

Développez une configuration MetroCluster IP
 Suggérer des modifications
Suggérer des modifications
Selon votre version de ONTAP, vous pouvez étendre votre configuration MetroCluster IP en ajoutant quatre nouveaux nœuds en tant que nouveau groupe de reprise sur incident.
À partir de ONTAP 9.13.1, vous pouvez développer temporairement une configuration MetroCluster à huit nœuds pour actualiser les contrôleurs et le stockage. Voir "Actualisation d'une configuration IP MetroCluster à quatre ou huit nœuds (ONTAP 9.8 et versions ultérieures)" pour en savoir plus.
Depuis ONTAP 9.9.1, vous pouvez ajouter quatre nouveaux nœuds à la configuration IP de MetroCluster en tant que second groupe de reprise après incident. Cela crée une configuration MetroCluster à huit nœuds.
Les conseils suivants concernent un scénario peu courant dans lequel vous devez ajouter un ancien modèle de plate-forme (plates-formes publiées avant ONTAP 9.15.1) à une configuration MetroCluster existante qui contient un modèle de plate-forme plus récent (plates-formes publiées dans ONTAP 9.15.1 ou plus tard).
Si votre configuration MetroCluster existante contient une plate-forme qui utilise des ports shared cluster/HA (plates-formes publiées dans ONTAP 9.15.1 ou plus tard), vous ne pouvez pas ajouter une plate-forme qui utilise des ports shared MetroCluster/HA (plates-formes publiées avant ONTAP 9.15.1) sans mettre à niveau tous les nœuds de la configuration vers ONTAP 9.15.1P11 ou ONTAP 9.16.1P4 ou plus tard.

|
L'ajout d'un ancien modèle de plate-forme qui utilise des ports partagés/MetroCluster HA à un MetroCluster contenant un modèle de plate-forme plus récent qui utilise des ports partagés cluster/HA est un scénario peu courant et la plupart des combinaisons ne sont pas affectées. |
Utilisez le tableau suivant pour vérifier si votre combinaison est affectée. Si votre plate-forme existante est répertoriée dans la première colonne et que la plate-forme que vous souhaitez ajouter à la configuration est répertoriée dans la deuxième colonne, tous les nœuds de la configuration doivent exécuter ONTAP 9.15.1P11 ou ONTAP 9.16.1P4 ou une version ultérieure pour ajouter le nouveau groupe DR.
| Si votre MetroCluster existant contient… | Et la plateforme que vous ajoutez est… | Alors… | ||
|---|---|---|---|---|
Un système AFF utilisant des ports de cluster/HA partagés :
|
Un système FAS utilisant des ports de cluster/HA partagés :
|
Un système AFF utilisant des ports MetroCluster/HA partagés :
|
Un système FAS utilisant des ports MetroCluster/HA partagés :
|
Avant d'ajouter la nouvelle plateforme à votre configuration MetroCluster existante, mettez à niveau tous les nœuds de la configuration existante et nouvelle vers ONTAP 9.15.1P11 ou ONTAP 9.16.1P4 ou version ultérieure. |
-
L'ancien et le nouveau nœud doivent exécuter la même version de ONTAP.
-
Cette procédure décrit les étapes requises pour ajouter un groupe DR à quatre nœuds à une configuration IP MetroCluster existante. Si vous actualisez une configuration à huit nœuds, vous devez répéter l'intégralité de la procédure pour chaque groupe de reprise après incident, en l'ajoutant un à la fois.
-
Vérifier que les anciens et nouveaux modèles de plate-forme sont pris en charge pour le mélange de plate-forme.
-
Vérifiez que les anciens et les nouveaux modèles de plate-forme sont pris en charge par les commutateurs IP.
-
Si vous l'êtes "Actualisation d'une configuration IP MetroCluster à quatre ou huit nœuds", les nouveaux nœuds doivent disposer d'un espace de stockage suffisant pour prendre en charge les données des anciens nœuds, ainsi que les disques appropriés pour les agrégats racine et les disques de secours.
-
Vérifiez qu'un domaine de diffusion par défaut est créé sur les anciens nœuds.
Lorsque vous ajoutez de nouveaux nœuds à un cluster existant sans broadcast domain par défaut, les LIFs de node-management sont créées pour les nouveaux nœuds à l'aide d'UUID (Universal unique identifier) à la place des noms attendus. Pour plus d'informations, consultez l'article de la base de connaissances "Les LIF de gestion de nœuds sur les nouveaux nœuds ajoutés sont générées avec des noms UUID".
Activer la journalisation de la console
NetApp vous recommande vivement d'activer la journalisation de la console sur les périphériques que vous utilisez et d'effectuer les actions suivantes lors de l'exécution de cette procédure :
-
Laissez AutoSupport activé pendant la maintenance.
-
Déclencher un message AutoSupport de maintenance avant et après la maintenance pour désactiver la création de dossiers pendant la durée de l'activité de maintenance.
Consultez l'article de la base de connaissances "Comment supprimer la création automatique de dossier pendant les fenêtres de maintenance planifiées".
-
Activer la journalisation de session pour toute session CLI. Pour obtenir des instructions sur l'activation de la journalisation des sessions, consultez la section « consignation des sorties de session » de l'article de la base de connaissances "Comment configurer PuTTY pour une connectivité optimale aux systèmes ONTAP".
Exemple de dénomination dans cette procédure
Cette procédure utilise des exemples de noms au cours de l'ensemble pour identifier les groupes de reprise sur incident, les nœuds et les commutateurs impliqués.
Groupes de reprise sur incident |
Cluster_A au site_A |
Cluster_B au niveau du site_B |
dr_group_1-old |
|
|
dr_group_2-new |
|
|
Combinaisons de plateformes prises en charge lors de l'ajout d'un deuxième groupe de reprise après incident
Les tableaux suivants présentent les combinaisons de plateformes prises en charge pour les configurations IP MetroCluster à huit nœuds.

|
|
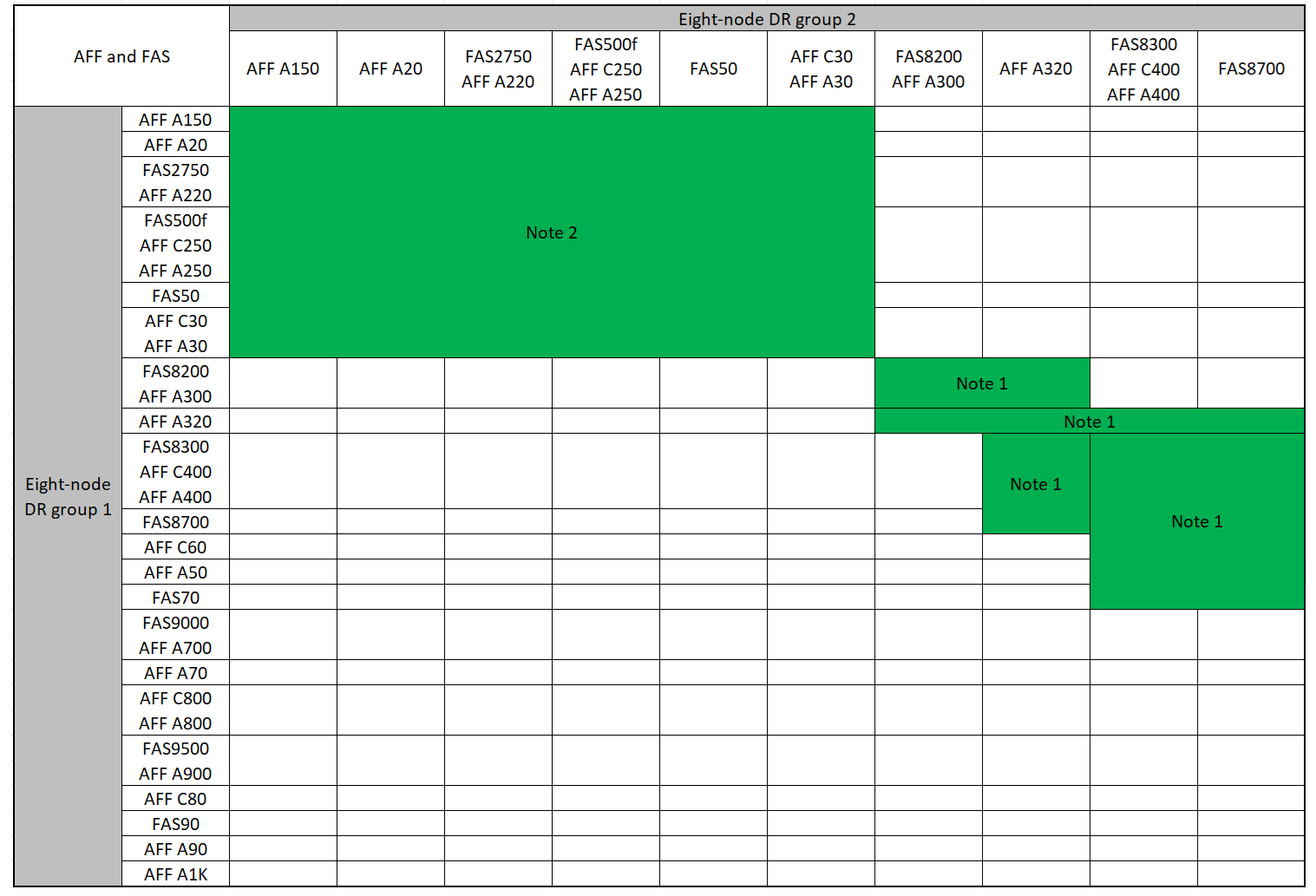
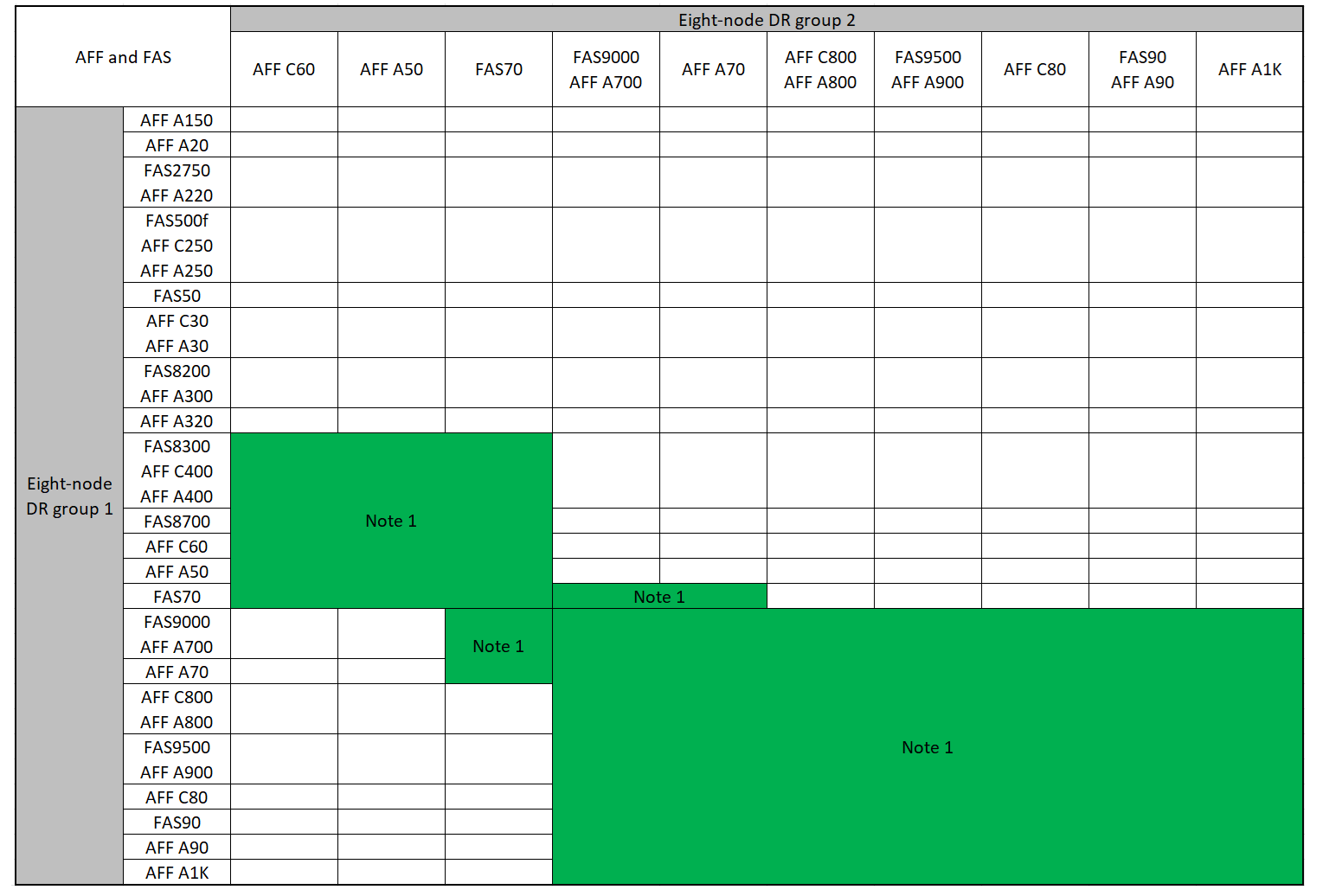
Combinaisons d'extension IP AFF et FAS MetroCluster prises en charge
Les tableaux suivants présentent les combinaisons de plates-formes prises en charge pour l'extension d'un système AFF ou FAS dans une configuration IP MetroCluster. Les tables sont divisées en deux groupes :
-
Le Groupe 1 présente des combinaisons pour les systèmes AFF A150, AFF A20, FAS2750, FAS8300, FAS500f, AFF C250, AFF A250, FAS50, AFF C30, AFF A30, FAS8200, AFF A300, AFF A400, AFF A220, AFF C400, AFF A320 et FAS8700.
-
Le Groupe 2 présente des combinaisons pour les systèmes AFF C60, AFF A50, FAS70, FAS9000, AFF A700, AFF A70, AFF C800, AFF A800, FAS9500, AFF A900, AFF C80, FAS90, AFF A90 et AFF A1K.
Les remarques suivantes s'appliquent aux deux groupes :
-
Remarque 1 : ONTAP 9.9.1 ou version ultérieure (ou la version minimale de ONTAP prise en charge sur la plate-forme) est requise pour ces combinaisons.
-
Remarque 2 : ONTAP 9.13.1 ou version ultérieure (ou la version minimale de ONTAP prise en charge sur la plate-forme) est requise pour ces combinaisons.
Examinez les combinaisons d'extension pour les systèmes AFF A150, AFF A20, FAS2750, FAS8300, FAS500f, AFF C250, AFF A250, FAS50, AFF C30, AFF A30, FAS8200, AFF A300, AFF A400, AFF A220, AFF C400, AFF A320 et FAS8700.
Découvrez les combinaisons d'extension pour les systèmes AFF C60, AFF A50, FAS70, FAS9000, AFF A700, AFF A70, AFF C800, AFF A800, FAS9500, AFF A900, AFF C80, FAS90, AFF A90 et AFF A1K.
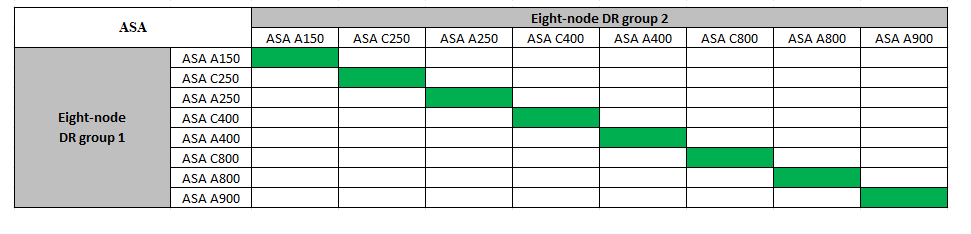
Combinaisons d'extension IP ASA MetroCluster prises en charge
Le tableau suivant présente les combinaisons de plateformes prises en charge pour l'extension d'un système ASA dans une configuration MetroCluster IP :
Envoyer un message AutoSupport personnalisé avant la maintenance
Avant d'effectuer la maintenance, vous devez envoyer un message AutoSupport pour informer le support technique de NetApp que la maintenance est en cours. Informer le support technique que la maintenance est en cours empêche l'ouverture d'un dossier en supposant une interruption de l'activité.
Cette tâche doit être effectuée sur chaque site MetroCluster.
-
Pour éviter la génération automatique de dossiers de demande de support, envoyez un message AutoSupport pour indiquer que la mise à niveau est en cours.
-
Exécutez la commande suivante :
system node autosupport invoke -node * -type all -message "MAINT=10h Upgrading <old-model> to <new-model>Cet exemple spécifie une fenêtre de maintenance de 10 heures. Selon votre plan, il est possible que vous souhaitiez accorder plus de temps.
Si la maintenance est terminée avant le temps écoulé, vous pouvez appeler un message AutoSupport indiquant la fin de la période de maintenance :
system node autosupport invoke -node * -type all -message MAINT=end-
Répétez la commande sur le cluster partenaire.
-
Considérations relatives aux VLAN lors de l'ajout d'un nouveau groupe DR
-
Les considérations VLAN suivantes s'appliquent lors de l'extension d'une configuration MetroCluster IP :
Certaines plates-formes utilisent un VLAN pour l'interface IP de MetroCluster. Par défaut, chacun des deux ports utilise un VLAN différent : 10 et 20.
Si elle est prise en charge, vous pouvez également spécifier un VLAN différent (non par défaut) supérieur à 100 (entre 101 et 4095) en utilisant le
-vlan-idparamètre de lametrocluster configuration-settings interface createcommande.Les plates-formes suivantes ne prennent pas en charge le
-vlan-idparamètre :-
FAS8200 ET AFF A300
-
AFF A320
-
FAS9000 et AFF A700
-
AFF C800, ASA C800, AFF A800 et ASA A800
Toutes les autres plates-formes prennent en charge le
-vlan-idparamètre.Les affectations de VLAN par défaut et valides dépendent du fait que la plate-forme prend en charge le
-vlan-idparamètre :
Les plateformes qui prennent en charge <code>-vlan-</code>VLAN par défaut :
-
Lorsque le
-vlan-idparamètre n'est pas spécifié, les interfaces sont créées avec le VLAN 10 pour les ports "A" et le VLAN 20 pour les ports "B". -
Le VLAN spécifié doit correspondre au VLAN sélectionné dans la FCR.
Plages VLAN valides :
-
VLAN 10 et 20 par défaut
-
VLAN 101 et supérieur (entre 101 et 4095)
Les plateformes qui ne prennent pas en charge <code>-vlan-</code>VLAN par défaut :
-
Sans objet L'interface ne nécessite pas la spécification d'un VLAN sur l'interface MetroCluster. Le port du commutateur définit le VLAN utilisé.
Plages VLAN valides :
-
Tous les VLAN non explicitement exclus lors de la génération de la FCR. Le RCF vous avertit si le VLAN n'est pas valide.
-
-
Les deux groupes de reprise sur incident utilisent les mêmes VLAN lorsque vous effectuez un développement à partir d'une configuration à quatre nœuds vers une configuration MetroCluster à huit nœuds.
-
Si les deux groupes DR ne peuvent pas être configurés à l'aide du même VLAN, vous devez mettre à niveau le groupe DR qui ne prend pas en charge
vlan-idle paramètre pour utiliser un VLAN pris en charge par l'autre groupe DR.
Vérifier l'état de santé de la configuration MetroCluster
Vous devez vérifier l'intégrité et la connectivité de la configuration MetroCluster avant d'effectuer l'extension.
-
Vérifier le fonctionnement de la configuration MetroCluster dans ONTAP :
-
Vérifier si le système est multipathed :
node run -node <node-name> sysconfig -a -
Vérifier si des alertes d'intégrité sont disponibles sur les deux clusters :
system health alert show -
Vérifier la configuration MetroCluster et que le mode opérationnel est normal :
metrocluster show -
Effectuer une vérification MetroCluster :
metrocluster check run -
Afficher les résultats de la vérification MetroCluster :
metrocluster check show -
Exécutez Config Advisor.
-
Une fois Config Advisor exécuté, vérifiez les résultats de l'outil et suivez les recommandations fournies dans la sortie pour résoudre tous les problèmes détectés.
-
-
Vérifiez que le cluster fonctionne correctement :
cluster showcluster_A::> cluster show Node Health Eligibility -------------- ------ ----------- node_A_1 true true node_A_2 true true cluster_A::>
-
Vérifier que tous les ports du cluster sont bien :
network port show -ipspace Clustercluster_A::> network port show -ipspace Cluster Node: node_A_1-old Speed(Mbps) Health Port IPspace Broadcast Domain Link MTU Admin/Oper Status --------- ------------ ---------------- ---- ---- ----------- -------- e0a Cluster Cluster up 9000 auto/10000 healthy e0b Cluster Cluster up 9000 auto/10000 healthy Node: node_A_2-old Speed(Mbps) Health Port IPspace Broadcast Domain Link MTU Admin/Oper Status --------- ------------ ---------------- ---- ---- ----------- -------- e0a Cluster Cluster up 9000 auto/10000 healthy e0b Cluster Cluster up 9000 auto/10000 healthy 4 entries were displayed. cluster_A::> -
Vérifier que toutes les LIFs de cluster sont opérationnelles :
network interface show -vserver ClusterChaque LIF de cluster doit afficher « true » pour is Home et avoir un Status Admin/Oper of up/up »
cluster_A::> network interface show -vserver cluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ----- Cluster node_A_1-old_clus1 up/up 169.254.209.69/16 node_A_1 e0a true node_A_1-old_clus2 up/up 169.254.49.125/16 node_A_1 e0b true node_A_2-old_clus1 up/up 169.254.47.194/16 node_A_2 e0a true node_A_2-old_clus2 up/up 169.254.19.183/16 node_A_2 e0b true 4 entries were displayed. cluster_A::> -
Vérifiez que la fonction de restauration automatique est activée sur l'ensemble des LIFs du cluster :
network interface show -vserver Cluster -fields auto-revertcluster_A::> network interface show -vserver Cluster -fields auto-revert Logical Vserver Interface Auto-revert --------- ------------- ------------ Cluster node_A_1-old_clus1 true node_A_1-old_clus2 true node_A_2-old_clus1 true node_A_2-old_clus2 true 4 entries were displayed. cluster_A::>
Supprimez la configuration des applications de surveillance
Si la configuration existante est contrôlée avec le logiciel MetroCluster Tiebreaker, le médiateur ONTAP ou d'autres applications tierces (par exemple, ClusterLion) qui peuvent lancer un basculement, vous devez supprimer la configuration MetroCluster du logiciel de surveillance avant la mise à niveau.
-
Supprimez la configuration MetroCluster existante du logiciel disjoncteur d'attache, du médiateur ou d'autres logiciels pouvant initier le basculement.
Si vous utilisez…
Utilisez cette procédure…
Disjoncteur d'attache
Médiateur
Exécutez la commande suivante depuis l'invite ONTAP :
metrocluster configuration-settings mediator removeApplications tierces
Reportez-vous à la documentation du produit.
-
Supprimez la configuration MetroCluster existante de toute application tierce pouvant effectuer le basculement.
Reportez-vous à la documentation de l'application.
Préparez les nouveaux modules de contrôleur
Vous devez préparer les quatre nouveaux nœuds MetroCluster et installer la version correcte de ONTAP.
Cette tâche doit être effectuée sur chacun des nouveaux nœuds :
-
Node_A_3-New
-
Node_A_4-New
-
Node_B_3-New
-
Node_B_4-New
Dans ces étapes, vous effacez la configuration sur les nœuds et désactivez la zone de la boîte aux lettres sur les nouveaux lecteurs.
-
Installez les nouveaux contrôleurs.
-
Reliez les nouveaux nœuds IP MetroCluster aux commutateurs IP, comme illustré à la "Câblez les commutateurs IP".
-
Configurez les nœuds IP MetroCluster à l'aide des procédures suivantes :
-
En mode maintenance, saisissez la commande halt pour quitter le mode maintenance :
halt -
Vérifiez si le partner-sysid est correct :
printenv partner-sysid -
Si le partenaire-sysid n'est pas correct, définissez-le :
setenv partner-sysid <partner-sysID> -
Démarrez le système et accédez à la configuration du cluster :
boot_ontapNe terminez pas encore l'assistant de cluster ou l'assistant de nœud pour le moment.
Mettre à niveau les fichiers RCF
Si vous installez un nouveau firmware du commutateur, vous devez installer le micrologiciel du commutateur avant de mettre à niveau le fichier RCF.
Cette procédure perturbe le trafic sur le commutateur où le fichier RCF est mis à niveau. Le trafic reprend lorsque le nouveau fichier RCF est appliqué.
-
Vérification de l'état de santé de la configuration.
-
Vérifiez que les composants MetroCluster sont sains :
metrocluster check runcluster_A::*> metrocluster check run
L'opération s'exécute en arrière-plan.
-
Après le
metrocluster check runopération terminée, exécutionmetrocluster check showpour afficher les résultats.Après environ cinq minutes, les résultats suivants s'affichent :
----------- ::*> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
Vérifier l'état de l'opération de vérification MetroCluster en cours :
metrocluster operation history show -job-id 38 -
Vérifiez qu'il n'y a pas d'alerte de santé :
system health alert show
-
-
Préparez les commutateurs IP pour l'application des nouveaux fichiers RCF.
Suivez les étapes pour votre fournisseur de commutateur :
-
Téléchargez et installez le fichier RCF IP, selon votre fournisseur de commutateur.

Mettre à jour les interrupteurs dans l'ordre suivant : Switch_A_1, Switch_B_1, Switch_A_2, Switch_B_2 -
"Téléchargez et installez les fichiers RCF IP de NVIDIA"
Si vous disposez d'une configuration réseau L2 partagée ou L3, il se peut que vous deviez ajuster les ports ISL sur les commutateurs intermédiaire/client. Le mode du port du commutateur peut passer du mode d'accès au mode de jonction. Ne procédez à la mise à niveau de la deuxième paire de commutateurs (A_2, B_2) que si la connectivité réseau entre les commutateurs A_1 et B_1 est pleinement opérationnelle et que le réseau fonctionne correctement.
Reliez les nouveaux nœuds aux clusters
Vous devez ajouter les quatre nouveaux nœuds IP MetroCluster à la configuration MetroCluster existante.
Vous devez effectuer cette tâche sur les deux clusters.
-
Ajoutez les nouveaux nœuds IP MetroCluster à la configuration MetroCluster existante.
-
Associez le premier nouveau nœud IP MetroCluster (node_A_1-New) à la configuration IP MetroCluster existante.
Welcome to the cluster setup wizard. You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the cluster setup wizard. Any changes you made before quitting will be saved. You can return to cluster setup at any time by typing "cluster setup". To accept a default or omit a question, do not enter a value. This system will send event messages and periodic reports to NetApp Technical Support. To disable this feature, enter autosupport modify -support disable within 24 hours. Enabling AutoSupport can significantly speed problem determination and resolution, should a problem occur on your system. For further information on AutoSupport, see: http://support.netapp.com/autosupport/ Type yes to confirm and continue {yes}: yes Enter the node management interface port [e0M]: 172.17.8.93 172.17.8.93 is not a valid port. The physical port that is connected to the node management network. Examples of node management ports are "e4a" or "e0M". You can type "back", "exit", or "help" at any question. Enter the node management interface port [e0M]: Enter the node management interface IP address: 172.17.8.93 Enter the node management interface netmask: 255.255.254.0 Enter the node management interface default gateway: 172.17.8.1 A node management interface on port e0M with IP address 172.17.8.93 has been created. Use your web browser to complete cluster setup by accessing https://172.17.8.93 Otherwise, press Enter to complete cluster setup using the command line interface: Do you want to create a new cluster or join an existing cluster? {create, join}: join Existing cluster interface configuration found: Port MTU IP Netmask e0c 9000 169.254.148.217 255.255.0.0 e0d 9000 169.254.144.238 255.255.0.0 Do you want to use this configuration? {yes, no} [yes]: yes . . . -
Associez le second nœud IP MetroCluster (node_A_2-New) à la configuration IP MetroCluster existante.
-
-
Répétez ces étapes pour joindre le noeud_B_1-New et le noeud_B_2-New à cluster_B.
Configurer les LIF intercluster pour le peering de clusters
Vous devez créer des LIFs intercluster sur les ports utilisés pour la communication entre les clusters partenaires MetroCluster. Vous pouvez utiliser des ports ou ports dédiés qui ont également le trafic de données.
Vous pouvez configurer les LIFs intercluster sur des ports dédiés. Cela augmente généralement la bande passante disponible pour le trafic de réplication.
-
Lister les ports dans le cluster :
network port showPour connaître la syntaxe complète des commandes, consultez le "Référence des commandes ONTAP".
L'exemple suivant montre les ports réseau en « cluster01 » :
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
Déterminer les ports disponibles pour dédier aux communications intercluster :
network interface show -fields home-port,curr-portPour connaître la syntaxe complète des commandes, consultez le "Référence des commandes ONTAP".
L'exemple suivant montre que les ports « e0e » et « e0f » n'ont pas été affectés aux LIF :
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
Créer un failover group pour les ports dédiés :
network interface failover-groups create -vserver <system_svm> -failover-group <failover_group> -targets <physical_or_logical_ports>L'exemple suivant attribue les ports « e0e » et « e0f » au groupe de basculement « intercluster01 » sur la SVM « cluster01 » :
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
Vérifier que le groupe de basculement a été créé :
network interface failover-groups showPour connaître la syntaxe complète des commandes, consultez le "Référence des commandes ONTAP".
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
Créer les LIF intercluster sur le SVM système et les assigner au failover group.
network interface create -vserver <system_svm> -lif <lif_name> -service-policy default-intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask_address> -failover-group <failover_group>L'exemple suivant illustre la création des LIFs intercluster « cluster01_icl01 » et « cluster01_icl02 » dans le groupe de basculement « intercluster01 » :
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
Vérifier que les LIFs intercluster ont été créés :
network interface show -service-policy default-interclustercluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0e true -
Vérifier que les LIFs intercluster sont redondants :
network interface show -service-policy default-intercluster -failoverL'exemple suivant montre que les LIF intercluster « cluster01_icl01 » et « cluster01_icl02 » sur le port « e0e » basculeront vers le port « e0f ».
cluster01::> network interface show -service-policy default-intercluster -failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
Vous pouvez configurer les LIFs intercluster sur des ports partagés avec le réseau de données. Cela réduit le nombre de ports nécessaires pour la mise en réseau intercluster.
-
Lister les ports dans le cluster :
network port showPour connaître la syntaxe complète des commandes, consultez le "Référence des commandes ONTAP".
L'exemple suivant montre les ports réseau en « cluster01 » :
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
Création des LIFs intercluster sur le SVM système :
network interface create -vserver <system_svm> -lif <lif_name> -service-policy default-intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask>L'exemple suivant illustre la création des LIFs intercluster « cluster01_icl01 » et « cluster01_icl02 » :
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
Vérifier que les LIFs intercluster ont été créés :
network interface show -service-policy default-interclusterVous devriez obtenir un résultat similaire à l'exemple suivant :
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
Vérifier que les LIFs intercluster sont redondants :
network interface show -service-policy default-intercluster -failoverL'exemple suivant montre que les LIFs intercluster « cluster01_icl01 » et « cluster01_icl02 » sur le port « e0c » basculeront vers le port « e0d ».
cluster01::> network interface show -service-policy default-intercluster -failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only Default Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only Default Failover Targets: cluster01-02:e0c, cluster01-02:e0d
Créer les interfaces MetroCluster et les agrégats racines en miroir
Vous devez créer les interfaces MetroCluster sur les nouveaux nœuds IP MetroCluster et mettre en miroir les agrégats racine.
-
Le port home utilisé dans les exemples est spécifique à la plate-forme. Vous devez utiliser le port home spécifique à votre plate-forme de nœuds IP MetroCluster.
-
Consultez les informations de la section Considérations relatives aux VLAN lors de l'ajout d'un nouveau groupe DR avant d'effectuer cette tâche.
-
Sur chaque site, ajoutez les nouveaux LIF intercluster à la relation de pair.
Depuis le cluster_A, exécutez la commande suivante :
cluster peer modify -cluster cluster_B -peer-addrs <node_B_1-old IC port_ip_address>,<node_B_2-old IC port_ip_address>,<node_B_1-new IC port_ip_address>,<node_B_2-new IC port_ip_address>Depuis le cluster_B, exécutez la commande suivante :
cluster peer modify -cluster cluster_A -peer-addrs <node_A_1-old IC port_ip_address>,<node_A_2-old IC port_ip_address>,<node_A_1-new IC port_ip_address>,<node_A_2-new IC port_ip_address> -
Sur chaque site, vérifiez que le peering de cluster est configuré :
cluster peer showL'exemple suivant montre la configuration de peering de cluster sur cluster_A :
cluster_A:> cluster peer show Peer Cluster Name Cluster Serial Number Availability Authentication ------------------------- --------------------- -------------- -------------- cluster_B 1-80-000011 Available ok cluster_A::>
L'exemple suivant montre la configuration de peering de cluster sur cluster_B :
cluster_B:> cluster peer show Peer Cluster Name Cluster Serial Number Availability Authentication ------------------------- --------------------- -------------- -------------- cluster_A 1-80-000011 Available ok cluster_B::>
-
Créez le groupe DR pour les nœuds IP MetroCluster :
metrocluster configuration-settings dr-group create -partner-clusterPour plus d'informations sur les paramètres de configuration et les connexions du MetroCluster, reportez-vous aux sections suivantes :
cluster_A::> metrocluster configuration-settings dr-group create -partner-cluster cluster_B -local-node node_A_1-new -remote-node node_B_1-new [Job 259] Job succeeded: DR Group Create is successful. cluster_A::>
-
Vérifiez que le groupe DR a été créé.
metrocluster configuration-settings dr-group showcluster_A::> metrocluster configuration-settings dr-group show DR Group ID Cluster Node DR Partner Node ----------- -------------------------- ------------------ ------------------ 1 cluster_A node_A_1-old node_B_1-old node_A_2-old node_B_2-old cluster_B node_B_1-old node_A_1-old node_B_2-old node_A_2-old 2 cluster_A node_A_1-new node_B_1-new node_A_2-new node_B_2-new cluster_B node_B_1-new node_A_1-new node_B_2-new node_A_2-new 8 entries were displayed. cluster_A::> -
Configurez les interfaces IP MetroCluster pour les nœuds IP MetroCluster nouvellement rejoints :
-
N'utilisez pas d'adresses IP 169.254.17.x ou 169.254.18.x lorsque vous créez des interfaces IP MetroCluster pour éviter les conflits avec les adresses IP d'interface générées automatiquement par le système dans la même plage.
-
Si elle est prise en charge, vous pouvez spécifier un VLAN différent (non par défaut) supérieur à 100 (entre 101 et 4095) en utilisant le
-vlan-idparamètre de lametrocluster configuration-settings interface createcommande. Reportez-vous Considérations relatives aux VLAN lors de l'ajout d'un nouveau groupe DR à pour obtenir des informations sur la plate-forme prise en charge -
Vous pouvez configurer les interfaces IP MetroCluster depuis n'importe quel cluster.
metrocluster configuration-settings interface create -cluster-namecluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_1-new -home-port e1a -address 172.17.26.10 -netmask 255.255.255.0 [Job 260] Job succeeded: Interface Create is successful. cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_1-new -home-port e1b -address 172.17.27.10 -netmask 255.255.255.0 [Job 261] Job succeeded: Interface Create is successful. cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2-new -home-port e1a -address 172.17.26.11 -netmask 255.255.255.0 [Job 262] Job succeeded: Interface Create is successful. cluster_A::> :metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2-new -home-port e1b -address 172.17.27.11 -netmask 255.255.255.0 [Job 263] Job succeeded: Interface Create is successful. cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_1-new -home-port e1a -address 172.17.26.12 -netmask 255.255.255.0 [Job 264] Job succeeded: Interface Create is successful. cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_1-new -home-port e1b -address 172.17.27.12 -netmask 255.255.255.0 [Job 265] Job succeeded: Interface Create is successful. cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_2-new -home-port e1a -address 172.17.26.13 -netmask 255.255.255.0 [Job 266] Job succeeded: Interface Create is successful. cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_2-new -home-port e1b -address 172.17.27.13 -netmask 255.255.255.0 [Job 267] Job succeeded: Interface Create is successful.
-
-
Vérifiez que les interfaces IP MetroCluster sont créées :
metrocluster configuration-settings interface showcluster_A::>metrocluster configuration-settings interface show DR Config Group Cluster Node Network Address Netmask Gateway State ----- ------- ------- --------------- --------------- --------------- --------- 1 cluster_A node_A_1-old Home Port: e1a 172.17.26.10 255.255.255.0 - completed Home Port: e1b 172.17.27.10 255.255.255.0 - completed node_A_2-old Home Port: e1a 172.17.26.11 255.255.255.0 - completed Home Port: e1b 172.17.27.11 255.255.255.0 - completed cluster_B node_B_1-old Home Port: e1a 172.17.26.13 255.255.255.0 - completed Home Port: e1b 172.17.27.13 255.255.255.0 - completed node_B_1-old Home Port: e1a 172.17.26.12 255.255.255.0 - completed Home Port: e1b 172.17.27.12 255.255.255.0 - completed 2 cluster_A node_A_3-new Home Port: e1a 172.17.28.10 255.255.255.0 - completed Home Port: e1b 172.17.29.10 255.255.255.0 - completed node_A_3-new Home Port: e1a 172.17.28.11 255.255.255.0 - completed Home Port: e1b 172.17.29.11 255.255.255.0 - completed cluster_B node_B_3-new Home Port: e1a 172.17.28.13 255.255.255.0 - completed Home Port: e1b 172.17.29.13 255.255.255.0 - completed node_B_3-new Home Port: e1a 172.17.28.12 255.255.255.0 - completed Home Port: e1b 172.17.29.12 255.255.255.0 - completed 8 entries were displayed. cluster_A> -
Connectez les interfaces IP MetroCluster :
metrocluster configuration-settings connection connect
Cette commande peut prendre plusieurs minutes. cluster_A::> metrocluster configuration-settings connection connect cluster_A::>
-
Vérifiez que les connexions sont correctement établies :
metrocluster configuration-settings connection show
Le résultat de la metrocluster configuration-settings connection showcommande peut varier selon votre modèle de plateforme. Par exemple, sur certaines plateformes, les lignes pour HA Partner ne sont pas affichées dans le résultat.cluster_A::> metrocluster configuration-settings connection show DR Source Destination Group Cluster Node Network Address Network Address Partner Type Config State ----- ------- ------- --------------- --------------- ------------ ------------ 1 cluster_A node_A_1-old Home Port: e1a 172.17.28.10 172.17.28.11 HA Partner completed Home Port: e1a 172.17.28.10 172.17.28.12 DR Partner completed Home Port: e1a 172.17.28.10 172.17.28.13 DR Auxiliary completed Home Port: e1b 172.17.29.10 172.17.29.11 HA Partner completed Home Port: e1b 172.17.29.10 172.17.29.12 DR Partner completed Home Port: e1b 172.17.29.10 172.17.29.13 DR Auxiliary completed node_A_2-old Home Port: e1a 172.17.28.11 172.17.28.10 HA Partner completed Home Port: e1a 172.17.28.11 172.17.28.13 DR Partner completed Home Port: e1a 172.17.28.11 172.17.28.12 DR Auxiliary completed Home Port: e1b 172.17.29.11 172.17.29.10 HA Partner completed Home Port: e1b 172.17.29.11 172.17.29.13 DR Partner completed Home Port: e1b 172.17.29.11 172.17.29.12 DR Auxiliary completed DR Source Destination Group Cluster Node Network Address Network Address Partner Type Config State ----- ------- ------- --------------- --------------- ------------ ------------ 1 cluster_B node_B_2-old Home Port: e1a 172.17.28.13 172.17.28.12 HA Partner completed Home Port: e1a 172.17.28.13 172.17.28.11 DR Partner completed Home Port: e1a 172.17.28.13 172.17.28.10 DR Auxiliary completed Home Port: e1b 172.17.29.13 172.17.29.12 HA Partner completed Home Port: e1b 172.17.29.13 172.17.29.11 DR Partner completed Home Port: e1b 172.17.29.13 172.17.29.10 DR Auxiliary completed node_B_1-old Home Port: e1a 172.17.28.12 172.17.28.13 HA Partner completed Home Port: e1a 172.17.28.12 172.17.28.10 DR Partner completed Home Port: e1a 172.17.28.12 172.17.28.11 DR Auxiliary completed Home Port: e1b 172.17.29.12 172.17.29.13 HA Partner completed Home Port: e1b 172.17.29.12 172.17.29.10 DR Partner completed Home Port: e1b 172.17.29.12 172.17.29.11 DR Auxiliary completed DR Source Destination Group Cluster Node Network Address Network Address Partner Type Config State ----- ------- ------- --------------- --------------- ------------ ------------ 2 cluster_A node_A_1-new** Home Port: e1a 172.17.26.10 172.17.26.11 HA Partner completed Home Port: e1a 172.17.26.10 172.17.26.12 DR Partner completed Home Port: e1a 172.17.26.10 172.17.26.13 DR Auxiliary completed Home Port: e1b 172.17.27.10 172.17.27.11 HA Partner completed Home Port: e1b 172.17.27.10 172.17.27.12 DR Partner completed Home Port: e1b 172.17.27.10 172.17.27.13 DR Auxiliary completed node_A_2-new Home Port: e1a 172.17.26.11 172.17.26.10 HA Partner completed Home Port: e1a 172.17.26.11 172.17.26.13 DR Partner completed Home Port: e1a 172.17.26.11 172.17.26.12 DR Auxiliary completed Home Port: e1b 172.17.27.11 172.17.27.10 HA Partner completed Home Port: e1b 172.17.27.11 172.17.27.13 DR Partner completed Home Port: e1b 172.17.27.11 172.17.27.12 DR Auxiliary completed DR Source Destination Group Cluster Node Network Address Network Address Partner Type Config State ----- ------- ------- --------------- --------------- ------------ ------------ 2 cluster_B node_B_2-new Home Port: e1a 172.17.26.13 172.17.26.12 HA Partner completed Home Port: e1a 172.17.26.13 172.17.26.11 DR Partner completed Home Port: e1a 172.17.26.13 172.17.26.10 DR Auxiliary completed Home Port: e1b 172.17.27.13 172.17.27.12 HA Partner completed Home Port: e1b 172.17.27.13 172.17.27.11 DR Partner completed Home Port: e1b 172.17.27.13 172.17.27.10 DR Auxiliary completed node_B_1-new Home Port: e1a 172.17.26.12 172.17.26.13 HA Partner completed Home Port: e1a 172.17.26.12 172.17.26.10 DR Partner completed Home Port: e1a 172.17.26.12 172.17.26.11 DR Auxiliary completed Home Port: e1b 172.17.27.12 172.17.27.13 HA Partner completed Home Port: e1b 172.17.27.12 172.17.27.10 DR Partner completed Home Port: e1b 172.17.27.12 172.17.27.11 DR Auxiliary completed 48 entries were displayed. cluster_A::> -
Vérifiez l'affectation automatique et le partitionnement des disques :
disk show -pool Pool1cluster_A::> disk show -pool Pool1 Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- 1.10.4 - 10 4 SAS remote - node_B_2 1.10.13 - 10 13 SAS remote - node_B_2 1.10.14 - 10 14 SAS remote - node_B_1 1.10.15 - 10 15 SAS remote - node_B_1 1.10.16 - 10 16 SAS remote - node_B_1 1.10.18 - 10 18 SAS remote - node_B_2 ... 2.20.0 546.9GB 20 0 SAS aggregate aggr0_rha1_a1 node_a_1 2.20.3 546.9GB 20 3 SAS aggregate aggr0_rha1_a2 node_a_2 2.20.5 546.9GB 20 5 SAS aggregate rha1_a1_aggr1 node_a_1 2.20.6 546.9GB 20 6 SAS aggregate rha1_a1_aggr1 node_a_1 2.20.7 546.9GB 20 7 SAS aggregate rha1_a2_aggr1 node_a_2 2.20.10 546.9GB 20 10 SAS aggregate rha1_a1_aggr1 node_a_1 ... 43 entries were displayed. cluster_A::> -
Mettez en miroir les agrégats racine :
storage aggregate mirror -aggregate aggr0_node_A_1-new
Cette étape doit être effectuée sur chaque nœud IP MetroCluster. cluster_A::> aggr mirror -aggregate aggr0_node_A_1-new Info: Disks would be added to aggregate "aggr0_node_A_1-new"on node "node_A_1-new" in the following manner: Second Plex RAID Group rg0, 3 disks (block checksum, raid_dp) Usable Physical Position Disk Type Size Size ---------- ------------------------- ---------- -------- -------- dparity 4.20.0 SAS - - parity 4.20.3 SAS - - data 4.20.1 SAS 546.9GB 558.9GB Aggregate capacity available forvolume use would be 467.6GB. Do you want to continue? {y|n}: y cluster_A::> -
Vérifier que les agrégats racine sont mis en miroir :
storage aggregate showcluster_A::> aggr show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ aggr0_node_A_1-old 349.0GB 16.84GB 95% online 1 node_A_1-old raid_dp, mirrored, normal aggr0_node_A_2-old 349.0GB 16.84GB 95% online 1 node_A_2-old raid_dp, mirrored, normal aggr0_node_A_1-new 467.6GB 22.63GB 95% online 1 node_A_1-new raid_dp, mirrored, normal aggr0_node_A_2-new 467.6GB 22.62GB 95% online 1 node_A_2-new raid_dp, mirrored, normal aggr_data_a1 1.02TB 1.01TB 1% online 1 node_A_1-old raid_dp, mirrored, normal aggr_data_a2 1.02TB 1.01TB 1% online 1 node_A_2-old raid_dp, mirrored,
Finaliser l'ajout des nouveaux nœuds
Vous devez intégrer le nouveau groupe de reprise après incident à la configuration MetroCluster et créer des agrégats de données en miroir sur les nouveaux nœuds.
-
Actualisez la configuration MetroCluster :
-
Entrer en mode de privilège avancé :
set -privilege advanced -
Actualisez la configuration de MetroCluster sur l’un des nœuds nouvellement ajoutés :
Si votre configuration MetroCluster possède…
Alors, procédez comme ça…
Plusieurs agrégats de données
À partir de l'invite de n'importe quel nœud, exécutez :
metrocluster configure <node-name>Un seul agrégat de données en miroir sur un ou les deux sites
Depuis l'invite d'un nœud, configurez le MetroCluster avec le
-allow-with-one-aggregate trueparamètre :metrocluster configure -allow-with-one-aggregate true <node-name> -
Rebooter chacun des nouveaux nœuds :
node reboot -node <node_name> -inhibit-takeover true
Vous n'avez pas besoin de redémarrer les nœuds dans un ordre spécifique, mais vous devez attendre qu'un nœud soit entièrement démarré et que toutes les connexions soient établies avant de redémarrer le nœud suivant. -
Revenir en mode de privilège admin :
set -privilege admin
-
-
Créez des agrégats de données en miroir sur chacun des nouveaux nœuds MetroCluster :
storage aggregate create -aggregate <aggregate-name> -node <node-name> -diskcount <no-of-disks> -mirror true
-
Vous devez créer au moins un agrégat de données en miroir par site. Il est recommandé d'avoir deux agrégats de données en miroir par site sur des nœuds IP MetroCluster pour héberger les volumes MDV. Cependant, un seul agrégat par site est pris en charge (mais non recommandé). Il est acceptable qu'un site du MetroCluster dispose d'un seul agrégat de données en miroir et que l'autre site possède plusieurs agrégats en miroir.
-
Les noms des agrégats doivent être uniques sur l'ensemble des MetroCluster sites. Cela signifie que vous ne pouvez pas avoir deux agrégats différents portant le même nom sur le site A et le site B.
L'exemple suivant montre la création d'un agrégat du node_A_1-New.
cluster_A::> storage aggregate create -aggregate data_a3 -node node_A_1-new -diskcount 10 -mirror t Info: The layout for aggregate "data_a3" on node "node_A_1-new" would be: First Plex RAID Group rg0, 5 disks (block checksum, raid_dp) Usable Physical Position Disk Type Size Size ---------- ------------------------- ---------- -------- -------- dparity 5.10.15 SAS - - parity 5.10.16 SAS - - data 5.10.17 SAS 546.9GB 547.1GB data 5.10.18 SAS 546.9GB 558.9GB data 5.10.19 SAS 546.9GB 558.9GB Second Plex RAID Group rg0, 5 disks (block checksum, raid_dp) Usable Physical Position Disk Type Size Size ---------- ------------------------- ---------- -------- -------- dparity 4.20.17 SAS - - parity 4.20.14 SAS - - data 4.20.18 SAS 546.9GB 547.1GB data 4.20.19 SAS 546.9GB 547.1GB data 4.20.16 SAS 546.9GB 547.1GB Aggregate capacity available for volume use would be 1.37TB. Do you want to continue? {y|n}: y [Job 440] Job succeeded: DONE cluster_A::> -
-
Vérifiez que les nœuds sont ajoutés à leur groupe de reprise après incident.
cluster_A::*> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- ------------------ -------------- --------- -------------------- 1 cluster_A node_A_1-old configured enabled normal node_A_2-old configured enabled normal cluster_B node_B_1-old configured enabled normal node_B_2-old configured enabled normal 2 cluster_A node_A_3-new configured enabled normal node_A_4-new configured enabled normal cluster_B node_B_3-new configured enabled normal node_B_4-new configured enabled normal 8 entries were displayed. cluster_A::*> -
Déplacez les volumes MDV_CRS en mode privilèges avancés.
-
Afficher les volumes pour identifier les volumes MDV :
Si vous disposez d'un seul agrégat de données en miroir par site, déplacez les deux volumes MDV vers cet agrégat unique. Si vous disposez de deux agrégats de données en miroir ou plus, déplacez chaque volume MDV vers un agrégat différent.
Si vous étendez une configuration MetroCluster à quatre nœuds à une configuration permanente à huit nœuds, vous devez déplacer l'un des volumes MDV vers le nouveau groupe DR.
L'exemple suivant montre les volumes MDV dans
volume showrésultat :cluster_A::> volume show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- ... cluster_A MDV_CRS_2c78e009ff5611e9b0f300a0985ef8c4_A aggr_b1 - RW - - - cluster_A MDV_CRS_2c78e009ff5611e9b0f300a0985ef8c4_B aggr_b2 - RW - - - cluster_A MDV_CRS_d6b0b313ff5611e9837100a098544e51_A aggr_a1 online RW 10GB 9.50GB 0% cluster_A MDV_CRS_d6b0b313ff5611e9837100a098544e51_B aggr_a2 online RW 10GB 9.50GB 0% ... 11 entries were displayed.mple -
Définissez le niveau de privilège avancé :
set -privilege advanced -
Déplacer les volumes MDV, un par un :
volume move start -volume <mdv-volume> -destination-aggregate <aggr-on-new-node> -vserver <svm-name>L'exemple suivant montre la commande et la sortie pour le déplacement de "MDV_CRS_d6b0b313ff5611e9837100a098544e51_A" vers "Data_a3" sur "node_A_3".
cluster_A::*> vol move start -volume MDV_CRS_d6b0b313ff5611e9837100a098544e51_A -destination-aggregate data_a3 -vserver cluster_A Warning: You are about to modify the system volume "MDV_CRS_d6b0b313ff5611e9837100a098544e51_A". This might cause severe performance or stability problems. Do not proceed unless directed to do so by support. Do you want to proceed? {y|n}: y [Job 494] Job is queued: Move "MDV_CRS_d6b0b313ff5611e9837100a098544e51_A" in Vserver "cluster_A" to aggregate "data_a3". Use the "volume move show -vserver cluster_A -volume MDV_CRS_d6b0b313ff5611e9837100a098544e51_A" command to view the status of this operation. -
Utilisez la commande volume show pour vérifier que le volume MDV a bien été déplacé :
volume show <mdv-name>Le résultat suivant indique que le volume MDV a été déplacé avec succès.
cluster_A::*> vol show MDV_CRS_d6b0b313ff5611e9837100a098544e51_B Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- cluster_A MDV_CRS_d6b0b313ff5611e9837100a098544e51_B aggr_a2 online RW 10GB 9.50GB 0% -
-
Déplacement d'epsilon d'un ancien nœud vers un nouveau nœud :
-
Identifier le nœud qui possède actuellement epsilon :
cluster show -fields epsiloncluster_B::*> cluster show -fields epsilon node epsilon ---------------- ------- node_A_1-old true node_A_2-old false node_A_3-new false node_A_4-new false 4 entries were displayed.
-
Définir epsilon sur false sur l'ancien nœud (node_A_1-Old) :
cluster modify -node <old-node> -epsilon false* -
Défini sur true sur le nouveau nœud (node_A_3-New) :
cluster modify -node <new-node> -epsilon true -
Vérifier que epsilon a déplacé vers le nœud approprié :
cluster show -fields epsilon
cluster_A::*> cluster show -fields epsilon node epsilon ---------------- ------- node_A_1-old false node_A_2-old false node_A_3-new true node_A_4-new false 4 entries were displayed.
-
-
Si votre système prend en charge le chiffrement de bout en bout, vous pouvez le faire "Chiffrez vos données de bout en bout" Sur le nouveau groupe DR.