

ONTAP Select HA 增強資料保護
 建議變更
建議變更
高可用性 (HA) 磁碟心跳、HA 信箱、HA 心跳、HA 故障轉移和回饋功能可增強資料保護。
磁碟心跳
儘管ONTAP Select HA 架構充分利用了傳統FAS陣列的許多程式碼路徑,但也存在一些例外。其中一個例外是基於磁碟的心跳機制的實現,這是一種非基於網路的通訊方法,叢集節點使用這種方法來防止網路隔離導致裂腦行為。裂腦場景是群集分區的結果,通常由網路故障引起,導致群集兩端都認為對方已宕機並試圖接管群集資源。
企業級 HA 實施必須妥善處理此類情況。 ONTAP透過一種基於磁碟的客製化心跳機制來實現這一點。 ONTAP郵箱負責處理此任務,它是叢集節點用於傳遞心跳訊息的實體儲存位置。這有助於集群確定連接性,從而在發生故障轉移時確定仲裁。
在使用共享儲存 HA 架構的FAS陣列上, ONTAP透過以下方式解決裂腦問題:
-
SCSI 持久預留
-
持久 HA 元數據
-
透過 HA 互連發送 HA 狀態
然而,在ONTAP Select叢集的無共用架構中,節點只能看到自己的本機存儲,而看不到 HA 配對節點的本機儲存。因此,當網路分區隔離 HA 對的每一側時,上述確定集群仲裁和故障轉移行為的方法將無法使用。
雖然現有的裂腦檢測和避免方法無法使用,但仍需要一種能夠適應無共享環境約束的調解方法。 ONTAPONTAP Select進一步擴展了現有的郵箱基礎架構,使其能夠在網路分區時充當調解方法。由於共用儲存不可用,因此調解是透過 NAS 存取郵箱磁碟來完成的。這些磁碟分佈在整個叢集中,包括雙節點叢集中的調解器,並使用 iSCSI 協定。因此,叢集節點可以根據對這些磁碟的存取做出智慧故障轉移決策。如果一個節點可以存取其 HA 夥伴節點之外的其他節點的郵箱磁碟,則該節點很可能已啟動且運作正常。

|
解決叢集仲裁和裂腦問題的郵箱架構和基於磁碟的心跳方法是ONTAP Select多節點變體需要四個獨立節點或雙節點叢集的調解器的原因。 |
HA郵箱發帖
HA 郵箱架構採用訊息發布模型。叢集節點會定期向叢集中所有其他郵件磁碟(包括中介節點)發布訊息,表示該節點已啟動並正在執行。在正常運作的叢集中,任何時間點,叢集節點上的單一郵箱磁碟都會收到來自所有其他叢集節點的訊息。
每個 Select 叢集節點都附加一個虛擬磁碟,專門用於共用郵箱存取。此磁碟被稱為中介郵箱磁碟,因為其主要功能是在發生節點故障或網路分割時充當叢集中介。此郵箱磁碟包含每個叢集節點的分割區,並由其他 Select 叢集節點透過 iSCSI 網路掛載。這些節點會定期將運作狀況發佈到郵件匣磁碟的對應分割區。使用分佈在整個叢集中的網路可存取郵箱磁碟,您可以透過可達性矩陣推斷節點的運作狀況。例如,叢集節點 A 和 B 可以向叢集節點 D 的郵箱傳送郵件,但不能傳送郵件給節點 C 的郵件。此外,叢集節點 D 無法向節點 C 的郵箱發送郵件,因此節點 C 很可能已關閉或網路隔離,應該被接管。
HA 心跳
與NetApp FAS平台一樣, ONTAP Select會定期透過 HA 互連發送 HA 心跳訊息。在ONTAP Select叢集中,此操作透過 HA 夥伴節點之間的 TCP/IP 網路連線執行。此外,基於磁碟的心跳訊息會傳遞到所有 HA 郵箱磁碟,包括中介郵箱磁碟。這些訊息每隔幾秒鐘傳遞一次,並定期讀取。如此高的發送和接收頻率使ONTAP Select叢集能夠在大約 15 秒內檢測到 HA 故障事件,這與FAS平台上的可用時間視窗相同。當不再讀取心跳訊息時,將觸發故障轉移事件。
下圖從單一ONTAP Select叢集節點(節點 C)的角度顯示了透過 HA 互連和調解磁碟發送和接收心跳訊息的過程。
|
|
網路心跳透過 HA 互連傳送到 HA 夥伴節點 D,而磁碟心跳使用跨所有叢集節點 A、B、C 和 D 的郵件磁碟。 |
四節點叢集中的 HA 心跳:穩定狀態 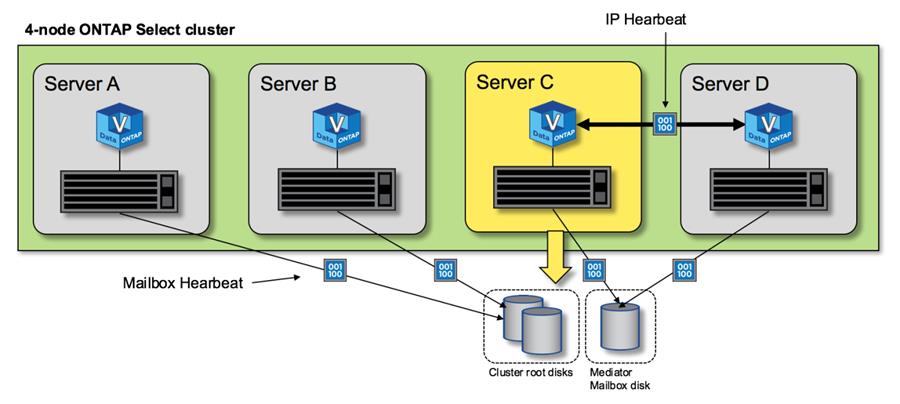
HA 故障轉移與恢復
在故障轉移作業期間,倖存節點將使用其 HA 夥伴節點資料的本機副本承擔其對等節點的資料服務責任。客戶端 I/O 可以繼續不間斷地運行,但必須先複製對此資料的更改,然後才能進行交還。請注意, ONTAP Select不支援強制交還,因為這會導致儲存在倖存節點上的變更遺失。
重啟的節點重新加入叢集時,會自動觸發同步復原操作。同步恢復所需的時間取決於多種因素。這些因素包括必須複製的更改數量、節點之間的網路延遲以及每個節點上磁碟子系統的速度。同步恢復所需的時間可能會超過 10 分鐘的自動交還視窗。在這種情況下,需要在同步恢復後進行手動交還。您可以使用以下命令監控同步復原的進度:
storage aggregate status -r -aggregate <aggregate name>