

RPO von null mit StorageGRID – Ein umfassender Leitfaden zur Replizierung an mehreren Standorten
 Änderungen vorschlagen
Änderungen vorschlagen
Dieser technische Bericht bietet eine umfassende Anleitung zur Implementierung von StorageGRID Replikationsstrategien, um im Falle eines Standortausfalls ein Recovery Point Objective (RPO) von Null zu erreichen. Das Dokument beschreibt detailliert verschiedene Bereitstellungsoptionen für StorageGRID, darunter standortübergreifende synchrone Replikation und standortübergreifende asynchrone Replikation. Darin wird erläutert, wie StorageGRID Information Lifecycle Management (ILM)-Richtlinien konfiguriert werden können, um die Datenbeständigkeit und -verfügbarkeit über mehrere Standorte hinweg zu gewährleisten. Darüber hinaus behandelt der Bericht Leistungsaspekte, Fehlerszenarien und Wiederherstellungsprozesse, um einen ununterbrochenen Kundenbetrieb zu gewährleisten. Ziel dieses Dokuments ist es, Informationen bereitzustellen, die sicherstellen, dass die Daten auch im Falle eines vollständigen Ausfalls der Website zugänglich und konsistent bleiben, indem sowohl synchrone als auch asynchrone Replikationstechniken genutzt werden.
Übersicht über StorageGRID
NetApp StorageGRID ist ein objektbasiertes Storage-System, das die branchenübliche API Amazon Simple Storage Service (Amazon S3) unterstützt.
StorageGRID bietet einen Single Namespace über mehrere Standorte mit variablen Service-Leveln basierend auf Information Lifecycle Management-Richtlinien (ILM). Mit diesen Lebenszyklusrichtlinien können Sie den Speicherort Ihrer Daten während ihres gesamten Lebenszyklus optimieren.
StorageGRID ermöglicht die konfigurierbare Aufbewahrung und Verfügbarkeit Ihrer Daten in lokalen und geografisch verteilten Lösungen. Unabhängig davon, ob sich Ihre Daten vor Ort oder in einer öffentlichen Cloud befinden, ermöglichen integrierte Hybrid-Cloud-Workflows Ihrem Unternehmen die Nutzung von Cloud-Diensten wie Amazon Simple Notification Service (Amazon SNS), Google Cloud, Microsoft Azure Blob, Amazon S3 Glacier, Elasticsearch und mehr.
StorageGRID Scale
Eine minimale StorageGRID Bereitstellung besteht aus einem Admin-Knoten und 3 Speicherknoten an einem einzigen Standort. Ein einzelnes Grid kann auf bis zu 220 Knoten anwachsen. StorageGRID kann als einzelner Standort eingesetzt oder auf bis zu 16 Standorte erweitert werden.
Der Admin-Knoten enthält die Verwaltungsschnittstelle, einen zentralen Punkt für Metriken und Protokollierung und verwaltet die Konfiguration der StorageGRID Komponenten. Der Admin-Knoten enthält außerdem einen integrierten Load Balancer für den S3-API-Zugriff.
StorageGRID kann als reine Software, als VMware Virtual Machine Appliances oder als speziell entwickelte Appliances bereitgestellt werden.
Ein Speicherknoten kann wie folgt bereitgestellt werden:
-
Ein reiner Metadatenknoten, der die Objektanzahl maximiert
-
Ein reiner Objektspeicherknoten, der den Objektspeicherplatz maximiert
-
Ein kombinierter Metadaten- und Objektspeicherknoten, der sowohl die Objektanzahl als auch den Objektspeicherplatz hinzufügt
Jeder Speicherknoten kann für die Objektspeicherung auf eine Kapazität von mehreren Petabyte skaliert werden, wodurch ein einzelner Namespace im Bereich von Hunderten von Petabyte möglich ist. StorageGRID bietet außerdem einen integrierten Load Balancer für S3-API-Operationen, der als Gateway-Knoten bezeichnet wird.
StorageGRID besteht aus einer Sammlung von Knoten, die in einer Site-Topologie platziert sind. Ein Standort in StorageGRID kann ein eindeutiger physischer Standort sein oder sich als logisches Konstrukt an einem gemeinsam genutzten physischen Standort wie andere Standorte im Grid befinden. Eine StorageGRID -Site sollte sich nicht über mehrere physische Standorte erstrecken. Ein Standort stellt eine gemeinsam genutzte Infrastruktur und Fehlerdomäne eines lokalen Netzwerks (LAN) dar.
StorageGRID und Ausfall-Domains
StorageGRID umfasst mehrere Schichten von Ausfall-Domains, die Sie bei der Entscheidung, wie Sie Ihre Lösung planen, wie Sie Ihre Daten speichern und wo Ihre Daten gespeichert werden sollten, um das Risiko von Ausfällen zu mindern.
-
Grid-Ebene – Ein Grid, das aus mehreren Standorten besteht, kann einen Standortausfall oder eine Isolierung aufweisen, und der/die zugängliche(n) Standort(e) kann/können weiterhin als Grid betrieben werden.
-
Standort-Ebene – Ausfälle innerhalb eines Standorts können den Betrieb dieses Standorts beeinträchtigen, beeinträchtigen aber nicht den Rest des Grids.
-
Node-Ebene – Ein Node-Ausfall hat keine Auswirkungen auf den Betrieb des Standorts.
-
Festplattenebene – ein Festplattenausfall beeinträchtigt den Betrieb des Node nicht.
Objektdaten und Metadaten
Bei Objekt-Storage ist die Storage-Einheit ein Objekt und nicht eine Datei oder ein Block. Im Gegensatz zur Baumstruktur eines File-Systems oder Block-Storage werden die Daten im Objekt-Storage in einem flachen, unstrukturierten Layout organisiert. Objekt-Storage entkoppelt den physischen Standort der Daten von der Methode zum Speichern und Abrufen dieser Daten.
Jedes Objekt in einem objektbasierten Storage-System besteht aus zwei Teilen: Objekt-Daten und Objekt-Metadaten.
-
Objektdaten stellen die eigentlichen zugrunde liegenden Daten dar, zum Beispiel ein Foto, einen Film oder eine Krankenakte.
-
Objektmetadaten sind alle Informationen, die ein Objekt beschreiben.
StorageGRID verwendet Objektmetadaten, um die Standorte aller Objekte im Grid zu verfolgen und den Lebenszyklus eines jeden Objekts mit der Zeit zu managen.
Objektmetadaten enthalten Informationen wie die folgenden:
-
Systemmetadaten, einschließlich einer eindeutigen ID für jedes Objekt, des Objektnamens, des Namens des S3-Buckets, des Mandantenkontonamens oder der ID, der logischen Größe des Objekts, des Datums und der Uhrzeit der ersten Erstellung des Objekts sowie des Datums und der Uhrzeit der letzten Änderung des Objekts.
-
Der aktuelle Speicherort der Replikatkopie oder des löschcodierten Fragments jedes Objekts.
-
Alle mit dem Objekt verknüpften Schlüssel-Wert-Paare für benutzerdefinierte Benutzer-Metadaten.
-
Bei S3-Objekten sind alle dem Objekt zugeordneten Objekt-Tag-Schlüssel-Wert-Paare vorhanden
-
Für segmentierte Objekte und mehrteilige Objekte, Segmentkennungen und Datengrößen.
Objektmetadaten sind individuell anpassbar und erweiterbar und bieten dadurch Flexibilität für die Nutzung von Applikationen. Detaillierte Informationen darüber, wie und wo StorageGRID Objektmetadaten speichert, finden Sie unter "Management von Objekt-Metadaten-Storage".
Das Information Lifecycle Management-System (ILM) von StorageGRID wird zur Orchestrierung der Platzierung, Dauer und Aufnahme aller Objektdaten in Ihrem StorageGRID System verwendet. ILM-Regeln bestimmen, wie StorageGRID Objekte mithilfe von Replikaten der Objekte oder Erasure Coding eines Objekts über Nodes und Standorte hinweg im Zeitverlauf speichert. Dieses ILM-System ist für die Konsistenz der Objektdaten in einem Grid verantwortlich.
Erasure Coding
StorageGRID bietet die Möglichkeit, Codedaten auf Knoten- und Laufwerksebene zu löschen. Mit StorageGRID -Geräten löschen wir die auf jedem Knoten gespeicherten Daten auf allen Laufwerken innerhalb des Knotens und bieten so lokalen Schutz vor mehreren Festplattenausfällen, die zu Datenverlust oder Unterbrechungen führen. Wiederherstellungen nach Laufwerksfehlern erfolgen lokal auf dem Knoten und erfordern keine Datenreplikation über das Netzwerk.
Darüber hinaus verwenden StorageGRID Geräte Erasure-Coding-Schemata, um Objektdaten über die Knoten innerhalb eines Standorts oder verteilt auf drei oder mehr Standorte im StorageGRID -System zu speichern, wobei die ILM-Regeln von StorageGRID vor Knotenausfällen schützen.
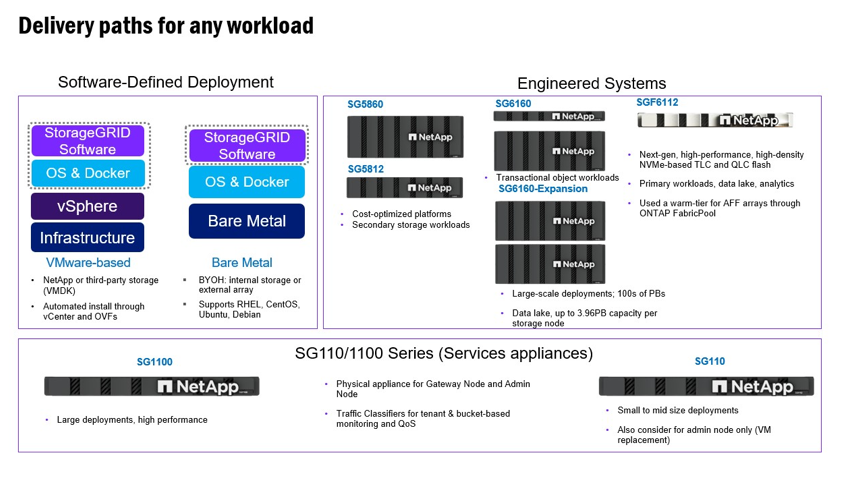
Erasure Coding bietet ein Speicherlayout, das gegenüber Knoten- und Standortausfällen robust ist und einen geringeren Aufwand als die Replikation verursacht. Alle StorageGRID -Erasure-Coding-Verfahren sind an einem einzigen Standort einsetzbar, sofern die Mindestanzahl der Knoten, die zum Speichern der Datenblöcke erforderlich sind, erreicht ist. Das bedeutet, dass für ein EC-Schema von 4+2 mindestens 6 Knoten zur Verfügung stehen müssen, um die Daten zu empfangen.
Metadatenkonsistenz
In StorageGRID werden Metadaten normalerweise mit drei Replikaten pro Standort gespeichert, um Konsistenz und Verfügbarkeit zu gewährleisten. Diese Redundanz trägt dazu bei, die Datenintegrität und -Verfügbarkeit auch bei einem Ausfall aufrechtzuerhalten.
Die Standardkonsistenz wird auf einer Grid-weiten Ebene definiert. Benutzer können die Konsistenz auf Bucket-Ebene jederzeit ändern.
Die in StorageGRID verfügbaren Bucket-Konsistenzoptionen sind:
-
All: Bietet die höchste Konsistenz. Alle Nodes im Grid erhalten die Daten sofort, andernfalls schlägt die Anforderung fehl.
-
Stark-global:
-
Legacy Strong Global: Gewährleistet Lese-nach-Schreib-Konsistenz für alle Client-Anfragen an allen Standorten.
-
Dies ist das Standardverhalten für alle Systeme, die von Version 11.9 oder älter auf Version 12.0 aktualisiert wurden, ohne dass manuell auf das neue Quorum Strong Global umgestellt wurde.
-
-
Quorum Strong-global: Garantiert Lese-nach-Schreib-Konsistenz für alle Clientanforderungen auf allen Sites. Bietet Konsistenz für mehrere Knoten oder sogar einen Site-Ausfall, wenn das Quorum für die Metadatenreplikation erreicht werden kann.
-
Dies ist das Standardverhalten für alle Systeme, die neu mit Version 12.0 oder höher installiert werden.
-
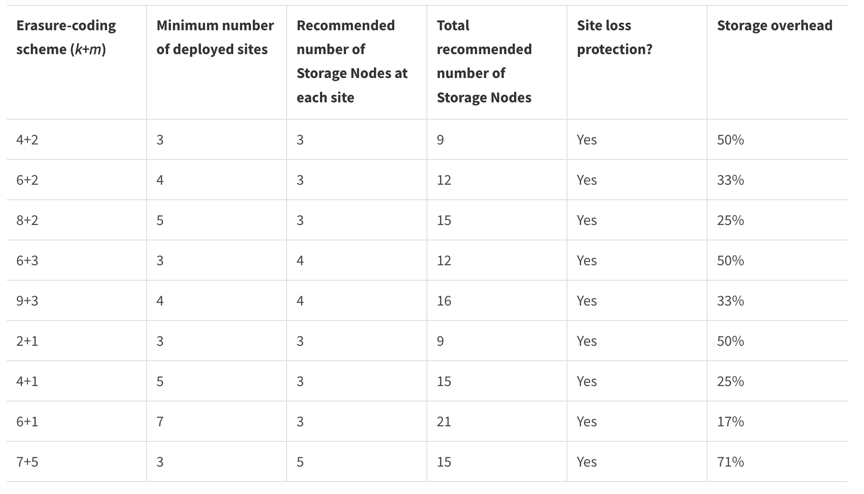
QUORUM-Konsistenz wird als Quorum von Storage Node-Metadatenreplikaten definiert, wobei jeder Standort über 3 Metadatenreplikate verfügt. Es kann wie folgt berechnet werden: 1+((N*3)/2), wobei N die Gesamtzahl der Standorte ist
-
Beispielsweise müssen aus einem Raster mit 3 Standorten mindestens 5 Replikate erstellt werden, innerhalb eines Standorts dürfen maximal 3 Replikate vorhanden sein.
-
-
-
Strong-site: Garantiert Lese-nach-Schreiben Konsistenz für alle Client-Anfragen innerhalb einer Site.
-
Read-after-New-write(default): Bietet Read-after-write-Konsistenz für neue Objekte und eventuelle Konsistenz für Objektaktualisierungen. Hochverfügbarkeit und garantierte Datensicherung Empfohlen für die meisten Fälle.
-
Verfügbar: Bietet eventuelle Konsistenz für neue Objekte und Objekt-Updates. Verwenden Sie für S3-Buckets nur nach Bedarf (z. B. für einen Bucket mit Protokollwerten, die nur selten gelesen werden, oder für HEAD- oder GET-Vorgänge für nicht vorhandene Schlüssel). Nicht unterstützt für S3 FabricPool-Buckets.
Konsistenz von Objektdaten
Metadaten werden automatisch innerhalb von und über Standorte hinweg repliziert, Entscheidungen zur Platzierung von Objektdaten liegen bei Ihnen. Objektdaten können in Replikaten innerhalb und über Standorte hinweg gespeichert werden, in Erasure Coding innerhalb von oder über Standorte hinweg, in einer Kombination oder in Replikaten und in Storage-Schemata, die nach Erasure Coding codiert sind. ILM-Regeln können für alle Objekte angewendet oder so gefiltert werden, dass sie nur für bestimmte Objekte, Buckets oder Mandanten gelten. ILM-Regeln legen fest, wie Objekte gespeichert werden, wie Replikate und/oder Erasure Coding codiert wird, wie lange Objekte an diesen Standorten gespeichert werden, ob sich die Anzahl der Replikate oder Erasure Coding-Schemata ändert oder sich der Standort im Laufe der Zeit ändert.
Jede ILM-Regel wird mit einem von drei Aufnahmeverhalten zum Schutz von Objekten konfiguriert: Dual Commit, Balanced oder Strict.
Die Dual-Commit-Option erstellt sofort zwei Kopien auf zwei beliebigen verschiedenen Speicherknoten im Grid und meldet dem Client, dass die Anfrage erfolgreich war. Die Knotenauswahl erfolgt innerhalb des Standorts der Anfrage, kann aber unter bestimmten Umständen auch Knoten eines anderen Standorts verwenden. Das Objekt wird der ILM-Warteschlange hinzugefügt, um gemäß den ILM-Regeln ausgewertet und platziert zu werden.
Die Option „ausgewogen“ wertet das Objekt sofort anhand der ILM-Richtlinie aus und platziert das Objekt synchron, bevor die Anfrage als erfolgreich an den Client zurückgesendet wird. Kann die ILM-Regel aufgrund eines Ausfalls oder unzureichenden Speicherplatzes zur Erfüllung der Platzierungsanforderungen nicht sofort eingehalten werden, wird stattdessen Dual Commit verwendet. Sobald das Problem behoben ist, platziert ILM das Objekt automatisch gemäß der definierten Regel.
Die strikte Option wertet das Objekt sofort anhand der ILM-Richtlinie aus und platziert das Objekt synchron, bevor die Anfrage als erfolgreich an den Client zurückgesendet wird. Kann die ILM-Regel aufgrund eines Ausfalls oder unzureichenden Speicherplatzes zur Erfüllung der Platzierungsanforderungen nicht sofort erfüllt werden, schlägt die Anfrage fehl und der Kunde muss es erneut versuchen.
Lastverteilung
StorageGRID kann mit Client-Zugriff über die integrierten Gateway-Nodes, einen externen Load Balancer von 3Rd Party, DNS-Round Robin oder direkt zu einem Storage-Node implementiert werden. Mehrere Gateway Nodes können an einem Standort implementiert und in Hochverfügbarkeitsgruppen konfiguriert werden, die für automatisches Failover und Failback bei einem Ausfall des Gateway Node sorgen. Sie können Lastausgleichsmethoden in einer Lösung kombinieren, um einen zentralen Zugriffspunkt für alle Standorte in einer Lösung bereitzustellen.
Die Gateway-Knoten gleichen standardmäßig die Last zwischen den Speicherknoten an dem Standort aus, an dem sich der Gateway-Knoten befindet. StorageGRID kann so konfiguriert werden, dass die Gateway-Knoten die Last mithilfe von Knoten von mehreren Standorten ausgleichen können. Diese Konfiguration würde die Latenz zwischen diesen Standorten zur Antwortlatenz der Clientanfragen addieren. Diese Konfiguration sollte nur vorgenommen werden, wenn die Gesamtlatenz für die Clients akzeptabel ist.
Durch eine Kombination aus lokalem und globalem Lastausgleich kann ein RTO von Null erreicht werden. Um einen unterbrechungsfreien Clientzugriff zu gewährleisten, ist ein Lastausgleich der Clientanfragen erforderlich. Eine StorageGRID Lösung kann an jedem Standort viele Gateway-Knoten und Hochverfügbarkeitsgruppen enthalten. Um einen unterbrechungsfreien Zugriff für Clients an jedem Standort auch bei einem Standortausfall zu gewährleisten, sollten Sie eine externe Load-Balancing-Lösung in Kombination mit StorageGRID Gateway-Knoten konfigurieren. Konfigurieren Sie Hochverfügbarkeitsgruppen für Gateway-Knoten, die die Last innerhalb jedes Standorts verwalten, und verwenden Sie den externen Load Balancer, um die Last auf die Hochverfügbarkeitsgruppen zu verteilen. Der externe Load Balancer muss so konfiguriert sein, dass er eine Zustandsprüfung durchführt, um sicherzustellen, dass Anfragen nur an betriebsbereite Standorte gesendet werden. Weitere Informationen zum Lastausgleich mit StorageGRID finden Sie unter "Technischer Bericht zum StorageGRID Load Balancer"Die
Anforderungen für Zero RPO mit StorageGRID
Um ein Recovery Point Objective (RPO) von null in einem Objekt-Storage-System zu erreichen, ist es bei einem Ausfall entscheidend:
-
Sowohl Metadaten als auch Objektinhalte werden synchron betrachtet und als konsistent betrachtet
-
Der Zugriff auf den Objektinhalt bleibt trotz des Fehlers erhalten.
Bei einer Bereitstellung an mehreren Standorten ist Quorum Strong Global das bevorzugte Konsistenzmodell, um sicherzustellen, dass Metadaten über alle Standorte hinweg synchronisiert werden. Dies ist für die Erfüllung der Null-RPO-Anforderung unerlässlich.
Objekte im Speichersystem werden auf der Grundlage von Information Lifecycle Management (ILM)-Regeln gespeichert, die vorschreiben, wie und wo Daten während ihres gesamten Lebenszyklus gespeichert werden. Bei der synchronen Replikation kann man zwischen strikter Ausführung und ausgewogener Ausführung abwägen.
-
Für ein RPO von null ist eine strikte Ausführung dieser ILM-Regeln nötig, da so sichergestellt wird, dass Objekte ohne Verzögerung oder Fallback an den definierten Standorten platziert werden, sodass die Datenverfügbarkeit und -Konsistenz erhalten bleiben.
-
Das ILM-Balance-Aufnahmeverhalten von StorageGRID sorgt für ein Gleichgewicht zwischen Hochverfügbarkeit und Ausfallsicherheit, sodass Benutzer auch bei einem Standortausfall weiterhin Daten aufnehmen können.
Synchrone Implementierungen an mehreren Standorten
Multi-Site-Lösungen: StorageGRID ermöglicht Ihnen die synchrone Replikation von Objekten über mehrere Sites innerhalb des Grids hinweg. Durch das Einrichten von Information Lifecycle Management (ILM)-Regeln mit ausgewogenem oder striktem Verhalten werden Objekte sofort an den angegebenen Orten platziert. Durch Konfigurieren der Bucket-Konsistenzebene auf Quorum Strong Global wird auch die synchrone Metadatenreplikation sichergestellt. StorageGRID verwendet einen einzigen globalen Namespace und speichert die Platzierungsorte der Objekte als Metadaten, sodass jeder Knoten weiß, wo sich alle Kopien oder Erasure-Coded-Teile befinden. Wenn ein Objekt nicht von der Site abgerufen werden kann, von der die Anforderung gestellt wurde, wird es automatisch von einer Remote-Site abgerufen, ohne dass Failover-Verfahren erforderlich sind.
Sobald der Ausfall behoben ist, sind keine manuellen Failback-Prozesse erforderlich. Die Replizierungs-Performance hängt von dem Standort mit dem niedrigsten Netzwerkdurchsatz, der höchsten Latenz und der niedrigsten Performance ab. Die Performance eines Standorts basiert auf der Anzahl der Nodes, der Anzahl und Geschwindigkeit der CPU-Kerne, dem Arbeitsspeicher, der Anzahl der Laufwerke und den Laufwerkstypen.
Multi-Grid-Lösungen: StorageGRID kann Mandanten, Benutzer und Buckets mithilfe von Grid-übergreifender Replikation (CGR) zwischen mehreren StorageGRID-Systemen replizieren. CGR kann ausgewählte Daten auf mehr als 16 Standorte erweitern, die nutzbare Kapazität Ihres Objektspeichers erhöhen und Disaster Recovery bereitstellen. Die Replikation von Buckets mit CGR umfasst Objekte, Objektversionen und Metadaten und kann bidirektional oder einseitig erfolgen. Der Recovery-Zeitpunkt (Recovery Point Objective, RPO) hängt von der Performance des jeweiligen StorageGRID-Systems und der Netzwerkverbindungen zwischen diesen Systemen ab.
Zusammenfassung:
-
Die Grid-interne Replizierung umfasst sowohl synchrone als auch asynchrone Replizierung, die mithilfe des ILM-Aufnahmeverhaltens und der Konsistenzkontrolle für Metadaten konfigurierbar ist.
-
Die Replizierung zwischen dem Grid erfolgt nur asynchron.
Bereitstellung über mehrere Standorte in einem einzigen Grid
In den folgenden Szenarien werden die StorageGRID Lösungen mit einem optionalen externen Load Balancer konfiguriert, der die Anfragen an die integrierten Load-Balancer-Hochverfügbarkeitsgruppen verwaltet. Dadurch wird sowohl ein RTO von Null als auch ein RPO von Null erreicht. ILM ist mit Balanced Ingest Protection für die synchrone Platzierung konfiguriert. Jeder Bucket ist mit der Quorum-Version des Strong Global-Konsistenzmodells für Grids mit 3 oder mehr Standorten und der Legacy-Version des Strong Global-Konsistenzmodells für 2 Standorte konfiguriert.
Szenario 1:
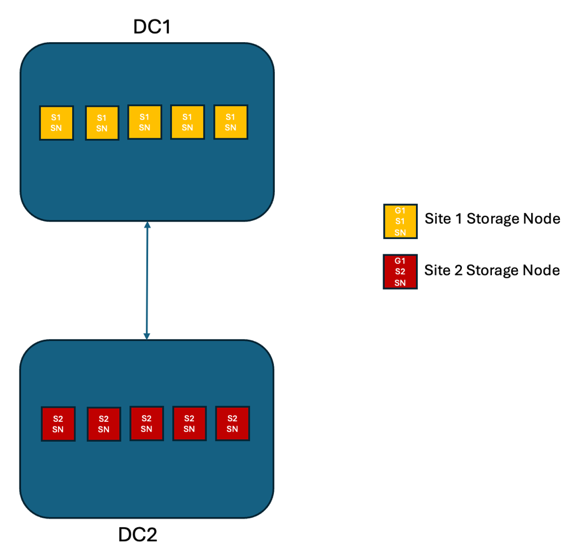
Bei einer StorageGRID Lösung mit zwei Standorten gibt es mindestens zwei Replikate jedes Objekts und sechs Replikate aller Metadaten. Nach der Wiederherstellung nach einem Ausfall werden die Aktualisierungen vom Ausfallort automatisch mit dem wiederhergestellten Standort/den wiederhergestellten Knoten synchronisiert. Bei nur zwei Standorten ist es unwahrscheinlich, dass in Ausfallszenarien, die über einen vollständigen Standortausfall hinausgehen, ein RPO von Null erreicht werden kann.
Szenario 2:
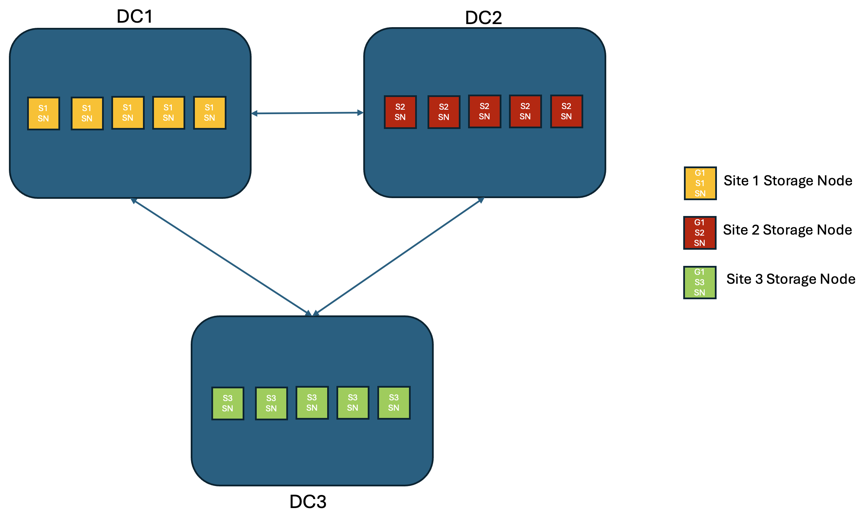
In einer StorageGRID Lösung mit drei oder mehr Standorten gibt es mindestens 3 Replikate oder 3 EC-Chunks von jedem Objekt und 9 Replikate aller Metadaten. Nach der Wiederherstellung nach einem Ausfall werden die Aktualisierungen vom Ausfallort automatisch mit dem wiederhergestellten Standort/den wiederhergestellten Knoten synchronisiert. Mit drei oder mehr Standorten ist es möglich, einen RPO von Null zu erreichen.
Ausfallszenarien für mehrere Standorte
| Ausfall | Ergebnis an zwei Standorten + Vermächtnis Starke globale Präsenz | Ergebnis von 3 oder mehr Standorten + Quorum Strong Global |
|---|---|---|
Ausfall eines Laufwerks mit einem Node |
Jede Appliance nutzt mehrere Festplattengruppen und kann den Ausfall von mindestens einem Laufwerk pro Gruppe ohne Unterbrechung oder Datenverlust überstehen. |
Jede Appliance nutzt mehrere Festplattengruppen und kann den Ausfall von mindestens einem Laufwerk pro Gruppe ohne Unterbrechung oder Datenverlust überstehen. |
Ausfall eines einzelnen Nodes an einem Standort |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall mehrerer Nodes an einem Standort |
Auf diesen Standort gerichtete Unterbrechung von Client-Vorgängen, jedoch kein Datenverlust. Der auf den anderen Standort gerichtete Betrieb bleibt ohne Unterbrechung und ohne Datenverlust erhalten. |
Der Betrieb wird auf alle anderen Standorte geleitet und erfolgt ohne Unterbrechung und Datenverlust. |
Ausfall eines einzelnen Nodes an mehreren Standorten |
Keine Unterbrechungen oder Datenverluste bei:
Betriebsausfall und Gefahr von Datenverlusten bei:
|
Keine Unterbrechungen oder Datenverluste bei:
Betriebsausfall und Gefahr von Datenverlusten bei:
|
Ausfall eines einzelnen Standorts |
Einige Clientvorgänge werden unterbrochen, bis die Störung behoben ist. GET- und HEAD-Operationen werden ohne Unterbrechung fortgesetzt. Reduzieren Sie die Bucket-Konsistenz auf „Lesen nach neuem Schreiben“ oder niedriger, um den Betrieb in diesem Fehlerzustand ununterbrochen fortzusetzen. |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines Standorts und eines einzelnen Node |
Einige Clientvorgänge werden unterbrochen, bis der Fehler behoben ist. Der Betrieb von HEAD wird ohne Unterbrechung fortgesetzt. GET-Operationen werden ohne Unterbrechung fortgesetzt, wenn eine Replikatkopie oder ausreichend viele EC-Chunks vorhanden sind. Reduzieren Sie die Bucket-Konsistenz auf „Lesen nach neuem Schreiben“ oder niedriger, um den Betrieb in diesem Fehlerzustand ununterbrochen fortzusetzen. |
Keine Betriebsunterbrechung oder Datenverlust. Möglicher Datenverlust abhängig von der Anzahl der Replikate. Lokales Erasure Coding kann Datenverlust verhindern. |
Von jedem verbleibenden Standort aus einen Standort und einen Node |
Es existieren nur zwei Standorte. Siehe: Einzelner Standort plus ein einzelner Knoten. |
Der Betrieb wird gestört, wenn das Quorum für die Metadatenreplikate nicht erreicht werden kann. Reduzieren Sie die Bucket-Konsistenz auf „Lesen nach neuem Schreiben“ oder niedriger, um den Betrieb in diesem Fehlerzustand ununterbrochen fortzusetzen. Möglicher Datenverlust bei dauerhaftem Ausfall, abhängig von der Anzahl der Replikatkopien. Lokales Erasure Coding kann Datenverlust verhindern. |
Ausfall mehrerer Standorte |
Es gibt keine betriebsbereiten Standorte mehr. Daten gehen verloren, wenn auch nur ein Standort nicht vollständig wiederhergestellt werden kann. |
Der Betrieb wird gestört, wenn das Quorum für die Metadatenreplikate nicht erreicht werden kann. Reduzieren Sie die Bucket-Konsistenz auf „Lesen nach neuem Schreiben“ oder niedriger, um den Betrieb in diesem Fehlerzustand ununterbrochen fortzusetzen. Bei einem permanenten Ausfall ist ein Datenverlust möglich, wenn nicht genügend löschcodierte Datenblöcke übrig bleiben. Lokales Erasure-Coding oder das Erstellen von Replikaten können Datenverlust verhindern. |
Netzwerkisolierung eines Standorts |
Der Betrieb der Kunden wird unterbrochen, bis der Fehler behoben ist. Reduzieren Sie die Bucket-Konsistenz auf „Lesen nach neuem Schreiben“ oder niedriger, um den Betrieb in diesem Fehlerzustand ununterbrochen fortzusetzen. Kein Datenverlust |
Der Betrieb des isolierten Standorts wird beeinträchtigt sein, es wird jedoch keinen Datenverlust geben. Reduzieren Sie die Bucket-Konsistenz auf „Lesen nach neuem Schreiben“ oder niedriger, um den Betrieb in diesem Fehlerzustand ununterbrochen fortzusetzen. Keine Betriebsunterbrechungen an den übrigen Standorten und kein Datenverlust. |
Eine Multi-Grid-Implementierung an mehreren Standorten
Um eine zusätzliche Redundanzebene hinzuzufügen, werden in diesem Szenario zwei StorageGRID Cluster eingesetzt und mithilfe der Cross-Grid-Replikation synchron gehalten. Für diese Lösung verfügt jeder StorageGRID Cluster über drei Standorte. Zwei Standorte werden für die Objektspeicherung und Metadaten verwendet, während der dritte Standort ausschließlich für Metadaten genutzt wird. Beide Systeme werden mit einer ausgewogenen ILM-Regel konfiguriert, um die Objekte mithilfe von Erasure Coding an jedem der beiden Datenstandorte synchron zu speichern. Buckets werden mit dem Quorum Strong Global-Konsistenzmodell konfiguriert. Jedes Grid wird mit einer bidirektionalen Cross-Grid-Replikation auf jedem Bucket konfiguriert. Dies ermöglicht die asynchrone Replikation zwischen den Regionen. Optional kann ein globaler Load Balancer implementiert werden, um Anfragen an die integrierten Load Balancer-Hochverfügbarkeitsgruppen beider StorageGRID -Systeme zu verwalten und so ein RPO von Null zu erreichen.
Die Lösung nutzt vier Standorte, die gleichmäßig in zwei Regionen aufgeteilt sind. Region 1 enthält die 2 Storage-Standorte von Grid 1 als primäres Grid der Region und den Metadaten-Standort von Grid 2. Region 2 enthält die 2 Storage-Standorte von Grid 2 als primäres Grid der Region und den Metadaten-Standort von Grid 1. In jeder Region kann der gleiche Standort den Speicherort des primären Grids der Region sowie den nur-Metadaten-Standort des anderen Regionengitters beherbergen. Wenn Nodes als dritter Standort nur Metadaten verwendet werden, sorgen sie für die erforderliche Konsistenz für die Metadaten und nicht für das Duplizieren des Storage von Objekten an diesem Standort.
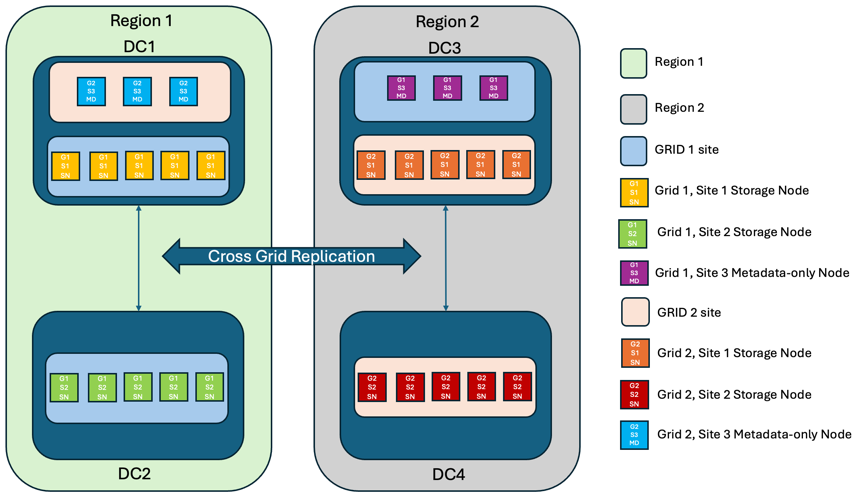
Diese Lösung mit vier separaten Standorten bietet vollständige Redundanz von zwei separaten StorageGRID-Systemen mit einem RPO von 0 und nutzt sowohl synchrone Replizierung an mehreren Standorten als auch asynchrone Replizierung in mehreren Grids. Bei jedem einzelnen Standort kann der Client-Betrieb auf beiden StorageGRID Systemen unterbrechungsfrei ausgeführt werden.
In dieser Lösung gibt es vier Kopien, die nach Erasure Coding codiert wurden, und 18 Replikate aller Metadaten. Dies ermöglicht mehrere Ausfallszenarien ohne Auswirkungen auf den Client-Betrieb. Bei einem Ausfall werden die Updates nach dem Ausfall automatisch mit dem ausgefallenen Standort bzw. den ausgefallenen Nodes synchronisiert.
Ausfallszenarien für mehrere Standorte und Grids
| Ausfall | Ergebnis |
|---|---|
Ausfall eines Laufwerks mit einem Node |
Jede Appliance nutzt mehrere Festplattengruppen und kann den Ausfall von mindestens einem Laufwerk pro Gruppe ohne Unterbrechung oder Datenverlust überstehen. |
Ausfall eines einzelnen Nodes an einem Standort in einem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines einzelnen Nodes an einem Standort in jedem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall mehrerer Nodes an einem Standort in einem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall mehrerer Nodes an einem Standort in jedem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines einzelnen Nodes an mehreren Standorten in einem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines einzelnen Nodes an mehreren Standorten in jedem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines einzelnen Standorts in einem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines Standorts in jedem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines einzelnen Standorts und eines einzelnen Node in einem Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ein Standort und ein Node von jedem verbleibenden Standort in einem einzelnen Grid |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines einzelnen Standorts |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines Standorts in jedem Grid DC1 und DC3 |
Der Betrieb wird unterbrochen, bis entweder der Fehler behoben oder die Bucket-Konsistenz verringert wird; jedes Grid hat 2 Standorte verloren Alle Daten sind noch an 2 Standorten vorhanden |
Ausfall eines Standorts in jedem Grid DC1 und DC4 oder DC2 und DC3 |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Ausfall eines Standorts in jedem Grid DC2 und DC4 |
Keine Unterbrechung von Prozessen oder Datenverlust: |
Netzwerkisolierung eines Standorts |
Der Betrieb des isolierten Standorts wird unterbrochen, aber es gehen keine Daten verloren Es gibt keine Unterbrechung des Betriebs an den verbleibenden Standorten oder Datenverluste. |
Schlussfolgerung
Das Erreichen eines Recovery Point Objective (RPO) von null mit StorageGRID ist ein wichtiges Ziel, um die Datenaufbewahrung und Verfügbarkeit bei Standortausfällen sicherzustellen. Durch den Einsatz der robusten Replikationsstrategien von StorageGRID, einschließlich synchroner Replizierung an mehreren Standorten und asynchroner Multi-Grid-Replizierung, können Unternehmen den unterbrechungsfreien Client-Betrieb gewährleisten und über mehrere Standorte hinweg für Datenkonsistenz sorgen. Die Implementierung von ILM-Richtlinien (Information Lifecycle Management) und die Verwendung von Nodes, die nur Metadaten enthalten, erhöhen die Ausfallsicherheit und Performance des Systems noch weiter. Mit StorageGRID können Unternehmen ihre Daten zuversichtlich managen, da sie wissen, dass sie auch bei komplexen Ausfallszenarien zugänglich und konsistent bleiben. Dieser umfassende Ansatz für Datenmanagement und -Replikation unterstreicht die Bedeutung einer sorgfältigen Planung und Ausführung bei der Erreichung eines Null-RPO-Ziels und der Sicherung wertvoller Informationen.