

Eliminar un grupo de DR de una configuración de MetroCluster
 Sugerir cambios
Sugerir cambios
A partir de ONTAP 9.8, puede eliminar un grupo de recuperación ante desastres (DR) de una configuración de MetroCluster de ocho nodos para crear una configuración de MetroCluster de cuatro nodos.

|
Utilizas estos pasos durante los flujos de trabajo de transición y actualización del sistema. Es posible que ya hayas completado algunos pasos de este procedimiento como parte de estos flujos de trabajo. |
Active el registro de la consola
NetApp recomienda encarecidamente que habilite el inicio de sesión de la consola en los dispositivos que esté utilizando y realice las siguientes acciones al realizar este procedimiento:
-
Deje la función AutoSupport habilitada durante el mantenimiento.
-
Active un mensaje de AutoSupport de mantenimiento antes y después de las tareas de mantenimiento para deshabilitar la creación de casos durante la actividad de mantenimiento.
Consulte el artículo de la base de conocimientos "Cómo impedir la creación automática de casos durante las ventanas de mantenimiento programado".
-
Habilite el registro de sesiones para cualquier sesión de CLI. Para obtener instrucciones sobre cómo activar el registro de sesiones, consulte la sección Salida de sesión de registro en el artículo de la Base de conocimientos "Cómo configurar PuTTY para una conectividad óptima con sistemas ONTAP".
Eliminar los nodos del grupo DR de cada clúster
Este procedimiento es compatible a partir de ONTAP 9.8. Para sistemas que ejecutan ONTAP 9.7 o anterior, consulte el artículo de la base de conocimientos:"Cómo quitar un grupo de recuperación ante desastres de una configuración de MetroCluster" .
-
Debe ejecutar esta tarea en ambos clústeres.
-
Una configuración de ocho nodos incluye ocho nodos organizados como dos grupos de recuperación ante desastres de cuatro nodos.
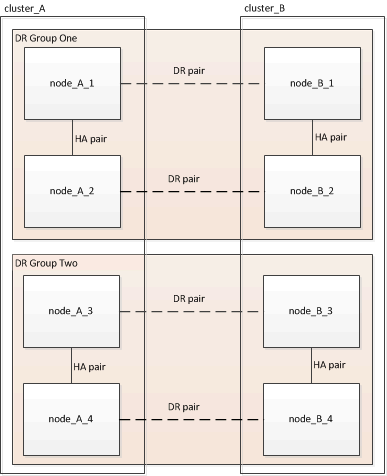
Cuando se elimina un grupo de DR, quedan cuatro nodos en la configuración.
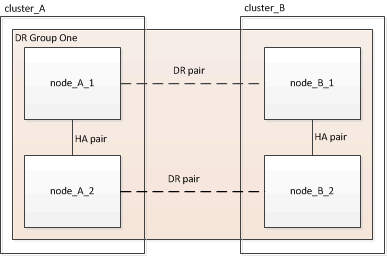
-
Prepárese para eliminar el grupo DR si aún no lo ha hecho.
-
Mueva todos los volúmenes de datos a otro grupo de recuperación ante desastres.
-
Si el grupo de DR que se va a eliminar tiene volúmenes espejo de reparto de carga, vuelva a crear todos los volúmenes espejo de reparto de carga en otro grupo de DR y elimínelos del grupo de DR que se va a eliminar.
-
Mueva todos los volúmenes de metadatos MDV_CRS a otro grupo de DR siguiendo el "Mover un volumen de metadatos en configuraciones de MetroCluster" procedimiento.
-
Elimine todos los volúmenes de metadatos MDV_aud que puedan existir en el grupo de recuperación ante desastres que se va a quitar.
-
Eliminar todos los agregados de datos en el grupo de DR que se van a eliminar:
ClusterA::> storage aggregate show -node ClusterA-01, ClusterA-02 -fields aggregate ,node ClusterA::> aggr delete -aggregate aggregate_name ClusterB::> storage aggregate show -node ClusterB-01, ClusterB-02 -fields aggregate ,node ClusterB::> aggr delete -aggregate aggregate_name
Los agregados raíz no se eliminan. -
Migre todos los LIF de datos NAS que utiliza para NFS y CIFS (SMB) a los nodos locales en otro grupo de recuperación ante desastres.
network interface show -home-node <old_node>network interface migrate -vserver <svm_name> -lif <data_lif> -destination-node <new_node> -destination-port <port> -
Mueva los LIF de datos al nuevo nodo de inicio en otro grupo de DR.
network interface modify -vserver <svm-name> -lif <data-lif> -home-node <new_node> -home-port <port> -
Migrar la LIF de gestión del clúster a un nodo inicial en otro grupo de recuperación ante desastres.
network interface show -role cluster-mgmtnetwork interface modify -vserver <svm-name> -lif <cluster_mgmt> -home-node <new_node> -home-port <port-id>
-
La gestión de nodos y los LIF entre clústeres no se migran. Cree nuevos LIF de administración de nodos y entre clústeres en los nodos del grupo de recuperación ante desastres según sea necesario.
-
No es posible migrar ni mover interfaces FCP utilizadas para el acceso a bloques (SAN) entre los nodos. Cree nuevas interfaces FCP según sea necesario.
-
Las LIF SAN iSCSI deben estar inactivas antes de que se puedan actualizar el nodo local y el puerto local.
-
Transfiera el valor épsilon a un nodo de otro grupo de recuperación ante desastres, si fuera necesario.
ClusterA::> set advanced -prompt-timestamp above ClusterA::*> cluster show Move epsilon if needed ClusterA::*> cluster modify -node nodename -epsilon false ClusterA::*> cluster modify -node nodename -epsilon true ClusterB::> set advanced -prompt-timestamp above ClusterB::*> cluster show ClusterB::*> cluster modify -node nodename -epsilon false ClusterB::*> cluster modify -node nodename -epsilon true ClusterB::*> set admin
-
-
Identifique y elimine el grupo de recuperación ante desastres.
-
Identificar el grupo de recuperación ante desastres correcto para su retirada:
metrocluster node show -
Quite los nodos del grupo DR:
metrocluster remove-dr-group -dr-group-id 1
La metrocluster remove-dr-groupEl comando solo se admite en ONTAP 9.8 y versiones posteriores.En el siguiente ejemplo, se muestra la eliminación de la configuración del grupo DR en cluster_A.
Ejemplo
cluster_A::*> Warning: Nodes in the DR group that are removed from the MetroCluster configuration will lose their disaster recovery protection. Local nodes "node_A_1-FC, node_A_2-FC"will be removed from the MetroCluster configuration. You must repeat the operation on the partner cluster "cluster_B"to remove the remote nodes in the DR group. Do you want to continue? {y|n}: y Info: The following preparation steps must be completed on the local and partner clusters before removing a DR group. 1. Move all data volumes to another DR group. 2. Move all MDV_CRS metadata volumes to another DR group. 3. Delete all MDV_aud metadata volumes that may exist in the DR group to be removed. 4. Delete all data aggregates in the DR group to be removed. Root aggregates are not deleted. 5. Migrate all data LIFs to home nodes in another DR group. 6. Migrate the cluster management LIF to a home node in another DR group. Node management and inter-cluster LIFs are not migrated. 7. Transfer epsilon to a node in another DR group. The command is vetoed if the preparation steps are not completed on the local and partner clusters. Do you want to continue? {y|n}: y [Job 513] Job succeeded: Remove DR Group is successful. cluster_A::*> -
-
Repita el paso anterior en el clúster del partner.
-
Deshabilite la conmutación por error de almacenamiento en los nodos del antiguo grupo de recuperación ante desastres:
storage failover modify -node <node-name> -enable false -
Si está en una configuración de IP de MetroCluster , realice los siguientes pasos para eliminar los plexos remotos de los agregados raíz y quitar la propiedad del disco en los nodos del antiguo grupo de DR.
En una configuración de MetroCluster FC, ve al paso para eliminando los nodos antiguos del grupo DR.
Estos pasos deben realizarse para ambos nodos del par HA en cada sitio.
-
Mostrar los plexos remotos de agregados raíz en los nodos del grupo de DR que se va a eliminar:
storage aggregate plex show -aggregate <root_aggr_name> -pool 1 -
Eliminar los plexos remotos:
storage aggregate plex delete -aggregate <root_aggr_name> -plex <plex_from_previous_step> -
Identifique los discos remotos que pertenecen a los nodos del grupo de recuperación ante desastres.
Los comandos que utilice dependerán de si está utilizando discos particionados/compartidos o discos completos:
Utilice una lista separada por comas en el -owner <node_names>campo para especificar los nombres de los nodos en el grupo DR que se eliminará.Discos particionados/compartidos:-
Configure el nivel de privilegio en Advanced:
set advanced -prompt-timestamp above -
Mostrar los discos remotos:
storage disk show -pool Pool1 -owner <node_names> -partition-ownership
Discos enteros:-
Configure el nivel de privilegio en Advanced:
set advanced -prompt-timestamp above -
Mostrar los discos remotos:
storage disk show -pool Pool1 -owner <node_names>
-
-
Deshabilitar la asignación automática de discos:
disk option modify -node <node_names_in_the_DR_group_to_be_deleted> -autoassign off -
Elimina la propiedad de los discos de pool1 en cada nodo del grupo DR que se va a eliminar. Realiza estos pasos en cada nodo que se va a eliminar. En los ejemplos usados en este paso, se está eliminando node_A_1.
-
Vaya al nodeshell:
run -node <node_name> -
Identifique los discos del pool1:
disk showSe muestran todos los discos, incluidos los discos Pool1 propiedad del nodo. El siguiente ejemplo muestra la salida truncada donde el disco 0n.4 y sus particiones se asignan a Pool1. La salida variará dependiendo de tu configuración.
DISK OWNER POOL SERIAL NUMBER HOME DR HOME ------------ ------------- ----- ------------- ------------- ------------- 0n.4 node_A1(537102267) Pool1 S3N9NX0J500267 node_A1(537102267) 0n.4P1 node_A1(537102267) Pool1 S3N9NX0J500267NP001 node_A1(537102267) 0n.4P2 node_A1(537102267) Pool1 S3N9NX0J500267NP002 node_A1(537102267) 0n.4P3 node_A1(537102267) Pool1 S3N9NX0J500267NP003 node_A1(537102267)
-
Configure el nivel de privilegio en Advanced:
set -privilege advanced -prompt-timestamp above -
Elimina la propiedad de disco para cada disco pool1:
Si tu configuración contiene discos particionados, primero elimina la propiedad de cada disco particionado y luego elimina la propiedad del disco contenedor:
disk remove_ownership <disk_name>
En el siguiente ejemplo, la propiedad de los discos particionados se elimina antes de eliminar la propiedad del disco contenedor
0n.4: -
*> disk remove_ownership 0n.4P1 Volumes must be taken offline. Are all impacted volumes offline(y/n)?? y Removing the ownership of aggregate disks may lead to partition of aggregates between high-availability pair. Do you want to continue(y/n)? y *> disk remove_ownership 0n.4P2 Volumes must be taken offline. Are all impacted volumes offline(y/n)?? y Removing the ownership of aggregate disks may lead to partition of aggregates between high-availability pair. Do you want to continue(y/n)? y *> disk remove_ownership 0n.4P3 Volumes must be taken offline. Are all impacted volumes offline(y/n)?? y Removing the ownership of aggregate disks may lead to partition of aggregates between high-availability pair. Do you want to continue(y/n)? y *> disk remove_ownership 0n.4 Volumes must be taken offline. Are all impacted volumes offline(y/n)?? y *>
-
-
Si está en una configuración de IP de MetroCluster , elimine las conexiones de MetroCluster en los nodos del antiguo grupo de DR.
En una configuración de MetroCluster FC, ve al paso para eliminando los nodos antiguos del grupo DR.
Estos comandos se pueden emitir desde cualquiera de los clústeres y se aplican a todo el grupo de DR que abarca ambos clústeres.
-
Desconectar las conexiones:
metrocluster configuration-settings connection disconnect -dr-group-id <dr_group_id>Ejemplo
cluster_A::*> metrocluster configuration-settings connection disconnect -dr-group-id 1 Warning: For the nodes in the DR group 1, this command will remove the existing connections that are used to mirror NV logs and access remote storage. Do you want to continue? {y|n}: y Warning: Before proceeding with disconnect, you must verify the following: 1. Unmirrored aggregates do not have disks in remote plexes. 2. Aggregates are not mirrored. 3. No disks are assigned in Pool1. 4. Storage failover is not enabled. Follow the "MetroCluster Installation and Configuration guide" for detailed instructions to verify this. Do you want to continue? {y|n}: y -
Elimine las interfaces MetroCluster en los nodos del antiguo grupo de recuperación ante desastres:
Este paso debe repetirse en cada nodo del grupo DR.
metrocluster configuration-settings interface delete-
Elimine la configuración del grupo de recuperación ante desastres antiguo.
metrocluster configuration-settings dr-group delete
-
-
Elimina los nodos del antiguo grupo DR.
Realice este paso en cada clúster.
-
Configure el nivel de privilegio avanzado:
set -privilege advanced -prompt-timestamp above -
Quita el nodo:
cluster remove-node -node <node-name>Repita este paso con el otro nodo local del grupo de recuperación ante desastres antiguo.
-
Establecer el nivel de privilegio de administrador:
set -privilege admin
-
-
Verifique que la alta disponibilidad del clúster esté habilitada en el nuevo grupo de recuperación ante desastres. Si es necesario, vuelva a habilitar la alta disponibilidad del clúster:
cluster ha modify -configured trueRealice este paso en cada clúster.
-
Detenga, apague y retire los módulos de controladora y las bandejas de almacenamiento antiguos.
Más información sobre los comandos utilizados en este procedimiento en el "Referencia de comandos de ONTAP".