

NVA-1173 NetApp AIPod mit NVIDIA DGX H100-Systemen – Lösungsarchitektur
 Änderungen vorschlagen
Änderungen vorschlagen
Dieser Abschnitt konzentriert sich auf die Architektur für den NetApp AIPod mit NVIDIA DGX-Systemen.
NetApp AIPod mit DGX-Systemen
Diese Referenzarchitektur nutzt separate Fabrics für die Verbindung von Rechenclustern und den Speicherzugriff mit 400 Gb/s InfiniBand (IB)-Konnektivität zwischen Rechenknoten. Die folgende Zeichnung zeigt die Gesamtlösungstopologie von NetApp AIPod mit DGX H100-Systemen.
Topologie der NetApp AIpod-Lösung
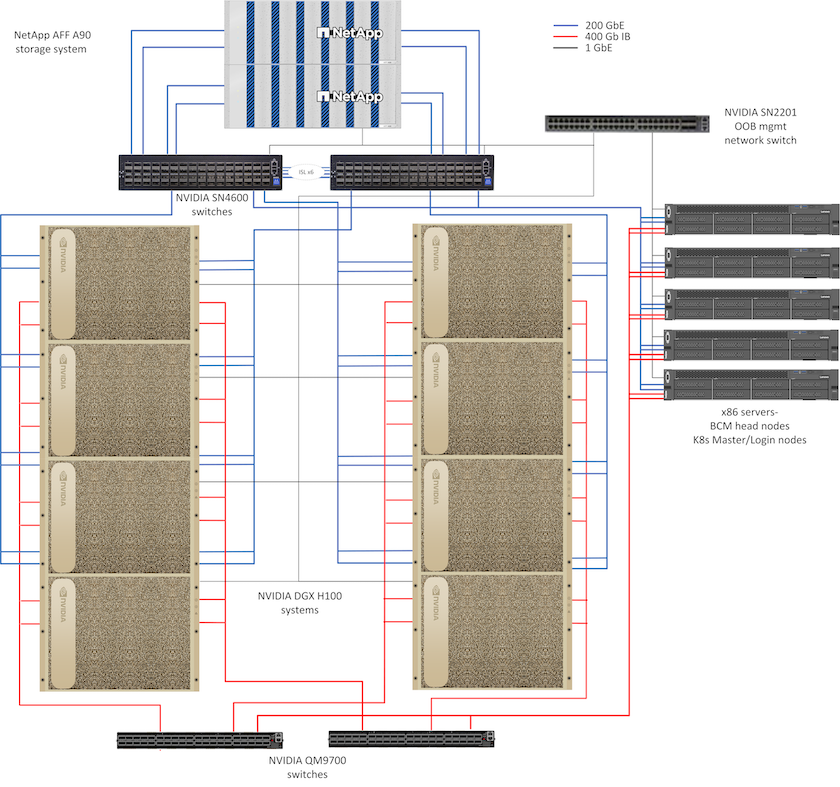
Netzwerkdesign
In dieser Konfiguration verwendet das Compute-Cluster-Fabric ein Paar QM9700 400Gb/s IB-Switches, die für eine hohe Verfügbarkeit miteinander verbunden sind. Jedes DGX H100-System ist über acht Verbindungen mit den Switches verbunden, wobei die Ports mit geraden Nummern mit einem Switch und die Ports mit ungeraden Nummern mit dem anderen Switch verbunden sind.
Für den Zugriff auf das Speichersystem, die In-Band-Verwaltung und den Clientzugriff wird ein Paar SN4600-Ethernet-Switches verwendet. Die Switches sind über Inter-Switch-Links verbunden und mit mehreren VLANs konfiguriert, um die verschiedenen Verkehrstypen zu isolieren. Grundlegendes L3-Routing wird zwischen bestimmten VLANs aktiviert, um mehrere Pfade zwischen Client- und Speicherschnittstellen auf demselben Switch sowie zwischen Switches für hohe Verfügbarkeit zu ermöglichen. Bei größeren Bereitstellungen kann das Ethernet-Netzwerk durch Hinzufügen zusätzlicher Switch-Paare für Spine-Switches und zusätzlicher Leaves nach Bedarf auf eine Leaf-Spine-Konfiguration erweitert werden.
Zusätzlich zur Computerverbindung und den Hochgeschwindigkeits-Ethernet-Netzwerken sind alle physischen Geräte für die Out-of-Band-Verwaltung auch mit einem oder mehreren SN2201-Ethernet-Switches verbunden. Bitte beachten Sie die"Bereitstellungsdetails" Weitere Informationen zur Netzwerkkonfiguration finden Sie auf der Seite.
Speicherzugriffsübersicht für DGX H100-Systeme
Jedes DGX H100-System ist mit zwei ConnectX-7-Adaptern mit zwei Ports für Verwaltungs- und Speicherverkehr ausgestattet und für diese Lösung sind beide Ports auf jeder Karte mit demselben Switch verbunden. Ein Port von jeder Karte wird dann in eine LACP MLAG-Verbindung konfiguriert, wobei ein Port mit jedem Switch verbunden ist, und VLANs für In-Band-Management, Clientzugriff und Speicherzugriff auf Benutzerebene werden auf dieser Verbindung gehostet.
Der andere Port auf jeder Karte wird für die Verbindung mit den AFF A90 Speichersystemen verwendet und kann je nach Arbeitslastanforderungen in mehreren Konfigurationen verwendet werden. Bei Konfigurationen, die NFS über RDMA zur Unterstützung von NVIDIA Magnum IO GPUDirect Storage verwenden, werden die Ports einzeln mit IP-Adressen in separaten VLANs verwendet. Für Bereitstellungen, die kein RDMA erfordern, können die Speicherschnittstellen auch mit LACP-Bonding konfiguriert werden, um hohe Verfügbarkeit und zusätzliche Bandbreite bereitzustellen. Mit oder ohne RDMA können Clients das Speichersystem mithilfe von NFS v4.1 pNFS und Session Trunking mounten, um parallelen Zugriff auf alle Speicherknoten im Cluster zu ermöglichen. Bitte beachten Sie die"Bereitstellungsdetails" Seite für weitere Informationen zur Clientkonfiguration.
Weitere Einzelheiten zur Konnektivität des DGX H100-Systems finden Sie in der"NVIDIA BasePOD-Dokumentation" .
Speichersystemdesign
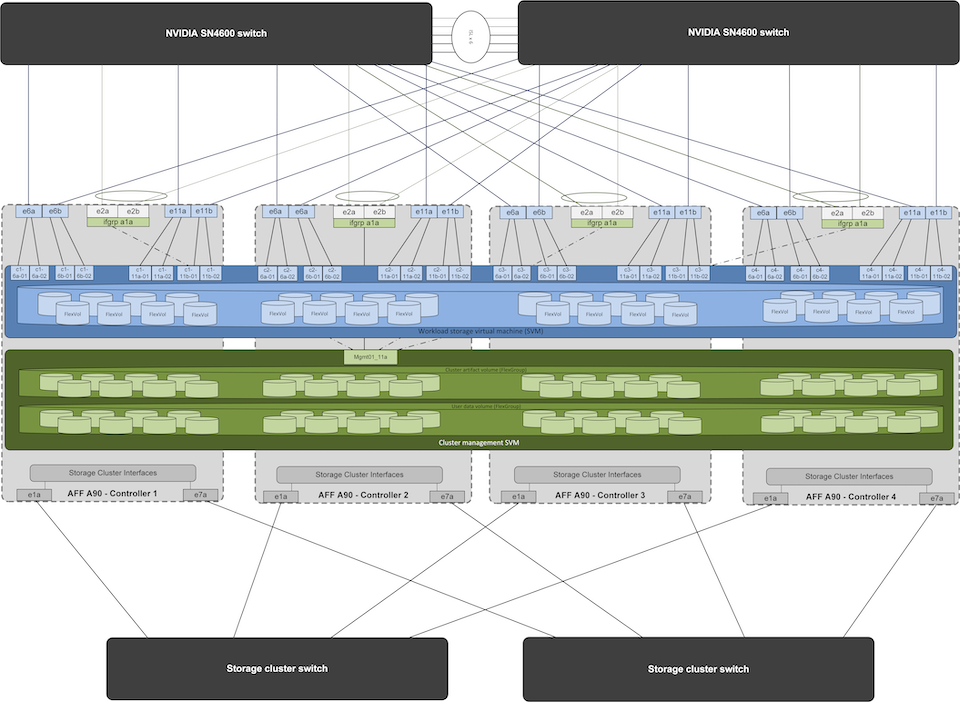
Jedes AFF A90 Speichersystem ist über sechs 200-GbE-Ports von jedem Controller aus verbunden. Vier Ports von jedem Controller werden für den Workload-Datenzugriff von den DGX-Systemen verwendet und zwei Ports von jedem Controller sind als LACP-Schnittstellengruppe konfiguriert, um den Zugriff von den Management-Plane-Servern auf Cluster-Management-Artefakte und Benutzer-Home-Verzeichnisse zu unterstützen. Der gesamte Datenzugriff vom Speichersystem erfolgt über NFS, wobei eine Storage Virtual Machine (SVM) für den Zugriff auf KI-Workloads und eine separate SVM für Clusterverwaltungszwecke vorgesehen ist.
Das Management-SVM benötigt nur ein einziges LIF, das auf den auf jedem Controller konfigurierten 2-Port-Schnittstellengruppen gehostet wird. Andere FlexGroup -Volumes werden auf der Management-SVM bereitgestellt, um Cluster-Management-Artefakte wie Cluster-Knoten-Images, historische Systemüberwachungsdaten und Endbenutzer-Home-Verzeichnisse aufzunehmen. Die folgende Zeichnung zeigt die logische Konfiguration des Speichersystems.
Logische Konfiguration des NetApp A90-Speicherclusters
Management-Plane-Server
Diese Referenzarchitektur umfasst außerdem fünf CPU-basierte Server für den Einsatz auf Verwaltungsebene. Zwei dieser Systeme werden als Hauptknoten für NVIDIA Base Command Manager zur Clusterbereitstellung und -verwaltung verwendet. Die anderen drei Systeme werden verwendet, um zusätzliche Clusterdienste wie Kubernetes-Masterknoten oder Anmeldeknoten für Bereitstellungen bereitzustellen, die Slurm für die Jobplanung verwenden. Bereitstellungen mit Kubernetes können den NetApp Trident CSI-Treiber nutzen, um automatisierte Bereitstellungs- und Datendienste mit persistentem Speicher für Management- und KI-Workloads auf dem AFF A900 Speichersystem bereitzustellen.
Jeder Server ist physisch mit den IB-Switches und den Ethernet-Switches verbunden, um die Clusterbereitstellung und -verwaltung zu ermöglichen, und mit NFS-Mounts zum Speichersystem über die Verwaltungs-SVM zur Speicherung von Clusterverwaltungsartefakten konfiguriert, wie zuvor beschrieben.