

Identifizieren des Problems und Durchführen von Korrekturmaßnahmen für einen fehlgeschlagenen Schutzauftrag
 Änderungen vorschlagen
Änderungen vorschlagen
Sie überprüfen die Fehlermeldung zum Jobfehler im Feld Ursache auf der Seite Ereignisdetails und stellen fest, dass der Job aufgrund eines Fehlers bei der Snapshot-Kopie fehlgeschlagen ist. Fahren Sie dann zur Seite Volume / Health Details, um weitere Informationen zu erhalten.
Was Sie brauchen
Sie müssen über die Anwendungsadministratorrolle verfügen.
Die Fehlermeldung, die im Feld Ursache auf der Seite Ereignisdetails angezeigt wird, enthält den folgenden Text über den fehlgeschlagenen Job:
Protection Job Failed. Reason: (Transfer operation for relationship 'cluster2_src_svm:cluster2_src_vol2->cluster3_dst_svm: managed_svc2_vol3' ended unsuccessfully. Last error reported by Data ONTAP: Failed to create Snapshot copy 0426cluster2_src_vol2snap on volume cluster2_src_svm:cluster2_src_vol2. (CSM: An operation failed due to an ONC RPC failure.) Job Details
Diese Meldung enthält folgende Informationen:
-
Ein Backup- oder Spiegelungsauftrag wurde nicht erfolgreich abgeschlossen.
Der Job umfasste eine Sicherungsbeziehung zwischen dem Quell-Volume
cluster2_src_vol2Auf dem virtuellen Servercluster2_src_svmUnd dem Ziel-Volumemanaged_svc2_vol3Auf dem virtuellen Server mit dem Namencluster3_dst_svm. -
Fehler beim Erstellen eines Jobs für die Snapshot Kopie
0426cluster2_src_vol2snapAuf dem Quell-Volumecluster2_src_svm:/cluster2_src_vol2.
In diesem Szenario können Sie die Ursache und mögliche Korrekturmaßnahmen für den Job-Fehler identifizieren. Zur Behebung des Fehlers müssen Sie jedoch entweder auf die Web-UI des System Managers oder auf die CLI-Befehle von ONTAP zugreifen.
-
Sie überprüfen die Fehlermeldung und stellen fest, dass ein Snapshot-Kopierauftrag auf dem Quell-Volume fehlgeschlagen ist, was darauf hinweist, dass möglicherweise ein Problem mit Ihrem Quell-Volume vorliegt.
Optional können Sie am Ende der Fehlermeldung auf den Link Job Details klicken, aber für die Zwecke dieses Szenarios wählen Sie nicht zu tun.
-
Sie entscheiden, dass Sie versuchen möchten, das Ereignis zu lösen, so gehen Sie wie folgt vor:
-
Klicken Sie auf die Schaltfläche Zuweisen zu und wählen Sie im Menü die Option ME aus.
-
Klicken Sie auf die Schaltfläche Bestätigen, damit Sie keine wiederholten Warnmeldungen erhalten, wenn für das Ereignis Warnmeldungen eingerichtet wurden.
-
Optional können Sie auch Anmerkungen zum Ereignis hinzufügen.
-
-
Klicken Sie im Fensterbereich Zusammenfassung auf das Feld Quelle, um Details zum Quellvolumen anzuzeigen.
Das Feld Quelle enthält den Namen des Quellobjekts: In diesem Fall das Volume, auf dem der Snapshot-Kopierauftrag geplant wurde.
Die Seite Volume / Health Details wird für angezeigt
cluster2_src_vol2, Zeigt den Inhalt der Registerkarte Schutz. -
Wenn man sich das Topologiediagramm ansieht, wird ein Fehlersymbol angezeigt, das mit dem ersten Volume in der Topologie verknüpft ist, das das Quell-Volume für die SnapMirror Beziehung ist.
Die horizontalen Balken im Quell-Volume-Symbol zeigen die für dieses Volume eingestellten Warn- und Fehlerschwellenwerte an.
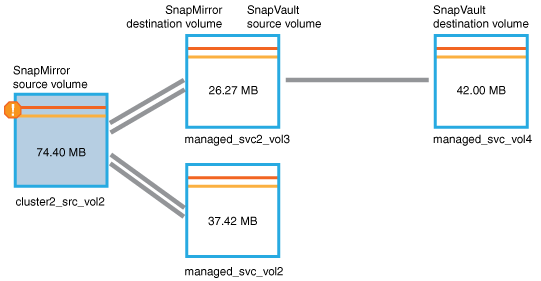
-
Sie platzieren den Cursor über das Fehlersymbol, um das Popup-Dialogfeld anzuzeigen, in dem die Schwellenwerteinstellungen angezeigt werden. Es wird angezeigt, dass das Volume den Fehlerschwellenwert überschritten hat und ein Kapazitätsproblem angezeigt wird.
-
Klicken Sie auf die Registerkarte Kapazität.
Kapazitätsinformationen zum Volume
cluster2_src_vol2Anzeigen. -
Im Fenster Kapazität sehen Sie, dass im Balkendiagramm ein Fehlersymbol angezeigt wird, das wiederum anzeigt, dass die Volumenkapazität den für das Volumen festgelegten Schwellenwert überschritten hat.
-
Unter dem Kapazitätsdiagramm sehen Sie, dass Autogrow von Volume deaktiviert wurde und eine Volume-Platzgarantie gesetzt wurde.
Sie könnten sich für die Aktivierung von Autogrow entscheiden. In diesem Szenario entscheiden Sie sich jedoch, bis Sie eine Entscheidung treffen, wie das Kapazitätsproblem zu lösen ist, bevor Sie eine Entscheidung treffen.
-
Sie scrollen nach unten zur Liste Ereignisse und sehen, dass der Schutzauftrag fehlgeschlagen ist, Volume Days bis Full und Volume Space Full Events generiert wurden.
-
In der Events-Liste klicken Sie auf das Event Volume Space Full, um weitere Informationen zu erhalten, nachdem Sie entschieden haben, dass dieses Ereignis für Ihr Kapazitätsproblem am relevantesten erscheint.
Auf der Seite Ereignisdetails wird das Ereignis Volume Space Full für das Quell-Volume angezeigt.
-
Im Bereich Zusammenfassung lesen Sie das Feld Ursache für das Ereignis:
The full threshold set at 90% is breached. 45.38 MB (95.54%) of 47.50 MB is used. -
Unter dem Übersichtsbereich werden vorgeschlagene Korrekturmaßnahmen angezeigt.

Die vorgeschlagenen Korrekturmaßnahmen werden nur für bestimmte Ereignisse angezeigt, sodass dieser Bereich für alle Arten von Ereignissen nicht angezeigt wird.
Klicken Sie durch die Liste der vorgeschlagenen Aktionen, die Sie möglicherweise durchführen können, um das Ereignis Volume Space Full aufzulösen:
-
Aktivieren Sie Autogrow auf diesem Volume.
-
Die Volume-Größe ändern
-
Aktivierung und Ausführung der Deduplizierung auf diesem Volume
-
Aktivieren und führen Sie die Komprimierung auf diesem Volume durch.
-
-
Sie entscheiden sich für die Aktivierung von Autogrow auf dem Volume. Dazu müssen Sie jedoch den verfügbaren freien Speicherplatz im übergeordneten Aggregat und die aktuelle Wachstumsrate des Volume bestimmen:
-
Sehen Sie sich das übergeordnete Aggregat an,
cluster2_src_aggr1, Im Fenster Verwandte Geräte.
Sie können auf den Namen des Aggregats klicken, um weitere Details zum Aggregat zu erhalten.
Sie bestimmen, dass das Aggregat über ausreichend Platz verfügt, um die Autogrow von Volumes zu aktivieren.
-
Sehen Sie sich oben auf der Seite das Symbol für einen kritischen Vorfall an, und überprüfen Sie den Text unter dem Symbol.
Sie bestimmen, dass „Tage voll: Weniger als ein Tag“- Wachstumsrate: 5.4%.
-
-
Wechseln Sie zu System Manager oder rufen Sie die ONTAP-CLI auf, um die zu aktivieren
volume autogrowOption.
Notieren Sie sich die Namen des Volumes und des Aggregats, sodass Sie sie bei der Aktivierung von Autogrow zur Verfügung haben.
-
Kehren Sie nach der Behebung des Kapazitätsproblem zur Detailseite für Unified Manager Event zurück, und markieren Sie das Ereignis als erledigt.