

Tierisation des données des clusters ONTAP sur site vers Amazon S3 dans NetApp Cloud Tiering
 Suggérer des modifications
Suggérer des modifications
Libérez de l'espace sur vos clusters ONTAP sur site en transférant les données inactives vers Amazon S3 dans NetApp Cloud Tiering.
Démarrage rapide
Pour démarrer rapidement, suivez ces étapes. Les détails de chaque étape sont fournis dans les sections suivantes de ce sujet.
 Identifiez la méthode de configuration que vous utiliserez.
Identifiez la méthode de configuration que vous utiliserez.Choisissez si vous connecterez votre cluster ONTAP local directement à AWS S3 via l'Internet public, ou si vous utiliserez un VPN ou AWS Direct Connect et acheminerez le trafic via une interface de point de terminaison VPC privée vers AWS S3.
 Préparez votre agent de console
Préparez votre agent de consoleSi vous avez déjà déployé l'agent Console dans votre VPC AWS ou sur site, alors tout est prêt. Sinon, vous devrez créer l'agent pour transférer les données ONTAP vers le stockage AWS S3. Vous devrez également personnaliser les paramètres réseau de l'agent afin qu'il puisse se connecter à AWS S3.
 Préparez votre cluster ONTAP sur site
Préparez votre cluster ONTAP sur siteDécouvrez votre cluster ONTAP dans la NetApp Console, vérifiez qu'il répond aux exigences minimales et personnalisez les paramètres réseau pour qu'il puisse se connecter à AWS S3.
 Préparez Amazon S3 comme cible de hiérarchisation
Préparez Amazon S3 comme cible de hiérarchisationConfigurez les autorisations permettant à l'agent de créer et de gérer le compartiment S3. Vous devrez également configurer les autorisations pour le cluster ONTAP local afin qu'il puisse lire et écrire des données dans le compartiment S3.
 Activez la hiérarchisation cloud sur le système
Activez la hiérarchisation cloud sur le systèmeSélectionnez un système sur site, sélectionnez Activer pour le service de hiérarchisation cloud et suivez les instructions pour hiérarchiser les données vers Amazon S3.
 Mise en place de la licence
Mise en place de la licenceUne fois votre période d'essai gratuite terminée, vous pouvez payer pour Cloud Tiering via un abonnement à la carte, une licence BYOL ONTAP Cloud Tiering ou une combinaison des deux :
-
Pour vous abonner depuis AWS Marketplace, "accéder à l'offre Marketplace" Sélectionnez S'abonner, puis suivez les instructions.
-
Pour payer avec une licence BYOL Cloud Tiering, envoyez un e-mail à ng-cloud-tiering@netapp.com?subject=Licensing[contactez-nous si vous devez en acheter une], puis"ajoutez-le à la NetApp Console" .
Schémas de réseau pour les options de connexion
Vous pouvez utiliser deux méthodes de connexion lors de la configuration de la hiérarchisation des systèmes ONTAP sur site vers AWS S3.
-
Connexion publique - Connectez directement le système ONTAP à AWS S3 à l'aide d'un point de terminaison S3 public.
-
Connexion privée - Utilisez un VPN ou AWS Direct Connect et acheminez le trafic via une interface de point de terminaison VPC utilisant une adresse IP privée.
Le diagramme suivant montre la méthode de connexion publique et les connexions que vous devez préparer entre les composants. Vous pouvez utiliser l'agent Console que vous avez installé sur vos locaux, ou un agent que vous avez déployé dans le VPC AWS.
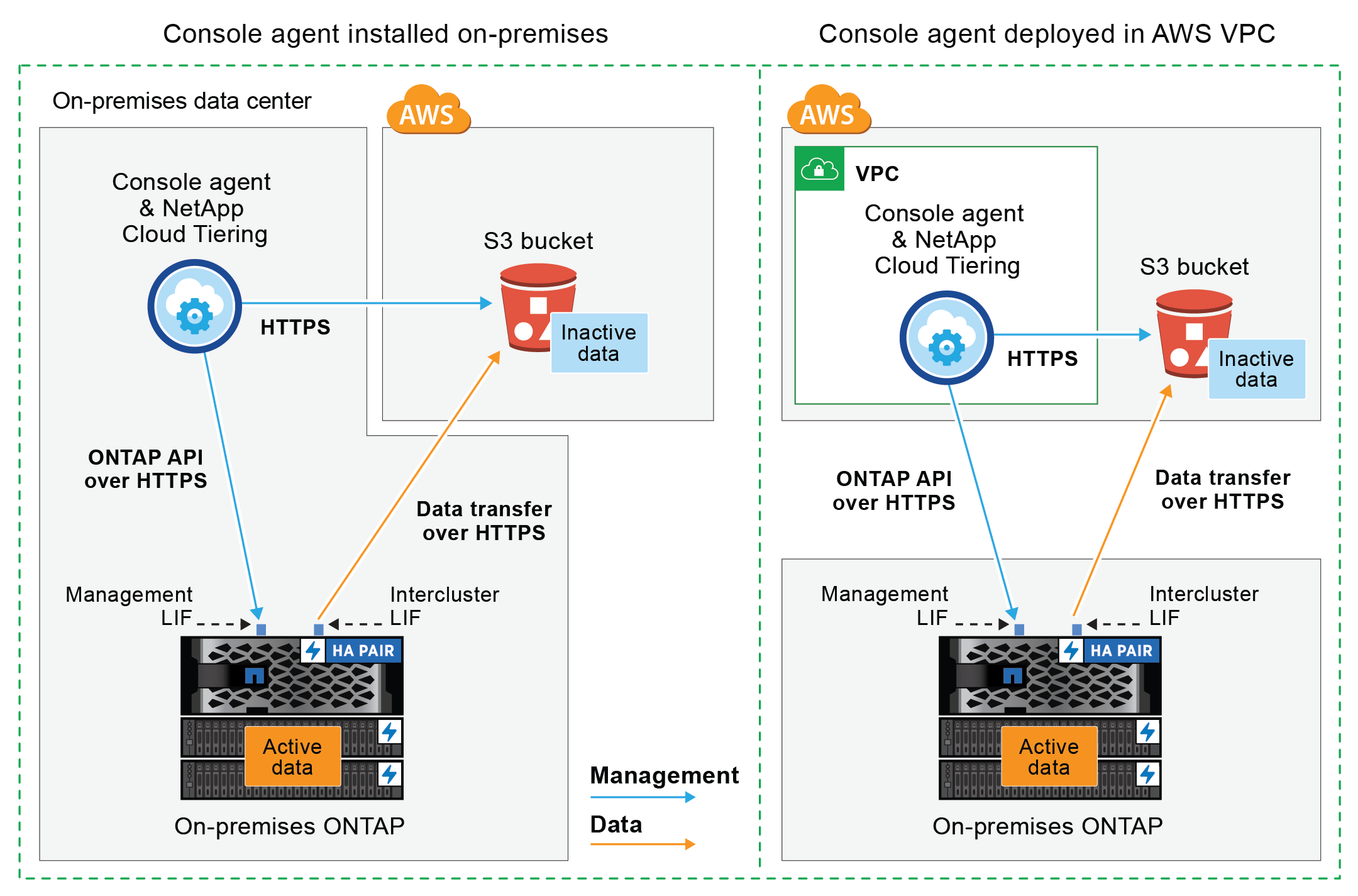
Le diagramme suivant montre la méthode de connexion privée et les connexions que vous devez préparer entre les composants. Vous pouvez utiliser l'agent Console que vous avez installé sur vos locaux, ou un agent que vous avez déployé dans le VPC AWS.
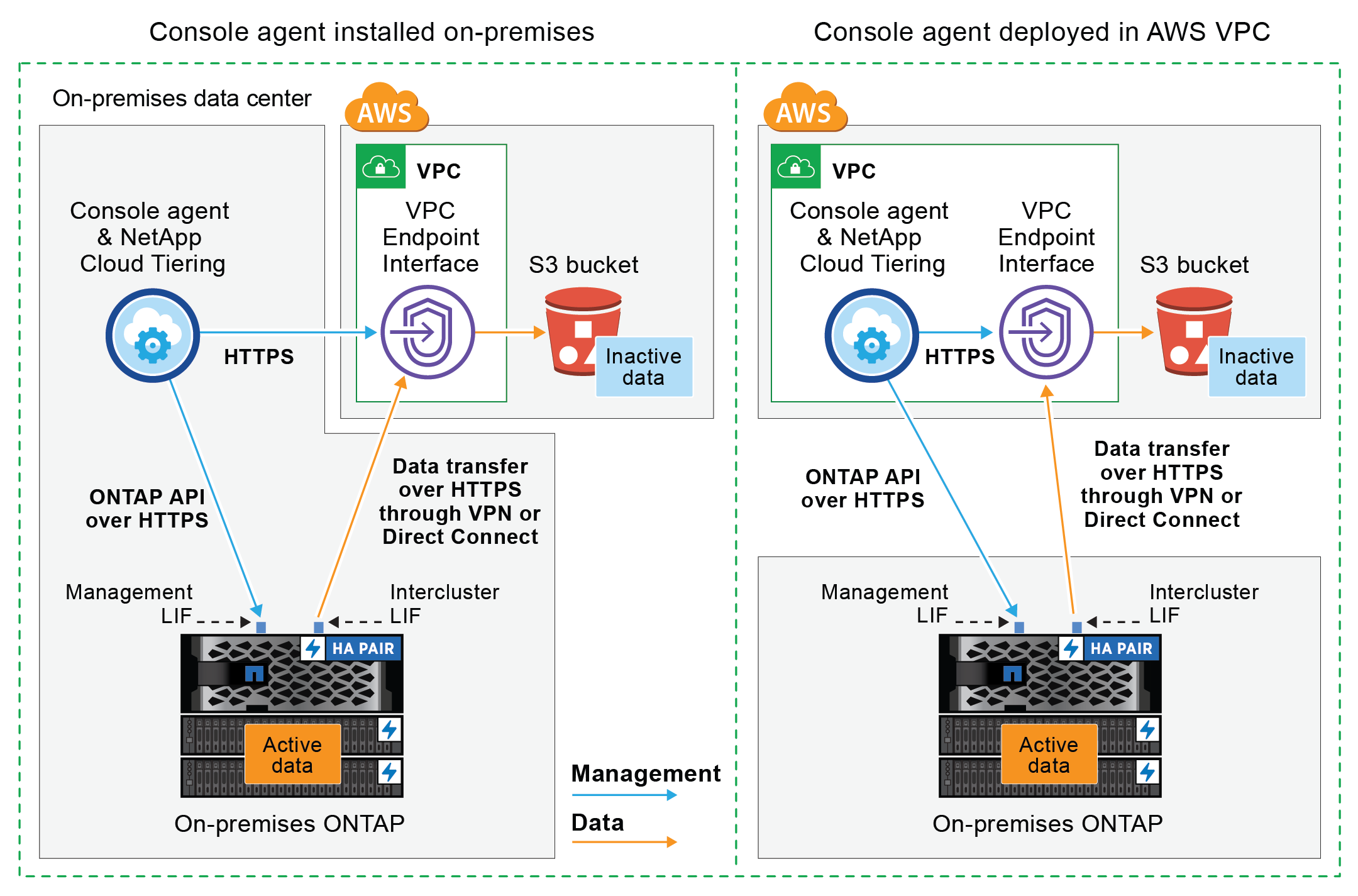

|
La communication entre un agent et S3 est réservée à la configuration du stockage d'objets. |
Préparez votre agent de console
L'agent active les fonctionnalités de hiérarchisation depuis la NetApp Console. Un agent est nécessaire pour hiérarchiser vos données ONTAP inactives.
Créer ou changer d'agent
Si vous avez déjà un agent déployé dans votre VPC AWS ou sur vos locaux, alors tout est prêt. Sinon, vous devrez créer un agent dans l'un de ces emplacements pour transférer les données ONTAP vers le stockage AWS S3. Vous ne pouvez pas utiliser un agent déployé chez un autre fournisseur de cloud.
exigences de mise en réseau des agents
-
Assurez-vous que le réseau sur lequel l'agent est installé autorise les connexions suivantes :
-
Une connexion HTTPS via le port 443 au service Cloud Tiering et à votre stockage d'objets S3("voir la liste des points de terminaison" )
-
Une connexion HTTPS via le port 443 vers votre LIF de gestion de cluster ONTAP
-
-
"Vérifiez que l'agent dispose des autorisations nécessaires pour gérer le compartiment S3."
-
Si vous disposez d'une connexion Direct Connect ou VPN entre votre cluster ONTAP et le VPC, et que vous souhaitez que la communication entre l'agent et S3 reste dans votre réseau interne AWS (une connexion privée), vous devrez activer une interface de point de terminaison VPC vers S3.Découvrez comment configurer une interface de point de terminaison VPC.
Préparez votre cluster ONTAP
Vos clusters ONTAP doivent répondre aux exigences suivantes lors du transfert de données vers Amazon S3.
Exigences ONTAP
- Plateformes ONTAP prises en charge
-
-
Lors de l'utilisation ONTAP 9.8 et versions ultérieures : vous pouvez hiérarchiser les données provenant de systèmes AFF ou de systèmes FAS avec des agrégats entièrement SSD ou des agrégats entièrement HDD.
-
Lors de l'utilisation ONTAP 9.7 et versions antérieures : vous pouvez hiérarchiser les données provenant de systèmes AFF ou de systèmes FAS avec des agrégats entièrement SSD.
-
- Versions ONTAP prises en charge
-
-
ONTAP 9.2 ou version ultérieure
-
ONTAP 9.7 ou une version ultérieure est requis si vous prévoyez d'utiliser une connexion AWS PrivateLink au stockage d'objets.
-
- Volumes et agrégats pris en charge
-
Le nombre total de volumes que Cloud Tiering peut hiérarchiser peut être inférieur au nombre de volumes présents sur votre système ONTAP . C'est parce que les volumes ne peuvent pas être hiérarchisés à partir de certains agrégats. Consultez la documentation ONTAP pour "fonctionnalités ou caractéristiques non prises en charge par FabricPool" .
|
|
Cloud Tiering prend en charge les volumes FlexGroup à partir d' ONTAP 9.5. La configuration fonctionne de la même manière que pour n'importe quel autre volume. |
exigences de mise en réseau du cluster
-
Le cluster nécessite une connexion HTTPS entrante de l'agent de console au LIF de gestion du cluster.
Aucune connexion entre le cluster et Cloud Tiering n'est requise.
-
Une interface LIF inter-cluster est requise sur chaque nœud ONTAP hébergeant les volumes que vous souhaitez hiérarchiser. Ces LIF interclusters doivent pouvoir accéder au magasin d’objets.
Le cluster initie une connexion HTTPS sortante sur le port 443 depuis les LIF inter-clusters vers le stockage Amazon S3 pour les opérations de hiérarchisation. ONTAP lit et écrit des données vers et depuis le stockage d'objets : le stockage d'objets ne s'initialise jamais, il répond simplement.
-
Les LIF intercluster doivent être associés à l'IPspace ONTAP doit utiliser pour se connecter au stockage d'objets. "En savoir plus sur IPspaces" .
Lors de la configuration de la hiérarchisation cloud, le système vous invite à indiquer l'espace IP à utiliser. Vous devez choisir l’espace IP auquel ces LIF sont associés. Il peut s'agir de l'espace IP « par défaut » ou d'un espace IP personnalisé que vous avez créé.
Si vous utilisez un espace IP différent de « Par défaut », vous devrez peut-être créer une route statique pour accéder au stockage d'objets.
Tous les LIF interclusters au sein de l'espace IP doivent avoir accès au magasin d'objets. Si vous ne pouvez pas configurer cela pour l'espace IP actuel, vous devrez créer un espace IP dédié où tous les LIF interclusters ont accès au magasin d'objets.
-
Si vous utilisez un point de terminaison d'interface VPC privé dans AWS pour la connexion S3, alors pour que HTTPS/443 puisse être utilisé, vous devrez charger le certificat du point de terminaison S3 dans le cluster ONTAP .Découvrez comment configurer une interface de point de terminaison VPC et charger le certificat S3.
Découvrez votre cluster ONTAP dans la NetApp Console
Vous devez découvrir votre cluster ONTAP local dans la NetApp Console avant de pouvoir commencer à hiérarchiser les données froides vers le stockage objet. Vous devrez connaître l’adresse IP de gestion du cluster et le mot de passe du compte utilisateur administrateur pour ajouter le cluster.
Préparez votre environnement AWS
Lorsque vous configurez la hiérarchisation des données pour un nouveau cluster, il vous est demandé si vous souhaitez que le service crée un compartiment S3 ou si vous préférez sélectionner un compartiment S3 existant dans le compte AWS où l'agent est configuré. Le compte AWS doit disposer des autorisations et d'une clé d'accès que vous pouvez saisir dans Cloud Tiering. Le cluster ONTAP utilise la clé d'accès pour hiérarchiser les données à l'intérieur et à l'extérieur de S3.
Par défaut, la hiérarchisation du cloud crée le compartiment pour vous. Si vous souhaitez utiliser votre propre compartiment, vous pouvez en créer un avant de démarrer l'assistant d'activation par paliers, puis sélectionner ce compartiment dans l'assistant. "Découvrez comment créer des compartiments S3 à partir de la NetApp Console." . Ce compartiment doit être utilisé exclusivement pour stocker les données inactives de vos volumes ; il ne peut être utilisé à aucune autre fin. Le compartiment S3 doit se trouver dans un"région prenant en charge la hiérarchisation du cloud" .
|
|
Si vous prévoyez de configurer Cloud Tiering pour utiliser une classe de stockage à moindre coût vers laquelle vos données hiérarchisées seront transférées après un certain nombre de jours, vous ne devez sélectionner aucune règle de cycle de vie lors de la configuration du compartiment dans votre compte AWS. Le Cloud Tiering gère les transitions du cycle de vie. |
Configurer les autorisations S3
Vous devrez configurer deux ensembles d’autorisations :
-
Autorisations pour l'agent afin qu'il puisse créer et gérer le compartiment S3.
-
Autorisations pour le cluster ONTAP sur site afin qu’il puisse lire et écrire des données dans le bucket S3.
-
Autorisations de l'agent de console :
-
Confirmez cela "ces autorisations S3" font partie du rôle IAM qui confère à l'agent les autorisations nécessaires. Ils auraient dû être inclus par défaut lors du premier déploiement de l'agent. Sinon, vous devrez ajouter les autorisations manquantes. Voir le "Documentation AWS : Modification des politiques IAM" pour les instructions.
-
Le compartiment par défaut créé par Cloud Tiering a pour préfixe « fabric-pool ». Si vous souhaitez utiliser un préfixe différent pour votre compartiment, vous devrez personnaliser les autorisations avec le nom souhaité. Dans les autorisations S3, vous verrez une ligne
"Resource": ["arn:aws:s3:::fabric-pool*"]. Vous devrez remplacer « fabric-pool » par le préfixe que vous souhaitez utiliser. Par exemple, si vous souhaitez utiliser « tiering-1 » comme préfixe pour vos compartiments, vous modifierez cette ligne comme suit :"Resource": ["arn:aws:s3:::tiering-1*"].Si vous souhaitez utiliser un préfixe différent pour les compartiments que vous utiliserez pour d'autres clusters dans cette même organisation NetApp Console , vous pouvez ajouter une autre ligne avec le préfixe pour les autres compartiments. Par exemple:
"Resource": ["arn:aws:s3:::tiering-1*"]
"Resource": ["arn:aws:s3:::tiering-2*"]
Si vous créez votre propre compartiment et que vous n'utilisez pas de préfixe standard, vous devez modifier cette ligne comme suit :
"Resource": ["arn:aws:s3:::*"]afin que chaque compartiment soit reconnu. Cependant, cela risque d'exposer tous vos compartiments au lieu de ceux que vous avez conçus pour contenir les données inactives de vos volumes. -
-
Autorisations du cluster :
-
Lorsque vous activez le service, l'assistant de gestion des niveaux vous invitera à saisir une clé d'accès et une clé secrète. Ces informations d’identification sont transmises au cluster ONTAP afin ONTAP puisse hiérarchiser les données vers le compartiment S3. Pour cela, vous devrez créer un utilisateur IAM disposant des autorisations suivantes :
"s3:ListAllMyBuckets", "s3:ListBucket", "s3:GetBucketLocation", "s3:GetObject", "s3:PutObject", "s3:DeleteObject"Voir le "Documentation AWS : Création d'un rôle pour déléguer des autorisations à un utilisateur IAM" pour plus de détails.
-
-
Créez ou localisez la clé d'accès.
Cloud Tiering transmet la clé d'accès au cluster ONTAP . Les identifiants ne sont pas stockés dans le service Cloud Tiering.
Configurez votre système pour une connexion privée à l'aide d'une interface de point de terminaison VPC
Si vous prévoyez d'utiliser une connexion Internet publique standard, toutes les autorisations sont configurées par l'agent et vous n'avez rien d'autre à faire. Ce type de connexion est illustré dans lepremier diagramme ci-dessus .
Si vous souhaitez disposer d'une connexion plus sécurisée via Internet entre votre centre de données sur site et le VPC, vous pouvez sélectionner une connexion AWS PrivateLink dans l'assistant d'activation de la hiérarchisation. Cela est nécessaire si vous prévoyez d'utiliser un VPN ou AWS Direct Connect pour connecter votre système sur site via une interface de point de terminaison VPC qui utilise une adresse IP privée. Ce type de connexion est illustré dans ledeuxième diagramme ci-dessus .
-
Créez une configuration de point de terminaison d'interface à l'aide de la console Amazon VPC ou de la ligne de commande. "Voir les détails sur l'utilisation d'AWS PrivateLink pour Amazon S3" .
-
Modifiez la configuration du groupe de sécurité associé à l'agent. Vous devez modifier la politique en « Personnalisé » (à partir de « Accès complet ») et vous devezajouter les autorisations requises pour l'agent S3 comme indiqué précédemment.
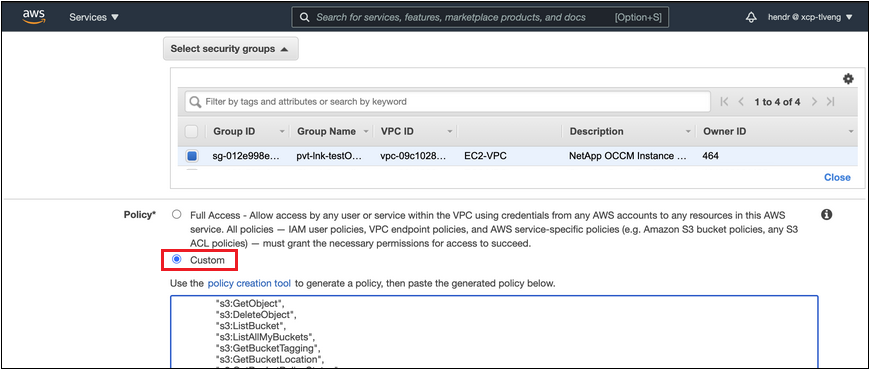
Si vous utilisez le port 80 (HTTP) pour communiquer avec le point de terminaison privé, vous êtes prêt. Vous pouvez activer la hiérarchisation cloud sur le cluster dès maintenant.
Si vous utilisez le port 443 (HTTPS) pour la communication avec le point de terminaison privé, vous devez copier le certificat du point de terminaison VPC S3 et l'ajouter à votre cluster ONTAP , comme indiqué dans les 4 étapes suivantes.
-
Obtenez le nom DNS du point de terminaison à partir de la console AWS.
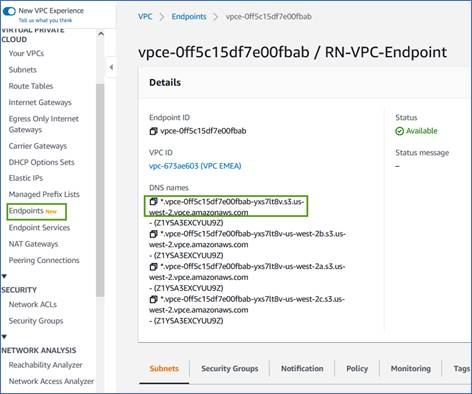
-
Obtenez le certificat à partir du point de terminaison VPC S3. Vous faites cela en "se connecter à la machine virtuelle qui héberge l'agent" et exécutez la commande suivante. Lors de la saisie du nom DNS du point de terminaison, ajoutez « bucket » au début, en remplaçant le « * » :
[ec2-user@ip-10-160-4-68 ~]$ openssl s_client -connect bucket.vpce-0ff5c15df7e00fbab-yxs7lt8v.s3.us-west-2.vpce.amazonaws.com:443 -showcerts -
À partir de la sortie de cette commande, copiez les données du certificat S3 (toutes les données comprises entre les balises BEGIN / END CERTIFICATE incluses) :
Certificate chain 0 s:/CN=s3.us-west-2.amazonaws.com` i:/C=US/O=Amazon/OU=Server CA 1B/CN=Amazon -----BEGIN CERTIFICATE----- MIIM6zCCC9OgAwIBAgIQA7MGJ4FaDBR8uL0KR3oltTANBgkqhkiG9w0BAQsFADBG … … GqvbOz/oO2NWLLFCqI+xmkLcMiPrZy+/6Af+HH2mLCM4EsI2b+IpBmPkriWnnxo= -----END CERTIFICATE----- -
Connectez-vous à l'interface de ligne de commande du cluster ONTAP et appliquez le certificat que vous avez copié à l'aide de la commande suivante (remplacez le nom de votre propre machine virtuelle de stockage) :
cluster1::> security certificate install -vserver <svm_name> -type server-ca Please enter Certificate: Press <Enter> when done
Stockez les données inactives de votre premier cluster sur Amazon S3.
Une fois votre environnement AWS préparé, commencez à hiérarchiser les données inactives de votre premier cluster.
-
Une clé d'accès AWS pour un utilisateur IAM disposant des autorisations S3 requises.
-
Sélectionnez le système ONTAP sur site.
-
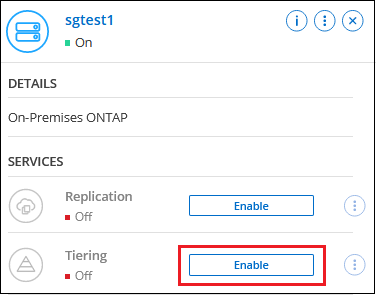
Cliquez sur Activer pour la hiérarchisation cloud dans le panneau de droite.
Si la destination de hiérarchisation Amazon S3 existe en tant que système sur la page Systèmes, vous pouvez faire glisser le cluster sur le système pour lancer l'assistant de configuration.
-
Définir le nom du stockage d'objets : Saisissez un nom pour ce stockage d'objets. Il doit être unique par rapport à tout autre stockage d'objets que vous pourriez utiliser avec des agrégats sur ce cluster.
-
Sélectionnez le fournisseur : Sélectionnez Amazon Web Services et sélectionnez Continuer.
-
Remplissez les sections de la page Configuration des niveaux :
-
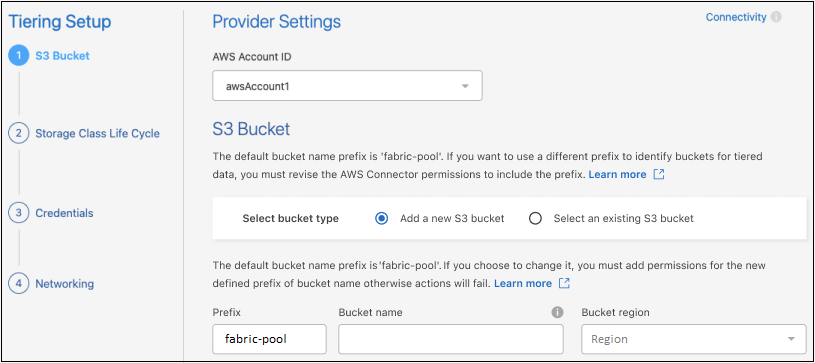
Compartiment S3 : Ajoutez un nouveau compartiment S3 ou sélectionnez un compartiment S3 existant, sélectionnez la région du compartiment, puis sélectionnez Continuer.
Lorsque vous utilisez un agent sur site, vous devez saisir l'ID du compte AWS qui donne accès au compartiment S3 existant ou au nouveau compartiment S3 qui sera créé.
Le préfixe fabric-pool est utilisé par défaut car la stratégie IAM de l'agent permet à l'instance d'effectuer des actions S3 sur des compartiments nommés avec ce préfixe exact. Par exemple, vous pourriez nommer le compartiment S3 fabric-pool-AFF1, où AFF1 est le nom du cluster. Vous pouvez également définir le préfixe des compartiments utilisés pour la hiérarchisation. Voirconfiguration des autorisations S3 pour vous assurer que vous disposez des autorisations AWS qui reconnaissent tout préfixe personnalisé que vous prévoyez d'utiliser.
-
Classe de stockage : Le stockage hiérarchisé dans le cloud gère les transitions du cycle de vie de vos données hiérarchisées. Les données sont initialement stockées dans la classe Standard, mais vous pouvez créer une règle pour appliquer une classe de stockage différente aux données après un certain nombre de jours.
Sélectionnez la classe de stockage S3 vers laquelle vous souhaitez transférer les données hiérarchisées et le nombre de jours avant que les données ne soient affectées à cette classe, puis sélectionnez Continuer. Par exemple, la capture d'écran ci-dessous montre que les données hiérarchisées sont affectées à la classe Standard-IA à partir de la classe Standard après 45 jours de stockage d'objets.
Si vous choisissez Conserver les données dans cette classe de stockage, les données restent dans la classe de stockage Standard et aucune règle n'est appliquée. "Voir les classes de stockage prises en charge".
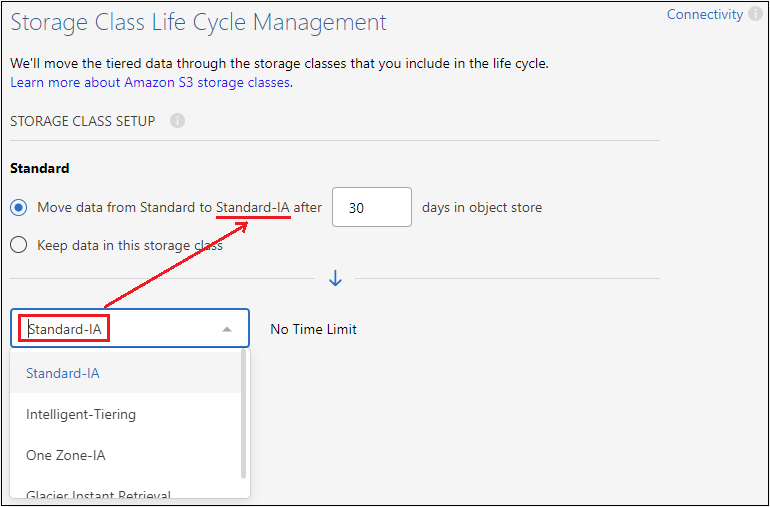
Notez que la règle de cycle de vie s'applique à tous les objets du compartiment sélectionné.
-
Identifiants : Saisissez l’ID de clé d’accès et la clé secrète d’un utilisateur IAM disposant des autorisations S3 requises, puis sélectionnez Continuer.
L'utilisateur IAM doit appartenir au même compte AWS que le compartiment que vous avez sélectionné ou créé sur la page Compartiment S3.
-
Réseau : Saisissez les informations de connexion au réseau et sélectionnez Continuer.
Sélectionnez l'espace IP dans le cluster ONTAP où résident les volumes que vous souhaitez hiérarchiser. Les LIF inter-clusters de cet espace IP doivent disposer d'un accès Internet sortant afin de pouvoir se connecter au stockage d'objets de votre fournisseur de cloud.
Vous pouvez également choisir d'utiliser un AWS PrivateLink que vous avez préalablement configuré. Consultez les informations de configuration ci-dessus. Une boîte de dialogue s'affiche pour vous guider tout au long de la configuration du point de terminaison.
Vous pouvez également définir la bande passante réseau disponible pour le transfert des données inactives vers le stockage d'objets en définissant le « débit de transfert maximal ». Sélectionnez le bouton radio Limité et entrez la bande passante maximale pouvant être utilisée, ou sélectionnez Illimité pour indiquer qu'il n'y a pas de limite.
-
-
Sur la page Tier Volumes, sélectionnez les volumes pour lesquels vous souhaitez configurer la hiérarchisation et lancez la page Tiering Policy :
-
Pour sélectionner tous les volumes, cochez la case dans la ligne du titre (
 ) et sélectionnez Configurer les volumes.
) et sélectionnez Configurer les volumes. -
Pour sélectionner plusieurs volumes, cochez la case correspondant à chaque volume (
 ) et sélectionnez Configurer les volumes.
) et sélectionnez Configurer les volumes. -
Pour sélectionner un seul volume, sélectionnez la ligne (ou
 icône) pour le volume.
icône) pour le volume.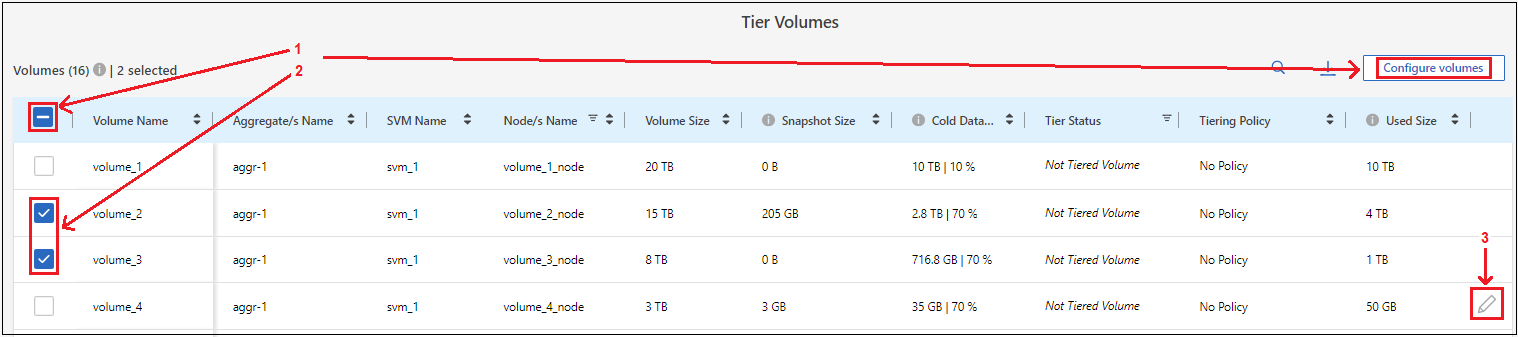
-
-
Dans la boîte de dialogue Stratégie de hiérarchisation, sélectionnez une stratégie de hiérarchisation, ajustez éventuellement les jours de refroidissement pour les volumes sélectionnés, puis sélectionnez Appliquer.
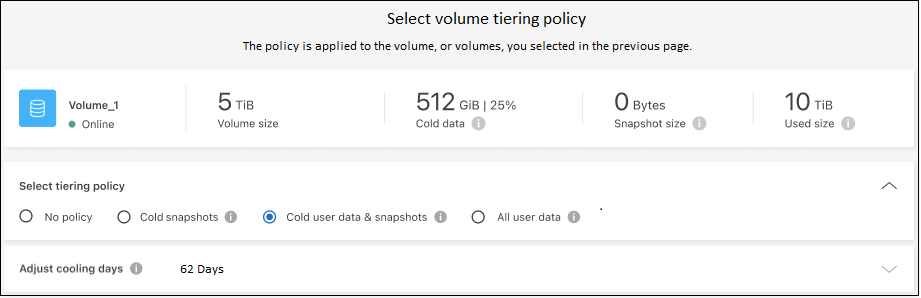
Vous avez configuré avec succès la hiérarchisation des données des volumes du cluster vers le stockage d'objets S3.
Vous pouvez consulter les informations relatives aux données actives et inactives du cluster. "Apprenez-en davantage sur la gestion de vos paramètres de hiérarchisation".
Vous pouvez également créer un stockage d'objets supplémentaire dans les cas où vous souhaiteriez hiérarchiser les données de certains agrégats d'un cluster vers différents stockages d'objets. Ou si vous prévoyez d'utiliser FabricPool Mirroring, où vos données hiérarchisées sont répliquées sur un stockage d'objets supplémentaire. "Apprenez-en davantage sur la gestion des magasins d'objets".