

TR-4931 : Reprise après sinistre avec VMware Cloud sur Amazon Web Services et Guest Connect
 Suggérer des modifications
Suggérer des modifications
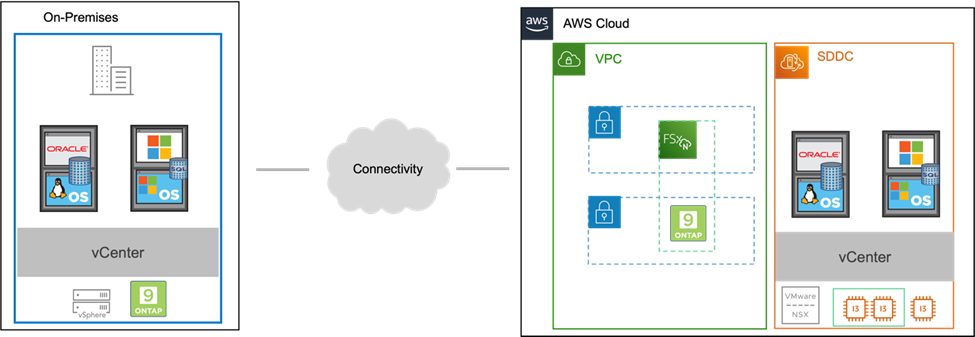
Un environnement et un plan de reprise après sinistre (DR) éprouvés sont essentiels pour les organisations afin de garantir que les applications critiques pour l'entreprise peuvent être rapidement restaurées en cas de panne majeure. Cette solution se concentre sur la démonstration de cas d’utilisation DR en mettant l’accent sur les technologies VMware et NetApp , à la fois sur site et avec VMware Cloud sur AWS.
Aperçu
NetApp possède une longue histoire d’intégration avec VMware, comme en témoignent les dizaines de milliers de clients qui ont choisi NetApp comme partenaire de stockage pour leur environnement virtualisé. Cette intégration se poursuit avec des options connectées aux invités dans le cloud et des intégrations récentes avec les magasins de données NFS également. Cette solution se concentre sur le cas d’utilisation communément appelé stockage connecté aux invités.
Dans le stockage connecté à l'invité, le VMDK invité est déployé sur une banque de données provisionnée par VMware et les données d'application sont hébergées sur iSCSI ou NFS et mappées directement sur la machine virtuelle. Les applications Oracle et MS SQL sont utilisées pour démontrer un scénario de reprise après sinistre, comme illustré dans la figure suivante.
Hypothèses, prérequis et aperçu des composants
Avant de déployer cette solution, examinez la présentation des composants, les prérequis requis pour déployer la solution et les hypothèses formulées lors de la documentation de cette solution.
Exécution de la reprise après sinistre avec SnapCenter
Dans cette solution, SnapCenter fournit des instantanés cohérents avec les applications pour les données d'application SQL Server et Oracle. Cette configuration, associée à la technologie SnapMirror , permet une réplication de données à haut débit entre notre cluster AFF sur site et notre cluster FSx ONTAP . De plus, Veeam Backup & Replication fournit des fonctionnalités de sauvegarde et de restauration pour nos machines virtuelles.
Dans cette section, nous couvrons la configuration de SnapCenter, SnapMirror et Veeam pour la sauvegarde et la restauration.
Les sections suivantes couvrent la configuration et les étapes nécessaires pour effectuer un basculement sur le site secondaire :
Configurer les relations et les calendriers de conservation de SnapMirror
SnapCenter peut mettre à jour les relations SnapMirror au sein du système de stockage principal (primaire > miroir) et vers les systèmes de stockage secondaires (primaire > coffre-fort) à des fins d'archivage et de conservation à long terme. Pour ce faire, vous devez établir et initialiser une relation de réplication de données entre un volume de destination et un volume source à l’aide de SnapMirror.
Les systèmes ONTAP source et de destination doivent se trouver dans des réseaux appairés à l'aide de l'appairage Amazon VPC, d'une passerelle de transit, d'AWS Direct Connect ou d'un VPN AWS.
Les étapes suivantes sont requises pour configurer les relations SnapMirror entre un système ONTAP sur site et FSx ONTAP:

|
Se référer à la "FSx ONTAP – Guide de l'utilisateur ONTAP" pour plus d'informations sur la création de relations SnapMirror avec FSx. |
Enregistrer les interfaces logiques intercluster source et destination
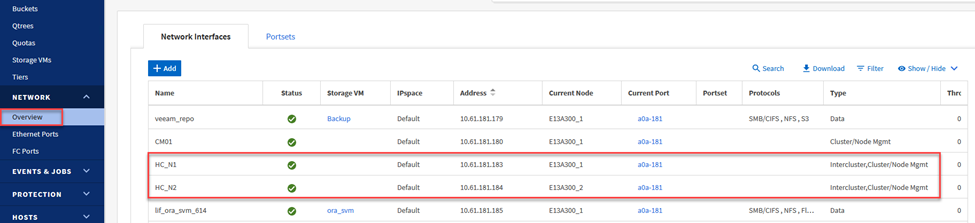
Pour le système ONTAP source résidant sur site, vous pouvez récupérer les informations LIF inter-cluster à partir du Gestionnaire système ou de l'interface de ligne de commande.
-
Dans ONTAP System Manager, accédez à la page Présentation du réseau et récupérez les adresses IP de type : Intercluster qui sont configurées pour communiquer avec le VPC AWS sur lequel FSx est installé.
-
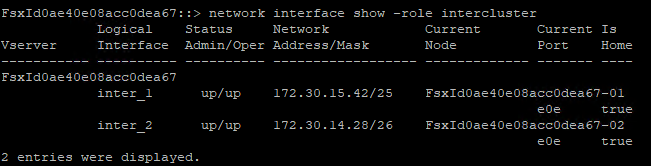
Pour récupérer les adresses IP intercluster pour FSx, connectez-vous à la CLI et exécutez la commande suivante :
FSx-Dest::> network interface show -role intercluster
Établir un peering de cluster entre ONTAP et FSx
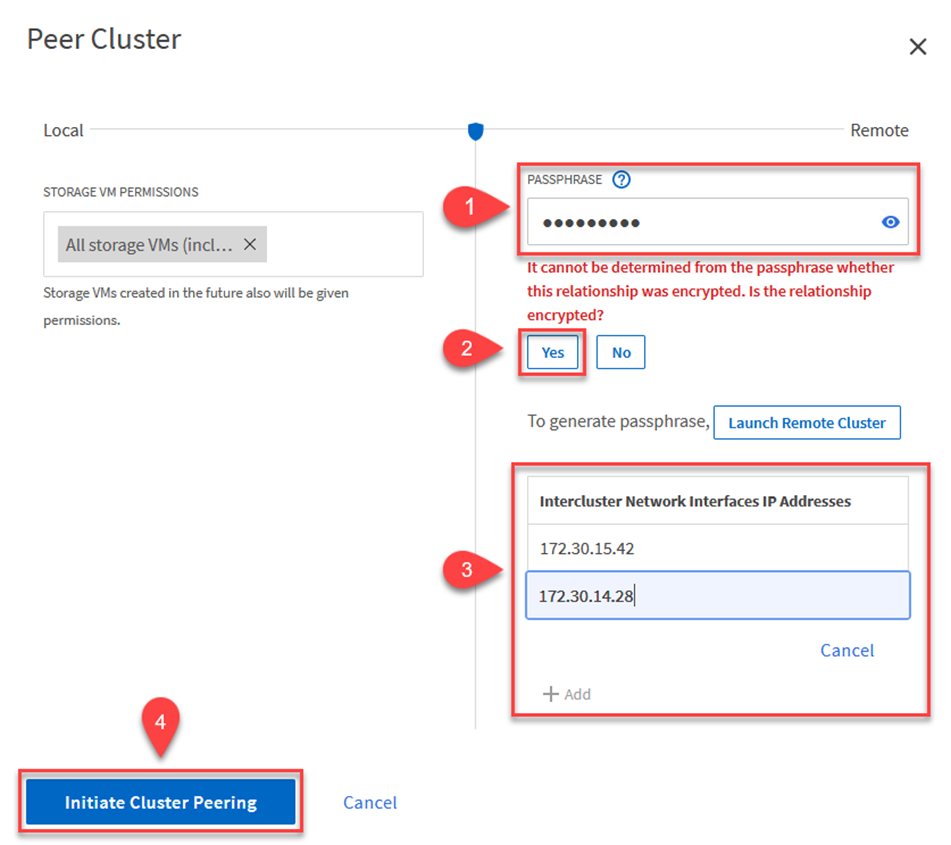
Pour établir un peering de cluster entre les clusters ONTAP , une phrase secrète unique entrée dans le cluster ONTAP initiateur doit être confirmée dans l'autre cluster homologue.
-
Configurer le peering sur le cluster FSx de destination à l'aide de
cluster peer createcommande. Lorsque vous y êtes invité, entrez une phrase secrète unique qui sera utilisée ultérieurement sur le cluster source pour finaliser le processus de création.FSx-Dest::> cluster peer create -address-family ipv4 -peer-addrs source_intercluster_1, source_intercluster_2 Enter the passphrase: Confirm the passphrase:
-
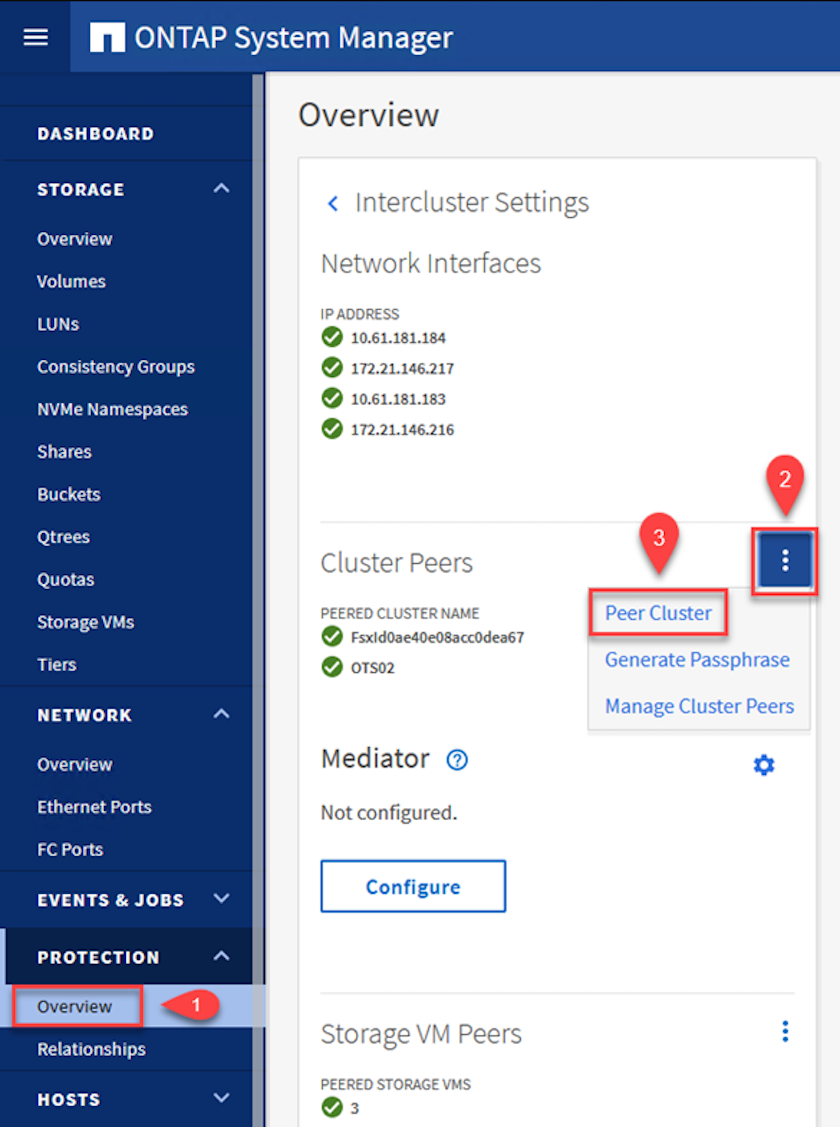
Au niveau du cluster source, vous pouvez établir la relation entre homologues du cluster à l'aide d' ONTAP System Manager ou de l'interface de ligne de commande. Depuis ONTAP System Manager, accédez à Protection > Présentation et sélectionnez Cluster homologue.
-
Dans la boîte de dialogue Cluster homologue, remplissez les informations requises :
-
Saisissez la phrase secrète utilisée pour établir la relation de cluster homologue sur le cluster FSx de destination.
-
Sélectionner
Yespour établir une relation cryptée. -
Saisissez la ou les adresses IP LIF intercluster du cluster FSx de destination.
-
Cliquez sur Initier l'appairage de cluster pour finaliser le processus.
-
-
Vérifiez l’état de la relation entre les homologues du cluster à partir du cluster FSx avec la commande suivante :
FSx-Dest::> cluster peer show

Établir une relation de peering SVM
L’étape suivante consiste à configurer une relation SVM entre les machines virtuelles de stockage de destination et source qui contiennent les volumes qui seront dans les relations SnapMirror .
-
À partir du cluster FSx source, utilisez la commande suivante depuis la CLI pour créer la relation homologue SVM :
FSx-Dest::> vserver peer create -vserver DestSVM -peer-vserver Backup -peer-cluster OnPremSourceSVM -applications snapmirror
-
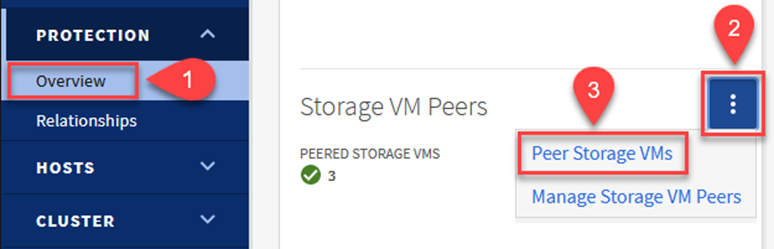
À partir du cluster ONTAP source, acceptez la relation de peering avec ONTAP System Manager ou l'interface de ligne de commande.
-
Depuis ONTAP System Manager, accédez à Protection > Présentation et sélectionnez Machines virtuelles de stockage homologues sous Homologues de machines virtuelles de stockage.
-
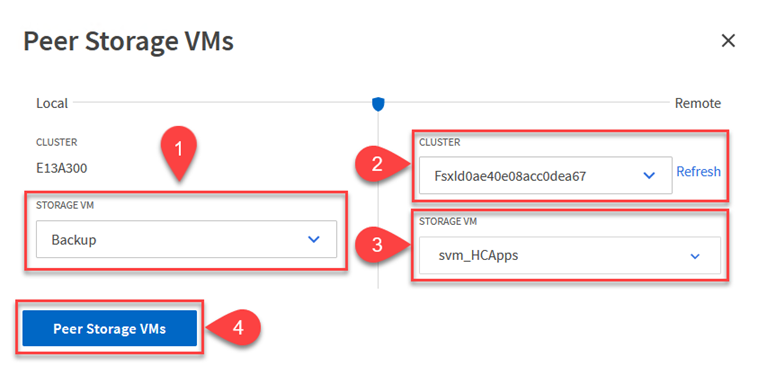
Dans la boîte de dialogue de la machine virtuelle de stockage homologue, remplissez les champs obligatoires :
-
La machine virtuelle de stockage source
-
Le cluster de destination
-
La machine virtuelle de stockage de destination
-
-
Cliquez sur « Appairer les machines virtuelles de stockage » pour terminer le processus d’appairage SVM.
Créer une politique de conservation des instantanés
SnapCenter gère les planifications de conservation pour les sauvegardes qui existent sous forme de copies instantanées sur le système de stockage principal. Ceci est établi lors de la création d'une politique dans SnapCenter. SnapCenter ne gère pas les politiques de rétention pour les sauvegardes conservées sur des systèmes de stockage secondaires. Ces politiques sont gérées séparément via une politique SnapMirror créée sur le cluster FSx secondaire et associée aux volumes de destination qui sont dans une relation SnapMirror avec le volume source.
Lors de la création d'une politique SnapCenter , vous avez la possibilité de spécifier une étiquette de politique secondaire qui est ajoutée à l'étiquette SnapMirror de chaque snapshot généré lorsqu'une sauvegarde SnapCenter est effectuée.
|
|
Sur le stockage secondaire, ces étiquettes correspondent aux règles de stratégie associées au volume de destination afin d'appliquer la conservation des instantanés. |
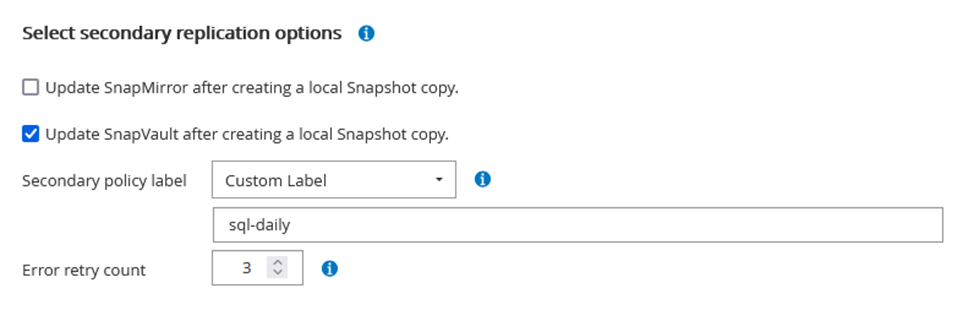
L'exemple suivant montre une étiquette SnapMirror présente sur tous les instantanés générés dans le cadre d'une stratégie utilisée pour les sauvegardes quotidiennes de notre base de données SQL Server et de nos volumes de journaux.
Pour plus d'informations sur la création de politiques SnapCenter pour une base de données SQL Server, consultez le "Documentation de SnapCenter" .
Vous devez d’abord créer une stratégie SnapMirror avec des règles qui dictent le nombre de copies d’instantanés à conserver.
-
Créez la politique SnapMirror sur le cluster FSx.
FSx-Dest::> snapmirror policy create -vserver DestSVM -policy PolicyName -type mirror-vault -restart always
-
Ajoutez des règles à la politique avec des étiquettes SnapMirror qui correspondent aux étiquettes de politique secondaires spécifiées dans les politiques SnapCenter .
FSx-Dest::> snapmirror policy add-rule -vserver DestSVM -policy PolicyName -snapmirror-label SnapMirrorLabelName -keep #ofSnapshotsToRetain
Le script suivant fournit un exemple de règle qui pourrait être ajoutée à une politique :
FSx-Dest::> snapmirror policy add-rule -vserver sql_svm_dest -policy Async_SnapCenter_SQL -snapmirror-label sql-ondemand -keep 15
Créez des règles supplémentaires pour chaque étiquette SnapMirror et le nombre d'instantanés à conserver (période de conservation).
Créer des volumes de destination
Pour créer un volume de destination sur FSx qui sera le destinataire des copies instantanées de nos volumes sources, exécutez la commande suivante sur FSx ONTAP:
FSx-Dest::> volume create -vserver DestSVM -volume DestVolName -aggregate DestAggrName -size VolSize -type DP
Créer les relations SnapMirror entre les volumes source et de destination
Pour créer une relation SnapMirror entre un volume source et un volume de destination, exécutez la commande suivante sur FSx ONTAP:
FSx-Dest::> snapmirror create -source-path OnPremSourceSVM:OnPremSourceVol -destination-path DestSVM:DestVol -type XDP -policy PolicyName
Initialiser les relations SnapMirror
Initialiser la relation SnapMirror . Ce processus lance un nouvel instantané généré à partir du volume source et le copie sur le volume de destination.
FSx-Dest::> snapmirror initialize -destination-path DestSVM:DestVol
Déployez et configurez le serveur Windows SnapCenter sur site.
Déployer Windows SnapCenter Server sur site
Cette solution utilise NetApp SnapCenter pour effectuer des sauvegardes cohérentes avec les applications des bases de données SQL Server et Oracle. Associé à Veeam Backup & Replication pour la sauvegarde des VMDK de machines virtuelles, cela fournit une solution complète de reprise après sinistre pour les centres de données sur site et dans le cloud.
Le SnapCenter software est disponible sur le site de support NetApp et peut être installé sur les systèmes Microsoft Windows qui résident dans un domaine ou un groupe de travail. Un guide de planification détaillé et des instructions d'installation sont disponibles sur le site "Centre de documentation NetApp" .
Le SnapCenter software peut être obtenu à l'adresse "ce lien" .
Une fois installé, vous pouvez accéder à la console SnapCenter à partir d'un navigateur Web en utilisant https://Virtual_Cluster_IP_or_FQDN:8146.
Après vous être connecté à la console, vous devez configurer SnapCenter pour la sauvegarde des bases de données SQL Server et Oracle.
Ajouter des contrôleurs de stockage à SnapCenter
Pour ajouter des contrôleurs de stockage à SnapCenter, procédez comme suit :
-
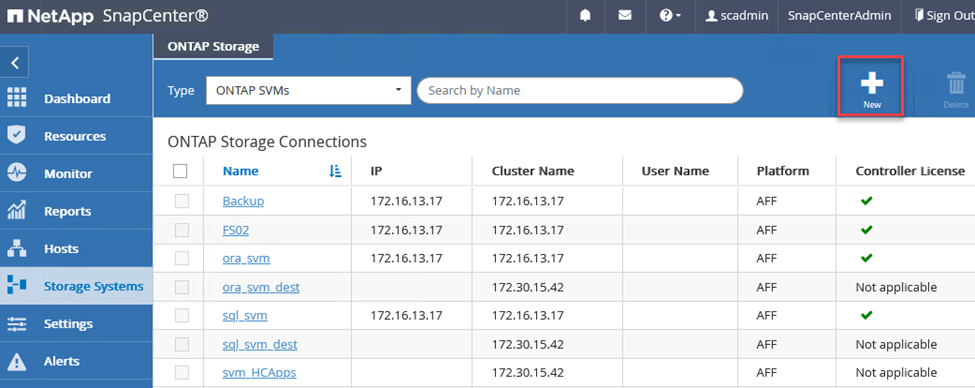
Dans le menu de gauche, sélectionnez Systèmes de stockage, puis cliquez sur Nouveau pour commencer le processus d'ajout de vos contrôleurs de stockage à SnapCenter.
-
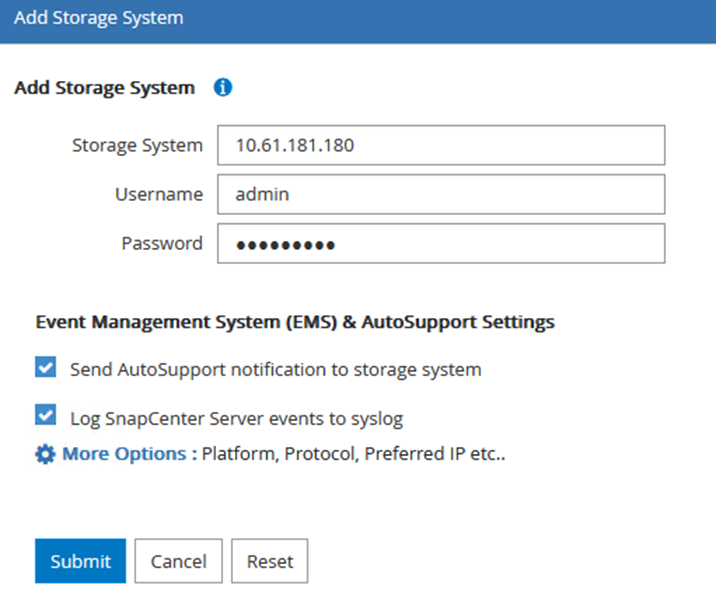
Dans la boîte de dialogue Ajouter un système de stockage, ajoutez l’adresse IP de gestion du cluster ONTAP local sur site, ainsi que le nom d’utilisateur et le mot de passe. Cliquez ensuite sur Soumettre pour commencer la découverte du système de stockage.
-
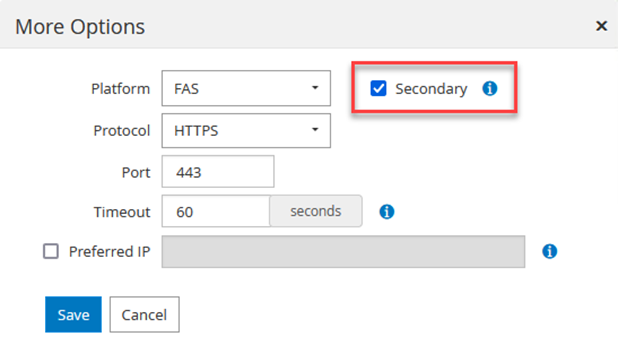
Répétez ce processus pour ajouter le système FSx ONTAP à SnapCenter. Dans ce cas, sélectionnez Plus d'options en bas de la fenêtre Ajouter un système de stockage et cliquez sur la case à cocher Secondaire pour désigner le système FSx comme système de stockage secondaire mis à jour avec des copies SnapMirror ou nos instantanés de sauvegarde principaux.
Pour plus d'informations sur l'ajout de systèmes de stockage à SnapCenter, consultez la documentation à l'adresse "ce lien" .
Ajouter des hôtes à SnapCenter
L’étape suivante consiste à ajouter des serveurs d’applications hôtes à SnapCenter. Le processus est similaire pour SQL Server et Oracle.
-
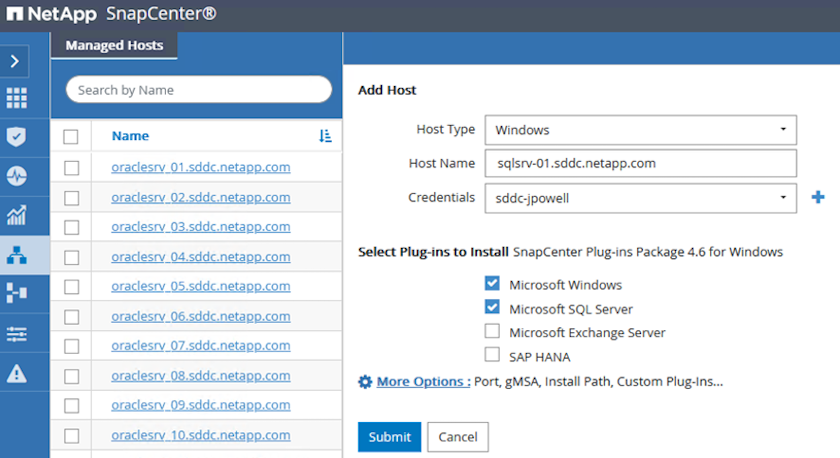
Dans le menu de gauche, sélectionnez Hôtes, puis cliquez sur Ajouter pour commencer le processus d’ajout de contrôleurs de stockage à SnapCenter.
-
Dans la fenêtre Ajouter des hôtes, ajoutez le type d’hôte, le nom d’hôte et les informations d’identification du système hôte. Sélectionnez le type de plug-in. Pour SQL Server, sélectionnez le plug-in Microsoft Windows et Microsoft SQL Server.
-
Pour Oracle, renseignez les champs obligatoires dans la boîte de dialogue « Ajouter un hôte » et cochez la case correspondant au plug-in Oracle Database. Cliquez ensuite sur « Soumettre » pour lancer le processus de découverte et ajouter l'hôte à SnapCenter.
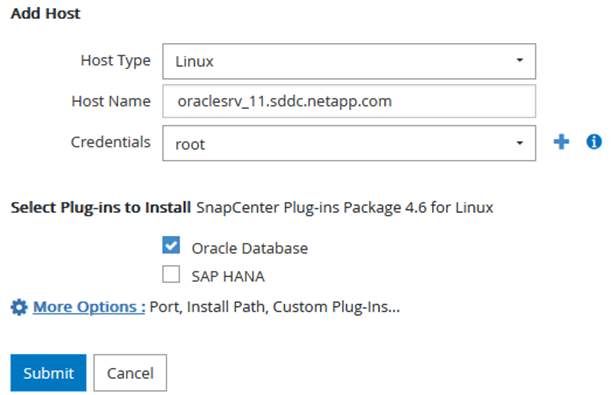
Créer des politiques SnapCenter
Les politiques établissent les règles spécifiques à suivre pour une tâche de sauvegarde. Ils incluent, sans toutefois s'y limiter, la planification de sauvegarde, le type de réplication et la manière dont SnapCenter gère la sauvegarde et la troncature des journaux de transactions.
Vous pouvez accéder aux politiques dans la section Paramètres du client Web SnapCenter .
Pour obtenir des informations complètes sur la création de politiques pour les sauvegardes SQL Server, consultez le "Documentation de SnapCenter" .
Pour obtenir des informations complètes sur la création de politiques pour les sauvegardes Oracle, consultez le "Documentation de SnapCenter" .
Remarques :
-
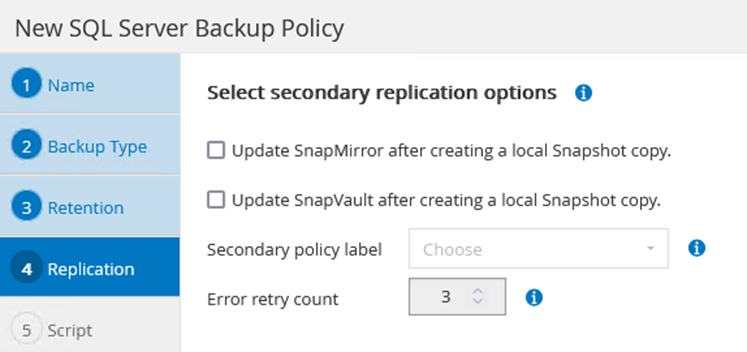
Au fur et à mesure que vous progressez dans l’assistant de création de stratégie, portez une attention particulière à la section Réplication. Dans cette section, vous indiquez les types de copies SnapMirror secondaires que vous souhaitez effectuer pendant le processus de sauvegarde.
-
Le paramètre « Mettre à jour SnapMirror après la création d'une copie Snapshot locale » fait référence à la mise à jour d'une relation SnapMirror lorsque cette relation existe entre deux machines virtuelles de stockage résidant sur le même cluster.
-
Le paramètre « Mettre à jour SnapVault après la création d'une copie SnapShot locale » est utilisé pour mettre à jour une relation SnapMirror qui existe entre deux clusters distincts et entre un système ONTAP sur site et Cloud Volumes ONTAP ou FSx ONTAP.
L’image suivante montre les options précédentes et leur apparence dans l’assistant de stratégie de sauvegarde.
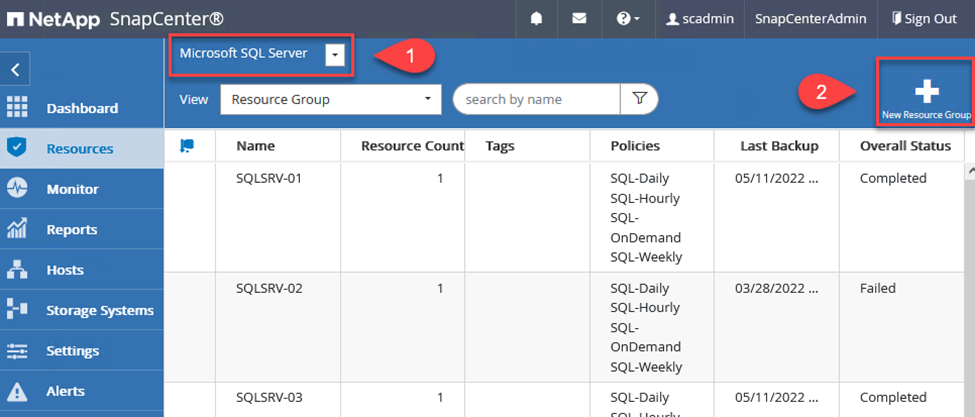
Créer des groupes de ressources SnapCenter
Les groupes de ressources vous permettent de sélectionner les ressources de base de données que vous souhaitez inclure dans vos sauvegardes et les politiques suivies pour ces ressources.
-
Accédez à la section Ressources dans le menu de gauche.
-
En haut de la fenêtre, sélectionnez le type de ressource avec lequel travailler (dans ce cas, Microsoft SQL Server), puis cliquez sur Nouveau groupe de ressources.
La documentation SnapCenter couvre les détails étape par étape pour la création de groupes de ressources pour les bases de données SQL Server et Oracle.
Pour sauvegarder les ressources SQL, suivez "ce lien" .
Pour sauvegarder les ressources Oracle, suivez "ce lien" .
Déployer et configurer Veeam Backup Server
Le logiciel Veeam Backup & Replication est utilisé dans la solution pour sauvegarder nos machines virtuelles d'application et archiver une copie des sauvegardes dans un compartiment Amazon S3 à l'aide d'un référentiel de sauvegarde évolutif Veeam (SOBR). Veeam est déployé sur un serveur Windows dans cette solution. Pour des conseils spécifiques sur le déploiement de Veeam, consultez le "Centre d'aide Veeam Documentation technique" .
Configurer le référentiel de sauvegarde évolutif Veeam
Après avoir déployé et obtenu la licence du logiciel, vous pouvez créer un référentiel de sauvegarde évolutif (SOBR) comme stockage cible pour les tâches de sauvegarde. Vous devez également inclure un compartiment S3 comme sauvegarde des données de la machine virtuelle hors site pour la reprise après sinistre.
Consultez les prérequis suivants avant de commencer.
-
Créez un partage de fichiers SMB sur votre système ONTAP local comme stockage cible pour les sauvegardes.
-
Créez un bucket Amazon S3 à inclure dans le SOBR. Il s'agit d'un référentiel pour les sauvegardes hors site.
Ajouter le stockage ONTAP à Veeam
Tout d’abord, ajoutez le cluster de stockage ONTAP et le système de fichiers SMB/NFS associé comme infrastructure de stockage dans Veeam.
-
Ouvrez la console Veeam et connectez-vous. Accédez à Infrastructure de stockage, puis sélectionnez Ajouter un stockage.
-
Dans l’assistant Ajouter un stockage, sélectionnez NetApp comme fournisseur de stockage, puis sélectionnez Data ONTAP.
-
Saisissez l’adresse IP de gestion et cochez la case NAS Filer. Cliquez sur Suivant.
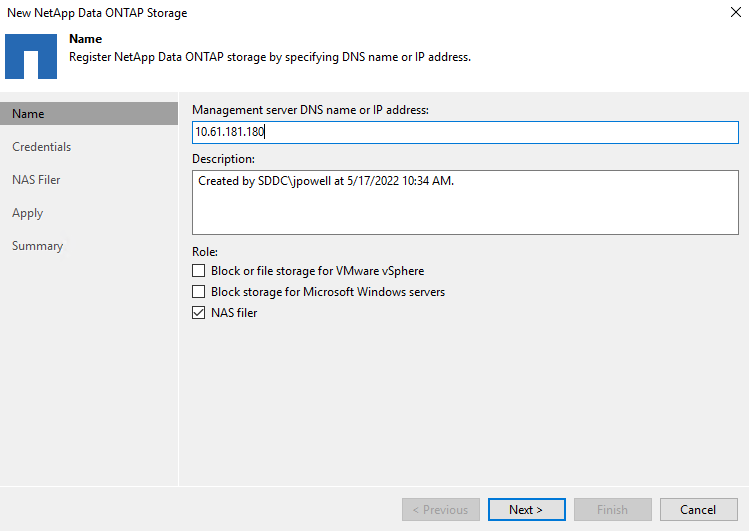
-
Ajoutez vos informations d’identification pour accéder au cluster ONTAP .
-
Sur la page NAS Filer, choisissez les protocoles souhaités à analyser et sélectionnez Suivant.
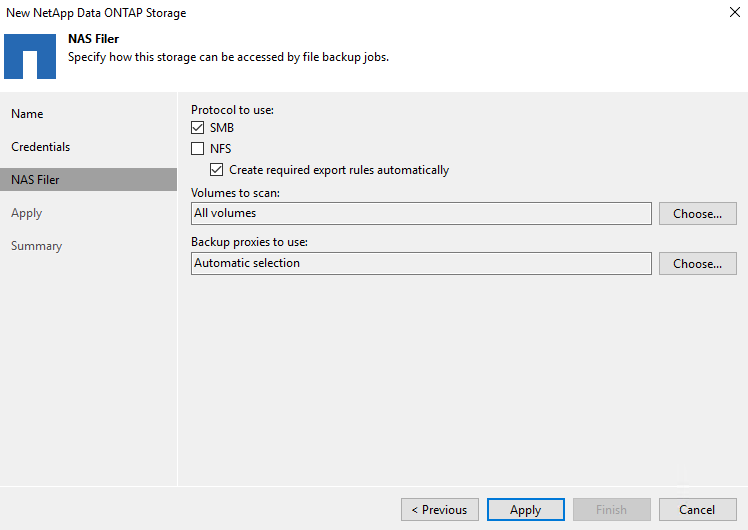
-
Remplissez les pages Appliquer et Résumé de l’assistant et cliquez sur Terminer pour commencer le processus de découverte de stockage. Une fois l'analyse terminée, le cluster ONTAP est ajouté avec les fichiers NAS en tant que ressources disponibles.
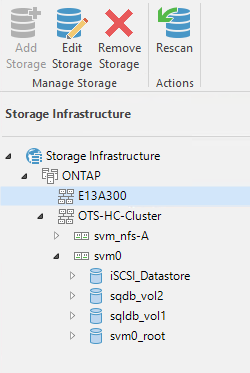
-
Créez un référentiel de sauvegarde à l’aide des partages NAS nouvellement découverts. Depuis l’infrastructure de sauvegarde, sélectionnez Référentiels de sauvegarde et cliquez sur l’élément de menu Ajouter un référentiel.
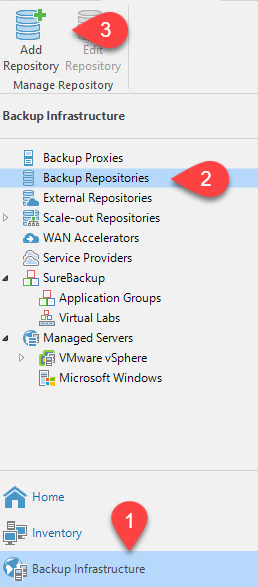
-
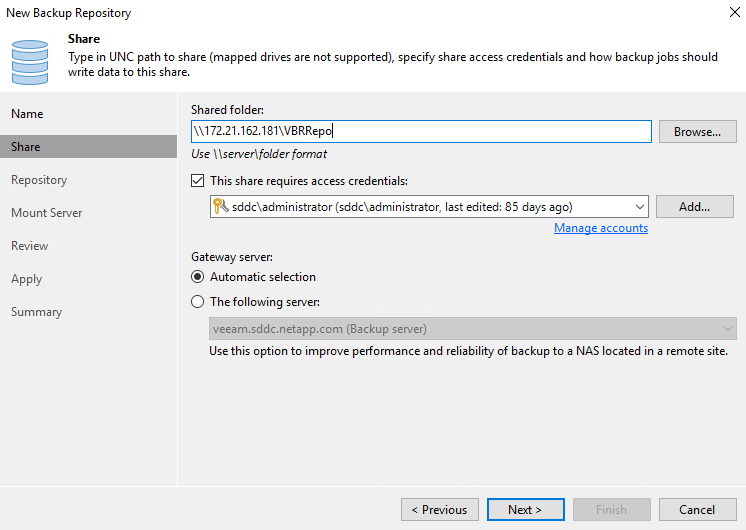
Suivez toutes les étapes de l’assistant Nouveau référentiel de sauvegarde pour créer le référentiel. Pour des informations détaillées sur la création de référentiels de sauvegarde Veeam, consultez le "Documentation Veeam" .
Ajouter le bucket Amazon S3 comme référentiel de sauvegarde
L’étape suivante consiste à ajouter le stockage Amazon S3 en tant que référentiel de sauvegarde.
-
Accédez à Infrastructure de sauvegarde > Référentiels de sauvegarde. Cliquez sur Ajouter un référentiel.
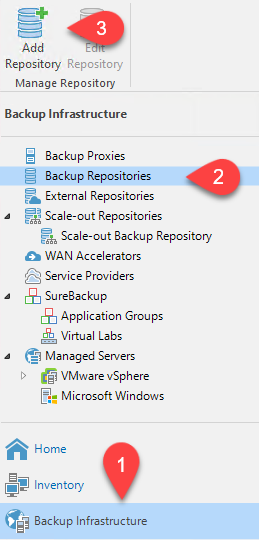
-
Dans l’assistant Ajouter un référentiel de sauvegarde, sélectionnez Stockage d’objets, puis Amazon S3. Cela démarre l'assistant Nouveau référentiel de stockage d'objets.

-
Donnez un nom à votre référentiel de stockage d’objets et cliquez sur Suivant.
-
Dans la section suivante, indiquez vos informations d’identification. Vous avez besoin d’une clé d’accès AWS et d’une clé secrète.
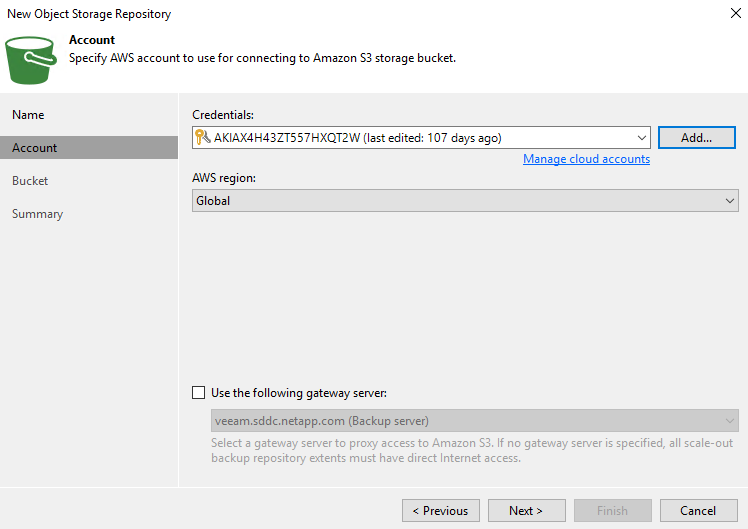
-
Une fois la configuration Amazon chargée, choisissez votre centre de données, votre bucket et votre dossier, puis cliquez sur Appliquer. Enfin, cliquez sur Terminer pour fermer l’assistant.
Créer un référentiel de sauvegarde évolutif
Maintenant que nous avons ajouté nos référentiels de stockage à Veeam, nous pouvons créer le SOBR pour hiérarchiser automatiquement les copies de sauvegarde vers notre stockage d'objets Amazon S3 hors site pour la reprise après sinistre.
-
Depuis l’infrastructure de sauvegarde, sélectionnez Référentiels évolutifs, puis cliquez sur l’élément de menu Ajouter un référentiel évolutif.
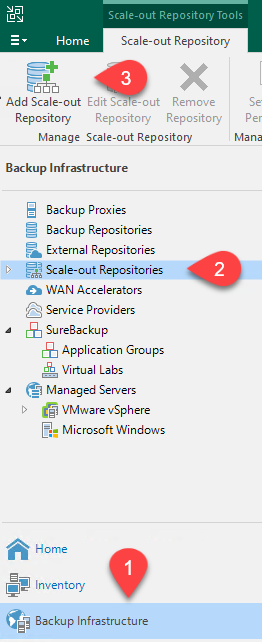
-
Dans le nouveau référentiel de sauvegarde évolutive, indiquez un nom pour le SOBR et cliquez sur Suivant.
-
Pour le niveau de performance, choisissez le référentiel de sauvegarde qui contient le partage SMB résidant sur votre cluster ONTAP local.
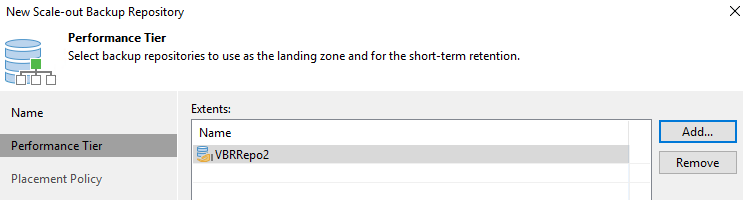
-
Pour la politique de placement, choisissez la localité des données ou les performances en fonction de vos besoins. Sélectionnez suivant.
-
Pour le niveau de capacité, nous étendons le SOBR avec le stockage d'objets Amazon S3. À des fins de reprise après sinistre, sélectionnez Copier les sauvegardes vers le stockage d'objets dès leur création pour garantir la livraison rapide de nos sauvegardes secondaires.
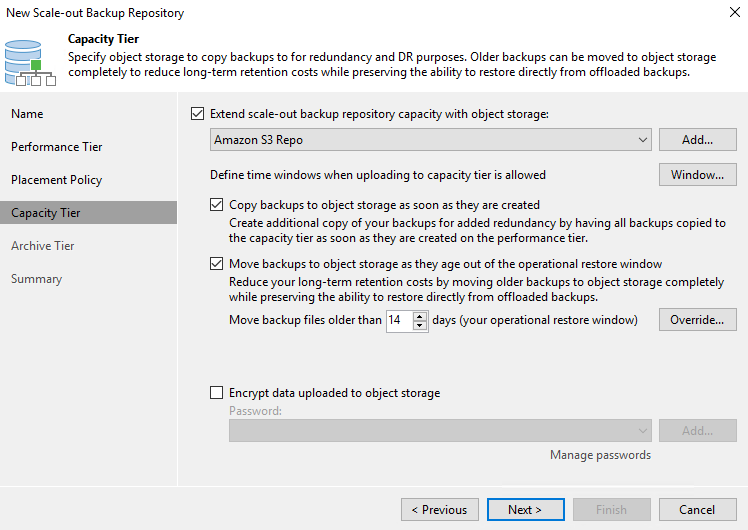
-
Enfin, sélectionnez Appliquer et Terminer pour finaliser la création du SOBR.
Créer les tâches de référentiel de sauvegarde évolutive
La dernière étape de la configuration de Veeam consiste à créer des tâches de sauvegarde en utilisant le SOBR nouvellement créé comme destination de sauvegarde. La création de tâches de sauvegarde fait partie intégrante du répertoire de tout administrateur de stockage et nous ne couvrons pas les étapes détaillées ici. Pour des informations plus complètes sur la création de tâches de sauvegarde dans Veeam, consultez le "Documentation technique du centre d'aide Veeam" .
Outils et configuration de BlueXP backup and recovery
Pour effectuer un basculement des machines virtuelles d'application et des volumes de base de données vers les services VMware Cloud Volume exécutés dans AWS, vous devez installer et configurer une instance en cours d'exécution de SnapCenter Server et de Veeam Backup and Replication Server. Une fois le basculement terminé, vous devez également configurer ces outils pour reprendre les opérations de sauvegarde normales jusqu'à ce qu'un retour arrière vers le centre de données sur site soit planifié et exécuté.
Déployer un serveur Windows SnapCenter secondaire
SnapCenter Server est déployé dans le SDDC VMware Cloud ou installé sur une instance EC2 résidant dans un VPC avec une connectivité réseau à l'environnement VMware Cloud.
Le SnapCenter software est disponible sur le site de support NetApp et peut être installé sur les systèmes Microsoft Windows qui résident dans un domaine ou un groupe de travail. Un guide de planification détaillé et des instructions d'installation sont disponibles sur le site "Centre de documentation NetApp" .
Vous pouvez trouver le SnapCenter software sur "ce lien" .
Configurer le serveur Windows SnapCenter secondaire
Pour effectuer une restauration des données d’application mises en miroir sur FSx ONTAP, vous devez d’abord effectuer une restauration complète de la base de données SnapCenter locale. Une fois ce processus terminé, la communication avec les machines virtuelles est rétablie et les sauvegardes d’applications peuvent désormais reprendre en utilisant FSx ONTAP comme stockage principal.
Pour ce faire, vous devez effectuer les opérations suivantes sur le serveur SnapCenter :
-
Configurez le nom de l’ordinateur pour qu’il soit identique à celui du serveur SnapCenter local d’origine.
-
Configurez la mise en réseau pour communiquer avec VMware Cloud et l’instance FSx ONTAP .
-
Terminez la procédure pour restaurer la base de données SnapCenter .
-
Confirmez que SnapCenter est en mode de récupération après sinistre pour vous assurer que FSx est désormais le stockage principal pour les sauvegardes.
-
Confirmez que la communication est rétablie avec les machines virtuelles restaurées.
Déployer un serveur Veeam Backup & Replication secondaire
Vous pouvez installer le serveur Veeam Backup & Replication sur un serveur Windows dans VMware Cloud sur AWS ou sur une instance EC2. Pour des conseils de mise en œuvre détaillés, consultez le "Documentation technique du centre d'aide Veeam" .
Configurer un serveur secondaire Veeam Backup & Replication
Pour effectuer une restauration de machines virtuelles qui ont été sauvegardées sur le stockage Amazon S3, vous devez installer le serveur Veeam sur un serveur Windows et le configurer pour communiquer avec VMware Cloud, FSx ONTAP et le bucket S3 qui contient le référentiel de sauvegarde d'origine. Il doit également disposer d'un nouveau référentiel de sauvegarde configuré sur FSx ONTAP pour effectuer de nouvelles sauvegardes des machines virtuelles après leur restauration.
Pour effectuer ce processus, les éléments suivants doivent être complétés :
-
Configurez la mise en réseau pour communiquer avec VMware Cloud, FSx ONTAP et le bucket S3 contenant le référentiel de sauvegarde d'origine.
-
Configurez un partage SMB sur FSx ONTAP pour qu'il devienne un nouveau référentiel de sauvegarde.
-
Montez le bucket S3 d’origine qui a été utilisé dans le cadre du référentiel de sauvegarde évolutif sur site.
-
Après avoir restauré la machine virtuelle, établissez de nouvelles tâches de sauvegarde pour protéger les machines virtuelles SQL et Oracle.
Pour plus d'informations sur la restauration de machines virtuelles à l'aide de Veeam, consultez la section"Restaurer les machines virtuelles d'application avec Veeam Full Restore" .
Sauvegarde de la base de données SnapCenter pour la reprise après sinistre
SnapCenter permet la sauvegarde et la récupération de sa base de données MySQL sous-jacente et de ses données de configuration dans le but de récupérer le serveur SnapCenter en cas de sinistre. Pour notre solution, nous avons récupéré la base de données et la configuration SnapCenter sur une instance AWS EC2 résidant dans notre VPC. Pour plus d'informations sur la reprise après sinistre de SnapCenter, consultez "ce lien" .
Conditions préalables à la sauvegarde de SnapCenter
Les conditions préalables suivantes sont requises pour la sauvegarde SnapCenter :
-
Un volume et un partage SMB créés sur le système ONTAP local pour localiser la base de données sauvegardée et les fichiers de configuration.
-
Une relation SnapMirror entre le système ONTAP sur site et FSx ou CVO dans le compte AWS. Cette relation est utilisée pour transporter l'instantané contenant la base de données SnapCenter sauvegardée et les fichiers de configuration.
-
Windows Server installé dans le compte cloud, soit sur une instance EC2, soit sur une machine virtuelle dans le SDDC VMware Cloud.
-
SnapCenter installé sur l'instance Windows EC2 ou la machine virtuelle dans VMware Cloud.
Résumé du processus de sauvegarde et de restauration de SnapCenter
-
Créez un volume sur le système ONTAP local pour héberger la base de données de sauvegarde et les fichiers de configuration.
-
Configurez une relation SnapMirror entre le système local et FSx/CVO.
-
Montez le partage SMB.
-
Récupérez le jeton d’autorisation Swagger pour effectuer des tâches API.
-
Démarrez le processus de restauration de la base de données.
-
Utilisez l'utilitaire xcopy pour copier le répertoire local de la base de données et du fichier de configuration sur le partage SMB.
-
Sur FSx, créez un clone du volume ONTAP (copié via SnapMirror à partir du site).
-
Montez le partage SMB de FSx vers EC2/VMware Cloud.
-
Copiez le répertoire de restauration du partage SMB vers un répertoire local.
-
Exécutez le processus de restauration de SQL Server à partir de Swagger.
Sauvegarder la base de données et la configuration de SnapCenter
SnapCenter fournit une interface client Web pour exécuter des commandes API REST. Pour plus d'informations sur l'accès aux API REST via Swagger, consultez la documentation SnapCenter à l'adresse "ce lien" .
Connectez-vous à Swagger et obtenez un jeton d'autorisation
Après avoir accédé à la page Swagger, vous devez récupérer un jeton d’autorisation pour lancer le processus de restauration de la base de données.
-
Accédez à la page Web de l'API SnapCenter Swagger à l'adresse https://< IP du serveur SnapCenter >:8146/swagger/.
-
Développez la section Authentification et cliquez sur Essayer.
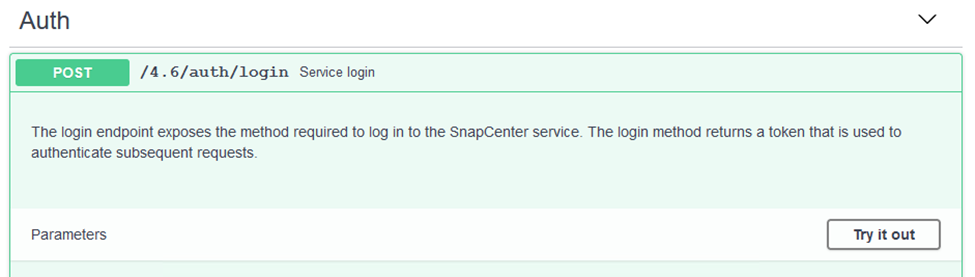
-
Dans la zone UserOperationContext, renseignez les informations d’identification et le rôle de SnapCenter et cliquez sur Exécuter.
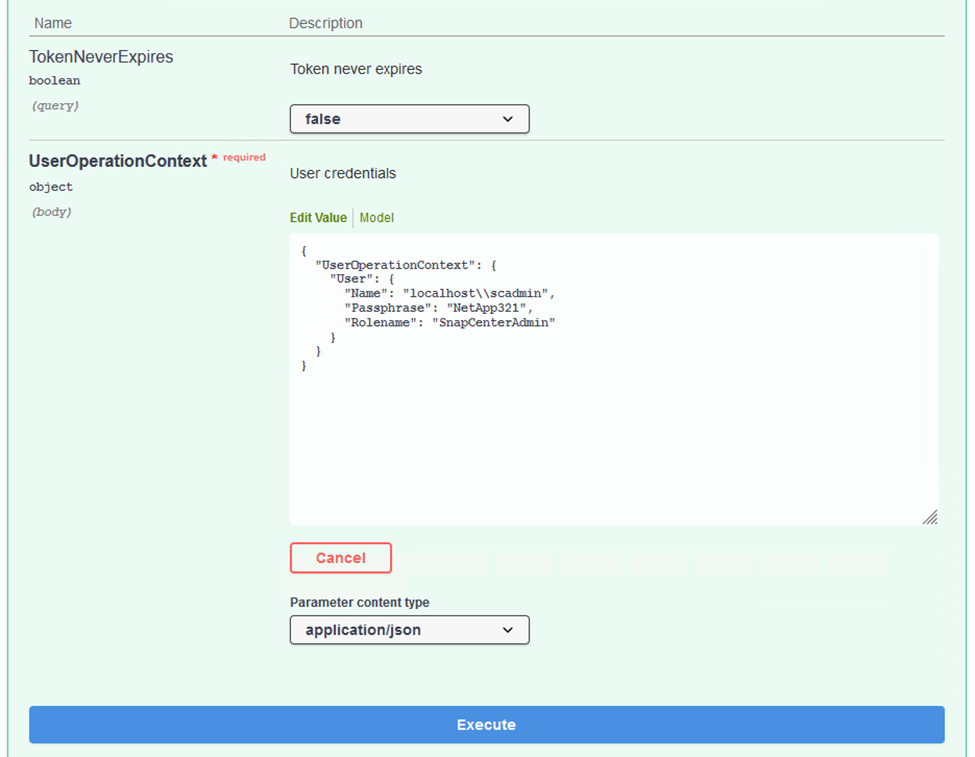
-
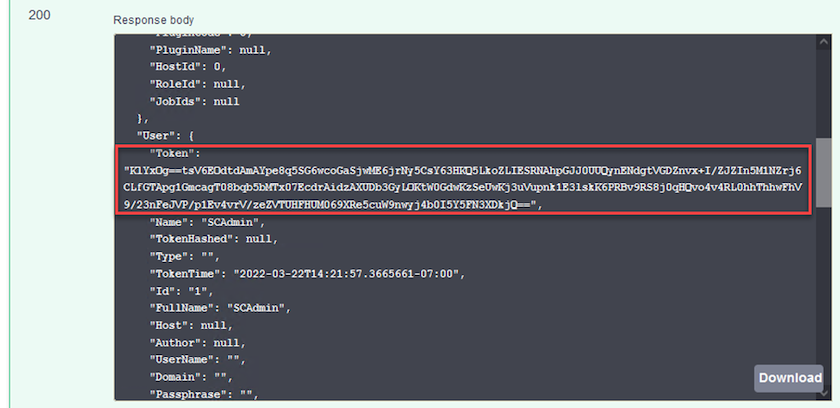
Dans le corps de la réponse ci-dessous, vous pouvez voir le jeton. Copiez le texte du jeton pour l’authentification lors de l’exécution du processus de sauvegarde.
Effectuer une sauvegarde de la base de données SnapCenter
Accédez ensuite à la zone de récupération après sinistre sur la page Swagger pour commencer le processus de sauvegarde de SnapCenter .
-
Développez la zone de reprise après sinistre en cliquant dessus.
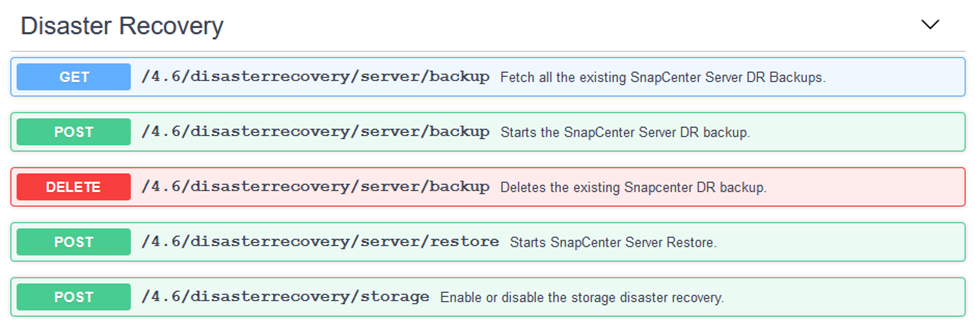
-
Développer le
/4.6/disasterrecovery/server/backupsection et cliquez sur Essayer.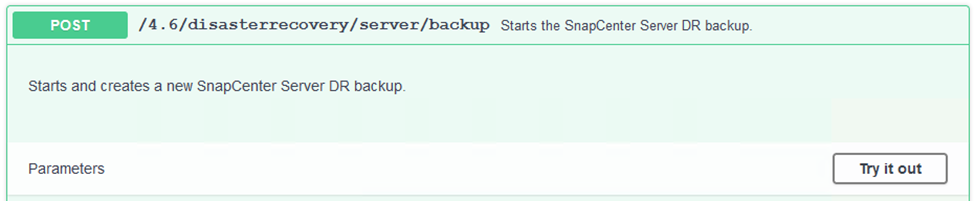
-
Dans la section SmDRBackupRequest, ajoutez le chemin cible local correct et sélectionnez Exécuter pour démarrer la sauvegarde de la base de données et de la configuration SnapCenter .
Le processus de sauvegarde ne permet pas de sauvegarder directement sur un partage de fichiers NFS ou CIFS. 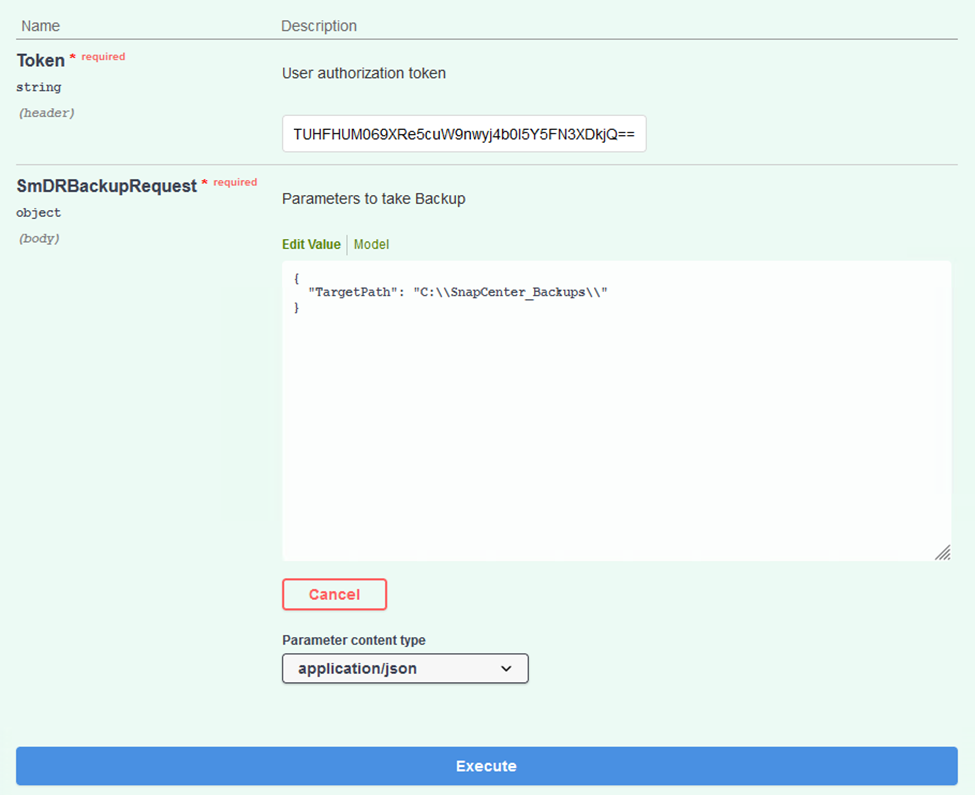
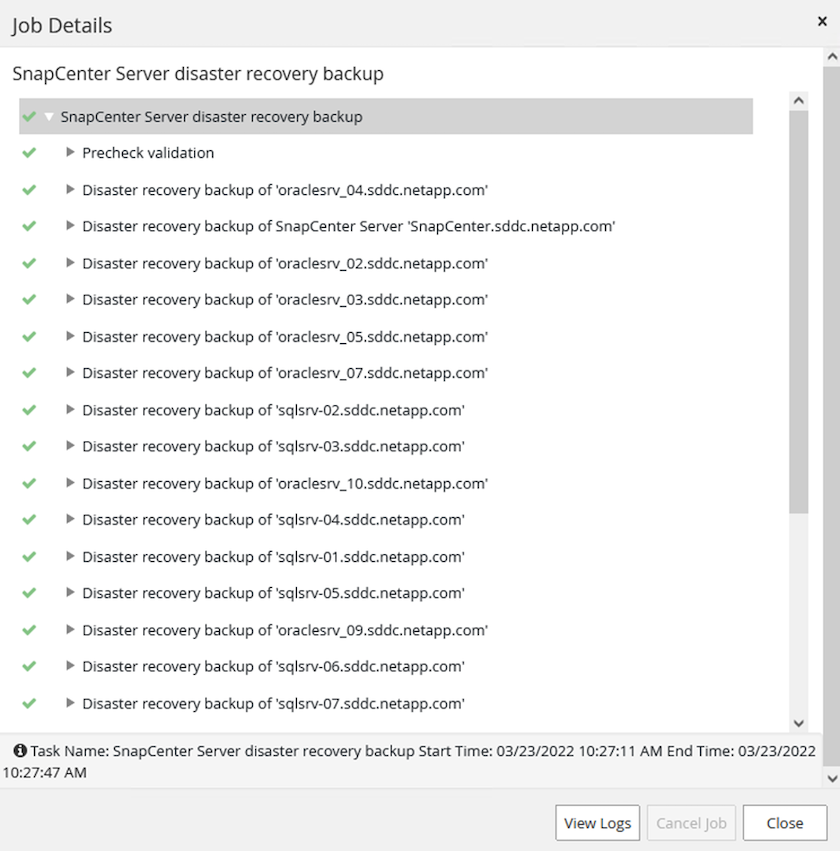
Surveiller la tâche de sauvegarde depuis SnapCenter
Connectez-vous à SnapCenter pour consulter les fichiers journaux lors du démarrage du processus de restauration de la base de données. Dans la section Moniteur, vous pouvez afficher les détails de la sauvegarde de récupération après sinistre du serveur SnapCenter .
Utilisez l'utilitaire XCOPY pour copier le fichier de sauvegarde de la base de données sur le partage SMB
Ensuite, vous devez déplacer la sauvegarde du lecteur local sur le serveur SnapCenter vers le partage CIFS utilisé pour copier les données SnapMirror vers l'emplacement secondaire situé sur l'instance FSx dans AWS. Utilisez xcopy avec des options spécifiques qui conservent les autorisations des fichiers.
Ouvrez une invite de commande en tant qu’administrateur. À partir de l’invite de commande, entrez les commandes suivantes :
xcopy <Source_Path> \\<Destination_Server_IP>\<Folder_Path> /O /X /E /H /K xcopy c:\SC_Backups\SnapCenter_DR \\10.61.181.185\snapcenter_dr /O /X /E /H /K
Basculement
Une catastrophe se produit sur le site principal
En cas de sinistre survenant dans le centre de données principal sur site, notre scénario inclut un basculement vers un site secondaire résidant sur l'infrastructure Amazon Web Services à l'aide de VMware Cloud sur AWS. Nous supposons que les machines virtuelles et notre cluster ONTAP sur site ne sont plus accessibles. De plus, les machines virtuelles SnapCenter et Veeam ne sont plus accessibles et doivent être reconstruites sur notre site secondaire.
Cette section aborde le basculement de notre infrastructure vers le cloud et nous abordons les sujets suivants :
-
Restauration de la base de données SnapCenter . Une fois qu'un nouveau serveur SnapCenter a été établi, restaurez la base de données MySQL et les fichiers de configuration et basculez la base de données en mode de récupération après sinistre afin de permettre au stockage FSx secondaire de devenir le périphérique de stockage principal.
-
Restaurez les machines virtuelles d’application à l’aide de Veeam Backup & Replication. Connectez le stockage S3 qui contient les sauvegardes de machines virtuelles, importez les sauvegardes et restaurez-les sur VMware Cloud sur AWS.
-
Restaurez les données de l’application SQL Server à l’aide de SnapCenter.
-
Restaurez les données de l'application Oracle à l'aide de SnapCenter.
Processus de restauration de la base de données SnapCenter
SnapCenter prend en charge les scénarios de reprise après sinistre en permettant la sauvegarde et la restauration de sa base de données MySQL et de ses fichiers de configuration. Cela permet à un administrateur de conserver des sauvegardes régulières de la base de données SnapCenter dans le centre de données local et de restaurer ultérieurement cette base de données dans une base de données SnapCenter secondaire.
Pour accéder aux fichiers de sauvegarde SnapCenter sur le serveur SnapCenter distant, procédez comme suit :
-
Rompre la relation SnapMirror du cluster FSx, ce qui rend le volume en lecture/écriture.
-
Créez un serveur CIFS (si nécessaire) et créez un partage CIFS pointant vers le chemin de jonction du volume cloné.
-
Utilisez xcopy pour copier les fichiers de sauvegarde dans un répertoire local sur le système SnapCenter secondaire.
-
Installez SnapCenter v4.6.
-
Assurez-vous que le serveur SnapCenter possède le même nom de domaine complet que le serveur d'origine. Ceci est nécessaire pour que la restauration de la base de données réussisse.
Pour démarrer le processus de restauration, procédez comme suit :
-
Accédez à la page Web de l’API Swagger pour le serveur SnapCenter secondaire et suivez les instructions précédentes pour obtenir un jeton d’autorisation.
-
Accédez à la section Reprise après sinistre de la page Swagger, sélectionnez
/4.6/disasterrecovery/server/restore, et cliquez sur Essayer.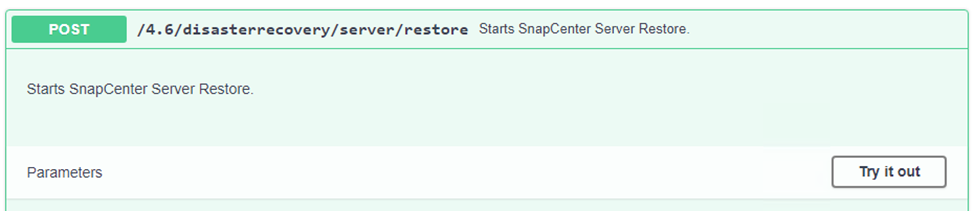
-
Collez votre jeton d’autorisation et, dans la section SmDRResterRequest, collez le nom de la sauvegarde et le répertoire local sur le serveur SnapCenter secondaire.
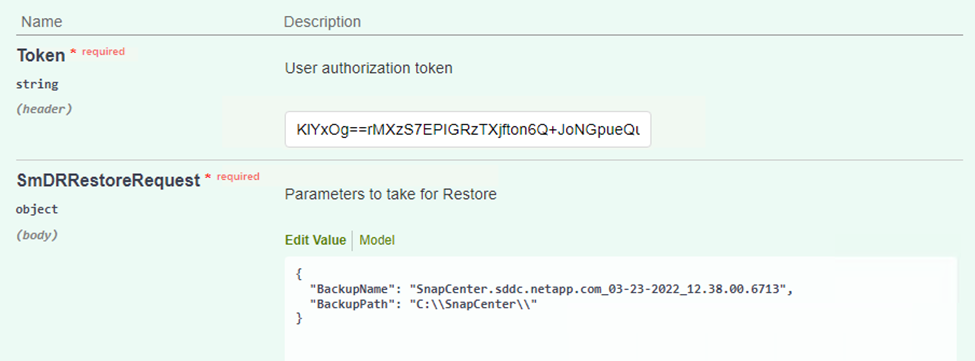
-
Sélectionnez le bouton Exécuter pour démarrer le processus de restauration.
-
Depuis SnapCenter, accédez à la section Surveiller pour afficher la progression de la tâche de restauration.
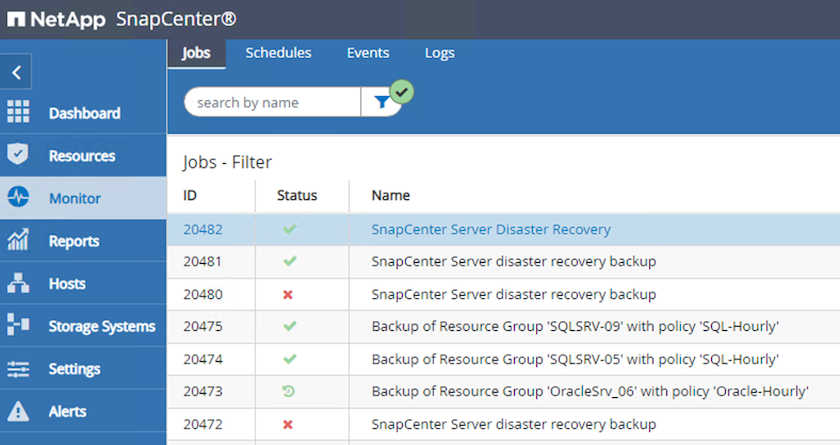
-
Pour activer les restaurations SQL Server à partir du stockage secondaire, vous devez basculer la base de données SnapCenter en mode de récupération après sinistre. Cette opération est effectuée comme une opération distincte et initiée sur la page Web de l'API Swagger.
-
Accédez à la section Reprise après sinistre et cliquez sur
/4.6/disasterrecovery/storage. -
Collez le jeton d’autorisation de l’utilisateur.
-
Dans la section SmSetDisasterRecoverySettingsRequest, modifiez
EnableDisasterRecoveràtrue. -
Cliquez sur Exécuter pour activer le mode de récupération après sinistre pour SQL Server.
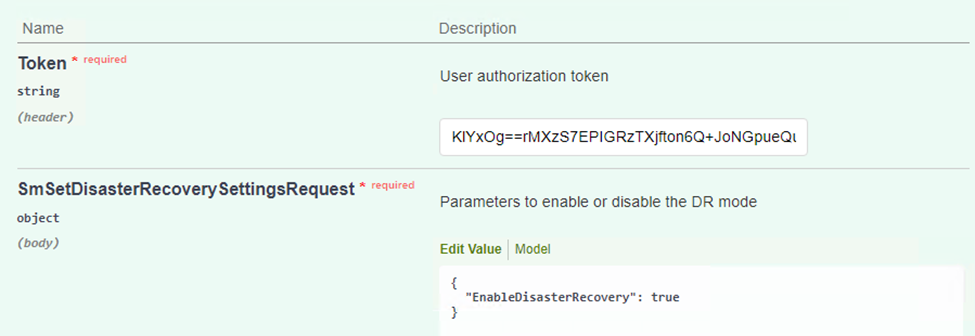
Voir les commentaires concernant les procédures supplémentaires. -
Restaurer les machines virtuelles d'application avec la restauration complète de Veeam
Créer un référentiel de sauvegarde et importer des sauvegardes depuis S3
À partir du serveur Veeam secondaire, importez les sauvegardes du stockage S3 et restaurez les machines virtuelles SQL Server et Oracle sur votre cluster VMware Cloud.
Pour importer les sauvegardes de l’objet S3 qui faisait partie du référentiel de sauvegarde évolutif sur site, procédez comme suit :
-
Accédez aux référentiels de sauvegarde et cliquez sur Ajouter un référentiel dans le menu supérieur pour lancer l'assistant Ajouter un référentiel de sauvegarde. Sur la première page de l’assistant, sélectionnez Stockage d’objets comme type de référentiel de sauvegarde.
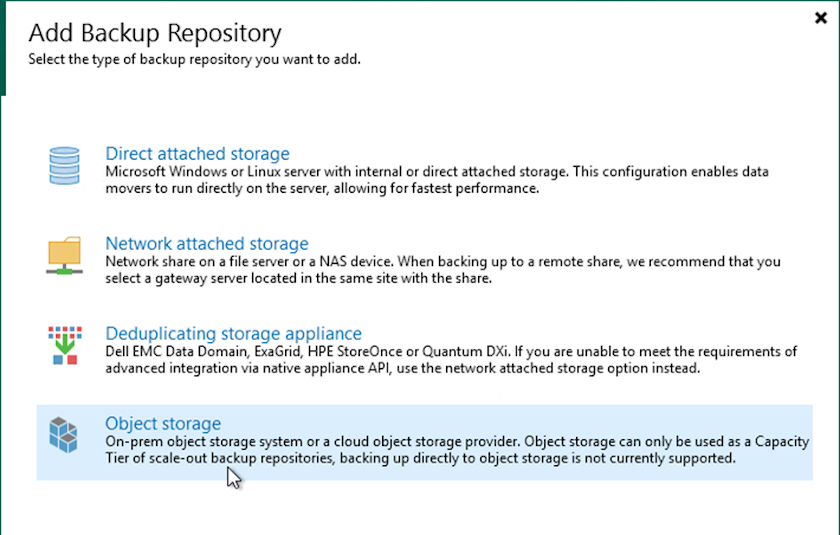
-
Sélectionnez Amazon S3 comme type de stockage d’objets.
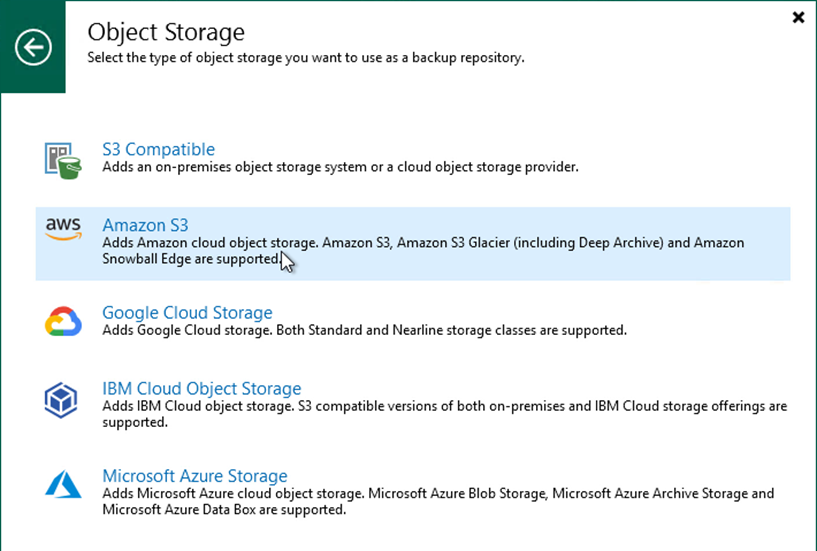
-
Dans la liste des services Amazon Cloud Storage, sélectionnez Amazon S3.

-
Sélectionnez vos informations d’identification pré-saisies dans la liste déroulante ou ajoutez une nouvelle information d’identification pour accéder à la ressource de stockage cloud. Cliquez sur Suivant pour continuer.
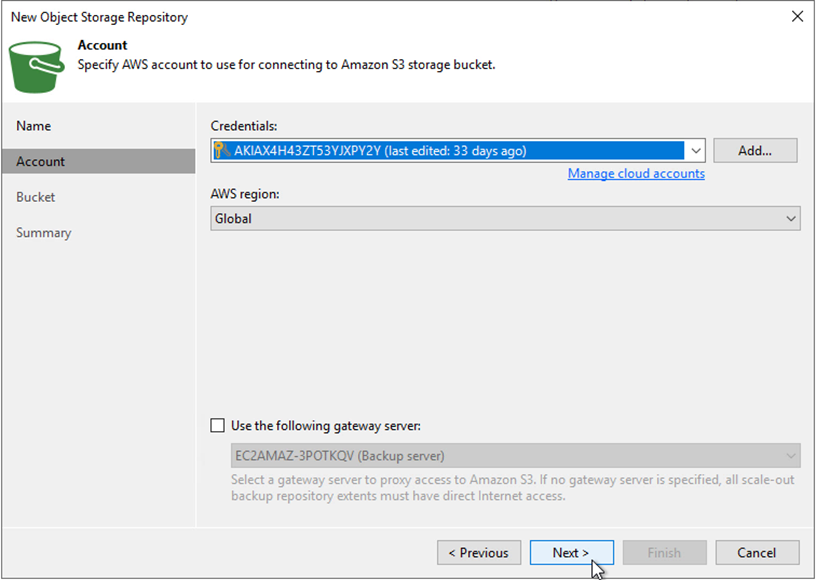
-
Sur la page Bucket, entrez le centre de données, le bucket, le dossier et les options souhaitées. Cliquez sur Appliquer.
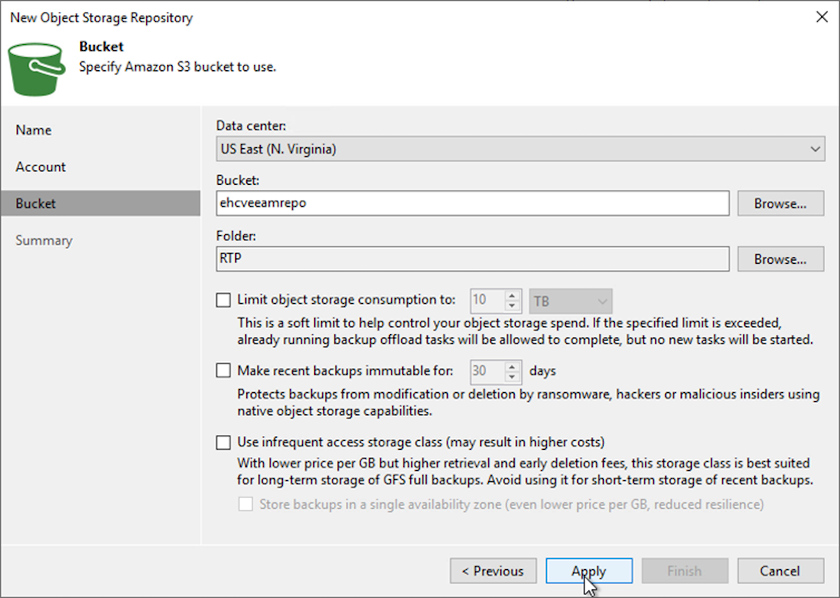
-
Enfin, sélectionnez Terminer pour terminer le processus et ajouter le référentiel.
Importer des sauvegardes à partir du stockage d'objets S3
Pour importer les sauvegardes du référentiel S3 ajouté dans la section précédente, procédez comme suit.
-
Depuis le référentiel de sauvegarde S3, sélectionnez Importer des sauvegardes pour lancer l’assistant Importer des sauvegardes.
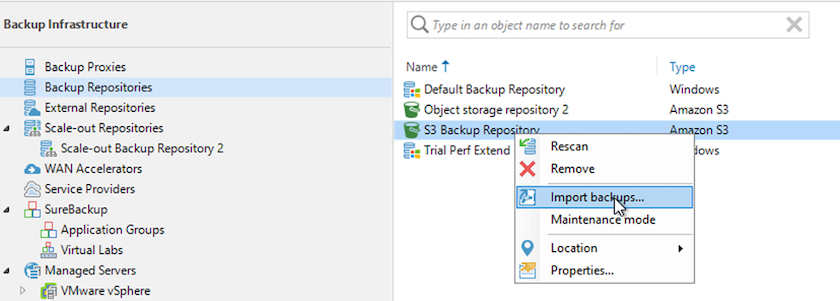
-
Une fois les enregistrements de base de données pour l'importation créés, sélectionnez Suivant, puis Terminer dans l'écran récapitulatif pour démarrer le processus d'importation.
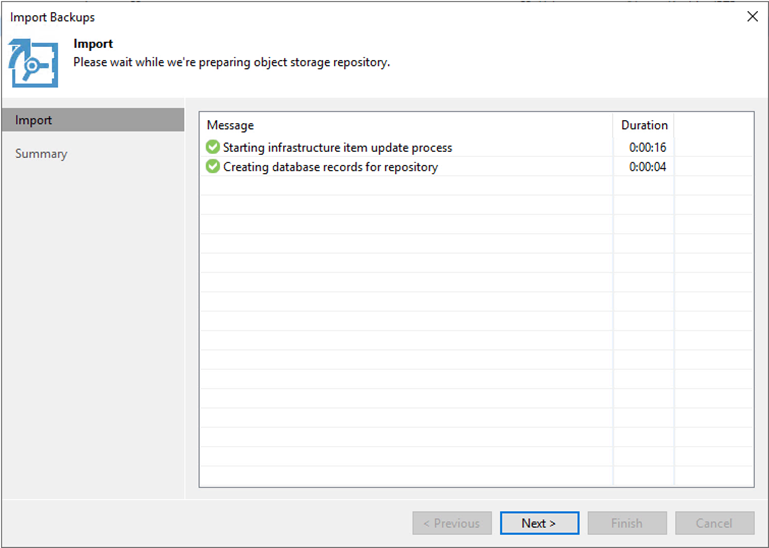
-
Une fois l’importation terminée, vous pouvez restaurer les machines virtuelles dans le cluster VMware Cloud.
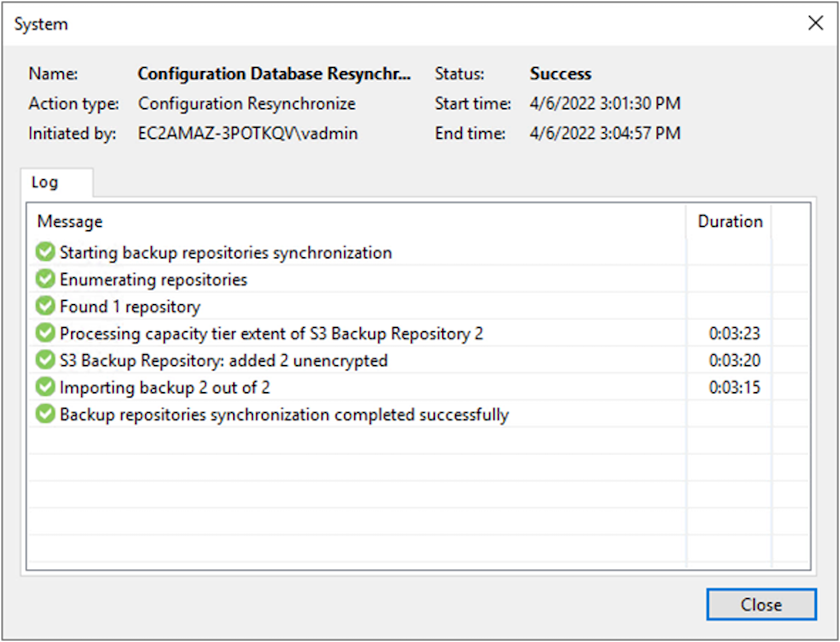
Restaurer les machines virtuelles d'application avec la restauration complète Veeam vers VMware Cloud
Pour restaurer les machines virtuelles SQL et Oracle sur le domaine/cluster de charge de travail VMware Cloud on AWS, procédez comme suit.
-
Depuis la page d’accueil de Veeam, sélectionnez le stockage d’objets contenant les sauvegardes importées, sélectionnez les machines virtuelles à restaurer, puis cliquez avec le bouton droit de la souris et sélectionnez Restaurer la machine virtuelle entière.
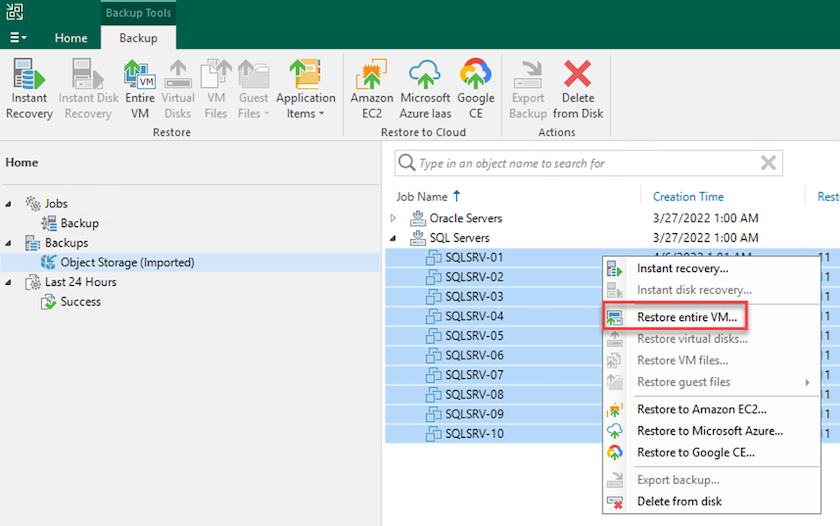
-
Sur la première page de l’assistant de restauration complète de la machine virtuelle, modifiez les machines virtuelles à sauvegarder si vous le souhaitez et sélectionnez Suivant.
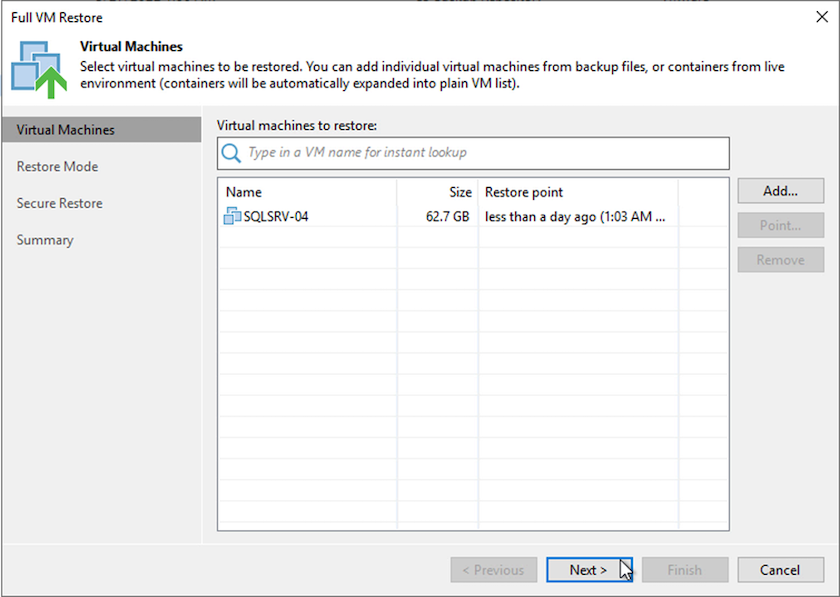
-
Sur la page Mode de restauration, sélectionnez Restaurer vers un nouvel emplacement ou avec des paramètres différents.
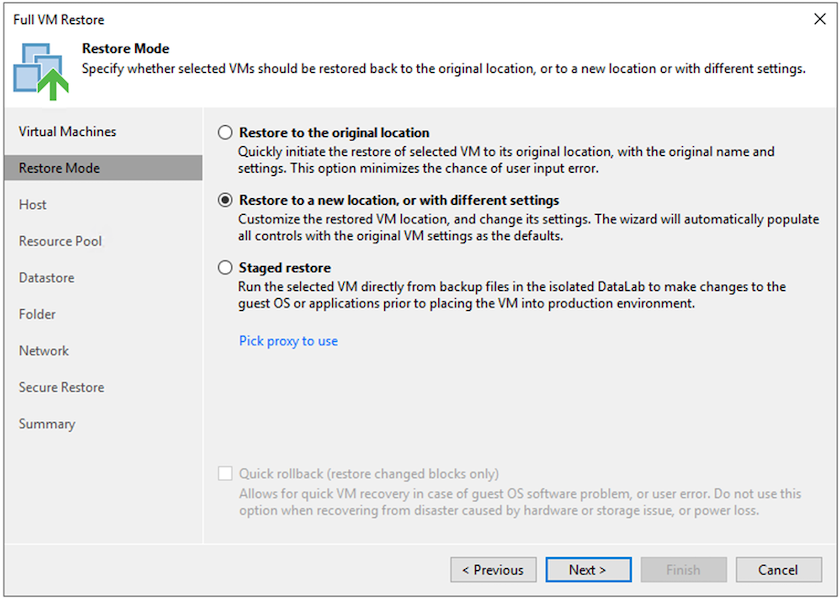
-
Sur la page de l’hôte, sélectionnez l’hôte ou le cluster ESXi cible sur lequel restaurer la machine virtuelle.
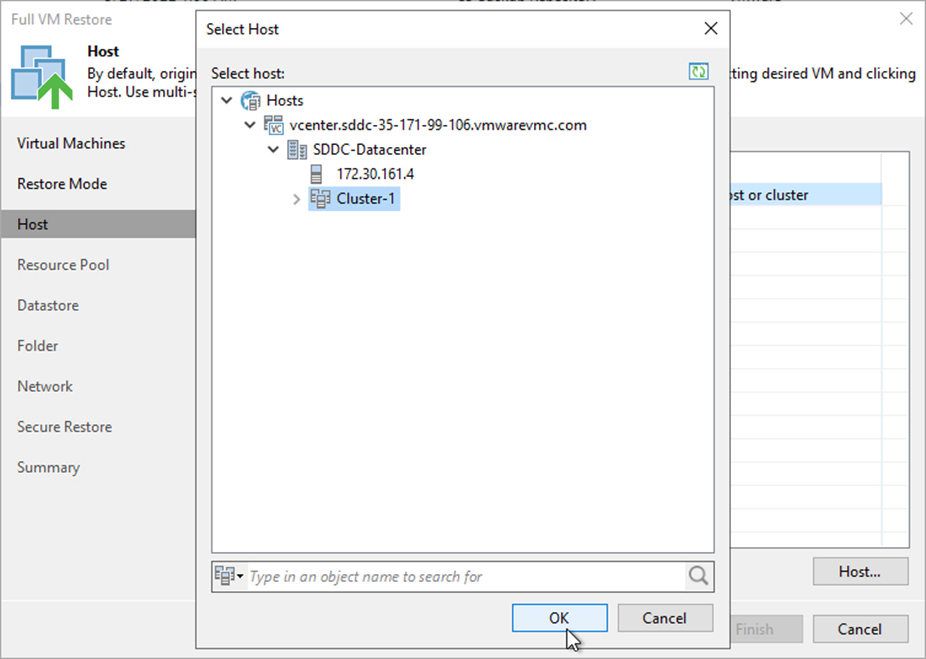
-
Sur la page Magasins de données, sélectionnez l’emplacement du magasin de données cible pour les fichiers de configuration et le disque dur.
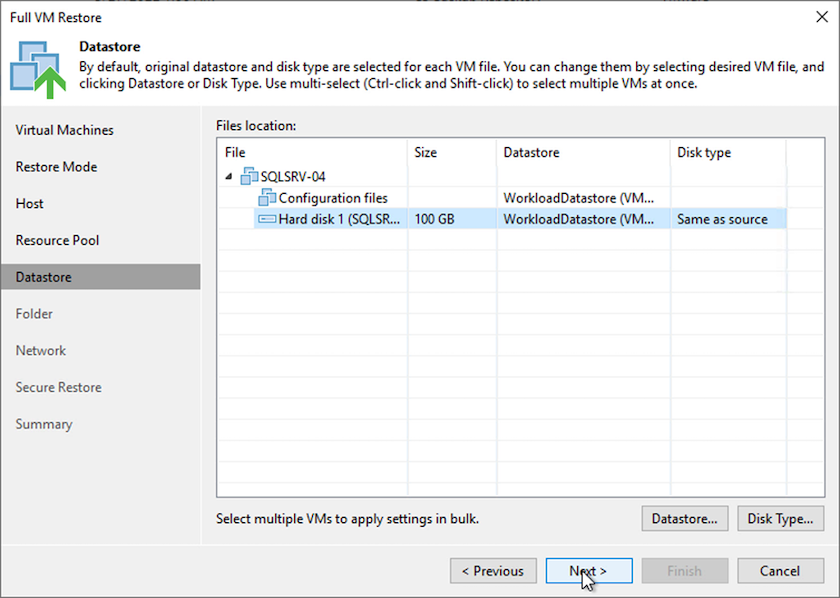
-
Sur la page Réseau, mappez les réseaux d’origine de la machine virtuelle aux réseaux du nouvel emplacement cible.
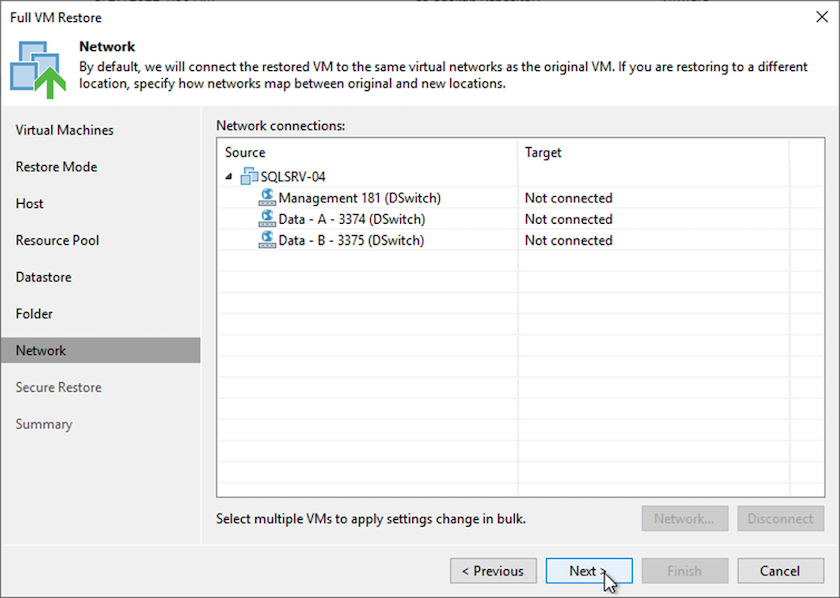
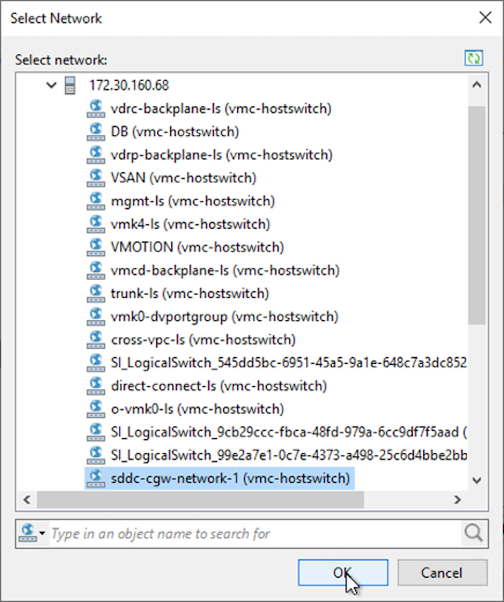
-
Sélectionnez si vous souhaitez analyser la machine virtuelle restaurée à la recherche de logiciels malveillants, consultez la page de résumé et cliquez sur Terminer pour démarrer la restauration.
Restaurer les données d'application SQL Server
Le processus suivant fournit des instructions sur la façon de récupérer un serveur SQL dans VMware Cloud Services dans AWS en cas de sinistre rendant le site local inutilisable.
Les conditions préalables suivantes sont supposées être remplies pour pouvoir poursuivre les étapes de récupération :
-
La machine virtuelle Windows Server a été restaurée sur le SDDC VMware Cloud à l’aide de Veeam Full Restore.
-
Un serveur SnapCenter secondaire a été établi et la restauration et la configuration de la base de données SnapCenter ont été effectuées en suivant les étapes décrites dans la section"Résumé du processus de sauvegarde et de restauration de SnapCenter ."
VM : configuration post-restauration pour la machine virtuelle SQL Server
Une fois la restauration de la machine virtuelle terminée, vous devez configurer la mise en réseau et d'autres éléments en vue de la redécouverte de la machine virtuelle hôte dans SnapCenter.
-
Attribuez de nouvelles adresses IP pour la gestion et iSCSI ou NFS.
-
Rejoignez l’hôte au domaine Windows.
-
Ajoutez les noms d’hôtes au DNS ou au fichier hosts sur le serveur SnapCenter .
|
|
Si le plug-in SnapCenter a été déployé à l'aide d'informations d'identification de domaine différentes de celles du domaine actuel, vous devez modifier le compte de connexion pour le plug-in pour le service Windows sur la machine virtuelle SQL Server. Après avoir modifié le compte de connexion, redémarrez les services SnapCenter SMCore, Plug-in pour Windows et Plug-in pour SQL Server. |
|
|
Pour redécouvrir automatiquement les machines virtuelles restaurées dans SnapCenter, le nom de domaine complet doit être identique à celui de la machine virtuelle qui a été initialement ajoutée au SnapCenter sur site. |
Configurer le stockage FSx pour la restauration de SQL Server
Pour réaliser le processus de restauration de récupération après sinistre pour une machine virtuelle SQL Server, vous devez rompre la relation SnapMirror existante du cluster FSx et accorder l'accès au volume. Pour ce faire, procédez comme suit.
-
Pour rompre la relation SnapMirror existante pour la base de données SQL Server et les volumes de journaux, exécutez la commande suivante à partir de l'interface de ligne de commande FSx :
FSx-Dest::> snapmirror break -destination-path DestSVM:DestVolName
-
Accordez l'accès au LUN en créant un groupe d'initiateurs contenant l'IQN iSCSI de la machine virtuelle Windows SQL Server :
FSx-Dest::> igroup create -vserver DestSVM -igroup igroupName -protocol iSCSI -ostype windows -initiator IQN
-
Enfin, mappez les LUN au groupe initiateur que vous venez de créer :
FSx-Dest::> lun mapping create -vserver DestSVM -path LUNPath igroup igroupName
-
Pour trouver le nom du chemin, exécutez la commande
lun showcommande.
Configurer la machine virtuelle Windows pour l'accès iSCSI et découvrir les systèmes de fichiers
-
À partir de la machine virtuelle SQL Server, configurez votre adaptateur réseau iSCSI pour communiquer sur le groupe de ports VMware qui a été établi avec une connectivité aux interfaces cibles iSCSI sur votre instance FSx.
-
Ouvrez l’utilitaire Propriétés de l’initiateur iSCSI et effacez les anciens paramètres de connectivité dans les onglets Découverte, Cibles favorites et Cibles.
-
Localisez la ou les adresses IP permettant d'accéder à l'interface logique iSCSI sur l'instance/le cluster FSx. Vous pouvez le trouver dans la console AWS sous Amazon FSx > ONTAP > Machines virtuelles de stockage.
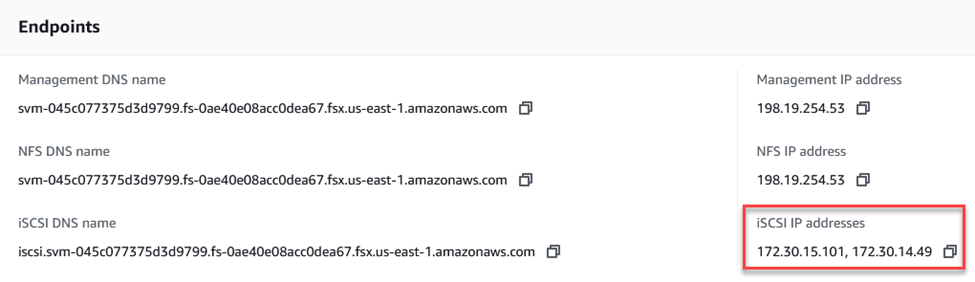
-
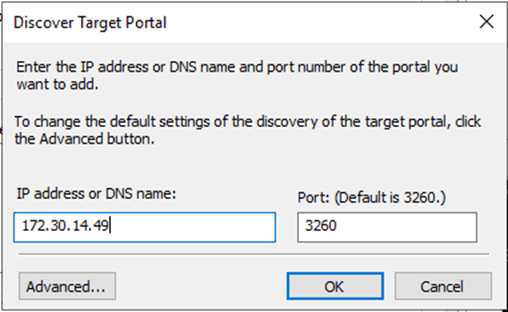
Dans l’onglet Découverte, cliquez sur Découvrir le portail et entrez les adresses IP de vos cibles iSCSI FSx.
-
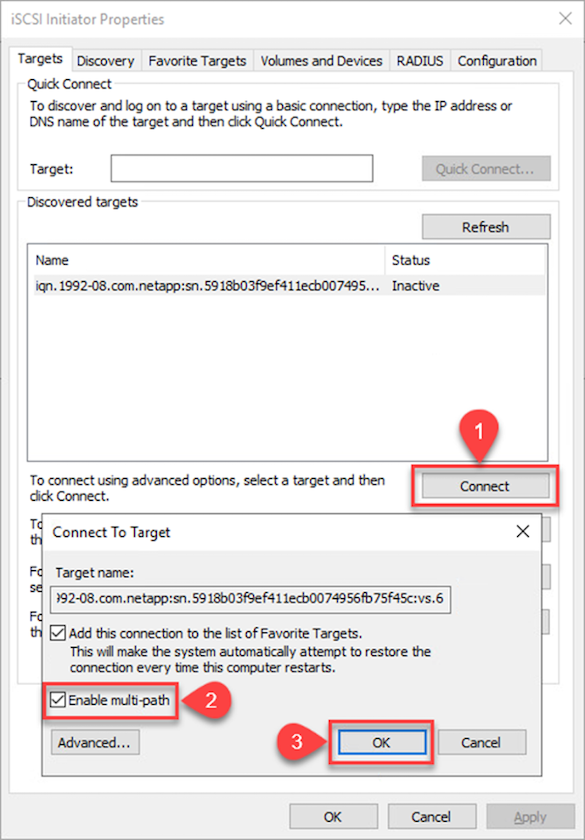
Dans l’onglet Cible, cliquez sur Connecter, sélectionnez Activer Multi-Path si cela convient à votre configuration, puis cliquez sur OK pour vous connecter à la cible.
-
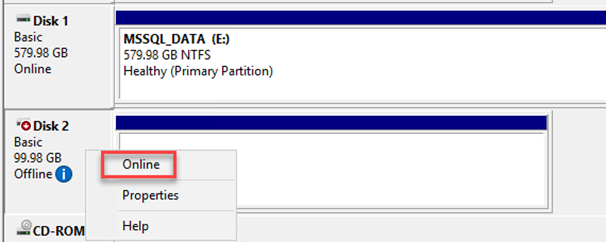
Ouvrez l’utilitaire Gestion de l’ordinateur et mettez les disques en ligne. Vérifiez qu’ils conservent les mêmes lettres de lecteur qu’ils détenaient auparavant.
Attacher les bases de données SQL Server
-
À partir de la machine virtuelle SQL Server, ouvrez Microsoft SQL Server Management Studio et sélectionnez Attacher pour démarrer le processus de connexion à la base de données.
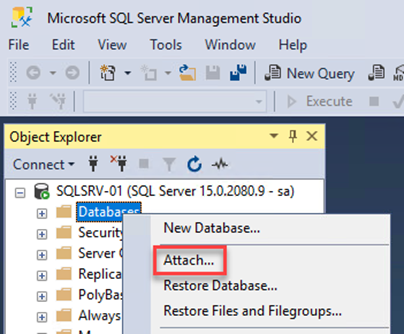
-
Cliquez sur Ajouter et accédez au dossier contenant le fichier de base de données principal SQL Server, sélectionnez-le et cliquez sur OK.
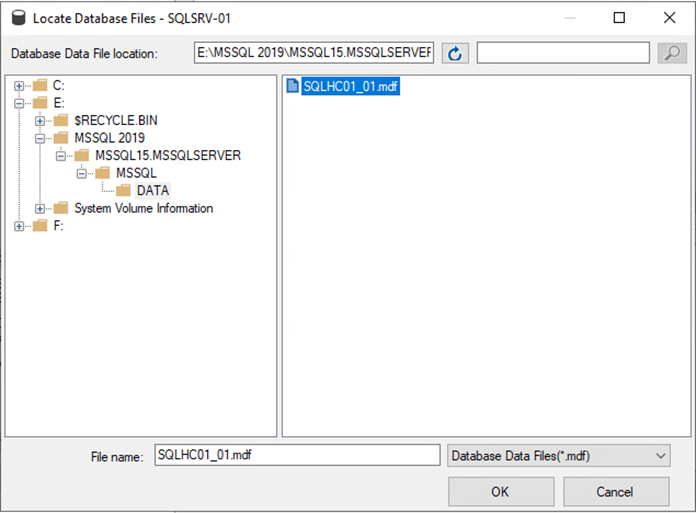
-
Si les journaux de transactions se trouvent sur un lecteur distinct, choisissez le dossier qui contient le journal des transactions.
-
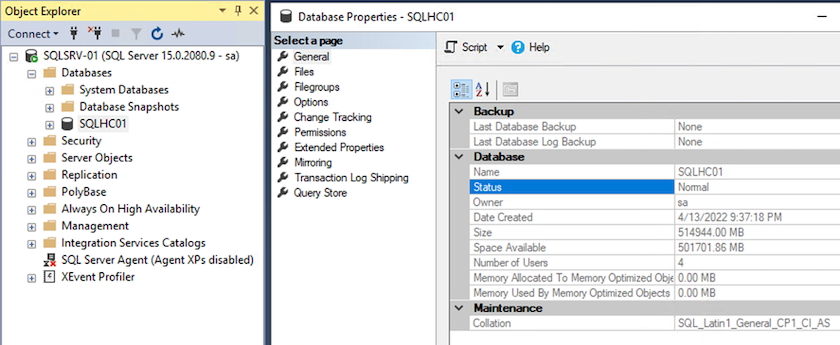
Une fois terminé, cliquez sur OK pour joindre la base de données.
Confirmer la communication de SnapCenter avec le plug-in SQL Server
Une fois la base de données SnapCenter restaurée à son état précédent, elle redécouvre automatiquement les hôtes SQL Server. Pour que cela fonctionne correctement, gardez à l’esprit les prérequis suivants :
-
SnapCenter doit être placé en mode de récupération après sinistre. Cela peut être réalisé via l'API Swagger ou dans les paramètres globaux sous Reprise après sinistre.
-
Le nom de domaine complet du serveur SQL doit être identique à celui de l’instance qui s’exécutait dans le centre de données local.
-
La relation SnapMirror d'origine doit être rompue.
-
Les LUN contenant la base de données doivent être montés sur l'instance SQL Server et la base de données attachée.
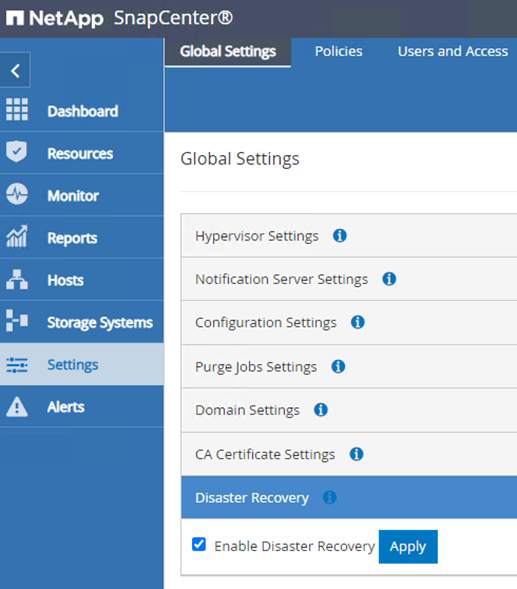
Pour confirmer que SnapCenter est en mode de récupération après sinistre, accédez aux paramètres depuis le client Web SnapCenter . Accédez à l’onglet Paramètres globaux, puis cliquez sur Récupération après sinistre. Assurez-vous que la case à cocher Activer la récupération après sinistre est activée.
Restaurer les données d'application Oracle
Le processus suivant fournit des instructions sur la façon de récupérer les données d'application Oracle dans VMware Cloud Services dans AWS en cas de sinistre rendant le site local inutilisable.
Remplissez les conditions préalables suivantes pour continuer les étapes de récupération :
-
La machine virtuelle du serveur Oracle Linux a été restaurée sur le SDDC VMware Cloud à l’aide de Veeam Full Restore.
-
Un serveur SnapCenter secondaire a été établi et la base de données et les fichiers de configuration SnapCenter ont été restaurés en suivant les étapes décrites dans cette section."Résumé du processus de sauvegarde et de restauration de SnapCenter ."
Configurer FSx pour la restauration Oracle – Rompre la relation SnapMirror
Pour rendre les volumes de stockage secondaires hébergés sur l'instance FSx ONTAP accessibles aux serveurs Oracle, vous devez d'abord rompre la relation SnapMirror existante.
-
Après vous être connecté à l'interface de ligne de commande FSx, exécutez la commande suivante pour afficher les volumes filtrés par le nom correct.
FSx-Dest::> volume show -volume VolumeName*
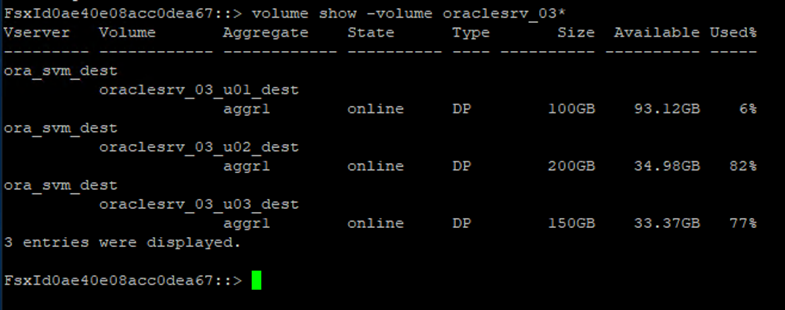
-
Exécutez la commande suivante pour rompre les relations SnapMirror existantes.
FSx-Dest::> snapmirror break -destination-path DestSVM:DestVolName

-
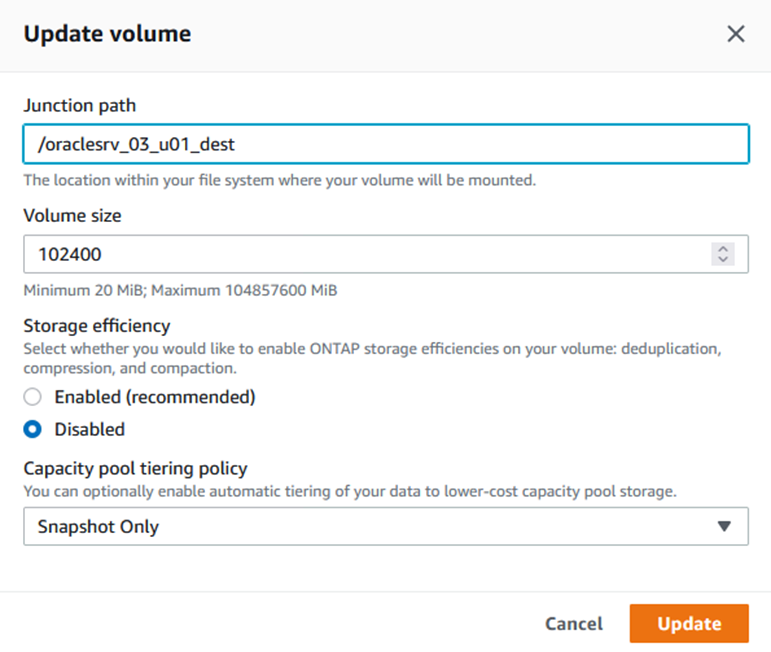
Mettre à jour le chemin de jonction dans le client Web Amazon FSx :
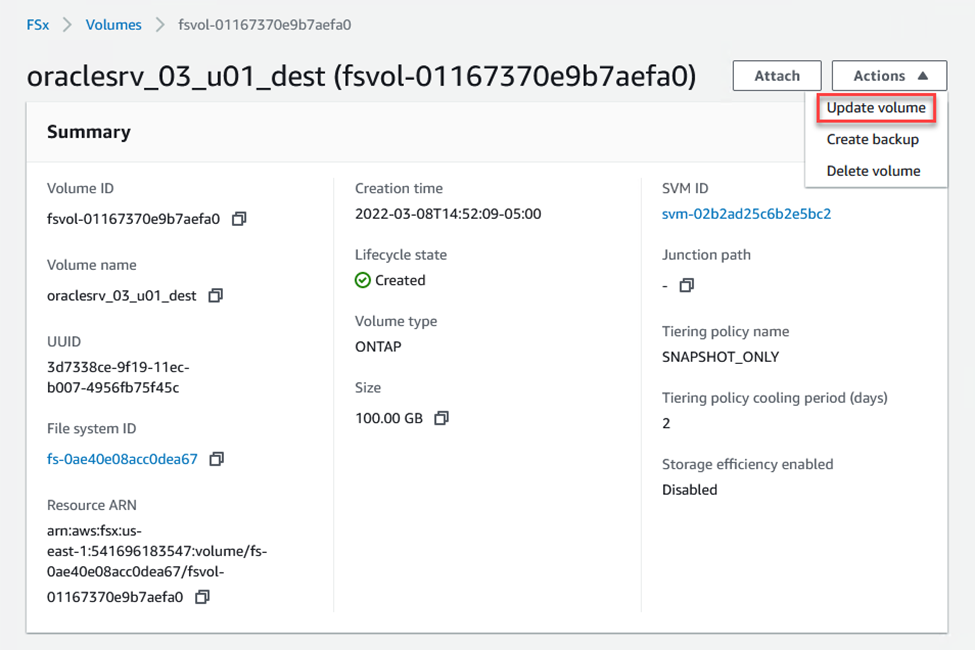
-
Ajoutez le nom du chemin de jonction et cliquez sur Mettre à jour. Spécifiez ce chemin de jonction lors du montage du volume NFS à partir du serveur Oracle.
Monter des volumes NFS sur Oracle Server
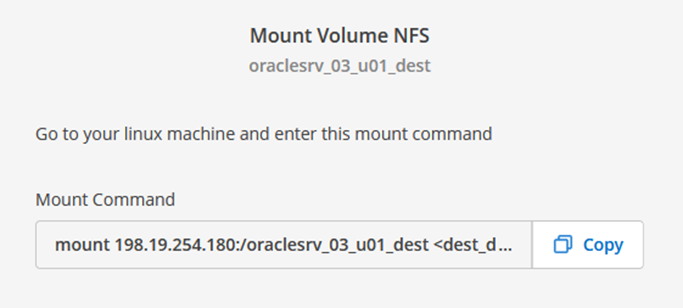
Dans Cloud Manager, vous pouvez obtenir la commande mount avec l'adresse IP NFS LIF correcte pour monter les volumes NFS qui contiennent les fichiers et les journaux de base de données Oracle.
-
Dans Cloud Manager, accédez à la liste des volumes de votre cluster FSx.
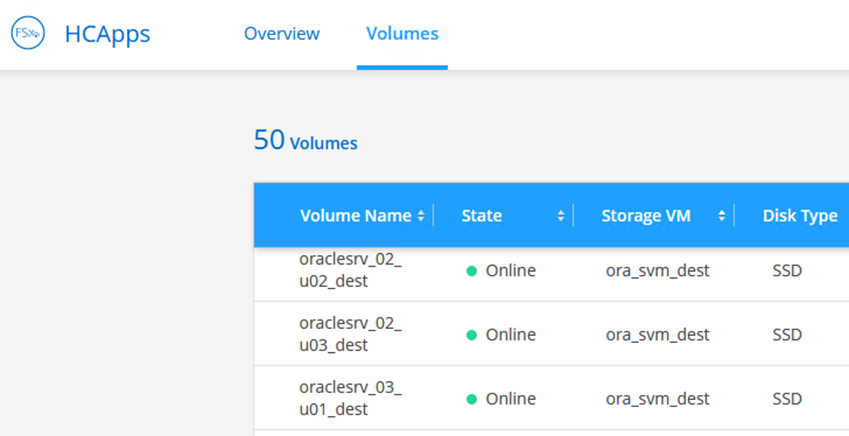
-
Dans le menu d’action, sélectionnez Commande de montage pour afficher et copier la commande de montage à utiliser sur notre serveur Oracle Linux.
-
Montez le système de fichiers NFS sur le serveur Oracle Linux. Les répertoires de montage du partage NFS existent déjà sur l'hôte Oracle Linux.
-
Depuis le serveur Oracle Linux, utilisez la commande mount pour monter les volumes NFS.
FSx-Dest::> mount -t oracle_server_ip:/junction-path
Répétez cette étape pour chaque volume associé aux bases de données Oracle.
Pour rendre le montage NFS persistant au redémarrage, modifiez le /etc/fstabfichier pour inclure les commandes de montage. -
Redémarrez le serveur Oracle. Les bases de données Oracle devraient démarrer normalement et être disponibles à l'utilisation.
Retour arrière
Une fois le processus de basculement décrit dans cette solution terminé avec succès, SnapCenter et Veeam reprennent leurs fonctions de sauvegarde exécutées dans AWS, et FSx ONTAP est désormais désigné comme stockage principal sans relations SnapMirror existantes avec le centre de données local d'origine. Une fois le fonctionnement normal repris sur site, vous pouvez utiliser un processus identique à celui décrit dans cette documentation pour mettre en miroir les données sur le système de stockage ONTAP sur site.
Comme indiqué dans cette documentation, vous pouvez configurer SnapCenter pour mettre en miroir les volumes de données d'application de FSx ONTAP vers un système de stockage ONTAP résidant sur site. De même, vous pouvez configurer Veeam pour répliquer des copies de sauvegarde sur Amazon S3 à l’aide d’un référentiel de sauvegarde évolutif afin que ces sauvegardes soient accessibles à un serveur de sauvegarde Veeam résidant dans le centre de données sur site.
La restauration automatique n'entre pas dans le cadre de cette documentation, mais elle diffère peu du processus détaillé décrit ici.
Conclusion
Le cas d’utilisation présenté dans cette documentation se concentre sur les technologies de reprise après sinistre éprouvées qui mettent en évidence l’intégration entre NetApp et VMware. Les systèmes de stockage NetApp ONTAP fournissent des technologies de mise en miroir de données éprouvées qui permettent aux organisations de concevoir des solutions de reprise après sinistre qui couvrent les technologies sur site et ONTAP résidant chez les principaux fournisseurs de cloud.
FSx ONTAP sur AWS est l'une de ces solutions qui permet une intégration transparente avec SnapCenter et SyncMirror pour la réplication des données d'application vers le cloud. Veeam Backup & Replication est une autre technologie bien connue qui s'intègre bien aux systèmes de stockage NetApp ONTAP et peut fournir un basculement vers le stockage natif vSphere.
Cette solution présentait une solution de reprise après sinistre utilisant le stockage de connexion invité à partir d'un système ONTAP hébergeant des données d'application SQL Server et Oracle. SnapCenter avec SnapMirror fournit une solution facile à gérer pour protéger les volumes d'application sur les systèmes ONTAP et les répliquer vers FSx ou CVO résidant dans le cloud. SnapCenter est une solution compatible DR permettant de basculer toutes les données d'application vers VMware Cloud sur AWS.