Wichtige Anwendungsfälle und Architekturen für KI, ML und DL
 Änderungen vorschlagen
Änderungen vorschlagen
Die wichtigsten Anwendungsfälle und Methoden für KI, ML und DL können in die folgenden Abschnitte unterteilt werden:
Spark NLP-Pipelines und verteilte TensorFlow-Inferenz
Die folgende Liste enthält die beliebtesten Open-Source-NLP-Bibliotheken, die von der Data-Science-Community in unterschiedlichen Entwicklungsstufen übernommen wurden:
-
"Toolkit für natürliche Sprache (NLTK)" . Das komplette Toolkit für alle NLP-Techniken. Es wird seit Anfang der 2000er Jahre gepflegt.
-
"TextBlob" . Eine benutzerfreundliche Python-API für NLP-Tools, die auf NLTK und Pattern basiert.
-
"Stanford Core NLP" . NLP-Dienste und -Pakete in Java, entwickelt von der Stanford NLP Group.
-
"Gensim" . „Topic Modelling for Humans“ begann als Sammlung von Python-Skripten für das Projekt „Czech Digital Mathematics Library“.
-
"SpaCy" . End-to-End-NLP-Workflows für die Industrie mit Python und Cython mit GPU-Beschleunigung für Transformatoren.
-
"Fasttext" . Eine kostenlose, leichtgewichtige Open-Source-NLP-Bibliothek zum Lernen von Wort-Embeddings und zur Satzklassifizierung, die vom AI Research (FAIR)-Labor von Facebook erstellt wurde.
Spark NLP ist eine einzige, einheitliche Lösung für alle NLP-Aufgaben und -Anforderungen, die skalierbare, leistungsstarke und hochpräzise NLP-basierte Software für echte Produktionsanwendungsfälle ermöglicht. Es nutzt Transferlernen und implementiert die neuesten hochmodernen Algorithmen und Modelle in der Forschung und branchenübergreifend. Aufgrund der fehlenden vollständigen Unterstützung durch Spark für die oben genannten Bibliotheken wurde Spark NLP auf Basis von "Spark ML" um die Vorteile der universellen verteilten In-Memory-Datenverarbeitungs-Engine von Spark als NLP-Bibliothek der Enterprise-Klasse für unternehmenskritische Produktionsabläufe zu nutzen. Seine Annotatoren nutzen regelbasierte Algorithmen, maschinelles Lernen und TensorFlow, um Deep-Learning-Implementierungen zu unterstützen. Dies umfasst gängige NLP-Aufgaben, einschließlich, aber nicht beschränkt auf Tokenisierung, Lemmatisierung, Stemming, Part-of-Speech-Tagging, Named-Entity-Erkennung, Rechtschreibprüfung und Stimmungsanalyse.
Bidirectional Encoder Representations from Transformers (BERT) ist eine transformerbasierte maschinelle Lerntechnik für NLP. Es machte das Konzept des Vortrainings und der Feinabstimmung populär. Die Transformer-Architektur in BERT stammt aus der maschinellen Übersetzung, die langfristige Abhängigkeiten besser modelliert als auf rekurrenten neuronalen Netzwerken (RNN) basierende Sprachmodelle. Außerdem wurde die Masked Language Modelling (MLM)-Aufgabe eingeführt, bei der zufällig 15 % aller Token maskiert werden und das Modell sie vorhersagt, wodurch echte Bidirektionalität ermöglicht wird.
Aufgrund der Fachsprache und des Mangels an gekennzeichneten Daten in diesem Bereich ist die Analyse der Finanzstimmung eine Herausforderung. FinBERT, ein Sprachmodell basierend auf vortrainiertem BERT, wurde domänenangepasst auf "Reuters TRC2" , ein Finanzkorpus, und mit gekennzeichneten Daten fein abgestimmt ( "Finanzielle PhraseBank" ) zur Klassifizierung der Finanzstimmung. Forscher extrahierten 4.500 Sätze aus Nachrichtenartikeln mit Finanzbegriffen. Anschließend bewerteten 16 Experten und Masterstudenten mit Finanzhintergrund die Sätze als positiv, neutral und negativ. Wir haben einen End-to-End-Spark-Workflow erstellt, um die Stimmung für die Transkripte der Telefonkonferenzen zu den Top-10-Gewinnzahlen der NASDAQ-Unternehmen von 2016 bis 2020 mithilfe von FinBERT und zwei weiteren vortrainierten Pipelines zu analysieren. "Dokument DL erklären" ) von Spark NLP.
Die zugrunde liegende Deep-Learning-Engine für Spark NLP ist TensorFlow, eine durchgängige Open-Source-Plattform für maschinelles Lernen, die eine einfache Modellerstellung, eine robuste ML-Produktion überall und leistungsstarke Experimente für die Forschung ermöglicht. Daher, wenn wir unsere Pipelines in Spark ausführen yarn cluster Im Modus führten wir im Wesentlichen verteiltes TensorFlow mit Daten- und Modellparallelisierung über einen Master- und mehrere Worker-Knoten sowie über einen auf dem Cluster montierten Netzwerkspeicher aus.
Horovod verteiltes Training
Die zentrale Hadoop-Validierung für die MapReduce-bezogene Leistung wird mit TeraGen, TeraSort, TeraValidate und DFSIO (Lesen und Schreiben) durchgeführt. Die Validierungsergebnisse von TeraGen und TeraSort werden in "NetApp E-Series-Lösung für Hadoop" und im Abschnitt „Storage Tiering“ für AFF.
Aufgrund von Kundenanfragen betrachten wir das verteilte Training mit Spark als einen der wichtigsten der verschiedenen Anwendungsfälle. In diesem Dokument haben wir die "Hovorod auf Spark" um die Spark-Leistung mit lokalen, Cloud-nativen und Hybrid-Cloud-Lösungen von NetApp unter Verwendung von NetApp All Flash FAS (AFF)-Speichercontrollern, Azure NetApp Files und StorageGRID zu validieren.
Das Horovod on Spark-Paket bietet einen praktischen Wrapper um Horovod, der die Ausführung verteilter Trainings-Workloads in Spark-Clustern vereinfacht und eine enge Modelldesignschleife ermöglicht, in der Datenverarbeitung, Modelltraining und Modellbewertung alle in Spark erfolgen, wo sich die Trainings- und Inferenzdaten befinden.
Es gibt zwei APIs zum Ausführen von Horovod auf Spark: eine Estimator-API auf hoher Ebene und eine Run-API auf niedrigerer Ebene. Obwohl beide denselben zugrunde liegenden Mechanismus zum Starten von Horovod auf Spark-Executoren verwenden, abstrahiert die Estimator-API die Datenverarbeitung, die Modelltrainingsschleife, die Modellprüfpunkte, die Metrikerfassung und das verteilte Training. Wir verwendeten Horovod Spark Estimators, TensorFlow und Keras für eine End-to-End-Datenaufbereitung und einen verteilten Trainings-Workflow basierend auf dem "Kaggle Rossmann Store Sales" Wettbewerb.
Das Drehbuch keras_spark_horovod_rossmann_estimator.py finden Sie im Abschnitt"Python-Skripte für jeden wichtigen Anwendungsfall." Es besteht aus drei Teilen:
-
Der erste Teil führt verschiedene Schritte zur Datenvorverarbeitung für einen ersten Satz von CSV-Dateien durch, die von Kaggle bereitgestellt und von der Community gesammelt wurden. Die Eingabedaten werden in einen Trainingssatz mit einem
ValidationTeilmenge und ein Testdatensatz. -
Der zweite Teil definiert ein Keras Deep Neural Network (DNN)-Modell mit logarithmischer Sigmoid-Aktivierungsfunktion und einem Adam-Optimierer und führt ein verteiltes Training des Modells mit Horovod auf Spark durch.
-
Der dritte Teil führt eine Vorhersage für den Testdatensatz durch, wobei das beste Modell verwendet wird, das den mittleren absoluten Gesamtfehler des Validierungssatzes minimiert. Anschließend wird eine CSV-Ausgabedatei erstellt.
Siehe den Abschnitt"Maschinelles Lernen" für verschiedene Laufzeitvergleichsergebnisse.
Multi-Worker-Deep-Learning mit Keras zur CTR-Vorhersage
Angesichts der jüngsten Fortschritte bei ML-Plattformen und -Anwendungen richtet sich der Fokus nun stark auf das Lernen im großen Maßstab. Die Klickrate (Click-Through-Rate, CTR) ist definiert als die durchschnittliche Anzahl von Klicks pro hundert Online-Anzeigenimpressionen (ausgedrückt als Prozentsatz). Es wird in zahlreichen Branchen und Anwendungsfällen, darunter digitales Marketing, Einzelhandel, E-Commerce und Dienstleister, als Schlüsselkennzahl eingesetzt. Weitere Einzelheiten zu den Anwendungen von CTR und verteilten Trainingsleistungsergebnissen finden Sie im"Deep-Learning-Modelle für die CTR-Vorhersageleistung" Abschnitt.
In diesem technischen Bericht verwendeten wir eine Variante des "Criteo Terabyte Click Logs-Datensatz" (siehe TR-4904) für verteiltes Deep Learning mit mehreren Workern unter Verwendung von Keras zum Erstellen eines Spark-Workflows mit Deep- und Cross-Network-Modellen (DCN), wobei die Leistung hinsichtlich der Log-Loss-Fehlerfunktion mit einem Basismodell der logistischen Regression von Spark ML verglichen wird. DCN erfasst effizient effektive Merkmalsinteraktionen begrenzten Grades, lernt hochgradig nichtlineare Interaktionen, erfordert keine manuelle Merkmalsentwicklung oder umfassende Suche und weist einen geringen Rechenaufwand auf.
Daten für Empfehlungssysteme im Webmaßstab sind größtenteils diskret und kategorisch, was zu einem großen und spärlichen Merkmalsraum führt, der die Merkmalserkundung erschwert. Dies hat die meisten groß angelegten Systeme auf lineare Modelle wie die logistische Regression beschränkt. Der Schlüssel zu guten Vorhersagen liegt jedoch darin, häufig vorhersagbare Merkmale zu identifizieren und gleichzeitig ungesehene oder seltene Kreuzmerkmale zu untersuchen. Lineare Modelle sind einfach, interpretierbar und leicht skalierbar, ihre Ausdruckskraft ist jedoch begrenzt.
Andererseits hat sich gezeigt, dass Kreuzmerkmale für die Verbesserung der Ausdruckskraft der Modelle von Bedeutung sind. Leider ist zur Identifizierung solcher Features häufig eine manuelle Feature-Entwicklung oder eine umfassende Suche erforderlich. Die Verallgemeinerung auf unsichtbare Funktionsinteraktionen ist oft schwierig. Durch die Verwendung eines gekreuzten neuronalen Netzwerks wie DCN wird aufgabenspezifisches Feature Engineering vermieden, indem Feature-Crossing explizit und automatisch angewendet wird. Das Kreuznetzwerk besteht aus mehreren Schichten, wobei der höchste Grad an Interaktionen nachweislich durch die Schichttiefe bestimmt wird. Jede Schicht erzeugt Interaktionen höherer Ordnung auf der Grundlage bestehender Interaktionen und behält die Interaktionen der vorherigen Schichten bei.
Ein tiefes neuronales Netzwerk (DNN) verspricht, sehr komplexe Interaktionen zwischen Features zu erfassen. Im Vergleich zu DCN erfordert es jedoch fast eine Größenordnung mehr Parameter, kann keine Kreuzmerkmale explizit bilden und kann einige Arten von Merkmalsinteraktionen möglicherweise nicht effizient erlernen. Das Cross-Network ist speichereffizient und einfach zu implementieren. Durch das gemeinsame Training der Cross- und DNN-Komponenten werden prädiktive Feature-Interaktionen effizient erfasst und eine hochmoderne Leistung im Criteo CTR-Datensatz erzielt.
Ein DCN-Modell beginnt mit einer Einbettungs- und Stapelschicht, gefolgt von einem Quernetzwerk und einem tiefen Netzwerk parallel. Darauf folgt wiederum eine letzte Kombinationsschicht, die die Ausgaben der beiden Netzwerke kombiniert. Ihre Eingabedaten können ein Vektor mit spärlichen und dichten Merkmalen sein. In Spark enthalten die Bibliotheken den Typ SparseVector . Daher ist es für Benutzer wichtig, zwischen den beiden zu unterscheiden und beim Aufrufen der jeweiligen Funktionen und Methoden vorsichtig zu sein. In webbasierten Empfehlungssystemen wie der CTR-Vorhersage sind die Eingaben meist kategorische Merkmale, zum Beispiel 'country=usa' . Solche Merkmale werden oft als One-Hot-Vektoren kodiert, zum Beispiel: '[0,1,0, …]' . One-Hot-Encoding (OHE) mit SparseVector ist nützlich, wenn Sie mit realen Datensätzen mit sich ständig änderndem und wachsendem Vokabular arbeiten. Wir haben Beispiele in "DeepCTR" um große Vokabulare zu verarbeiten und Einbettungsvektoren in der Einbettungs- und Stapelschicht unseres DCN zu erstellen.
Der "Criteo Display Ads-Datensatz" sagt die Klickrate der Anzeigen voraus. Es verfügt über 13 ganzzahlige Merkmale und 26 kategorische Merkmale, wobei jede Kategorie eine hohe Kardinalität aufweist. Für diesen Datensatz ist aufgrund der großen Eingabegröße eine Verbesserung des Logverlusts um 0,001 praktisch signifikant. Eine kleine Verbesserung der Vorhersagegenauigkeit für eine große Benutzerbasis kann möglicherweise zu einer erheblichen Steigerung des Umsatzes eines Unternehmens führen. Der Datensatz enthält 11 GB Benutzerprotokolle aus einem Zeitraum von 7 Tagen, was etwa 41 Millionen Datensätzen entspricht. Wir haben Spark verwendet dataFrame.randomSplit()function die Daten nach dem Zufallsprinzip für das Training (80 %), die Kreuzvalidierung (10 %) und die restlichen 10 % für Tests aufzuteilen.
DCN wurde auf TensorFlow mit Keras implementiert. Bei der Implementierung des Modelltrainingsprozesses mit DCN gibt es vier Hauptkomponenten:
-
Datenverarbeitung und -einbettung. Realwertige Merkmale werden durch Anwenden einer Log-Transformation normalisiert. Für kategorische Merkmale betten wir die Merkmale in dichte Vektoren der Dimension 6 × (Kategoriekardinalität) 1/4 ein. Durch Verketten aller Einbettungen entsteht ein Vektor der Dimension 1026.
-
Optimierung. Wir haben eine stochastische Mini-Batch-Optimierung mit dem Adam-Optimierer angewendet. Die Batchgröße wurde auf 512 festgelegt. Auf das tiefe Netzwerk wurde eine Batch-Normalisierung angewendet und die Gradienten-Clip-Norm auf 100 festgelegt.
-
Regularisierung. Wir haben ein frühes Stoppen verwendet, da sich die L2-Regularisierung oder das Dropout als nicht wirksam erwiesen haben.
-
Hyperparameter. Wir berichten über Ergebnisse, die auf einer Rastersuche über die Anzahl der verborgenen Schichten, die Größe der verborgenen Schichten, die anfängliche Lernrate und die Anzahl der Kreuzschichten basieren. Die Anzahl der verborgenen Schichten lag zwischen 2 und 5, wobei die Größe der verborgenen Schichten zwischen 32 und 1024 lag. Bei DCN lag die Anzahl der Querschichten zwischen 1 und 6. Die anfängliche Lernrate wurde in Schritten von 0,0001 von 0,0001 auf 0,001 eingestellt. Bei allen Experimenten wurde ein frühzeitiger Stopp bei Trainingsschritt 150.000 angewendet, da ab diesem Zeitpunkt eine Überanpassung eintrat.
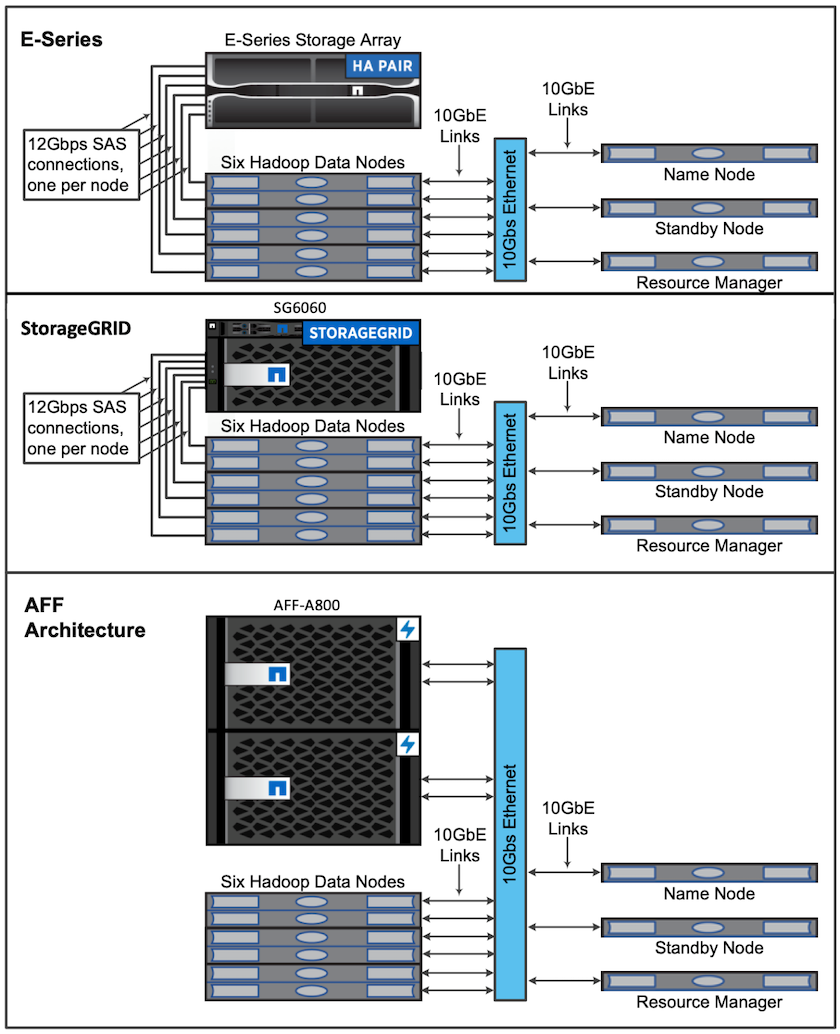
Zur Validierung verwendete Architekturen
Für diese Validierung haben wir vier Worker-Knoten und einen Master-Knoten mit einem AFF-A800-HA-Paar verwendet. Alle Clustermitglieder waren über 10GbE-Netzwerk-Switches verbunden.
Für diese Validierung der NetApp Spark-Lösung haben wir drei verschiedene Speichercontroller verwendet: den E5760, den E5724 und den AFF-A800. Die Speichercontroller der E-Serie wurden mit 12-Gbit/s-SAS-Verbindungen an fünf Datenknoten angeschlossen. Der AFF HA-Paar-Speichercontroller stellt exportierte NFS-Volumes über 10-GbE-Verbindungen für Hadoop-Workerknoten bereit. Die Hadoop-Clustermitglieder wurden über 10-GbE-Verbindungen in den Hadoop-Lösungen E-Series, AFF und StorageGRID verbunden.