

En savoir plus sur la NetApp Data Classification
 Suggérer des modifications
Suggérer des modifications
NetApp Data Classification est un service de gouvernance des données pour la NetApp Console qui analyse vos sources de données d'entreprise sur site et dans le cloud pour mapper et classer les données et identifier les informations privées. Cela peut vous aider à réduire vos risques de sécurité et de conformité, à diminuer vos coûts de stockage et à vous aider dans vos projets de migration de données.

|
À partir de la version 1.31, la classification des données est disponible en tant que fonctionnalité principale dans la NetApp Console. Il n'y a pas de frais supplémentaires. Aucune licence de classification ni abonnement n'est requis. + Si vous avez utilisé la version héritée 1.30 ou une version antérieure, cette version est disponible jusqu'à l'expiration de votre abonnement. |
NetApp Console
La classification des données est accessible via la NetApp Console.
La NetApp Console fournit une gestion centralisée des services de stockage et de données NetApp dans les environnements sur site et cloud à l'échelle de l'entreprise. La console est requise pour accéder aux services de données NetApp et les utiliser. En tant qu'interface de gestion, il vous permet de gérer de nombreuses ressources de stockage à partir d'une seule interface. Les administrateurs de console peuvent contrôler l’accès au stockage et aux services pour tous les systèmes de l’entreprise.
Vous n'avez pas besoin de licence ni d'abonnement pour commencer à utiliser NetApp Console et vous n'encourez des frais que lorsque vous devez déployer des agents de console dans votre cloud pour garantir la connectivité à vos systèmes de stockage ou à vos services de données NetApp . Cependant, certains services de données NetApp accessibles depuis la console sont sous licence ou basés sur un abonnement.
En savoir plus sur le"NetApp Console" .
Caractéristiques
La classification des données utilise l'intelligence artificielle (IA), le traitement du langage naturel (NLP) et l'apprentissage automatique (ML) pour comprendre le contenu qu'elle analyse afin d'extraire des entités et de catégoriser le contenu en conséquence. Cela permet à la classification des données de fournir les domaines de fonctionnalités suivants.
La classification des données fournit plusieurs outils qui peuvent vous aider dans vos efforts de conformité. Vous pouvez utiliser la classification des données pour :
-
Identifier les informations personnelles identifiables (PII).
-
Identifiez un large éventail d’informations personnelles sensibles comme l’exigent les réglementations de confidentialité GDPR, CCPA, PCI et HIPAA.
-
Répondre aux demandes d’accès aux données des personnes concernées (DSAR) en fonction du nom ou de l’adresse e-mail.
La classification des données permet d’identifier les données potentiellement susceptibles d’être consultées à des fins criminelles. Vous pouvez utiliser la classification des données pour :
-
Identifiez tous les fichiers et répertoires (partages et dossiers) avec des autorisations ouvertes qui sont exposés à l’ensemble de votre organisation ou au public.
-
Identifiez les données sensibles qui résident en dehors de l’emplacement initial dédié.
-
Respecter les politiques de conservation des données.
-
Utilisez Policies pour détecter automatiquement les nouveaux problèmes de sécurité afin que le personnel de sécurité puisse agir immédiatement.
La classification des données fournit des outils qui peuvent vous aider à déterminer le coût total de possession (TCO) de votre stockage. Vous pouvez utiliser la classification des données pour :
-
Augmentez l’efficacité du stockage en identifiant les données en double ou non liées à l’entreprise.
-
Réduisez les coûts de stockage en identifiant les données inactives que vous pouvez hiérarchiser vers un stockage d'objets moins coûteux. "En savoir plus sur la hiérarchisation des systèmes Cloud Volumes ONTAP" . "En savoir plus sur la hiérarchisation des systèmes ONTAP sur site" .
Systèmes et sources de données pris en charge
La classification des données peut scanner et analyser des données structurées et non structurées provenant des types de systèmes et de sources de données suivants :
Systèmes
-
Amazon FSx for NetApp ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP (déployé dans AWS, Azure ou GCP)
-
Google Cloud NetApp Volumes
-
Clusters ONTAP sur site
-
StorageGRID
Sources de données
-
Partages de fichiers NetApp
-
Bases de données:
-
Service de base de données relationnelle Amazon (Amazon RDS)
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SAP HANA
-
Serveur SQL (MSSQL)
-
La classification des données prend en charge les versions NFS 3.x, 4.0 et 4.1, ainsi que les versions CIFS 1.x, 2.0, 2.1 et 3.0.
Coût
La classification des données est gratuite. Aucune licence de classification ni abonnement payant n'est requis.
Coûts d'infrastructure
-
L'installation de Data Classification dans le cloud nécessite le déploiement d'une instance cloud, ce qui entraîne des frais de la part du fournisseur cloud où elle est déployée. Voir le type d'instance déployé pour chaque fournisseur de cloud . L’installation de Data Classification sur un système local est gratuite.
-
La classification des données nécessite que vous ayez déployé un agent de console. Dans de nombreux cas, vous disposez déjà d’un agent de console en raison d’autres stockages et services que vous utilisez dans la console. L'instance de l'agent de console entraîne des frais auprès du fournisseur de cloud où elle est déployée. Voir le "type d'instance déployée pour chaque fournisseur de cloud" . L’installation de l’agent de console sur un système local est gratuite.
Coûts de transfert de données
Les coûts de transfert de données dépendent de votre configuration. Si l'instance de classification des données et la source de données se trouvent dans la même zone de disponibilité et la même région, il n'y a aucun coût de transfert de données. Mais si la source de données, comme un système Cloud Volumes ONTAP , se trouve dans une zone de disponibilité ou une région différente, les frais de transfert de données vous seront facturés par votre fournisseur de cloud. Consultez ces liens pour plus de détails :
L'instance de classification des données
Lorsque vous déployez la classification des données dans le cloud, la console déploie l’instance dans le même sous-réseau que l’agent de la console. "En savoir plus sur l’agent de console."
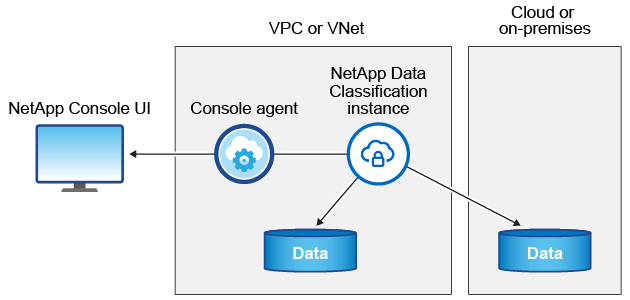
Notez ce qui suit à propos de l’instance par défaut :
-
Dans AWS, la classification des données s'exécute sur un "instance m6i.4xlarge" avec un disque GP2 de 500 Gio. L'image du système d'exploitation est Amazon Linux 2.
-
Dans Azure, la classification des données s'exécute sur un"VM Standard_D16s_v3" avec un disque de 500 Gio. L'image du système d'exploitation est Ubuntu 22.04.
-
Dans GCP, la classification des données s'exécute sur un"n2-standard-16 VM" avec un disque persistant standard de 500 Gio. L'image du système d'exploitation est Ubuntu 22.04.
-
Dans les régions où l’instance par défaut n’est pas disponible, la classification des données s’exécute sur une instance alternative. "Voir les types d'instances alternatifs" .
-
L'instance est nommée CloudCompliance avec un hachage généré (UUID) concaténé. Par exemple : CloudCompliance-16bb6564-38ad-4080-9a92-36f5fd2f71c7
-
Une seule instance de classification des données est déployée par agent de console.
Vous pouvez également déployer la classification des données sur un hôte Linux dans vos locaux ou sur un hôte chez votre fournisseur de cloud préféré. Le logiciel fonctionne exactement de la même manière, quelle que soit la méthode d'installation choisie. Les mises à niveau du logiciel de classification des données sont automatisées tant que l'instance dispose d'un accès Internet.

|
L'instance doit rester en cours d'exécution en permanence, car la classification des données analyse en permanence les données. |
Déployer sur différents types d'instances
Consultez les spécifications suivantes pour les types d’instances :
| Taille du système | Spécifications | Limites |
|---|---|---|
Très grand |
32 processeurs, 128 Go de RAM, 1 To de SSD |
Peut numériser jusqu'à 500 millions de fichiers. |
Grand (par défaut) |
16 processeurs, 64 Go de RAM, 500 Go de SSD |
Peut numériser jusqu'à 250 millions de fichiers. |
Comment fonctionne l'analyse de classification des données
À un niveau élevé, l’analyse de classification des données fonctionne comme ceci :
-
Vous déployez une instance de classification des données dans la console.
-
Vous activez les analyses sur une ou plusieurs sources de données.
-
La classification des données analyse les données à l’aide d’un processus d’apprentissage de l’IA.
-
Vous utilisez les tableaux de bord et les outils de reporting fournis pour vous aider dans vos efforts de conformité et de gouvernance.
Une fois que vous avez activé la classification des données et sélectionné les référentiels que vous souhaitez analyser (il s'agit des volumes, des schémas de base de données ou d'autres données utilisateur), l'analyse des données commence immédiatement pour identifier les données personnelles et sensibles. Dans la plupart des cas, vous devez vous concentrer sur l’analyse des données de production en direct plutôt que sur les sauvegardes, les miroirs ou les sites de reprise après sinistre. Ensuite, la classification des données cartographie vos données organisationnelles, catégorise chaque fichier et identifie et extrait les entités et les modèles prédéfinis dans les données. Le résultat de l’analyse est un index des informations personnelles, des informations personnelles sensibles, des catégories de données et des types de fichiers.
La classification des données se connecte aux données comme n’importe quel autre client en montant des volumes NFS et CIFS. Les volumes NFS sont automatiquement accessibles en lecture seule, tandis que vous devez fournir les informations d'identification Active Directory pour analyser les volumes CIFS.
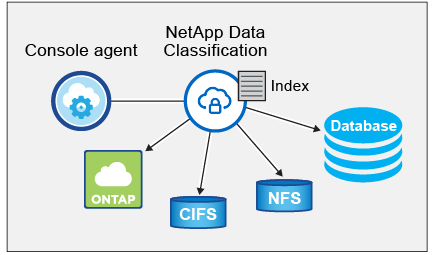
Après l'analyse initiale, Data Classification analyse en continu vos données de manière circulaire pour détecter les modifications incrémentielles. C'est pourquoi il est important de maintenir l'instance en cours d'exécution.
Vous pouvez activer et désactiver les analyses au niveau du volume ou au niveau du schéma de base de données.

|
La classification des données n’impose pas de limite à la quantité de données qu’elle peut analyser. Chaque agent de console prend en charge l'analyse et l'affichage de 500 Tio de données. Pour scanner plus de 500 Tio de données,"installer un autre agent de console" alors"déployer une autre instance de classification des données" . + L'interface utilisateur de la console affiche les données d'un seul connecteur. Pour obtenir des conseils sur l'affichage des données de plusieurs agents de console, consultez"Travailler avec plusieurs agents de console" . |
Cartographie et analyses complètes
Vous pouvez effectuer deux types d’analyses dans la classification des données :
-
Les analyses cartographiques uniquement offrent un aperçu général de vos données et sont effectuées sur des sources de données sélectionnées. Les analyses cartographiques uniquement prennent moins de temps que les analyses complètes car elles n'accèdent pas aux fichiers pour voir les données à l'intérieur. Vous pouvez commencer par cela afin d'identifier des axes de recherche, puis effectuer une analyse complète de ces axes.
-
L'analyse complète permet une analyse approfondie de vos données. Une analyse complète inclut une analyse cartographique uniquement et une classification des données à l'intérieur des fichiers.
Pour une analyse détaillée des différences entre les analyses map-only et les analyses complètes, voir "Quelle est la différence entre les analyses de cartographie et de classification ?".
Informations catégorisées par la classification des données
La classification des données collecte, indexe et attribue des catégories aux données suivantes :
-
Métadonnées standard sur les fichiers : le type de fichier, sa taille, ses dates de création et de modification, etc.
-
Données personnelles : Informations personnelles identifiables (PII) telles que les adresses e-mail, les numéros d'identification ou les numéros de carte de crédit, que Data Classification identifie à l'aide de mots, de chaînes et de modèles spécifiques dans les fichiers. "En savoir plus sur les données personnelles" .
-
Données personnelles sensibles : Types particuliers d'informations personnelles sensibles (IPS), telles que les données de santé, l'origine ethnique ou les opinions politiques, telles que définies par le Règlement général sur la protection des données (RGPD) et d'autres réglementations sur la confidentialité. "En savoir plus sur les données personnelles sensibles" .
-
Catégories : La classification des données prend les données numérisées et les divise en différents types de catégories. Les catégories sont des sujets basés sur l'analyse par l'IA du contenu et des métadonnées de chaque fichier. "En savoir plus sur les catégories".
-
Reconnaissance d'entité de nom : la classification des données utilise l'IA pour extraire les noms naturels des personnes à partir de documents. "En savoir plus sur la réponse aux demandes d'accès aux données des personnes concernées" .
Présentation du réseau
Data Classification déploie un serveur unique, ou cluster, où vous le souhaitez : dans le cloud ou sur site. Les serveurs se connectent via des protocoles standard aux sources de données et indexent les résultats dans un cluster Elasticsearch, qui est également déployé sur les mêmes serveurs. Cela permet la prise en charge des environnements multicloud, cross-cloud, cloud privé et sur site.
La console déploie l’instance de classification des données avec un groupe de sécurité qui active les connexions HTTP entrantes à partir de l’agent de la console.
Lorsque vous utilisez la console en mode SaaS, la connexion à la console est effectuée via HTTPS et les données privées envoyées entre votre navigateur et l'instance de classification des données sont sécurisées par un cryptage de bout en bout à l'aide de TLS 1.2, ce qui signifie que NetApp et des tiers ne peuvent pas les lire.
Les règles sortantes sont complètement ouvertes. Un accès Internet est nécessaire pour installer et mettre à niveau le logiciel de classification des données et pour envoyer des mesures d'utilisation.
Si vous avez des exigences réseau strictes,"en savoir plus sur les points de terminaison contactés par la classification des données" .