

Configurar clústeres ONTAP en una configuración IP de MetroCluster
 Sugerir cambios
Sugerir cambios
Debe configurar la paridad de los clústeres, reflejar los agregados raíz, crear un agregado de datos reflejados y, a continuación, emitir el comando para implementar las operaciones de MetroCluster.
Antes de correr metrocluster configure, El modo ha y la duplicación DR no están habilitados y puede que aparezca un mensaje de error relacionado con este comportamiento esperado. Habilite el modo de alta disponibilidad y la duplicación de recuperación ante desastres más adelante cuando ejecute el comando metrocluster configure para implementar la configuración.
Deshabilitación de la asignación automática de unidades (si se realiza la asignación manual en ONTAP 9.4)
En ONTAP 9.4, si la configuración IP de MetroCluster tiene menos de cuatro bandejas de almacenamiento externas por sitio, debe deshabilitar la asignación automática de unidades en todos los nodos y asignar manualmente unidades.
No es necesario realizar esta tarea en ONTAP 9.5 y versiones posteriores.
Esta tarea no se aplica a un sistema AFF A800 con una bandeja interna y sin bandejas externas.
-
Deshabilitar asignación automática de unidades:
storage disk option modify -node <node_name> -autoassign off -
Debe emitir este comando en todos los nodos de la configuración IP de MetroCluster.
Verificación de la asignación de unidades del pool 0 unidades
Debe verificar que las unidades remotas sean visibles para los nodos y que se hayan asignado correctamente.
La asignación automática depende del modelo de plataforma del sistema de almacenamiento y de la disposición de la bandeja de unidades.
-
Verifique que las unidades del pool 0 se asignen automáticamente:
disk showEn el siguiente ejemplo se muestra la salida "cluster_A" de un sistema AFF A800 sin bandejas externas.
Un cuarto (8 unidades) se asignaron automáticamente a "node_A_1" y un cuarto se asignaron automáticamente a "node_A_2". Las unidades restantes serán remotas (pool 1) para "node_B_1" y "node_B_2".
cluster_A::*> disk show Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_1:0n.12 1.75TB 0 12 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.13 1.75TB 0 13 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.14 1.75TB 0 14 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.15 1.75TB 0 15 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.16 1.75TB 0 16 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.17 1.75TB 0 17 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.18 1.75TB 0 18 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.19 1.75TB 0 19 SSD-NVM shared - node_A_1 node_A_2:0n.0 1.75TB 0 0 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.1 1.75TB 0 1 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.2 1.75TB 0 2 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.3 1.75TB 0 3 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.4 1.75TB 0 4 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.5 1.75TB 0 5 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.6 1.75TB 0 6 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.7 1.75TB 0 7 SSD-NVM shared - node_A_2 node_A_2:0n.24 - 0 24 SSD-NVM unassigned - - node_A_2:0n.25 - 0 25 SSD-NVM unassigned - - node_A_2:0n.26 - 0 26 SSD-NVM unassigned - - node_A_2:0n.27 - 0 27 SSD-NVM unassigned - - node_A_2:0n.28 - 0 28 SSD-NVM unassigned - - node_A_2:0n.29 - 0 29 SSD-NVM unassigned - - node_A_2:0n.30 - 0 30 SSD-NVM unassigned - - node_A_2:0n.31 - 0 31 SSD-NVM unassigned - - node_A_2:0n.36 - 0 36 SSD-NVM unassigned - - node_A_2:0n.37 - 0 37 SSD-NVM unassigned - - node_A_2:0n.38 - 0 38 SSD-NVM unassigned - - node_A_2:0n.39 - 0 39 SSD-NVM unassigned - - node_A_2:0n.40 - 0 40 SSD-NVM unassigned - - node_A_2:0n.41 - 0 41 SSD-NVM unassigned - - node_A_2:0n.42 - 0 42 SSD-NVM unassigned - - node_A_2:0n.43 - 0 43 SSD-NVM unassigned - - 32 entries were displayed.En el siguiente ejemplo se muestra la salida "cluster_B":
cluster_B::> disk show Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- Info: This cluster has partitioned disks. To get a complete list of spare disk capacity use "storage aggregate show-spare-disks". node_B_1:0n.12 1.75TB 0 12 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.13 1.75TB 0 13 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.14 1.75TB 0 14 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.15 1.75TB 0 15 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.16 1.75TB 0 16 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.17 1.75TB 0 17 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.18 1.75TB 0 18 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.19 1.75TB 0 19 SSD-NVM shared - node_B_1 node_B_2:0n.0 1.75TB 0 0 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.1 1.75TB 0 1 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.2 1.75TB 0 2 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.3 1.75TB 0 3 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.4 1.75TB 0 4 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.5 1.75TB 0 5 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.6 1.75TB 0 6 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.7 1.75TB 0 7 SSD-NVM shared - node_B_2 node_B_2:0n.24 - 0 24 SSD-NVM unassigned - - node_B_2:0n.25 - 0 25 SSD-NVM unassigned - - node_B_2:0n.26 - 0 26 SSD-NVM unassigned - - node_B_2:0n.27 - 0 27 SSD-NVM unassigned - - node_B_2:0n.28 - 0 28 SSD-NVM unassigned - - node_B_2:0n.29 - 0 29 SSD-NVM unassigned - - node_B_2:0n.30 - 0 30 SSD-NVM unassigned - - node_B_2:0n.31 - 0 31 SSD-NVM unassigned - - node_B_2:0n.36 - 0 36 SSD-NVM unassigned - - node_B_2:0n.37 - 0 37 SSD-NVM unassigned - - node_B_2:0n.38 - 0 38 SSD-NVM unassigned - - node_B_2:0n.39 - 0 39 SSD-NVM unassigned - - node_B_2:0n.40 - 0 40 SSD-NVM unassigned - - node_B_2:0n.41 - 0 41 SSD-NVM unassigned - - node_B_2:0n.42 - 0 42 SSD-NVM unassigned - - node_B_2:0n.43 - 0 43 SSD-NVM unassigned - - 32 entries were displayed. cluster_B::>
Una relación entre iguales de los clústeres
Los clústeres de la configuración de MetroCluster deben tener una relación entre iguales para que puedan comunicarse entre sí y realizar las operaciones de mirroring de datos esenciales para la recuperación ante desastres de MetroCluster.
"Configuración exprés de relación entre iguales de clústeres y SVM"
Configurar LIF de interconexión de clústeres para clústeres entre iguales
Debe crear LIF de interconexión de clústeres en puertos utilizados para la comunicación entre los clústeres de partners de MetroCluster. Puede utilizar puertos o puertos dedicados que también tengan tráfico de datos.
Configurar las LIF de interconexión de clústeres en puertos dedicados
Puede configurar LIF de interconexión de clústeres en puertos dedicados. Al hacerlo, normalmente aumenta el ancho de banda disponible para el tráfico de replicación.
-
Enumere los puertos del clúster:
network port showPara obtener una sintaxis de comando completa, consulte la página man.
En el siguiente ejemplo, se muestran los puertos de red en "cluster01":
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
Determine qué puertos están disponibles para dedicar a la comunicación entre clústeres:
network interface show -fields home-port,curr-portPara obtener una sintaxis de comando completa, consulte la página man.
En el siguiente ejemplo se muestra que no se han asignado LIF a los puertos "e0e" y "e0f":
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
Cree un grupo de recuperación tras fallos para los puertos dedicados:
network interface failover-groups create -vserver <system_svm> -failover-group <failover_group> -targets <physical_or_logical_ports>En el siguiente ejemplo se asignan los puertos "e0e" y" e0f" al grupo de recuperación tras fallos "intercluster01" en el sistema "SVMcluster01":
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
Compruebe que el grupo de recuperación tras fallos se ha creado:
network interface failover-groups showPara obtener una sintaxis de comando completa, consulte la página man.
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
Cree LIF de interconexión de clústeres en la SVM del sistema y asígnelas al grupo de recuperación tras fallos.
En ONTAP 9,6 y versiones posteriores, ejecute:network interface create -vserver <system_svm> -lif <lif_name> -service-policy default-intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask_address> -failover-group <failover_group>En ONTAP 9,5 y versiones anteriores, ejecute:network interface create -vserver <system_svm> -lif <lif_name> -role intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask_address> -failover-group <failover_group>Para obtener una sintaxis de comando completa, consulte la página man.
En el siguiente ejemplo se crean las LIF de interconexión de clústeres "cluster01_icl01" y "cluster01_icl02" en el grupo de conmutación por error "intercluster01":
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
Compruebe que se han creado las LIF de interconexión de clústeres:
En ONTAP 9,6 y versiones posteriores, ejecute:network interface show -service-policy default-interclusterEn ONTAP 9,5 y versiones anteriores, ejecute:network interface show -role interclusterPara obtener una sintaxis de comando completa, consulte la página man.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
Compruebe que las LIF de interconexión de clústeres son redundantes:
En ONTAP 9,6 y versiones posteriores, ejecute:network interface show -service-policy default-intercluster -failoverEn ONTAP 9,5 y versiones anteriores, ejecute:network interface show -role intercluster -failoverPara obtener una sintaxis de comando completa, consulte la página man.
En el siguiente ejemplo, se muestra que las LIF de interconexión de clústeres "cluster01_icl01" y "cluster01_icl02" en el puerto "SVMe0e" conmutarán al puerto "e0f".
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
"Consideraciones que tener en cuenta al utilizar puertos dedicados"
Configurar las LIF de interconexión de clústeres en puertos de datos compartidos
Las LIF de interconexión de clústeres se pueden configurar en los puertos compartidos con la red de datos. De este modo, se reduce el número de puertos necesarios para interconectar redes.
-
Enumere los puertos del clúster:
network port showPara obtener una sintaxis de comando completa, consulte la página man.
En el siguiente ejemplo, se muestran los puertos de red en "cluster01":
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
Crear LIF de interconexión de clústeres en la SVM del sistema:
En ONTAP 9,6 y versiones posteriores, ejecute:network interface create -vserver <system_svm> -lif <lif_name> -service-policy default-intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask>En ONTAP 9,5 y versiones anteriores, ejecute:network interface create -vserver <system_svm> -lif <lif_name> -role intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask>Para obtener una sintaxis de comando completa, consulte la página man.
En el siguiente ejemplo se crean las LIF de interconexión de clústeres "cluster01_icl01" y "cluster01_icl02":
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
Compruebe que se han creado las LIF de interconexión de clústeres:
En ONTAP 9,6 y versiones posteriores, ejecute:network interface show -service-policy default-interclusterEn ONTAP 9,5 y versiones anteriores, ejecute:network interface show -role interclusterPara obtener una sintaxis de comando completa, consulte la página man.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
Compruebe que las LIF de interconexión de clústeres son redundantes:
En ONTAP 9,6 y versiones posteriores, ejecute:network interface show –service-policy default-intercluster -failoverEn ONTAP 9,5 y versiones anteriores, ejecute:network interface show -role intercluster -failoverPara obtener una sintaxis de comando completa, consulte la página man.
En el siguiente ejemplo, se muestra que las LIF de interconexión de clústeres "cluster01_icl01" y "cluster01_icl02" en el puerto "e0c" conmutarán al puerto "e0d".
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
"Consideraciones que tener en cuenta al compartir puertos de datos"
Creación de una relación de paridad entre clústeres
Puede usar el comando cluster peer create para crear una relación entre iguales entre un clúster local y remoto. Después de crear la relación entre iguales, puede ejecutar la creación entre iguales de clústeres en el clúster remoto para autenticarla en el clúster local.
-
Debe haber creado LIF de interconexión de clústeres en todos los nodos de los clústeres que se están interponiendo.
-
Los clústeres deben ejecutar ONTAP 9.3 o una versión posterior.
-
En el clúster de destino, cree una relación entre iguales con el clúster de origen:
cluster peer create -generate-passphrase -offer-expiration <MM/DD/YYYY HH:MM:SS|1…7days|1…168hours> -peer-addrs <peer_lif_ip_addresses> -ipspace <ipspace>Si especifica ambas
-generate-passphrasey..-peer-addrs, Sólo el clúster cuyas LIF de interconexión de clústeres se especifican en-peer-addrspuede utilizar la contraseña generada.Puede ignorar la
-ipspaceSi no está utilizando un espacio IP personalizado. Para obtener una sintaxis de comando completa, consulte la página man.En el siguiente ejemplo se crea una relación de paridad de clústeres en un clúster remoto no especificado:
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
En el clúster de origen, autentique el clúster de origen con el clúster de destino:
cluster peer create -peer-addrs <peer_lif_ip_addresses> -ipspace <ipspace>Para obtener una sintaxis de comando completa, consulte la página man.
En el siguiente ejemplo se autentica el clúster local en el clúster remoto en las direcciones IP de LIF entre clústeres "192.140.112.101" y "192.140.112.102":
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.Introduzca la frase de acceso para la relación entre iguales cuando se le solicite.
-
Compruebe que se ha creado la relación de paridad entre clústeres:
cluster peer show -instancecluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Cluster UUID: b07036f2-7d1c-11f0-bedb-d039ea48b059 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster02 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Remote Cluster Nodes: cluster02-01, cluster02-02, Remote Cluster Health: true Unreachable Local Nodes: - Operation Timeout (seconds): 60 Address Family of Relationship: ipv4 Authentication Status Administrative: use-authentication Authentication Status Operational: ok Timeout for RPC Connect: 10 Timeout for Update Pings: 5 Last Update Time: 10/9/2025 10:15:29 IPspace for the Relationship: Default Proposed Setting for Encryption of Inter-Cluster Communication: - Encryption Protocol For Inter-Cluster Communication: tls-psk Algorithm By Which the PSK Was Derived: jpake -
Compruebe la conectividad y el estado de los nodos en la relación de paridad:
cluster peer health showcluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
Creando el grupo DR
Debe crear las relaciones del grupo de recuperación de desastres (DR) entre los clústeres.
Este procedimiento se debe realizar en uno de los clústeres de la configuración de MetroCluster para crear las relaciones de recuperación ante desastres entre los nodos de ambos clústeres.

|
Las relaciones de recuperación ante desastres no se pueden cambiar una vez que se han creado los grupos de recuperación ante desastres. |
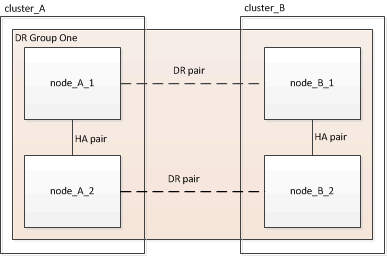
-
Compruebe que los nodos están listos para la creación del grupo de recuperación ante desastres introduciendo el siguiente comando en cada nodo:
metrocluster configuration-settings show-statusEl resultado del comando debería mostrar que los nodos están listos:
cluster_A::> metrocluster configuration-settings show-status Cluster Node Configuration Settings Status -------------------------- ------------- -------------------------------- cluster_A node_A_1 ready for DR group create node_A_2 ready for DR group create 2 entries were displayed.cluster_B::> metrocluster configuration-settings show-status Cluster Node Configuration Settings Status -------------------------- ------------- -------------------------------- cluster_B node_B_1 ready for DR group create node_B_2 ready for DR group create 2 entries were displayed. -
Cree el grupo DR:
metrocluster configuration-settings dr-group create -partner-cluster <partner_cluster_name> -local-node <local_node_name> -remote-node <remote_node_name>Este comando se emite una sola vez. No es necesario que se repita en el clúster de partners. En el comando, debe especificar el nombre del clúster remoto y el nombre de un nodo local y un nodo en el clúster de compañero.
Los dos nodos que especifique están configurados como partners de recuperación ante desastres y los otros dos nodos (que no se especifican en el comando) se configuran como la segunda pareja de recuperación ante desastres del grupo de recuperación ante desastres. Estas relaciones no se pueden cambiar después de introducir este comando.
El siguiente comando crea estas parejas de recuperación ante desastres:
-
Node_A_1 y Node_B_1
-
Node_A_2 y Node_B_2
Cluster_A::> metrocluster configuration-settings dr-group create -partner-cluster cluster_B -local-node node_A_1 -remote-node node_B_1 [Job 27] Job succeeded: DR Group Create is successful.
-
Configurar y conectar las interfaces MetroCluster IP
Debe configurar las interfaces IP de MetroCluster que se usan para replicar el almacenamiento de cada nodo y la caché no volátil. A continuación, establezca las conexiones mediante las interfaces IP de MetroCluster. Esto crea conexiones iSCSI para la replicación del almacenamiento.
|
|
Los puertos IP de MetroCluster y switch conectados no se conectan hasta que se han creado las interfaces IP de MetroCluster. |
-
Debe crear dos interfaces para cada nodo. Las interfaces deben estar asociadas a las VLAN definidas en el archivo MetroCluster RCF.
-
Debe crear todos los puertos de interfaz IP "A" de MetroCluster en la misma VLAN y todos los puertos de interfaz IP de MetroCluster "B" en la otra VLAN. Consulte "Consideraciones sobre la configuración de IP de MetroCluster".
-
A partir de ONTAP 9.9.1, si utiliza una configuración de capa 3, también debe especificar el
-gatewayAl crear interfaces IP de MetroCluster. Consulte "Consideraciones sobre las redes de área amplia de capa 3".Algunas plataformas utilizan una VLAN para la interfaz de IP de MetroCluster. De manera predeterminada, cada uno de los dos puertos utiliza una VLAN diferente: 10 y 20.
Si es compatible, también puede especificar una VLAN diferente (no predeterminada) superior a 100 (entre 101 y 4095) con el
-vlan-idparámetro delmetrocluster configuration-settings interface createcomando.Las siguientes plataformas no soportan el
-vlan-idparámetro:-
FAS8200 y AFF A300
-
AFF A320
-
FAS9000 y AFF A700
-
AFF C800, ASA C800, AFF A800 y ASA A800
Todas las demás plataformas admiten
-vlan-idel parámetro.Las asignaciones de VLAN predeterminadas y válidas dependen de si la plataforma admite el
-vlan-idparámetro:
Plataformas compatibles con <code>-vlan-id</code>VLAN predeterminada:
-
Cuando no se especifica el
-vlan-idparámetro, las interfaces se crean con VLAN 10 para los puertos “A” y VLAN 20 para los puertos “B”. -
La VLAN especificada debe coincidir con la VLAN seleccionada en el RCF.
Rangos de VLAN válidos:
-
VLAN predeterminada 10 y 20
-
VLAN 101 y superior (entre 101 y 4095)
Plataformas que no admiten <code>-vlan-id</code>VLAN predeterminada:
-
No aplicable La interfaz no requiere que se especifique una VLAN en la interfaz de MetroCluster. El puerto del switch define la VLAN que se usa.
Rangos de VLAN válidos:
-
Todas las VLAN no se excluyen explícitamente al generar el RCF. La RCF le avisa si la VLAN no es válida.
-
-
Los puertos físicos utilizados por las interfaces IP de MetroCluster dependen del modelo de plataforma. Consulte "Conecte los cables de los switches IP de MetroCluster" para conocer el uso del puerto para el sistema.
-
Las siguientes direcciones IP y subredes se usan en los ejemplos:
Nodo
Interfaz
Dirección IP
Subred
Node_a_1
Interfaz IP de MetroCluster 1
10.1.1.1
10.1.1/24
Interfaz IP de MetroCluster 2
10.1.2.1
10.1.2/24
Node_A_2
Interfaz IP de MetroCluster 1
10.1.1.2
10.1.1/24
Interfaz IP de MetroCluster 2
10.1.2.2
10.1.2/24
Node_B_1
Interfaz IP de MetroCluster 1
10.1.1.3
10.1.1/24
Interfaz IP de MetroCluster 2
10.1.2.3
10.1.2/24
Node_B_2
Interfaz IP de MetroCluster 1
10.1.1.4
10.1.1/24
Interfaz IP de MetroCluster 2
10.1.2.4
10.1.2/24
-
Este procedimiento utiliza los siguientes ejemplos:
Los puertos para un sistema AFF A700 o FAS9000 (e5a y e5b).
Los puertos de un sistema AFF A220 para mostrar cómo usar
-vlan-idel parámetro en una plataforma compatible.Configure las interfaces en los puertos correctos para el modelo de plataforma.
-
Confirme que cada nodo tiene habilitada la asignación automática de discos:
storage disk option showLa asignación automática de discos asignará discos de pool 0 y pool 1 a bandeja.
La columna asignación automática indica si la asignación automática de discos está habilitada.
Node BKg. FW. Upd. Auto Copy Auto Assign Auto Assign Policy ---------- ------------- ---------- ----------- ------------------ node_A_1 on on on default node_A_2 on on on default 2 entries were displayed.
-
Compruebe que puede crear interfaces IP de MetroCluster en los nodos:
metrocluster configuration-settings show-statusTodos los nodos deben estar listos:
Cluster Node Configuration Settings Status ---------- ----------- --------------------------------- cluster_A node_A_1 ready for interface create node_A_2 ready for interface create cluster_B node_B_1 ready for interface create node_B_2 ready for interface create 4 entries were displayed. -
Cree las interfaces en node_A_1.
-
Configure la interfaz en el puerto "e5a" en "node_A_1":

No utilice las direcciones IP 169.254.17.x o 169.254.18.x al crear interfaces IP de MetroCluster para evitar conflictos con las direcciones IP de interfaz generadas automáticamente del sistema en el mismo rango. metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5a -address <ip_address> -netmask <netmask>En el ejemplo siguiente se muestra la creación de la interfaz en el puerto "e5a" en "node_A_1" con la dirección IP "10.1.1.1":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_1 -home-port e5a -address 10.1.1.1 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
En los modelos de plataforma que admiten VLAN para la interfaz IP de MetroCluster, se puede incluir el
-vlan-idSi no desea usar los identificadores de VLAN predeterminados. En el siguiente ejemplo, se muestra el comando para un sistema AFF A220 con un ID de VLAN de 120:cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2 -home-port e0a -address 10.1.1.2 -netmask 255.255.255.0 -vlan-id 120 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
-
Configure la interfaz en el puerto "e5b" en "node_A_1":
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5b -address <ip_address> -netmask <netmask>En el ejemplo siguiente se muestra la creación de la interfaz en el puerto "e5b" en "node_A_1" con la dirección IP "10.1.2.1":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_1 -home-port e5b -address 10.1.2.1 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
Puede verificar la presencia de estas interfaces mediante el metrocluster configuration-settings interface showcomando. -
-
Cree las interfaces en node_A_2.
-
Configure la interfaz en el puerto "e5a" en "node_A_2":
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5a -address <ip_address> -netmask <netmask>En el ejemplo siguiente se muestra la creación de la interfaz en el puerto "e5a" en "node_A_2" con la dirección IP "10.1.1.2":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2 -home-port e5a -address 10.1.1.2 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
-
Configure la interfaz en el puerto "e5b" en "node_A_2":
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5b -address <ip_address> -netmask <netmask>En el ejemplo siguiente se muestra la creación de la interfaz en el puerto "e5b" en "node_A_2" con la dirección IP "10.1.2.2":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2 -home-port e5b -address 10.1.2.2 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
En los modelos de plataforma que admiten VLAN para la interfaz IP de MetroCluster, se puede incluir el
-vlan-idSi no desea usar los identificadores de VLAN predeterminados. En el siguiente ejemplo, se muestra el comando para un sistema AFF A220 con un ID de VLAN de 220:
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2 -home-port e0b -address 10.1.2.2 -netmask 255.255.255.0 -vlan-id 220 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
-
-
Cree las interfaces en "node_B_1".
-
Configure la interfaz en el puerto "e5a" en "node_B_1":
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5a -address <ip_address> -netmask <netmask>En el ejemplo siguiente se muestra la creación de la interfaz en el puerto "e5a" en "node_B_1" con la dirección IP "10.1.1.3":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_1 -home-port e5a -address 10.1.1.3 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful.cluster_B::>
-
Configure la interfaz en el puerto "e5b" en "node_B_1":
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5b -address <ip_address> -netmask <netmask>En el ejemplo siguiente se muestra la creación de la interfaz en el puerto "e5b" en "node_B_1" con la dirección IP "10.1.2.3":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_1 -home-port e5b -address 10.1.2.3 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful.cluster_B::>
-
-
Cree las interfaces en "node_B_2".
-
Configure la interfaz en el puerto e5a en node_B_2:
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5a -address <ip_address> -netmask <netmask>En el ejemplo siguiente se muestra la creación de la interfaz en el puerto "e5a" en "node_B_2" con la dirección IP "10.1.1.4":
cluster_B::>metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_2 -home-port e5a -address 10.1.1.4 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful.cluster_A::>
-
Configure la interfaz en el puerto "e5b" en "node_B_2":
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5b -address <ip_address> -netmask <netmask>En el ejemplo siguiente se muestra la creación de la interfaz en el puerto "e5b" en "node_B_2" con la dirección IP "10.1.2.4":
cluster_B::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_2 -home-port e5b -address 10.1.2.4 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
-
-
Compruebe que las interfaces se han configurado:
metrocluster configuration-settings interface showEl ejemplo siguiente muestra que se ha completado el estado de configuración de cada interfaz.
cluster_A::> metrocluster configuration-settings interface show DR Config Group Cluster Node Network Address Netmask Gateway State ----- ------- ------- --------------- --------------- --------- ---------- 1 cluster_A node_A_1 Home Port: e5a 10.1.1.1 255.255.255.0 - completed Home Port: e5b 10.1.2.1 255.255.255.0 - completed node_A_2 Home Port: e5a 10.1.1.2 255.255.255.0 - completed Home Port: e5b 10.1.2.2 255.255.255.0 - completed cluster_B node_B_1 Home Port: e5a 10.1.1.3 255.255.255.0 - completed Home Port: e5b 10.1.2.3 255.255.255.0 - completed node_B_2 Home Port: e5a 10.1.1.4 255.255.255.0 - completed Home Port: e5b 10.1.2.4 255.255.255.0 - completed 8 entries were displayed. cluster_A::> -
Compruebe que los nodos estén listos para conectar las interfaces MetroCluster:
metrocluster configuration-settings show-statusEn el siguiente ejemplo, se muestran todos los nodos en el estado "Ready for connection":
Cluster Node Configuration Settings Status ---------- ----------- --------------------------------- cluster_A node_A_1 ready for connection connect node_A_2 ready for connection connect cluster_B node_B_1 ready for connection connect node_B_2 ready for connection connect 4 entries were displayed. -
Establezca las conexiones:
metrocluster configuration-settings connection connectSi ejecuta una versión anterior a ONTAP 9.10.1, las direcciones IP no se pueden cambiar después de emitir este comando.
En el ejemplo siguiente se muestra Cluster_A conectado correctamente:
cluster_A::> metrocluster configuration-settings connection connect [Job 53] Job succeeded: Connect is successful. cluster_A::>
-
Compruebe que se han establecido las conexiones:
metrocluster configuration-settings show-statusSe debe completar el estado de los ajustes de configuración de todos los nodos:
Cluster Node Configuration Settings Status ---------- ----------- --------------------------------- cluster_A node_A_1 completed node_A_2 completed cluster_B node_B_1 completed node_B_2 completed 4 entries were displayed. -
Compruebe que se hayan establecido las conexiones iSCSI:
-
Cambie al nivel de privilegio avanzado:
set -privilege advancedDebe responder con
ycuando se le pida que continúe en el modo avanzado y verá el aviso del modo avanzado (*>). -
Mostrar las conexiones:
storage iscsi-initiator showEn los sistemas que ejecutan ONTAP 9.5, hay ocho iniciadores IP de MetroCluster en cada clúster que deben aparecer en el resultado.
En los sistemas que ejecutan ONTAP 9.4 y versiones anteriores, hay cuatro iniciadores IP de MetroCluster en cada clúster que deben aparecer en el resultado.
En el ejemplo siguiente se muestran los ocho iniciadores IP de MetroCluster en un clúster que ejecuta ONTAP 9.5:
cluster_A::*> storage iscsi-initiator show Node Type Label Target Portal Target Name Admin/Op ---- ---- -------- ------------------ -------------------------------- -------- cluster_A-01 dr_auxiliary mccip-aux-a-initiator 10.227.16.113:65200 prod506.com.company:abab44 up/up mccip-aux-a-initiator2 10.227.16.113:65200 prod507.com.company:abab44 up/up mccip-aux-b-initiator 10.227.95.166:65200 prod506.com.company:abab44 up/up mccip-aux-b-initiator2 10.227.95.166:65200 prod507.com.company:abab44 up/up dr_partner mccip-pri-a-initiator 10.227.16.112:65200 prod506.com.company:cdcd88 up/up mccip-pri-a-initiator2 10.227.16.112:65200 prod507.com.company:cdcd88 up/up mccip-pri-b-initiator 10.227.95.165:65200 prod506.com.company:cdcd88 up/up mccip-pri-b-initiator2 10.227.95.165:65200 prod507.com.company:cdcd88 up/up cluster_A-02 dr_auxiliary mccip-aux-a-initiator 10.227.16.112:65200 prod506.com.company:cdcd88 up/up mccip-aux-a-initiator2 10.227.16.112:65200 prod507.com.company:cdcd88 up/up mccip-aux-b-initiator 10.227.95.165:65200 prod506.com.company:cdcd88 up/up mccip-aux-b-initiator2 10.227.95.165:65200 prod507.com.company:cdcd88 up/up dr_partner mccip-pri-a-initiator 10.227.16.113:65200 prod506.com.company:abab44 up/up mccip-pri-a-initiator2 10.227.16.113:65200 prod507.com.company:abab44 up/up mccip-pri-b-initiator 10.227.95.166:65200 prod506.com.company:abab44 up/up mccip-pri-b-initiator2 10.227.95.166:65200 prod507.com.company:abab44 up/up 16 entries were displayed.-
Vuelva al nivel de privilegio de administrador:
set -privilege admin
-
-
Compruebe que los nodos están listos para la implementación final de la configuración de MetroCluster:
metrocluster node showcluster_A::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- ------------------ -------------- --------- ---- - cluster_A node_A_1 ready to configure - - node_A_2 ready to configure - - 2 entries were displayed. cluster_A::>cluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- ------------------ -------------- --------- ---- - cluster_B node_B_1 ready to configure - - node_B_2 ready to configure - - 2 entries were displayed. cluster_B::>
Verificación o ejecución manual de la asignación de unidades del pool 1
Según la configuración de almacenamiento, debe verificar la asignación de una unidad en el pool 1 o asignar manualmente unidades al pool 1 para cada nodo de la configuración IP de MetroCluster. El procedimiento que utilice dependerá de la versión de ONTAP que esté utilizando.
Tipo de configuración |
Procedimiento |
Los sistemas cumplen los requisitos para la asignación automática de unidades o, si ejecutan ONTAP 9.3, se recibieron de fábrica. |
|
La configuración incluye tres bandejas o, si contiene más de cuatro bandejas, tiene un múltiplo desigual de cuatro bandejas (por ejemplo, siete bandejas) y utiliza ONTAP 9.5. |
|
La configuración no incluye cuatro bandejas de almacenamiento por sitio y ejecuta ONTAP 9.4 |
|
Los sistemas no se recibieron de fábrica y ejecutan ONTAP 9.3los sistemas recibidos de fábrica están preconfigurados con unidades asignadas. |
Verificación de la asignación de discos de los discos del pool 1
Debe verificar que los discos remotos sean visibles para los nodos y que se han asignado correctamente.
Debe esperar al menos diez minutos para que la asignación automática del disco se complete después de que se hayan creado las interfaces IP de MetroCluster y las conexiones con el metrocluster configuration-settings connection connect comando.
El resultado del comando mostrará los nombres de disco con el formato: Node-name:0m.i1.0L1
-
Compruebe que los discos del pool 1 se asignan automáticamente:
disk showEl siguiente resultado muestra el resultado de un sistema AFF A800 sin bandejas externas.
La asignación automática de la unidad ha asignado un cuarto (8 unidades) a "node_A_1" y un cuarto a "node_A_2". Las unidades restantes serán discos remotos (pool 1) para "node_B_1" y "node_B_2".
cluster_B::> disk show -host-adapter 0m -owner node_B_2 Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_B_2:0m.i0.2L4 894.0GB 0 29 SSD-NVM shared - node_B_2 node_B_2:0m.i0.2L10 894.0GB 0 25 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L3 894.0GB 0 28 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L9 894.0GB 0 24 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L11 894.0GB 0 26 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L12 894.0GB 0 27 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L15 894.0GB 0 30 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L16 894.0GB 0 31 SSD-NVM shared - node_B_2 8 entries were displayed. cluster_B::> disk show -host-adapter 0m -owner node_B_1 Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_B_1:0m.i2.3L19 1.75TB 0 42 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L20 1.75TB 0 43 SSD-NVM spare Pool1 node_B_1 node_B_1:0m.i2.3L23 1.75TB 0 40 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L24 1.75TB 0 41 SSD-NVM spare Pool1 node_B_1 node_B_1:0m.i2.3L29 1.75TB 0 36 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L30 1.75TB 0 37 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L31 1.75TB 0 38 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L32 1.75TB 0 39 SSD-NVM shared - node_B_1 8 entries were displayed. cluster_B::> disk show Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_B_1:0m.i1.0L6 1.75TB 0 1 SSD-NVM shared - node_A_2 node_B_1:0m.i1.0L8 1.75TB 0 3 SSD-NVM shared - node_A_2 node_B_1:0m.i1.0L17 1.75TB 0 18 SSD-NVM shared - node_A_1 node_B_1:0m.i1.0L22 1.75TB 0 17 SSD-NVM shared - node_A_1 node_B_1:0m.i1.0L25 1.75TB 0 12 SSD-NVM shared - node_A_1 node_B_1:0m.i1.2L2 1.75TB 0 5 SSD-NVM shared - node_A_2 node_B_1:0m.i1.2L7 1.75TB 0 2 SSD-NVM shared - node_A_2 node_B_1:0m.i1.2L14 1.75TB 0 7 SSD-NVM shared - node_A_2 node_B_1:0m.i1.2L21 1.75TB 0 16 SSD-NVM shared - node_A_1 node_B_1:0m.i1.2L27 1.75TB 0 14 SSD-NVM shared - node_A_1 node_B_1:0m.i1.2L28 1.75TB 0 15 SSD-NVM shared - node_A_1 node_B_1:0m.i2.1L1 1.75TB 0 4 SSD-NVM shared - node_A_2 node_B_1:0m.i2.1L5 1.75TB 0 0 SSD-NVM shared - node_A_2 node_B_1:0m.i2.1L13 1.75TB 0 6 SSD-NVM shared - node_A_2 node_B_1:0m.i2.1L18 1.75TB 0 19 SSD-NVM shared - node_A_1 node_B_1:0m.i2.1L26 1.75TB 0 13 SSD-NVM shared - node_A_1 node_B_1:0m.i2.3L19 1.75TB 0 42 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L20 1.75TB 0 43 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L23 1.75TB 0 40 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L24 1.75TB 0 41 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L29 1.75TB 0 36 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L30 1.75TB 0 37 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L31 1.75TB 0 38 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L32 1.75TB 0 39 SSD-NVM shared - node_B_1 node_B_1:0n.12 1.75TB 0 12 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.13 1.75TB 0 13 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.14 1.75TB 0 14 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.15 1.75TB 0 15 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.16 1.75TB 0 16 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.17 1.75TB 0 17 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.18 1.75TB 0 18 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.19 1.75TB 0 19 SSD-NVM shared - node_B_1 node_B_1:0n.24 894.0GB 0 24 SSD-NVM shared - node_A_2 node_B_1:0n.25 894.0GB 0 25 SSD-NVM shared - node_A_2 node_B_1:0n.26 894.0GB 0 26 SSD-NVM shared - node_A_2 node_B_1:0n.27 894.0GB 0 27 SSD-NVM shared - node_A_2 node_B_1:0n.28 894.0GB 0 28 SSD-NVM shared - node_A_2 node_B_1:0n.29 894.0GB 0 29 SSD-NVM shared - node_A_2 node_B_1:0n.30 894.0GB 0 30 SSD-NVM shared - node_A_2 node_B_1:0n.31 894.0GB 0 31 SSD-NVM shared - node_A_2 node_B_1:0n.36 1.75TB 0 36 SSD-NVM shared - node_A_1 node_B_1:0n.37 1.75TB 0 37 SSD-NVM shared - node_A_1 node_B_1:0n.38 1.75TB 0 38 SSD-NVM shared - node_A_1 node_B_1:0n.39 1.75TB 0 39 SSD-NVM shared - node_A_1 node_B_1:0n.40 1.75TB 0 40 SSD-NVM shared - node_A_1 node_B_1:0n.41 1.75TB 0 41 SSD-NVM shared - node_A_1 node_B_1:0n.42 1.75TB 0 42 SSD-NVM shared - node_A_1 node_B_1:0n.43 1.75TB 0 43 SSD-NVM shared - node_A_1 node_B_2:0m.i0.2L4 894.0GB 0 29 SSD-NVM shared - node_B_2 node_B_2:0m.i0.2L10 894.0GB 0 25 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L3 894.0GB 0 28 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L9 894.0GB 0 24 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L11 894.0GB 0 26 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L12 894.0GB 0 27 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L15 894.0GB 0 30 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L16 894.0GB 0 31 SSD-NVM shared - node_B_2 node_B_2:0n.0 1.75TB 0 0 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.1 1.75TB 0 1 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.2 1.75TB 0 2 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.3 1.75TB 0 3 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.4 1.75TB 0 4 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.5 1.75TB 0 5 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.6 1.75TB 0 6 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.7 1.75TB 0 7 SSD-NVM shared - node_B_2 64 entries were displayed. cluster_B::> cluster_A::> disk show Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_1:0m.i1.0L2 1.75TB 0 5 SSD-NVM shared - node_B_2 node_A_1:0m.i1.0L8 1.75TB 0 3 SSD-NVM shared - node_B_2 node_A_1:0m.i1.0L18 1.75TB 0 19 SSD-NVM shared - node_B_1 node_A_1:0m.i1.0L25 1.75TB 0 12 SSD-NVM shared - node_B_1 node_A_1:0m.i1.0L27 1.75TB 0 14 SSD-NVM shared - node_B_1 node_A_1:0m.i1.2L1 1.75TB 0 4 SSD-NVM shared - node_B_2 node_A_1:0m.i1.2L6 1.75TB 0 1 SSD-NVM shared - node_B_2 node_A_1:0m.i1.2L7 1.75TB 0 2 SSD-NVM shared - node_B_2 node_A_1:0m.i1.2L14 1.75TB 0 7 SSD-NVM shared - node_B_2 node_A_1:0m.i1.2L17 1.75TB 0 18 SSD-NVM shared - node_B_1 node_A_1:0m.i1.2L22 1.75TB 0 17 SSD-NVM shared - node_B_1 node_A_1:0m.i2.1L5 1.75TB 0 0 SSD-NVM shared - node_B_2 node_A_1:0m.i2.1L13 1.75TB 0 6 SSD-NVM shared - node_B_2 node_A_1:0m.i2.1L21 1.75TB 0 16 SSD-NVM shared - node_B_1 node_A_1:0m.i2.1L26 1.75TB 0 13 SSD-NVM shared - node_B_1 node_A_1:0m.i2.1L28 1.75TB 0 15 SSD-NVM shared - node_B_1 node_A_1:0m.i2.3L19 1.75TB 0 42 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L20 1.75TB 0 43 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L23 1.75TB 0 40 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L24 1.75TB 0 41 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L29 1.75TB 0 36 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L30 1.75TB 0 37 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L31 1.75TB 0 38 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L32 1.75TB 0 39 SSD-NVM shared - node_A_1 node_A_1:0n.12 1.75TB 0 12 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.13 1.75TB 0 13 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.14 1.75TB 0 14 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.15 1.75TB 0 15 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.16 1.75TB 0 16 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.17 1.75TB 0 17 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.18 1.75TB 0 18 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.19 1.75TB 0 19 SSD-NVM shared - node_A_1 node_A_1:0n.24 894.0GB 0 24 SSD-NVM shared - node_B_2 node_A_1:0n.25 894.0GB 0 25 SSD-NVM shared - node_B_2 node_A_1:0n.26 894.0GB 0 26 SSD-NVM shared - node_B_2 node_A_1:0n.27 894.0GB 0 27 SSD-NVM shared - node_B_2 node_A_1:0n.28 894.0GB 0 28 SSD-NVM shared - node_B_2 node_A_1:0n.29 894.0GB 0 29 SSD-NVM shared - node_B_2 node_A_1:0n.30 894.0GB 0 30 SSD-NVM shared - node_B_2 node_A_1:0n.31 894.0GB 0 31 SSD-NVM shared - node_B_2 node_A_1:0n.36 1.75TB 0 36 SSD-NVM shared - node_B_1 node_A_1:0n.37 1.75TB 0 37 SSD-NVM shared - node_B_1 node_A_1:0n.38 1.75TB 0 38 SSD-NVM shared - node_B_1 node_A_1:0n.39 1.75TB 0 39 SSD-NVM shared - node_B_1 node_A_1:0n.40 1.75TB 0 40 SSD-NVM shared - node_B_1 node_A_1:0n.41 1.75TB 0 41 SSD-NVM shared - node_B_1 node_A_1:0n.42 1.75TB 0 42 SSD-NVM shared - node_B_1 node_A_1:0n.43 1.75TB 0 43 SSD-NVM shared - node_B_1 node_A_2:0m.i2.3L3 894.0GB 0 28 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L4 894.0GB 0 29 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L9 894.0GB 0 24 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L10 894.0GB 0 25 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L11 894.0GB 0 26 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L12 894.0GB 0 27 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L15 894.0GB 0 30 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L16 894.0GB 0 31 SSD-NVM shared - node_A_2 node_A_2:0n.0 1.75TB 0 0 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.1 1.75TB 0 1 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.2 1.75TB 0 2 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.3 1.75TB 0 3 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.4 1.75TB 0 4 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.5 1.75TB 0 5 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.6 1.75TB 0 6 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.7 1.75TB 0 7 SSD-NVM shared - node_A_2 64 entries were displayed. cluster_A::>
Asignar manualmente unidades para un pool 1 (ONTAP 9.4 o posterior)
Si el sistema no ha sido preconfigurado de fábrica y no cumple los requisitos para la asignación automática de unidades, debe asignar manualmente las unidades del pool remoto 1.
Este procedimiento se aplica a configuraciones que ejecuten ONTAP 9.4 o posterior.
Se incluyen detalles para determinar si el sistema requiere la asignación manual de discos en "Consideraciones sobre la asignación automática de unidades y los sistemas ADP en ONTAP 9.4 y versiones posteriores".
Cuando la configuración incluye solo dos bandejas externas por sitio, pool 1 unidades para cada sitio debe compartirse entre la misma bandeja que se muestra en los ejemplos siguientes:
-
El nodo_A_1 está asignado a las unidades de las bahías 0-11 en el sitio_B-shelf_2 (remoto)
-
El nodo_A_2 está asignado a las unidades de las bahías 12-23 en el sitio_B-shelf_2 (remoto)
-
Desde cada nodo de la configuración IP de MetroCluster, asigne unidades remotas al pool 1.
-
Mostrar la lista de unidades sin asignar:
disk show -host-adapter 0m -container-type unassignedcluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- 6.23.0 - 23 0 SSD unassigned - - 6.23.1 - 23 1 SSD unassigned - - . . . node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - . . . 48 entries were displayed. cluster_A::> -
Asigne la propiedad de las unidades remotas (0m) al pool 1 del primer nodo (por ejemplo, node_A_1):
disk assign -disk <disk-id> -pool 1 -owner <owner_node_name>disk-iddebe identificar una unidad en una bandeja remota deowner_node_name. -
Confirmar que las unidades se asignaron al pool 1:
disk show -host-adapter 0m -container-type unassigned
La conexión iSCSI utilizada para acceder a las unidades remotas aparece como dispositivo 0m. El siguiente resultado muestra que las unidades de la bandeja 23 se asignaron porque ya no se muestran en la lista de unidades sin asignar:
cluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - . . . node_A_2:0m.i2.1L90 - 21 19 SSD unassigned - - 24 entries were displayed. cluster_A::>-
Repita estos pasos para asignar unidades de pool 1 al segundo nodo del sitio A (por ejemplo, "node_A_2").
-
Repita estos pasos en el sitio B.
-
Asignación manual de discos para el pool 1 (ONTAP 9.3)
Si tiene al menos dos bandejas de discos para cada nodo, utiliza la funcionalidad de asignación automática de ONTAP para asignar automáticamente los discos remotos (varios).
Primero se debe asignar un disco de la bandeja al pool 1. ONTAP asigna automáticamente el resto de los discos de la bandeja al mismo pool.
Este procedimiento se aplica a configuraciones que ejecuten ONTAP 9.3.
Este procedimiento solo se puede utilizar si tiene al menos dos bandejas de discos para cada nodo, lo que permite la asignación automática de discos a nivel de bandeja.
Si no puede utilizar la asignación automática a nivel de bandeja, debe asignar manualmente los discos remotos para que cada nodo tenga un pool remoto de discos (pool 1).
La función de asignación automática de discos de ONTAP asigna los discos de bandeja en bandeja. Por ejemplo:
-
Todos los discos del site_B-shelf_2 se asignan automáticamente a la agrupación 1 de node_A_1
-
Todos los discos del site_B-shelf_4 se asignan automáticamente a la agrupación 1 de node_A_2
-
Todos los discos del site_A-shelf_2 se asignan automáticamente a la agrupación 1 de node_B_1
-
Todos los discos del site_A-shelf_4 se asignan automáticamente a la agrupación 1 de node_B_2
Debe "sembrar" la asignación automática especificando un solo disco en cada bandeja.
-
Asigne un disco remoto al pool 1 desde cada nodo de la configuración IP de MetroCluster.
-
Mostrar la lista de discos sin asignar:
disk show -host-adapter 0m -container-type unassignedcluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- 6.23.0 - 23 0 SSD unassigned - - 6.23.1 - 23 1 SSD unassigned - - . . . node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - . . . 48 entries were displayed. cluster_A::> -
Seleccione un disco remoto (0m) y asigne la propiedad del disco al pool 1 del primer nodo (por ejemplo, "node_A_1"):
disk assign -disk <disk_id> -pool 1 -owner <owner_node_name>El
disk-iddebe identificar un disco en una bandeja remota deowner_node_name.La función de asignación automática de discos de ONTAP asigna todos los discos de la bandeja remota que contiene el disco especificado.
-
Después de esperar al menos 60 segundos para que se realice la asignación automática de discos, compruebe que los discos remotos de la bandeja se asignaron automáticamente al pool 1:
disk show -host-adapter 0m -container-type unassigned
La conexión iSCSI utilizada para acceder a los discos remotos aparece como dispositivo 0m. El siguiente resultado muestra que los discos de la bandeja 23 ahora están asignados y ya no aparecen:
cluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - node_A_2:0m.i1.2L72 - 21 23 SSD unassigned - - node_A_2:0m.i1.2L74 - 21 1 SSD unassigned - - node_A_2:0m.i1.2L83 - 21 22 SSD unassigned - - node_A_2:0m.i1.2L90 - 21 7 SSD unassigned - - node_A_2:0m.i1.3L52 - 21 6 SSD unassigned - - node_A_2:0m.i1.3L59 - 21 13 SSD unassigned - - node_A_2:0m.i1.3L66 - 21 17 SSD unassigned - - node_A_2:0m.i1.3L73 - 21 12 SSD unassigned - - node_A_2:0m.i1.3L80 - 21 5 SSD unassigned - - node_A_2:0m.i1.3L81 - 21 2 SSD unassigned - - node_A_2:0m.i1.3L82 - 21 16 SSD unassigned - - node_A_2:0m.i1.3L91 - 21 3 SSD unassigned - - node_A_2:0m.i2.0L49 - 21 15 SSD unassigned - - node_A_2:0m.i2.0L50 - 21 4 SSD unassigned - - node_A_2:0m.i2.1L57 - 21 18 SSD unassigned - - node_A_2:0m.i2.1L58 - 21 11 SSD unassigned - - node_A_2:0m.i2.1L59 - 21 21 SSD unassigned - - node_A_2:0m.i2.1L65 - 21 20 SSD unassigned - - node_A_2:0m.i2.1L72 - 21 9 SSD unassigned - - node_A_2:0m.i2.1L80 - 21 0 SSD unassigned - - node_A_2:0m.i2.1L88 - 21 8 SSD unassigned - - node_A_2:0m.i2.1L90 - 21 19 SSD unassigned - - 24 entries were displayed. cluster_A::>-
Repita estos pasos para asignar discos del pool 1 al segundo nodo del sitio A (por ejemplo, "node_A_2").
-
Repita estos pasos en el sitio B.
-
Habilitación de la asignación automática de unidades en ONTAP 9.4
En ONTAP 9.4, si deshabilitó la asignación automática de unidades como indicó anteriormente en este procedimiento, debe rehabilitarla en todos los nodos.
-
Habilitar asignación automática de unidades:
storage disk option modify -node <node_name> -autoassign onDebe emitir este comando en todos los nodos de la configuración de IP de MetroCluster.
Mirroring de los agregados raíz
Para proporcionar protección de datos, debe reflejar los agregados raíz.
De forma predeterminada, el agregado raíz se crea como agregado de tipo RAID-DP. Puede cambiar el agregado raíz de RAID-DP a agregado de tipo RAID4. El siguiente comando modifica el agregado raíz para el agregado de tipo RAID4:
storage aggregate modify –aggregate <aggr_name> -raidtype raid4
|
|
En los sistemas que no son ADP, el tipo RAID del agregado se puede modificar desde el RAID-DP predeterminado a RAID4 antes o después de la duplicación del agregado. |
-
Reflejar el agregado raíz:
storage aggregate mirror <aggr_name>El siguiente comando refleja el agregado raíz para "Controller_A_1":
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
Esto refleja el agregado, por lo que consta de un complejo local y un complejo remoto ubicado en el sitio remoto de MetroCluster.
-
Repita el paso anterior para cada nodo de la configuración MetroCluster.
Crear un agregado de datos reflejados en cada nodo
Debe crear un agregado de datos reflejados en cada nodo del grupo de recuperación ante desastres.
-
Debe conocer qué unidades se utilizarán en el nuevo agregado.
-
Si tiene varios tipos de unidades en el sistema (almacenamiento heterogéneo), debe comprender cómo puede asegurarse de seleccionar el tipo de unidad correcto.
-
Las unidades son propiedad de un nodo específico; cuando se crea un agregado, todas las unidades de ese agregado deben ser propiedad del mismo nodo, que se convierte en el nodo inicial para ese agregado.
En los sistemas que utilizan ADP, los agregados se crean utilizando particiones en las que cada unidad se divide en particiones P1, P2 y P3.
-
Los nombres de agregados deben ajustarse al esquema de nomenclatura que se determinó al planificar la configuración de MetroCluster.
-
Los nombres de los agregados deben ser únicos en todos los sitios MetroCluster. Esto significa que no puedes tener dos agregados diferentes con el mismo nombre en el sitio A y en el sitio B.
-
Mostrar una lista de repuestos disponibles:
storage disk show -spare -owner <node_name> -
Cree el agregado:
storage aggregate create -mirror trueSi ha iniciado sesión en el clúster en la interfaz de gestión del clúster, puede crear un agregado en cualquier nodo del clúster. Para garantizar que el agregado se ha creado en un nodo concreto, utilice
-nodeespecifique o especifique las unidades que son propiedad de ese nodo.Puede especificar las siguientes opciones:
-
Nodo principal del agregado (es decir, el nodo al que pertenece el agregado en un funcionamiento normal)
-
Lista de unidades específicas que se añadirán al agregado
-
Cantidad de unidades que se incluirán
En la configuración mínima admitida, en la que haya disponible una cantidad limitada de unidades, debe utilizar la opción force-small-aggregate para permitir la creación de un agregado de tres discos RAID-DP. -
Estilo de suma de comprobación que se utilizará para el agregado
-
El tipo de unidades que se van a utilizar
-
El tamaño de las unidades que se van a utilizar
-
Conduzca la velocidad que se va a utilizar
-
Tipo de RAID para grupos RAID en el agregado
-
Cantidad máxima de unidades que se pueden incluir en un grupo RAID
-
Si se permiten unidades con distintas RPM para obtener más información acerca de estas opciones, consulte la página man CREATE Aggregate Storage.
El siguiente comando crea un agregado con 10 discos:
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Compruebe el grupo RAID y las unidades del nuevo agregado:
storage aggregate show-status -aggregate <aggregate-name>
Implementar la configuración de MetroCluster
Debe ejecutar el metrocluster configure Comando para iniciar la protección de datos en una configuración de MetroCluster.
-
Debe haber al menos dos agregados de datos reflejados no raíz en cada clúster.
Puede comprobarlo con la
storage aggregate showcomando.
Si desea utilizar un solo agregado de datos reflejados, consulte Paso 1 si desea obtener instrucciones. -
El estado ha-config de las controladoras y el chasis debe ser "mccip".
Emita el metrocluster configure Comando una vez en cualquiera de los nodos para habilitar la configuración de MetroCluster. No es necesario emitir el comando en cada uno de los sitios o nodos y no importa el nodo o sitio en el que elija ejecutar el comando.
La metrocluster configure El comando empareja automáticamente los dos nodos con el ID de sistema más bajo de cada uno de los dos clústeres como socios de recuperación ante desastres (DR). En una configuración MetroCluster de cuatro nodos, existen dos pares de recuperación ante desastres asociados. El segundo par DR se crea a partir de los dos nodos con ID de sistema superiores.
|
|
No debe configurar el Administrador de claves incorporado (OKM) o la gestión de claves externas antes de ejecutar el comando metrocluster configure.
|
-
Configure el MetroCluster en el siguiente formato:
Si la configuración de MetroCluster tiene…
Realice lo siguiente…
Varios agregados de datos
Desde el símbolo del sistema de cualquier nodo, configure MetroCluster:
metrocluster configure <node_name>Un único agregado de datos reflejado
-
Desde el símbolo del sistema de cualquier nodo, cambie al nivel de privilegio avanzado:
set -privilege advancedDebe responder con
ycuando se le pida que continúe en modo avanzado y vea el símbolo del sistema del modo avanzado (*>). -
Configure la MetroCluster con el
-allow-with-one-aggregate trueparámetro:metrocluster configure -allow-with-one-aggregate true <node_name> -
Vuelva al nivel de privilegio de administrador:
set -privilege admin
Lo mejor es disponer de varios agregados de datos. Si el primer grupo de recuperación ante desastres tiene un solo agregado y desea añadir un grupo de recuperación ante desastres con un agregado, debe mover el volumen de metadatos fuera del agregado de datos único. Para obtener más información sobre este procedimiento, consulte "Mover un volumen de metadatos en configuraciones de MetroCluster". El siguiente comando habilita la configuración de MetroCluster en todos los nodos del grupo DR que contiene "Controller_A_1":
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
Compruebe el estado de la red en el sitio A:
network port showEn el ejemplo siguiente se muestra el uso de puerto de red en una configuración de MetroCluster de cuatro nodos:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
Compruebe la configuración de MetroCluster en ambos sitios de la configuración de MetroCluster.
-
Verifique la configuración desde el sitio A:
metrocluster showcluster_A::> metrocluster show Configuration: IP fabric Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal Remote: cluster_B Configuration state configured Mode normal -
Verifique la configuración desde el sitio B:
metrocluster show
cluster_B::> metrocluster show Configuration: IP fabric Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal Remote: cluster_A Configuration state configured Mode normal -
-
Para evitar posibles problemas con el mirroring de memoria no volátil, reinicie cada uno de los cuatro nodos:
node reboot -node <node_name> -inhibit-takeover true -
Emita el
metrocluster showcomando en ambos clústeres para volver a verificar la configuración.
Configurar el segundo grupo DR con una configuración de ocho nodos
Repita las tareas anteriores para configurar los nodos del segundo grupo de recuperación ante desastres.
Creación de agregados de datos no reflejados
Opcionalmente, puede crear agregados de datos no reflejados para datos que no requieren el mirroring redundante que proporcionan las configuraciones de MetroCluster.
-
Verifique que sepa qué unidades se utilizarán en el nuevo agregado.
-
Si tiene varios tipos de unidades en el sistema (almacenamiento heterogéneo), debe comprender cómo verificar que se selecciona el tipo de unidad correcto.

|
En las configuraciones de IP de MetroCluster, no se puede acceder a los agregados remotos no reflejados tras una conmutación por sitios |
|
|
Los agregados no reflejados deben ser locales para el nodo a los que pertenecen. |
-
Las unidades son propiedad de un nodo específico; cuando se crea un agregado, todas las unidades de ese agregado deben ser propiedad del mismo nodo, que se convierte en el nodo inicial para ese agregado.
-
Los nombres de agregados deben ajustarse al esquema de nomenclatura que se determinó al planificar la configuración de MetroCluster.
-
Administración de discos y agregados contiene más información sobre el mirroring de agregados.
-
Habilitar la puesta en marcha de agregados no reflejados:
metrocluster modify -enable-unmirrored-aggr-deployment true -
Compruebe que la asignación automática de discos está deshabilitada:
disk option show -
Instale y cablee las bandejas de discos que contendrán los agregados no reflejados.
Puede usar los procedimientos en la documentación de instalación y configuración para su plataforma y bandejas de discos.
-
Asigne manualmente todos los discos de la bandeja nueva al nodo apropiado:
disk assign -disk <disk_id> -owner <owner_node_name> -
Cree el agregado:
storage aggregate createSi ha iniciado sesión en el clúster en la interfaz de gestión del clúster, puede crear un agregado en cualquier nodo del clúster. Para verificar que el agregado se ha creado en un nodo específico, debe usar el parámetro -node o especificar unidades que son propiedad de ese nodo.
También debe asegurarse de que solo se incluyan unidades de la bandeja no reflejada al agregado.
Puede especificar las siguientes opciones:
-
Nodo principal del agregado (es decir, el nodo al que pertenece el agregado en un funcionamiento normal)
-
Lista de unidades específicas que se añadirán al agregado
-
Cantidad de unidades que se incluirán
-
Estilo de suma de comprobación que se utilizará para el agregado
-
El tipo de unidades que se van a utilizar
-
El tamaño de las unidades que se van a utilizar
-
Conduzca la velocidad que se va a utilizar
-
Tipo de RAID para grupos RAID en el agregado
-
Cantidad máxima de unidades que se pueden incluir en un grupo RAID
-
Si se permiten unidades con RPM diferentes
Para obtener más información sobre estas opciones, consulte la página man de creación de agregados de almacenamiento.
El siguiente comando crea un agregado no reflejado con 10 discos:
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Compruebe el grupo RAID y las unidades del nuevo agregado:
storage aggregate show-status -aggregate <aggregate_name> -
Desactivar la implementación de agregados no reflejados:
metrocluster modify -enable-unmirrored-aggr-deployment false -
Compruebe que la asignación automática de discos está habilitada:
disk option show
Comprobar la configuración de MetroCluster
Puede comprobar que los componentes y las relaciones de la configuración de MetroCluster funcionan correctamente.
Debe hacer una comprobación después de la configuración inicial y después de realizar cualquier cambio en la configuración de MetroCluster.
También debe hacer una comprobación antes de una operación de conmutación negociada (planificada) o de conmutación de estado.
Si la metrocluster check run el comando se emite dos veces en un corto tiempo en uno de los clústeres o en ambos, se puede producir un conflicto y es posible que el comando no recopile todos los datos. Posteriormente metrocluster check show los comandos no muestran el resultado esperado.
-
Compruebe la configuración:
metrocluster check runEl comando se ejecuta como un trabajo en segundo plano y es posible que no se complete inmediatamente.
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
Mostrar resultados más detallados del comando check run de MetroCluster más reciente:
metrocluster check aggregate showmetrocluster check cluster showmetrocluster check config-replication showmetrocluster check lif showmetrocluster check node show
La metrocluster check showlos comandos muestran los resultados de los más recientesmetrocluster check runcomando. Siempre debe ejecutar elmetrocluster check runantes de utilizar elmetrocluster check showcomandos para que la información mostrada sea actual.En el siguiente ejemplo se muestra el
metrocluster check aggregate showResultado del comando para una configuración de MetroCluster de cuatro nodos en buen estado:cluster_A::> metrocluster check aggregate show Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.En el siguiente ejemplo se muestra el
metrocluster check cluster showResultado del comando para una configuración de MetroCluster de cuatro nodos en buen estado. Indica que los clústeres están listos para ejecutar una conmutación de sitios negociada, si es necesario.cluster_A::> metrocluster check cluster show Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
Completando la configuración de ONTAP
Después de configurar, habilitar y comprobar la configuración de MetroCluster, puede continuar para completar la configuración del clúster añadiendo SVM, interfaces de red y otras funcionalidades de ONTAP según sea necesario.