

NetApp StorageGRID 與巨量資料分析
 建議變更
建議變更
NetApp StorageGRID 使用案例
NetApp StorageGRID 物件儲存解決方案提供擴充性、資料可用度、安全性及高效能。各種規模的組織、以及各行各業的組織、都會使用 StorageGRID S3 來處理各種使用案例。讓我們來探索一些典型案例:
-
巨量資料分析: * StorageGRID S3 經常用作資料湖、企業可在其中儲存大量結構化和非結構化資料、以便使用 Apache Spark 、 Splunk Smartstore 和 Dremio 等工具進行分析。
-
資料分層: * NetApp 客戶使用 ONTAP 的 FabricPool 功能、在高效能本機層之間自動將資料移至 StorageGRID 。分層可釋放昂貴的 Flash 儲存空間、以儲存熱資料、同時在低成本物件儲存設備上隨時提供冷資料。如此可將效能與節約效益發揮到極致。
-
資料備份與災難恢復: * 企業可以使用 StorageGRID S3 做為可靠且具成本效益的解決方案、在發生災難時備份關鍵資料並加以恢復。
-
應用程式的資料儲存: * StorageGRID S3 可作為應用程式的儲存後端、讓開發人員輕鬆儲存及擷取檔案、影像、影片及其他類型的資料。
-
內容交付: * StorageGRID S3 可用於儲存靜態網站內容、媒體檔案及軟體下載、並提供給全球各地的使用者、運用 StorageGRID 的地理發佈和全球命名空間、提供快速可靠的內容交付。
-
資料歸檔: * StorageGRID 提供不同的儲存類型、並支援分層處理至公有長期低成本儲存選項、因此是歸檔及長期保留資料的理想解決方案、這些資料必須保留以供法規遵循或歷史用途。
-
物件儲存使用案例 *
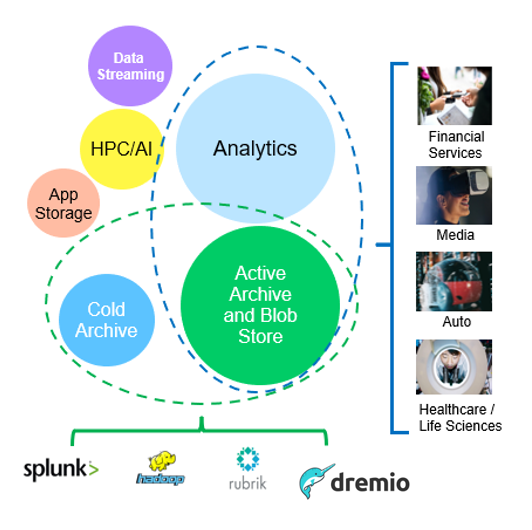
在上述情況中、巨量資料分析是最熱門的使用案例之一、其使用率也逐漸上升。
為何選擇 StorageGRID 來處理資料湖?
-
更高的協同作業效率:大規模共用多站台、多租戶、並具備業界標準 API 存取功能
-
降低營運成本:單一、自我修復、自動化橫向擴充架構的操作簡易性
-
擴充性:與傳統的 Hadoop 和資料倉儲解決方案不同、 StorageGRID S3 物件儲存設備可將儲存設備與運算和資料分離、讓企業能夠隨著成長擴充儲存需求。
-
耐用性與可靠性: StorageGRID 提供 99.999% 的耐用度、這表示儲存的資料對於資料遺失具有高度抵抗能力。它也提供高可用度、確保資料隨時可供存取。
-
安全性: StorageGRID 提供各種安全功能、包括加密、存取控制原則、資料生命週期管理、物件鎖定和版本設定、以保護儲存在 S3 儲存區中的資料
-
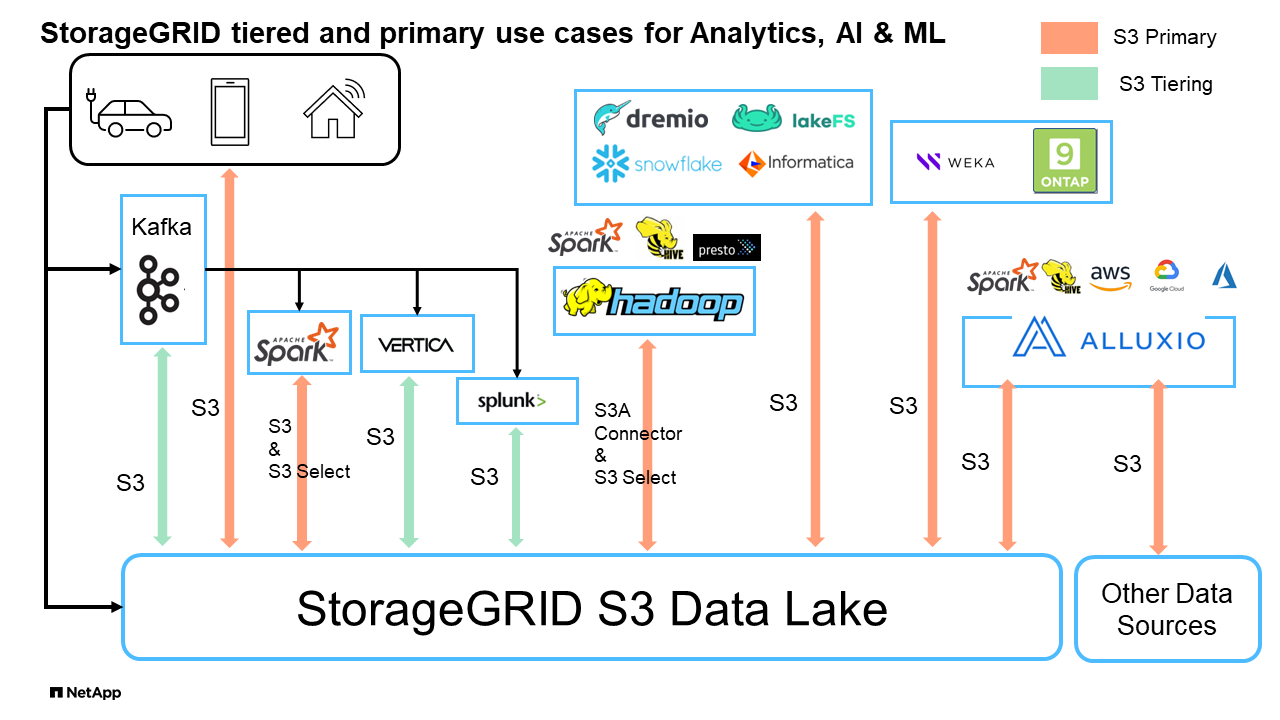
StorageGRID S3 資料湖 *
以 S3 物件儲存為基準測試資料倉儲和 Lakeouses :比較研究
本文使用 NetApp StorageGRID 對各種資料倉儲和湖倉式儲存生態系統進行了全面的基準測試。目標是確定哪個系統在 S3 物件儲存方面效能最佳。請參閱此https://hello.dremio.com/wp-apache-iceberg-the-definitive-guide-reg.html["Apache 冰山:最終指南"]以了解更多關於資料倉儲/湖倉式儲存架構和表格式(Parquet 和 Iceberg)的資訊。
-
基準測試工具 - TPC-DS - https://www.tpc.org/tpcds/
-
Big Data 生態系統
-
VM 叢集、每個都有 128G RAM 和 24 個 vCPU 、系統磁碟的 SSD 儲存設備
-
Hadoop 3.3.5 搭配 Hive 3.1.3 ( 1 個名稱節點 + 4 個資料節點)
-
Delta Lake with Spark 3.2.0 ( 1 位大師 + 4 位員工)和 Hadoop 3.3.5
-
Dremio v25.2 ( 1 名協調員 + 5 名執行者)
-
Trino v438 ( 1 名協調員 + 5 名員工)
-
Starburst v453 ( 1 名協調員 + 5 名員工)
-
-
物件儲存
-
NetApp ^ ® ^ StorageGRID ^ ® ^ 11.8 含 3 個 SG6060 + 1 個 SG1000 負載平衡器
-
物件保護 - 2 份複本(結果與 EC 2+1 類似)
-
-
資料庫大小 1000GB
-
每項查詢測試的所有生態系統都會使用「硬碟區」格式停用快取。對於冰山格式、我們比較了 S3 取得要求的數量、以及快取停用和啟用快取的案例之間的查詢時間總計。
TPC-DS 包含 99 個複雜的 SQL 查詢、專為基準測試而設計。我們測量了執行所有 99 項查詢所需的總時間、並透過檢查 S3 要求的類型和數量來進行詳細分析。我們的測試比較了兩種常用表格格式的效率:拼花地板和冰山。
-
使用 Parquet 資料表格式的 TPC-DS 查詢結果 *
| 生態系統 | Hive | 德爾塔湖 | 夢中 | Trino | Starburst |
|---|---|---|---|---|---|
TPCDS 99 查詢 |
10841 |
55 |
36 |
32 |
28 |
S3 要求明細 |
取得 |
1,117,184 |
2,074,610 |
3,939,690 |
1,504,212 |
1,495,039 |
觀察: |
從 32 MB 物件到 2 KB 到 2 MB 的範圍達到 80% 、每秒 50 到 100 個要求 |
73% 的範圍從 32 MB 物件低於 100KB 、從 1000 到 1400 個要求 / 秒 |
從 256 MB 物件獲得 90% 的 100 萬位元組範圍、 2500 年至 3000 個要求 / 秒 |
範圍取得大小:低於 100KB 50% 、約 16% 1 MB 、 27% 2Mb 至 9Mb 、 3500 至 4000 個要求 / 秒 |
範圍取得大小:低於 100KB 50% 、約 16% 1MB 、 27% 2Mb 至 9Mb 、 4000 至 5000 要求 / 秒 |
列出物件 |
312,053 |
24 、 158 |
120 |
509 |
512 |
標題 |
156,027 |
12 、 103 |
96 |
0 |
0 |
標題 |
982,126. |
922,732. |
0 |
0 |
0 |
申請總數 |
2,567,390 |
3 、 033 、 603 |
3,939.906 |
1,504,721 |
1 Hive 無法完成查詢編號 72
-
TPC-DS 查詢結果、內含冰山表格格式 *
| 生態系統 | 夢中 | Trino | Starburst |
|---|---|---|---|
TPCDS 99 查詢 + 總分鐘數(停用快取) |
22 |
28 |
22 |
TPCDS 99 查詢 + 總分鐘 2 (啟用快取) |
16. |
28 |
21.5 |
S3 要求明細 |
Get (快取已停用) |
1,985,922 |
938,639 |
931,582 |
Get (啟用快取) |
611,347 |
30,158 |
3,281 |
觀察: |
範圍取得大小: 67% 1MB 、 15% 100KB 、 10% 500KB 、 3500 - 4500 個要求 / 秒 |
範圍取得大小:低於 100KB 42% 、約 17% 1 MB 、 33% 2Mb 至 9Mb 、 3500 至 4000 個要求 / 秒 |
範圍取得大小:低於 100KB 43% 、約 17% 1 MB 、 33% 2Mb 至 9Mb 、 4000 至 5000 個要求 / 秒 |
列出物件 |
1465 |
0 |
0 |
標題 |
1464 |
0 |
0 |
標題 |
3,702 |
509 |
509 |
要求總數(快取停用) |
1,992,553 |
939,148 |
2 Trino/Starburst 效能受到運算資源的限制;將更多 RAM 新增至叢集可縮短查詢時間。
如第一張表所示、 Hive 的速度遠低於其他現代資料湖屋生態系統。我們觀察到 Hive 傳送了大量的 S3 清單物件要求、這在所有物件儲存平台上通常都很緩慢、尤其是在處理包含許多物件的貯體時。如此可大幅增加整體查詢持續時間。此外、現代的湖屋生態系統也能同時傳送大量的 GET 要求、每秒可傳送 2 、 000 至 5 、 000 個要求、相較於 Hive 每秒 50 至 100 個要求。與 S3 物件儲存設備互動時、 Hive 和 Hadoop S3A 所提供的標準檔案系統會導致 Hive 速度緩慢。
搭配 Hive 或 Spark 使用 Hadoop (在 HDFS 或 S3 物件儲存設備上)需要對 Hadoop 和 Hive/Spark 有廣泛的瞭解、同時也需要瞭解每個服務的設定如何互動。它們一起擁有超過 1 、 000 種設定、其中許多是相互關聯的、無法分別變更。尋找設定與值的最佳組合需要大量的時間和精力。
比較 Parquet 和冰山結果時、我們發現表格格式是主要的效能因素。從 S3 要求的數量來看、冰山表格格式比 Parquet 更有效率、相較於 Parquet 格式、申請數量減少 35% 至 50% 。
Dremio 、 Trino 或 Starburst 的效能主要是由叢集的運算能力所驅動。雖然這三個系統都使用 S3A 連接器來連接 S3 物件儲存連線、但它們不需要 Hadoop 、而且這些系統也不使用 Hadoop 的 FS.s3a 設定。如此可簡化效能調校、免除學習和測試各種 Hadoop S3A 設定的需求。
從這個基準測試結果中、我們可以得出結論、針對 S3 型工作負載最佳化的大型資料分析系統是主要的效能因素。現代化的湖上環境可最佳化查詢執行、有效運用中繼資料、並提供對 S3 資料的無縫存取、因此相較於使用 S3 儲存設備時的 Hive 、效能更佳。
請參閱此 "頁面"資訊、以使用 StorageGRID 設定 Dremio S3 資料來源。
請造訪下列連結、深入瞭解 StorageGRID 和 Dremio 如何合作提供現代化且有效率的資料湖基礎架構、以及 NetApp 如何從 Hive + HDFS 移轉至 Dremio + StorageGRID 、大幅提升巨量資料分析效率。