

Beheben Sie Fehler bei Netzwerk-, Hardware- und Plattformproblemen
 Änderungen vorschlagen
Änderungen vorschlagen
Sie können verschiedene Aufgaben durchführen, um die Ursache von Problemen im Zusammenhang mit dem StorageGRID Netzwerk-, Hardware- und Plattformproblemen zu ermitteln.
„422: Nicht verarbeitbare Entität“ Fehler
Der Fehler 422: Nicht verarbeitbare Entität kann aus verschiedenen Gründen auftreten. Überprüfen Sie die Fehlermeldung, um festzustellen, welche Ursache Ihr Problem verursacht hat.
Wenn eine der aufgeführten Fehlermeldungen angezeigt wird, führen Sie die empfohlene Aktion durch.
| Fehlermeldung | Ursache und Korrekturmaßnahme |
|---|---|
422: Unprocessable Entity Validation failed. Please check the values you entered for errors. Test connection failed. Please verify your configuration. Unable to authenticate, please verify your username and password: LDAP Result Code 8 "Strong Auth Required": 00002028: LdapErr: DSID-0C090256, comment: The server requires binds to turn on integrity checking if SSL\TLS are not already active on the connection, data 0, v3839 |
Diese Meldung kann auftreten, wenn Sie bei der Konfiguration der Identitätsföderation mit Windows Active Directory (AD) die Option TLS nicht verwenden für Transport Layer Security (TLS) auswählen. Die Verwendung der Option keine Verwendung von TLS wird nicht für die Verwendung mit AD-Servern unterstützt, die LDAP-Signatur erzwingen. Sie müssen entweder die Option STARTTLS verwenden oder die Option LDAPS verwenden für TLS auswählen. |
422: Unprocessable Entity
Validation failed. Please check
the values you entered for
errors. Test connection failed.
Please verify your
configuration.Unable to
begin TLS, verify your
certificate and TLS
configuration: LDAP Result
Code 200 "Network Error":
TLS handshake failed
(EOF)
|
Diese Meldung wird angezeigt, wenn Sie versuchen, eine nicht unterstützte Chiffre zu verwenden, um eine TLS-Verbindung (Transport Layer Security) von StorageGRID zu einem externen System herzustellen, das für Identify Federation oder Cloud Storage Pools verwendet wird. Überprüfen Sie die vom externen System angebotenen Chiffren. Das System muss einen der verwenden "Von StorageGRID unterstützte Chiffren" Für ausgehende TLS-Verbindungen, wie in der Anleitung zur Verwaltung von StorageGRID gezeigt. |
Alarm bei MTU-Nichtübereinstimmung im Grid-Netzwerk
Die Warnung Grid Network MTU mismatch wird ausgelöst, wenn sich die MTU-Einstellung (Maximum Transmission Unit) für die Grid Network Interface (eth0) über Knoten im Grid deutlich unterscheidet.
Die Unterschiede in den MTU-Einstellungen könnten darauf hinweisen, dass einige, aber nicht alle, eth0-Netzwerke für Jumbo Frames konfiguriert sind. Eine MTU-Größe von mehr als 1000 kann zu Problemen mit der Netzwerkleistung führen.
-
Führen Sie die MTU-Einstellungen für eth0 auf allen Knoten auf.
-
Verwenden Sie die im Grid Manager angegebene Abfrage.
-
Navigieren Sie zu
primary Admin Node IP address/metrics/graphUnd geben Sie die folgende Abfrage ein:node_network_mtu_bytes{interface='eth0'}
-
-
"Ändern Sie die MTU-Einstellungen" Falls erforderlich, um sicherzustellen, dass sie für die Grid Network Interface (eth0) auf allen Knoten gleich sind.
-
Verwenden Sie für Linux- und VMware-basierte Knoten den folgenden Befehl:
/usr/sbin/change-ip.py [-h] [-n node] mtu network [network...]-
Beispiel*:
change-ip.py -n node 1500 grid adminHinweis: Wenn auf Linux-basierten Knoten der gewünschte MTU-Wert für das Netzwerk im Container den bereits auf der Hostschnittstelle konfigurierten Wert überschreitet, müssen Sie zuerst die Hostschnittstelle so konfigurieren, dass sie den gewünschten MTU-Wert hat, und dann den verwenden
change-ip.pySkript zum Ändern des MTU-Werts des Netzwerks im Container.
Verwenden Sie die folgenden Argumente, um die MTU auf Linux- oder VMware-basierten Knoten zu ändern.
-
Positionsargumente Beschreibung mtuDie MTU, die eingestellt werden soll. Muss zwischen 1280 und 9216 liegen.
networkDie Netzwerke, auf die die MTU angewendet werden soll. Geben Sie einen oder mehrere der folgenden Netzwerktypen an:
-
Raster
-
Admin
-
Client
+
Optionale Argumente Beschreibung -h, – helpHilMeldung anzeigen und beenden.
-n node, --node nodeDer Node. Die Standardeinstellung ist der lokale Knoten.
-
NRER-Alarm (Network Receive Error)
NRER-Alarme (Network Receive Error) können durch Verbindungsprobleme zwischen StorageGRID und Ihrer Netzwerk-Hardware verursacht werden. In einigen Fällen können NRER-Fehler ohne manuelles Eingreifen gelöscht werden. Wenn die Fehler nicht behoben werden, führen Sie die empfohlenen Maßnahmen durch.
NRER-Alarme können durch die folgenden Probleme mit Netzwerk-Hardware verursacht werden, die eine Verbindung mit StorageGRID herstellt:
-
Eine Vorwärtsfehlerkorrektur (FEC) ist erforderlich und wird nicht verwendet
-
Switch-Port und MTU-NIC stimmen nicht überein
-
Hohe Link-Fehlerraten
-
NIC-Klingelpuffer überlaufen
-
Befolgen Sie die Schritte zur Fehlerbehebung für alle möglichen Ursachen des NRER-Alarms bei der Netzwerkkonfiguration.
-
Führen Sie je nach Fehlerursache die folgenden Schritte aus:
FEC stimmt nicht überein
Diese Schritte gelten nur für NRER-Fehler, die durch FEC-Nichtübereinstimmung auf StorageGRID-Geräten verursacht werden. -
Überprüfen Sie den FEC-Status des Ports im Switch, der an Ihr StorageGRID-Gerät angeschlossen ist.
-
Überprüfen Sie die physikalische Integrität der Kabel vom Gerät zum Switch.
-
Wenn Sie die FEC-Einstellungen ändern möchten, um zu versuchen, den NRER-Alarm zu lösen, stellen Sie zunächst sicher, dass das Gerät auf der Seite Verbindungskonfiguration des Installationsprogramms für das StorageGRID-Gerät für den Modus Auto konfiguriert ist (siehe Anweisungen für Ihr Gerät:
-
Ändern Sie die FEC-Einstellungen an den Switch-Ports. Die StorageGRID-Appliance-Ports passen ihre FEC-Einstellungen nach Möglichkeit an.
Sie können die FEC-Einstellungen auf StorageGRID-Geräten nicht konfigurieren. Stattdessen versuchen die Geräte, die FEC-Einstellungen an den Switch-Ports zu erkennen und zu spiegeln, an denen sie angeschlossen sind. Wenn die Verbindungen zu 25-GbE- oder 100-GbE-Netzwerkgeschwindigkeiten gezwungen sind, können Switch und NIC eine gemeinsame FEC-Einstellung nicht aushandeln. Ohne eine gemeinsame FEC-Einstellung kehrt das Netzwerk in den Modus „
no-FEC“ zurück. Wenn FEC nicht aktiviert ist, sind die Anschlüsse anfälliger für Fehler, die durch elektrische Geräusche verursacht werden.
StorageGRID Appliances unterstützen Firecode (FC) und Reed Solomon (RS) FEC sowie keine FEC.
Switch-Port und MTU-NIC stimmen nicht übereinWenn der Fehler durch einen Switch Port und eine nicht übereinstimmende NIC MTU verursacht wird, überprüfen Sie, ob die auf dem Node konfigurierte MTU-Größe mit der MTU-Einstellung für den Switch-Port identisch ist.
Die auf dem Node konfigurierte MTU-Größe ist möglicherweise kleiner als die Einstellung am Switch-Port, mit dem der Node verbunden ist. Wenn ein StorageGRID-Knoten einen Ethernet-Frame empfängt, der größer ist als seine MTU, was mit dieser Konfiguration möglich ist, wird möglicherweise der NRR-Alarm gemeldet. Wenn Sie der Ansicht sind, dass dies geschieht, ändern Sie entweder die MTU des Switch Ports entsprechend der StorageGRID Netzwerkschnittstelle MTU oder ändern Sie die MTU der StorageGRID-Netzwerkschnittstelle je nach Ihren End-to-End-Zielen oder Anforderungen an den Switch-Port.

Für die beste Netzwerkleistung sollten alle Knoten auf ihren Grid Network Interfaces mit ähnlichen MTU-Werten konfiguriert werden. Die Warnung Grid Network MTU mismatch wird ausgelöst, wenn sich die MTU-Einstellungen für das Grid Network auf einzelnen Knoten erheblich unterscheiden. Die MTU-Werte müssen nicht für alle Netzwerktypen gleich sein. Siehe Fehler bei der Warnmeldung zur Nichtübereinstimmung bei Grid Network MTU Finden Sie weitere Informationen.
Siehe auch "MTU-Einstellung ändern". Hohe Link-Fehlerraten-
Aktivieren Sie FEC, falls nicht bereits aktiviert.
-
Stellen Sie sicher, dass Ihre Netzwerkkabel von guter Qualität sind und nicht beschädigt oder nicht ordnungsgemäß angeschlossen sind.
-
Wenn die Kabel nicht das Problem darstellen, wenden Sie sich an den technischen Support.
In einer Umgebung mit hohem elektrischen Rauschen können hohe Fehlerraten festgestellt werden.
NIC-Klingelpuffer überlaufenWenn es sich bei dem Fehler um einen NIC-Ringpuffer handelt, wenden Sie sich an den technischen Support.
Der Ruffuffer kann bei Überlastung des StorageGRID-Systems überlaufen werden und kann Netzwerkereignisse nicht zeitnah verarbeiten.
-
-
Nachdem Sie das zugrunde liegende Problem gelöst haben, setzen Sie den Fehlerzähler zurück.
-
Wählen Sie SUPPORT > Tools > Grid-Topologie aus.
-
Wählen Sie site > GRID Node > SSM > Ressourcen > Konfiguration > Main aus.
-
Wählen Sie Empfangspunkt zurücksetzen und klicken Sie auf Änderungen anwenden.
-
Fehler bei der Zeitsynchronisierung
Möglicherweise treten Probleme mit der Zeitsynchronisierung in Ihrem Raster auf.
Wenn Probleme mit der Zeitsynchronisierung auftreten, stellen Sie sicher, dass Sie mindestens vier externe NTP-Quellen angegeben haben, die jeweils eine Stratum 3 oder eine bessere Referenz liefern, und dass alle externen NTP-Quellen normal funktionieren und von Ihren StorageGRID-Knoten zugänglich sind.
|
|
Wenn "Angeben der externen NTP-Quelle" Verwenden Sie für eine StorageGRID-Installation auf Produktionsebene nicht den Windows Time-Dienst (W32Time) auf einer Windows-Version vor Windows Server 2016. Der Zeitdienst für ältere Windows Versionen ist nicht ausreichend genau und wird von Microsoft nicht für die Verwendung in Umgebungen mit hoher Genauigkeit, wie z. B. StorageGRID, unterstützt. |
Linux: Probleme mit der Netzwerkverbindung
Möglicherweise werden Probleme mit der Netzwerkverbindung für StorageGRID Grid-Nodes auftreten, die auf Linux-Hosts gehostet werden.
Klonen VON MAC Adressen
In einigen Fällen können Netzwerkprobleme mithilfe des Klonens von MAC-Adressen behoben werden. Wenn Sie virtuelle Hosts verwenden, legen Sie den Wert des MAC-Adressenklonens für jedes Ihrer Netzwerke in der Node-Konfigurationsdatei auf „true“ fest. Diese Einstellung bewirkt, dass die MAC-Adresse des StorageGRID-Containers die MAC-Adresse des Hosts verwendet. Informationen zum Erstellen von Node-Konfigurationsdateien finden Sie in den Anweisungen für "Red hat Enterprise Linux oder CentOS" Oder "Ubuntu oder Debian".
|
|
Erstellen Sie separate virtuelle Netzwerkschnittstellen, die vom Linux Host-Betriebssystem verwendet werden können. Die Verwendung derselben Netzwerkschnittstellen für das Linux-Hostbetriebssystem und den StorageGRID-Container kann dazu führen, dass das Host-Betriebssystem nicht mehr erreichbar ist, wenn der promiskuious-Modus auf dem Hypervisor nicht aktiviert wurde. |
Weitere Informationen zum Aktivieren des MAC-Klonens finden Sie in den Anweisungen für "Red hat Enterprise Linux oder CentOS" Oder "Ubuntu oder Debian".
Promiskuous Modus
Wenn Sie das Klonen von MAC-Adressen nicht verwenden möchten und lieber allen Schnittstellen erlauben möchten, Daten für andere MAC-Adressen als die vom Hypervisor zugewiesenen zu empfangen und zu übertragen, Stellen Sie sicher, dass die Sicherheitseigenschaften auf der Ebene des virtuellen Switches und der Portgruppen für den Promiscuous-Modus, MAC-Adressänderungen und Forged-Übertragungen auf Accept gesetzt sind. Die auf dem virtuellen Switch eingestellten Werte können von den Werten auf der Portgruppenebene außer Kraft gesetzt werden. Stellen Sie also sicher, dass die Einstellungen an beiden Stellen identisch sind.
Weitere Informationen zur Verwendung des Promiscuous-Modus finden Sie in den Anweisungen für "Red hat Enterprise Linux oder CentOS" Oder "Ubuntu oder Debian".
Linux: Node-Status lautet „verwaiste“
Ein Linux-Node in einem verwaisten Status gibt in der Regel an, dass entweder der StorageGRID-Service oder der StorageGRID-Node-Daemon, der den Container steuert, unerwartet gestorben ist.
Wenn ein Linux-Knoten meldet, dass er sich in einem verwaisten Status befindet, sollten Sie Folgendes tun:
-
Überprüfen Sie die Protokolle auf Fehler und Meldungen.
-
Versuchen Sie, den Node erneut zu starten.
-
Verwenden Sie bei Bedarf Befehle der Container-Engine, um den vorhandenen Node-Container zu beenden.
-
Starten Sie den Node neu.
-
Überprüfen Sie die Protokolle sowohl für den Service-Daemon als auch für den verwaisten Node auf offensichtliche Fehler oder Meldungen zum unerwarteten Beenden.
-
Melden Sie sich beim Host als Root an oder verwenden Sie ein Konto mit sudo-Berechtigung.
-
Versuchen Sie, den Node erneut zu starten, indem Sie den folgenden Befehl ausführen:
$ sudo storagegrid node start node-name$ sudo storagegrid node start DC1-S1-172-16-1-172
Wenn der Node verwaiste ist, wird die Antwort angezeigt
Not starting ORPHANED node DC1-S1-172-16-1-172
-
Stoppen Sie von Linux die Container-Engine und alle kontrollierenden storagegrid Node-Prozesse. Beispiel:
sudo docker stop --time secondscontainer-nameFür `seconds`Geben Sie die Anzahl der Sekunden ein, die Sie warten möchten, bis der Container angehalten wird (normalerweise 15 Minuten oder weniger). Beispiel:
sudo docker stop --time 900 storagegrid-DC1-S1-172-16-1-172
-
Starten Sie den Knoten neu:
storagegrid node start node-namestoragegrid node start DC1-S1-172-16-1-172
Linux: Fehlerbehebung bei der IPv6-Unterstützung
Möglicherweise müssen Sie die IPv6-Unterstützung im Kernel aktivieren, wenn Sie StorageGRID-Knoten auf Linux-Hosts installiert haben und Sie bemerken, dass den Knoten-Containern keine IPv6-Adressen wie erwartet zugewiesen wurden.
Die IPv6-Adresse, die einem Grid-Node zugewiesen wurde, wird in den folgenden Speicherorten im Grid Manager angezeigt:
-
Wählen Sie NODES aus, und wählen Sie den Knoten aus. Wählen Sie dann auf der Registerkarte Übersicht neben IP-Adressen die Option Mehr anzeigen aus.
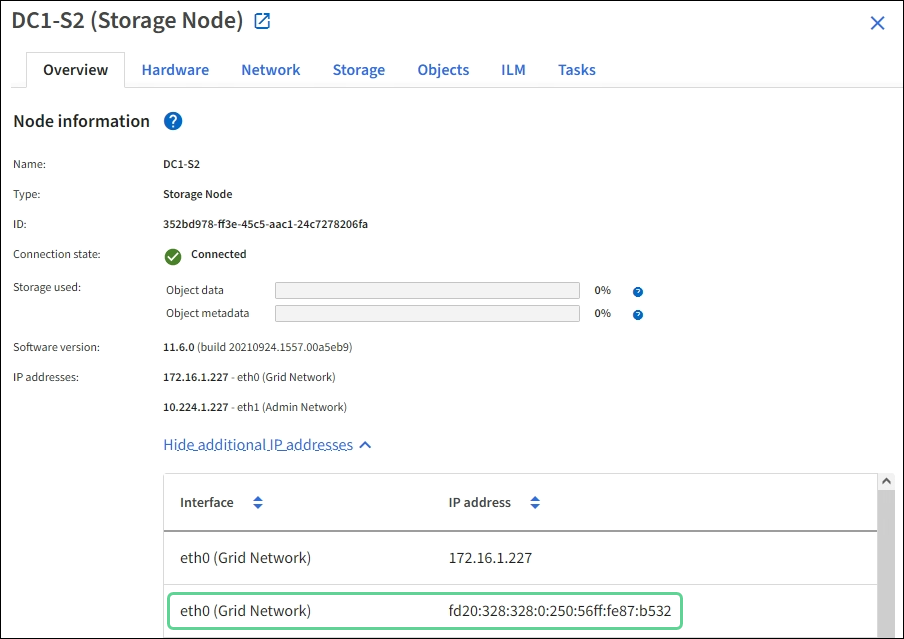
-
Wählen Sie SUPPORT > Tools > Grid-Topologie aus. Wählen Sie dann Node > SSM > Ressourcen aus. Wenn eine IPv6-Adresse zugewiesen wurde, wird sie unter der IPv4-Adresse im Abschnitt Netzwerkadressen aufgelistet.
Wenn die IPv6-Adresse nicht angezeigt wird und der Knoten auf einem Linux-Host installiert ist, führen Sie diese Schritte aus, um die IPv6-Unterstützung im Kernel zu aktivieren.
-
Melden Sie sich beim Host als Root an oder verwenden Sie ein Konto mit sudo-Berechtigung.
-
Führen Sie den folgenden Befehl aus:
sysctl net.ipv6.conf.all.disable_ipv6root@SG:~ # sysctl net.ipv6.conf.all.disable_ipv6
Das Ergebnis sollte 0 sein.
net.ipv6.conf.all.disable_ipv6 = 0
Wenn das Ergebnis nicht 0 ist, lesen Sie die Dokumentation zum Ändern des Betriebssystems sysctlEinstellungen. Ändern Sie dann den Wert in 0, bevor Sie fortfahren. -
Geben Sie den StorageGRID-Node-Container ein:
storagegrid node enter node-name -
Führen Sie den folgenden Befehl aus:
sysctl net.ipv6.conf.all.disable_ipv6root@DC1-S1:~ # sysctl net.ipv6.conf.all.disable_ipv6
Das Ergebnis sollte 1 sein.
net.ipv6.conf.all.disable_ipv6 = 1
Wenn das Ergebnis nicht 1 ist, gilt dieses Verfahren nicht. Wenden Sie sich an den technischen Support. -
Verlassen Sie den Behälter:
exitroot@DC1-S1:~ # exit
-
Bearbeiten Sie als root die folgende Datei:
/var/lib/storagegrid/settings/sysctl.d/net.conf.sudo vi /var/lib/storagegrid/settings/sysctl.d/net.conf
-
Suchen Sie die folgenden beiden Zeilen, und entfernen Sie die Kommentar-Tags. Speichern und schließen Sie anschließend die Datei.
net.ipv6.conf.all.disable_ipv6 = 0
net.ipv6.conf.default.disable_ipv6 = 0
-
Führen Sie folgende Befehle aus, um den StorageGRID-Container neu zu starten:
storagegrid node stop node-name
storagegrid node start node-name