間龐大且稀疏,這對於特徵探索來說是一個挑戰。這使得大多數大型系統僅限於邏輯迴歸等線性模型。然而,識別經常預測的特徵並同時探索看不見的或罕見的交叉特徵是做出良好預測的關鍵。線性模型簡單、可解釋、易於擴展,但其表達能力有限。
另一方面,交叉特徵已被證明對提高模型的表現力具有重要意義。不幸的是,通常需要手動特徵工程或詳盡搜尋來識別這些特徵。推廣到看不見的特徵互動通常很困難。使用像 DCN 這樣的交叉神經網路可以透過以自動方式明確應用特徵交叉來避免特定於任務的特徵工程。交叉網路由多層組成,其中最高程度的交互作用可由層深度決定。每一層都會在現有交互的基礎上產生更高階的交互,並保留前幾層的交互。
深度神經網路 (DNN) 有望捕捉跨特徵的非常複雜的交互作用。然而,與 DCN 相比,它需要的參數幾乎多一個數量級,無法明確地形成交叉特徵,並且可能無法有效地學習某些類型的特徵交叉。交叉網路記憶體效率高且易於實現。聯合訓練交叉和 DNN 元件可以有效地捕捉預測特徵交互作用並在 Criteo CTR 資料集上提供最先進的效能。
DCN 模型從嵌入和堆疊層開始,然後並行連接交叉網路和深度網路。接下來是最終的組合層,它將兩個網路的輸出組合在一起。您的輸入資料可以是具有稀疏和密集特徵的向量。在 Spark 中,庫包含類型 SparseVector。因此,使用者區分兩者並在呼叫各自的函數和方法時要小心,這一點很重要。在 CTR 預測等網路規模推薦系統中,輸入大多是分類特徵,例如 'country=usa'。這些特徵通常被編碼為獨熱向量,例如, '[0,1,0, …]' 。獨熱編碼(OHE) `SparseVector`在處理詞彙不斷變化和增長的真實世界資料集時很有用。我們修改了範例 "深度點擊率"處理大型詞彙表,在 DCN 的嵌入和堆疊層中建立嵌入向量。
這 "Criteo 展示廣告資料集"預測廣告點擊率。它有 13 個整數特徵和 26 個分類特徵,其中每個類別都有很高的基數。對於該資料集,由於輸入規模較大,對數損失 0.001 的改進實際上具有顯著意義。對於龐大的用戶群,預測準確度的微小提升都可能帶來公司收入的大幅增加。該資料集包含 7 天內 11GB 的使用者日誌,相當於約 4,100 萬筆記錄。我們使用了 Spark `dataFrame.randomSplit()function`隨機分割資料用於訓練(80%)、交叉驗證(10%),剩餘 10% 用於測試。
DCN 是使用 Keras 在 TensorFlow 上實現的。使用DCN實現模型訓練過程主要有四個部分:
-
*資料處理和嵌入。 *透過應用對數變換對實值特徵進行規範化。對於分類特徵,我們將特徵嵌入到維度為 6×(類別基數)1/4 的密集向量中。連接所有嵌入將產生一個維度為 1026 的向量。
-
*最佳化.*我們利用 Adam 優化器進行了小批量隨機優化。批次大小設定為 512。將深度網路進行批量歸一化,梯度裁剪範數設為100。
-
*正則化。 *我們採用了早期停止的方法,因為 L2 正規化或 dropout 被發現無效。
-
超參數。我們報告基於對隱藏層數量、隱藏層大小、初始學習率和交叉層數量的網格搜尋的結果。隱藏層的數量範圍為 2 至 5,隱藏層大小範圍為 32 至 1024。對於DCN,交叉層的數量為1至6。初始學習率從 0.0001 調整到 0.001,增量為 0.0001。所有實驗均在訓練步驟 150,000 時提前停止,超過該步驟後就會開始出現過度擬合。
用於驗證的架構
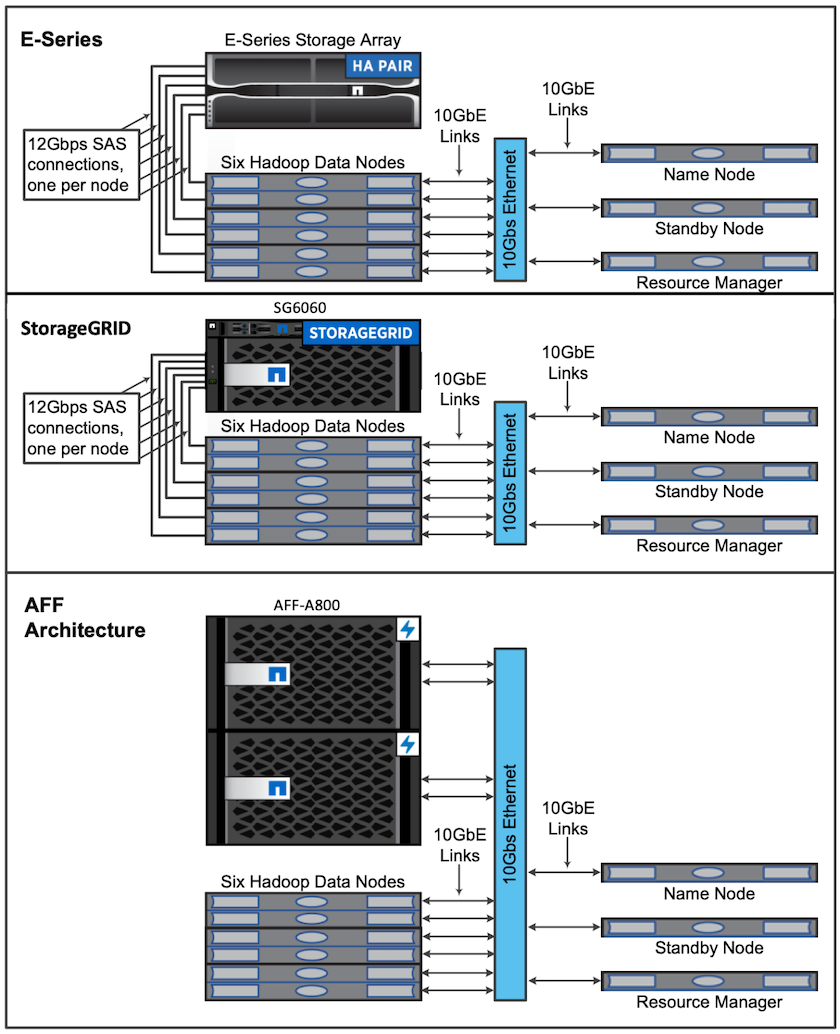
為了進行此驗證,我們使用了四個工作節點和一個主節點以及一個AFF-A800 HA 對。所有群集成員都透過 10GbE 網路交換器連接。
為了驗證NetApp Spark 解決方案,我們使用了三種不同的儲存控制器:E5760、E5724 和AFF-A800。 E系列儲存控制器透過12Gbps SAS連線連接到五個資料節點。 AFF HA 對儲存控制器透過 10GbE 連線向 Hadoop 工作節點提供匯出的 NFS 磁碟區。 Hadoop 叢集成員透過 E 系列、 AFF和StorageGRID Hadoop 解決方案中的 10GbE 連線進行連線。