

Installation und Konfiguration des Kubernetes Monitoring Operators
 Änderungen vorschlagen
Änderungen vorschlagen
Data Infrastructure Insights bietet den Kubernetes Monitoring Operator für die Kubernetes-Sammlung. Navigieren Sie zu Kubernetes > Collectors > +Kubernetes Collector, um einen neuen Operator bereitzustellen.
Vor der Installation des Kubernetes Monitoring Operator
Siehe die"Voraussetzungen" Dokumentation, bevor Sie den Kubernetes Monitoring Operator installieren oder aktualisieren.
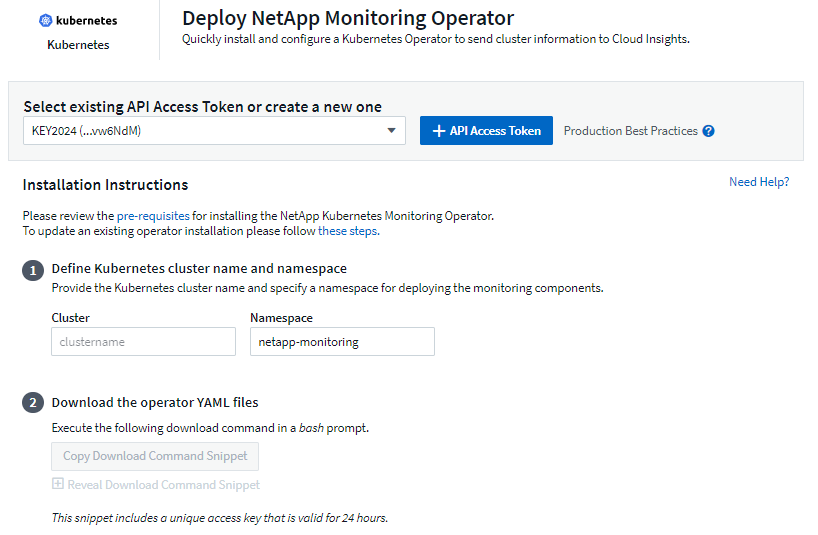
Installieren des Kubernetes Monitoring Operators
-
Geben Sie einen eindeutigen Clusternamen und Namespace ein. Wenn SieUpgrade von einem vorherigen Kubernetes-Operator, verwenden Sie denselben Clusternamen und Namespace.
-
Sobald diese eingegeben sind, können Sie den Download-Befehlsausschnitt in die Zwischenablage kopieren.
-
Fügen Sie den Snippet in ein Bash-Fenster ein und führen Sie ihn aus. Die Operator-Installationsdateien werden heruntergeladen. Beachten Sie, dass das Snippet einen eindeutigen Schlüssel hat und 24 Stunden gültig ist.
-
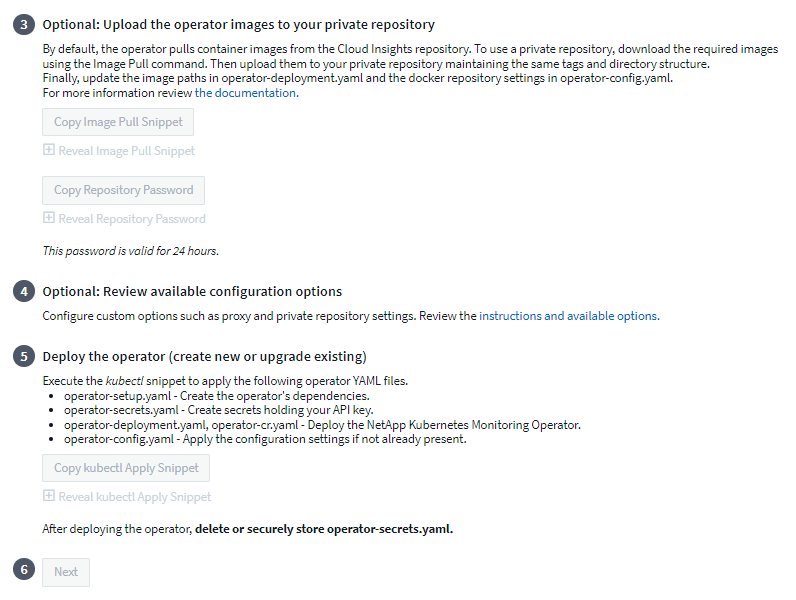
Wenn Sie ein benutzerdefiniertes oder privates Repository haben, kopieren Sie den optionalen Image Pull-Ausschnitt, fügen Sie ihn in eine Bash-Shell ein und führen Sie ihn aus. Sobald die Bilder abgerufen wurden, kopieren Sie sie in Ihr privates Repository. Achten Sie darauf, dieselben Tags und dieselbe Ordnerstruktur beizubehalten. Aktualisieren Sie die Pfade in operator-deployment.yaml sowie die Docker-Repository-Einstellungen in operator-config.yaml.
-
Überprüfen Sie bei Bedarf die verfügbaren Konfigurationsoptionen wie Proxy- oder private Repository-Einstellungen. Weitere Informationen finden Sie unter"Konfigurationsoptionen" .
-
Wenn Sie bereit sind, stellen Sie den Operator bereit, indem Sie das kubectl Apply-Snippet kopieren, herunterladen und ausführen.
-
Die Installation erfolgt automatisch. Wenn der Vorgang abgeschlossen ist, klicken Sie auf die Schaltfläche Weiter.
-
Wenn die Installation abgeschlossen ist, klicken Sie auf die Schaltfläche Weiter. Denken Sie daran, auch die Datei operator-secrets.yaml zu löschen oder sicher zu speichern.
Wenn Sie ein benutzerdefiniertes Repository haben, lesen Sie überVerwenden eines benutzerdefinierten/privaten Docker-Repositorys .
Kubernetes-Überwachungskomponenten
Data Infrastructure Insights Kubernetes Monitoring besteht aus vier Überwachungskomponenten:
-
Clustermetriken
-
Netzwerkleistung und Karte (optional)
-
Ereignisprotokolle (optional)
-
Änderungsanalyse (optional)
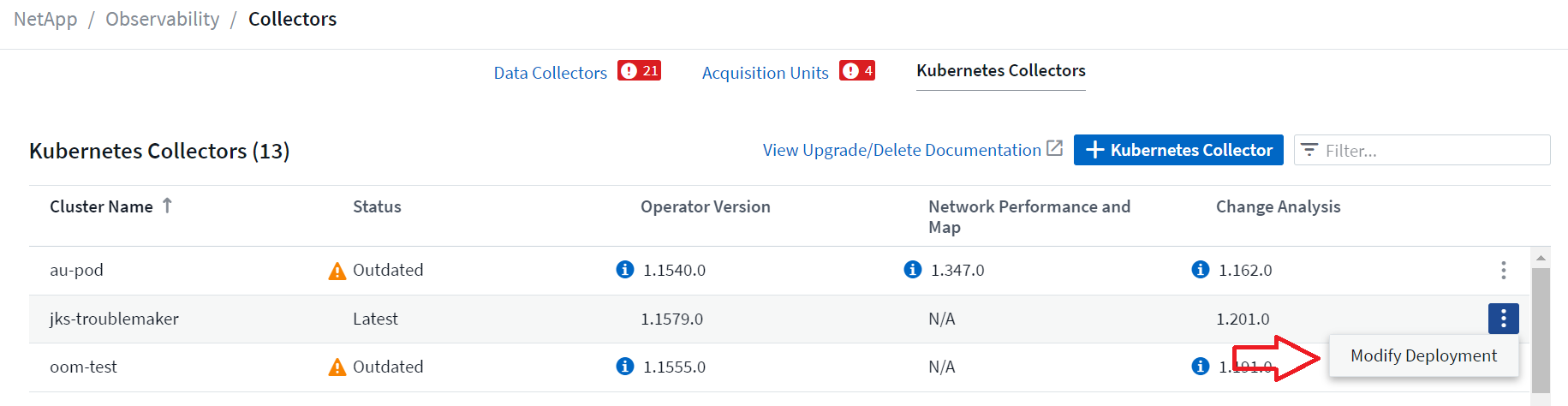
Die oben genannten optionalen Komponenten sind standardmäßig für jeden Kubernetes-Collector aktiviert. Wenn Sie entscheiden, dass Sie eine Komponente für einen bestimmten Collector nicht benötigen, können Sie sie deaktivieren, indem Sie zu Kubernetes > Collectors navigieren und im Drei-Punkte-Menü des Collectors auf der rechten Bildschirmseite Bereitstellung ändern auswählen.
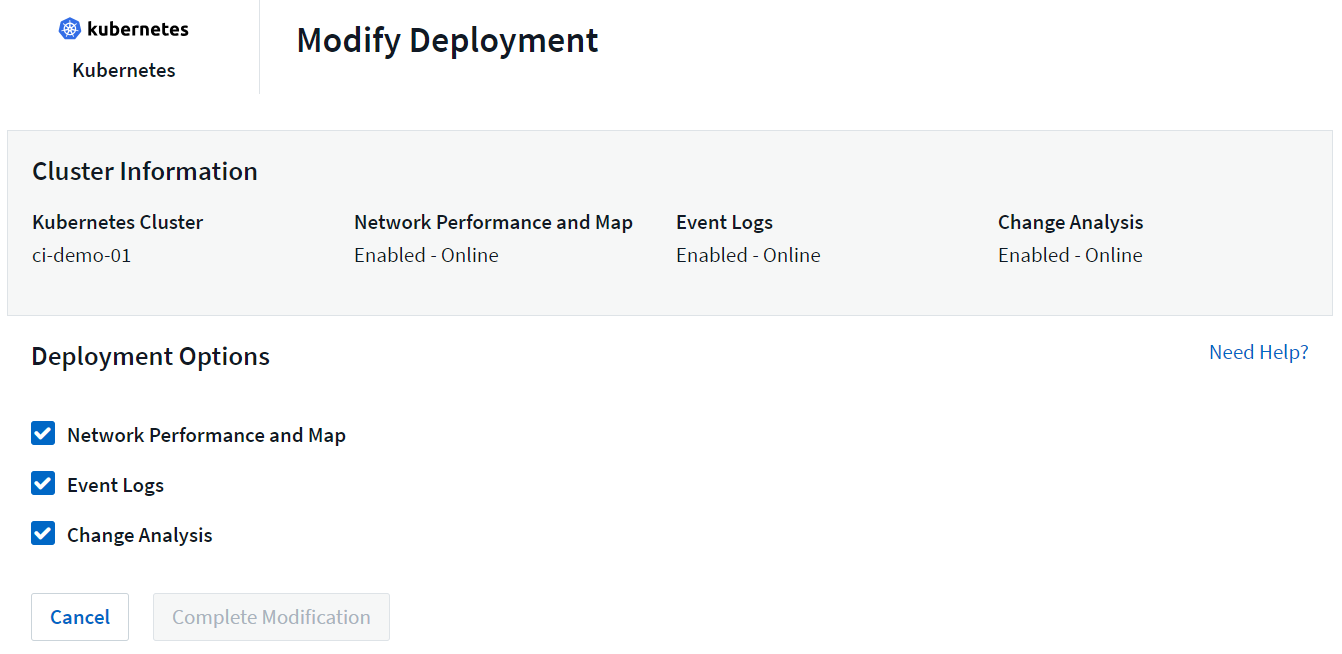
Der Bildschirm zeigt den aktuellen Status jeder Komponente an und ermöglicht Ihnen, Komponenten für diesen Collector nach Bedarf zu deaktivieren oder zu aktivieren.
Upgrade auf den neuesten Kubernetes Monitoring Operator
DII-Druckknopf-Upgrades
Sie können den Kubernetes Monitoring Operator über die DII Kubernetes Collectors-Seite aktualisieren. Klicken Sie auf das Menü neben dem Cluster, den Sie aktualisieren möchten, und wählen Sie Upgrade. Der Betreiber überprüft die Bildsignaturen, erstellt einen Snapshot Ihrer aktuellen Installation und führt das Upgrade durch. Innerhalb weniger Minuten sollte der Status des Operators von „Upgrade läuft“ bis „Neueste“ fortschreiten. Wenn ein Fehler auftritt, können Sie für weitere Einzelheiten den Fehlerstatus auswählen und die Tabelle zur Fehlerbehebung bei Push-Button-Upgrades weiter unten zu Rate ziehen.
Push-Button-Upgrades mit privaten Repositories
Wenn Ihr Operator für die Verwendung eines privaten Repositorys konfiguriert ist, stellen Sie bitte sicher, dass alle zum Ausführen des Operators erforderlichen Bilder und deren Signaturen in Ihrem Repository verfügbar sind. Wenn während des Upgrade-Vorgangs ein Fehler aufgrund fehlender Bilder auftritt, fügen Sie diese einfach zu Ihrem Repository hinzu und versuchen Sie das Upgrade erneut. Um die Bildsignaturen in Ihr Repository hochzuladen, verwenden Sie bitte das Cosign-Tool wie folgt und stellen Sie sicher, dass Sie Signaturen für alle unter 3 angegebenen Bilder hochladen. Optional: Laden Sie die Operatorbilder in Ihr privates Repository hoch > Image Pull Snippet
cosign copy example.com/src:v1 example.com/dest:v1 #Example cosign copy <DII container registry>/netapp-monitoring:<image version> <private repository>/netapp-monitoring:<image version>
Rollback auf eine zuvor ausgeführte Version
Wenn Sie das Upgrade mithilfe der Funktion „Upgrade per Knopfdruck“ durchgeführt haben und innerhalb von sieben Tagen nach dem Upgrade Probleme mit der aktuellen Version des Operators auftreten, können Sie mithilfe des während des Upgrade-Vorgangs erstellten Snapshots ein Downgrade auf die zuvor ausgeführte Version durchführen. Klicken Sie auf das Menü neben dem Cluster, für den Sie ein Rollback durchführen möchten, und wählen Sie Rollback aus.
Manuelle Upgrades
Stellen Sie fest, ob eine Agentenkonfiguration mit dem vorhandenen Operator vorhanden ist (wenn Ihr Namespace nicht der Standardnamespace netapp-monitoring ist, ersetzen Sie ihn durch den entsprechenden Namespace):
kubectl -n netapp-monitoring get agentconfiguration netapp-ci-monitoring-configuration Wenn eine Agentenkonfiguration vorhanden ist:
-
Installierender neueste Operator über den vorhandenen Operator.
-
Stellen Sie sicher, dass SieAbrufen der neuesten Container-Images wenn Sie ein benutzerdefiniertes Repository verwenden.
-
Wenn die Agentenkonfiguration nicht vorhanden ist:
-
Notieren Sie sich den von Data Infrastructure Insights erkannten Clusternamen (wenn Ihr Namespace nicht der Standardnamespace „netapp-monitoring“ ist, ersetzen Sie ihn durch den entsprechenden Namespace):
kubectl -n netapp-monitoring get agent -o jsonpath='{.items[0].spec.cluster-name}' * Erstellen Sie eine Sicherungskopie des vorhandenen Operators (wenn Ihr Namespace nicht der Standard-Netapp-Monitoring-Namespace ist, ersetzen Sie ihn durch den entsprechenden Namespace):kubectl -n netapp-monitoring get agent -o yaml > agent_backup.yaml * <<to-remove-the-kubernetes-monitoring-operator,Deinstallieren>>der bestehende Betreiber. * <<installing-the-kubernetes-monitoring-operator,Installieren>>der neueste Operator.
-
Verwenden Sie denselben Clusternamen.
-
Nachdem Sie die neuesten Operator-YAML-Dateien heruntergeladen haben, portieren Sie vor der Bereitstellung alle in agent_backup.yaml gefundenen Anpassungen in die heruntergeladene operator-config.yaml.
-
Stellen Sie sicher, dass SieAbrufen der neuesten Container-Images wenn Sie ein benutzerdefiniertes Repository verwenden.
-
Stoppen und Starten des Kubernetes-Überwachungsoperators
So stoppen Sie den Kubernetes Monitoring Operator:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=0 So starten Sie den Kubernetes Monitoring Operator:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=1
Deinstallation
So entfernen Sie den Kubernetes Monitoring Operator
Beachten Sie, dass der Standardnamespace für den Kubernetes Monitoring Operator „netapp-monitoring“ ist. Wenn Sie Ihren eigenen Namespace festgelegt haben, ersetzen Sie diesen Namespace in diesen und allen nachfolgenden Befehlen und Dateien.
Neuere Versionen des Monitoring-Operators können mit den folgenden Befehlen deinstalliert werden:
kubectl -n <NAMESPACE> delete agent -l installed-by=nkmo-<NAMESPACE> kubectl -n <NAMESPACE> delete clusterrole,clusterrolebinding,crd,svc,deploy,role,rolebinding,secret,sa -l installed-by=nkmo-<NAMESPACE>
Wenn der Überwachungsoperator in seinem eigenen dedizierten Namespace bereitgestellt wurde, löschen Sie den Namespace:
kubectl delete ns <NAMESPACE> Hinweis: Wenn der erste Befehl „Keine Ressourcen gefunden“ zurückgibt, befolgen Sie die folgenden Anweisungen, um ältere Versionen des Überwachungsoperators zu deinstallieren.
Führen Sie die folgenden Befehle der Reihe nach aus. Abhängig von Ihrer aktuellen Installation können einige dieser Befehle die Meldung „Objekt nicht gefunden“ zurückgeben. Diese Nachrichten können bedenkenlos ignoriert werden.
kubectl -n <NAMESPACE> delete agent agent-monitoring-netapp kubectl delete crd agents.monitoring.netapp.com kubectl -n <NAMESPACE> delete role agent-leader-election-role kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader <NAMESPACE>-agent-manager-role <NAMESPACE>-agent-proxy-role <NAMESPACE>-cluster-role-privileged kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding <NAMESPACE>-agent-manager-rolebinding <NAMESPACE>-agent-proxy-rolebinding <NAMESPACE>-cluster-role-binding-privileged kubectl delete <NAMESPACE>-psp-nkmo kubectl delete ns <NAMESPACE>
Wenn zuvor eine Sicherheitskontextbeschränkung erstellt wurde:
kubectl delete scc telegraf-hostaccess
Über Kube-State-Metrics
Der NetApp Kubernetes Monitoring Operator installiert seine eigenen Kube-State-Metriken, um Konflikte mit anderen Instanzen zu vermeiden.
Informationen zu Kube-State-Metrics finden Sie unter"diese Seite" .
Konfigurieren/Anpassen des Operators
Diese Abschnitte enthalten Informationen zum Anpassen Ihrer Operatorkonfiguration, zum Arbeiten mit Proxy, zum Verwenden eines benutzerdefinierten oder privaten Docker-Repositorys oder zum Arbeiten mit OpenShift.
Konfigurationsoptionen
Die am häufigsten geänderten Einstellungen können in der benutzerdefinierten Ressource AgentConfiguration konfiguriert werden. Sie können diese Ressource vor der Bereitstellung des Operators bearbeiten, indem Sie die Datei operator-config.yaml bearbeiten. Diese Datei enthält auskommentierte Beispiele für Einstellungen. Siehe die Liste der"Verfügbare Einstellungen" für die neueste Version des Operators.
Sie können diese Ressource auch bearbeiten, nachdem der Operator bereitgestellt wurde, indem Sie den folgenden Befehl verwenden:
kubectl -n netapp-monitoring edit AgentConfiguration Um festzustellen, ob Ihre bereitgestellte Version des Operators AgentConfiguration unterstützt, führen Sie den folgenden Befehl aus:
kubectl get crd agentconfigurations.monitoring.netapp.com Wenn die Meldung „Fehler vom Server (Nicht gefunden)“ angezeigt wird, muss Ihr Operator aktualisiert werden, bevor Sie die Agentenkonfiguration verwenden können.
Konfigurieren der Proxy-Unterstützung
Es gibt zwei Stellen, an denen Sie einen Proxy auf Ihrem Mandanten verwenden können, um den Kubernetes Monitoring Operator zu installieren. Dabei kann es sich um dasselbe oder um separate Proxy-Systeme handeln:
-
Proxy, der während der Ausführung des Installationscode-Snippets (mit „curl“) benötigt wird, um das System, auf dem das Snippet ausgeführt wird, mit Ihrer Data Infrastructure Insights -Umgebung zu verbinden
-
Proxy, der vom Ziel-Kubernetes-Cluster zur Kommunikation mit Ihrer Data Infrastructure Insights -Umgebung benötigt wird
Wenn Sie für einen oder beide einen Proxy verwenden, müssen Sie zur Installation des Kubernetes Operating Monitor zunächst sicherstellen, dass Ihr Proxy so konfiguriert ist, dass eine gute Kommunikation mit Ihrer Data Infrastructure Insights Umgebung möglich ist. Wenn Sie über einen Proxy verfügen und von dem Server/der VM, von dem/der Sie den Operator installieren möchten, auf Data Infrastructure Insights zugreifen können, ist Ihr Proxy wahrscheinlich richtig konfiguriert.
Legen Sie für den Proxy, der zur Installation des Kubernetes Operating Monitor verwendet wird, vor der Installation des Operators die Umgebungsvariablen http_proxy/https_proxy fest. Für einige Proxy-Umgebungen müssen Sie möglicherweise auch die Umgebungsvariable no_proxy festlegen.
Um die Variable(n) festzulegen, führen Sie vor der Installation des Kubernetes Monitoring Operator die folgenden Schritte auf Ihrem System aus:
-
Legen Sie die Umgebungsvariable(n) https_proxy und/oder http_proxy für den aktuellen Benutzer fest:
-
Wenn der einzurichtende Proxy keine Authentifizierung (Benutzername/Passwort) hat, führen Sie den folgenden Befehl aus:
export https_proxy=<proxy_server>:<proxy_port> .. Wenn der einzurichtende Proxy über eine Authentifizierung (Benutzername/Passwort) verfügt, führen Sie diesen Befehl aus:
export http_proxy=<proxy_username>:<proxy_password>@<proxy_server>:<proxy_port>
-
Damit der für Ihren Kubernetes-Cluster verwendete Proxy mit Ihrer Data Infrastructure Insights -Umgebung kommunizieren kann, installieren Sie nach dem Lesen aller dieser Anweisungen den Kubernetes Monitoring Operator.
Konfigurieren Sie den Proxy-Abschnitt der AgentConfiguration in operator-config.yaml, bevor Sie den Kubernetes Monitoring Operator bereitstellen.
agent:
...
proxy:
server: <server for proxy>
port: <port for proxy>
username: <username for proxy>
password: <password for proxy>
# In the noproxy section, enter a comma-separated list of
# IP addresses and/or resolvable hostnames that should bypass
# the proxy
noproxy: <comma separated list>
isTelegrafProxyEnabled: true
isFluentbitProxyEnabled: <true or false> # true if Events Log enabled
isCollectorsProxyEnabled: <true or false> # true if Network Performance and Map enabled
isAuProxyEnabled: <true or false> # true if AU enabled
...
...
Verwenden eines benutzerdefinierten oder privaten Docker-Repositorys
Standardmäßig ruft der Kubernetes Monitoring Operator Container-Images aus dem Data Infrastructure Insights Repository ab. Wenn Sie einen Kubernetes-Cluster als Ziel für die Überwachung verwenden und dieser Cluster so konfiguriert ist, dass er nur Container-Images aus einem benutzerdefinierten oder privaten Docker-Repository oder Container-Register abruft, müssen Sie den Zugriff auf die vom Kubernetes Monitoring Operator benötigten Container konfigurieren.
Führen Sie das „Image Pull Snippet“ aus der Installationskachel des NetApp Monitoring Operator aus. Mit diesem Befehl melden Sie sich beim Data Infrastructure Insights -Repository an, rufen alle Bildabhängigkeiten für den Operator ab und melden sich vom Data Infrastructure Insights -Repository ab. Geben Sie bei der entsprechenden Aufforderung das bereitgestellte temporäre Repository-Passwort ein. Dieser Befehl lädt alle vom Bediener verwendeten Bilder herunter, auch für optionale Funktionen. Unten sehen Sie, für welche Funktionen diese Bilder verwendet werden.
Kernoperator-Funktionalität und Kubernetes-Überwachung
-
NetApp-Überwachung
-
ci-kube-rbac-proxy
-
ci-ksm
-
ci-telegraf
-
Distroless-Root-Benutzer
Ereignisprotokoll
-
ci-fluent-bit
-
ci-kubernetes-event-exporter
Netzwerkleistung und Karte
-
ci-net-observer
Übertragen Sie das Operator-Docker-Image gemäß Ihren Unternehmensrichtlinien in Ihr privates/lokales/Unternehmens-Docker-Repository. Stellen Sie sicher, dass die Bild-Tags und Verzeichnispfade zu diesen Bildern in Ihrem Repository mit denen im Data Infrastructure Insights -Repository übereinstimmen.
Bearbeiten Sie die Bereitstellung des Überwachungsoperators in operator-deployment.yaml und ändern Sie alle Bildreferenzen, um Ihr privates Docker-Repository zu verwenden.
image: <docker repo of the enterprise/corp docker repo>/ci-kube-rbac-proxy:<ci-kube-rbac-proxy version> image: <docker repo of the enterprise/corp docker repo>/netapp-monitoring:<version>
Bearbeiten Sie die AgentConfiguration in operator-config.yaml, um den neuen Speicherort des Docker-Repositorys widerzuspiegeln. Erstellen Sie ein neues imagePullSecret für Ihr privates Repository. Weitere Informationen finden Sie unter https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
agent: ... # An optional docker registry where you want docker images to be pulled from as compared to CI's docker registry # Please see documentation link here: link:task_config_telegraf_agent_k8s.html#using-a-custom-or-private-docker-repository dockerRepo: your.docker.repo/long/path/to/test # Optional: A docker image pull secret that maybe needed for your private docker registry dockerImagePullSecret: docker-secret-name
OpenShift-Anweisungen
Wenn Sie OpenShift 4.6 oder höher verwenden, müssen Sie die AgentConfiguration in operator-config.yaml bearbeiten, um die Einstellung runPrivileged zu aktivieren:
# Set runPrivileged to true SELinux is enabled on your kubernetes nodes runPrivileged: true
Openshift implementiert möglicherweise eine zusätzliche Sicherheitsebene, die den Zugriff auf einige Kubernetes-Komponenten blockieren kann.
Toleranzen und Makel
Die DaemonSets netapp-ci-telegraf-ds, netapp-ci-fluent-bit-ds und netapp-ci-net-observer-l4-ds müssen auf jedem Knoten in Ihrem Cluster einen Pod planen, um Daten auf allen Knoten korrekt zu erfassen. Der Operator wurde so konfiguriert, dass er einige bekannte Verunreinigungen toleriert. Wenn Sie benutzerdefinierte Taints auf Ihren Knoten konfiguriert haben und dadurch verhindern, dass Pods auf jedem Knoten ausgeführt werden, können Sie eine Toleranz für diese Taints erstellen."in der AgentConfiguration" . Wenn Sie benutzerdefinierte Taints auf alle Knoten in Ihrem Cluster angewendet haben, müssen Sie der Operatorbereitstellung auch die erforderlichen Toleranzen hinzufügen, damit der Operator-Pod geplant und ausgeführt werden kann.
Mehr über Kubernetes erfahren"Makel und Duldungen" .
Eine Anmerkung zu Geheimnissen
Um dem Kubernetes Monitoring Operator die Berechtigung zum Anzeigen von Geheimnissen im gesamten Cluster zu entziehen, löschen Sie vor der Installation die folgenden Ressourcen aus der Datei operator-setup.yaml:
ClusterRole/netapp-ci<namespace>-agent-secret ClusterRoleBinding/netapp-ci<namespace>-agent-secret
Wenn es sich um ein Upgrade handelt, löschen Sie auch die Ressourcen aus Ihrem Cluster:
kubectl delete ClusterRole/netapp-ci-<namespace>-agent-secret-clusterrole kubectl delete ClusterRoleBinding/netapp-ci-<namespace>-agent-secret-clusterrolebinding
Wenn die Änderungsanalyse aktiviert ist, ändern Sie die Datei AgentConfiguration oder operator-config.yaml, um den Abschnitt zur Änderungsverwaltung zu kommentieren und kindsToIgnoreFromWatch: '"secrets"' in den Abschnitt zur Änderungsverwaltung aufzunehmen. Beachten Sie das Vorhandensein und die Position von einfachen und doppelten Anführungszeichen in dieser Zeile.
change-management: ... # # A comma separated list of kinds to ignore from watching from the default set of kinds watched by the collector # # Each kind will have to be prefixed by its apigroup # # Example: '"networking.k8s.io.networkpolicies,batch.jobs", "authorization.k8s.io.subjectaccessreviews"' kindsToIgnoreFromWatch: '"secrets"' ...
Überprüfen der Bildsignaturen des Kubernetes-Überwachungsoperators
Das Image für den Operator und alle zugehörigen Images, die er bereitstellt, sind von NetApp signiert. Sie können die Images vor der Installation manuell mit dem Cosign-Tool überprüfen oder einen Kubernetes-Zulassungscontroller konfigurieren. Weitere Einzelheiten finden Sie in der"Kubernetes-Dokumentation" .
Der öffentliche Schlüssel, der zum Überprüfen der Bildsignaturen verwendet wird, ist in der Installationskachel des Überwachungsoperators unter Optional: Laden Sie die Operatorbilder in Ihr privates Repository hoch > Öffentlicher Schlüssel der Bildsignatur verfügbar.
Um eine Bildsignatur manuell zu überprüfen, führen Sie die folgenden Schritte aus:
-
Kopieren und führen Sie das Image Pull Snippet aus
-
Kopieren Sie das Repository-Passwort und geben Sie es ein, wenn Sie dazu aufgefordert werden.
-
Speichern Sie den öffentlichen Schlüssel der Bildsignatur (dii-image-signing.pub im Beispiel).
-
Überprüfen Sie die Bilder mit Cosign. Siehe das folgende Beispiel für die Verwendung von Cosign
$ cosign verify --key dii-image-signing.pub --insecure-ignore-sct --insecure-ignore-tlog <repository>/<image>:<tag>
Verification for <repository>/<image>:<tag> --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
[{"critical":{"identity":{"docker-reference":"<repository>/<image>"},"image":{"docker-manifest-digest":"sha256:<hash>"},"type":"cosign container image signature"},"optional":null}]
Fehlerbehebung
Wenn beim Einrichten des Kubernetes Monitoring Operators Probleme auftreten, können Sie Folgendes versuchen:
| Problem: | Versuchen Sie Folgendes: |
|---|---|
Ich sehe keinen Hyperlink/keine Verbindung zwischen meinem Kubernetes Persistent Volume und dem entsprechenden Back-End-Speichergerät. Mein Kubernetes Persistent Volume wird mit dem Hostnamen des Speicherservers konfiguriert. |
Befolgen Sie die Schritte zum Deinstallieren des vorhandenen Telegraf-Agenten und installieren Sie anschließend den neuesten Telegraf-Agenten neu. Sie müssen Telegraf Version 2.0 oder höher verwenden und Ihr Kubernetes-Clusterspeicher muss aktiv von Data Infrastructure Insights überwacht werden. |
Ich sehe in den Protokollen Meldungen, die den folgenden ähneln: E0901 15:21:39.962145 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: *v1.MutatingWebhookConfiguration konnte nicht aufgelistet werden: Der Server konnte die angeforderte Ressource nicht finden. E0901 15:21:43.168161 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: *v1.Lease konnte nicht aufgelistet werden: Der Server konnte die angeforderte Ressource nicht finden (get leases.coordination.k8s.io) usw. |
Diese Meldungen können auftreten, wenn Sie kube-state-metrics Version 2.0.0 oder höher mit Kubernetes-Versionen unter 1.20 ausführen. So erhalten Sie die Kubernetes-Version: kubectl version So erhalten Sie die kube-state-metrics-Version: kubectl get deploy/kube-state-metrics -o jsonpath='{..image}' Um diese Meldungen zu verhindern, können Benutzer ihre kube-state-metrics-Bereitstellung ändern, um die folgenden Leases zu deaktivieren: mutatingwebhookconfigurations validatingwebhookconfigurations volumeattachments resources Genauer gesagt können sie das folgende CLI-Argument verwenden: resources=certificatesigningrequests,configmaps,cronjobs,daemonsets, deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,limitranges, namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes, poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas, secrets,services,statefulsets,storageclasses Die Standardressourcenliste ist: „Zertifikatsignaturanforderungen, Konfigurationszuordnungen, Cronjobs, Daemonsets, Bereitstellungen, Endpunkte, horizontale Pod-Autoskalierer, Ingresses, Jobs, Leases, Grenzwertbereiche, mutierende Webhookkonfigurationen, Namespaces, Netzwerkrichtlinien, Knoten, persistente Volumeansprüche, persistente Volumes, Pod-Unterbrechungsbudgets, Pods, Replikatsets, Replikationscontroller, Ressourcenkontingente, Geheimnisse, Dienste, Statefulsets, Speicherklassen, validierende Webhookkonfigurationen, Volumeanhänge“ |
Ich sehe Fehlermeldungen von Telegraf, die den folgenden ähneln, aber Telegraf wird gestartet und ausgeführt: 11. Okt. 14:23:41 ip-172-31-39-47 systemd[1]: Der Plugin-gesteuerte Server-Agent zum Melden von Metriken in InfluxDB wurde gestartet. 11. Okt. 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="Cache-Verzeichnis konnte nicht erstellt werden. /etc/telegraf/.cache/snowflake, err: mkdir /etc/telegraf/.ca che: Zugriff verweigert. Ignoriert\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11. Okt. 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="Öffnen fehlgeschlagen. Ignoriert. Öffnen Sie /etc/telegraf/.cache/snowflake/ocsp_response_cache.json: keine solche Datei oder kein solches Verzeichnis\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11. Okt. 14:23:41 ip-172-31-39-47 telegraf[1827]: 2021-10-11T14:23:41Z I! Telegraf 1.19.3 wird gestartet |
Dies ist ein bekanntes Problem. Siehe"Dieser GitHub-Artikel" für weitere Details. Solange Telegraf läuft, können Benutzer diese Fehlermeldungen ignorieren. |
Auf Kubernetes melden meine Telegraf-Pods den folgenden Fehler: „Fehler beim Verarbeiten der Mountstats-Informationen: Mountstats-Datei konnte nicht geöffnet werden: /hostfs/proc/1/mountstats, Fehler: Öffnen von /hostfs/proc/1/mountstats: Berechtigung verweigert“ |
Wenn SELinux aktiviert ist und erzwungen wird, verhindert es wahrscheinlich, dass die Telegraf-Pods auf die Datei /proc/1/mountstats auf dem Kubernetes-Knoten zugreifen können. Um diese Einschränkung zu umgehen, bearbeiten Sie die Agentenkonfiguration und aktivieren Sie die Einstellung „runPrivileged“. Weitere Einzelheiten finden Sie in den OpenShift-Anweisungen. |
Auf Kubernetes meldet mein Telegraf ReplicaSet-Pod den folgenden Fehler: [inputs.prometheus] Fehler im Plugin: Schlüsselpaar /etc/kubernetes/pki/etcd/server.crt konnte nicht geladen werden:/etc/kubernetes/pki/etcd/server.key: öffne /etc/kubernetes/pki/etcd/server.crt: keine solche Datei oder kein solches Verzeichnis |
Der Telegraf ReplicaSet-Pod soll auf einem Knoten ausgeführt werden, der als Master oder für etcd bestimmt ist. Wenn der ReplicaSet-Pod auf einem dieser Knoten nicht ausgeführt wird, werden diese Fehler angezeigt. Überprüfen Sie, ob Ihre Master-/etcd-Knoten Verunreinigungen aufweisen. Wenn dies der Fall ist, fügen Sie die erforderlichen Toleranzen zum Telegraf ReplicaSet, telegraf-rs, hinzu. Bearbeiten Sie beispielsweise das ReplicaSet … kubectl edit rs telegraf-rs … und fügen Sie der Spezifikation die entsprechenden Toleranzen hinzu. Starten Sie dann den ReplicaSet-Pod neu. |
Ich habe eine PSP/PSA-Umgebung. Betrifft dies meinen Überwachungsbetreiber? |
Wenn Ihr Kubernetes-Cluster mit Pod Security Policy (PSP) oder Pod Security Admission (PSA) ausgeführt wird, müssen Sie auf den neuesten Kubernetes Monitoring Operator aktualisieren. Befolgen Sie diese Schritte, um auf den aktuellen Operator mit Unterstützung für PSP/PSA zu aktualisieren: 1. Deinstallieren der vorherige Überwachungsoperator: kubectl delete agent agent-monitoring-netapp -n netapp-monitoring kubectl delete ns netapp-monitoring kubectl delete crd agents.monitoring.netapp.com kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding 2. Installieren die neueste Version des Überwachungsoperators. |
Beim Versuch, den Operator bereitzustellen, sind mir Probleme begegnet, und ich verwende PSP/PSA. |
1. Bearbeiten Sie den Agenten mit dem folgenden Befehl: kubectl -n <name-space> edit agent 2. Markieren Sie „security-policy-enabled“ als „false“. Dadurch werden die Pod-Sicherheitsrichtlinien und die Pod-Sicherheitszulassung deaktiviert und dem Operator die Bereitstellung ermöglicht. Bestätigen Sie mit den folgenden Befehlen: kubectl get psp (sollte anzeigen, dass die Pod-Sicherheitsrichtlinie entfernt wurde) kubectl get all -n <namespace> |
grep -i psp (sollte anzeigen, dass nichts gefunden wurde) |
„ImagePullBackoff“-Fehler aufgetreten |
Diese Fehler können auftreten, wenn Sie über ein benutzerdefiniertes oder privates Docker-Repository verfügen und den Kubernetes Monitoring Operator noch nicht so konfiguriert haben, dass es ordnungsgemäß erkannt wird. Mehr lesen Informationen zur Konfiguration für benutzerdefinierte/private Repos. |
Ich habe ein Problem mit der Bereitstellung meines Überwachungsoperators und die aktuelle Dokumentation hilft mir nicht bei der Lösung. |
Erfassen oder notieren Sie die Ausgabe der folgenden Befehle und wenden Sie sich an das technische Supportteam. kubectl -n netapp-monitoring get all kubectl -n netapp-monitoring describe all kubectl -n netapp-monitoring logs <monitoring-operator-pod> --all-containers=true kubectl -n netapp-monitoring logs <telegraf-pod> --all-containers=true |
Net-Observer-Pods (Workload Map) im Operator-Namespace befinden sich in CrashLoopBackOff |
Diese Pods entsprechen dem Workload Map-Datensammler für die Netzwerkbeobachtung. Versuchen Sie Folgendes: • Überprüfen Sie die Protokolle eines der Pods, um die Mindestkernelversion zu bestätigen. Beispiel: ---- {"ci-tenant-id":"Ihre Mandanten-ID","collector-cluster":"Ihr K8S-Clustername","environment":"prod","level":"error","msg":"Validierung fehlgeschlagen. Grund: Kernelversion 3.10.0 ist niedriger als die Mindestkernelversion 4.18.0","time":"2022-11-09T08:23:08Z"} ---- • Net-Observer-Pods erfordern mindestens die Linux-Kernelversion 4.18.0. Überprüfen Sie die Kernelversion mit dem Befehl „uname -r“ und stellen Sie sicher, dass sie >= 4.18.0 ist |
Pods werden im Operator-Namespace ausgeführt (Standard: Netapp-Monitoring), aber in der Benutzeroberfläche werden keine Daten für die Workload-Map oder Kubernetes-Metriken in Abfragen angezeigt. |
Überprüfen Sie die Zeiteinstellung auf den Knoten des K8S-Clusters. Für eine genaue Prüfung und Datenberichterstattung wird dringend empfohlen, die Zeit auf dem Agent-Computer mithilfe des Network Time Protocol (NTP) oder Simple Network Time Protocol (SNTP) zu synchronisieren. |
Einige der Net-Observer-Pods im Operator-Namespace befinden sich im Status „Ausstehend“ |
Net-Observer ist ein DaemonSet und führt in jedem Knoten des K8S-Clusters einen Pod aus. • Beachten Sie den Pod, der sich im Status „Ausstehend“ befindet, und prüfen Sie, ob ein Ressourcenproblem für die CPU oder den Speicher vorliegt. Stellen Sie sicher, dass im Knoten genügend Speicher und CPU verfügbar sind. |
Unmittelbar nach der Installation des Kubernetes Monitoring Operator wird mir in meinen Protokollen Folgendes angezeigt: [inputs.prometheus] Fehler im Plug-In: Fehler beim Senden der HTTP-Anforderung an http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics: Get http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics: dial tcp: lookup kube-state-metrics.<namespace>.svc.cluster.local: no such host |
Diese Meldung wird normalerweise nur angezeigt, wenn ein neuer Operator installiert wird und der telegraf-rs-Pod vor dem ksm-Pod aktiv ist. Diese Nachrichten sollten aufhören, sobald alle Pods ausgeführt werden. |
Ich sehe keine erfassten Metriken für die in meinem Cluster vorhandenen Kubernetes-CronJobs. |
Überprüfen Sie Ihre Kubernetes-Version (d. h. |
Nach der Installation des Operators treten die Telegraf-DS-Pods in CrashLoopBackOff ein und die Pod-Protokolle zeigen „su: Authentifizierungsfehler“ an. |
Bearbeiten Sie den Telegraf-Abschnitt in AgentConfiguration und setzen Sie dockerMetricCollectionEnabled auf „false“. Weitere Einzelheiten finden Sie in der Betriebsanleitung des Betreibers."Konfigurationsoptionen" . … Spezifikation: … Telegraf: … - Name: Docker-Ausführungsmodus: - DaemonSet-Ersetzungen: - Schlüssel: DOCKER_UNIX_SOCK_PLACEHOLDER-Wert: unix:///run/docker.sock … … |
In meinen Telegraf-Protokollen werden immer wieder Fehlermeldungen angezeigt, die den folgenden ähneln: E! [Agent] Fehler beim Schreiben in outputs.http: Post "https://<tenant_url>/rest/v1/lake/ingest/influxdb": Kontextfrist überschritten (Client.Timeout beim Warten auf Header überschritten) |
Bearbeiten Sie den Telegraf-Abschnitt in AgentConfiguration und erhöhen Sie outputTimeout auf 10 s. Weitere Einzelheiten finden Sie in der Betriebsanleitung des Betreibers."Konfigurationsoptionen" . |
Mir fehlen involvedobject-Daten für einige Ereignisprotokolle. |
Stellen Sie sicher, dass Sie die Schritte in der"Berechtigungen" Abschnitt oben. |
Warum werden zwei Überwachungsoperator-Pods ausgeführt, einer mit dem Namen netapp-ci-monitoring-operator-<pod> und der andere mit dem Namen monitoring-operator-<pod>? |
Ab dem 12. Oktober 2023 hat Data Infrastructure Insights den Operator überarbeitet, um unseren Benutzern einen besseren Service zu bieten. Damit diese Änderungen vollständig übernommen werden können, müssen SieEntfernen Sie den alten Operator Undinstallieren Sie die neue . |
Meine Kubernetes-Ereignisse wurden unerwartet nicht mehr an Data Infrastructure Insights gemeldet. |
Rufen Sie den Namen des Event-Exporter-Pods ab: `kubectl -n netapp-monitoring get pods |
grep event-exporter |
awk '{print $1}' |
sed 's/event-exporter./event-exporter/'` |
Ich sehe, dass vom Kubernetes Monitoring Operator bereitgestellte Pods aufgrund unzureichender Ressourcen abstürzen. |
Siehe den Kubernetes Monitoring Operator"Konfigurationsoptionen" um die CPU- und/oder Speichergrenzen nach Bedarf zu erhöhen. |
Ein fehlendes Image oder eine ungültige Konfiguration führte dazu, dass die netapp-ci-kube-state-metrics-Pods nicht gestartet werden konnten oder nicht bereit waren. Jetzt steckt das StatefulSet fest und Konfigurationsänderungen werden nicht auf die Netapp-CI-Kube-State-Metrics-Pods angewendet. |
Das StatefulSet ist in einem"gebrochen" Zustand. Nachdem Sie alle Konfigurationsprobleme behoben haben, führen Sie einen Bounce der Netapp-CI-Kube-State-Metrics-Pods durch. |
netapp-ci-kube-state-metrics-Pods können nach der Ausführung eines Kubernetes Operator-Upgrades nicht gestartet werden und lösen ErrImagePull aus (das Abrufen des Images schlägt fehl). |
Versuchen Sie, die Pods manuell zurückzusetzen. |
Bei der Protokollanalyse werden für meinen Kubernetes-Cluster Meldungen vom Typ „Ereignis verworfen, da es älter ist als maxEventAgeSeconds“ beobachtet. |
Ändern Sie die Operator-Agentenkonfiguration und erhöhen Sie event-exporter-maxEventAgeSeconds (z. B. auf 60 s), event-exporter-kubeQPS (z. B. auf 100) und event-exporter-kubeBurst (z. B. auf 500). Weitere Einzelheiten zu diesen Konfigurationsoptionen finden Sie im"Konfigurationsoptionen" Seite. |
Telegraf warnt vor unzureichendem sperrbaren Speicher oder stürzt ab. |
Versuchen Sie, das Limit des sperrbaren Speichers für Telegraf im zugrunde liegenden Betriebssystem/Knoten zu erhöhen. Wenn eine Erhöhung des Limits keine Option ist, ändern Sie die NKMO-Agentenkonfiguration und setzen Sie unprotected auf true. Dadurch wird Telegraf angewiesen, keinen Versuch zu unternehmen, gesperrte Speicherseiten zu reservieren. Dies kann zwar ein Sicherheitsrisiko darstellen, da entschlüsselte Geheimnisse möglicherweise auf die Festplatte ausgelagert werden, ermöglicht jedoch die Ausführung in Umgebungen, in denen die Reservierung gesperrten Speichers nicht möglich ist. Weitere Informationen zu den ungeschützten Konfigurationsoptionen finden Sie im"Konfigurationsoptionen" Seite. |
Ich sehe Warnmeldungen von Telegraf, die etwa wie folgt aussehen: W! [inputs.diskio] Der Datenträgername für „vdc“ konnte nicht ermittelt werden: Fehler beim Lesen von /dev/vdc: keine solche Datei oder kein solches Verzeichnis |
Für den Kubernetes Monitoring Operator sind diese Warnmeldungen harmlos und können ignoriert werden. Alternativ können Sie den Abschnitt „Telegraf“ in der AgentConfiguration bearbeiten und runDsPrivileged auf „true“ setzen. Weitere Einzelheiten finden Sie im"Konfigurationsoptionen des Betreibers" . |
Mein Fluent-Bit-Pod schlägt mit den folgenden Fehlern fehl: [2024/10/16 14:16:23] [Fehler] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:360 errno=24] Zu viele offene Dateien [2024/10/16 14:16:23] [Fehler] Initialisierung der Eingabe tail.0 fehlgeschlagen [2024/10/16 14:16:23] [Fehler] [Engine] Initialisierung der Eingabe fehlgeschlagen |
Versuchen Sie, Ihre fsnotify-Einstellungen in Ihrem Cluster zu ändern: sudo sysctl fs.inotify.max_user_instances (take note of setting) sudo sysctl fs.inotify.max_user_instances=<something larger than current setting> sudo sysctl fs.inotify.max_user_watches (take note of setting) sudo sysctl fs.inotify.max_user_watches=<something larger than current setting> Starten Sie Fluent-bit neu. Hinweis: Um diese Einstellungen auch nach einem Neustart des Knotens dauerhaft zu halten, müssen Sie die folgenden Zeilen in /etc/sysctl.conf einfügen. fs.inotify.max_user_instances=<something larger than current setting> fs.inotify.max_user_watches=<something larger than current setting> |
Die Telegraf DS-Pods melden Fehler im Zusammenhang mit dem Kubernetes-Eingabe-Plugin, das keine HTTP-Anfragen stellen kann, da das TLS-Zertifikat nicht validiert werden kann. Zum Beispiel: E! [inputs.kubernetes] Fehler im Plugin: Fehler beim Senden einer HTTP-Anfrage an"https://<kubelet_IP>:10250/stats/summary": Erhalten"https://<kubelet_IP>:10250/stats/summary": tls: Zertifikat konnte nicht überprüft werden: x509: Zertifikat für <kubelet_IP> kann nicht validiert werden, da es keine IP-SANs enthält |
Dies tritt auf, wenn das Kubelet selbstsignierte Zertifikate verwendet und/oder das angegebene Zertifikat die <kubelet_IP> nicht in der Liste „Subject Alternative Name“ des Zertifikats enthält. Um dieses Problem zu lösen, kann der Benutzer die"Agentenkonfiguration" , und setzen Sie telegraf:insecureK8sSkipVerify auf true. Dadurch wird das Telegraf-Eingabe-Plugin so konfiguriert, dass die Überprüfung übersprungen wird. Alternativ kann der Benutzer das Kubelet konfigurieren für"serverTLSBootstrap" , wodurch eine Zertifikatsanforderung von der API „certificates.k8s.io“ ausgelöst wird. |
Weitere Informationen finden Sie in der"Support" Seite oder in der"Datensammler-Supportmatrix" .