

Implementación de la recuperación ante desastres con NetApp Disaster Recovery
 Sugerir cambios
Sugerir cambios
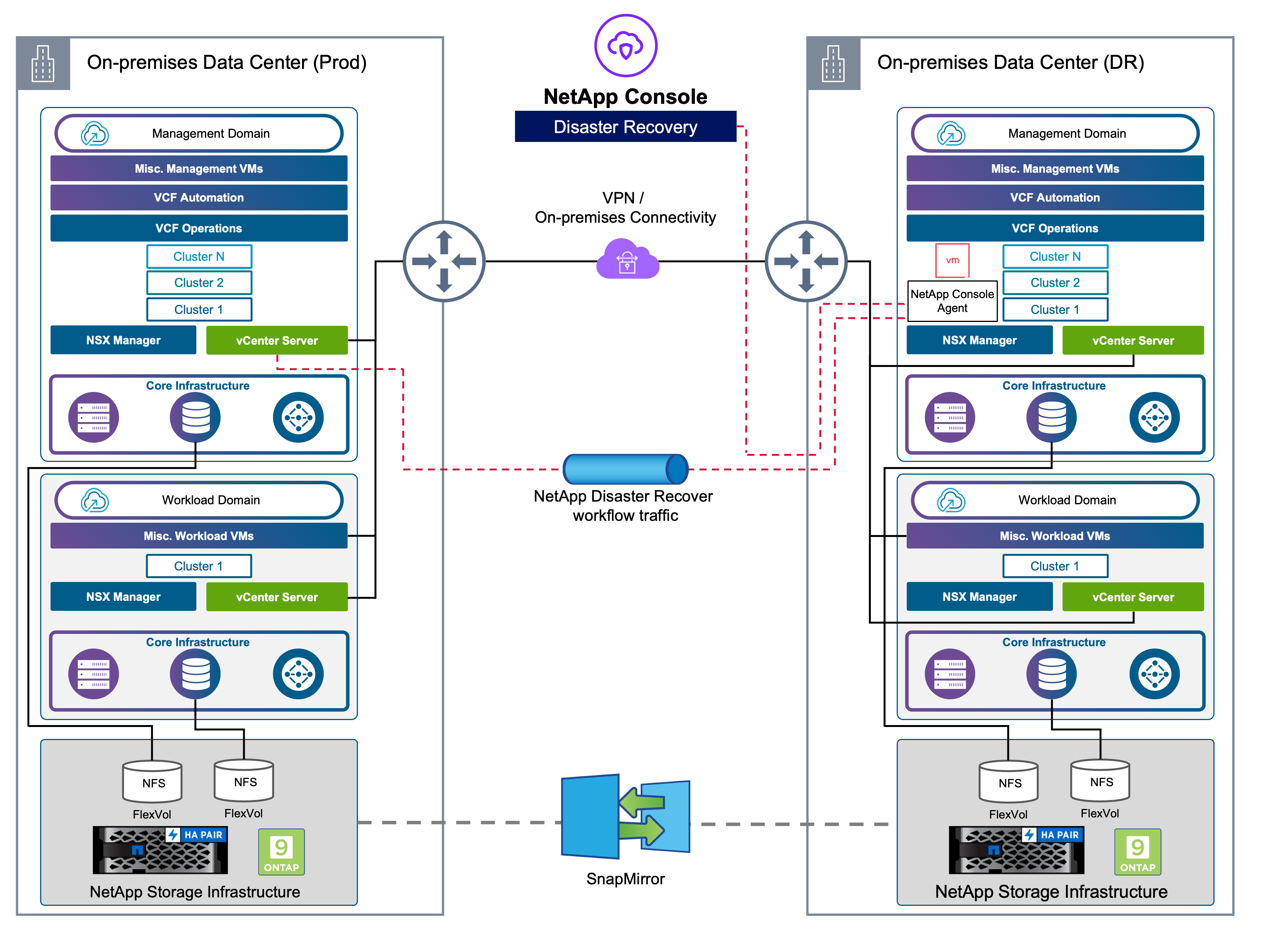
Solución de recuperación ante desastres VCF para almacenes de datos NFS con NetApp SnapMirror y NetApp Disaster Recovery
La replicación a nivel de bloque desde un sitio de producción a un sitio de recuperación ante desastres (DR) ofrece una estrategia resistente y rentable para proteger las cargas de trabajo contra interrupciones del sitio y eventos de corrupción de datos, incluidos ataques de ransomware. La replicación SnapMirror de NetApp permite que los dominios de carga de trabajo VMware VCF 9 que se ejecutan en sistemas ONTAP locales (mediante almacenes de datos NFS o VMFS) se repliquen en un sistema ONTAP secundario ubicado en un centro de datos de recuperación designado donde también se implementa VMware.
Para obtener más información, consulte lo siguiente:"Documentación de NetApp Disaster Recovery" .
En esta sección se describe la configuración de NetApp Disaster Recovery para establecer DR para máquinas virtuales VMware locales.
La configuración incluye:
-
Creación de una cuenta de NetApp Console e implementación de un agente.
-
Agregar matrices ONTAP a la NetApp Console a los sistemas bajo administración para facilitar la comunicación entre VMware vCenter y el almacenamiento ONTAP .
-
Configurar la replicación entre sitios usando SnapMirror.
-
Configurar y probar un plan de recuperación para validar la preparación para la conmutación por error.
NetApp Disaster Recovery, integrado en la NetApp Console, permite a las organizaciones descubrir sin problemas sus VMware vCenters locales y sistemas de almacenamiento ONTAP . Una vez descubiertos, los administradores pueden definir agrupaciones de recursos, crear planes de recuperación ante desastres, asociarlos con los recursos adecuados e iniciar o probar operaciones de conmutación por error y recuperación. NetApp SnapMirror proporciona una replicación eficiente a nivel de bloques, lo que garantiza que el sitio de DR permanezca sincronizado con el entorno de producción a través de actualizaciones incrementales. Esto permite alcanzar un objetivo de punto de recuperación (RPO) de tan solo cinco minutos.
NetApp Disaster Recovery también admite pruebas de recuperación ante desastres sin interrupciones. Al aprovechar la tecnología FlexClone de ONTAP, crea copias temporales que ahorran espacio del almacén de datos NFS a partir de la instantánea replicada más reciente, sin afectar las cargas de trabajo de producción ni incurrir en costos de almacenamiento adicionales. Después de la prueba, el entorno se puede desmontar fácilmente, preservando la integridad de los datos replicados.
En caso de una conmutación por error real, NetApp Console orquesta el proceso de recuperación, activando automáticamente las máquinas virtuales protegidas en el sitio de recuperación ante desastres designado con una mínima intervención del usuario. Cuando se restaura el sitio principal, el servicio revierte la relación de SnapMirror y replica cualquier cambio en el sitio original, lo que permite una conmutación por error fluida y controlada.
Todas estas capacidades se ofrecen a un coste significativamente menor en comparación con las soluciones tradicionales de recuperación ante desastres.
Empezando
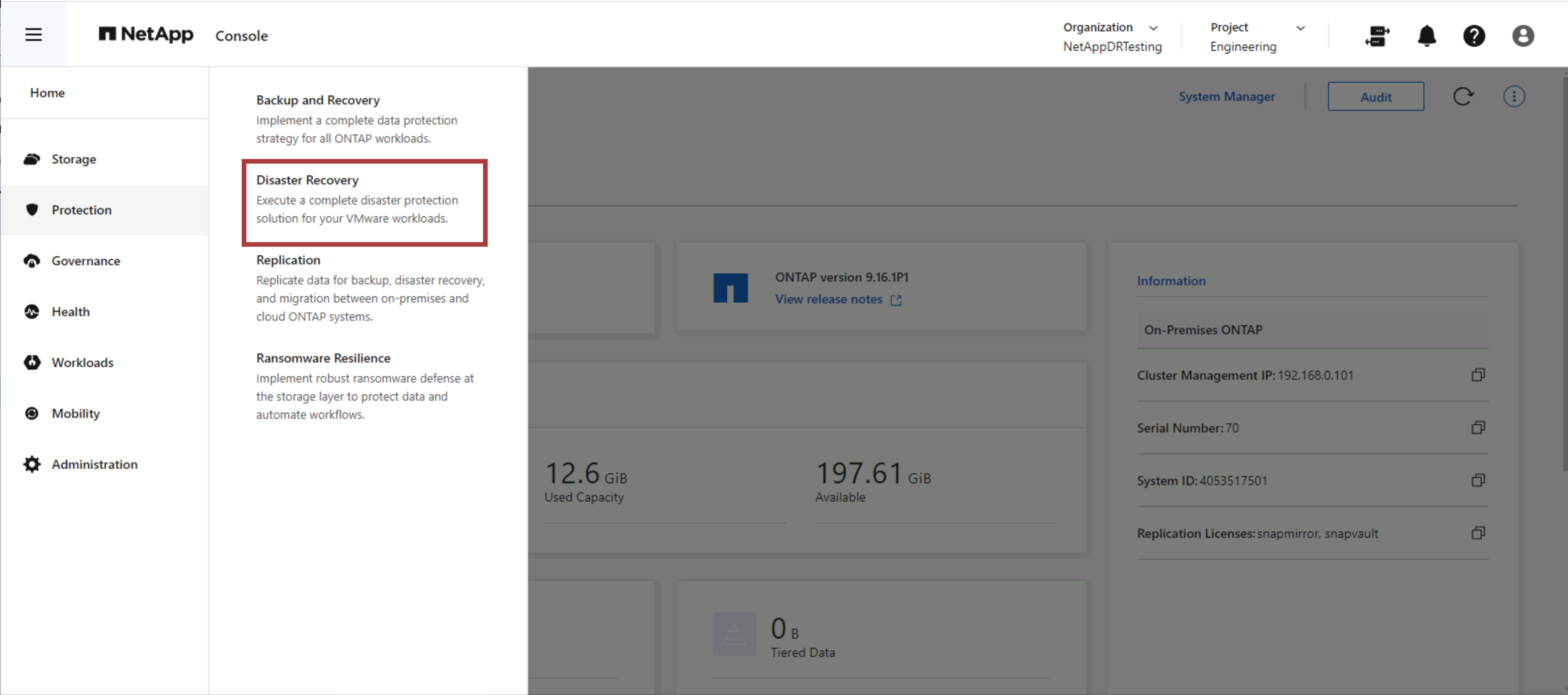
Para comenzar a utilizar NetApp Disaster Recovery, utilice la NetApp Console y luego acceda al servicio.
-
Inicie sesión en la NetApp Console.
-
Desde el panel de navegación izquierdo de la NetApp Console , seleccione Protección > Recuperación ante desastres.
-
Aparece el panel de NetApp Disaster Recovery .
Antes de configurar el plan de recuperación ante desastres, asegúrese de lo siguiente"prerrequisitos" se cumplen:
-
El agente de consola se configura en la NetApp Console.
-
La instancia del agente tiene conectividad con el dominio de carga de trabajo de origen y destino vCenter y los sistemas de almacenamiento.
-
Clúster NetApp Data ONTAP para proporcionar almacenes de datos NFS o VMFS.
-
Los sistemas de almacenamiento NetApp locales que alojan almacenes de datos NFS o VMFS para VMware se agregan en la NetApp Console.
-
La resolución de DNS debe estar vigente cuando se utilizan nombres DNS. De lo contrario, utilice direcciones IP para vCenter.
-
La replicación de SnapMirror está configurada para los volúmenes de almacén de datos designados basados en NFS o VMFS.
-
Asegúrese de que el entorno tenga versiones compatibles de vCenter Server y servidores ESXi.
Una vez establecida la conectividad entre los sitios de origen y destino, proceda con los pasos de configuración, que deberían tomar un par de clics y entre 3 y 5 minutos.
Nota: NetApp recomienda implementar el agente de consola en el sitio de destino o en un tercer sitio, para que el agente pueda comunicarse a través de la red con los recursos de origen y destino.
En esta demostración, los dominios de carga de trabajo están configurados con almacenamiento NFS de ONTAP . Los pasos en términos de flujo de trabajo siguen siendo los mismos para los almacenes de datos basados en VMFS.
Configuración de NetApp Disaster Recovery
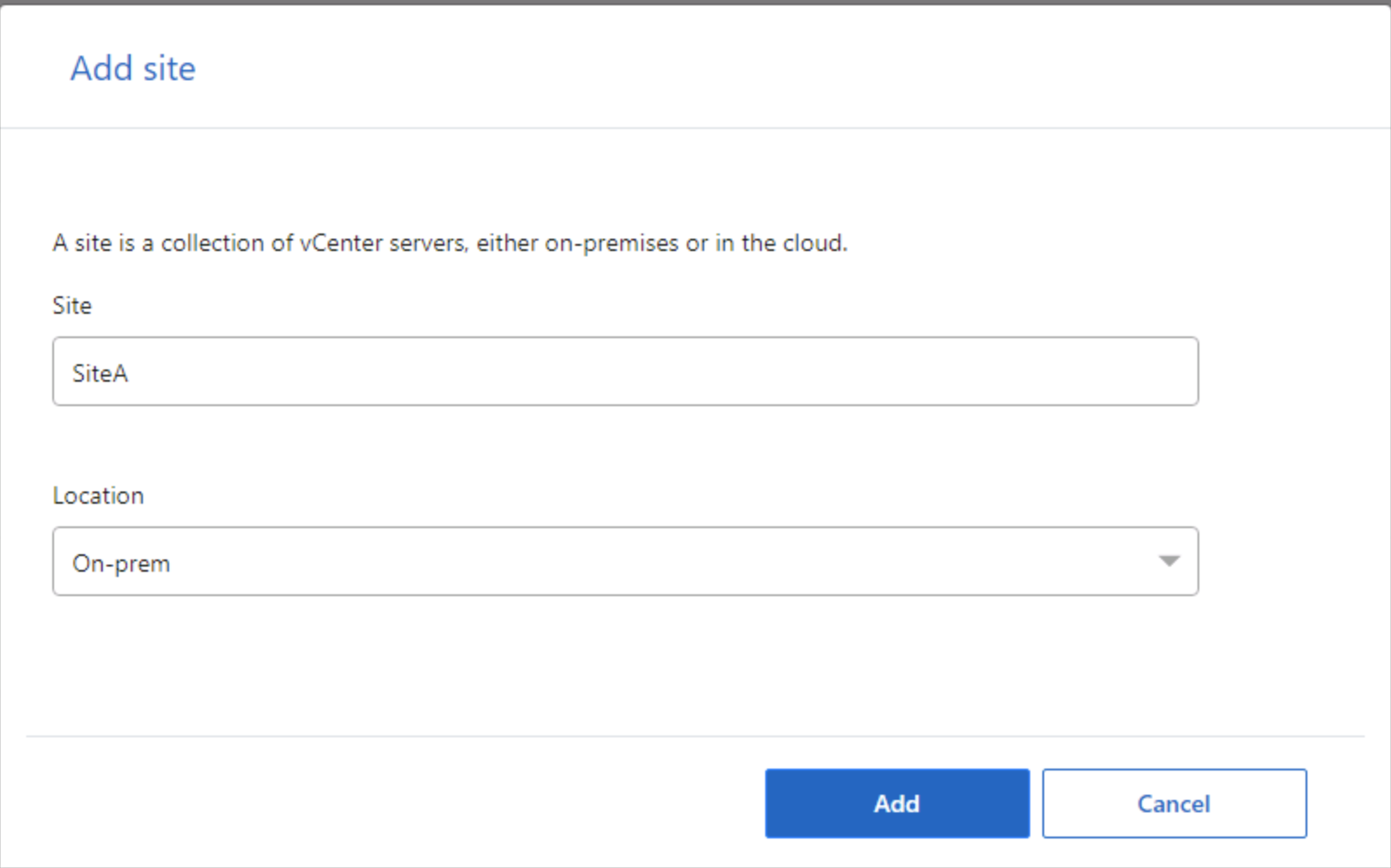
El primer paso para prepararse para la recuperación ante desastres es descubrir y agregar el vCenter de origen y los recursos de almacenamiento a NetApp Disaster Recovery.
Abra la NetApp Console y seleccione Protección > Recuperación ante desastres en el menú de navegación izquierdo. Seleccione Sitios y luego elija Agregar. Ingrese un nombre para el nuevo sitio de origen y sus ubicaciones. Repita el paso para agregar el sitio de destino y la ubicación.
Agregue las siguientes plataformas:
-
Dominio de carga de trabajo de origen vCenter
-
Dominio de carga de trabajo de destino vCenter.
Una vez que se agregan los vCenters, se activa el descubrimiento automático.
Configuración de la replicación de almacenamiento entre la matriz del sitio de origen y la matriz del sitio de destino
SnapMirror proporciona replicación de datos en un entorno NetApp . Basada en la tecnología NetApp Snapshot®, la replicación de SnapMirror es extremadamente eficiente porque replica solo los bloques que se han modificado o agregado desde la actualización anterior. SnapMirror se configura fácilmente mediante NetApp OnCommand® System Manager o la CLI de ONTAP . NetApp Disaster Recovery también crea la relación SnapMirror siempre que el emparejamiento de clúster y SVM esté configurado de antemano.
Para los casos en los que el almacenamiento principal no se pierde por completo, SnapMirror proporciona un medio eficiente para resincronizar los sitios primarios y de recuperación ante desastres. SnapMirror puede resincronizar los dos sitios, transfiriendo únicamente datos modificados o nuevos al sitio principal desde el sitio de recuperación ante desastres simplemente invirtiendo las relaciones de SnapMirror . Esto significa que los planes de replicación en NetApp Disaster Recovery se pueden resincronizar en cualquier dirección después de una conmutación por error sin tener que volver a copiar todo el volumen. Si una relación se vuelve a sincronizar en la dirección inversa, solo los datos nuevos que se escribieron desde la última sincronización exitosa de la copia de instantánea se envían de regreso al destino.

|
Si la relación SnapMirror ya está configurada para el volumen a través de CLI o System Manager, NetApp Disaster Recovery retoma la relación y continúa con el resto de las operaciones del flujo de trabajo. |
Cómo configurar relaciones de replicación para NetApp Disaster Recovery
El proceso subyacente para crear la replicación de SnapMirror sigue siendo el mismo para cualquier aplicación. La forma más sencilla es aprovechar NetApp Disaster Recovery , que automatizará el flujo de trabajo de replicación siempre que se cumplan los dos criterios siguientes: El proceso puede ser manual o automatizado. La forma más sencilla es aprovechar NetApp Disaster Recovery, que automatizará el flujo de trabajo de replicación siempre que se cumplan los dos criterios siguientes:
-
Los clústeres de origen y destino tienen una relación de pares.
-
El SVM de origen y el SVM de destino tienen una relación de pares.
NetApp Console también proporciona una opción alternativa para configurar la replicación de SnapMirror mediante un simple arrastrar y soltar del sistema ONTAP de origen en el entorno al destino para activar el asistente que lo guía a través del resto del proceso.
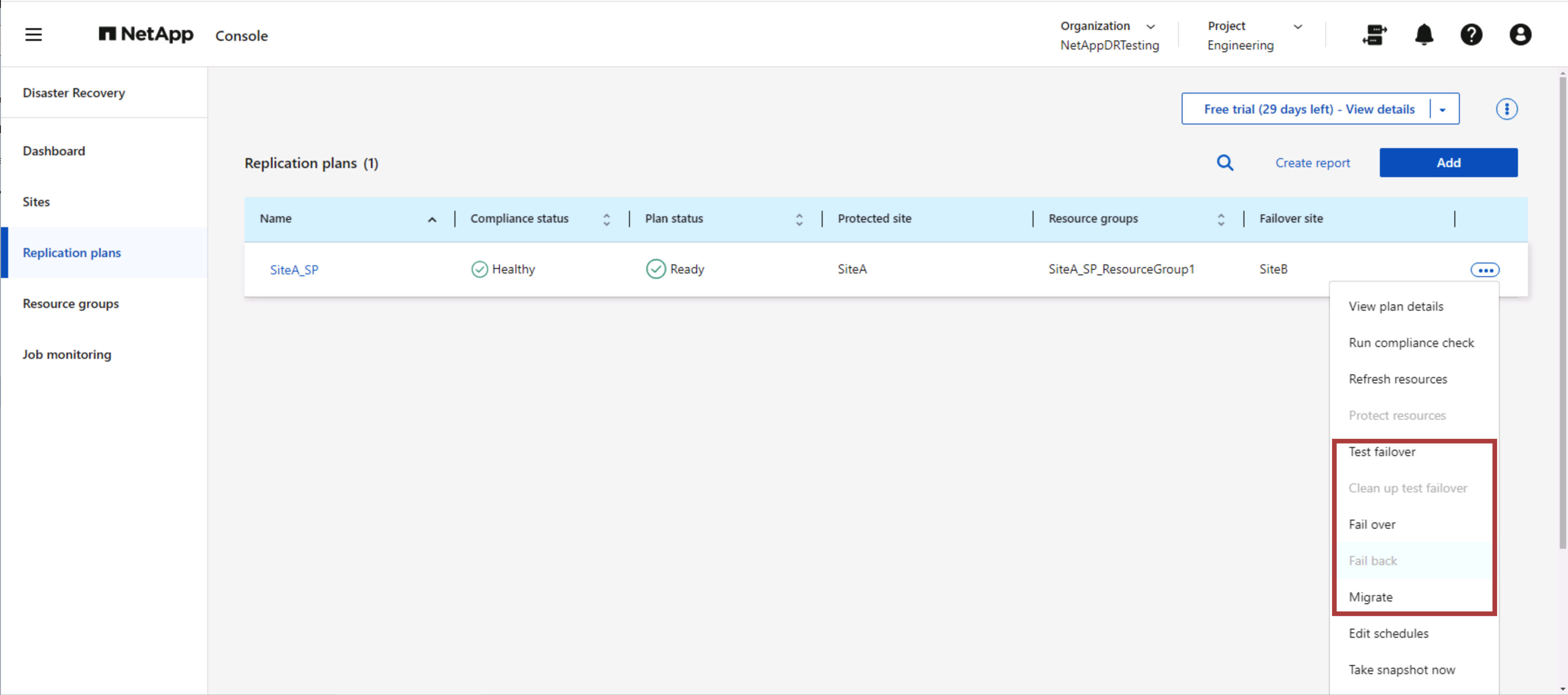
¿Qué puede hacer NetApp Disaster Recovery por usted?
Una vez agregados los sitios de origen y destino, NetApp Disaster Recovery realiza un descubrimiento profundo automático y muestra las máquinas virtuales junto con los metadatos asociados. NetApp Disaster Recovery también detecta automáticamente las redes y los grupos de puertos utilizados por las máquinas virtuales y los completa.
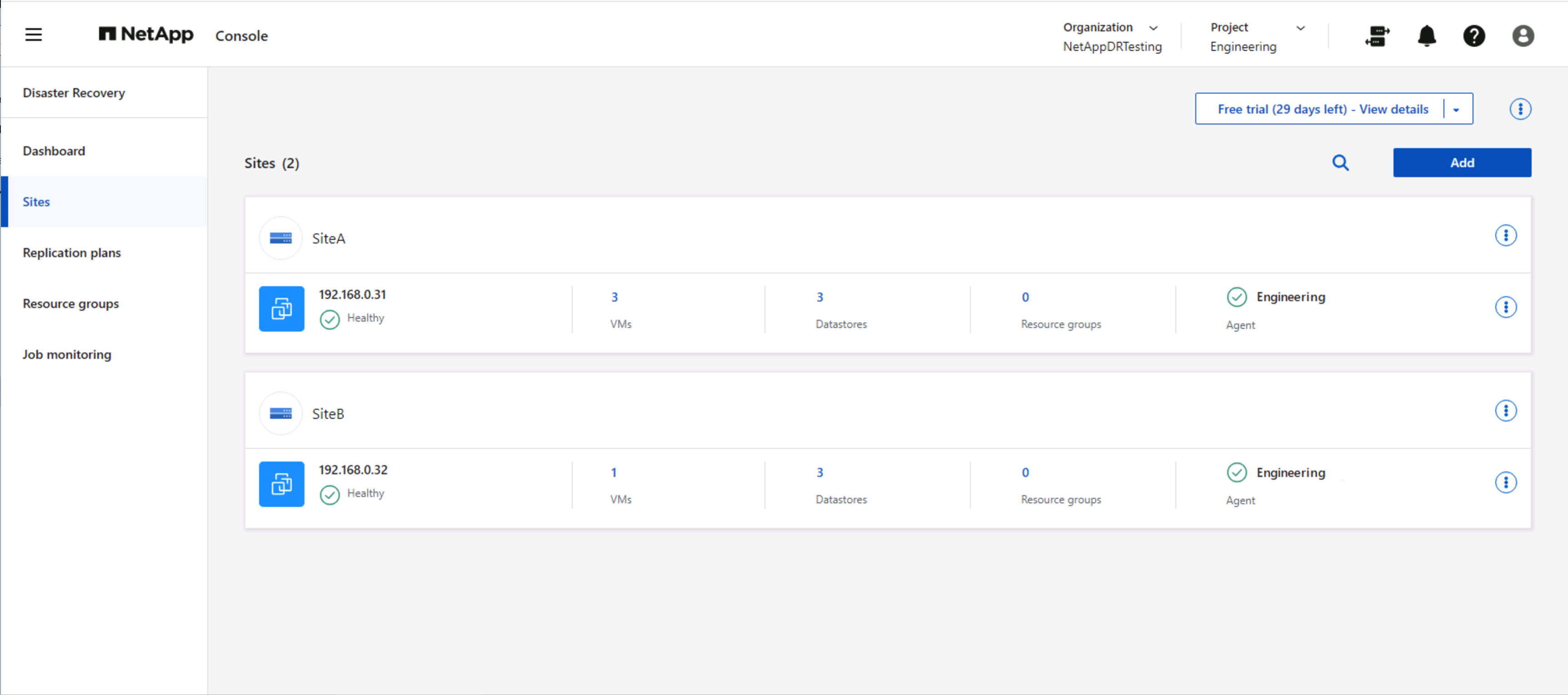
Una vez agregados los sitios, configure el plan de replicación seleccionando las plataformas vCenter de origen y destino y elija los grupos de recursos que se incluirán en el plan, junto con la agrupación de cómo se deben restaurar y encender las aplicaciones y el mapeo de clústeres y redes. Para definir el plan de recuperación, navegue a la pestaña Planes de replicación y haga clic en Agregar.
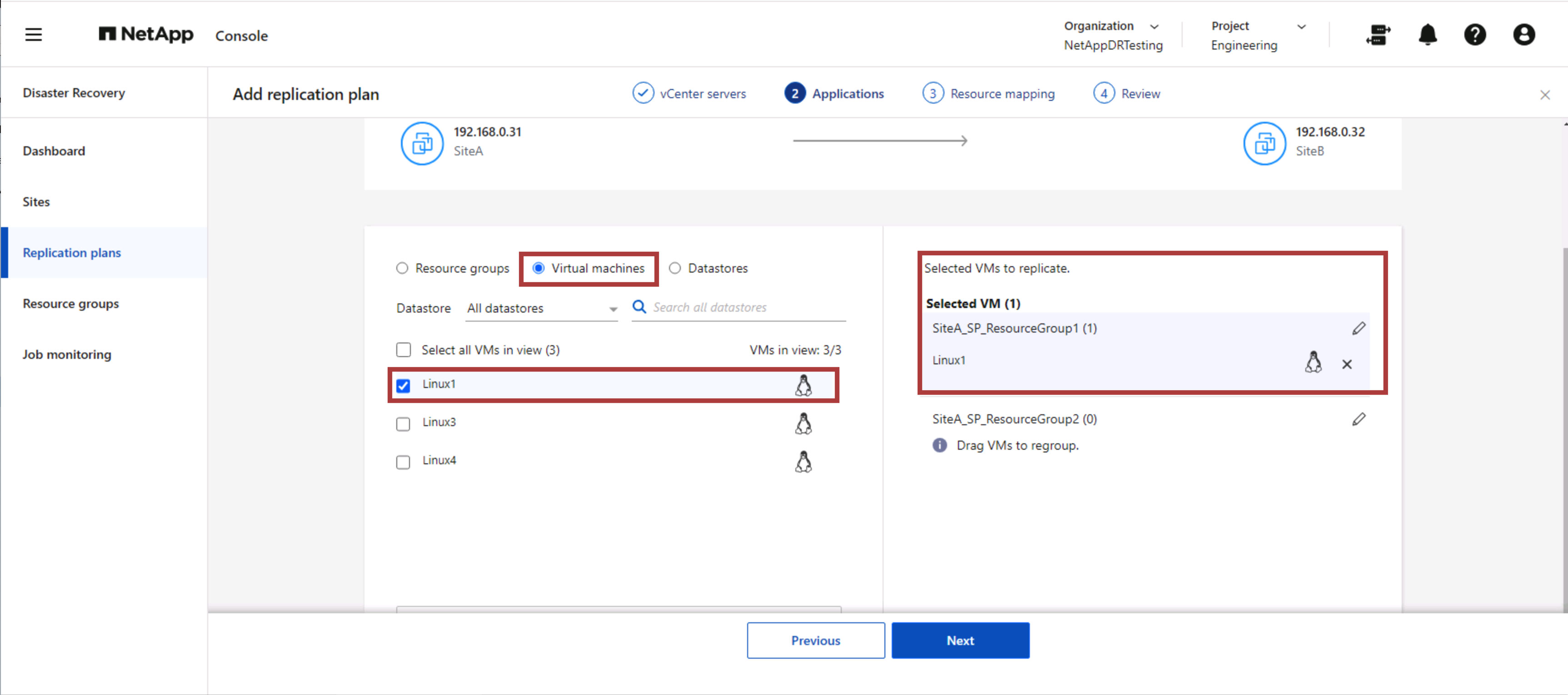
En este paso, las máquinas virtuales se pueden agrupar en grupos de recursos. Los grupos de recursos de NetApp Disaster Recovery le permiten agrupar un conjunto de máquinas virtuales dependientes en grupos lógicos que contienen sus órdenes de arranque y los retrasos de arranque que se pueden ejecutar durante la recuperación. Los grupos de recursos pueden existir durante la creación del plan de replicación o mediante la pestaña Grupo de recursos en la navegación izquierda.
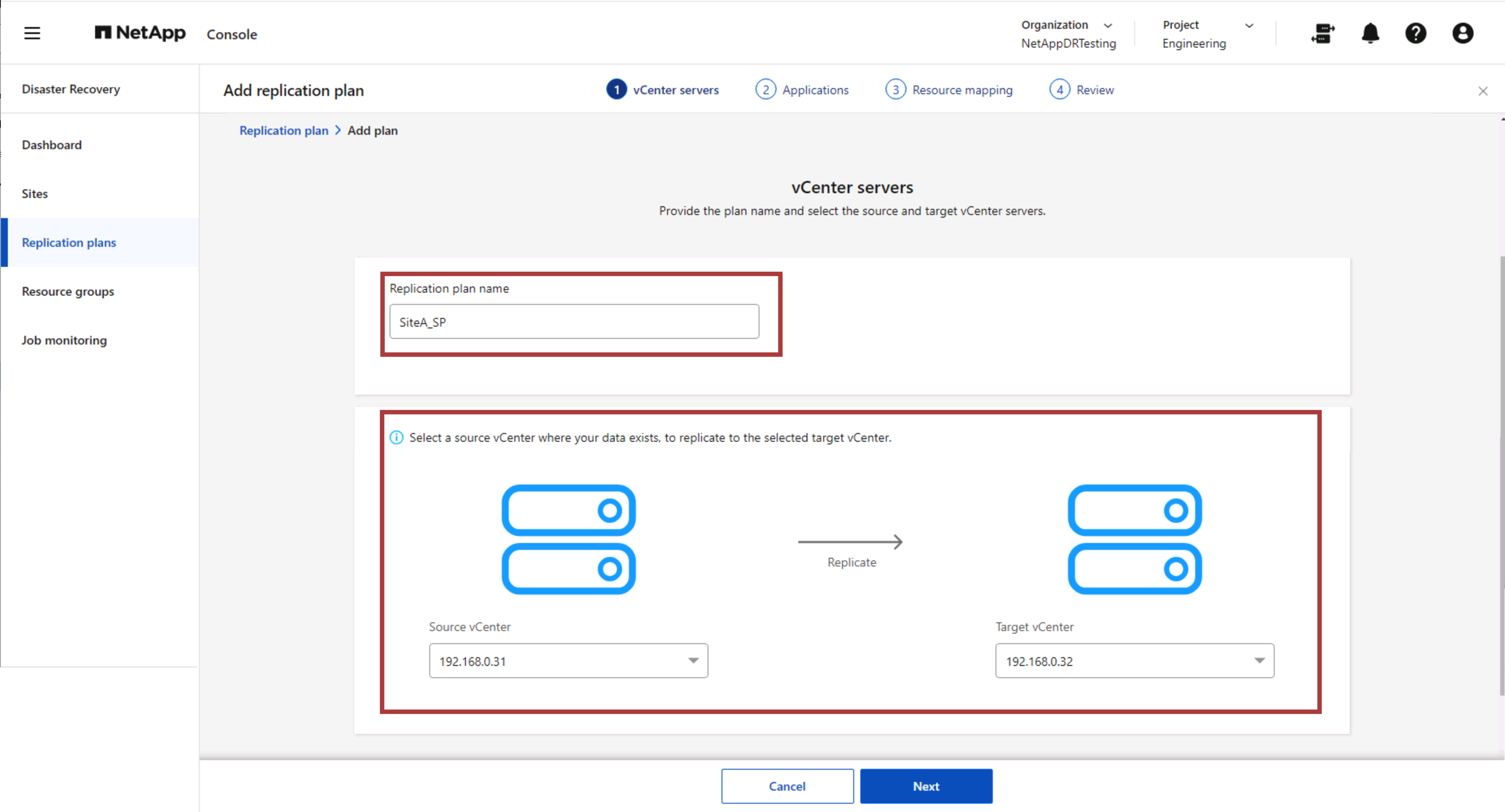
Primero, nombre el plan de replicación y seleccione el vCenter de origen y el vCenter de destino.
El siguiente paso es elegir si está creando un plan de replicación con grupos de recursos, máquinas virtuales o almacenes de datos. Seleccione un grupo de recursos existente y, si no se crea ningún grupo de recursos, el asistente ayuda a agrupar las máquinas virtuales necesarias (básicamente, crear grupos de recursos funcionales) en función de los objetivos de recuperación. Esto también ayuda a definir la secuencia de operaciones de cómo se deben restaurar las máquinas virtuales de la aplicación.
|
|
El grupo de recursos permite establecer el orden de arranque mediante la funcionalidad de arrastrar y soltar. Se puede utilizar para modificar fácilmente el orden en que se encenderán las máquinas virtuales durante el proceso de recuperación. |
Una vez creados los grupos de recursos a través del plan de replicación, el siguiente paso es crear la asignación para recuperar máquinas virtuales y aplicaciones en caso de desastre. En este paso, especifique cómo se asignan los recursos del entorno de origen al destino. Esto incluye recursos computacionales, redes virtuales, personalización de IP, scripts previos y posteriores, retrasos de arranque, consistencia de la aplicación, etc. Para obtener información detallada, consulte"Crear un plan de replicación" . Como se menciona en los requisitos previos, la replicación de SnapMirror se puede configurar de antemano o DRaaS puede configurarla utilizando el RPO y el recuento de retención especificados durante la creación del plan de replicación.
Nota: De forma predeterminada, se utilizan los mismos parámetros de asignación para las operaciones de prueba y de conmutación por error. Para configurar diferentes asignaciones para el entorno de prueba, seleccione la opción Asignación de prueba después de desmarcar la casilla de verificación “Usar las mismas asignaciones para conmutación por error y asignaciones de prueba”. Una vez completado el mapeo de recursos, haga clic en Siguiente.
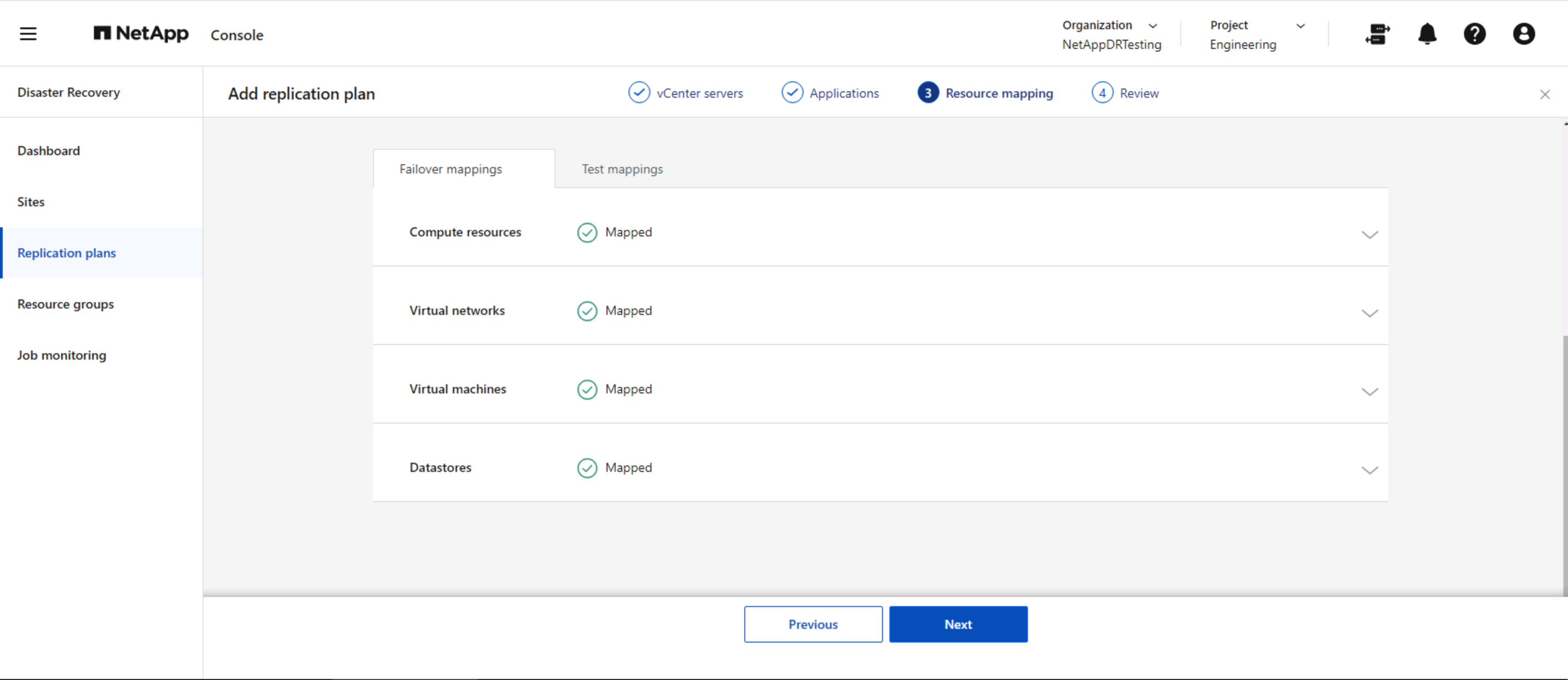
Una vez hecho esto, revise los mapeos creados y luego haga clic en Agregar plan.
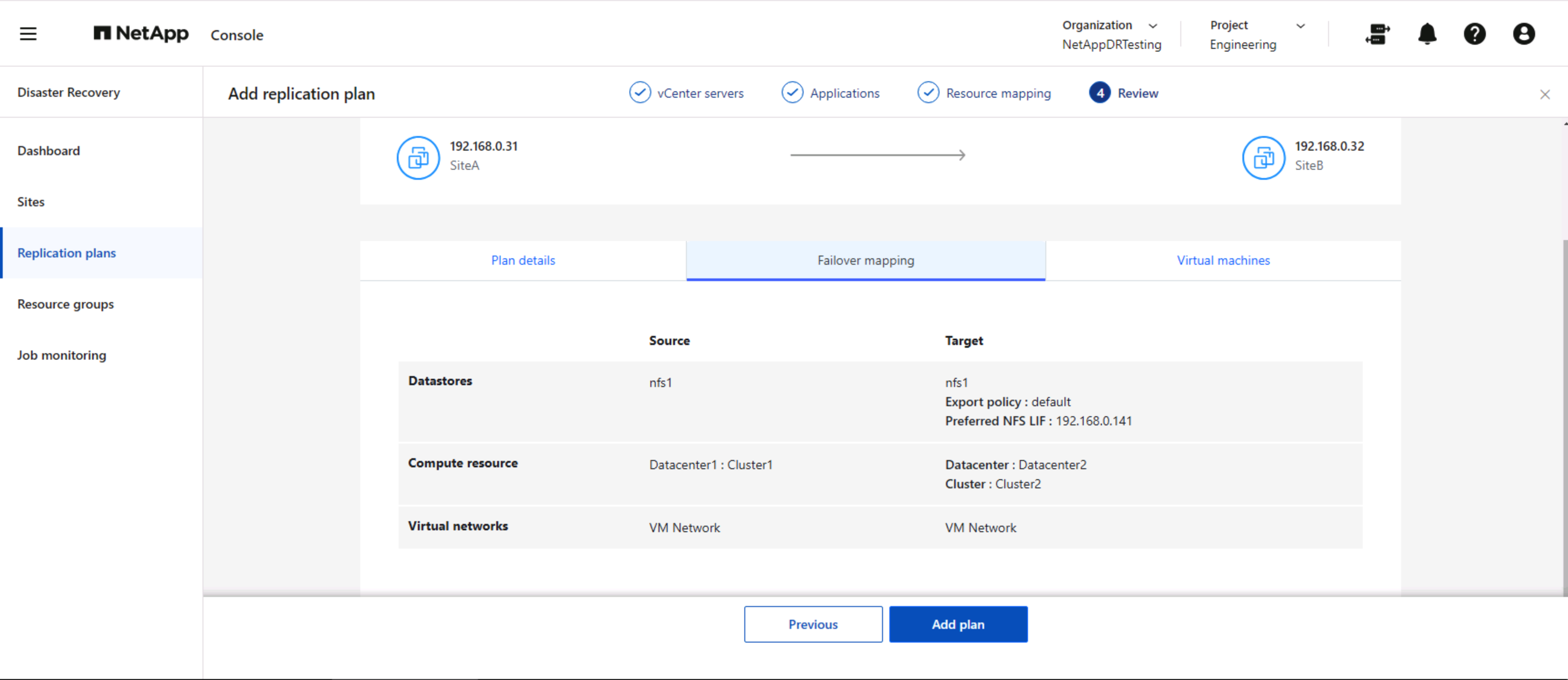
|
|
Se pueden incluir máquinas virtuales de diferentes volúmenes y SVM en un plan de replicación. Según la ubicación de la máquina virtual (ya sea en el mismo volumen o en un volumen separado dentro de la misma SVM, volúmenes separados en diferentes SVM), NetApp Disaster Recovery crea una instantánea del grupo de consistencia. |

Tan pronto como se crea el plan, se activan una serie de validaciones y se configuran la replicación y las programaciones de SnapMirror según la selección.
NetApp Disaster Recovery consta de los siguientes flujos de trabajo:
-
Conmutación por error de prueba (incluidas simulaciones automatizadas periódicas)
-
Prueba de conmutación por error de limpieza
-
Conmutación por error:
-
Migración planificada (ampliar el caso de uso para una conmutación por error única)
-
Recuperación ante desastres
-
-
Recuperación por recuperación
Prueba de conmutación por error
La conmutación por error de prueba en NetApp Disaster Recovery es un procedimiento operativo que permite a los administradores de VMware validar completamente sus planes de recuperación sin interrumpir sus entornos de producción.
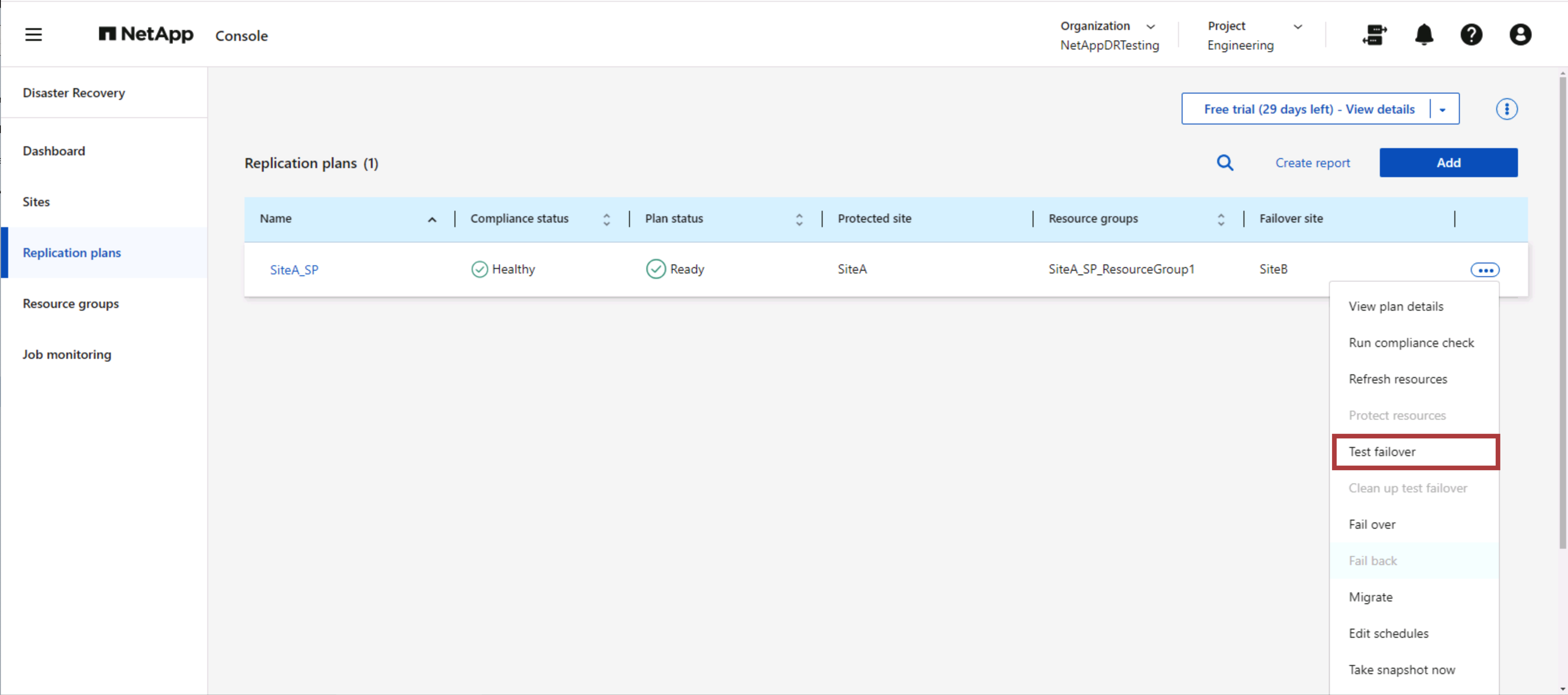
NetApp Disaster Recovery incorpora la capacidad de seleccionar la instantánea como una capacidad opcional en la operación de conmutación por error de prueba. Esta capacidad permite al administrador de VMware verificar que cualquier cambio realizado recientemente en el entorno se replique en el sitio de destino y, por lo tanto, esté presente durante la prueba. Estos cambios incluyen parches para el sistema operativo invitado de la máquina virtual.
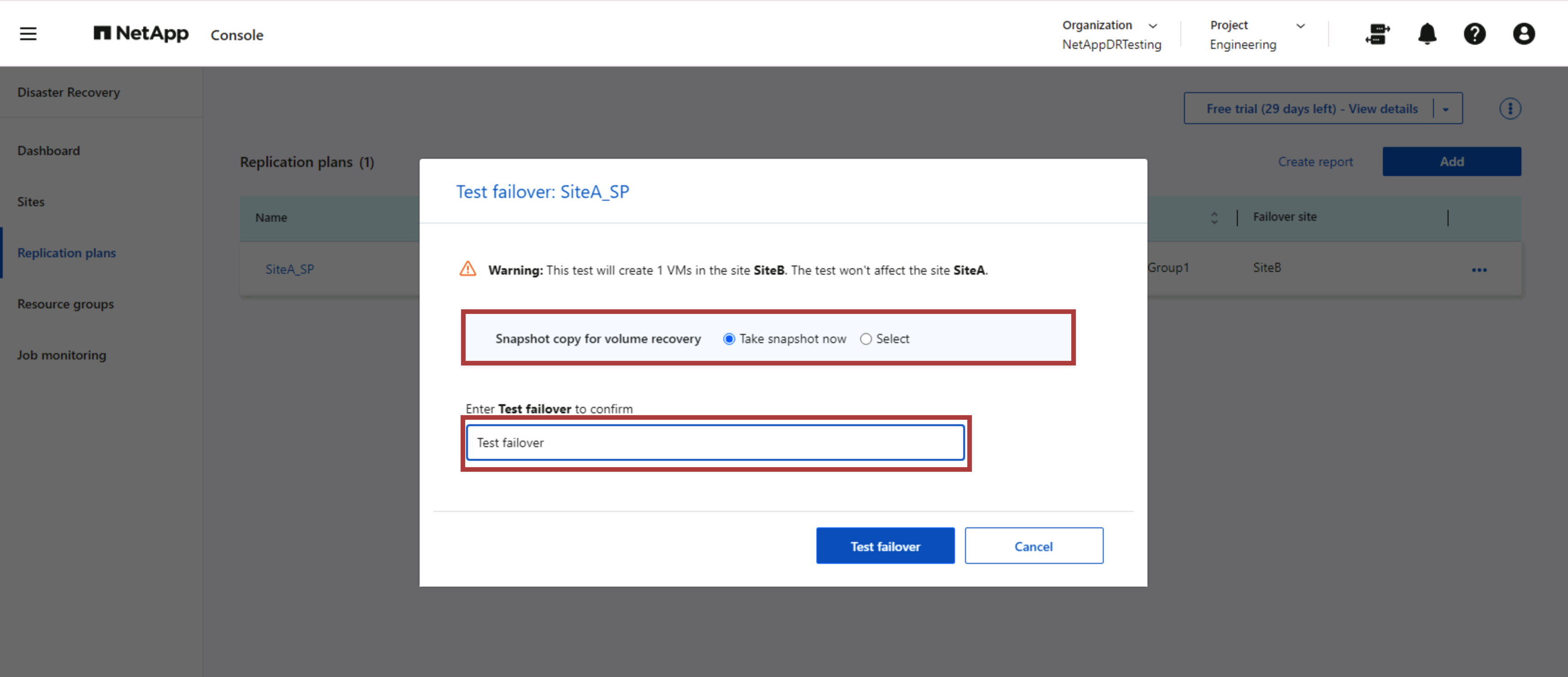
Cuando el administrador de VMware ejecuta una operación de conmutación por error de prueba, NetApp Disaster Recovery automatiza las siguientes tareas:
-
Activar relaciones de SnapMirror para actualizar el almacenamiento en el sitio de destino con cualquier cambio reciente que se haya realizado en el sitio de producción.
-
Creación de volúmenes NetApp FlexClone de los volúmenes FlexVol en la matriz de almacenamiento DR.
-
Conexión de los almacenes de datos en los volúmenes FlexClone a los hosts ESXi en el sitio de recuperación ante desastres.
-
Conectar los adaptadores de red de la máquina virtual a la red de prueba especificada durante la asignación.
-
Reconfigurar la configuración de red del sistema operativo invitado de la máquina virtual según lo definido para la red en el sitio de recuperación ante desastres.
-
Ejecutar cualquier comando personalizado que se haya almacenado en el plan de replicación.
-
Encender las máquinas virtuales en el orden definido en el plan de replicación.

Operación de prueba de conmutación por error de limpieza
La operación de prueba de conmutación por error de limpieza se produce después de que se haya completado la prueba del plan de replicación y el administrador de VMware responda al mensaje de limpieza.

Esta acción restablecerá las máquinas virtuales (VM) y el estado del plan de replicación al estado listo. Cuando el administrador de VMware realiza una operación de recuperación, NetApp Disaster Recovery completa el siguiente proceso:
-
Apaga cada VM recuperada en la copia FlexClone que se utilizó para la prueba.
-
Elimina el volumen FlexClone que se utilizó para presentar las máquinas virtuales recuperadas durante la prueba.
Migración planificada y conmutación por error
NetApp Disaster Recovery tiene dos métodos para realizar una conmutación por error real: migración planificada y conmutación por error. El primer método, la migración planificada, incorpora el apagado de la máquina virtual y la sincronización de la replicación del almacenamiento en el proceso para recuperar o mover eficazmente las máquinas virtuales al sitio de destino. La migración planificada requiere acceso al sitio de origen. El segundo método, conmutación por error, es una conmutación por error planificada/no planificada en la que las máquinas virtuales se recuperan en el sitio de destino desde el último intervalo de replicación de almacenamiento que pudo completarse. Dependiendo del RPO que se diseñó en la solución, se puede esperar cierta cantidad de pérdida de datos en el escenario de recuperación ante desastres.
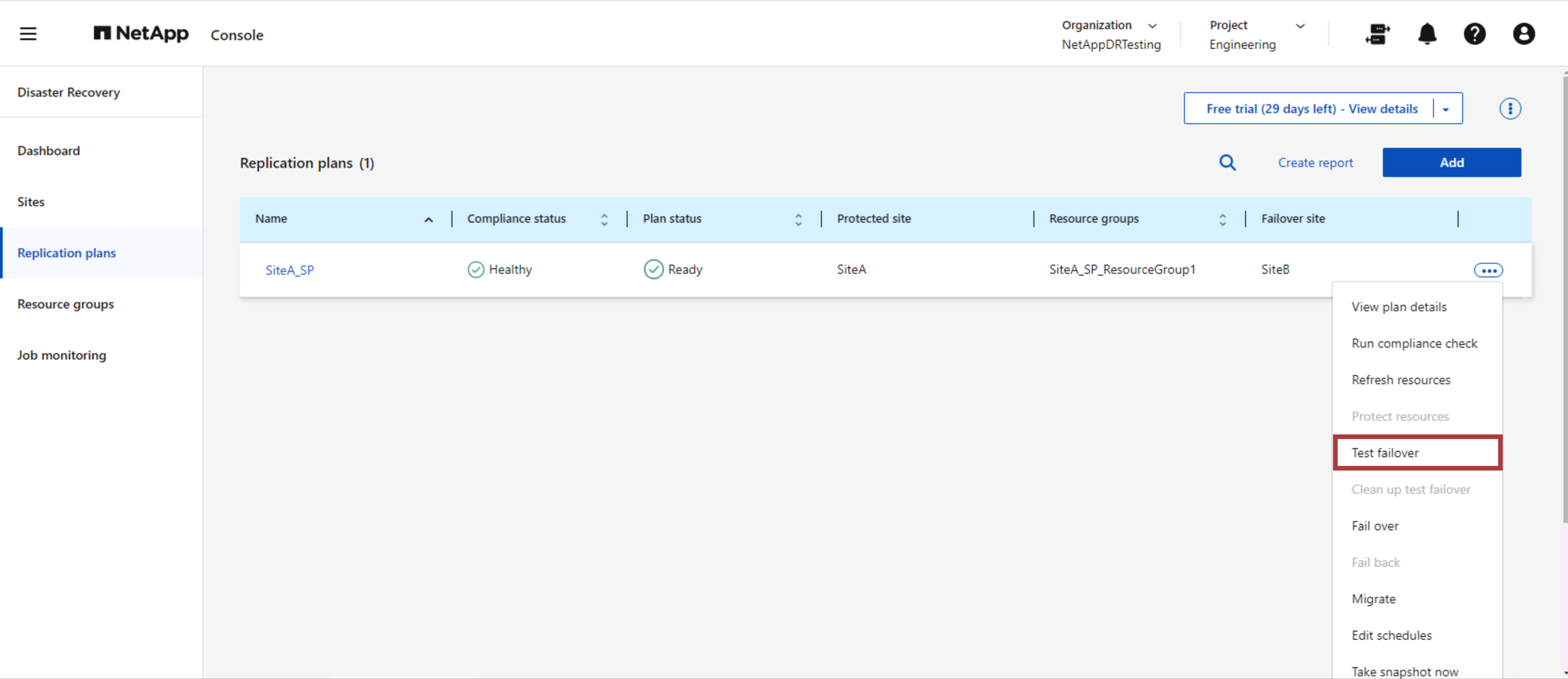
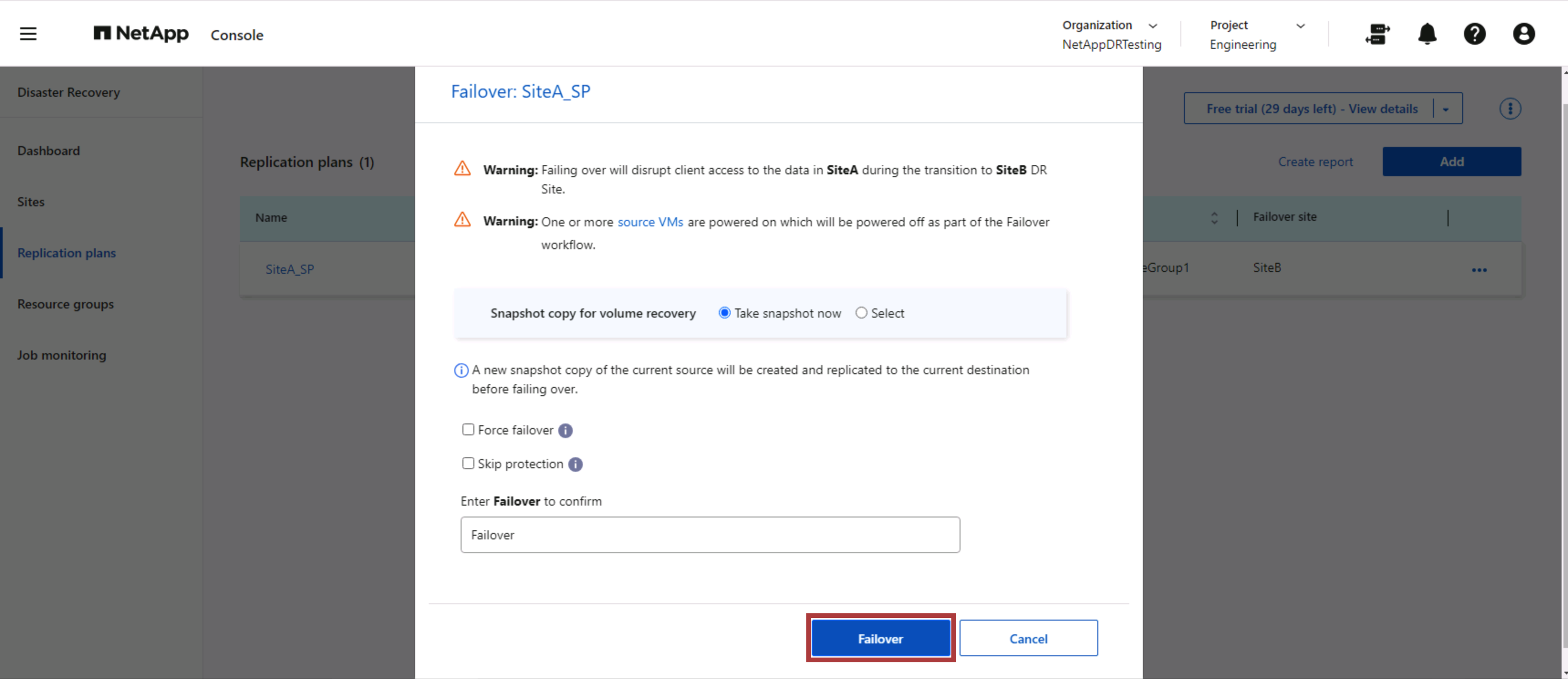
Cuando el administrador de VMware realiza una operación de conmutación por error, NetApp Disaster Recovery automatiza las siguientes tareas:
-
Romper y conmutar por error las relaciones de NetApp SnapMirror .
-
Conecte los almacenes de datos replicados a los hosts ESXi en el sitio de recuperación ante desastres.
-
Conecte los adaptadores de red de la máquina virtual a la red del sitio de destino apropiado.
-
Reconfigure la configuración de red del sistema operativo invitado de la máquina virtual según lo definido para la red en el sitio de destino.
-
Ejecute cualquier comando personalizado (si hay alguno) que se haya almacenado en el plan de replicación.
-
Encienda las máquinas virtuales en el orden definido en el plan de replicación.
Recuperación por recuperación
Una conmutación por recuperación es un procedimiento opcional que restaura la configuración original de los sitios de origen y destino después de una recuperación.
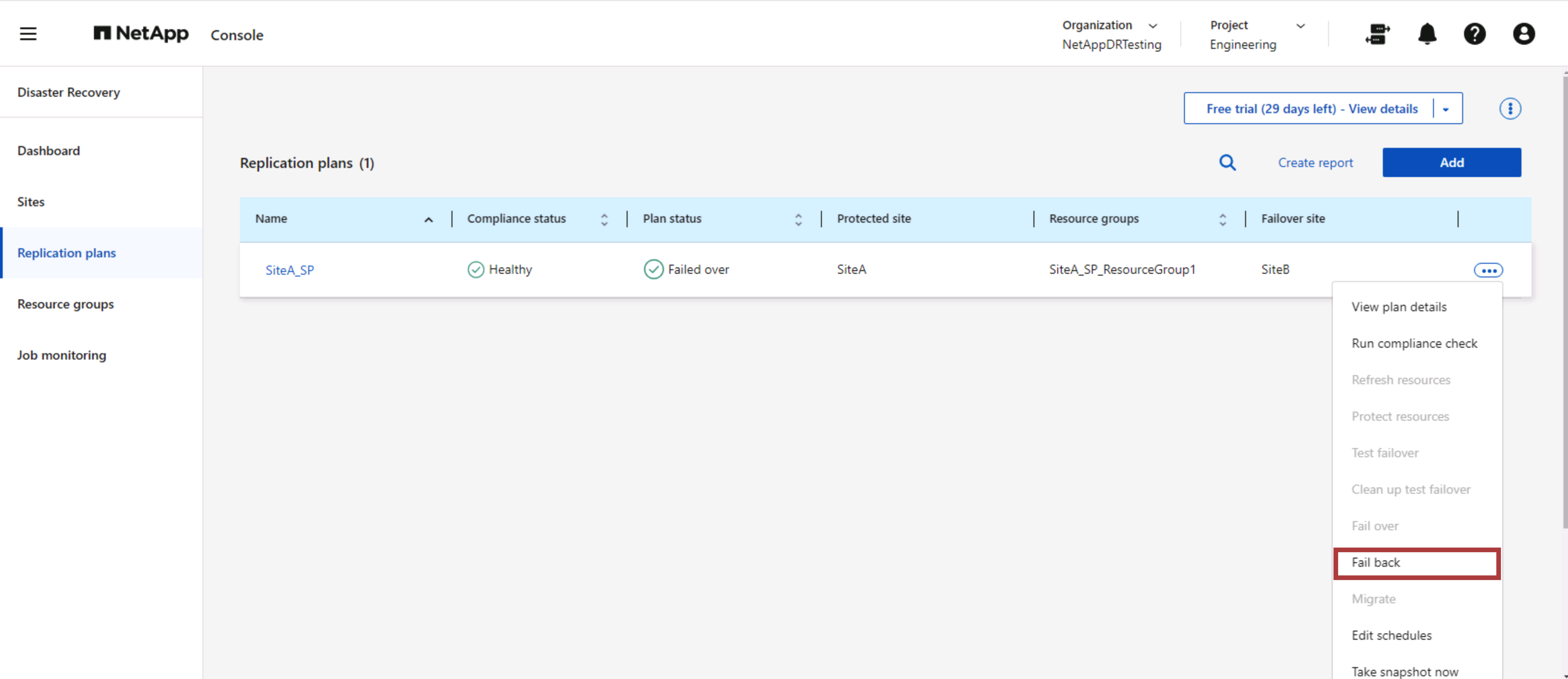
Los administradores de VMware pueden configurar y ejecutar un procedimiento de conmutación por error cuando estén listos para restaurar los servicios en el sitio de origen original.
|
|
NetApp Disaster Recovery replica (resincroniza) cualquier cambio en la máquina virtual de origen original antes de revertir la dirección de replicación. |
Este proceso comienza a partir de una relación que ha completado la conmutación por error a un destino e implica los siguientes pasos:
-
Apague y anule el registro de las máquinas virtuales y los volúmenes en el sitio de destino se desmontan.
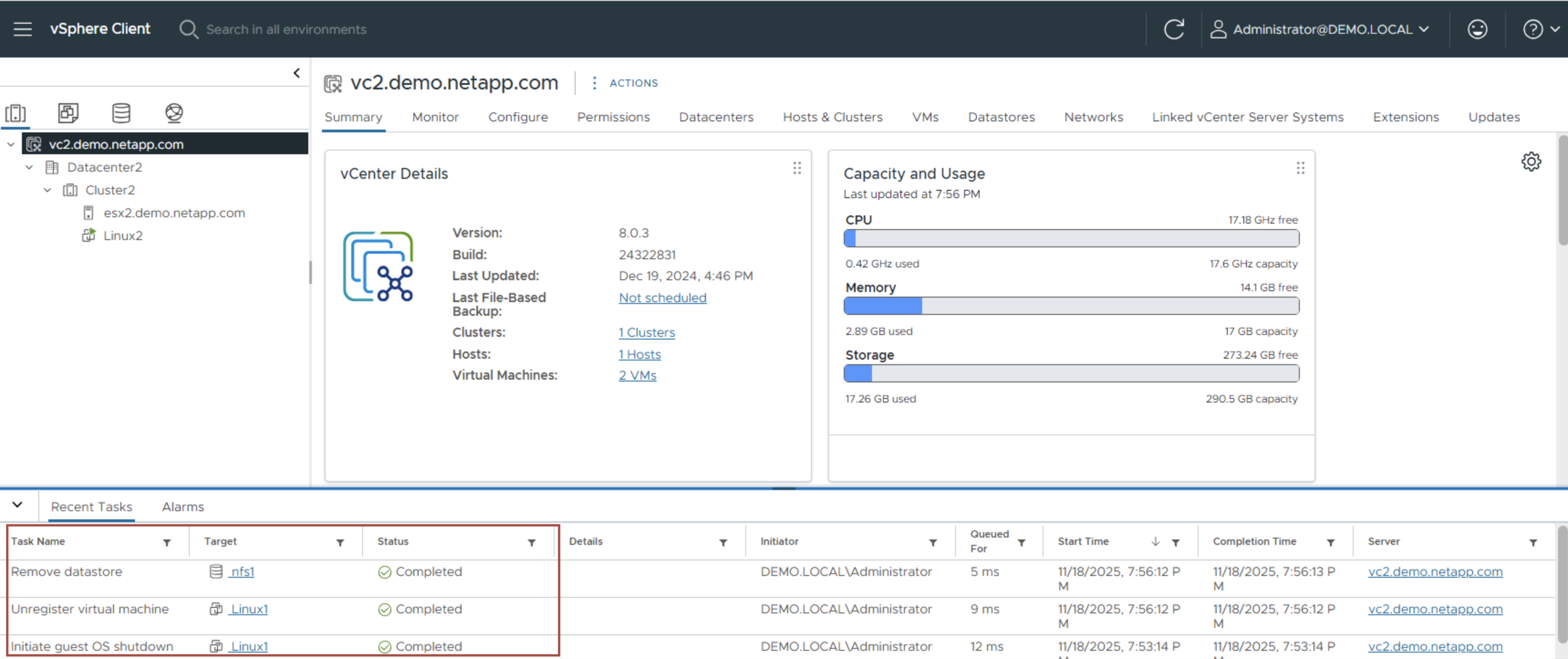
-
Romper la relación SnapMirror en la fuente original se rompe para hacerla de lectura/escritura.
-
Vuelva a sincronizar la relación SnapMirror para revertir la replicación.
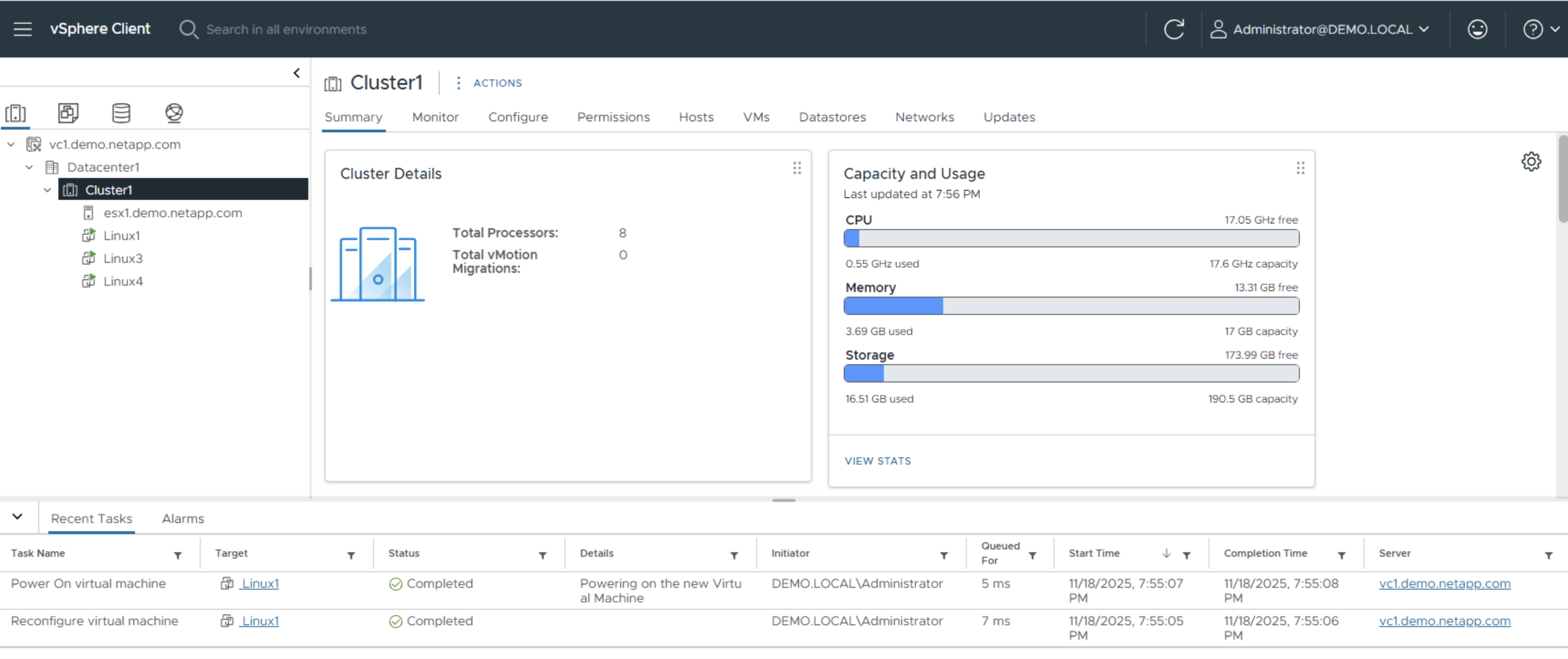
-
Monte el volumen en la fuente, encienda y registre las máquinas virtuales de origen.
Para obtener más detalles sobre cómo acceder y configurar NetApp Disaster Recovery, consulte la"Obtenga más información sobre NetApp Disaster Recovery para VMware" .
Monitoreo y tablero de control
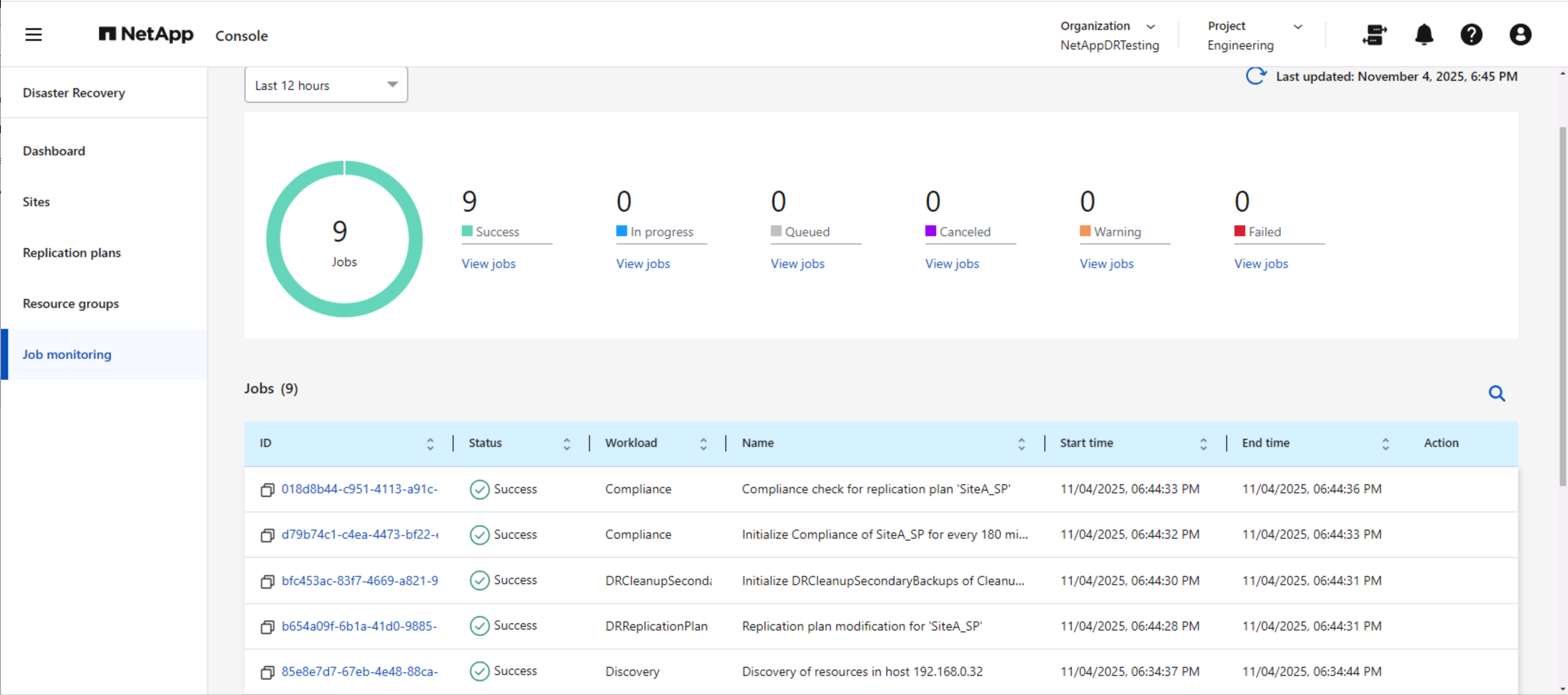
Desde NetApp Disaster Recovery o la CLI de ONTAP , puede supervisar el estado de salud de la replicación para los volúmenes de almacén de datos adecuados, y el estado de una conmutación por error o de una conmutación por error de prueba se puede rastrear a través de la Supervisión de trabajos.
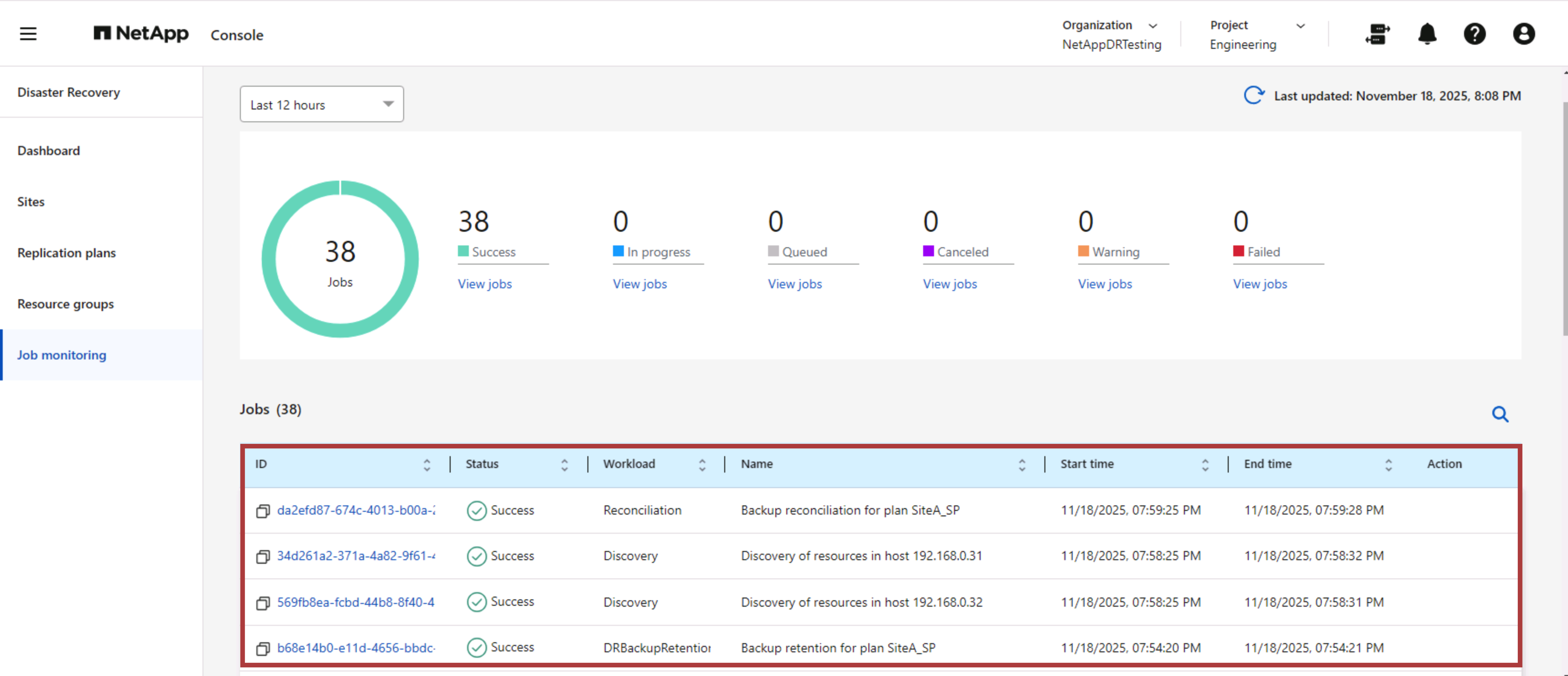
|
|
Si un trabajo está actualmente en progreso o en cola y desea detenerlo, existe una opción para cancelarlo. |
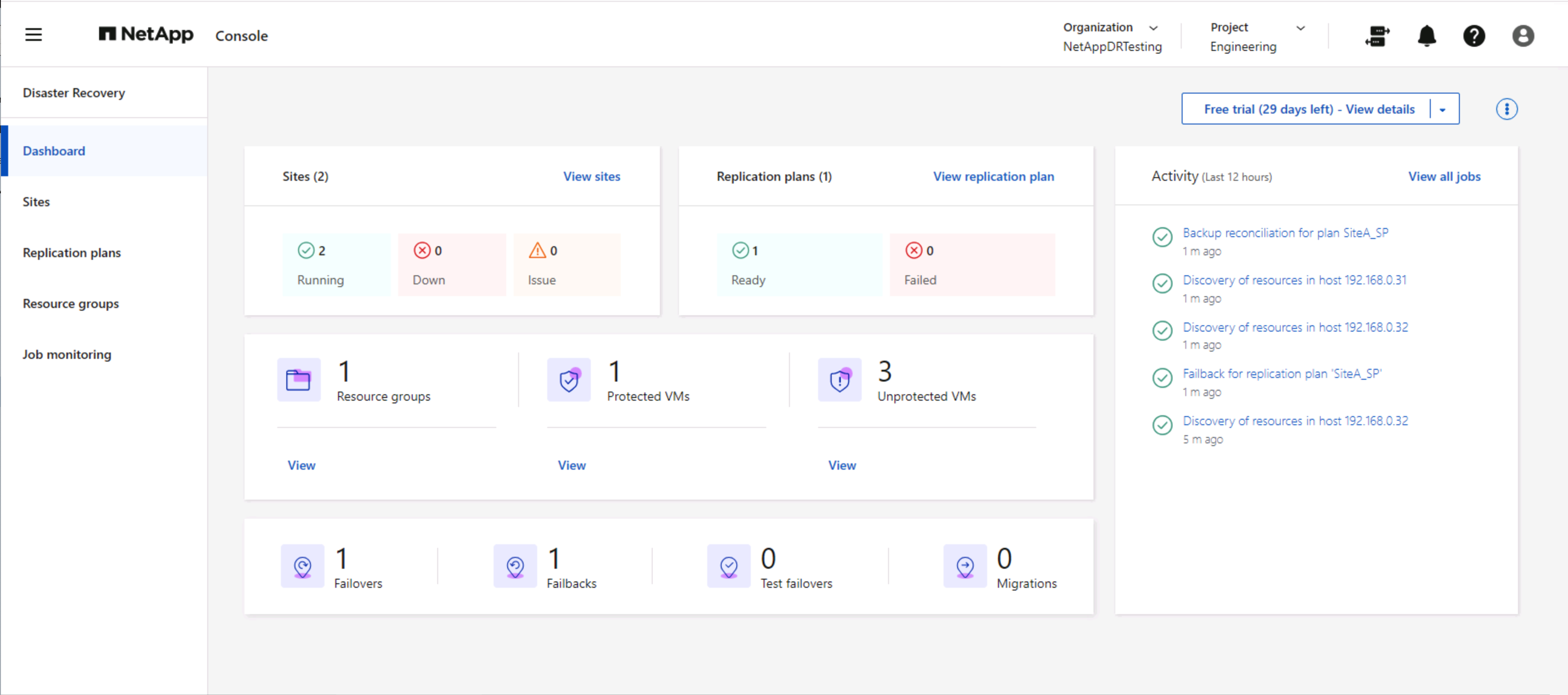
Con el panel de NetApp Disaster Recovery , evalúe con confianza el estado de los sitios de recuperación ante desastres y los planes de replicación. Esto permite a los administradores identificar rápidamente sitios y planes saludables, desconectados o degradados.
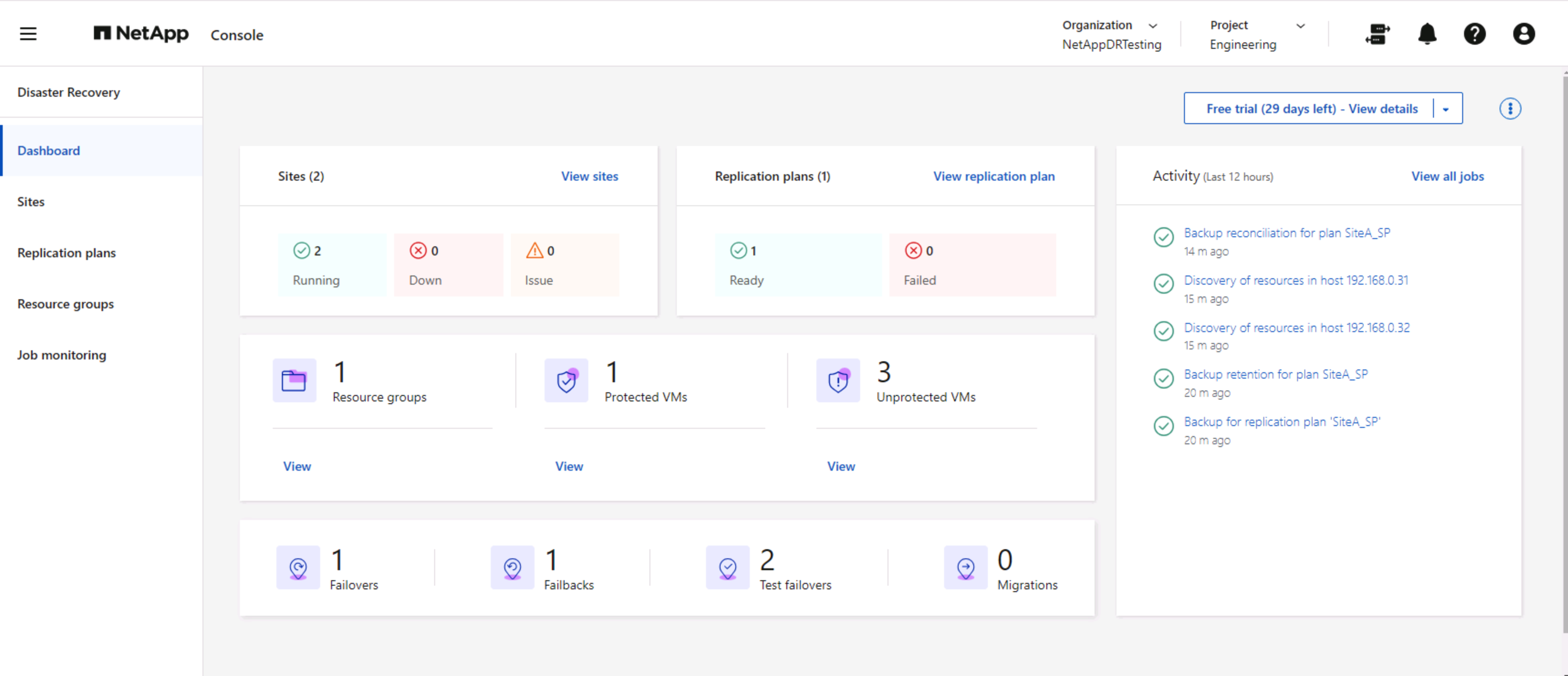
Esto proporciona una solución poderosa para gestionar un plan de recuperación ante desastres personalizado y adaptado. La conmutación por error se puede realizar de forma planificada o con solo hacer clic en un botón cuando ocurre un desastre y se toma la decisión de activar el sitio de recuperación ante desastres.