

Instalación y configuración del operador de monitoreo de Kubernetes
 Sugerir cambios
Sugerir cambios
Data Infrastructure Insights ofrece el Operador de monitoreo de Kubernetes para la recopilación de Kubernetes. Vaya a Kubernetes > Recopiladores > +Recopilador de Kubernetes para implementar un nuevo operador.
Antes de instalar el operador de monitoreo de Kubernetes
Ver el"Prerrequisitos" documentación antes de instalar o actualizar el Operador de Monitoreo de Kubernetes.
Instalación del operador de monitorización de Kubernetes
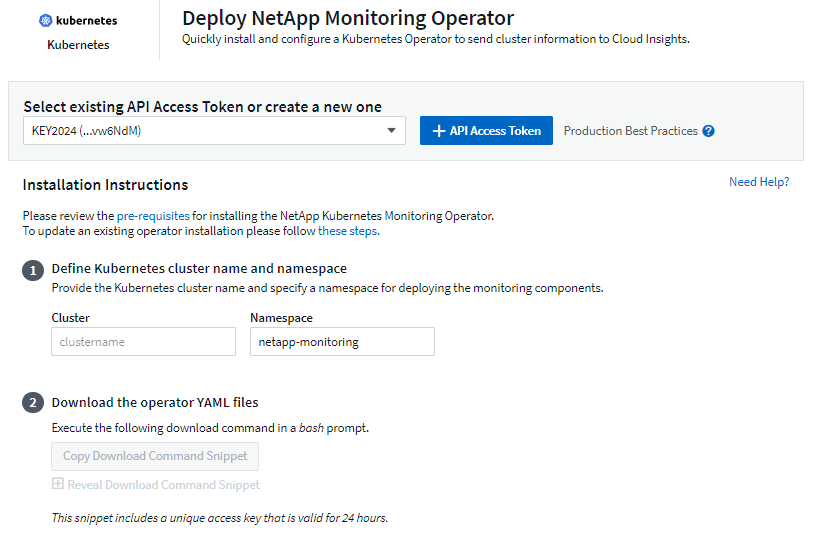
-
Introduzca un nombre de clúster y un espacio de nombres únicos. Si tu estasactualización de un operador de Kubernetes anterior, use el mismo nombre de clúster y espacio de nombres.
-
Una vez ingresados estos datos, puedes copiar el fragmento del comando de descarga al portapapeles.
-
Pegue el fragmento en una ventana bash y ejecútelo. Se descargarán los archivos de instalación del operador. Tenga en cuenta que el fragmento tiene una clave única y es válido durante 24 horas.
-
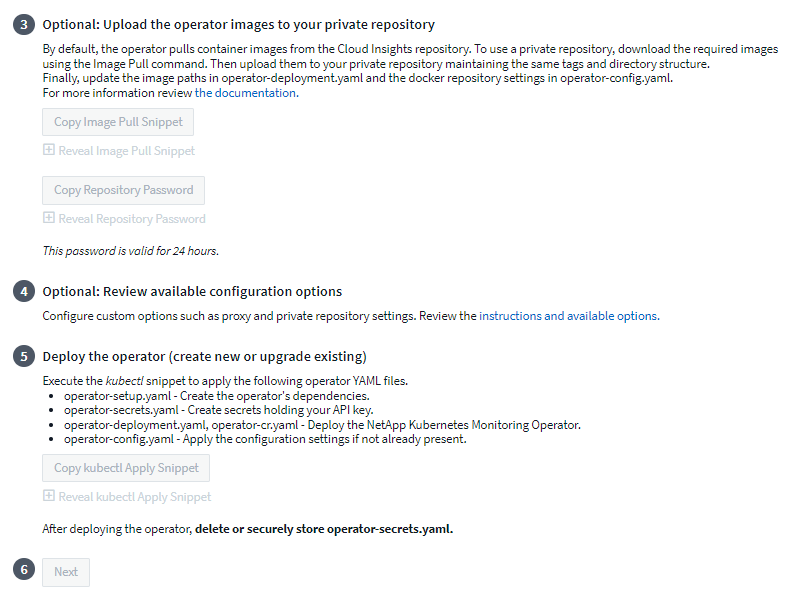
Si tiene un repositorio personalizado o privado, copie el fragmento de Image Pull opcional, péguelo en un shell bash y ejecútelo. Una vez extraídas las imágenes, cópielas a su repositorio privado. Asegúrese de mantener las mismas etiquetas y estructura de carpetas. Actualice las rutas en operator-deployment.yaml así como la configuración del repositorio de Docker en operator-config.yaml.
-
Si lo desea, revise las opciones de configuración disponibles, como la configuración de proxy o repositorio privado. Puedes leer más sobre"opciones de configuración" .
-
Cuando esté listo, implemente el operador copiando el fragmento de kubectl Apply, descargándolo y ejecutándolo.
-
La instalación se realiza automáticamente. Cuando haya terminado, haga clic en el botón Siguiente.
-
Cuando se complete la instalación, haga clic en el botón Siguiente. Asegúrese de eliminar también o almacenar de forma segura el archivo operator-secrets.yaml.
Si tiene un repositorio personalizado, lea sobreUsando un repositorio Docker personalizado/privado .
Componentes de monitorización de Kubernetes
El monitoreo de Kubernetes de Data Infrastructure Insights consta de cuatro componentes de monitoreo:
-
Métricas de clúster
-
Rendimiento y mapa de la red (opcional)
-
Registros de eventos (opcional)
-
Análisis de cambios (opcional)
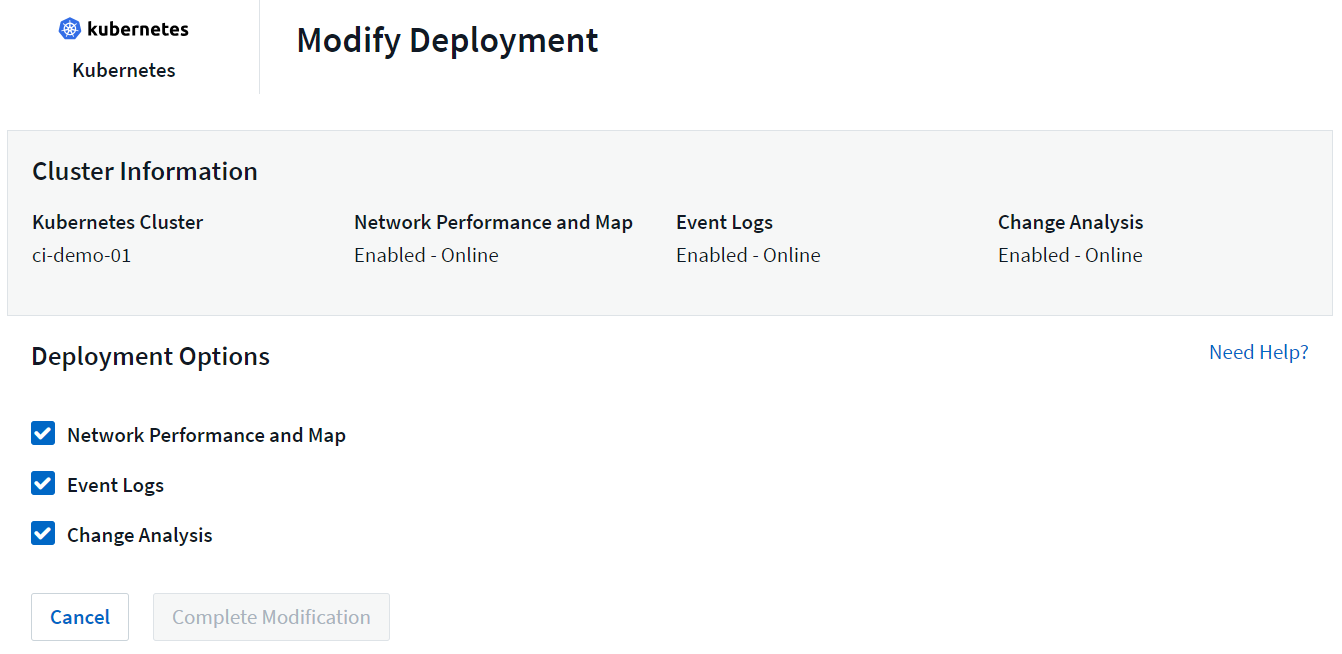
Los componentes opcionales anteriores están habilitados de forma predeterminada para cada recopilador de Kubernetes; si decide que no necesita un componente para un recopilador en particular, puede deshabilitarlo navegando a Kubernetes > Recopiladores y seleccionando Modificar implementación en el menú de "tres puntos" del recopilador a la derecha de la pantalla.
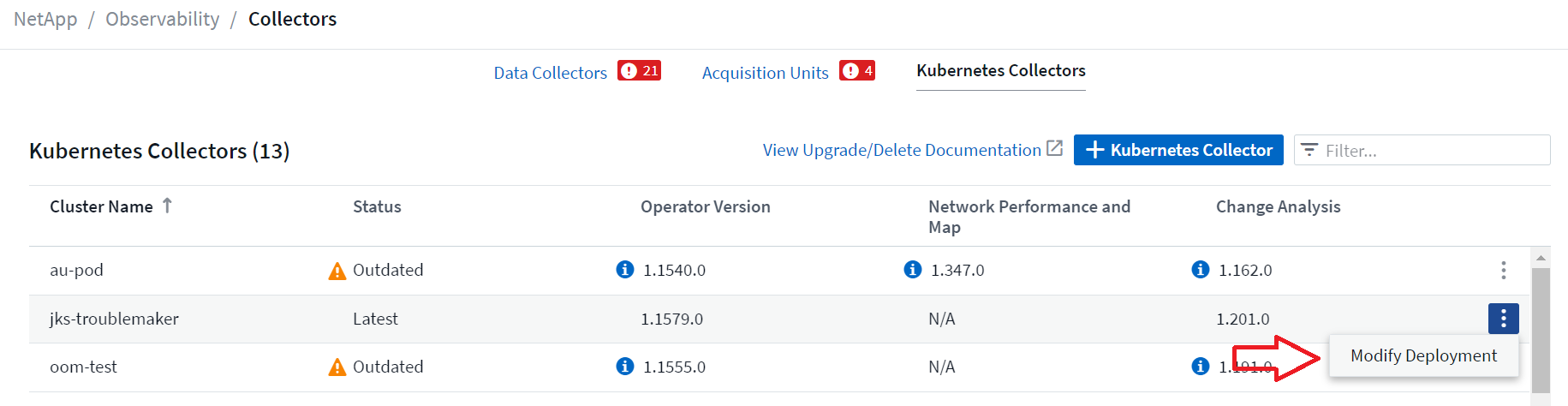
La pantalla muestra el estado actual de cada componente y le permite deshabilitar o habilitar componentes para ese recopilador según sea necesario.
Actualización al último operador de monitoreo de Kubernetes
Actualizaciones del pulsador DII
Puede actualizar el operador de monitoreo de Kubernetes a través de la página Recopiladores de Kubernetes de DII. Haga clic en el menú junto al clúster que desea actualizar y seleccione Actualizar. El operador verificará las firmas de la imagen, realizará una instantánea de su instalación actual y realizará la actualización. En unos minutos deberías ver el progreso del estado del operador desde Actualización en progreso hasta Último. Si encuentra un error, puede seleccionar el estado de Error para obtener más detalles y consultar la tabla de solución de problemas de actualizaciones con botón a continuación.

|
Las actualizaciones mediante pulsador no están disponibles para las versiones del operador anteriores a la 1.2057.0. Sigue las instrucciones de actualización manual que aparecen a continuación para actualizar a la última versión. Después de hacer esto, las futuras actualizaciones se pueden realizar usando la función de actualización mediante pulsador. |
Actualizaciones con solo pulsar un botón con repositorios privados
Si su operador está configurado para utilizar un repositorio privado, asegúrese de que todas las imágenes necesarias para ejecutar el operador y sus firmas estén disponibles en su repositorio. Si encuentra un error durante el proceso de actualización por imágenes faltantes, simplemente agréguelas a su repositorio y vuelva a intentar la actualización. Para cargar las firmas de imágenes a su repositorio, utilice la herramienta de firma conjunta de la siguiente manera, asegurándose de cargar las firmas para todas las imágenes especificadas en 3 Opcional: Cargue las imágenes del operador a su repositorio privado > Fragmento de extracción de imagen
cosign copy example.com/src:v1 example.com/dest:v1 #Example cosign copy <DII container registry>/netapp-monitoring:<image version> <private repository>/netapp-monitoring:<image version>
Volver a una versión que se estaba ejecutando anteriormente
Si realizó la actualización mediante la función de actualización con solo presionar un botón y encuentra dificultades con la versión actual del operador dentro de los siete días posteriores a la actualización, puede volver a la versión que se estaba ejecutando anteriormente utilizando la instantánea creada durante el proceso de actualización. Haga clic en el menú junto al clúster que desea revertir y seleccione Revertir.
Actualizaciones manuales
Determina si existe un AgentConfiguration con el Operador existente (si tu espacio de nombres no es el predeterminado netapp-monitoring, sustitúyelo por el espacio de nombres adecuado):
kubectl -n netapp-monitoring get agentconfiguration netapp-ci-monitoring-configuration Si existe una _AgentConfiguration_:
-
InstalarEl último operador sobre el operador existente.
-
Asegúrese de que estáextrayendo las últimas imágenes de contenedores si está utilizando un repositorio personalizado.
-
Si la AgentConfiguration no existe:
-
Tome nota del nombre de su clúster tal como lo reconoce Data Infrastructure Insights (si su espacio de nombres no es el predeterminado netapp-monitoring, sustitúyalo por el espacio de nombres apropiado):
kubectl -n netapp-monitoring get agent -o jsonpath='{.items[0].spec.cluster-name}' * Cree una copia de seguridad del operador existente (si su espacio de nombres no es el predeterminado netapp-monitoring, sustitúyalo por el espacio de nombres apropiado):kubectl -n netapp-monitoring get agent -o yaml > agent_backup.yaml * <<to-remove-the-kubernetes-monitoring-operator,Desinstalar>>el operador existente. * <<installing-the-kubernetes-monitoring-operator,Instalar>>El último operador.
-
Utilice el mismo nombre de clúster.
-
Después de descargar los últimos archivos YAML de Operator, transfiere cualquier personalización encontrada en agent_backup.yaml al operator-config.yaml descargado antes de desplegar.
-
Asegúrese de que estáextrayendo las últimas imágenes de contenedores si está utilizando un repositorio personalizado.
-
Detener e iniciar el operador de monitoreo de Kubernetes
Para detener el operador de monitoreo de Kubernetes:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=0 Para iniciar el operador de monitoreo de Kubernetes:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=1
Desinstalación
Para eliminar el operador de monitoreo de Kubernetes
Tenga en cuenta que el espacio de nombres predeterminado para el operador de monitoreo de Kubernetes es "netapp-monitoring". Si ha configurado su propio espacio de nombres, sustitúyalo en estos y todos los comandos y archivos posteriores.
Las versiones más nuevas del operador de monitoreo se pueden desinstalar con los siguientes comandos:
kubectl -n <NAMESPACE> delete agent -l installed-by=nkmo-<NAMESPACE> kubectl -n <NAMESPACE> delete clusterrole,clusterrolebinding,crd,svc,deploy,role,rolebinding,secret,sa -l installed-by=nkmo-<NAMESPACE>
Si el operador de monitoreo se implementó en su propio espacio de nombres dedicado, elimine el espacio de nombres:
kubectl delete ns <NAMESPACE> Nota: Si el primer comando devuelve “No se encontraron recursos”, utilice las siguientes instrucciones para desinstalar versiones anteriores del operador de monitoreo.
Ejecute cada uno de los siguientes comandos en orden. Dependiendo de su instalación actual, algunos de estos comandos pueden devolver mensajes de "objeto no encontrado". Estos mensajes pueden ignorarse sin problemas.
kubectl -n <NAMESPACE> delete agent agent-monitoring-netapp kubectl delete crd agents.monitoring.netapp.com kubectl -n <NAMESPACE> delete role agent-leader-election-role kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader <NAMESPACE>-agent-manager-role <NAMESPACE>-agent-proxy-role <NAMESPACE>-cluster-role-privileged kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding <NAMESPACE>-agent-manager-rolebinding <NAMESPACE>-agent-proxy-rolebinding <NAMESPACE>-cluster-role-binding-privileged kubectl delete <NAMESPACE>-psp-nkmo kubectl delete ns <NAMESPACE>
Si se creó previamente una restricción de contexto de seguridad:
kubectl delete scc telegraf-hostaccess
Acerca de Kube-state-metrics
El operador de monitoreo de Kubernetes de NetApp instala sus propias métricas de estado de kube para evitar conflictos con otras instancias.
Para obtener información sobre Kube-State-Metrics, consulte"esta página" .
Configuración/personalización del operador
Estas secciones contienen información sobre cómo personalizar la configuración de su operador, trabajar con proxy, utilizar un repositorio Docker personalizado o privado o trabajar con OpenShift.
Opciones de configuración
Las configuraciones más comúnmente modificadas se pueden configurar en el recurso personalizado AgentConfiguration. Puede editar este recurso antes de implementar el operador editando el archivo operator-config.yaml. Este archivo incluye ejemplos de configuraciones comentadas. Ver la lista de"configuraciones disponibles" para la versión más reciente del operador.
También puede editar este recurso después de que se haya implementado el operador utilizando el siguiente comando:
kubectl -n netapp-monitoring edit AgentConfiguration Para determinar si tu versión desplegada del operador soporta _AgentConfiguration_, ejecuta el siguiente comando:
kubectl get crd agentconfigurations.monitoring.netapp.com Si ve un mensaje de “Error del servidor (No encontrado)”, su operador debe actualizarse antes de poder usar AgentConfiguration.
Configuración del soporte de proxy
Hay dos lugares donde puedes usar un proxy en tu inquilino para instalar el Operador de Monitoreo de Kubernetes. Estos pueden ser los mismos sistemas proxy o sistemas separados:
-
Se necesita un proxy durante la ejecución del fragmento de código de instalación (usando "curl") para conectar el sistema donde se ejecuta el fragmento a su entorno de Data Infrastructure Insights
-
Proxy necesario para que el clúster de Kubernetes de destino se comunique con su entorno de Data Infrastructure Insights
Si usa un proxy para uno o ambos de estos, para instalar Kubernetes Operating Monitor primero debe asegurarse de que su proxy esté configurado para permitir una buena comunicación con su entorno de Data Infrastructure Insights . Si tiene un proxy y puede acceder a Data Infrastructure Insights desde el servidor/VM desde el que desea instalar el Operador, entonces es probable que su proxy esté configurado correctamente.
Para el proxy utilizado para instalar Kubernetes Operating Monitor, antes de instalar el Operador, configure las variables de entorno http_proxy/https_proxy. Para algunos entornos de proxy, es posible que también necesite configurar la variable de entorno no_proxy.
Para configurar las variables, realice los siguientes pasos en su sistema antes de instalar el operador de monitoreo de Kubernetes:
-
Establezca las variables de entorno https_proxy y/o http_proxy para el usuario actual:
-
Si el proxy que se está configurando no tiene autenticación (nombre de usuario/contraseña), ejecute el siguiente comando:
export https_proxy=<proxy_server>:<proxy_port> .. Si el proxy que se está configurando tiene autenticación (nombre de usuario/contraseña), ejecute este comando:
export http_proxy=<proxy_username>:<proxy_password>@<proxy_server>:<proxy_port>
-
Para que el proxy utilizado para su clúster de Kubernetes se comunique con su entorno de Data Infrastructure Insights , instale el Operador de monitoreo de Kubernetes después de leer todas estas instrucciones.
Configura la sección proxy de AgentConfiguration en operator-config.yaml antes de desplegar el Kubernetes Monitoring Operator.
agent:
...
proxy:
server: <server for proxy>
port: <port for proxy>
username: <username for proxy>
password: <password for proxy>
# In the noproxy section, enter a comma-separated list of
# IP addresses and/or resolvable hostnames that should bypass
# the proxy
noproxy: <comma separated list>
isTelegrafProxyEnabled: true
isFluentbitProxyEnabled: <true or false> # true if Events Log enabled
isCollectorsProxyEnabled: <true or false> # true if Network Performance and Map enabled
isAuProxyEnabled: <true or false> # true if AU enabled
...
...
Uso de un repositorio Docker personalizado o privado
De forma predeterminada, el operador de monitoreo de Kubernetes extraerá imágenes de contenedores del repositorio de Data Infrastructure Insights . Si tiene un clúster de Kubernetes utilizado como destino para la supervisión, y ese clúster está configurado para extraer únicamente imágenes de contenedores desde un repositorio de Docker personalizado o privado o un registro de contenedores, debe configurar el acceso a los contenedores que necesita el operador de supervisión de Kubernetes.
Ejecute el “Fragmento de extracción de imagen” desde el mosaico de instalación del Operador de monitoreo de NetApp . Este comando iniciará sesión en el repositorio de Data Infrastructure Insights , extraerá todas las dependencias de imágenes para el operador y cerrará sesión en el repositorio de Data Infrastructure Insights . Cuando se le solicite, ingrese la contraseña temporal del repositorio proporcionada. Este comando descarga todas las imágenes utilizadas por el operador, incluidas las funciones opcionales. Vea a continuación para qué funciones se utilizan estas imágenes.
Funcionalidad del operador principal y monitoreo de Kubernetes
-
Monitoreo de netapp
-
proxy ci-kube-rbac
-
ci-ksm
-
ci-telegraf
-
usuario root sin distribución
Registro de eventos
-
ci-fluent-bit
-
exportador de eventos de ci-kubernetes
Rendimiento y mapa de la red
-
observador de ci-net
Análisis de cambios
-
ci-k8s-change-observer
Envíe la imagen de Docker del operador a su repositorio de Docker privado/local/empresarial de acuerdo con sus políticas corporativas. Asegúrese de que las etiquetas de imagen y las rutas de directorio de estas imágenes en su repositorio sean coherentes con las del repositorio de Data Infrastructure Insights .
Edite la implementación del operador de monitoreo en operator-deployment.yaml y modifique todas las referencias de imágenes para usar su repositorio privado de Docker.
image: <docker repo of the enterprise/corp docker repo>/ci-kube-rbac-proxy:<ci-kube-rbac-proxy version> image: <docker repo of the enterprise/corp docker repo>/netapp-monitoring:<version>
Edita el AgentConfiguration en operator-config.yaml para reflejar la nueva ubicación del repositorio docker. Crea un nuevo imagePullSecret para tu repositorio privado, para más detalles ve https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
agent: ... # An optional docker registry where you want docker images to be pulled from as compared to CI's docker registry # Please see documentation link here: link:task_config_telegraf_agent_k8s.html#using-a-custom-or-private-docker-repository[Using a custom or private docker repository] dockerRepo: your.docker.repo/long/path/to/test # Optional: A docker image pull secret that maybe needed for your private docker registry dockerImagePullSecret: docker-secret-name
Token de acceso API para contraseñas de larga duración
Algunos entornos (es decir, repositorios proxy) requieren contraseñas de larga duración para el repositorio docker de Data Infrastructure Insights. La contraseña proporcionada en la UI durante la instalación solo es válida por 24 horas. En lugar de usar esa, se puede usar un API Access Token como la contraseña del repositorio docker. Esta contraseña será válida mientras el API Access Token sea válido. Se puede generar un nuevo API Access Token para este propósito específico o usar uno existente.
"Lee aquí" para obtener instrucciones para crear un nuevo API Access Token.
Para extraer un API Access Token existente de un archivo operator-secrets.yaml descargado, los usuarios pueden ejecutar lo siguiente:
grep '\.dockerconfigjson' operator-secrets.yaml |sed 's/.*\.dockerconfigjson: //g' |base64 -d |jq
Para extraer un token de acceso a la API existente de una instalación de operador en ejecución, los usuarios pueden ejecutar lo siguiente:
kubectl -n netapp-monitoring get secret netapp-ci-docker -o jsonpath='{.data.\.dockerconfigjson}' |base64 -d |jq
Instrucciones de OpenShift
Si estás ejecutando en OpenShift 4.6 o superior, debes editar el AgentConfiguration en operator-config.yaml para habilitar la opción runPrivileged:
# Set runPrivileged to true SELinux is enabled on your kubernetes nodes runPrivileged: true
Openshift puede implementar un nivel adicional de seguridad que puede bloquear el acceso a algunos componentes de Kubernetes.
Tolerancias y Manchas
Los DaemonSets netapp-ci-telegraf-ds, netapp-ci-fluent-bit-ds y netapp-ci-net-observer-l4-ds deben programar un pod en cada nodo de su clúster para poder recopilar datos correctamente en todos los nodos. El operador ha sido configurado para tolerar algunas manchas bien conocidas. Si ha configurado alguna tolerancia personalizada en sus nodos, lo que impide que los pods se ejecuten en todos los nodos, puede crear una tolerancia para esas tolerancias."en la Configuración del agente" . Si ha aplicado tolerancias personalizadas a todos los nodos de su clúster, también debe agregar las tolerancias necesarias a la implementación del operador para permitir que el pod del operador se programe y ejecute.
Más información sobre Kubernetes"Manchas y tolerancias" .
Verificación de las firmas de imágenes del operador de monitoreo de Kubernetes
La imagen del operador y todas las imágenes relacionadas que implementa están firmadas por NetApp. Puede verificar manualmente las imágenes antes de la instalación utilizando la herramienta de firma conjunta o configurar un controlador de admisión de Kubernetes. Para más detalles, consulte la"Documentación de Kubernetes" .
La clave pública utilizada para verificar las firmas de imágenes está disponible en el mosaico de instalación del Operador de Monitoreo en Opcional: Cargue las imágenes del operador a su repositorio privado > Clave pública de firma de imagen
Para verificar manualmente una firma de imagen, realice los siguientes pasos:
-
Copiar y ejecutar el fragmento de extracción de imagen
-
Copie e ingrese la contraseña del repositorio cuando se le solicite
-
Almacenar la clave pública de la firma de la imagen (dii-image-signing.pub en el ejemplo)
-
Verificar las imágenes usando cosign. Consulte el siguiente ejemplo de uso de cosignatarios
$ cosign verify --key dii-image-signing.pub --insecure-ignore-sct --insecure-ignore-tlog <repository>/<image>:<tag>
Verification for <repository>/<image>:<tag> --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
[{"critical":{"identity":{"docker-reference":"<repository>/<image>"},"image":{"docker-manifest-digest":"sha256:<hash>"},"type":"cosign container image signature"},"optional":null}]
Solución de problemas
Algunas cosas que puedes probar si tienes problemas al configurar el operador de monitoreo de Kubernetes:
| Problema: | Prueba esto: |
|---|---|
No veo un hipervínculo/conexión entre mi volumen persistente de Kubernetes y el dispositivo de almacenamiento de back-end correspondiente. Mi volumen persistente de Kubernetes está configurado utilizando el nombre de host del servidor de almacenamiento. |
Siga los pasos para desinstalar el agente Telegraf existente y luego vuelva a instalar el agente Telegraf más reciente. Debe utilizar la versión 2.0 o posterior de Telegraf, y el almacenamiento de su clúster de Kubernetes debe estar monitoreado activamente por Data Infrastructure Insights. |
Veo mensajes en los registros similares a los siguientes: E0901 15:21:39.962145 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: No se pudo enumerar *v1.MutatingWebhookConfiguration: el servidor no pudo encontrar el recurso solicitado E0901 15:21:43.168161 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: No se pudo enumerar *v1.Lease: el servidor no pudo encontrar el recurso solicitado (get leases.coordination.k8s.io) etc. |
Estos mensajes pueden aparecer si está ejecutando kube-state-metrics versión 2.0.0 o superior con versiones de Kubernetes inferiores a 1.20. Para obtener la versión de Kubernetes: kubectl version Para obtener la versión de kube-state-metrics: kubectl get deploy/kube-state-metrics -o jsonpath='{..image}' Para evitar que aparezcan estos mensajes, los usuarios pueden modificar su implementación de kube-state-metrics para deshabilitar las siguientes concesiones: mutatingwebhookconfigurations validatingwebhookconfigurations volumeattachments resources Más específicamente, pueden usar el siguiente argumento de CLI: resources=certificatesigningrequests,configmaps,cronjobs,daemonsets,ployments,endpoints,horizontalpodautoscalers,ingresses,jobs,limitranges, namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes, poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas, Secretos, servicios, conjuntos con estado, clases de almacenamiento. La lista de recursos predeterminada es: "solicitudes de firma de certificados, mapas de configuración, trabajos cron, conjuntos de daemon, implementaciones, puntos finales, escaladores automáticos de pods horizontales, ingresos, trabajos, concesiones, rangos de límites, configuraciones de webhook mutantes, espacios de nombres, políticas de red, nodos, reclamaciones de volumen persistente, volúmenes persistentes, presupuestos de interrupción de pods, pods, conjuntos de réplicas, controladores de replicación, cuotas de recursos, secretos, servicios, conjuntos con estado, clases de almacenamiento, configuraciones de webhook de validación, archivos adjuntos de volumen". |
Veo mensajes de error de Telegraf similares a los siguientes, pero Telegraf se inicia y se ejecuta: 11 de octubre 14:23:41 ip-172-31-39-47 systemd[1]: iniciado El agente de servidor controlado por complemento para informar métricas en InfluxDB. 11 oct 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="No se pudo crear el directorio de caché. /etc/telegraf/.cache/snowflake, err: mkdir /etc/telegraf/.ca che: permiso denegado. ignorado\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11 oct 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="error al abrir. Ignorado. abrir /etc/telegraf/.cache/snowflake/ocsp_response_cache.json: no existe el archivo o directorio\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11 oct 14:23:41 ip-172-31-39-47 telegraf[1827]: 2021-10-11T14:23:41Z ¡Yo! Iniciando Telegraf 1.19.3 |
Este es un problema conocido. Referirse a"Este artículo de GitHub" Para más detalles. Mientras Telegraf esté en funcionamiento, los usuarios pueden ignorar estos mensajes de error. |
En Kubernetes, mis pods de Telegraf informan el siguiente error: "Error al procesar la información de mountstats: no se pudo abrir el archivo mountstats: /hostfs/proc/1/mountstats, error: abrir /hostfs/proc/1/mountstats: permiso denegado". |
Si SELinux está habilitado y en ejecución, es probable que impida que los pods de Telegraf accedan al archivo /proc/1/mountstats en el nodo Kubernetes. Para superar esta restricción, edite la configuración del agente y habilite la configuración runPrivileged. Para obtener más detalles, consulte las instrucciones de OpenShift. |
En Kubernetes, mi pod Telegraf ReplicaSet informa el siguiente error: [inputs.prometheus] Error en el complemento: no se pudo cargar el par de claves /etc/kubernetes/pki/etcd/server.crt:/etc/kubernetes/pki/etcd/server.key: abrir /etc/kubernetes/pki/etcd/server.crt: no existe el archivo o directorio |
El pod Telegraf ReplicaSet está diseñado para ejecutarse en un nodo designado como maestro o para etcd. Si el pod ReplicaSet no se está ejecutando en uno de estos nodos, obtendrá estos errores. Verifique si sus nodos maestros/etcd tienen manchas. Si es así, agregue las tolerancias necesarias al Telegraf ReplicaSet, telegraf-rs. Por ejemplo, edite ReplicaSet… kubectl edit rs telegraf-rs …y agregue las tolerancias apropiadas a la especificación. Luego, reinicie el pod ReplicaSet. |
Tengo un entorno PSP/PSA. ¿Esto afecta a mi operador de monitoreo? |
Si su clúster de Kubernetes se ejecuta con la Política de seguridad de pod (PSP) o la Admisión de seguridad de pod (PSA) implementadas, debe actualizar al Operador de monitoreo de Kubernetes más reciente. Siga estos pasos para actualizar al Operador actual con soporte para PSP/PSA: 1. Desinstalar el operador de monitorización anterior: kubectl delete agent agent-monitoring-netapp -n netapp-monitoring kubectl delete ns netapp-monitoring kubectl delete crd agents.monitoring.netapp.com kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding 2. Instalar la última versión del operador de monitoreo. |
Tuve problemas al intentar implementar el Operador y tengo PSP/PSA en uso. |
1. Edite el agente utilizando el siguiente comando: kubectl -n <name-space> edit agent 2. Marcar 'security-policy-enabled' como 'falso'. Esto deshabilitará las Políticas de seguridad de pod y la Admisión de seguridad de pod y permitirá que el Operador realice la implementación. Confirme usando los siguientes comandos: kubectl get psp (debería mostrar que se eliminó la política de seguridad del pod) kubectl get all -n <namespace> |
grep -i psp (debería mostrar que no se encontró nada) |
Errores "ImagePullBackoff" detectados |
Estos errores pueden aparecer si tienes un repositorio de docker personalizado o privado y aún no has configurado el Kubernetes Monitoring Operator para que lo reconozca correctamente. Leer más sobre cómo configurar para un repo personalizado/privado. |
Tengo un problema con la implementación de mi operador de monitoreo y la documentación actual no me ayuda a resolverlo. |
Capture o anote de otro modo el resultado de los siguientes comandos y comuníquese con el equipo de soporte técnico. kubectl -n netapp-monitoring get all kubectl -n netapp-monitoring describe all kubectl -n netapp-monitoring logs <monitoring-operator-pod> --all-containers=true kubectl -n netapp-monitoring logs <telegraf-pod> --all-containers=true |
Los pods de net-observer (Mapa de carga de trabajo) en el espacio de nombres del operador están en CrashLoopBackOff |
Estos pods corresponden al recopilador de datos del mapa de carga de trabajo para la observabilidad de la red. Pruebe lo siguiente: • Verifique los registros de uno de los pods para confirmar la versión mínima del kernel. Por ejemplo: ---- {"ci-tenant-id":"your-tenant-id","collector-cluster":"your-k8s-cluster-name","environment":"prod","level":"error","msg":"error en la validación. Motivo: la versión del kernel 3.10.0 es inferior a la versión mínima del kernel 4.18.0","time":"2022-11-09T08:23:08Z"} ---- • Los pods de Net-observer requieren que la versión del kernel de Linux sea al menos 4.18.0. Verifique la versión del kernel usando el comando “uname -r” y asegúrese de que sea >= 4.18.0 |
Los pods se ejecutan en el espacio de nombres del operador (predeterminado: netapp-monitoring), pero no se muestran datos en la interfaz de usuario para el mapa de carga de trabajo ni las métricas de Kubernetes en las consultas. |
Verifique la configuración de la hora en los nodos del clúster K8S. Para obtener informes de datos y auditorías precisos, se recomienda encarecidamente sincronizar la hora en la máquina del Agente mediante el Protocolo de tiempo de red (NTP) o el Protocolo simple de tiempo de red (SNTP). |
Algunos de los pods de net-observer en el espacio de nombres del operador están en estado pendiente |
Net-observer es un DaemonSet y ejecuta un pod en cada nodo del clúster k8s. • Observe el pod que está en estado pendiente y verifique si está experimentando un problema de recursos de CPU o memoria. Asegúrese de que la memoria y la CPU necesarias estén disponibles en el nodo. |
Veo lo siguiente en mis registros inmediatamente después de instalar el operador de monitoreo de Kubernetes: [inputs.prometheus] Error en el complemento: error al realizar la solicitud HTTP a http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics: Obtener http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics: marcar tcp: buscar kube-state-metrics.<namespace>.svc.cluster.local: no existe dicho host |
Este mensaje normalmente solo se ve cuando se instala un nuevo operador y el pod telegraf-rs está activo antes que el pod ksm. Estos mensajes deberían detenerse una vez que todos los pods estén ejecutándose. |
No veo ninguna métrica recopilada para los CronJobs de Kubernetes que existen en mi clúster. |
Verifique su versión de Kubernetes (es decir, |
Después de instalar el operador, los pods telegraf-ds ingresan a CrashLoopBackOff y los registros de los pods indican "su: Error de autenticación". |
Edita la sección telegraf en AgentConfiguration, y establece dockerMetricCollectionEnabled en false. Para más detalles, consulta el "opciones de configuración" del operador. … spec: … telegraf: … - name: docker run-mode: - DaemonSet substitutions: - key: DOCKER_UNIX_SOCK_PLACEHOLDER value: unix:///run/docker.sock … … |
Veo mensajes de error repetidos similares al siguiente en mis registros de Telegraf: E! [agente] Error al escribir en outputs.http: Publicación "https://<tenant_url>/rest/v1/lake/ingest/influxdb": se excedió el plazo de contexto (se excedió el tiempo de espera del cliente mientras se esperaban los encabezados) |
Edite la sección telegraf en AgentConfiguration y aumente outputTimeout a 10 s. Para obtener más detalles, consulte el manual del operador."opciones de configuración" . |
Me faltan datos de involvedobject para algunos registros de eventos. |
Asegúrese de haber seguido los pasos de la"Permisos" Sección anterior. |
¿Por qué veo dos pods de operador de monitoreo en ejecución, uno llamado netapp-ci-monitoring-operator-<pod> y el otro llamado monitoring-operator-<pod>? |
A partir del 12 de octubre de 2023, Data Infrastructure Insights ha refactorizado el operador para brindar un mejor servicio a nuestros usuarios; para que esos cambios se adopten por completo, debeeliminar el antiguo operador yinstalar el nuevo . |
Mis eventos de Kubernetes dejaron de informarse inesperadamente a Data Infrastructure Insights. |
Recuperar el nombre del pod del exportador de eventos: `kubectl -n netapp-monitoring get pods |
grep event-exporter |
awk '{print $1}' |
sed 's/event-exporter./event-exporter/'` |
Veo que los pods implementados por el operador de monitoreo de Kubernetes fallan debido a recursos insuficientes. |
Consulte el operador de monitoreo de Kubernetes"opciones de configuración" para aumentar los límites de CPU y/o memoria según sea necesario. |
Una imagen faltante o una configuración no válida provocó que los pods netapp-ci-kube-state-metrics no pudieran iniciarse o no estuvieran listos. Ahora el StatefulSet está bloqueado y los cambios de configuración no se aplican a los pods netapp-ci-kube-state-metrics. |
El StatefulSet está en un"roto" estado. Después de solucionar cualquier problema de configuración, rebote los pods netapp-ci-kube-state-metrics. |
Los pods netapp-ci-kube-state-metrics no se inician después de ejecutar una actualización del operador de Kubernetes y arrojan ErrImagePull (error al extraer la imagen). |
Intente restablecer los pods manualmente. |
Se están observando mensajes del tipo "Evento descartado por ser más antiguo que maxEventAgeSeconds" para mi clúster de Kubernetes en Análisis de registros. |
Modifique el operador agentconfiguration y aumente event-exporter-maxEventAgeSeconds (es decir, a 60 s), event-exporter-kubeQPS (es decir, a 100) y event-exporter-kubeBurst (es decir, a 500). Para obtener más detalles sobre estas opciones de configuración, consulte la"opciones de configuración" página. |
Telegraf advierte o se bloquea debido a que no hay suficiente memoria bloqueable. |
Intente aumentar el límite de memoria bloqueable para Telegraf en el nodo/sistema operativo subyacente. Si aumentar el límite no es una opción, modifique la configuración del agente NKMO y establezca unprotected en true. Esto le indicará a Telegraf que no intente reservar páginas de memoria bloqueadas. Si bien esto puede representar un riesgo de seguridad, ya que los secretos descifrados pueden intercambiarse en el disco, permite la ejecución en entornos donde no es posible reservar memoria bloqueada. Para obtener más detalles sobre las opciones de configuración unprotected, consulte la"opciones de configuración" página. |
Veo mensajes de advertencia de Telegraf similares al siguiente: W! [inputs.diskio] No se puede obtener el nombre del disco para "vdc": error al leer /dev/vdc: no existe el archivo o directorio |
Para el Kubernetes Monitoring Operator, estos mensajes de advertencia son benignos y puedes ignorarlos sin problema. O bien, edita la sección telegraf en AgentConfiguration y pon runDsPrivileged en true. Para más detalles, consulta el "opciones de configuración del operador". |
Mi pod de fluent-bit está fallando con los siguientes errores: [2024/10/16 14:16:23] [error] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:360 errno=24] Demasiados archivos abiertos [2024/10/16 14:16:23] [error] No se pudo inicializar la entrada tail.0 [2024/10/16 14:16:23] [error] [engine] Falló la inicialización de la entrada |
Intente cambiar la configuración de fsnotify en su clúster: sudo sysctl fs.inotify.max_user_instances (take note of setting) sudo sysctl fs.inotify.max_user_instances=<something larger than current setting> sudo sysctl fs.inotify.max_user_watches (take note of setting) sudo sysctl fs.inotify.max_user_watches=<something larger than current setting> Reinicie Fluent-bit. Nota: para que estas configuraciones sean persistentes después de reiniciar el nodo, debe colocar las siguientes líneas en /etc/sysctl.conf fs.inotify.max_user_instances=<something larger than current setting> fs.inotify.max_user_watches=<something larger than current setting> |
Los pods DS de Telegraf informan errores relacionados con el complemento de entrada de Kubernetes que no puede realizar solicitudes HTTP debido a la imposibilidad de validar el certificado TLS. Por ejemplo: E! [inputs.kubernetes] Error en el complemento: error al realizar la solicitud HTTP a"https://<kubelet_IP>:10250/stats/summary": Conseguir"https://<kubelet_IP>:10250/stats/summary": tls: no se pudo verificar el certificado: x509: no se puede validar el certificado para <kubelet_IP> porque no contiene ninguna SAN IP |
Esto ocurrirá si el kubelet usa certificados autofirmados y/o el certificado especificado no incluye <kubelet_IP> en la lista Nombre alternativo del sujeto del certificado. Para solucionar esto, el usuario puede modificar el"configuración del agente" , y establezca telegraf:insecureK8sSkipVerify en true. Esto configurará el complemento de entrada de telegraf para omitir la verificación. Alternativamente, el usuario puede configurar el kubelet para"servidorTLSBootstrap" , lo que activará una solicitud de certificado desde la API 'certificates.k8s.io'. |
Estoy recibiendo el siguiente error en los pods de Fluent-bit y el pod no puede arrancar: 026/01/12 20:20:32] [error] [sqldb] error=unable to open database file [2026/01/12 20:20:32] [error] [input:tail:tail.0] db: could not create 'in_tail_files' table [2026/01/12 20:20:32] [error] [input:tail:tail.0] no se pudo abrir/crear la base de datos [2026/01/12 20:20:32] [error] falló la inicialización de la entrada tail.0 [2026/01/12 20:20:32] [error] [engine] falló la inicialización de la entrada |
Asegúrate de que el directorio host en el que reside el archivo DB tiene los permisos de lectura/escritura adecuados. Más específicamente, el directorio host debe conceder permisos de lectura/escritura a los usuarios que no sean root. La ubicación predeterminada del archivo DB es /var/log/ a menos que se anule mediante la opción fluent-bit-dbFile agentconfiguration. Si SELinux está activado, intenta establecer la opción fluent-bit-seLinuxOptionsType agentconfiguration en 'spc_t' |
Me aparecen mensajes de error de Telegraf similares a los siguientes, aunque Telegraf sí se inicia y funciona: E! [inputs.kubernetes] Error en el complemento: https://<IP>>:<port>>/pods devolvió el estado HTTP 403 Forbidden |
Estos mensajes pueden aparecer si estás utilizando versiones de Kubernetes anteriores a la 1.33. El recurso RBAC "nodes/pods" que utiliza telegraf no existe en estas versiones. Consulta la sección "For Kubernetes versions < 1.33" del archivo operator-additional-permissions.yaml para conocer los recursos RBAC necesarios en versiones anteriores. |
Información adicional se puede encontrar en el"Soporte" página o en el"Matriz de soporte del recopilador de datos" .