

Parte 3: Creación de una canalización de MLOps simplificada (CI/CT/CD)
 Sugerir cambios
Sugerir cambios
Este artículo proporciona una guía para crear una canalización de MLOps con servicios de AWS, centrándose en el reentrenamiento automatizado de modelos, la implementación y la optimización de costos.
Introducción
En este tutorial, aprenderá cómo aprovechar varios servicios de AWS para construir una canalización MLOps simple que abarque integración continua (CI), capacitación continua (CT) e implementación continua (CD). A diferencia de los pipelines DevOps tradicionales, MLOps requiere consideraciones adicionales para completar el ciclo operativo. Al seguir este tutorial, obtendrá conocimientos sobre cómo incorporar CT en el ciclo MLOps, lo que permitirá el entrenamiento continuo de sus modelos y una implementación perfecta para la inferencia. El tutorial lo guiará a través del proceso de utilización de los servicios de AWS para establecer esta canalización MLOps de extremo a extremo.
Manifiesto
| Funcionalidad | Nombre | Comentario |
|---|---|---|
Almacenamiento de datos |
AWS FSx ONTAP |
|
IDE de ciencia de datos |
AWS SageMaker |
Este tutorial se basa en el cuaderno Jupyter presentado en"Parte 2: Aprovechamiento de Amazon FSx for NetApp ONTAP (FSx ONTAP) como fuente de datos para el entrenamiento de modelos en SageMaker" . |
Función para activar la canalización MLOps |
Función AWS Lambda |
- |
Desencadenador de trabajo cron |
Puente de eventos de AWS |
- |
Marco de aprendizaje profundo |
PyTorch |
- |
SDK de Python de AWS |
boto3 |
- |
Lenguaje de programación |
Pitón |
v3.10 |
Requisito previo
-
Un sistema de archivos FSx ONTAP preconfigurado. Este tutorial utiliza datos almacenados en FSx ONTAP para el proceso de entrenamiento.
-
Una instancia de SageMaker Notebook que está configurada para compartir la misma VPC que el sistema de archivos FSx ONTAP mencionado anteriormente.
-
Antes de activar la función AWS Lambda, asegúrese de que la instancia de SageMaker Notebook esté en estado detenida.
-
El tipo de instancia ml.g4dn.xlarge es necesario para aprovechar la aceleración de la GPU necesaria para los cálculos de redes neuronales profundas.
Arquitectura
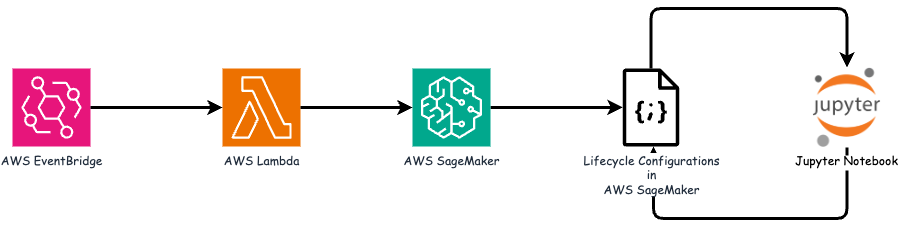
Esta canalización MLOps es una implementación práctica que utiliza un trabajo cron para activar una función sin servidor, que a su vez ejecuta un servicio de AWS registrado con una función de devolución de llamada de ciclo de vida. AWS EventBridge actúa como trabajo cron. Periódicamente invoca una función AWS Lambda responsable de volver a entrenar y reimplementar el modelo. Este proceso implica poner en marcha la instancia AWS SageMaker Notebook para realizar las tareas necesarias.
Configuración paso a paso
Configuraciones del ciclo de vida
Para configurar la función de devolución de llamada del ciclo de vida para la instancia de AWS SageMaker Notebook, deberá utilizar Configuraciones de ciclo de vida. Este servicio le permite definir las acciones necesarias que se deben realizar durante el inicio de la instancia del notebook. Específicamente, se puede implementar un script de shell dentro de las Configuraciones del ciclo de vida para apagar automáticamente la instancia del notebook una vez que se hayan completado los procesos de entrenamiento e implementación. Esta es una configuración obligatoria ya que el costo es una de las principales consideraciones en MLOps.
Es importante tener en cuenta que la configuración para las Configuraciones del ciclo de vida debe realizarse con anticipación. Por lo tanto, se recomienda priorizar la configuración de este aspecto antes de continuar con la configuración del resto del pipeline de MLOps.
-
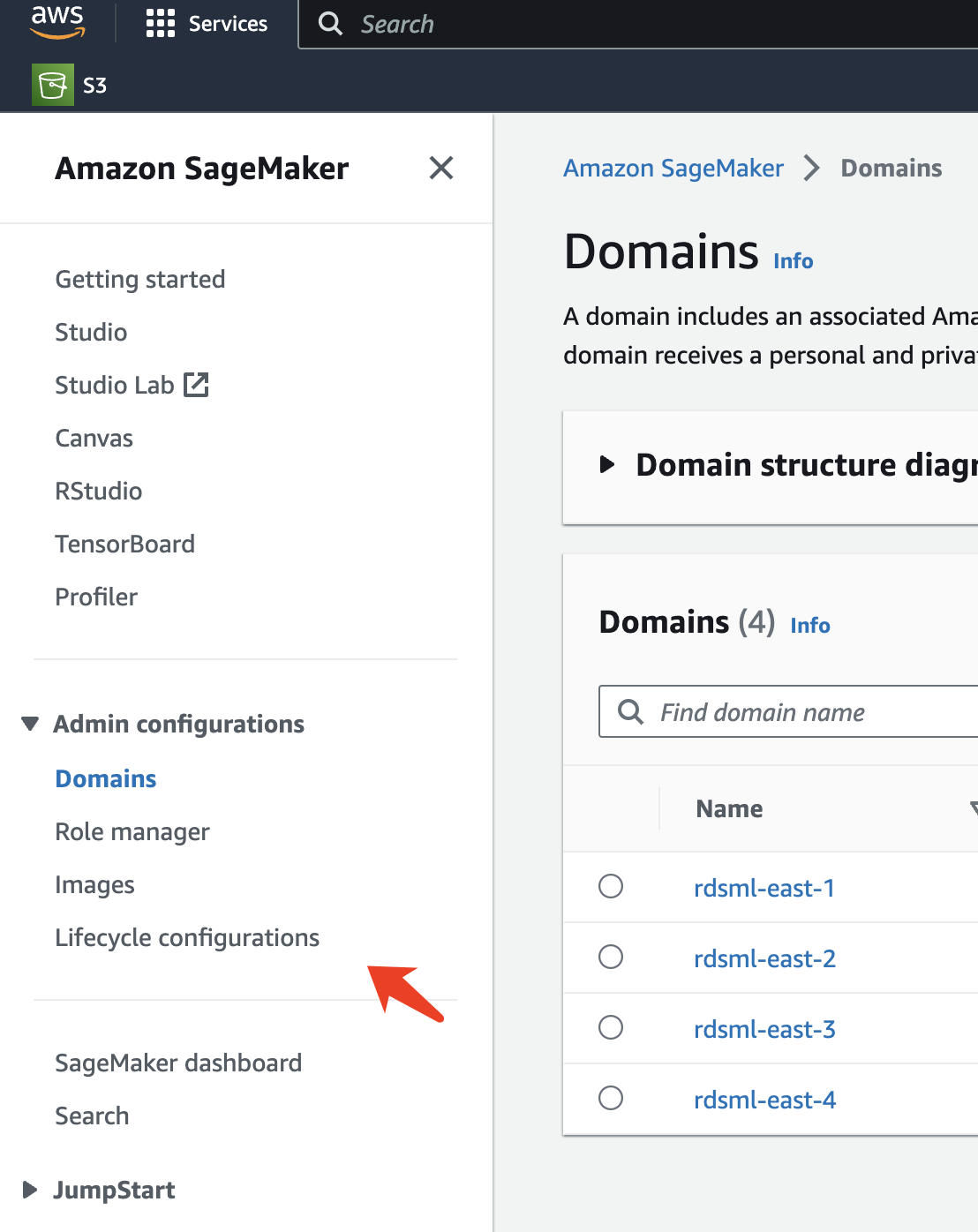
Para configurar un ciclo de vida, abra el panel Sagemaker y navegue a Configuraciones de ciclo de vida en la sección Configuraciones de administración.
-
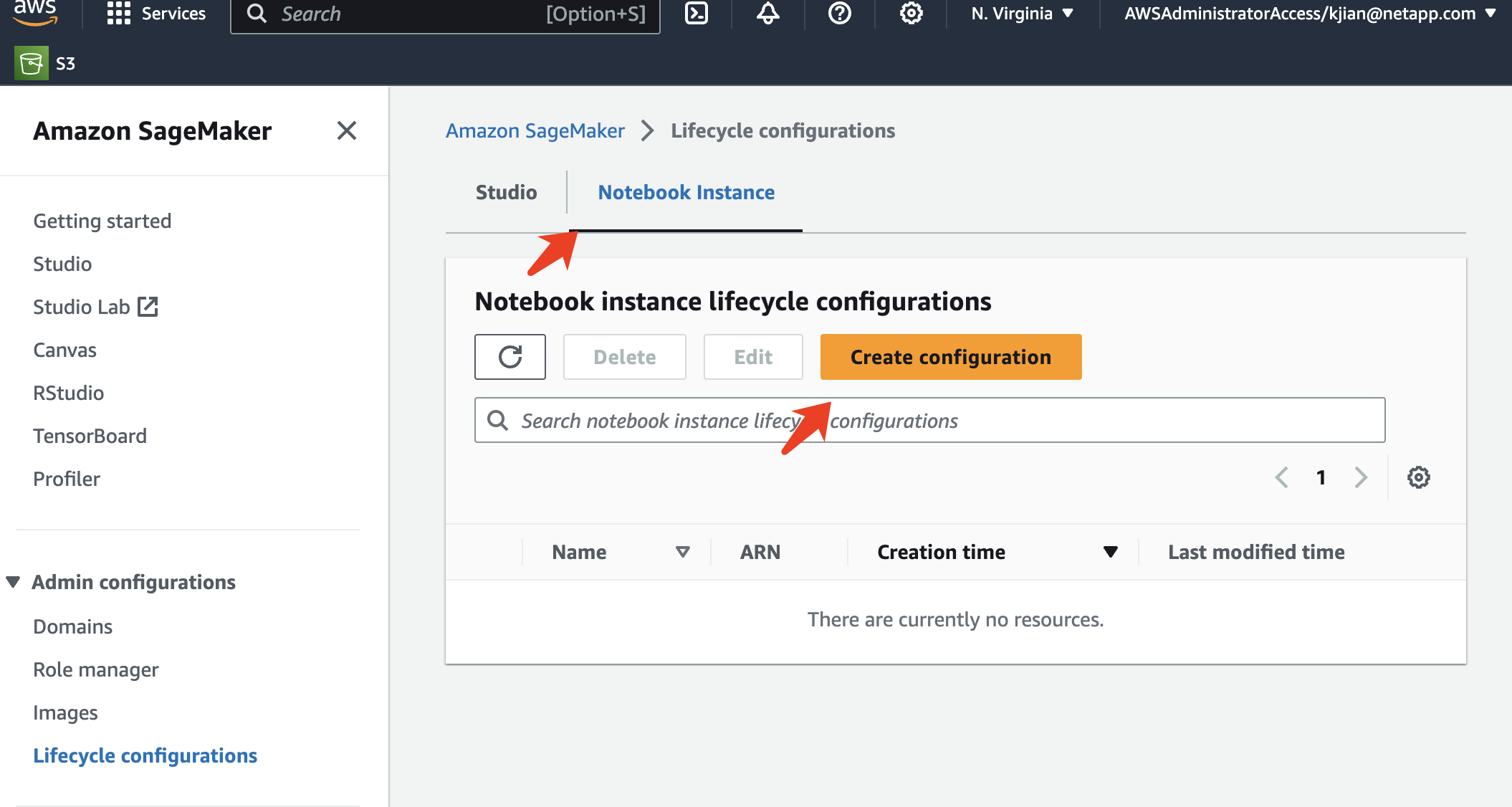
Seleccione la pestaña Instancia de Notebook y haga clic en el botón Crear configuración
-
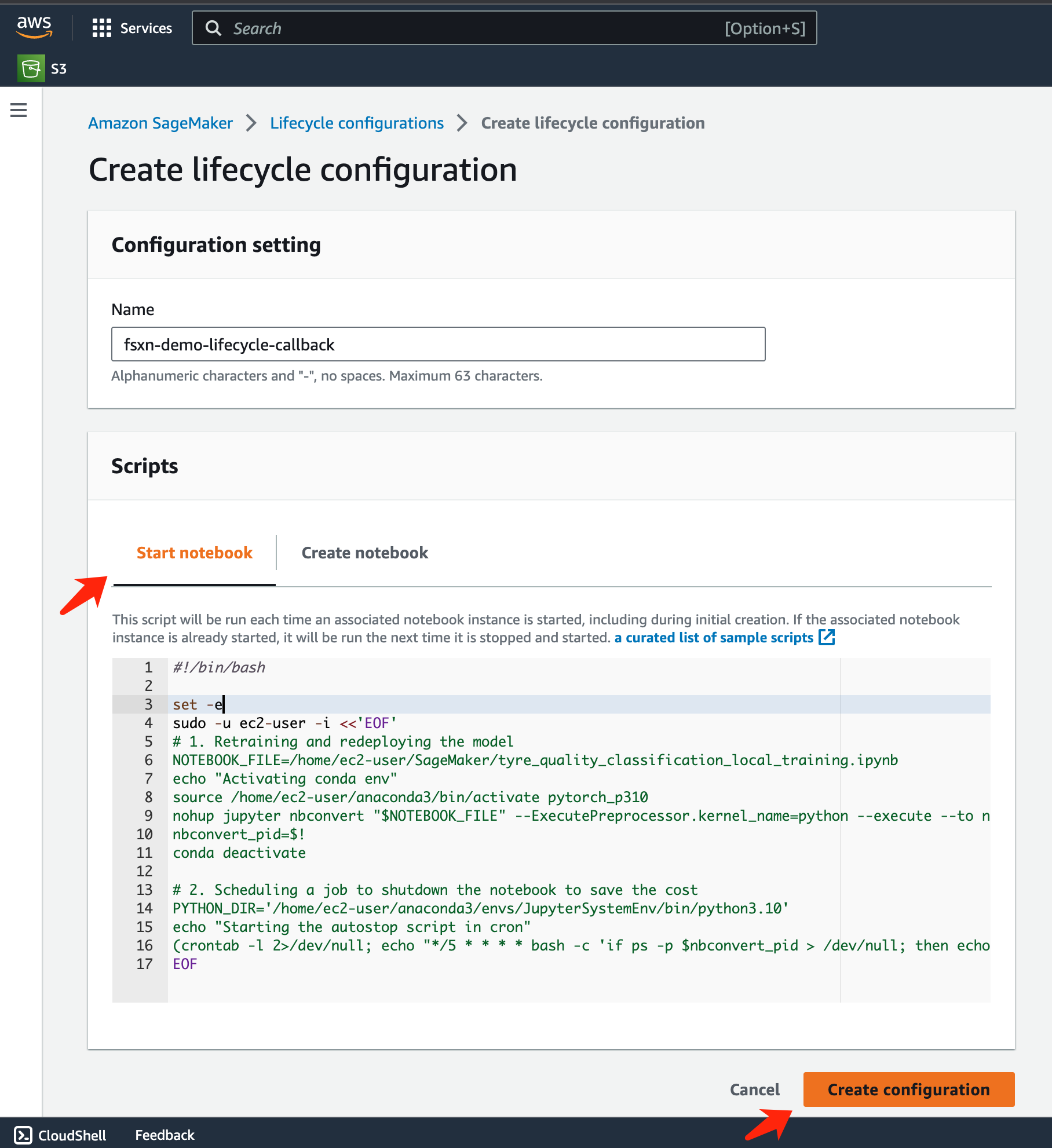
Pegue el siguiente código en el área de entrada.
#!/bin/bash set -e sudo -u ec2-user -i <<'EOF' # 1. Retraining and redeploying the model NOTEBOOK_FILE=/home/ec2-user/SageMaker/tyre_quality_classification_local_training.ipynb echo "Activating conda env" source /home/ec2-user/anaconda3/bin/activate pytorch_p310 nohup jupyter nbconvert "$NOTEBOOK_FILE" --ExecutePreprocessor.kernel_name=python --execute --to notebook & nbconvert_pid=$! conda deactivate # 2. Scheduling a job to shutdown the notebook to save the cost PYTHON_DIR='/home/ec2-user/anaconda3/envs/JupyterSystemEnv/bin/python3.10' echo "Starting the autostop script in cron" (crontab -l 2>/dev/null; echo "*/5 * * * * bash -c 'if ps -p $nbconvert_pid > /dev/null; then echo \"Notebook is still running.\" >> /var/log/jupyter.log; else echo \"Notebook execution completed.\" >> /var/log/jupyter.log; $PYTHON_DIR -c \"import boto3;boto3.client(\'sagemaker\').stop_notebook_instance(NotebookInstanceName=get_notebook_name())\" >> /var/log/jupyter.log; fi'") | crontab - EOF -
Este script ejecuta Jupyter Notebook, que maneja el reentrenamiento y la redistribución del modelo para la inferencia. Una vez completada la ejecución, la computadora portátil se apagará automáticamente en 5 minutos. Para obtener más información sobre el enunciado del problema y la implementación del código, consulte"Parte 2: Aprovechamiento de Amazon FSx for NetApp ONTAP (FSx ONTAP) como fuente de datos para el entrenamiento de modelos en SageMaker" .
-
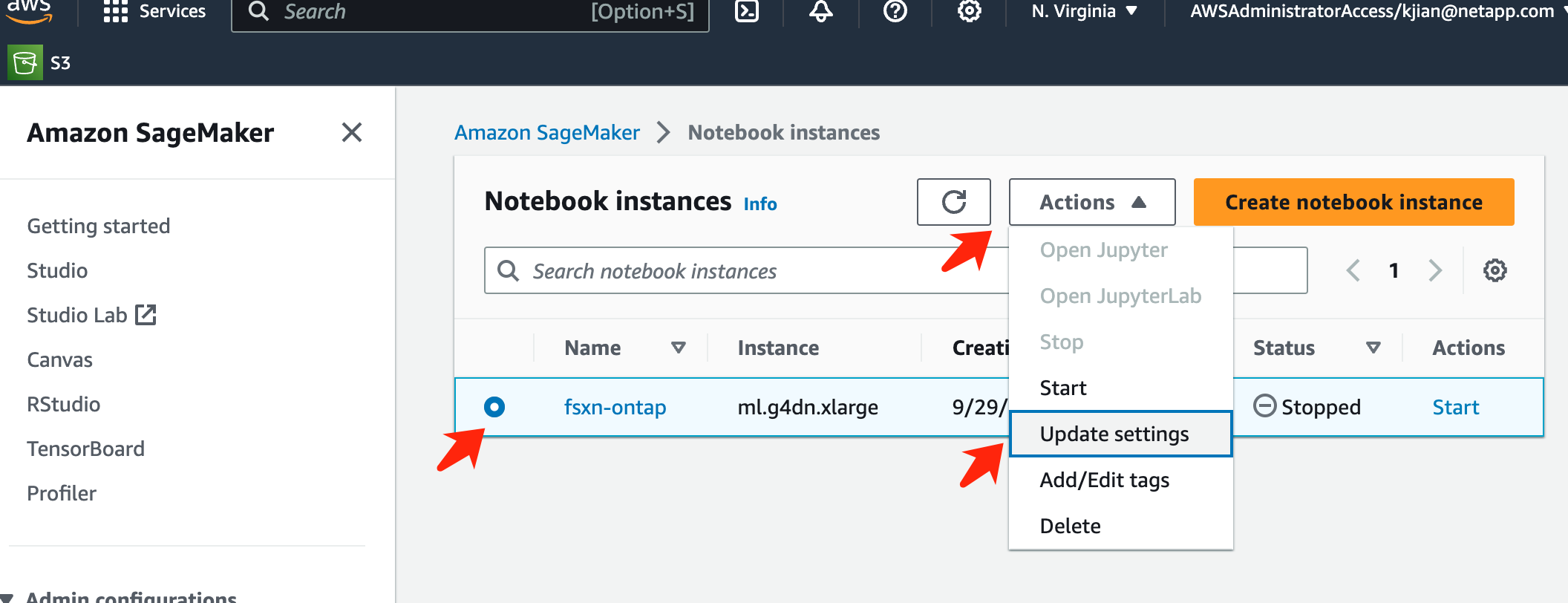
Después de la creación, navegue a Instancias de Notebook, seleccione la instancia de destino y haga clic en Actualizar configuración en el menú desplegable Acciones.
-
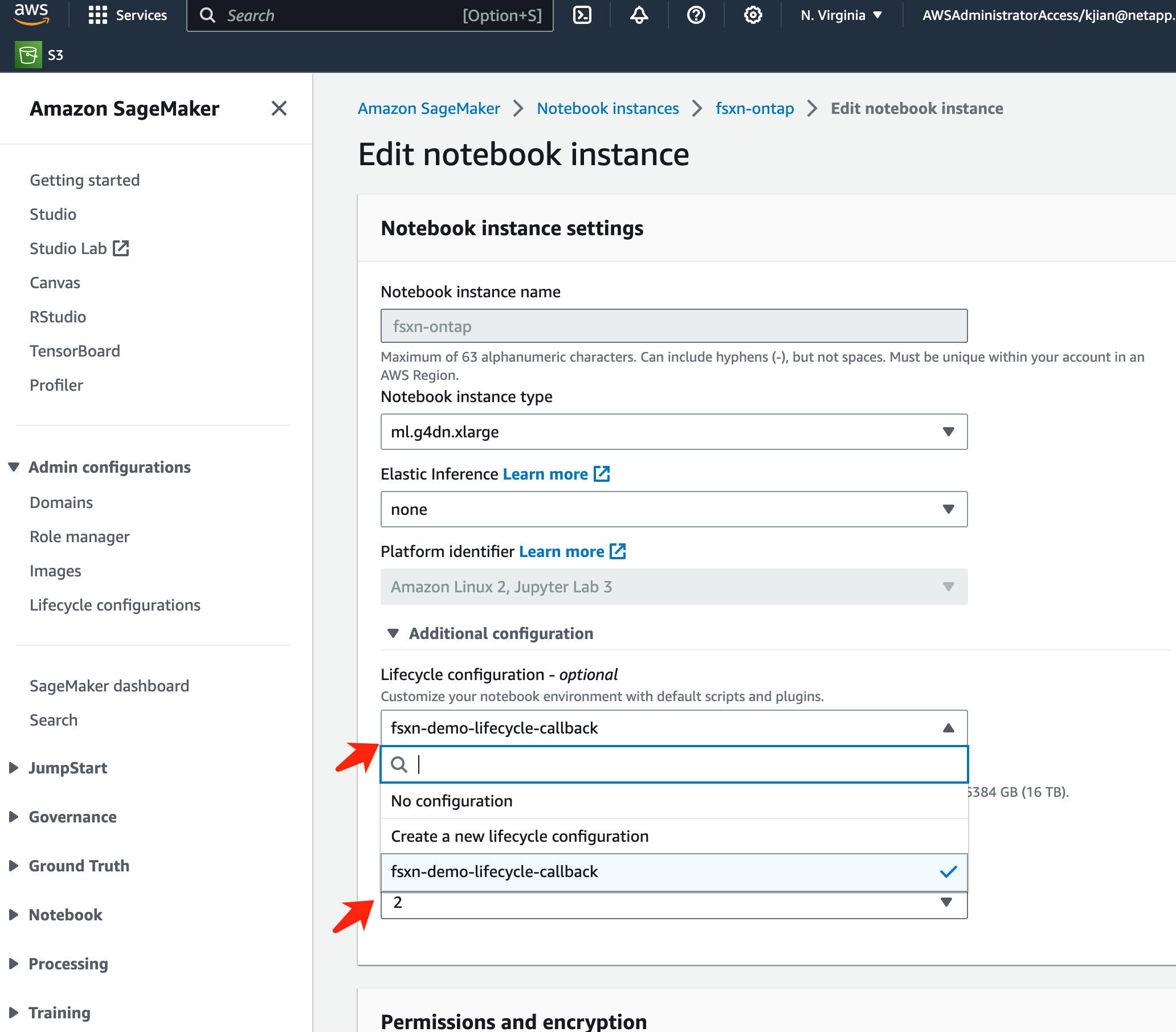
Seleccione la Configuración de ciclo de vida creada y haga clic en Actualizar instancia de notebook.
Función sin servidor de AWS Lambda
Como se mencionó anteriormente, la función AWS Lambda es responsable de poner en marcha la instancia de AWS SageMaker Notebook.
-
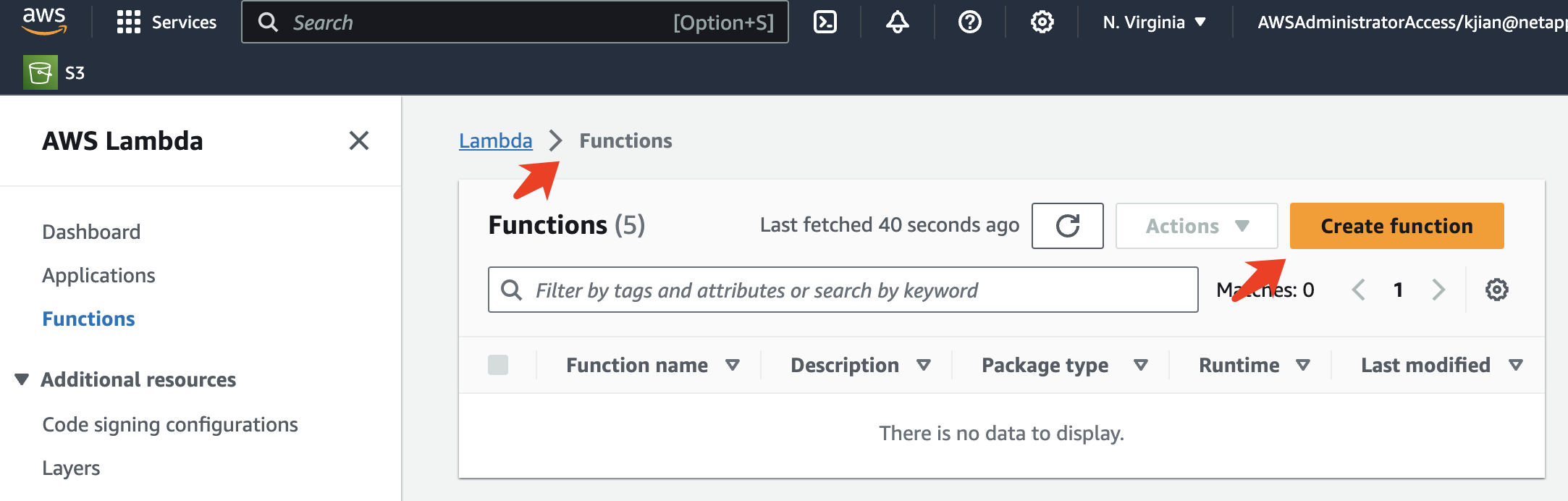
Para crear una función AWS Lambda, navegue al panel correspondiente, cambie a la pestaña Funciones y haga clic en Crear función.
-
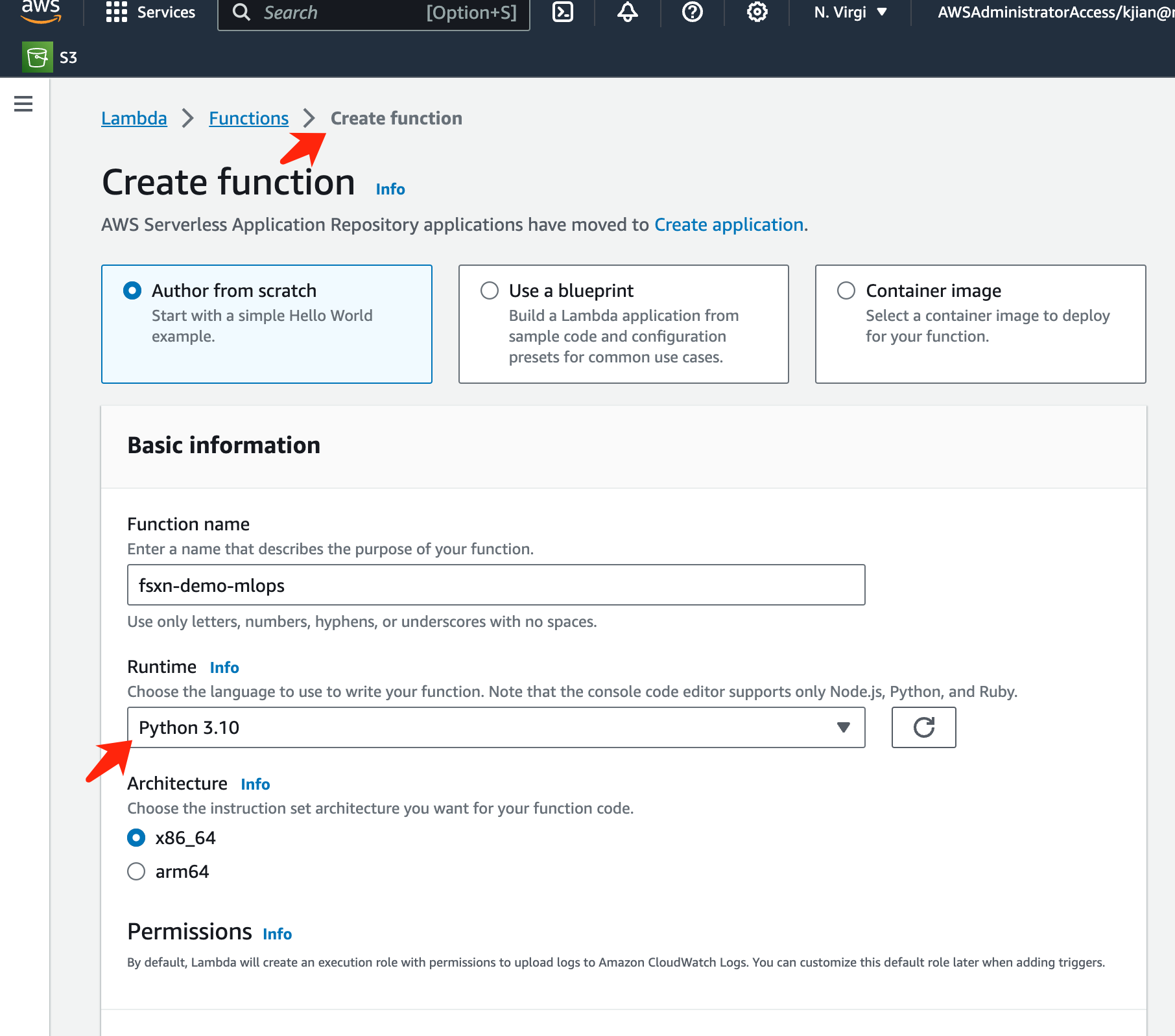
Complete todas las entradas requeridas en la página y recuerde cambiar el tiempo de ejecución a Python 3.10.
-
Verifique que el rol designado tenga el permiso requerido AmazonSageMakerFullAccess y haga clic en el botón Crear función.
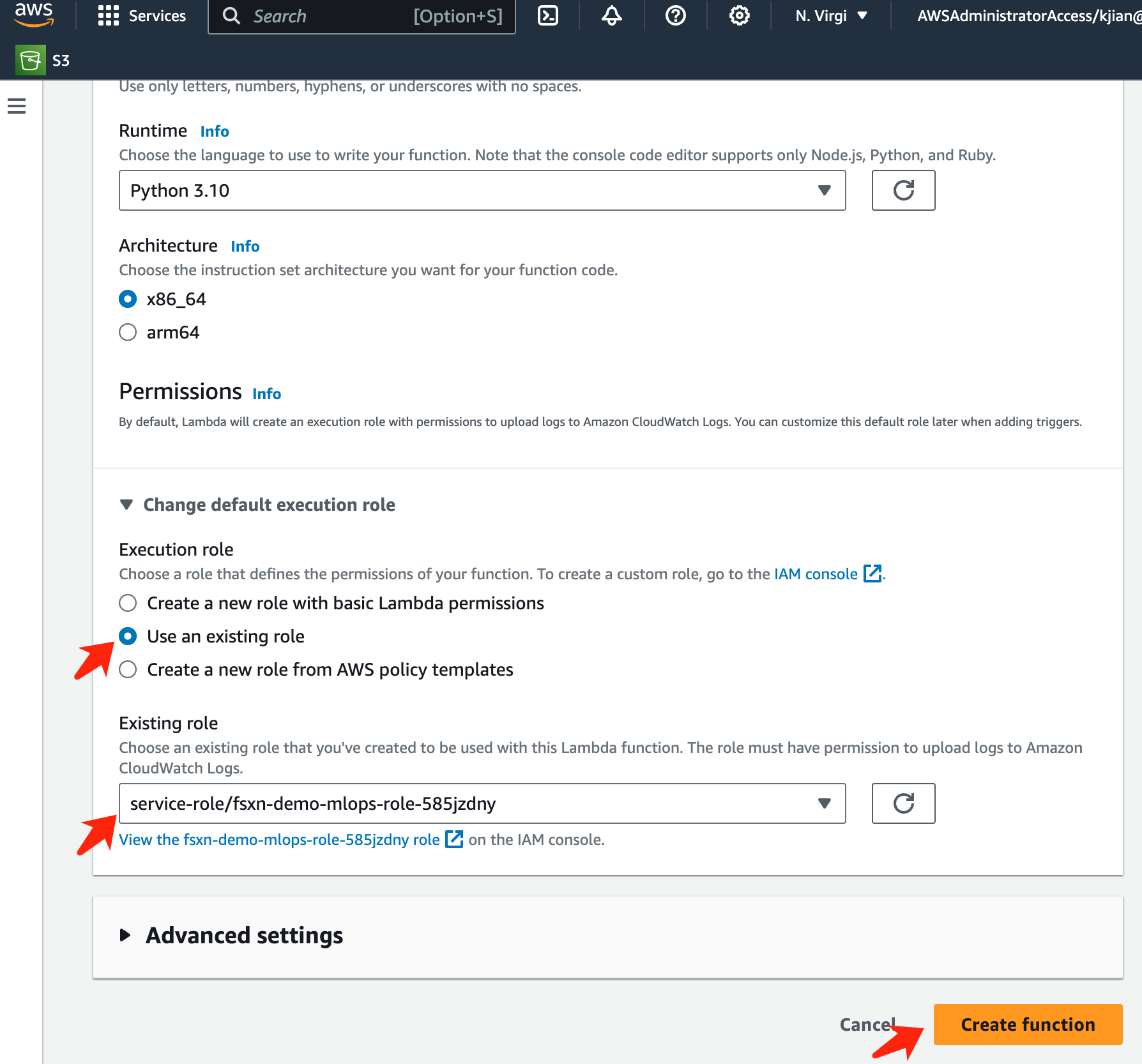
-
Seleccione la función Lambda creada. En la pestaña de código, copie y pegue el siguiente código en el área de texto. Este código inicia la instancia del cuaderno denominada fsxn-ontap.
import boto3 import logging def lambda_handler(event, context): client = boto3.client('sagemaker') logging.info('Invoking SageMaker') client.start_notebook_instance(NotebookInstanceName='fsxn-ontap') return { 'statusCode': 200, 'body': f'Starting notebook instance: {notebook_instance_name}' } -
Haga clic en el botón Implementar para aplicar este cambio de código.
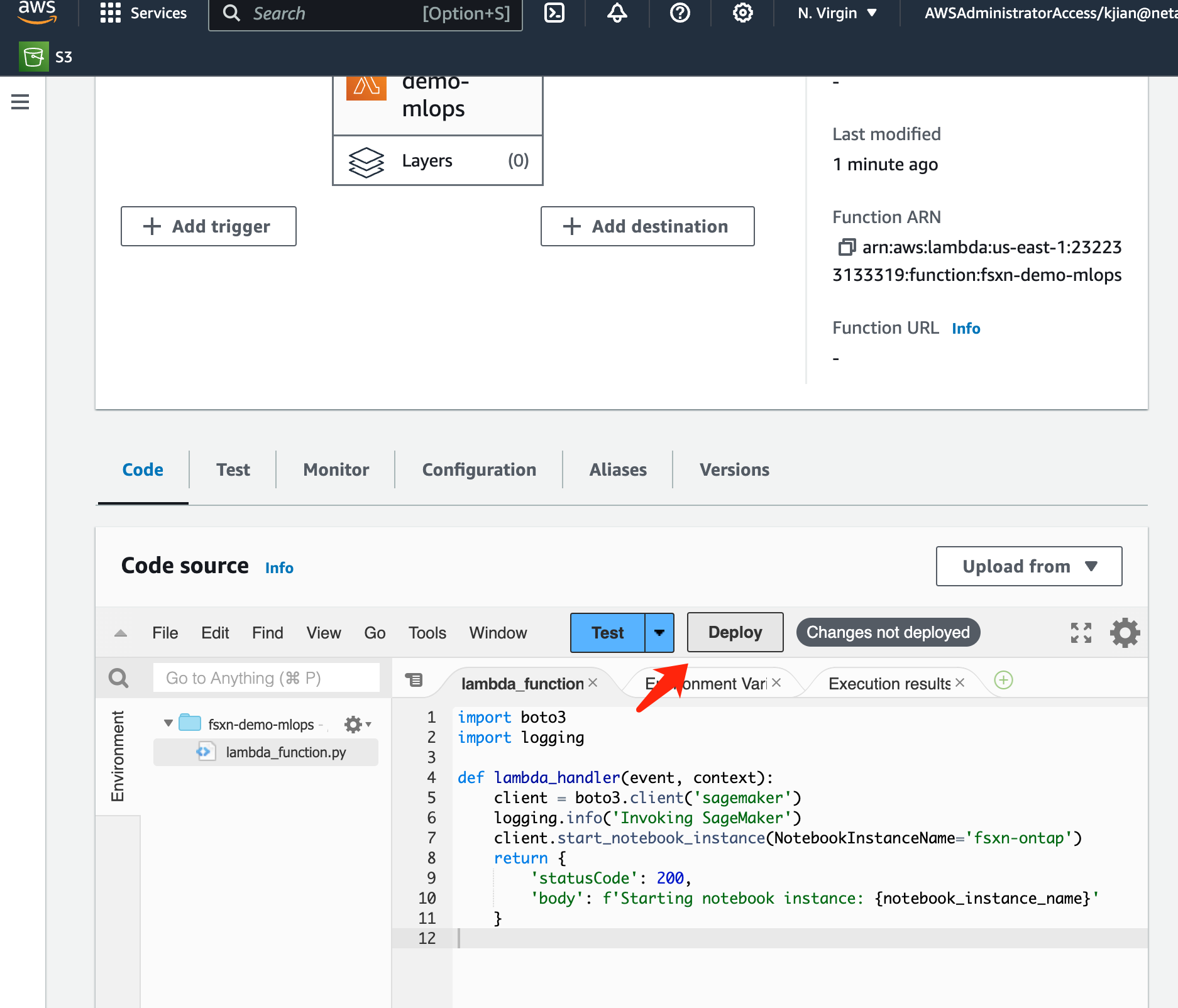
-
Para especificar cómo activar esta función de AWS Lambda, haga clic en el botón Agregar activador.
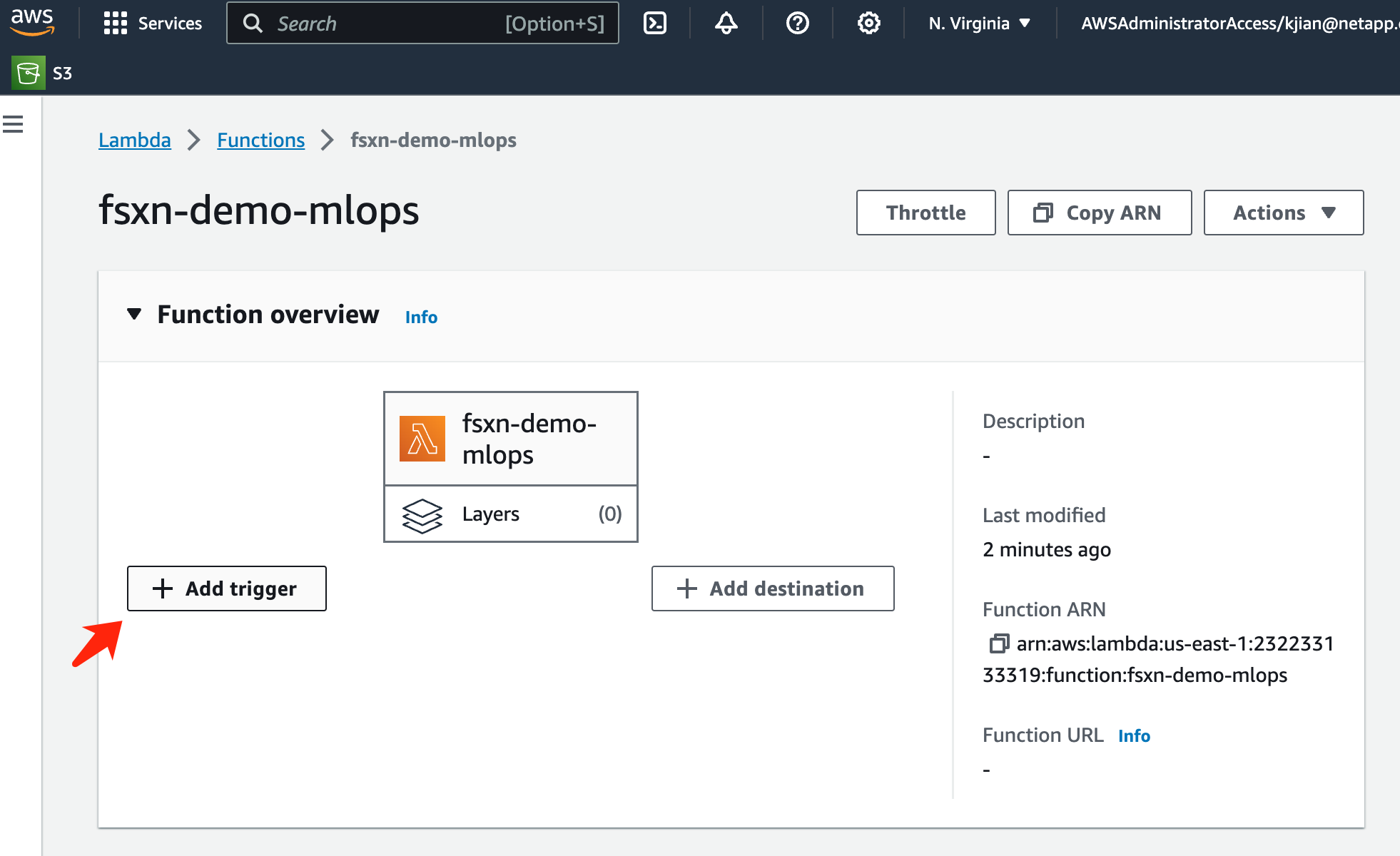
-
Seleccione EventBridge en el menú desplegable, luego haga clic en el botón denominado Crear una nueva regla. En el campo de expresión de programación, ingrese
rate(1 day)y haga clic en el botón Agregar para crear y aplicar esta nueva regla de trabajo cron a la función AWS Lambda.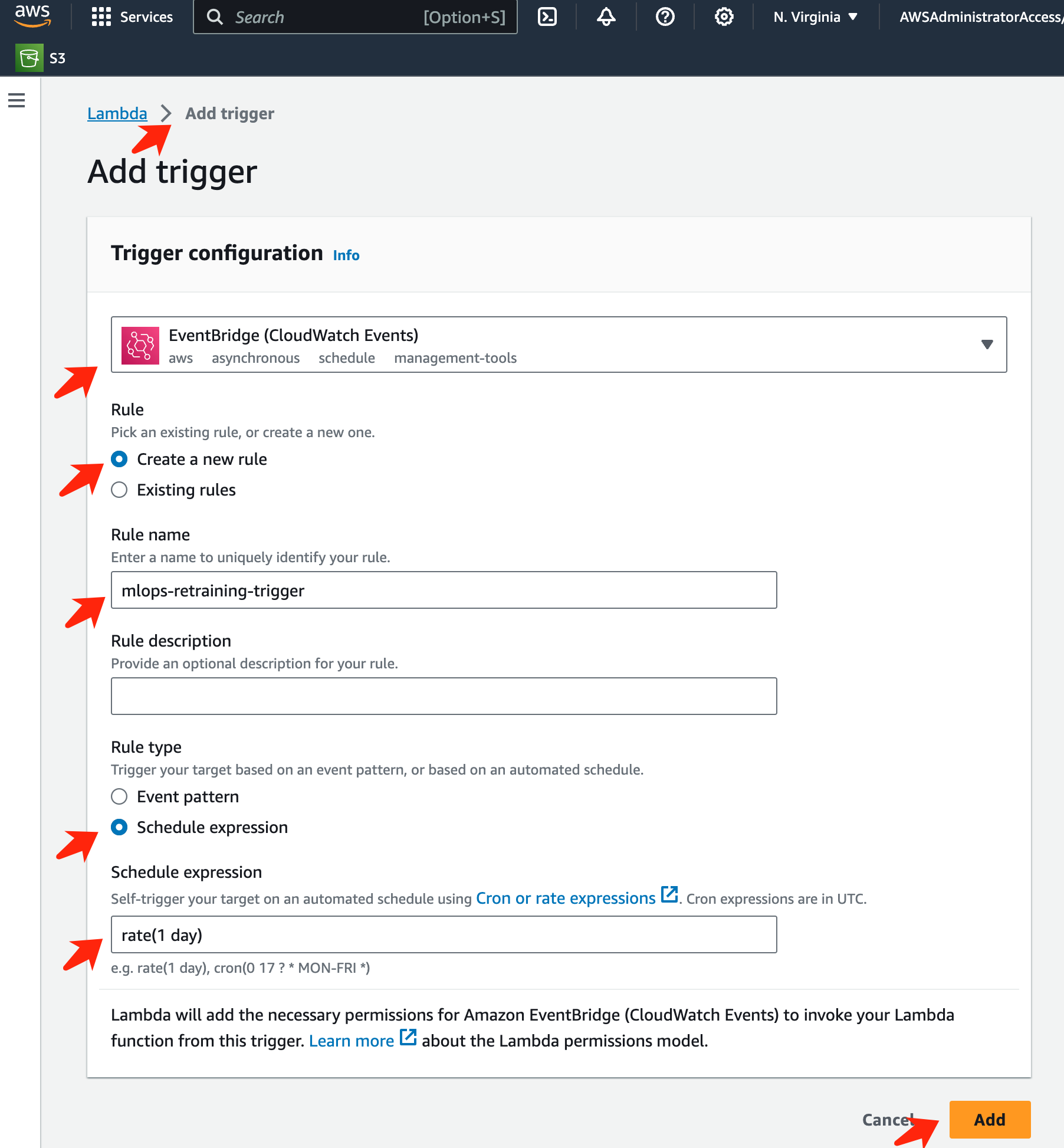
Después de completar la configuración de dos pasos, diariamente, la función AWS Lambda iniciará SageMaker Notebook, realizará un reentrenamiento del modelo utilizando los datos del repositorio FSx ONTAP, volverá a implementar el modelo actualizado en el entorno de producción y apagará automáticamente la instancia de SageMaker Notebook para optimizar los costos. Esto garantiza que el modelo se mantenga actualizado.
Con esto concluye el tutorial para desarrollar un pipeline MLOps.