Principales casos de uso y arquitecturas de IA, ML y DL
 Sugerir cambios
Sugerir cambios
Los principales casos de uso y metodología de IA, ML y DL se pueden dividir en las siguientes secciones:
Canalizaciones de Spark NLP e inferencia distribuida de TensorFlow
La siguiente lista contiene las bibliotecas de PNL de código abierto más populares que han sido adoptadas por la comunidad de ciencia de datos en diferentes niveles de desarrollo:
-
"Kit de herramientas de lenguaje natural (NLTK)" . El kit de herramientas completo para todas las técnicas de PNL. Se mantiene desde principios de la década del 2000.
-
"TextoBlob" . Una API de Python de herramientas de PNL fácil de usar construida sobre NLTK y Pattern.
-
"PNL de Stanford Core" . Servicios y paquetes de PNL en Java desarrollados por Stanford NLP Group.
-
"Gensim" . Topic Modelling for Humans comenzó como una colección de scripts de Python para el proyecto de la Biblioteca Checa de Matemáticas Digitales.
-
"SpaCy" . Flujos de trabajo de PNL industrial de extremo a extremo con Python y Cython con aceleración de GPU para transformadores.
-
"Texto rápido" . Una biblioteca de PNL gratuita, liviana y de código abierto para el aprendizaje de incrustaciones de palabras y la clasificación de oraciones creada por el laboratorio de investigación de inteligencia artificial (FAIR) de Facebook.
Spark NLP es una solución única y unificada para todas las tareas y requisitos de PNL que permite un software escalable, de alto rendimiento y alta precisión impulsado por PNL para casos de uso de producción reales. Aprovecha el aprendizaje por transferencia e implementa los últimos algoritmos y modelos de última generación en la investigación y en todas las industrias. Debido a la falta de soporte completo por parte de Spark para las bibliotecas anteriores, Spark NLP se creó sobre "Spark ML" aprovechar el motor de procesamiento de datos distribuido en memoria de propósito general de Spark como una biblioteca de PNL de nivel empresarial para flujos de trabajo de producción de misión crítica. Sus anotadores utilizan algoritmos basados en reglas, aprendizaje automático y TensorFlow para impulsar implementaciones de aprendizaje profundo. Esto cubre tareas comunes de PNL que incluyen, entre otras, tokenización, lematización, derivación, etiquetado de partes del discurso, reconocimiento de entidades nombradas, corrección ortográfica y análisis de sentimientos.
Representaciones de codificador bidireccional a partir de transformadores (BERT) es una técnica de aprendizaje automático basada en transformadores para PNL. Popularizó el concepto de preentrenamiento y ajuste fino. La arquitectura del transformador en BERT se originó a partir de la traducción automática, que modela las dependencias a largo plazo mejor que los modelos de lenguaje basados en redes neuronales recurrentes (RNN). También introdujo la tarea de modelado de lenguaje enmascarado (MLM), donde un 15% aleatorio de todos los tokens se enmascaran y el modelo los predice, lo que permite una verdadera bidireccionalidad.
El análisis del sentimiento financiero es un desafío debido al lenguaje especializado y la falta de datos etiquetados en ese dominio. FinBERT, un modelo de lenguaje basado en BERT preentrenado, fue adaptado al dominio en "Reuters TRC2" , un corpus financiero, y ajustado con datos etiquetados ( "Frase financiera del banco" ) para la clasificación del sentimiento financiero. Los investigadores extrajeron 4.500 frases de artículos de noticias con términos financieros. Luego, 16 expertos y estudiantes de maestría con experiencia en finanzas etiquetaron las oraciones como positivas, neutrales y negativas. Creamos un flujo de trabajo Spark de extremo a extremo para analizar el sentimiento de las transcripciones de las llamadas de ganancias de las 10 principales empresas del NASDAQ de 2016 a 2020 utilizando FinBERT y otras dos canalizaciones entrenadas previamente. "Explicar el documento DL" ) de Spark NLP.
El motor de aprendizaje profundo subyacente para Spark NLP es TensorFlow, una plataforma de código abierto de extremo a extremo para el aprendizaje automático que permite la creación sencilla de modelos, la producción de ML sólida en cualquier lugar y la experimentación potente para la investigación. Por lo tanto, al ejecutar nuestros pipelines en Spark yarn cluster En este modo, básicamente estábamos ejecutando TensorFlow distribuido con paralelización de datos y modelos en un nodo maestro y varios nodos de trabajo, así como almacenamiento conectado a la red montado en el clúster.
Capacitación distribuida de Horovod
La validación central de Hadoop para el rendimiento relacionado con MapReduce se realiza con TeraGen, TeraSort, TeraValidate y DFSIO (lectura y escritura). Los resultados de la validación de TeraGen y TeraSort se presentan en "Solución NetApp E-Series para Hadoop" y en la sección "Niveles de almacenamiento" para AFF.
Basándonos en las solicitudes de los clientes, consideramos que la capacitación distribuida con Spark es uno de los casos de uso más importantes. En este documento, utilizamos el "Hovorod en Spark" para validar el rendimiento de Spark con soluciones locales, nativas de la nube e híbridas de NetApp mediante controladores de almacenamiento NetApp All Flash FAS (AFF), Azure NetApp Files y StorageGRID.
El paquete Horovod en Spark proporciona un envoltorio conveniente alrededor de Horovod que simplifica la ejecución de cargas de trabajo de entrenamiento distribuidas en clústeres Spark, lo que permite un ciclo de diseño de modelo ajustado en el que el procesamiento de datos, el entrenamiento del modelo y la evaluación del modelo se realizan en Spark, donde residen los datos de entrenamiento e inferencia.
Hay dos API para ejecutar Horovod en Spark: una API de estimación de alto nivel y una API de ejecución de nivel inferior. Aunque ambos utilizan el mismo mecanismo subyacente para ejecutar Horovod en los ejecutores Spark, la API Estimator abstrae el procesamiento de datos, el ciclo de entrenamiento del modelo, los puntos de control del modelo, la recopilación de métricas y el entrenamiento distribuido. Utilizamos Horovod Spark Estimators, TensorFlow y Keras para un flujo de trabajo de preparación de datos de extremo a extremo y entrenamiento distribuido basado en "Ventas en tiendas Kaggle Rossmann" competencia.
El guión keras_spark_horovod_rossmann_estimator.py se puede encontrar en la sección"Scripts de Python para cada caso de uso principal." Consta de tres partes:
-
La primera parte realiza varios pasos de preprocesamiento de datos sobre un conjunto inicial de archivos CSV proporcionados por Kaggle y recopilados por la comunidad. Los datos de entrada se separan en un conjunto de entrenamiento con un
Validationsubconjunto y un conjunto de datos de prueba. -
La segunda parte define un modelo de red neuronal profunda (DNN) Keras con función de activación sigmoidea logarítmica y un optimizador Adam, y realiza un entrenamiento distribuido del modelo utilizando Horovod en Spark.
-
La tercera parte realiza una predicción en el conjunto de datos de prueba utilizando el mejor modelo que minimiza el error absoluto medio general del conjunto de validación. Luego crea un archivo CSV de salida.
Ver la sección"Aprendizaje automático" para varios resultados de comparación de tiempo de ejecución.
Aprendizaje profundo multitrabajador con Keras para la predicción del CTR
Con los recientes avances en plataformas y aplicaciones de ML, ahora se presta mucha atención al aprendizaje a escala. La tasa de clics (CTR) se define como el número promedio de clics por cada cien impresiones de anuncios en línea (expresado como porcentaje). Se adopta ampliamente como una métrica clave en varios sectores industriales y casos de uso, incluidos el marketing digital, el comercio minorista, el comercio electrónico y los proveedores de servicios. Para obtener más detalles sobre las aplicaciones de CTR y los resultados del rendimiento del entrenamiento distribuido, consulte"Modelos de aprendizaje profundo para el rendimiento de la predicción de CTR" sección.
En este informe técnico utilizamos una variación del "Conjunto de datos de registros de clics de Criteo en terabytes" (ver TR-4904) para el aprendizaje profundo distribuido de múltiples trabajadores que utiliza Keras para crear un flujo de trabajo Spark con modelos de redes profundas y cruzadas (DCN), comparando su desempeño en términos de función de error de pérdida de registro con un modelo de regresión logística Spark ML de referencia. DCN captura de manera eficiente interacciones de características efectivas de grados limitados, aprende interacciones altamente no lineales, no requiere ingeniería de características manual ni búsqueda exhaustiva y tiene un bajo costo computacional.
Los datos para los sistemas de recomendación a escala web son en su mayoría discretos y categóricos, lo que genera un espacio de características grande y escaso que dificulta la exploración de características. Esto ha limitado la mayoría de los sistemas a gran escala a modelos lineales como la regresión logística. Sin embargo, la clave para hacer buenas predicciones es identificar características frecuentemente predictivas y, al mismo tiempo, explorar características cruzadas poco comunes o no observadas. Los modelos lineales son simples, interpretables y fáciles de escalar, pero tienen un poder expresivo limitado.
Por otra parte, se ha demostrado que las características cruzadas son significativas para mejorar la expresividad de los modelos. Lamentablemente, a menudo se requiere ingeniería de características manual o una búsqueda exhaustiva para identificar dichas características. Generalizar a interacciones de características invisibles suele ser difícil. El uso de una red neuronal cruzada como DCN evita la ingeniería de características específicas de la tarea al aplicar explícitamente el cruce de características de manera automática. La red cruzada consta de múltiples capas, donde el mayor grado de interacciones está determinado probablemente por la profundidad de la capa. Cada capa produce interacciones de orden superior basadas en las existentes y conserva las interacciones de las capas anteriores.
Una red neuronal profunda (DNN) promete capturar interacciones muy complejas entre características. Sin embargo, en comparación con DCN, requiere casi un orden de magnitud más de parámetros, no puede formar características cruzadas de manera explícita y puede fallar en el aprendizaje eficiente de algunos tipos de interacciones de características. La red cruzada utiliza eficientemente la memoria y es fácil de implementar. El entrenamiento conjunto de los componentes cruzados y DNN captura de manera eficiente las interacciones de características predictivas y brinda un rendimiento de última generación en el conjunto de datos CTR de Criteo.
Un modelo DCN comienza con una capa de incrustación y apilamiento, seguida de una red cruzada y una red profunda en paralelo. A estas, a su vez, les sigue una capa de combinación final que combina las salidas de las dos redes. Los datos de entrada pueden ser un vector con características dispersas y densas. En Spark, las bibliotecas contienen el tipo SparseVector . Por lo tanto, es importante que los usuarios distingan entre ambos y tengan cuidado al llamar a sus respectivas funciones y métodos. En los sistemas de recomendación a escala web, como la predicción de CTR, las entradas son principalmente características categóricas, por ejemplo 'country=usa' . Estas características suelen codificarse como vectores one-hot, por ejemplo, '[0,1,0, …]' . Codificación one-hot (OHE) con SparseVector es útil cuando se trabaja con conjuntos de datos del mundo real con vocabularios en constante cambio y crecimiento. Modificamos los ejemplos en "CTR profundo" para procesar vocabularios grandes, creando vectores de incrustación en la capa de incrustación y apilamiento de nuestro DCN.
El "Conjunto de datos de anuncios de display de Criteo" predice la tasa de clics de los anuncios. Tiene 13 características enteras y 26 características categóricas en las que cada categoría tiene una alta cardinalidad. Para este conjunto de datos, una mejora de 0,001 en la pérdida logarítmica es prácticamente significativa debido al gran tamaño de entrada. Una pequeña mejora en la precisión de la predicción para una gran base de usuarios puede conducir potencialmente a un gran aumento en los ingresos de una empresa. El conjunto de datos contiene 11 GB de registros de usuarios de un período de 7 días, lo que equivale a alrededor de 41 millones de registros. Usamos Spark dataFrame.randomSplit()function Dividir aleatoriamente los datos para entrenamiento (80%), validación cruzada (10%) y el 10% restante para pruebas.
DCN se implementó en TensorFlow con Keras. Hay cuatro componentes principales en la implementación del proceso de entrenamiento de modelos con DCN:
-
Procesamiento e incrustación de datos. Las características de valor real se normalizan aplicando una transformación logarítmica. Para las características categóricas, integramos las características en vectores densos de dimensión 6×(cardinalidad de categoría)1/4. La concatenación de todas las incrustaciones da como resultado un vector de dimensión 1026.
-
Mejoramiento. Aplicamos optimización estocástica de minilotes con el optimizador Adam. El tamaño del lote se estableció en 512. Se aplicó la normalización por lotes a la red profunda y la norma de recorte de gradiente se estableció en 100.
-
Regularización. Utilizamos la detención temprana, ya que no se encontró que la regularización o el abandono de L2 fueran efectivos.
-
Hiperparámetros. Informamos los resultados basados en una búsqueda en cuadrícula sobre el número de capas ocultas, el tamaño de la capa oculta, la tasa de aprendizaje inicial y el número de capas cruzadas. El número de capas ocultas varió entre 2 y 5, con tamaños de capas ocultas que variaron entre 32 y 1024. Para DCN, el número de capas cruzadas fue de 1 a 6. La tasa de aprendizaje inicial se ajustó de 0,0001 a 0,001 con incrementos de 0,0001. Todos los experimentos se detuvieron anticipadamente en el paso de entrenamiento 150 000, más allá del cual comenzó a producirse un sobreajuste.
Arquitecturas utilizadas para la validación
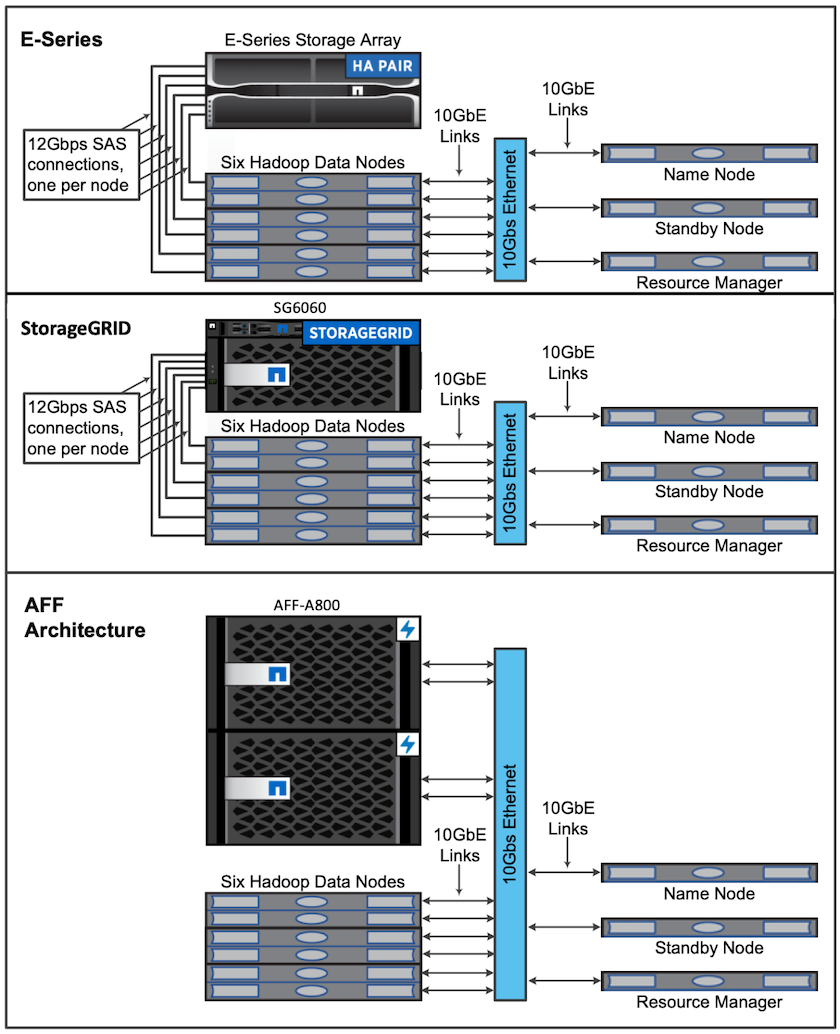
Para esta validación, utilizamos cuatro nodos de trabajo y un nodo maestro con un par AFF-A800 HA. Todos los miembros del clúster estaban conectados a través de conmutadores de red 10GbE.
Para esta validación de la solución NetApp Spark, utilizamos tres controladores de almacenamiento diferentes: el E5760, el E5724 y el AFF-A800. Los controladores de almacenamiento de la Serie E se conectaron a cinco nodos de datos con conexiones SAS de 12 Gbps. El controlador de almacenamiento de par HA AFF proporciona volúmenes NFS exportados a través de conexiones de 10 GbE a nodos de trabajo de Hadoop. Los miembros del clúster Hadoop se conectaron a través de conexiones 10GbE en las soluciones Hadoop E-Series, AFF y StorageGRID .