

Learn about NetApp Data Classification
 Suggest changes
Suggest changes
NetApp Data Classification is a data governance service for the NetApp Console that scans your corporate on-premises and cloud data sources to map and classify data, and to identify private information. This can help reduce your security and compliance risk, decrease storage costs, and assist with your data migration projects.

|
Beginning with version 1.31, Data Classification is available as a core capability within the NetApp Console. There's no additional charge. No Classification license or subscription is required. If you've been using legacy version 1.30 or earlier, that version is available until your subscription expires. |
NetApp Console
Data Classification is accessible through the NetApp Console.
The NetApp Console provides centralized management of NetApp storage and data services across on-premises and cloud environments at enterprise grade. The Console is required to access and use NetApp data services. As a management interface, it enables you to manage many storage resources from one interface. Console administrators can control access to storage and services for all systems within the enterprise.
You don't need a license or subscription to start using NetApp Console and you only incur charges when you need to deploy Console agents in your cloud to ensure connectivity to your storage systems or NetApp data services. However, some NetApp data services accessible from the Console are licensed or subscription-based.
Learn more about the NetApp Console.
Features
Data Classification uses artificial intelligence (AI), natural language processing (NLP), and machine learning (ML) to understand the content that it scans in order to extract entities and categorize the content accordingly. This allows Data Classification to provide the following areas of functionality.
Data Classification provides several tools that can help with your compliance efforts. You can use Data Classification to:
-
Identify Personal Identifiable Information (PII).
-
Identify a wide scope of sensitive personal information as required by GDPR, CCPA, PCI, and HIPAA privacy regulations.
-
Respond to Data Subject Access Requests (DSAR) based on name or email address.
Data Classification can identify data that is potentially at risk for being accessed for criminal purposes. You can use Data Classification to:
-
Identify all the files and directories (shares and folders) with open permissions that are exposed to your entire organization or to the public.
-
Identify sensitive data that resides outside of the initial, dedicated location.
-
Comply with data retention policies.
-
Use Policies to automatically detect new security issues so security staff can take action immediately.
Data Classification provides tools that can help with your storage total cost of ownership (TCO). You can use Data Classification to:
-
Increase storage efficiency by identifying duplicate or non-business-related data.
-
Save storage costs by identifying inactive data that you can tier to less expensive object storage. Learn more about tiering from Cloud Volumes ONTAP systems. Learn more about tiering from on-premises ONTAP systems.
Supported systems and data sources
Data Classification can scan and analyze structured and unstructured data from the following types of systems and data sources:
Systems
-
Amazon FSx for NetApp ONTAP management
-
Azure NetApp Files
-
Cloud Volumes ONTAP (deployed in AWS, Azure, or GCP)
-
Google Cloud NetApp Volumes
-
On-premises ONTAP clusters
-
StorageGRID
Data sources
-
NetApp file shares
-
Databases:
-
Amazon Relational Database Service (Amazon RDS)
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SAP HANA
-
SQL Server (MSSQL)
-
Data Classification supports NFS versions 3.x, 4.0, and 4.1, and CIFS versions 1.x, 2.0, 2.1, and 3.0.
Cost
Data Classification is free to use. No Classification license or paid subscription is required.
Infrastructure costs
-
Installing Data Classification in the cloud requires deploying a cloud instance, which results in charges from the cloud provider where it is deployed. See the type of instance that is deployed for each cloud provider. There is no cost if you install Data Classification on an on-premises system.
-
Data Classification requires that you have deployed a Console agent. In many cases you already have a Console agent because of other storage and services you are using in the Console. The Console agent instance results in charges from the cloud provider where it's deployed. See the type of instance that is deployed for each cloud provider. There is no cost if you install the Console agent on an on-premises system.
Data transfer costs
Data transfer costs depend on your setup. If the Data Classification instance and data source are in the same Availability Zone and region, then there are no data transfer costs. But if the data source, such as a Cloud Volumes ONTAP system, is in a different Availability Zone or region, then you'll be charged by your cloud provider for data transfer costs. See these links for more details:
The Data Classification instance
When you deploy Data Classification in the cloud, the Console deploys the instance in the same subnet as the Console agent. Learn more about the Console agent.
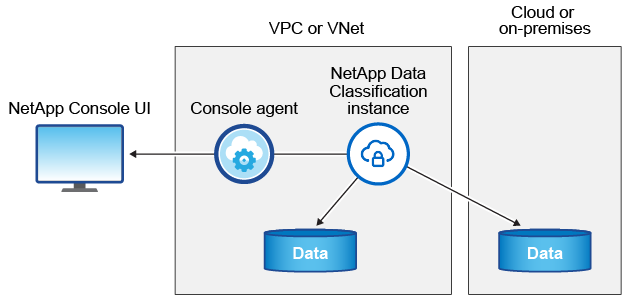
Note the following about the default instance:
-
In AWS, Data Classification runs on an m6i.4xlarge instance with a 500 GiB GP2 disk. The operating system image is Amazon Linux 2.
-
In Azure, Data Classification runs on a Standard_D16s_v3 VM with a 500 GiB disk. The operating system image is Ubuntu 22.04.
-
In GCP, Data Classification runs on an n2-standard-16 VM with a 500 GiB Standard persistent disk. The operating system image is Ubuntu 22.04.
-
In regions where the default instance isn't available, Data Classification runs on an alternate instance. See the alternate instance types.
-
The instance is named CloudCompliance with a generated hash (UUID) concatenated to it. For example: CloudCompliance-16bb6564-38ad-4080-9a92-36f5fd2f71c7
-
Only one Data Classification instance is deployed per Console Agent.
You can also deploy Data Classification on a Linux host on your premises or on a host in your preferred cloud provider. The software functions exactly the same way regardless of which installation method you choose. Upgrades of Data Classification software are automated as long as the instance has internet access.

|
The instance should remain running at all times because Data Classification continuously scans the data. |
Deploy on different instance types
Review the following specifications for instance types:
| System size | Specs | Limitations |
|---|---|---|
Extra Large |
32 CPUs, 128 GB RAM, 1 TiB SSD |
Can scan up to 500 million files. |
Large (default) |
16 CPUs, 64 GB RAM, 500 GiB SSD |
Can scan up to 250 million files. |
How Data Classification scanning works
At a high-level, Data Classification scanning works like this:
-
You deploy an instance of Data Classification in the Console.
-
You enable scans on one or more data sources.
-
Data Classification scans data using an AI learning process.
-
You use the provided dashboards and reporting tools to help in your compliance and governance efforts.
After you enable Data Classification and select the repositories that you want to scan (these are the volumes, database schemas, or other user data), it immediately starts scanning the data to identify personal and sensitive data. You should focus on scanning live production data in most cases instead of backups, mirrors, or DR sites. Then Data Classification maps your organizational data, categorizes each file, and identifies and extracts entities and predefined patterns in the data. The result of the scan is an index of personal information, sensitive personal information, data categories, and file types.
Data Classification connects to the data like any other client by mounting NFS and CIFS volumes. NFS volumes are automatically accessed as read-only, while you need to provide Active Directory credentials to scan CIFS volumes.
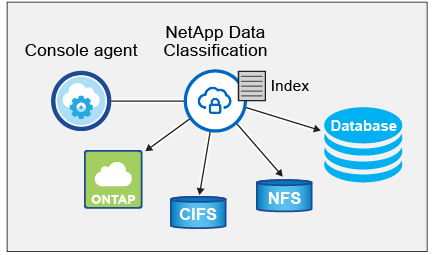
After the initial scan, Data Classification continuously scans your data in a round-robin fashion to detect incremental changes. This is why it's important to keep the instance running.
You can enable and disable scans at the volume level or the database schema level.

|
Data Classification does not impose a limit on the amount of data it can scan. Each Console agent supports scanning and displaying 500 TiB of data. To scan more than 500 TiB of data, install another Console agent then deploy another Data Classification instance. The Console UI displays data from a single connector. For tips on viewing data from multiple Console agents, see Work with multiple Console agents. |
Mapping and full scans
You can conduct two types of scans in Data Classification:
-
Map-only scans provide only a high-level overview of your data and are performed on selected data sources. Map-only scans take less time than full scans because they don't access files to see the data inside. You might want to do this initially to identify areas of research and then perform a full scan on those areas.
-
Full scans provide deep-level scanning of your data. A full scan includes a map-only scan and a classification of data inside the files.
For a breakdown of the differences between map-only and full scans, see What's the difference between Mapping and Classification scans?.
Information that Data Classification categorizes
Data Classification collects, indexes, and assigns categories to the following data:
-
Standard metadata about files: the file type, its size, creation and modification dates, and so on.
-
Personal data: Personally identifiable information (PII) such as email addresses, identification numbers, or credit card numbers, which Data Classification identifies using specific words, strings, and patterns in the files. Learn more about personal data.
-
Sensitive personal data: Special types of sensitive personal information (SPII), such as health data, ethnic origin, or political opinions, as defined by General Data Protection Regulation (GDPR) and other privacy regulations. Learn more about sensitive personal data.
-
Categories: Data Classification takes the data that it scanned and divides it into different types of categories. Categories are topics based on AI analysis of the content and metadata of each file. Learn more about categories.
-
Name entity recognition: Data Classification uses AI to extract people's natural names from documents. Learn about responding to Data Subject Access Requests.
Networking overview
Data Classification deploys a single server, or cluster, wherever you choose: in the cloud or on premises. The servers connect via standard protocols to the data sources and index the findings in an Elasticsearch cluster, which is also deployed on the same servers. This enables support for multi-cloud, cross-cloud, private cloud, and on-premises environments.
The Console deploys the Data Classification instance with a security group that enables inbound HTTP connections from the Console agent.
When you use the Console in SaaS mode, the connection to the Console is served over HTTPS, and the private data sent between your browser and the Data Classification instance are secured with end-to-end encryption using TLS 1.2, which means NetApp and third parties can't read it.
Outbound rules are completely open. Internet access is needed to install and upgrade the Data Classification software and to send usage metrics.
If you have strict networking requirements, learn about the endpoints that Data Classification contacts.