

Obtenga más información sobre la NetApp Data Classification
 Sugerir cambios
Sugerir cambios
NetApp Data Classification es un servicio de gobernanza de datos para la NetApp Console que escanea sus fuentes de datos locales y en la nube corporativas para mapear y clasificar datos e identificar información privada. Esto puede ayudar a reducir el riesgo de seguridad y cumplimiento, disminuir los costos de almacenamiento y ayudarlo con sus proyectos de migración de datos.

|
A partir de la versión 1.31, la clasificación de datos está disponible como una capacidad principal dentro de la NetApp Console. No hay ningún cargo adicional No se requiere licencia de clasificación ni suscripción. + Si ha estado utilizando la versión heredada 1.30 o anterior, esa versión estará disponible hasta que expire su suscripción. |
NetApp Console
Se puede acceder a la clasificación de datos a través de la NetApp Console.
La NetApp Console proporciona una gestión centralizada de los servicios de datos y almacenamiento de NetApp en entornos locales y en la nube a nivel empresarial. La consola es necesaria para acceder y utilizar los servicios de datos de NetApp . Como interfaz de administración, le permite administrar muchos recursos de almacenamiento desde una sola interfaz. Los administradores de la consola pueden controlar el acceso al almacenamiento y los servicios para todos los sistemas dentro de la empresa.
No necesita una licencia o suscripción para comenzar a usar NetApp Console y solo incurre en cargos cuando necesita implementar agentes de Console en su nube para garantizar la conectividad con sus sistemas de almacenamiento o servicios de datos de NetApp . Sin embargo, algunos servicios de datos de NetApp accesibles desde la consola requieren licencia o suscripción.
Obtenga más información sobre el"NetApp Console" .
Funciones
La clasificación de datos utiliza inteligencia artificial (IA), procesamiento del lenguaje natural (PLN) y aprendizaje automático (ML) para comprender el contenido que escanea con el fin de extraer entidades y categorizar el contenido en consecuencia. Esto permite que la clasificación de datos proporcione las siguientes áreas de funcionalidad.
La clasificación de datos proporciona varias herramientas que pueden ayudarle con sus esfuerzos de cumplimiento. Puede utilizar la clasificación de datos para:
-
Identificar información de identificación personal (PII).
-
Identifique un amplio alcance de información personal confidencial según lo exigen las regulaciones de privacidad GDPR, CCPA, PCI y HIPAA.
-
Responder a las solicitudes de acceso del titular de los datos (DSAR) basadas en el nombre o la dirección de correo electrónico.
La clasificación de datos puede identificar datos que potencialmente corren el riesgo de ser accedidos con fines delictivos. Puede utilizar la clasificación de datos para:
-
Identifique todos los archivos y directorios (recursos compartidos y carpetas) con permisos abiertos que estén expuestos a toda su organización o al público.
-
Identifique datos confidenciales que residen fuera de la ubicación inicial dedicada.
-
Cumplir con las políticas de retención de datos.
-
Utilice Políticas para detectar automáticamente nuevos problemas de seguridad para que el personal de seguridad pueda tomar medidas de inmediato.
La clasificación de datos proporciona herramientas que pueden ayudarle con el costo total de propiedad (TCO) de su almacenamiento. Puede utilizar la clasificación de datos para:
-
Aumente la eficiencia del almacenamiento identificando datos duplicados o no relacionados con el negocio.
-
Ahorre costos de almacenamiento identificando datos inactivos que puede clasificar en un almacenamiento de objetos menos costoso. "Obtenga más información sobre la organización en niveles de los sistemas Cloud Volumes ONTAP" . "Obtenga más información sobre la organización en niveles de los sistemas ONTAP locales" .
Sistemas y fuentes de datos compatibles
La clasificación de datos puede escanear y analizar datos estructurados y no estructurados de los siguientes tipos de sistemas y fuentes de datos:
Sistemas
-
Amazon FSx for NetApp ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP (implementado en AWS, Azure o GCP)
-
Google Cloud NetApp Volumes
-
Clústeres ONTAP locales
-
StorageGRID
Fuentes de datos
-
Recursos compartidos de archivos de NetApp
-
Bases de datos:
-
Servicio de base de datos relacional de Amazon (Amazon RDS)
-
MongoDB
-
MySQL
-
Oráculo
-
PostgreSQL
-
SAP HANA
-
Servidor SQL (MSSQL)
-
La clasificación de datos admite las versiones NFS 3.x, 4.0 y 4.1, y las versiones CIFS 1.x, 2.0, 2.1 y 3.0.
Costo
La clasificación de datos es de uso gratuito. No se requiere licencia de clasificación ni suscripción paga.
Costos de infraestructura
-
La instalación de Data Classification en la nube requiere implementar una instancia en la nube, lo que genera cargos por parte del proveedor de la nube donde se implementa. Ver el tipo de instancia que se implementa para cada proveedor de nube . No hay ningún costo si instala Data Classification en un sistema local.
-
Para la clasificación de datos es necesario que haya implementado un agente de consola. En muchos casos, ya tienes un agente de consola debido a otro almacenamiento y servicios que estás usando en la consola. La instancia del agente de consola genera cargos del proveedor de la nube donde se implementa. Ver el "tipo de instancia que se implementa para cada proveedor de nube" . No hay ningún costo si instala el agente de consola en un sistema local.
Costos de transferencia de datos
Los costos de transferencia de datos dependen de su configuración. Si la instancia de clasificación de datos y la fuente de datos están en la misma zona de disponibilidad y región, no hay costos de transferencia de datos. Pero si la fuente de datos, como un sistema Cloud Volumes ONTAP , está en una zona de disponibilidad o región diferente, su proveedor de nube le cobrará los costos de transferencia de datos. Consulte estos enlaces para obtener más detalles:
La instancia de Clasificación de Datos
Cuando implementa la clasificación de datos en la nube, la consola implementa la instancia en la misma subred que el agente de la consola. "Obtenga más información sobre el agente de consola."
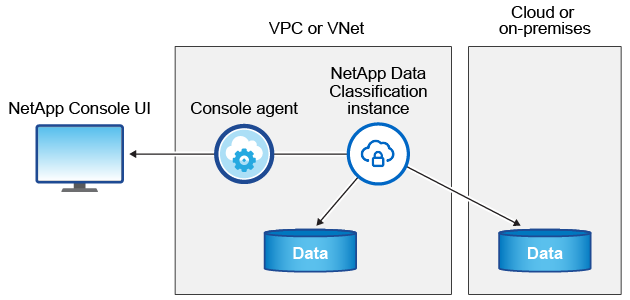
Tenga en cuenta lo siguiente sobre la instancia predeterminada:
-
En AWS, la clasificación de datos se ejecuta en un "instancia m6i.4xlarge" con un disco GP2 de 500 GiB. La imagen del sistema operativo es Amazon Linux 2.
-
En Azure, la clasificación de datos se ejecuta en un"Standard_D16s_v3 VM" con un disco de 500 GiB. La imagen del sistema operativo es Ubuntu 22.04.
-
En GCP, la clasificación de datos se ejecuta en un"Máquina virtual n2-standard-16" con un disco persistente estándar de 500 GiB. La imagen del sistema operativo es Ubuntu 22.04.
-
En las regiones donde la instancia predeterminada no está disponible, la clasificación de datos se ejecuta en una instancia alternativa. "Ver los tipos de instancias alternativos" .
-
La instancia se llama CloudCompliance con un hash generado (UUID) concatenado a ella. Por ejemplo: CloudCompliance-16bb6564-38ad-4080-9a92-36f5fd2f71c7
-
Solo se implementa una instancia de clasificación de datos por agente de consola.
También puede implementar la clasificación de datos en un host Linux en sus instalaciones o en un host en su proveedor de nube preferido. El software funciona exactamente de la misma manera independientemente del método de instalación que elija. Las actualizaciones del software de clasificación de datos se automatizan siempre que la instancia tenga acceso a Internet.

|
La instancia debe permanecer en ejecución en todo momento porque la clasificación de datos escanea continuamente los datos. |
Implementar en diferentes tipos de instancias
Revise las siguientes especificaciones para los tipos de instancias:
| Tamaño del sistema | Especificaciones | Limitaciones |
|---|---|---|
Extra grande |
32 CPU, 128 GB de RAM, 1 TiB SSD |
Puede escanear hasta 500 millones de archivos. |
Grande (predeterminado) |
16 CPU, 64 GB de RAM, SSD de 500 GiB |
Puede escanear hasta 250 millones de archivos. |
Cómo funciona el escaneo de clasificación de datos
A un alto nivel, el escaneo de clasificación de datos funciona así:
-
Implementa una instancia de Clasificación de datos en la consola.
-
Tú habilitas los análisis en una o varias fuentes de datos.
-
La clasificación de datos escanea datos utilizando un proceso de aprendizaje de IA.
-
Puede utilizar los paneles y las herramientas de generación de informes proporcionados para ayudarle en sus esfuerzos de cumplimiento y gobernanza.
Después de habilitar la Clasificación de datos y seleccionar los repositorios que desea escanear (estos son los volúmenes, esquemas de bases de datos u otros datos de usuario), inmediatamente comienza a escanear los datos para identificar datos personales y confidenciales. En la mayoría de los casos, debe centrarse en escanear datos de producción en vivo en lugar de copias de seguridad, espejos o sitios de recuperación ante desastres. Luego, la clasificación de datos mapea los datos de su organización, categoriza cada archivo e identifica y extrae entidades y patrones predefinidos en los datos. El resultado del escaneo es un índice de información personal, información personal confidencial, categorías de datos y tipos de archivos.
La clasificación de datos se conecta a los datos como cualquier otro cliente montando volúmenes NFS y CIFS. A los volúmenes NFS se accede automáticamente como de solo lectura, mientras que es necesario proporcionar credenciales de Active Directory para escanear volúmenes CIFS.
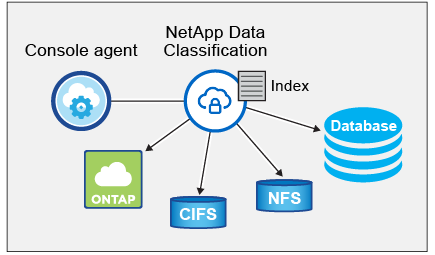
Después del escaneo inicial, la clasificación de datos escanea continuamente sus datos de manera rotatoria para detectar cambios incrementales. Por eso es importante mantener la instancia en ejecución.
Puede habilitar y deshabilitar escaneos a nivel de volumen o a nivel de esquema de base de datos.

|
La clasificación de datos no impone un límite en la cantidad de datos que puede escanear. Cada agente de consola admite el escaneo y la visualización de 500 TiB de datos. Para escanear más de 500 TiB de datos,"instalar otro agente de consola" entonces"Implementar otra instancia de clasificación de datos" . + La interfaz de usuario de la consola muestra datos de un solo conector. Para obtener sugerencias sobre cómo ver datos de varios agentes de la consola, consulte"Trabajar con múltiples agentes de consola" . |
Mapeo y exploraciones completas
Puede realizar dos tipos de escaneos en Clasificación de datos:
-
Los escaneos de sólo mapa proporcionan solo una visión a grandes rasgos de tus datos y se realizan en fuentes de datos seleccionadas. Los escaneos de sólo mapa tardan menos que los escaneos completos porque no acceden a los archivos para ver los datos que hay dentro. Quizá quieras hacer esto al principio para identificar áreas de investigación y luego realizar un escaneo completo en esas áreas.
-
Los escaneados completos proporcionan un escaneado en profundidad de tus datos. Un escaneado completo incluye un escaneado solo de mapas y una clasificación de los datos dentro de los archivos.
Para ver un desglose de las diferencias entre las exploraciones de sólo mapa y las completas, consulta "¿Cuál es la diferencia entre los escaneos de mapeo y clasificación?".
Información que la clasificación de datos categoriza
La clasificación de datos recopila, indexa y asigna categorías a los siguientes datos:
-
Metadatos estándar sobre los archivos: el tipo de archivo, su tamaño, fechas de creación y modificación, etc.
-
Datos personales: Información de identificación personal (PII), como direcciones de correo electrónico, números de identificación o números de tarjetas de crédito, que la clasificación de datos identifica mediante palabras, cadenas y patrones específicos en los archivos. "Obtenga más información sobre los datos personales" .
-
Datos personales sensibles: Tipos especiales de información personal sensible (IPS), como datos de salud, origen étnico u opiniones políticas, según lo define el Reglamento General de Protección de Datos (RGPD) y otras regulaciones de privacidad. "Obtenga más información sobre datos personales sensibles" .
-
Categorías: La clasificación de datos toma los datos que escanea y los divide en diferentes tipos de categorías. Las categorías son temas basados en el análisis de IA del contenido y los metadatos de cada archivo. "Obtenga más información sobre las categorías".
-
Reconocimiento de entidades de nombre: la clasificación de datos utiliza IA para extraer los nombres naturales de las personas de los documentos. "Obtenga información sobre cómo responder a las solicitudes de acceso de los interesados" .
Descripción general de la red
Data Classification implementa un solo servidor o clúster donde usted elija: en la nube o en las instalaciones. Los servidores se conectan a través de protocolos estándar a las fuentes de datos e indexan los resultados en un clúster Elasticsearch, que también está implementado en los mismos servidores. Esto permite compatibilidad con entornos multicloud, cross-cloud, cloud privado y locales.
La consola implementa la instancia de clasificación de datos con un grupo de seguridad que habilita conexiones HTTP entrantes desde el agente de la consola.
Cuando usa la consola en modo SaaS, la conexión a la consola se proporciona a través de HTTPS y los datos privados enviados entre su navegador y la instancia de clasificación de datos están protegidos con cifrado de extremo a extremo mediante TLS 1.2, lo que significa que NetApp y terceros no pueden leerlos.
Las reglas de salida están completamente abiertas. Se necesita acceso a Internet para instalar y actualizar el software de clasificación de datos y para enviar métricas de uso.
Si tiene requisitos de red estrictos,"Obtenga información sobre los puntos finales con los que se comunica la clasificación de datos" .