

Configurer les clusters ONTAP dans une configuration IP MetroCluster
 Suggérer des modifications
Suggérer des modifications
Vous devez peer-to-peer les clusters, mettre en miroir les agrégats racine, créer un agrégat de données en miroir, puis lancer la commande pour mettre en œuvre les opérations MetroCluster.
Avant de courir metrocluster configure, Le mode HA et la mise en miroir DR ne sont pas activés et un message d'erreur peut s'afficher concernant ce comportement attendu. Vous activez le mode HA et la mise en miroir de reprise après incident plus tard lors de l'exécution de la commande metrocluster configure pour implémenter la configuration.
Désactivation de l'affectation automatique des lecteurs (en cas d'affectation manuelle dans ONTAP 9.4)
Dans ONTAP 9.4, si votre configuration MetroCluster IP comporte moins de quatre tiroirs de stockage externes par site, vous devez désactiver l'affectation automatique des disques sur tous les nœuds et attribuer manuellement des disques.
Cette tâche n'est pas requise dans ONTAP 9.5 et versions ultérieures.
Cette tâche ne s'applique pas à un système AFF A800 équipé d'un tiroir interne et sans tiroirs externes.
-
Désactiver l'affectation automatique des disques :
storage disk option modify -node <node_name> -autoassign off -
Vous devez lancer cette commande sur tous les nœuds de la configuration IP MetroCluster.
Vérification de l'affectation des disques du pool 0
Vous devez vérifier que les lecteurs distants sont visibles par les nœuds et ont été correctement affectés.
L'assignation automatique dépend du modèle de plateforme de stockage et de l'organisation des tiroirs disques.
-
Vérifiez que les disques du pool 0 sont affectés automatiquement :
disk showL'exemple suivant montre la sortie « cluster_A » pour un système AFF A800 sans tiroir externe.
Un quart (8 disques) ont été automatiquement affectés à « node_A_1 » et un trimestre a été automatiquement affecté à « node_A_2 ». Les disques restants seront des disques distants (pool 1) pour « node_B_1 » et « node_B_2 ».
cluster_A::*> disk show Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_1:0n.12 1.75TB 0 12 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.13 1.75TB 0 13 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.14 1.75TB 0 14 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.15 1.75TB 0 15 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.16 1.75TB 0 16 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.17 1.75TB 0 17 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.18 1.75TB 0 18 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.19 1.75TB 0 19 SSD-NVM shared - node_A_1 node_A_2:0n.0 1.75TB 0 0 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.1 1.75TB 0 1 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.2 1.75TB 0 2 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.3 1.75TB 0 3 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.4 1.75TB 0 4 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.5 1.75TB 0 5 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.6 1.75TB 0 6 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.7 1.75TB 0 7 SSD-NVM shared - node_A_2 node_A_2:0n.24 - 0 24 SSD-NVM unassigned - - node_A_2:0n.25 - 0 25 SSD-NVM unassigned - - node_A_2:0n.26 - 0 26 SSD-NVM unassigned - - node_A_2:0n.27 - 0 27 SSD-NVM unassigned - - node_A_2:0n.28 - 0 28 SSD-NVM unassigned - - node_A_2:0n.29 - 0 29 SSD-NVM unassigned - - node_A_2:0n.30 - 0 30 SSD-NVM unassigned - - node_A_2:0n.31 - 0 31 SSD-NVM unassigned - - node_A_2:0n.36 - 0 36 SSD-NVM unassigned - - node_A_2:0n.37 - 0 37 SSD-NVM unassigned - - node_A_2:0n.38 - 0 38 SSD-NVM unassigned - - node_A_2:0n.39 - 0 39 SSD-NVM unassigned - - node_A_2:0n.40 - 0 40 SSD-NVM unassigned - - node_A_2:0n.41 - 0 41 SSD-NVM unassigned - - node_A_2:0n.42 - 0 42 SSD-NVM unassigned - - node_A_2:0n.43 - 0 43 SSD-NVM unassigned - - 32 entries were displayed.L'exemple suivant montre la sortie « cluster_B » :
cluster_B::> disk show Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- Info: This cluster has partitioned disks. To get a complete list of spare disk capacity use "storage aggregate show-spare-disks". node_B_1:0n.12 1.75TB 0 12 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.13 1.75TB 0 13 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.14 1.75TB 0 14 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.15 1.75TB 0 15 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.16 1.75TB 0 16 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.17 1.75TB 0 17 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.18 1.75TB 0 18 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.19 1.75TB 0 19 SSD-NVM shared - node_B_1 node_B_2:0n.0 1.75TB 0 0 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.1 1.75TB 0 1 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.2 1.75TB 0 2 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.3 1.75TB 0 3 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.4 1.75TB 0 4 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.5 1.75TB 0 5 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.6 1.75TB 0 6 SSD-NVM shared aggr0_node_B_1_0 node_B_2 node_B_2:0n.7 1.75TB 0 7 SSD-NVM shared - node_B_2 node_B_2:0n.24 - 0 24 SSD-NVM unassigned - - node_B_2:0n.25 - 0 25 SSD-NVM unassigned - - node_B_2:0n.26 - 0 26 SSD-NVM unassigned - - node_B_2:0n.27 - 0 27 SSD-NVM unassigned - - node_B_2:0n.28 - 0 28 SSD-NVM unassigned - - node_B_2:0n.29 - 0 29 SSD-NVM unassigned - - node_B_2:0n.30 - 0 30 SSD-NVM unassigned - - node_B_2:0n.31 - 0 31 SSD-NVM unassigned - - node_B_2:0n.36 - 0 36 SSD-NVM unassigned - - node_B_2:0n.37 - 0 37 SSD-NVM unassigned - - node_B_2:0n.38 - 0 38 SSD-NVM unassigned - - node_B_2:0n.39 - 0 39 SSD-NVM unassigned - - node_B_2:0n.40 - 0 40 SSD-NVM unassigned - - node_B_2:0n.41 - 0 41 SSD-NVM unassigned - - node_B_2:0n.42 - 0 42 SSD-NVM unassigned - - node_B_2:0n.43 - 0 43 SSD-NVM unassigned - - 32 entries were displayed. cluster_B::>
Peering des clusters
Les clusters de la configuration MetroCluster doivent être dans une relation de pairs, de sorte qu'ils puissent communiquer entre eux et exécuter la mise en miroir des données essentielle à la reprise sur incident de MetroCluster.
Configuration des LIFs intercluster pour le peering de cluster
Vous devez créer des LIFs intercluster sur les ports utilisés pour la communication entre les clusters partenaires MetroCluster. Vous pouvez utiliser des ports ou ports dédiés qui ont également le trafic de données.
Configuration des LIFs intercluster sur des ports dédiés
Vous pouvez configurer les LIFs intercluster sur des ports dédiés. Cela augmente généralement la bande passante disponible pour le trafic de réplication.
-
Lister les ports dans le cluster :
network port showPour connaître la syntaxe complète de la commande, reportez-vous à la page man.
L'exemple suivant montre les ports réseau en « cluster01 » :
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
Déterminer les ports disponibles pour dédier aux communications intercluster :
network interface show -fields home-port,curr-portPour connaître la syntaxe complète de la commande, reportez-vous à la page man.
L'exemple suivant montre que les ports « e0e » et « e0f » n'ont pas été affectés aux LIF :
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
Créer un failover group pour les ports dédiés :
network interface failover-groups create -vserver <system_svm> -failover-group <failover_group> -targets <physical_or_logical_ports>L'exemple suivant attribue les ports « e0e » et « e0f » au groupe de basculement « intercluster 01 » sur le système « SVM cluster01 » :
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
Vérifier que le groupe de basculement a été créé :
network interface failover-groups showPour connaître la syntaxe complète de la commande, reportez-vous à la page man.
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
Créer les LIF intercluster sur le SVM système et les assigner au failover group.
Dans ONTAP 9.6 et versions ultérieures, exécutez :network interface create -vserver <system_svm> -lif <lif_name> -service-policy default-intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask_address> -failover-group <failover_group>Dans ONTAP 9.5 et les versions antérieures, exécutez :network interface create -vserver <system_svm> -lif <lif_name> -role intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask_address> -failover-group <failover_group>Pour connaître la syntaxe complète de la commande, reportez-vous à la page man.
L'exemple suivant illustre la création des LIFs intercluster « cluster01_icl01 » et « cluster01_icl02 » dans le groupe de basculement « intercluster01 » :
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
Vérifier que les LIFs intercluster ont été créés :
Dans ONTAP 9.6 et versions ultérieures, exécutez :network interface show -service-policy default-interclusterDans ONTAP 9.5 et les versions antérieures, exécutez :network interface show -role interclusterPour connaître la syntaxe complète de la commande, reportez-vous à la page man.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
Vérifier que les LIFs intercluster sont redondants :
Dans ONTAP 9.6 et versions ultérieures, exécutez :network interface show -service-policy default-intercluster -failoverDans ONTAP 9.5 et les versions antérieures, exécutez :network interface show -role intercluster -failoverPour connaître la syntaxe complète de la commande, reportez-vous à la page man.
L'exemple suivant montre que les LIFs intercluster « cluster01_icl01 » et « cluster01_icl02 » sur le port « SVMe0e » basculeront vers le port « e0f ».
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
Configuration des LIFs intercluster sur des ports data partagés
Vous pouvez configurer les LIFs intercluster sur des ports partagés avec le réseau de données. Cela réduit le nombre de ports nécessaires pour la mise en réseau intercluster.
-
Lister les ports dans le cluster :
network port showPour connaître la syntaxe complète de la commande, reportez-vous à la page man.
L'exemple suivant montre les ports réseau en « cluster01 » :
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
Création des LIFs intercluster sur le SVM système :
Dans ONTAP 9.6 et versions ultérieures, exécutez :network interface create -vserver <system_svm> -lif <lif_name> -service-policy default-intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask>Dans ONTAP 9.5 et les versions antérieures, exécutez :network interface create -vserver <system_svm> -lif <lif_name> -role intercluster -home-node <node_name> -home-port <port_name> -address <port_ip_address> -netmask <netmask>Pour connaître la syntaxe complète de la commande, reportez-vous à la page man.
L'exemple suivant illustre la création des LIFs intercluster « cluster01_icl01 » et « cluster01_icl02 » :
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
Vérifier que les LIFs intercluster ont été créés :
Dans ONTAP 9.6 et versions ultérieures, exécutez :network interface show -service-policy default-interclusterDans ONTAP 9.5 et les versions antérieures, exécutez :network interface show -role interclusterPour connaître la syntaxe complète de la commande, reportez-vous à la page man.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
Vérifier que les LIFs intercluster sont redondants :
Dans ONTAP 9.6 et versions ultérieures, exécutez :network interface show –service-policy default-intercluster -failoverDans ONTAP 9.5 et les versions antérieures, exécutez :network interface show -role intercluster -failoverPour connaître la syntaxe complète de la commande, reportez-vous à la page man.
L'exemple suivant montre que les LIFs intercluster « cluster01_icl01 » et « cluster01_icl02 » sur le port « e0c » basculeront vers le port « e0d ».
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
"Points à prendre en compte lors du partage de ports de données"
Création d'une relation entre clusters
Vous pouvez utiliser la commande cluster peer create pour créer une relation homologue entre un cluster local et un cluster distant. Une fois la relation homologue créée, vous pouvez exécuter cluster peer create sur le cluster distant afin de l'authentifier auprès du cluster local.
-
Vous devez avoir créé des LIF intercluster sur chaque nœud des clusters qui sont en cours de peering.
-
Les clusters doivent exécuter ONTAP 9.3 ou version ultérieure.
-
Sur le cluster destination, créez une relation entre pairs et le cluster source :
cluster peer create -generate-passphrase -offer-expiration <MM/DD/YYYY HH:MM:SS|1…7days|1…168hours> -peer-addrs <peer_lif_ip_addresses> -ipspace <ipspace>Si vous spécifiez les deux
-generate-passphraseet-peer-addrs, Uniquement le cluster dont les LIFs intercluster sont spécifiés dans-peer-addrspeut utiliser le mot de passe généré.Vous pouvez ignorer
-ipspaceOption si vous n'utilisez pas un IPspace personnalisé. Pour connaître la syntaxe complète de la commande, reportez-vous à la page man.L'exemple suivant crée une relation de cluster peer-to-peer sur un cluster distant non spécifié :
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
Sur le cluster source, authentifier le cluster source sur le cluster destination :
cluster peer create -peer-addrs <peer_lif_ip_addresses> -ipspace <ipspace>Pour connaître la syntaxe complète de la commande, reportez-vous à la page man.
L'exemple suivant authentifie le cluster local sur le cluster distant aux adresses IP « 192.140.112.101 » et « 192.140.112.102 » de LIF intercluster :
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.Entrez la phrase de passe de la relation homologue lorsque vous y êtes invité.
-
Vérifiez que la relation entre clusters a été créée :
cluster peer show -instancecluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Cluster UUID: b07036f2-7d1c-11f0-bedb-d039ea48b059 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster02 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Remote Cluster Nodes: cluster02-01, cluster02-02, Remote Cluster Health: true Unreachable Local Nodes: - Operation Timeout (seconds): 60 Address Family of Relationship: ipv4 Authentication Status Administrative: use-authentication Authentication Status Operational: ok Timeout for RPC Connect: 10 Timeout for Update Pings: 5 Last Update Time: 10/9/2025 10:15:29 IPspace for the Relationship: Default Proposed Setting for Encryption of Inter-Cluster Communication: - Encryption Protocol For Inter-Cluster Communication: tls-psk Algorithm By Which the PSK Was Derived: jpake -
Vérifier la connectivité et l'état des nœuds de la relation peer-to-peer :
cluster peer health showcluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
Création du groupe DR
Vous devez créer les relations de groupe de reprise après incident entre les clusters.
Cette procédure est effectuée sur l'un des clusters de la configuration MetroCluster afin de créer les relations de DR entre les nœuds des deux clusters.

|
Les relations de DR ne peuvent pas être modifiées une fois les groupes de DR créés. |
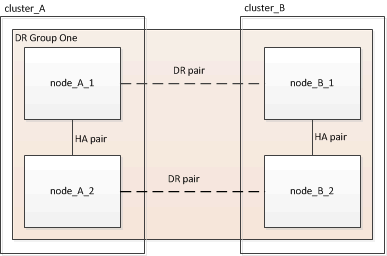
-
Vérifiez que les nœuds sont prêts à créer le groupe de reprise sur incident en entrant la commande suivante sur chaque nœud :
metrocluster configuration-settings show-statusLe résultat de la commande doit afficher que les nœuds sont prêts :
cluster_A::> metrocluster configuration-settings show-status Cluster Node Configuration Settings Status -------------------------- ------------- -------------------------------- cluster_A node_A_1 ready for DR group create node_A_2 ready for DR group create 2 entries were displayed.cluster_B::> metrocluster configuration-settings show-status Cluster Node Configuration Settings Status -------------------------- ------------- -------------------------------- cluster_B node_B_1 ready for DR group create node_B_2 ready for DR group create 2 entries were displayed. -
Créez le groupe DR :
metrocluster configuration-settings dr-group create -partner-cluster <partner_cluster_name> -local-node <local_node_name> -remote-node <remote_node_name>Cette commande n'est émise qu'une seule fois. Il n'est pas nécessaire de le répéter sur le cluster partenaire. Dans la commande, vous spécifiez le nom du cluster distant, ainsi que le nom d'un nœud local et d'un nœud sur le cluster partenaire.
Les deux nœuds que vous spécifiez sont configurés en tant que partenaires DR et les deux autres nœuds (qui ne sont pas spécifiés dans la commande) sont configurés en tant que seconde paire DR dans le groupe DR. Ces relations ne peuvent pas être modifiées une fois que vous avez saisi cette commande.
La commande suivante crée ces paires de reprise sur incident :
-
Node_A_1 et node_B_1
-
Node_A_2 et node_B_2
Cluster_A::> metrocluster configuration-settings dr-group create -partner-cluster cluster_B -local-node node_A_1 -remote-node node_B_1 [Job 27] Job succeeded: DR Group Create is successful.
-
Configuration et connexion des interfaces IP MetroCluster
Vous devez configurer les interfaces IP MetroCluster utilisées pour la réplication du stockage de chaque nœud et du cache non volatile. Vous déterminez ensuite les connexions en utilisant les interfaces IP de MetroCluster. Cela crée des connexions iSCSI pour la réplication du stockage.
|
|
L'adresse IP MetroCluster et les ports de commutateur connectés ne sont pas mis en ligne avant la création des interfaces IP MetroCluster. |
-
Vous devez créer deux interfaces pour chaque nœud. Les interfaces doivent être associées aux VLAN définis dans le fichier RCF MetroCluster.
-
Vous devez créer tous les ports de l'interface IP MetroCluster « A » sur le même VLAN et tous les ports de l'interface IP MetroCluster « B » dans l'autre VLAN. Reportez-vous à la section "Considérations relatives à la configuration MetroCluster IP".
-
À partir de ONTAP 9.9.1, si vous utilisez une configuration de couche 3, vous devez également spécifier le
-gatewayParamètre lors de la création des interfaces IP MetroCluster. Reportez-vous à la section "Considérations relatives aux réseaux étendus de couche 3".Certaines plates-formes utilisent un VLAN pour l'interface IP de MetroCluster. Par défaut, chacun des deux ports utilise un VLAN différent : 10 et 20.
Si elle est prise en charge, vous pouvez également spécifier un VLAN différent (non par défaut) supérieur à 100 (entre 101 et 4095) en utilisant le
-vlan-idparamètre de lametrocluster configuration-settings interface createcommande.Les plates-formes suivantes ne prennent pas en charge le
-vlan-idparamètre :-
FAS8200 ET AFF A300
-
AFF A320
-
FAS9000 et AFF A700
-
AFF C800, ASA C800, AFF A800 et ASA A800
Toutes les autres plates-formes prennent en charge le
-vlan-idparamètre.Les affectations de VLAN par défaut et valides dépendent du fait que la plate-forme prend en charge le
-vlan-idparamètre :
Les plateformes qui prennent en charge <code>-vlan-</code>VLAN par défaut :
-
Lorsque le
-vlan-idparamètre n'est pas spécifié, les interfaces sont créées avec le VLAN 10 pour les ports "A" et le VLAN 20 pour les ports "B". -
Le VLAN spécifié doit correspondre au VLAN sélectionné dans la FCR.
Plages VLAN valides :
-
VLAN 10 et 20 par défaut
-
VLAN 101 et supérieur (entre 101 et 4095)
Les plateformes qui ne prennent pas en charge <code>-vlan-</code>VLAN par défaut :
-
Sans objet L'interface ne nécessite pas la spécification d'un VLAN sur l'interface MetroCluster. Le port du commutateur définit le VLAN utilisé.
Plages VLAN valides :
-
Tous les VLAN non explicitement exclus lors de la génération de la FCR. Le RCF vous avertit si le VLAN n'est pas valide.
-
-
Les ports physiques utilisés par les interfaces IP MetroCluster dépendent du modèle de plateforme. Reportez-vous "Branchez les câbles des commutateurs IP MetroCluster" à pour connaître l'utilisation des ports pour votre système.
-
Les adresses IP et sous-réseaux suivants sont utilisés dans les exemples :
Nœud
Interface
Adresse IP
Sous-réseau
Nœud_A_1
Interface IP MetroCluster 1
10.1.1.1
10.1.1/24
Interface IP MetroCluster 2
10.1.2.1
10.1.2/24
Nœud_A_2
Interface IP MetroCluster 1
10.1.1.2
10.1.1/24
Interface IP MetroCluster 2
10.1.2.2
10.1.2/24
Nœud_B_1
Interface IP MetroCluster 1
10.1.1.3
10.1.1/24
Interface IP MetroCluster 2
10.1.2.3
10.1.2/24
Nœud_B_2
Interface IP MetroCluster 1
10.1.1.4
10.1.1/24
Interface IP MetroCluster 2
10.1.2.4
10.1.2/24
-
Cette procédure utilise les exemples suivants :
Ports pour un système AFF A700 ou FAS9000 (e5a et e5b).
Ports d'un système AFF A220 pour montrer comment utiliser le
-vlan-idparamètre sur une plateforme prise en charge.Configurez les interfaces sur les ports appropriés pour votre modèle de plate-forme.
-
Vérifiez que l'affectation automatique des disques est activée pour chaque nœud :
storage disk option showL'assignation automatique des disques attribue 0 pool et 1 pool disques par tiroir.
La colonne affectation automatique indique si l'affectation automatique des disques est activée.
Node BKg. FW. Upd. Auto Copy Auto Assign Auto Assign Policy ---------- ------------- ---------- ----------- ------------------ node_A_1 on on on default node_A_2 on on on default 2 entries were displayed.
-
Vérifiez que vous pouvez créer les interfaces IP MetroCluster sur les nœuds :
metrocluster configuration-settings show-statusTous les nœuds doivent être prêts :
Cluster Node Configuration Settings Status ---------- ----------- --------------------------------- cluster_A node_A_1 ready for interface create node_A_2 ready for interface create cluster_B node_B_1 ready for interface create node_B_2 ready for interface create 4 entries were displayed. -
Créer les interfaces sur node_A_1.
-
Configurer l'interface sur le port "e5a" sur "node_A_1" :

N'utilisez pas d'adresses IP 169.254.17.x ou 169.254.18.x lorsque vous créez des interfaces IP MetroCluster pour éviter les conflits avec les adresses IP d'interface générées automatiquement par le système dans la même plage. metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5a -address <ip_address> -netmask <netmask>L'exemple suivant montre la création de l'interface sur le port "e5a" sur "node_A_1" avec l'adresse IP "10.1.1.1":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_1 -home-port e5a -address 10.1.1.1 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
Sur les modèles de plateforme prenant en charge les VLAN pour l'interface IP MetroCluster, vous pouvez inclure le
-vlan-idParamètre si vous ne souhaitez pas utiliser les ID de VLAN par défaut. L'exemple suivant montre la commande pour un système AFF A220 avec un ID VLAN de 120 :cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2 -home-port e0a -address 10.1.1.2 -netmask 255.255.255.0 -vlan-id 120 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
-
Configurer l'interface sur le port "e5b" sur "node_A_1" :
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5b -address <ip_address> -netmask <netmask>L'exemple suivant montre la création de l'interface sur le port "e5b" sur "node_A_1" avec l'adresse IP "10.1.2.1":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_1 -home-port e5b -address 10.1.2.1 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
Vous pouvez vérifier que ces interfaces sont présentes à l'aide du metrocluster configuration-settings interface showcommande. -
-
Créer les interfaces sur node_A_2.
-
Configurer l'interface sur le port « e5a » sur « node_A_2 » :
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5a -address <ip_address> -netmask <netmask>L'exemple suivant montre la création de l'interface sur le port "e5a" sur "node_A_2" avec l'adresse IP "10.1.1.2":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2 -home-port e5a -address 10.1.1.2 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
-
Configurer l'interface sur le port « e5b » sur « node_A_2 » :
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5b -address <ip_address> -netmask <netmask>L'exemple suivant montre la création de l'interface sur le port "e5b" sur "node_A_2" avec l'adresse IP "10.1.2.2":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2 -home-port e5b -address 10.1.2.2 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
Sur les modèles de plateforme prenant en charge les VLAN pour l'interface IP MetroCluster, vous pouvez inclure le
-vlan-idParamètre si vous ne souhaitez pas utiliser les ID de VLAN par défaut. L'exemple suivant montre la commande pour un système AFF A220 avec un ID VLAN de 220 :
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_A -home-node node_A_2 -home-port e0b -address 10.1.2.2 -netmask 255.255.255.0 -vlan-id 220 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
-
-
Créer les interfaces sur « node_B_1 ».
-
Configurer l'interface sur le port « e5a » sur « node_B_1 » :
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5a -address <ip_address> -netmask <netmask>L'exemple suivant montre la création de l'interface sur le port "e5a" sur "node_B_1" avec l'adresse IP "10.1.1.3":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_1 -home-port e5a -address 10.1.1.3 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful.cluster_B::>
-
Configurer l'interface sur le port « e5b » sur « node_B_1 » :
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5b -address <ip_address> -netmask <netmask>L'exemple suivant montre la création de l'interface sur le port "e5b" sur "node_B_1" avec l'adresse IP "10.1.2.3":
cluster_A::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_1 -home-port e5b -address 10.1.2.3 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful.cluster_B::>
-
-
Créer les interfaces sur « node_B_2 ».
-
Configurez l'interface sur le port e5a du nœud_B_2 :
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5a -address <ip_address> -netmask <netmask>L'exemple suivant montre la création de l'interface sur le port "e5a" sur "node_B_2" avec l'adresse IP "10.1.1.4":
cluster_B::>metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_2 -home-port e5a -address 10.1.1.4 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful.cluster_A::>
-
Configurer l'interface sur le port « e5b » sur « node_B_2 » :
metrocluster configuration-settings interface create -cluster-name <cluster_name> -home-node <node_name> -home-port e5b -address <ip_address> -netmask <netmask>L'exemple suivant montre la création de l'interface sur le port "e5b" sur "node_B_2" avec l'adresse IP "10.1.2.4":
cluster_B::> metrocluster configuration-settings interface create -cluster-name cluster_B -home-node node_B_2 -home-port e5b -address 10.1.2.4 -netmask 255.255.255.0 [Job 28] Job succeeded: Interface Create is successful. cluster_A::>
-
-
Vérifiez que les interfaces ont été configurées :
metrocluster configuration-settings interface showL'exemple suivant montre que l'état de configuration de chaque interface est terminé.
cluster_A::> metrocluster configuration-settings interface show DR Config Group Cluster Node Network Address Netmask Gateway State ----- ------- ------- --------------- --------------- --------- ---------- 1 cluster_A node_A_1 Home Port: e5a 10.1.1.1 255.255.255.0 - completed Home Port: e5b 10.1.2.1 255.255.255.0 - completed node_A_2 Home Port: e5a 10.1.1.2 255.255.255.0 - completed Home Port: e5b 10.1.2.2 255.255.255.0 - completed cluster_B node_B_1 Home Port: e5a 10.1.1.3 255.255.255.0 - completed Home Port: e5b 10.1.2.3 255.255.255.0 - completed node_B_2 Home Port: e5a 10.1.1.4 255.255.255.0 - completed Home Port: e5b 10.1.2.4 255.255.255.0 - completed 8 entries were displayed. cluster_A::> -
Vérifiez que les nœuds sont prêts à connecter les interfaces MetroCluster :
metrocluster configuration-settings show-statusL'exemple suivant montre tous les nœuds avec l'état « prêt pour la connexion » :
Cluster Node Configuration Settings Status ---------- ----------- --------------------------------- cluster_A node_A_1 ready for connection connect node_A_2 ready for connection connect cluster_B node_B_1 ready for connection connect node_B_2 ready for connection connect 4 entries were displayed. -
Établir les connexions :
metrocluster configuration-settings connection connectSi vous exécutez une version antérieure à ONTAP 9.10.1, les adresses IP ne peuvent pas être modifiées après l'exécution de cette commande.
L'exemple suivant montre que cluster_A est connecté avec succès :
cluster_A::> metrocluster configuration-settings connection connect [Job 53] Job succeeded: Connect is successful. cluster_A::>
-
Vérifier que les connexions ont été établies :
metrocluster configuration-settings show-statusL'état des paramètres de configuration de tous les nœuds doit être terminé :
Cluster Node Configuration Settings Status ---------- ----------- --------------------------------- cluster_A node_A_1 completed node_A_2 completed cluster_B node_B_1 completed node_B_2 completed 4 entries were displayed. -
Vérifiez que les connexions iSCSI ont été établies :
-
Changement au niveau de privilège avancé :
set -privilege advancedVous devez répondre avec
ylorsque vous êtes invité à passer en mode avancé, l'invite du mode avancé s'affiche (*>). -
Afficher les connexions :
storage iscsi-initiator showSur les systèmes exécutant ONTAP 9.5, il existe huit initiateurs IP MetroCluster sur chaque cluster qui doivent apparaître dans la sortie.
Sur les systèmes exécutant ONTAP 9.4 et versions antérieures, chaque cluster doit avoir quatre initiateurs IP MetroCluster qui doivent s'afficher dans la sortie.
L'exemple suivant montre les huit initiateurs IP MetroCluster sur un cluster exécutant ONTAP 9.5 :
cluster_A::*> storage iscsi-initiator show Node Type Label Target Portal Target Name Admin/Op ---- ---- -------- ------------------ -------------------------------- -------- cluster_A-01 dr_auxiliary mccip-aux-a-initiator 10.227.16.113:65200 prod506.com.company:abab44 up/up mccip-aux-a-initiator2 10.227.16.113:65200 prod507.com.company:abab44 up/up mccip-aux-b-initiator 10.227.95.166:65200 prod506.com.company:abab44 up/up mccip-aux-b-initiator2 10.227.95.166:65200 prod507.com.company:abab44 up/up dr_partner mccip-pri-a-initiator 10.227.16.112:65200 prod506.com.company:cdcd88 up/up mccip-pri-a-initiator2 10.227.16.112:65200 prod507.com.company:cdcd88 up/up mccip-pri-b-initiator 10.227.95.165:65200 prod506.com.company:cdcd88 up/up mccip-pri-b-initiator2 10.227.95.165:65200 prod507.com.company:cdcd88 up/up cluster_A-02 dr_auxiliary mccip-aux-a-initiator 10.227.16.112:65200 prod506.com.company:cdcd88 up/up mccip-aux-a-initiator2 10.227.16.112:65200 prod507.com.company:cdcd88 up/up mccip-aux-b-initiator 10.227.95.165:65200 prod506.com.company:cdcd88 up/up mccip-aux-b-initiator2 10.227.95.165:65200 prod507.com.company:cdcd88 up/up dr_partner mccip-pri-a-initiator 10.227.16.113:65200 prod506.com.company:abab44 up/up mccip-pri-a-initiator2 10.227.16.113:65200 prod507.com.company:abab44 up/up mccip-pri-b-initiator 10.227.95.166:65200 prod506.com.company:abab44 up/up mccip-pri-b-initiator2 10.227.95.166:65200 prod507.com.company:abab44 up/up 16 entries were displayed.-
Retour au niveau de privilège admin :
set -privilege admin
-
-
Vérifier que les nœuds sont prêts pour une implémentation finale de la configuration MetroCluster :
metrocluster node showcluster_A::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- ------------------ -------------- --------- ---- - cluster_A node_A_1 ready to configure - - node_A_2 ready to configure - - 2 entries were displayed. cluster_A::>cluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- ------------------ -------------- --------- ---- - cluster_B node_B_1 ready to configure - - node_B_2 ready to configure - - 2 entries were displayed. cluster_B::>
Vérification ou exécution manuelle de l'affectation des disques du pool 1
En fonction de la configuration du stockage, vous devez vérifier l'affectation des lecteurs du pool 1 ou attribuer manuellement les lecteurs au pool 1 pour chaque nœud de la configuration IP MetroCluster. La procédure que vous utilisez dépend de la version de ONTAP que vous utilisez.
Type de configuration |
Procédure |
Les systèmes répondent aux exigences d'affectation automatique des disques ou, s'ils exécutent ONTAP 9.3, ont été reçus en usine. |
|
La configuration inclut trois tiroirs ou, si elle contient plus de quatre tiroirs, présente un nombre irrégulier de quatre tiroirs (par exemple, sept tiroirs) et exécute ONTAP 9.5. |
|
La configuration n'inclut pas quatre tiroirs de stockage par site et exécute ONTAP 9.4 |
|
Les systèmes n'ont pas été reçus en usine et exécutent ONTAP 9.3les systèmes reçus en usine sont préconfigurés avec les disques affectés. |
Vérification de l'affectation des disques du pool 1
Vous devez vérifier que les disques distants sont visibles pour les nœuds et qu'ils ont été correctement affectés.
Vous devez patienter au moins dix minutes que l'affectation automatique du disque se termine après la création des interfaces IP MetroCluster et des connexions avec le metrocluster configuration-settings connection connect commande.
La sortie de la commande affiche les noms des disques sous la forme : nom-nœud:0m.i1.0L1
-
Vérifiez que les disques du pool 1 sont affectés automatiquement :
disk showLe résultat suivant montre les valeurs de sortie d'un système AFF A800 sans tiroir externe.
L'affectation automatique des disques a affecté un quart (8 disques) à « node_A_1 » et un quart à « node_A_2 ». Les disques restants seront des disques distants (pool 1) pour « node_B_1 » et « node_B_2 ».
cluster_B::> disk show -host-adapter 0m -owner node_B_2 Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_B_2:0m.i0.2L4 894.0GB 0 29 SSD-NVM shared - node_B_2 node_B_2:0m.i0.2L10 894.0GB 0 25 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L3 894.0GB 0 28 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L9 894.0GB 0 24 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L11 894.0GB 0 26 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L12 894.0GB 0 27 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L15 894.0GB 0 30 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L16 894.0GB 0 31 SSD-NVM shared - node_B_2 8 entries were displayed. cluster_B::> disk show -host-adapter 0m -owner node_B_1 Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_B_1:0m.i2.3L19 1.75TB 0 42 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L20 1.75TB 0 43 SSD-NVM spare Pool1 node_B_1 node_B_1:0m.i2.3L23 1.75TB 0 40 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L24 1.75TB 0 41 SSD-NVM spare Pool1 node_B_1 node_B_1:0m.i2.3L29 1.75TB 0 36 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L30 1.75TB 0 37 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L31 1.75TB 0 38 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L32 1.75TB 0 39 SSD-NVM shared - node_B_1 8 entries were displayed. cluster_B::> disk show Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_B_1:0m.i1.0L6 1.75TB 0 1 SSD-NVM shared - node_A_2 node_B_1:0m.i1.0L8 1.75TB 0 3 SSD-NVM shared - node_A_2 node_B_1:0m.i1.0L17 1.75TB 0 18 SSD-NVM shared - node_A_1 node_B_1:0m.i1.0L22 1.75TB 0 17 SSD-NVM shared - node_A_1 node_B_1:0m.i1.0L25 1.75TB 0 12 SSD-NVM shared - node_A_1 node_B_1:0m.i1.2L2 1.75TB 0 5 SSD-NVM shared - node_A_2 node_B_1:0m.i1.2L7 1.75TB 0 2 SSD-NVM shared - node_A_2 node_B_1:0m.i1.2L14 1.75TB 0 7 SSD-NVM shared - node_A_2 node_B_1:0m.i1.2L21 1.75TB 0 16 SSD-NVM shared - node_A_1 node_B_1:0m.i1.2L27 1.75TB 0 14 SSD-NVM shared - node_A_1 node_B_1:0m.i1.2L28 1.75TB 0 15 SSD-NVM shared - node_A_1 node_B_1:0m.i2.1L1 1.75TB 0 4 SSD-NVM shared - node_A_2 node_B_1:0m.i2.1L5 1.75TB 0 0 SSD-NVM shared - node_A_2 node_B_1:0m.i2.1L13 1.75TB 0 6 SSD-NVM shared - node_A_2 node_B_1:0m.i2.1L18 1.75TB 0 19 SSD-NVM shared - node_A_1 node_B_1:0m.i2.1L26 1.75TB 0 13 SSD-NVM shared - node_A_1 node_B_1:0m.i2.3L19 1.75TB 0 42 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L20 1.75TB 0 43 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L23 1.75TB 0 40 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L24 1.75TB 0 41 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L29 1.75TB 0 36 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L30 1.75TB 0 37 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L31 1.75TB 0 38 SSD-NVM shared - node_B_1 node_B_1:0m.i2.3L32 1.75TB 0 39 SSD-NVM shared - node_B_1 node_B_1:0n.12 1.75TB 0 12 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.13 1.75TB 0 13 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.14 1.75TB 0 14 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.15 1.75TB 0 15 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.16 1.75TB 0 16 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.17 1.75TB 0 17 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.18 1.75TB 0 18 SSD-NVM shared aggr0 node_B_1 node_B_1:0n.19 1.75TB 0 19 SSD-NVM shared - node_B_1 node_B_1:0n.24 894.0GB 0 24 SSD-NVM shared - node_A_2 node_B_1:0n.25 894.0GB 0 25 SSD-NVM shared - node_A_2 node_B_1:0n.26 894.0GB 0 26 SSD-NVM shared - node_A_2 node_B_1:0n.27 894.0GB 0 27 SSD-NVM shared - node_A_2 node_B_1:0n.28 894.0GB 0 28 SSD-NVM shared - node_A_2 node_B_1:0n.29 894.0GB 0 29 SSD-NVM shared - node_A_2 node_B_1:0n.30 894.0GB 0 30 SSD-NVM shared - node_A_2 node_B_1:0n.31 894.0GB 0 31 SSD-NVM shared - node_A_2 node_B_1:0n.36 1.75TB 0 36 SSD-NVM shared - node_A_1 node_B_1:0n.37 1.75TB 0 37 SSD-NVM shared - node_A_1 node_B_1:0n.38 1.75TB 0 38 SSD-NVM shared - node_A_1 node_B_1:0n.39 1.75TB 0 39 SSD-NVM shared - node_A_1 node_B_1:0n.40 1.75TB 0 40 SSD-NVM shared - node_A_1 node_B_1:0n.41 1.75TB 0 41 SSD-NVM shared - node_A_1 node_B_1:0n.42 1.75TB 0 42 SSD-NVM shared - node_A_1 node_B_1:0n.43 1.75TB 0 43 SSD-NVM shared - node_A_1 node_B_2:0m.i0.2L4 894.0GB 0 29 SSD-NVM shared - node_B_2 node_B_2:0m.i0.2L10 894.0GB 0 25 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L3 894.0GB 0 28 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L9 894.0GB 0 24 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L11 894.0GB 0 26 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L12 894.0GB 0 27 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L15 894.0GB 0 30 SSD-NVM shared - node_B_2 node_B_2:0m.i0.3L16 894.0GB 0 31 SSD-NVM shared - node_B_2 node_B_2:0n.0 1.75TB 0 0 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.1 1.75TB 0 1 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.2 1.75TB 0 2 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.3 1.75TB 0 3 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.4 1.75TB 0 4 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.5 1.75TB 0 5 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.6 1.75TB 0 6 SSD-NVM shared aggr0_rha12_b1_cm_02_0 node_B_2 node_B_2:0n.7 1.75TB 0 7 SSD-NVM shared - node_B_2 64 entries were displayed. cluster_B::> cluster_A::> disk show Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_1:0m.i1.0L2 1.75TB 0 5 SSD-NVM shared - node_B_2 node_A_1:0m.i1.0L8 1.75TB 0 3 SSD-NVM shared - node_B_2 node_A_1:0m.i1.0L18 1.75TB 0 19 SSD-NVM shared - node_B_1 node_A_1:0m.i1.0L25 1.75TB 0 12 SSD-NVM shared - node_B_1 node_A_1:0m.i1.0L27 1.75TB 0 14 SSD-NVM shared - node_B_1 node_A_1:0m.i1.2L1 1.75TB 0 4 SSD-NVM shared - node_B_2 node_A_1:0m.i1.2L6 1.75TB 0 1 SSD-NVM shared - node_B_2 node_A_1:0m.i1.2L7 1.75TB 0 2 SSD-NVM shared - node_B_2 node_A_1:0m.i1.2L14 1.75TB 0 7 SSD-NVM shared - node_B_2 node_A_1:0m.i1.2L17 1.75TB 0 18 SSD-NVM shared - node_B_1 node_A_1:0m.i1.2L22 1.75TB 0 17 SSD-NVM shared - node_B_1 node_A_1:0m.i2.1L5 1.75TB 0 0 SSD-NVM shared - node_B_2 node_A_1:0m.i2.1L13 1.75TB 0 6 SSD-NVM shared - node_B_2 node_A_1:0m.i2.1L21 1.75TB 0 16 SSD-NVM shared - node_B_1 node_A_1:0m.i2.1L26 1.75TB 0 13 SSD-NVM shared - node_B_1 node_A_1:0m.i2.1L28 1.75TB 0 15 SSD-NVM shared - node_B_1 node_A_1:0m.i2.3L19 1.75TB 0 42 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L20 1.75TB 0 43 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L23 1.75TB 0 40 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L24 1.75TB 0 41 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L29 1.75TB 0 36 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L30 1.75TB 0 37 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L31 1.75TB 0 38 SSD-NVM shared - node_A_1 node_A_1:0m.i2.3L32 1.75TB 0 39 SSD-NVM shared - node_A_1 node_A_1:0n.12 1.75TB 0 12 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.13 1.75TB 0 13 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.14 1.75TB 0 14 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.15 1.75TB 0 15 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.16 1.75TB 0 16 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.17 1.75TB 0 17 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.18 1.75TB 0 18 SSD-NVM shared aggr0 node_A_1 node_A_1:0n.19 1.75TB 0 19 SSD-NVM shared - node_A_1 node_A_1:0n.24 894.0GB 0 24 SSD-NVM shared - node_B_2 node_A_1:0n.25 894.0GB 0 25 SSD-NVM shared - node_B_2 node_A_1:0n.26 894.0GB 0 26 SSD-NVM shared - node_B_2 node_A_1:0n.27 894.0GB 0 27 SSD-NVM shared - node_B_2 node_A_1:0n.28 894.0GB 0 28 SSD-NVM shared - node_B_2 node_A_1:0n.29 894.0GB 0 29 SSD-NVM shared - node_B_2 node_A_1:0n.30 894.0GB 0 30 SSD-NVM shared - node_B_2 node_A_1:0n.31 894.0GB 0 31 SSD-NVM shared - node_B_2 node_A_1:0n.36 1.75TB 0 36 SSD-NVM shared - node_B_1 node_A_1:0n.37 1.75TB 0 37 SSD-NVM shared - node_B_1 node_A_1:0n.38 1.75TB 0 38 SSD-NVM shared - node_B_1 node_A_1:0n.39 1.75TB 0 39 SSD-NVM shared - node_B_1 node_A_1:0n.40 1.75TB 0 40 SSD-NVM shared - node_B_1 node_A_1:0n.41 1.75TB 0 41 SSD-NVM shared - node_B_1 node_A_1:0n.42 1.75TB 0 42 SSD-NVM shared - node_B_1 node_A_1:0n.43 1.75TB 0 43 SSD-NVM shared - node_B_1 node_A_2:0m.i2.3L3 894.0GB 0 28 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L4 894.0GB 0 29 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L9 894.0GB 0 24 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L10 894.0GB 0 25 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L11 894.0GB 0 26 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L12 894.0GB 0 27 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L15 894.0GB 0 30 SSD-NVM shared - node_A_2 node_A_2:0m.i2.3L16 894.0GB 0 31 SSD-NVM shared - node_A_2 node_A_2:0n.0 1.75TB 0 0 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.1 1.75TB 0 1 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.2 1.75TB 0 2 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.3 1.75TB 0 3 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.4 1.75TB 0 4 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.5 1.75TB 0 5 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.6 1.75TB 0 6 SSD-NVM shared aggr0_node_A_2_0 node_A_2 node_A_2:0n.7 1.75TB 0 7 SSD-NVM shared - node_A_2 64 entries were displayed. cluster_A::>
Affectation manuelle de lecteurs pour le pool 1 (ONTAP 9.4 ou version ultérieure)
Si le système n'a pas été préconfiguré en usine et ne répond pas aux exigences relatives à l'affectation automatique des lecteurs, vous devez affecter manuellement les lecteurs du pool distant 1.
Cette procédure s'applique aux configurations exécutant ONTAP 9.4 ou version ultérieure.
Vous trouverez des informations permettant de déterminer si votre système nécessite une affectation manuelle des disques dans le "Considérations relatives à l'affectation automatique des disques et aux systèmes ADP dans ONTAP 9.4 et versions ultérieures".
Lorsque la configuration inclut uniquement deux tiroirs externes par site, les pools 1 disques pour chaque site doivent être partagés depuis le même tiroir, comme illustré ci-dessous :
-
Le nœud_A_1 est affecté aux disques dans les baies 0-11 du site_B-shelf_2 (à distance)
-
Le node_A_2 est affecté aux disques dans les baies 12-23 sur site_B-shelf_2 (à distance)
-
À partir de chaque nœud de la configuration IP MetroCluster, attribuez des disques distants au pool 1.
-
Afficher la liste des disques non assignés :
disk show -host-adapter 0m -container-type unassignedcluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- 6.23.0 - 23 0 SSD unassigned - - 6.23.1 - 23 1 SSD unassigned - - . . . node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - . . . 48 entries were displayed. cluster_A::> -
Affecter la propriété des lecteurs distants (0m) au pool 1 du premier nœud (par exemple, node_A_1) :
disk assign -disk <disk-id> -pool 1 -owner <owner_node_name>disk-idvous devez identifier un lecteur sur un shelf distant deowner_node_name. -
Vérifiez que les disques ont été affectés au pool 1 :
disk show -host-adapter 0m -container-type unassigned
La connexion iSCSI utilisée pour accéder aux lecteurs distants apparaît comme périphérique 0m. Le résultat suivant indique que les disques du tiroir 23 ont été affectés, car ils n'apparaissent plus dans la liste des disques non assignés :
cluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - . . . node_A_2:0m.i2.1L90 - 21 19 SSD unassigned - - 24 entries were displayed. cluster_A::>-
Répétez ces étapes pour affecter les lecteurs du pool 1 au second nœud du site A (par exemple, « node_A_2 »).
-
Répétez ces étapes sur le site B.
-
Assignation manuelle de disques pour le pool 1 (ONTAP 9.3)
Si vous avez au moins deux tiroirs disques pour chaque nœud, vous utilisez la fonctionnalité d'affectation automatique d'ONTAP pour attribuer automatiquement des disques distants (pool1).
Vous devez d'abord affecter un disque du tiroir au pool 1. ONTAP attribue ensuite automatiquement le reste des disques du tiroir au même pool.
Cette procédure s'applique aux configurations exécutant ONTAP 9.3.
Cette procédure ne peut être utilisée que si vous disposez d'au moins deux tiroirs disques pour chaque nœud, ce qui permet l'assignation automatique de disques au niveau des tiroirs.
Si vous ne pouvez pas utiliser l'affectation automatique au niveau du tiroir, vous devez attribuer manuellement les disques distants de sorte que chaque nœud dispose d'un pool de disques distant (pool 1).
La fonctionnalité d'affectation automatique de disques ONTAP attribue les disques selon le tiroir. Par exemple :
-
Tous les disques du site_B-shelf_2 sont affectés automatiquement dans la pool1 du nœud_A_1
-
Tous les disques du site_B-shelf_4 sont affectés automatiquement dans la pool1 du nœud_A_2
-
Tous les disques du site_A-shelf_2 sont affectés automatiquement dans la pool1 du nœud_B_1
-
Tous les disques du site_A-shelf_4 sont automatiquement affectés à la pool1 du nœud_B_2
Vous devez définir l'auto-assignation en spécifiant un seul disque sur chaque shelf.
-
À partir de chaque nœud de la configuration IP MetroCluster, affectez un disque distant au pool 1.
-
Afficher la liste des disques non assignés :
disk show -host-adapter 0m -container-type unassignedcluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- 6.23.0 - 23 0 SSD unassigned - - 6.23.1 - 23 1 SSD unassigned - - . . . node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - . . . 48 entries were displayed. cluster_A::> -
Sélectionner un disque distant (0m) et attribuer la propriété du disque au pool 1 du premier nœud (par exemple, « node_A_1 ») :
disk assign -disk <disk_id> -pool 1 -owner <owner_node_name>Le
disk-iddoit identifier un disque sur un shelf distant deowner_node_name.La fonction d'affectation automatique des disques ONTAP affecte tous les disques du tiroir distant qui contient le disque spécifié.
-
Après avoir attendu au moins 60 secondes que l'affectation automatique du disque ait lieu, vérifiez que les disques distants du shelf ont été affectés automatiquement au pool 1 :
disk show -host-adapter 0m -container-type unassigned
La connexion iSCSI utilisée pour accéder aux disques distants s'affiche en tant que périphérique 0m. Le résultat suivant indique que les disques du tiroir 23 ont été attribués et qu'ils ne sont plus visibles :
cluster_A::> disk show -host-adapter 0m -container-type unassigned Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- node_A_2:0m.i1.2L51 - 21 14 SSD unassigned - - node_A_2:0m.i1.2L64 - 21 10 SSD unassigned - - node_A_2:0m.i1.2L72 - 21 23 SSD unassigned - - node_A_2:0m.i1.2L74 - 21 1 SSD unassigned - - node_A_2:0m.i1.2L83 - 21 22 SSD unassigned - - node_A_2:0m.i1.2L90 - 21 7 SSD unassigned - - node_A_2:0m.i1.3L52 - 21 6 SSD unassigned - - node_A_2:0m.i1.3L59 - 21 13 SSD unassigned - - node_A_2:0m.i1.3L66 - 21 17 SSD unassigned - - node_A_2:0m.i1.3L73 - 21 12 SSD unassigned - - node_A_2:0m.i1.3L80 - 21 5 SSD unassigned - - node_A_2:0m.i1.3L81 - 21 2 SSD unassigned - - node_A_2:0m.i1.3L82 - 21 16 SSD unassigned - - node_A_2:0m.i1.3L91 - 21 3 SSD unassigned - - node_A_2:0m.i2.0L49 - 21 15 SSD unassigned - - node_A_2:0m.i2.0L50 - 21 4 SSD unassigned - - node_A_2:0m.i2.1L57 - 21 18 SSD unassigned - - node_A_2:0m.i2.1L58 - 21 11 SSD unassigned - - node_A_2:0m.i2.1L59 - 21 21 SSD unassigned - - node_A_2:0m.i2.1L65 - 21 20 SSD unassigned - - node_A_2:0m.i2.1L72 - 21 9 SSD unassigned - - node_A_2:0m.i2.1L80 - 21 0 SSD unassigned - - node_A_2:0m.i2.1L88 - 21 8 SSD unassigned - - node_A_2:0m.i2.1L90 - 21 19 SSD unassigned - - 24 entries were displayed. cluster_A::>-
Répétez ces étapes pour affecter les disques du pool 1 au second nœud du site A (par exemple, « node_A_2 »).
-
Répétez ces étapes sur le site B.
-
Activation de l'affectation automatique des disques dans ONTAP 9.4
Dans ONTAP 9.4, si vous avez désactivé l'affectation automatique des disques comme indiqué précédemment dans cette procédure, vous devez la réactiver sur tous les nœuds.
-
Activer l'affectation automatique des disques :
storage disk option modify -node <node_name> -autoassign onVous devez exécuter cette commande sur tous les nœuds de la configuration IP MetroCluster.
Mise en miroir des agrégats racine
Pour assurer la protection des données, vous devez mettre en miroir les agrégats racine.
Par défaut, l'agrégat root est créé comme un agrégat de type RAID-DP. Vous pouvez changer l'agrégat racine de RAID-DP à l'agrégat de type RAID4 La commande suivante modifie l'agrégat racine pour l'agrégat de type RAID4 :
storage aggregate modify –aggregate <aggr_name> -raidtype raid4
|
|
Sur les systèmes non ADP, le type RAID de l'agrégat peut être modifié depuis le RAID-DP par défaut vers le RAID4 avant ou après la mise en miroir de l'agrégat. |
-
Mettre en miroir l'agrégat racine :
storage aggregate mirror <aggr_name>La commande suivante met en miroir l'agrégat racine pour « Controller_A_1 » :
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
Cela met en miroir l'agrégat, il se compose d'un plex local et d'un plex distant situé sur le site MetroCluster distant.
-
Répétez l'étape précédente pour chaque nœud de la configuration MetroCluster.
Crée un agrégat de données en miroir sur chaque nœud
Vous devez créer un agrégat de données en miroir sur chaque nœud du groupe de reprise sur incident.
-
Vous devez savoir quels disques seront utilisés dans le nouvel agrégat.
-
Si votre système compte plusieurs types de disques (stockage hétérogène), vous devez comprendre comment vous assurer que le type de disque approprié est sélectionné.
-
Les disques sont détenus par un nœud spécifique ; lorsque vous créez un agrégat, tous les disques de cet agrégat doivent être détenus par le même nœud, qui devient le nœud de rattachement de cet agrégat.
Dans les systèmes utilisant ADP, des agrégats sont créés à l'aide de partitions dans lesquelles chaque disque est partitionné en partitions P1, P2 et P3.
-
Les noms d'agrégats doivent être conformes au schéma de nommage que vous avez déterminé lors de la planification de votre configuration MetroCluster.
-
Les noms des agrégats doivent être uniques sur l'ensemble des MetroCluster sites. Cela signifie que vous ne pouvez pas avoir deux agrégats différents portant le même nom sur le site A et le site B.
-
Afficher la liste des pièces de rechange disponibles :
storage disk show -spare -owner <node_name> -
Créer l'agrégat :
storage aggregate create -mirror trueSi vous êtes connecté au cluster depuis l'interface de gestion du cluster, vous pouvez créer un agrégat sur n'importe quel nœud du cluster. Pour s'assurer que l'agrégat est créé sur un nœud spécifique, utilisez le
-nodeparamètre ou spécifiez les disques qui sont détenus par ce nœud.Vous pouvez spécifier les options suivantes :
-
Nœud de rattachement de l'agrégat (c'est-à-dire le nœud qui détient l'agrégat en fonctionnement normal)
-
Liste de disques spécifiques à ajouter à l'agrégat
-
Nombre de disques à inclure
Dans la configuration minimale prise en charge, dans laquelle un nombre limité de disques sont disponibles, vous devez utiliser l'option force-petits agrégats pour créer un agrégat RAID-DP à trois disques. -
Style de checksum à utiliser pour l'agrégat
-
Type de disques à utiliser
-
Taille des disques à utiliser
-
Vitesse de conduite à utiliser
-
Type RAID des groupes RAID sur l'agrégat
-
Nombre maximal de disques pouvant être inclus dans un groupe RAID
-
Si les disques à RPM différents sont autorisés pour plus d'informations sur ces options, consultez la page man de l'agrégat de stockage create.
La commande suivante crée un agrégat en miroir avec 10 disques :
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Vérifier le groupe RAID et les disques de votre nouvel agrégat :
storage aggregate show-status -aggregate <aggregate-name>
Mise en œuvre de la configuration MetroCluster
Vous devez exécuter le metrocluster configure Commande pour démarrer la protection des données en configuration MetroCluster.
-
Chaque cluster doit contenir au moins deux agrégats de données en miroir non racines.
Vous pouvez le vérifier à l'aide du
storage aggregate showcommande.
Si vous souhaitez utiliser un seul agrégat de données en miroir, reportez-vous à la section Étape 1 pour obtenir des instructions. -
L'état ha-config des contrôleurs et du châssis doit être « mccip ».
Vous émettez le metrocluster configure Commandez une fois sur n'importe quel nœud pour activer la configuration MetroCluster. Vous n'avez pas besoin d'exécuter la commande sur chacun des sites ou nœuds, et ce n'est pas quel nœud ou site vous choisissez d'exécuter la commande.
Le metrocluster configure La commande couple automatiquement les deux nœuds avec les ID système les plus bas dans chacun des deux clusters comme partenaires de reprise d'activité. Dans une configuration MetroCluster à quatre nœuds, il existe deux paires de partenaires pour la reprise après incident. La seconde paire DR est créée à partir des deux nœuds avec des ID système plus élevés.
|
|
Vous devez pas configurer Onboard Key Manager (OKM) ou la gestion externe des clés avant d'exécuter la commande metrocluster configure.
|
-
configurer le MetroCluster au format suivant :
Si votre configuration MetroCluster possède…
Alors, procédez comme ça…
Plusieurs agrégats de données
Depuis n'importe quelle invite de nœud, configurer MetroCluster :
metrocluster configure <node_name>Un seul agrégat de données en miroir
-
Depuis l'invite de n'importe quel nœud, passez au niveau de privilège avancé :
set -privilege advancedVous devez répondre avec
ylorsque vous êtes invité à passer en mode avancé et que vous voyez l'invite du mode avancé (*>). -
Configurez le MetroCluster avec le
-allow-with-one-aggregate trueparamètre :metrocluster configure -allow-with-one-aggregate true <node_name> -
Retour au niveau de privilège admin :
set -privilege admin
Il est recommandé d'avoir plusieurs agrégats de données. Si le premier groupe de reprise après incident ne dispose que d'un seul agrégat et que vous souhaitez ajouter un groupe de reprise après incident avec un seul agrégat, vous devez déplacer le volume de métadonnées depuis cet agrégat. Pour plus d'informations sur cette procédure, voir "Déplacement d'un volume de métadonnées dans les configurations MetroCluster". La commande suivante permet d'activer la configuration MetroCluster sur tous les nœuds du groupe DR qui contient « Controller_A_1 » :
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
Vérifiez l'état de la mise en réseau sur le site A :
network port showL'exemple suivant montre l'utilisation du port réseau sur une configuration MetroCluster à quatre nœuds :
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
Vérifier la configuration MetroCluster des deux sites de la configuration MetroCluster.
-
Vérifier la configuration à partir du site A :
metrocluster showcluster_A::> metrocluster show Configuration: IP fabric Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal Remote: cluster_B Configuration state configured Mode normal -
Vérifier la configuration à partir du site B :
metrocluster show
cluster_B::> metrocluster show Configuration: IP fabric Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal Remote: cluster_A Configuration state configured Mode normal -
-
Pour éviter tout problème avec la mise en miroir de la mémoire non volatile, redémarrez chacun des quatre nœuds :
node reboot -node <node_name> -inhibit-takeover true -
Émettez le
metrocluster showcontrôlez les deux clusters pour vérifier à nouveau la configuration.
Configuration du second groupe de reprise sur incident dans une configuration à huit nœuds
Répétez les tâches précédentes pour configurer les nœuds dans le second groupe DR.
Création d'agrégats de données sans mise en miroir
Vous pouvez choisir de créer des agrégats de données non mis en miroir pour des données ne nécessitant pas la mise en miroir redondante fournie par les configurations MetroCluster.
-
Vérifiez que vous savez quels lecteurs seront utilisés dans le nouvel agrégat.
-
Si votre système compte plusieurs types de disques (stockage hétérogène), vous devez comprendre comment vous pouvez vérifier que le type de disque approprié est sélectionné.

|
Dans les configurations MetroCluster IP, les agrégats distants sans mise en miroir ne sont pas accessibles après un basculement |
|
|
Les agrégats non mis en miroir doivent être locaux au nœud qu'ils possèdent. |
-
Les disques sont détenus par un nœud spécifique ; lorsque vous créez un agrégat, tous les disques de cet agrégat doivent être détenus par le même nœud, qui devient le nœud de rattachement de cet agrégat.
-
Les noms d'agrégats doivent être conformes au schéma de nommage que vous avez déterminé lors de la planification de votre configuration MetroCluster.
-
Gestion des disques et des agrégats contient plus d'informations sur les agrégats en miroir.
-
Activer le déploiement d'agrégats non mis en miroir :
metrocluster modify -enable-unmirrored-aggr-deployment true -
Vérifiez que l'autoassignation des disques est désactivée :
disk option show -
Installez et câisez les tiroirs disques qui contiennent les agrégats non mis en miroir.
Vous pouvez utiliser les procédures décrites dans la documentation installation et configuration de la plateforme et des tiroirs disques.
-
Attribuer manuellement tous les disques du nouveau shelf au nœud approprié :
disk assign -disk <disk_id> -owner <owner_node_name> -
Créer l'agrégat :
storage aggregate createSi vous êtes connecté au cluster depuis l'interface de gestion du cluster, vous pouvez créer un agrégat sur n'importe quel nœud du cluster. Pour vérifier que l'agrégat est créé sur un nœud spécifique, vous devez utiliser le paramètre -node ou spécifier les disques qui appartiennent à ce nœud.
Vous devez également vous assurer d'inclure uniquement les disques du tiroir sans miroir à l'agrégat.
Vous pouvez spécifier les options suivantes :
-
Nœud de rattachement de l'agrégat (c'est-à-dire le nœud qui détient l'agrégat en fonctionnement normal)
-
Liste de disques spécifiques à ajouter à l'agrégat
-
Nombre de disques à inclure
-
Style de checksum à utiliser pour l'agrégat
-
Type de disques à utiliser
-
Taille des disques à utiliser
-
Vitesse de conduite à utiliser
-
Type RAID des groupes RAID sur l'agrégat
-
Nombre maximal de disques pouvant être inclus dans un groupe RAID
-
Indique si les disques à régime différent sont autorisés
Pour plus d'informations sur ces options, consultez la page man relative à la création d'agrégat de stockage.
La commande suivante crée un agrégat sans mise en miroir avec 10 disques :
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Vérifier le groupe RAID et les disques de votre nouvel agrégat :
storage aggregate show-status -aggregate <aggregate_name> -
Désactiver le déploiement d'agrégats non mis en miroir :
metrocluster modify -enable-unmirrored-aggr-deployment false -
Vérifiez que l'autoassignation des disques est activée :
disk option show
Vérification de la configuration MetroCluster
Vous pouvez vérifier que les composants et les relations de la configuration MetroCluster fonctionnent correctement.
Vous devez effectuer un contrôle après la configuration initiale et après avoir apporté des modifications à la configuration MetroCluster.
Vous devez également effectuer une vérification avant le basculement (prévu) ou le rétablissement.
Si le metrocluster check run la commande est émise deux fois en peu de temps sur l'un des clusters ou les deux clusters. un conflit peut se produire et la commande risque de ne pas collecter toutes les données. Ensuite metrocluster check show les commandes n'affichent pas la sortie attendue.
-
Vérifiez la configuration :
metrocluster check runLa commande s'exécute en arrière-plan et peut ne pas être terminée immédiatement.
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
Affiche des résultats plus détaillés à partir de la commande MetroCluster check run la plus récente :
metrocluster check aggregate showmetrocluster check cluster showmetrocluster check config-replication showmetrocluster check lif showmetrocluster check node show
Le metrocluster check showles commandes affichent les résultats des plus récentesmetrocluster check runcommande. Vous devez toujours exécuter lemetrocluster check runavant d'utiliser lemetrocluster check showcommandes de manière à ce que les informations affichées soient à jour.L'exemple suivant montre le
metrocluster check aggregate showRésultat de la commande pour une configuration MetroCluster à quatre nœuds saine :cluster_A::> metrocluster check aggregate show Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.L'exemple suivant montre le
metrocluster check cluster showRésultat de la commande pour une configuration MetroCluster à quatre nœuds saine. Il indique que les clusters sont prêts à effectuer un basculement négocié si nécessaire.cluster_A::> metrocluster check cluster show Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
Finalisation de la configuration ONTAP
Après la configuration, l'activation et la vérification de la configuration MetroCluster, vous pouvez terminer la configuration du cluster en ajoutant des SVM, des interfaces réseau et d'autres fonctionnalités ONTAP supplémentaires, si nécessaire.