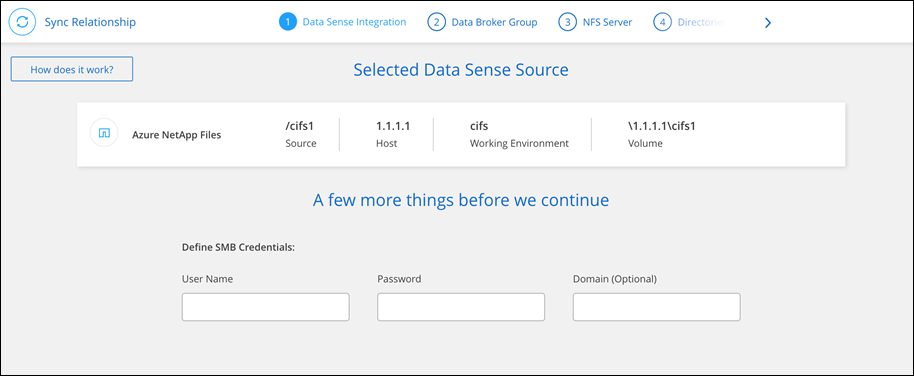
Crear relaciones de sincronización en NetApp Copy and Sync
 Sugerir cambios
Sugerir cambios
Cuando se crea una relación de sincronización, NetApp Copy and Sync copia archivos del origen al destino. Después de la copia inicial, Copiar y sincronizar sincroniza cualquier dato modificado cada 24 horas.
Antes de poder crear algunos tipos de relaciones de sincronización, primero deberá crear un sistema en la NetApp Console.
Crear relaciones de sincronización para tipos específicos de sistemas
Si desea crear relaciones de sincronización para cualquiera de los siguientes, primero debe crear o descubrir el sistema:
-
Amazon FSx para ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP
-
Clústeres ONTAP locales
-
Crear o descubrir el sistema.
-
Seleccione Página de sistemas.
-
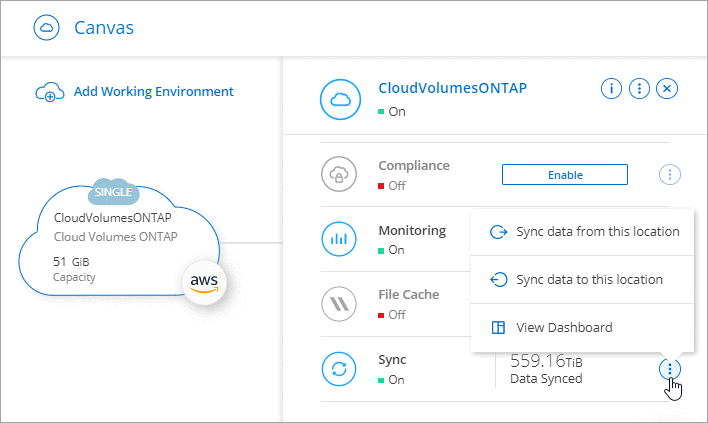
Seleccione un sistema que coincida con cualquiera de los tipos enumerados anteriormente.
-
Seleccione el menú de acción junto a Sincronizar.
-
Seleccione Sincronizar datos desde esta ubicación o Sincronizar datos con esta ubicación y siga las instrucciones para configurar la relación de sincronización.
Crear otros tipos de relaciones de sincronización
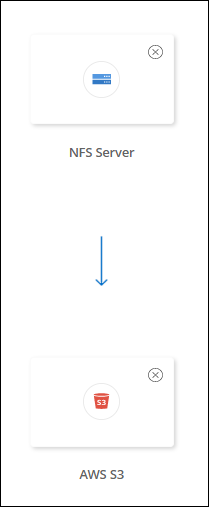
Utilice estos pasos para sincronizar datos hacia o desde un tipo de almacenamiento compatible que no sea Amazon FSx para ONTAP, Azure NetApp Files, Cloud Volumes ONTAP o clústeres de ONTAP locales. Los pasos a continuación proporcionan un ejemplo que muestra cómo configurar una relación de sincronización desde un servidor NFS a un depósito S3.
-
En la NetApp Console, seleccione Sincronizar.
-
En la página Definir relación de sincronización, elija un origen y un destino.
Los siguientes pasos proporcionan un ejemplo de cómo crear una relación de sincronización desde un servidor NFS a un depósito S3.
-
En la página Servidor NFS, ingrese la dirección IP o el nombre de dominio completo del servidor NFS que desea sincronizar con AWS.
-
En la página Grupo de agente de datos, siga las instrucciones para crear una máquina virtual de agente de datos en AWS, Azure o Google Cloud Platform, o para instalar el software de agente de datos en un host Linux existente.
Para más detalles, consulte las siguientes páginas:
-
Después de instalar el agente de datos, seleccione Continuar.
-
En la página Directorios, seleccione un directorio o subdirectorio de nivel superior.
Si Copiar y sincronizar no puede recuperar las exportaciones, seleccione Agregar exportación manualmente e ingrese el nombre de una exportación NFS.

Si desea sincronizar más de un directorio en el servidor NFS, deberá crear relaciones de sincronización adicionales una vez que haya terminado. -
En la página AWS S3 Bucket, seleccione un bucket:
-
Desplácese hacia abajo para seleccionar una carpeta existente dentro del depósito o para seleccionar una nueva carpeta que cree dentro del depósito.
-
Seleccione Agregar a la lista para seleccionar un depósito S3 que no esté asociado con su cuenta de AWS. "Se deben aplicar permisos específicos al bucket S3" .
-
-
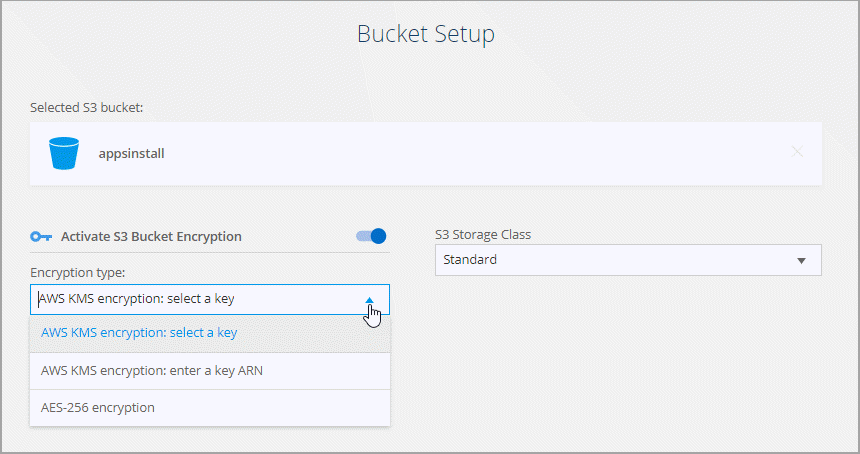
En la página Configuración del depósito, configure el depósito:
-
Elija si desea habilitar el cifrado del bucket S3 y luego seleccione una clave AWS KMS, ingrese el ARN de una clave KMS o seleccione el cifrado AES-256.
-
Seleccione una clase de almacenamiento S3. "Ver las clases de almacenamiento admitidas" .
-
-
En la página Configuración, defina cómo se sincronizan y mantienen los archivos y carpetas de origen en la ubicación de destino:
- Cronograma
-
Elija una programación recurrente para sincronizaciones futuras o desactive la programación de sincronización. Puede programar una relación para sincronizar datos con una frecuencia de hasta 1 minuto.
- Tiempo de espera de sincronización
-
Define si Copiar y sincronizar debe cancelar una sincronización de datos si la sincronización no se ha completado en la cantidad especificada de minutos, horas o días.
- Notificaciones
-
Le permite elegir si desea recibir notificaciones de copia y sincronización en el Centro de notificaciones de la consola de NetApp . Puede habilitar notificaciones para sincronizaciones de datos exitosas, fallidas y canceladas.
- Reintentos
-
Define la cantidad de veces que Copiar y sincronizar debe volver a intentar sincronizar un archivo antes de omitirlo.
- Sincronización continua
-
Después de la sincronización de datos inicial, Copy and Sync escucha los cambios en el depósito S3 de origen o en el depósito de Google Cloud Storage y sincroniza continuamente cualquier cambio con el destino a medida que se produce. No es necesario volver a escanear la fuente a intervalos programados.
Esta configuración solo está disponible cuando se crea una relación de sincronización y cuando se sincronizan datos desde un bucket S3 o Google Cloud Storage con Azure Blob Storage, CIFS, Google Cloud Storage, IBM Cloud Object Storage, NFS, S3 y StorageGRID o desde Azure Blob Storage con Azure Blob Storage, CIFS, Google Cloud Storage, IBM Cloud Object Storage, NFS y StorageGRID.
Si habilita esta configuración, afectará otras funciones de la siguiente manera:
-
La programación de sincronización está deshabilitada.
-
Las siguientes configuraciones vuelven a sus valores predeterminados: Tiempo de espera de sincronización, Archivos modificados recientemente y Fecha de modificación.
-
Si S3 es la fuente, el filtro por tamaño estará activo solo en eventos de copia (no en eventos de eliminación).
-
Una vez creada la relación, solo puedes acelerarla o eliminarla. No puedes cancelar sincronizaciones, modificar configuraciones ni ver informes.
Es posible crear una relación de sincronización continua con un depósito externo. Para ello siga estos pasos:
-
Vaya a la consola de Google Cloud para el proyecto del depósito externo.
-
Vaya a Almacenamiento en la nube > Configuración > Cuenta de servicio de almacenamiento en la nube.
-
Actualice el archivo local.json:
{ "protocols": { "gcp": { "storage-account-email": <storage account email> } } } -
Reiniciar el agente de datos:
-
sudo pm2 detener todo
-
sudo pm2 start all
-
-
Cree una relación de sincronización continua con el depósito externo relevante.
Un agente de datos utilizado para crear una relación de sincronización continua con un depósito externo no podrá crear otra relación de sincronización continua con un depósito en su proyecto.
-
-
- Comparar por
-
Elija si Copiar y sincronizar debe comparar ciertos atributos al determinar si un archivo o directorio ha cambiado y debe sincronizarse nuevamente.
Incluso si desmarca estos atributos, Copiar y sincronizar aún compara el origen con el destino verificando las rutas, los tamaños de archivo y los nombres de archivo. Si hay algún cambio, sincroniza esos archivos y directorios.
Puede elegir habilitar o deshabilitar Copiar y sincronizar comparando los siguientes atributos:
-
mtime: La hora de la última modificación de un archivo. Este atributo no es válido para directorios.
-
uid, gid y mode: Indicadores de permisos para Linux.
-
- Copiar para objetos
-
Habilite esta opción para copiar metadatos y etiquetas de almacenamiento de objetos. Si un usuario cambia los metadatos en la fuente, Copiar y sincronizar copia este objeto en la próxima sincronización, pero si un usuario cambia las etiquetas en la fuente (y no los datos en sí), Copiar y sincronizar no copia el objeto en la próxima sincronización.
No puedes editar esta opción después de crear la relación.
La copia de etiquetas se admite con relaciones de sincronización que incluyen Azure Blob o un punto final compatible con S3 (S3, StorageGRID o IBM Cloud Object Storage) como destino.
La copia de metadatos es compatible con relaciones "de nube a nube" entre cualquiera de los siguientes puntos finales:
-
AWS S3
-
Blob de Azure
-
Almacenamiento en la nube de Google
-
Almacenamiento de objetos en la nube de IBM
-
StorageGRID
-
- Archivos modificados recientemente
-
Elija excluir archivos que se modificaron recientemente antes de la sincronización programada.
- Eliminar archivos en la fuente
-
Elija eliminar archivos de la ubicación de origen después de que Copiar y sincronizar copie los archivos a la ubicación de destino. Esta opción incluye el riesgo de pérdida de datos porque los archivos de origen se eliminan después de copiarse.
Si habilita esta opción, también deberá cambiar un parámetro en el archivo local.json en el agente de datos. Abra el archivo y actualícelo de la siguiente manera:
{ "workers":{ "transferrer":{ "delete-on-source": true } } }Después de actualizar el archivo local.json, debes reiniciar:
pm2 restart all. - Eliminar archivos en el destino
-
Elija eliminar archivos de la ubicación de destino, si se eliminaron de la fuente. El valor predeterminado es nunca eliminar archivos de la ubicación de destino.
- Tipos de archivos
-
Define los tipos de archivos que se incluirán en cada sincronización: archivos, directorios, enlaces simbólicos y enlaces duros.
Los enlaces duros solo están disponibles para relaciones NFS a NFS no seguras. Los usuarios estarán limitados a un proceso de escáner y a una concurrencia de escáneres, y los escaneos deberán ejecutarse desde un directorio raíz. - Excluir extensiones de archivo
-
Especifique la expresión regular o las extensiones de archivo que desea excluir de la sincronización escribiendo la extensión del archivo y presionando Enter. Por ejemplo, escriba log o .log para excluir archivos *.log. No se requiere un separador para múltiples extensiones. El siguiente vídeo ofrece una breve demostración:
Excluir extensiones de archivo para una relación de sincronización
Las expresiones regulares o regex se diferencian de los comodines o expresiones glob. Esta función sólo funciona con expresiones regulares. - Excluir directorios
-
Especifique un máximo de 15 expresiones regulares o directorios para excluir de la sincronización escribiendo su nombre o la ruta completa del directorio y presionando Enter. Los directorios .copy-offload, .snapshot y ~snapshot están excluidos de forma predeterminada.
Las expresiones regulares o regex se diferencian de los comodines o expresiones glob. Esta función sólo funciona con expresiones regulares. - Tamaño del archivo
-
Elija sincronizar todos los archivos independientemente de su tamaño o solo los archivos que estén en un rango de tamaño específico.
- Fecha de modificación
-
Elija todos los archivos independientemente de su última fecha de modificación, archivos modificados después de una fecha específica, antes de una fecha específica o entre un rango de tiempo.
- Fecha de creación
-
Cuando un servidor SMB es la fuente, esta configuración le permite sincronizar archivos que se crearon después de una fecha específica, antes de una fecha específica o entre un rango de tiempo específico.
- ACL - Lista de control de acceso
-
Copie solo ACL, solo archivos o ACL y archivos desde un servidor SMB habilitando una configuración cuando crea una relación o después de crear una relación.
-
En la página Etiquetas/Metadatos, elija si desea guardar un par clave-valor como etiqueta en todos los archivos transferidos al bucket S3 o asignar un par clave-valor de metadatos en todos los archivos.
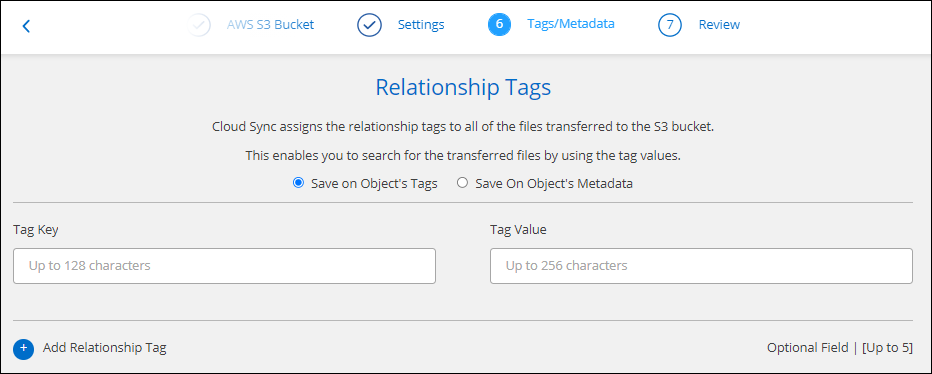

Esta misma función está disponible al sincronizar datos con StorageGRID e IBM Cloud Object Storage. Para Azure y Google Cloud Storage, solo está disponible la opción de metadatos. -
Revise los detalles de la relación de sincronización y luego seleccione Crear relación.
Resultado
Copiar y sincronizar comienza a sincronizar datos entre el origen y el destino. Están disponibles estadísticas de sincronización sobre cuánto tiempo tomó la sincronización, si se detuvo y cuántos archivos se copiaron, escanearon o eliminaron. Luego podrás administrar tu "relaciones de sincronización" , "Gestione sus corredores de datos" , o "Crea informes para optimizar tu rendimiento y configuración" .
Crear relaciones de sincronización desde NetApp Data Classification
Copy and Sync está integrado con NetApp Data Classification. Desde NetApp Data Classification, puede seleccionar los archivos de origen que desea sincronizar con una ubicación de destino mediante Copiar y sincronizar.
Después de iniciar una sincronización de datos desde NetApp Data Classification, toda la información de origen está contenida en un solo paso y solo requiere que ingrese algunos detalles clave. A continuación, elige la ubicación de destino para la nueva relación de sincronización.