

Installazione e configurazione dell'operatore di monitoraggio Kubernetes
 Suggerisci modifiche
Suggerisci modifiche
Data Infrastructure Insights offre l'operatore di monitoraggio Kubernetes per la raccolta Kubernetes. Passare a Kubernetes > Collectors > +Kubernetes Collector per distribuire un nuovo operatore.
Prima di installare Kubernetes Monitoring Operator
Vedi il"Prerequisiti" documentazione prima di installare o aggiornare Kubernetes Monitoring Operator.
Installazione dell'operatore di monitoraggio Kubernetes
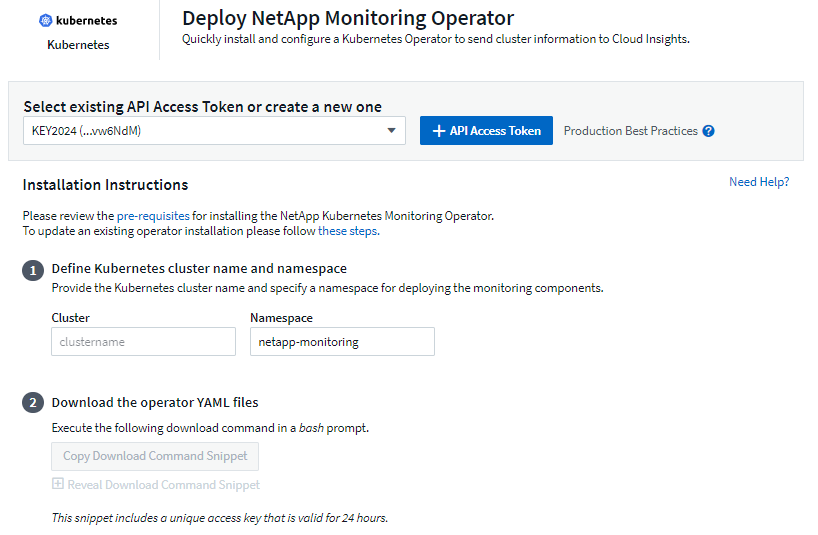
-
Immettere un nome cluster e uno spazio dei nomi univoci. Se seiaggiornamento da un precedente operatore Kubernetes, utilizzare lo stesso nome del cluster e lo stesso spazio dei nomi.
-
Una volta inseriti questi dati, è possibile copiare il frammento del comando Download negli appunti.
-
Incolla lo snippet in una finestra bash ed eseguilo. Verranno scaricati i file di installazione dell'operatore. Si noti che lo snippet ha una chiave univoca ed è valido per 24 ore.
-
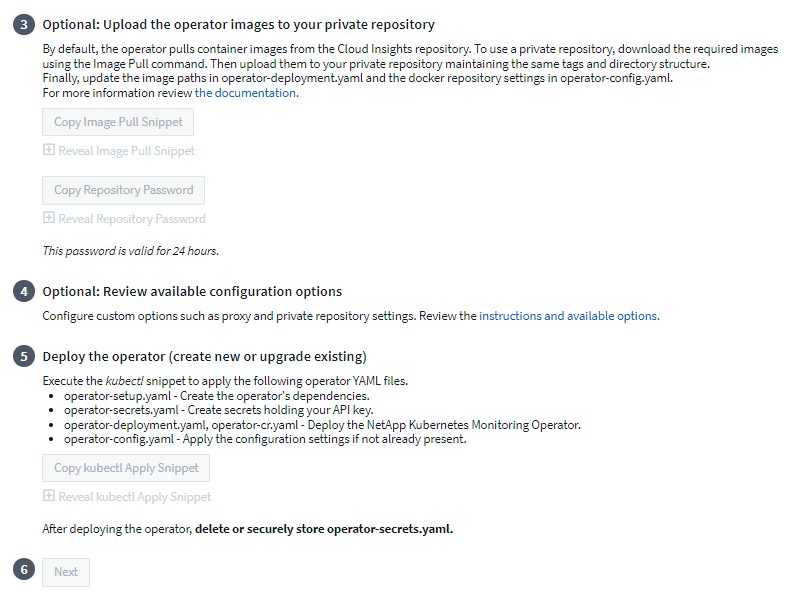
Se hai un repository personalizzato o privato, copia il frammento di codice Image Pull facoltativo, incollalo in una shell bash ed eseguilo. Una volta estratte le immagini, copiale nel tuo repository privato. Assicuratevi di mantenere gli stessi tag e la stessa struttura delle cartelle. Aggiornare i percorsi in operator-deployment.yaml e le impostazioni del repository Docker in operator-config.yaml.
-
Se lo si desidera, rivedere le opzioni di configurazione disponibili, come le impostazioni del proxy o del repository privato. Puoi leggere di più su"opzioni di configurazione" .
-
Quando sei pronto, distribuisci l'operatore copiando lo snippet Apply di kubectl, scaricandolo ed eseguendolo.
-
L'installazione procede automaticamente. Una volta completato, fare clic sul pulsante Avanti.
-
Al termine dell'installazione, fare clic sul pulsante Avanti. Assicurati di eliminare o archiviare in modo sicuro anche il file operator-secrets.yaml.
Se hai un repository personalizzato, leggi a riguardoutilizzando un repository Docker personalizzato/privato .
Componenti di monitoraggio di Kubernetes
Data Infrastructure Insights Kubernetes Monitoring è composto da quattro componenti di monitoraggio:
-
Metriche del cluster
-
Prestazioni di rete e mappa (facoltativo)
-
Registri eventi (facoltativo)
-
Analisi del cambiamento (facoltativo)
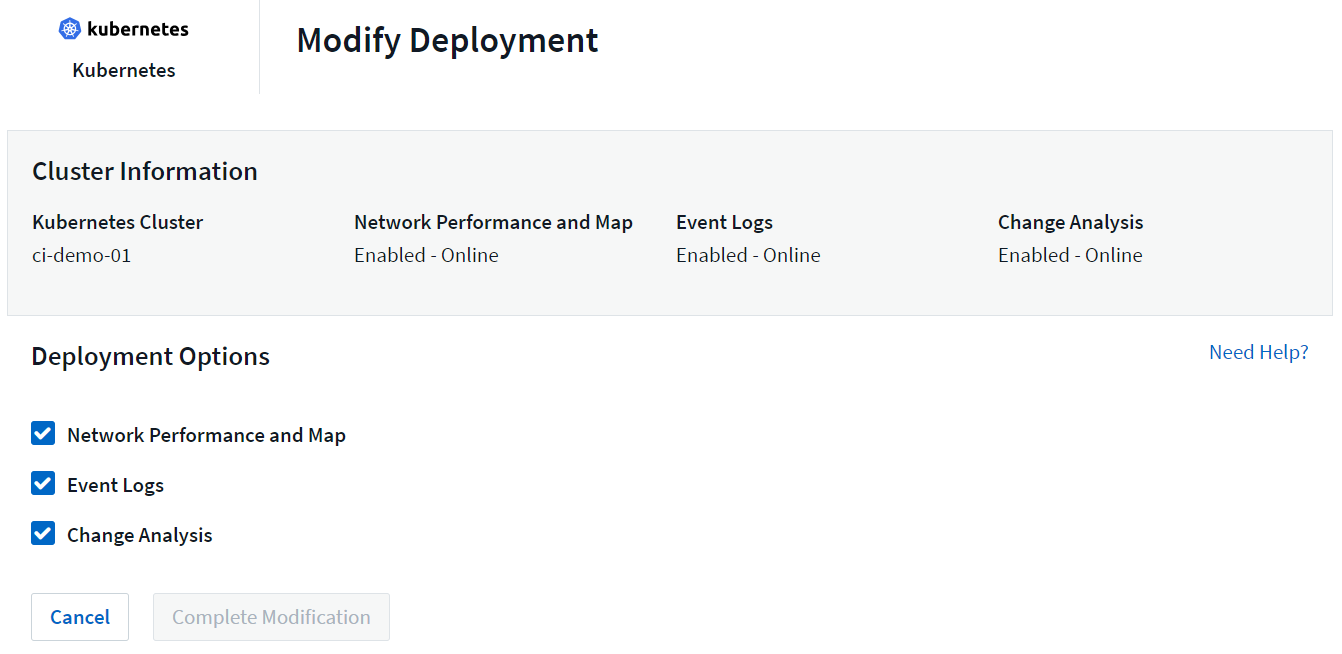
I componenti facoltativi sopra indicati sono abilitati per impostazione predefinita per ciascun collector Kubernetes; se decidi che non hai bisogno di un componente per un collector specifico, puoi disabilitarlo andando su Kubernetes > Collectors e selezionando Modifica distribuzione dal menu "tre punti" del collector sulla destra dello schermo.
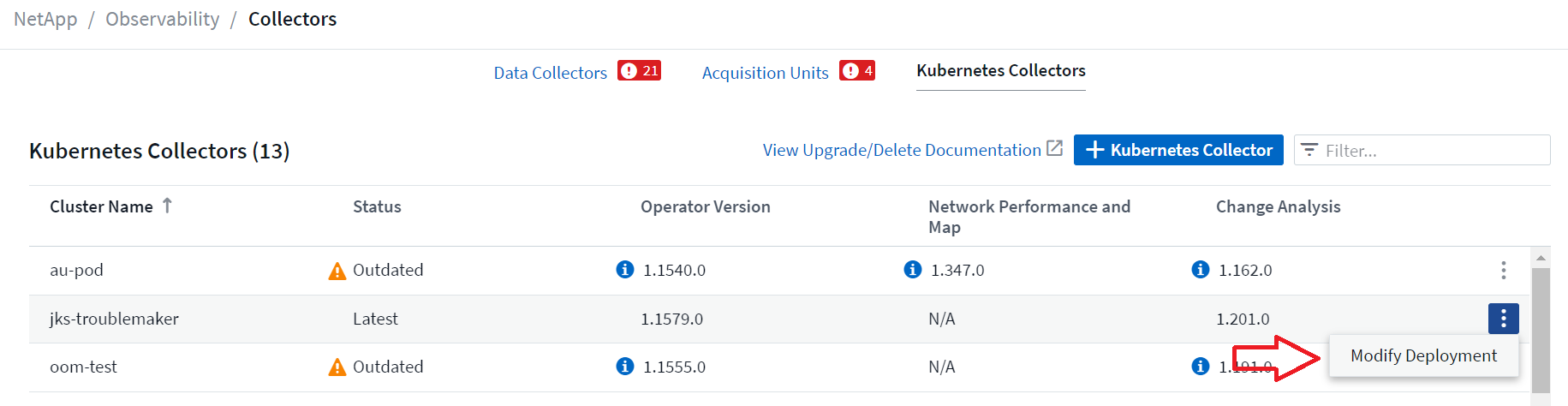
La schermata mostra lo stato attuale di ciascun componente e consente di disabilitare o abilitare i componenti per quel raccoglitore, a seconda delle necessità.
Aggiornamento all'ultima versione di Kubernetes Monitoring Operator
Aggiornamenti dei pulsanti DII
È possibile aggiornare Kubernetes Monitoring Operator tramite la pagina DII Kubernetes Collectors. Fare clic sul menu accanto al cluster che si desidera aggiornare e selezionare Aggiorna. L'operatore verificherà le firme delle immagini, eseguirà uno snapshot dell'installazione corrente ed eseguirà l'aggiornamento. Entro pochi minuti dovresti vedere l'avanzamento dello Stato dell'operatore da Aggiornamento in corso a Ultimo. Se si verifica un errore, è possibile selezionare lo stato Errore per maggiori dettagli e fare riferimento alla tabella di risoluzione dei problemi degli aggiornamenti tramite pulsante riportata di seguito.
Aggiornamenti rapidi con repository privati
Se il tuo operatore è configurato per utilizzare un repository privato, assicurati che tutte le immagini necessarie per eseguire l'operatore e le relative firme siano disponibili nel tuo repository. Se durante il processo di aggiornamento si verifica un errore per immagini mancanti, è sufficiente aggiungerle al repository e riprovare l'aggiornamento. Per caricare le firme delle immagini nel tuo repository, utilizza lo strumento di co-firma come segue, assicurandoti di caricare le firme per tutte le immagini specificate in 3 Facoltativo: carica le immagini dell'operatore nel tuo repository privato > Frammento di estrazione dell'immagine
cosign copy example.com/src:v1 example.com/dest:v1 #Example cosign copy <DII container registry>/netapp-monitoring:<image version> <private repository>/netapp-monitoring:<image version>
Ripristino di una versione precedentemente in esecuzione
Se hai effettuato l'aggiornamento utilizzando la funzionalità di aggiornamento tramite pulsante e riscontri difficoltà con la versione corrente dell'operatore entro sette giorni dall'aggiornamento, puoi effettuare il downgrade alla versione in esecuzione in precedenza utilizzando lo snapshot creato durante il processo di aggiornamento. Fare clic sul menu accanto al cluster di cui si desidera eseguire il rollback e selezionare Roll back.
Aggiornamenti manuali
Determinare se esiste un AgentConfiguration con l'operatore esistente (se lo spazio dei nomi non è quello predefinito netapp-monitoring, sostituirlo con lo spazio dei nomi appropriato):
kubectl -n netapp-monitoring get agentconfiguration netapp-ci-monitoring-configuration Se esiste un AgentConfiguration:
-
Installarel'ultimo Operatore rispetto all'Operatore esistente.
-
Assicurati di essereestrazione delle ultime immagini del contenitore se si utilizza un repository personalizzato.
-
Se AgentConfiguration non esiste:
-
Prendi nota del nome del tuo cluster riconosciuto da Data Infrastructure Insights (se il tuo namespace non è quello predefinito netapp-monitoring, sostituiscilo con il namespace appropriato):
kubectl -n netapp-monitoring get agent -o jsonpath='{.items[0].spec.cluster-name}' * Crea un backup dell'operatore esistente (se il tuo namespace non è il netapp-monitoring predefinito, sostituiscilo con il namespace appropriato):kubectl -n netapp-monitoring get agent -o yaml > agent_backup.yaml * <<to-remove-the-kubernetes-monitoring-operator,Disinstallare>>l'operatore esistente. * <<installing-the-kubernetes-monitoring-operator,Installare>>l'ultimo Operatore.
-
Utilizzare lo stesso nome del cluster.
-
Dopo aver scaricato gli ultimi file YAML dell'operatore, trasferire tutte le personalizzazioni presenti in agent_backup.yaml al file operator-config.yaml scaricato prima della distribuzione.
-
Assicurati di essereestrazione delle ultime immagini del contenitore se si utilizza un repository personalizzato.
-
Arresto e avvio dell'operatore di monitoraggio Kubernetes
Per arrestare Kubernetes Monitoring Operator:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=0 Per avviare Kubernetes Monitoring Operator:
kubectl -n netapp-monitoring scale deploy monitoring-operator --replicas=1
Disinstallazione
Per rimuovere l'operatore di monitoraggio Kubernetes
Si noti che lo spazio dei nomi predefinito per l'operatore di monitoraggio Kubernetes è "netapp-monitoring". Se hai impostato un tuo namespace, sostituiscilo in questi e in tutti i comandi e file successivi.
Le versioni più recenti dell'operatore di monitoraggio possono essere disinstallate con i seguenti comandi:
kubectl -n <NAMESPACE> delete agent -l installed-by=nkmo-<NAMESPACE> kubectl -n <NAMESPACE> delete clusterrole,clusterrolebinding,crd,svc,deploy,role,rolebinding,secret,sa -l installed-by=nkmo-<NAMESPACE>
Se l'operatore di monitoraggio è stato distribuito nel proprio namespace dedicato, eliminare il namespace:
kubectl delete ns <NAMESPACE> Nota: se il primo comando restituisce "Nessuna risorsa trovata", utilizzare le seguenti istruzioni per disinstallare le versioni precedenti dell'operatore di monitoraggio.
Eseguire ciascuno dei seguenti comandi nell'ordine indicato. A seconda dell'installazione corrente, alcuni di questi comandi potrebbero restituire messaggi di tipo "oggetto non trovato". Questi messaggi possono essere tranquillamente ignorati.
kubectl -n <NAMESPACE> delete agent agent-monitoring-netapp kubectl delete crd agents.monitoring.netapp.com kubectl -n <NAMESPACE> delete role agent-leader-election-role kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader <NAMESPACE>-agent-manager-role <NAMESPACE>-agent-proxy-role <NAMESPACE>-cluster-role-privileged kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding <NAMESPACE>-agent-manager-rolebinding <NAMESPACE>-agent-proxy-rolebinding <NAMESPACE>-cluster-role-binding-privileged kubectl delete <NAMESPACE>-psp-nkmo kubectl delete ns <NAMESPACE>
Se in precedenza è stato creato un vincolo di contesto di sicurezza:
kubectl delete scc telegraf-hostaccess
Informazioni su Kube-state-metrics
NetApp Kubernetes Monitoring Operator installa le proprie metriche kube-state per evitare conflitti con altre istanze.
Per informazioni su Kube-State-Metrics, vedere"questa pagina" .
Configurazione/Personalizzazione dell'operatore
Queste sezioni contengono informazioni sulla personalizzazione della configurazione dell'operatore, sull'utilizzo del proxy, sull'utilizzo di un repository Docker personalizzato o privato o sull'utilizzo di OpenShift.
Opzioni di configurazione
Le impostazioni modificate più comunemente possono essere configurate nella risorsa personalizzata AgentConfiguration. È possibile modificare questa risorsa prima di distribuire l'operatore modificando il file operator-config.yaml. Questo file include esempi di impostazioni commentati. Vedi l'elenco di"impostazioni disponibili" per la versione più recente dell'operatore.
È anche possibile modificare questa risorsa dopo aver distribuito l'operatore utilizzando il seguente comando:
kubectl -n netapp-monitoring edit AgentConfiguration Per determinare se la versione distribuita dell'operatore supporta AgentConfiguration, eseguire il seguente comando:
kubectl get crd agentconfigurations.monitoring.netapp.com Se viene visualizzato il messaggio "Errore dal server (NotFound)", è necessario aggiornare l'operatore prima di poter utilizzare AgentConfiguration.
Configurazione del supporto proxy
Esistono due posti in cui è possibile utilizzare un proxy sul tenant per installare Kubernetes Monitoring Operator. Possono essere gli stessi sistemi proxy o sistemi proxy separati:
-
Proxy necessario durante l'esecuzione dello snippet di codice di installazione (utilizzando "curl") per connettere il sistema in cui viene eseguito lo snippet al tuo ambiente Data Infrastructure Insights
-
Proxy necessario al cluster Kubernetes di destinazione per comunicare con l'ambiente Data Infrastructure Insights
Se si utilizza un proxy per uno o entrambi questi elementi, per installare Kubernetes Operating Monitor è necessario innanzitutto assicurarsi che il proxy sia configurato per consentire una buona comunicazione con l'ambiente Data Infrastructure Insights . Se disponi di un proxy e puoi accedere a Data Infrastructure Insights dal server/VM da cui desideri installare l'operatore, è probabile che il tuo proxy sia configurato correttamente.
Per il proxy utilizzato per installare Kubernetes Operating Monitor, prima di installare l'operatore, impostare le variabili di ambiente http_proxy/https_proxy. Per alcuni ambienti proxy, potrebbe essere necessario impostare anche la variabile di ambiente no_proxy.
Per impostare le variabili, esegui i seguenti passaggi sul tuo sistema prima di installare Kubernetes Monitoring Operator:
-
Imposta le variabili di ambiente https_proxy e/o http_proxy per l'utente corrente:
-
Se il proxy da configurare non dispone di autenticazione (nome utente/password), eseguire il seguente comando:
export https_proxy=<proxy_server>:<proxy_port> .. Se il proxy da configurare dispone di autenticazione (nome utente/password), eseguire questo comando:
export http_proxy=<proxy_username>:<proxy_password>@<proxy_server>:<proxy_port>
-
Per far sì che il proxy utilizzato per il cluster Kubernetes comunichi con l'ambiente Data Infrastructure Insights , installare Kubernetes Monitoring Operator dopo aver letto tutte queste istruzioni.
Configurare la sezione proxy di AgentConfiguration in operator-config.yaml prima di distribuire Kubernetes Monitoring Operator.
agent:
...
proxy:
server: <server for proxy>
port: <port for proxy>
username: <username for proxy>
password: <password for proxy>
# In the noproxy section, enter a comma-separated list of
# IP addresses and/or resolvable hostnames that should bypass
# the proxy
noproxy: <comma separated list>
isTelegrafProxyEnabled: true
isFluentbitProxyEnabled: <true or false> # true if Events Log enabled
isCollectorsProxyEnabled: <true or false> # true if Network Performance and Map enabled
isAuProxyEnabled: <true or false> # true if AU enabled
...
...
Utilizzo di un repository Docker personalizzato o privato
Per impostazione predefinita, Kubernetes Monitoring Operator estrarrà le immagini dei container dal repository Data Infrastructure Insights . Se si utilizza un cluster Kubernetes come destinazione per il monitoraggio e tale cluster è configurato per estrarre immagini di container solo da un repository Docker personalizzato o privato o da un registro di container, è necessario configurare l'accesso ai container necessari all'operatore di monitoraggio Kubernetes.
Eseguire "Image Pull Snippet" dal riquadro di installazione di NetApp Monitoring Operator. Questo comando effettuerà l'accesso al repository Data Infrastructure Insights , estrarrà tutte le dipendenze delle immagini per l'operatore e uscirà dal repository Data Infrastructure Insights . Quando richiesto, immettere la password temporanea del repository fornita. Questo comando scarica tutte le immagini utilizzate dall'operatore, comprese quelle per le funzionalità opzionali. Di seguito sono riportate le funzioni per cui vengono utilizzate queste immagini.
Funzionalità dell'operatore principale e monitoraggio di Kubernetes
-
monitoraggio netapp
-
ci-kube-rbac-proxy
-
ci-ksm
-
ci-telegraf
-
utente root senza distribuzione
Registro eventi
-
ci-fluent-bit
-
ci-kubernetes-event-exporter
Prestazioni e mappa della rete
-
ci-net-observer
Invia l'immagine Docker dell'operatore al tuo repository Docker privato/locale/aziendale in base alle policy aziendali. Assicurati che i tag delle immagini e i percorsi delle directory di queste immagini nel tuo repository siano coerenti con quelli nel repository Data Infrastructure Insights .
Modifica la distribuzione monitoring-operator in operator-deployment.yaml e modifica tutti i riferimenti alle immagini per utilizzare il tuo repository Docker privato.
image: <docker repo of the enterprise/corp docker repo>/ci-kube-rbac-proxy:<ci-kube-rbac-proxy version> image: <docker repo of the enterprise/corp docker repo>/netapp-monitoring:<version>
Modifica AgentConfiguration in operator-config.yaml per riflettere la nuova posizione del repository Docker. Crea un nuovo imagePullSecret per il tuo repository privato, per maggiori dettagli consulta https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
agent: ... # An optional docker registry where you want docker images to be pulled from as compared to CI's docker registry # Please see documentation link here: link:task_config_telegraf_agent_k8s.html#using-a-custom-or-private-docker-repository dockerRepo: your.docker.repo/long/path/to/test # Optional: A docker image pull secret that maybe needed for your private docker registry dockerImagePullSecret: docker-secret-name
Istruzioni OpenShift
Se utilizzi OpenShift 4.6 o versione successiva, devi modificare AgentConfiguration in operator-config.yaml per abilitare l'impostazione runPrivileged:
# Set runPrivileged to true SELinux is enabled on your kubernetes nodes runPrivileged: true
Openshift potrebbe implementare un livello di sicurezza aggiuntivo che potrebbe bloccare l'accesso ad alcuni componenti di Kubernetes.
Tolleranze e difetti
I DaemonSet netapp-ci-telegraf-ds, netapp-ci-fluent-bit-ds e netapp-ci-net-observer-l4-ds devono pianificare un pod su ogni nodo del cluster per raccogliere correttamente i dati su tutti i nodi. L'operatore è stato configurato per tollerare alcune imperfezioni ben note. Se hai configurato delle taint personalizzate sui tuoi nodi, impedendo così ai pod di essere eseguiti su ogni nodo, puoi creare una tolleranza per quelle taint"nella AgentConfiguration" . Se hai applicato taint personalizzati a tutti i nodi del tuo cluster, devi anche aggiungere le tolleranze necessarie alla distribuzione dell'operatore per consentire la pianificazione e l'esecuzione del pod dell'operatore.
Scopri di più su Kubernetes"Contaminazioni e tolleranze" .
Una nota sui segreti
Per rimuovere l'autorizzazione per l'operatore di monitoraggio Kubernetes a visualizzare i segreti a livello di cluster, eliminare le seguenti risorse dal file operator-setup.yaml prima dell'installazione:
ClusterRole/netapp-ci<namespace>-agent-secret ClusterRoleBinding/netapp-ci<namespace>-agent-secret
Se si tratta di un aggiornamento, elimina anche le risorse dal tuo cluster:
kubectl delete ClusterRole/netapp-ci-<namespace>-agent-secret-clusterrole kubectl delete ClusterRoleBinding/netapp-ci-<namespace>-agent-secret-clusterrolebinding
Se l'analisi delle modifiche è abilitata, modificare AgentConfiguration o operator-config.yaml per rimuovere il commento dalla sezione change-management e includere kindsToIgnoreFromWatch: '"secrets"' nella sezione change-management. Notare la presenza e la posizione delle virgolette singole e doppie in questa riga.
change-management: ... # # A comma separated list of kinds to ignore from watching from the default set of kinds watched by the collector # # Each kind will have to be prefixed by its apigroup # # Example: '"networking.k8s.io.networkpolicies,batch.jobs", "authorization.k8s.io.subjectaccessreviews"' kindsToIgnoreFromWatch: '"secrets"' ...
Verifica delle firme delle immagini degli operatori di monitoraggio di Kubernetes
L'immagine per l'operatore e tutte le immagini correlate che distribuisce sono firmate da NetApp. È possibile verificare manualmente le immagini prima dell'installazione utilizzando lo strumento di co-firma oppure configurare un controller di ammissione Kubernetes. Per maggiori dettagli si prega di consultare il"Documentazione di Kubernetes" .
La chiave pubblica utilizzata per verificare le firme delle immagini è disponibile nel riquadro di installazione dell'operatore di monitoraggio in Facoltativo: carica le immagini dell'operatore nel tuo repository privato > Chiave pubblica della firma dell'immagine
Per verificare manualmente una firma immagine, procedere come segue:
-
Copia ed esegui l'Image Pull Snippet
-
Copia e inserisci la password del repository quando richiesto
-
Memorizza la chiave pubblica della firma dell'immagine (dii-image-signing.pub nell'esempio)
-
Verificare le immagini tramite co-firma. Fare riferimento al seguente esempio di utilizzo del cosign
$ cosign verify --key dii-image-signing.pub --insecure-ignore-sct --insecure-ignore-tlog <repository>/<image>:<tag>
Verification for <repository>/<image>:<tag> --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- The signatures were verified against the specified public key
[{"critical":{"identity":{"docker-reference":"<repository>/<image>"},"image":{"docker-manifest-digest":"sha256:<hash>"},"type":"cosign container image signature"},"optional":null}]
Risoluzione dei problemi
Ecco alcune cose da provare se riscontri problemi durante la configurazione dell'operatore di monitoraggio Kubernetes:
| Problema: | Prova questo: |
|---|---|
Non vedo alcun collegamento ipertestuale/connessione tra il mio volume persistente Kubernetes e il dispositivo di archiviazione back-end corrispondente. Il mio volume persistente Kubernetes è configurato utilizzando il nome host del server di archiviazione. |
Seguire i passaggi per disinstallare l'agente Telegraf esistente, quindi reinstallare l'agente Telegraf più recente. È necessario utilizzare Telegraf versione 2.0 o successiva e l'archiviazione del cluster Kubernetes deve essere monitorata attivamente da Data Infrastructure Insights. |
Nei log vedo messaggi simili ai seguenti: E0901 15:21:39.962145 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: Impossibile elencare *v1.MutatingWebhookConfiguration: il server non è riuscito a trovare la risorsa richiesta E0901 15:21:43.168161 1 reflector.go:178] k8s.io/kube-state-metrics/internal/store/builder.go:352: Impossibile elencare *v1.Lease: il server non è riuscito a trovare la risorsa richiesta (ottenere leases.coordination.k8s.io) ecc. |
Questi messaggi possono essere visualizzati se si esegue kube-state-metrics versione 2.0.0 o successiva con versioni di Kubernetes precedenti alla 1.20. Per ottenere la versione di Kubernetes: kubectl version Per ottenere la versione di kube-state-metrics: kubectl get deploy/kube-state-metrics -o jsonpath='{..image}' Per evitare che questi messaggi si verifichino, gli utenti possono modificare la distribuzione di kube-state-metrics per disabilitare i seguenti lease: mutatingwebhookconfigurations validatingwebhookconfigurations volumeattachments resources Più specificamente, possono utilizzare il seguente argomento CLI: resources=certificatesigningrequests,configmaps,cronjobs,daemonsets, deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,limitranges, namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes, poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas, secrets,services,statefulsets,storageclasses L'elenco di risorse predefinito è: "certificatesigningrequests,configmaps,cronjobs,daemonsets,deployments, endpoints,horizontalpodautoscalers,ingresses,jobs,leases,limitranges, mutatingwebhookconfigurations,namespaces,networkpolicies,nodes, persistentvolumeclaims,persistentvolumes,poddisruptionbudgets,pods,replicasets, replicationcontrollers,resourcequotas,secrets,services,statefulsets,storageclasses, validatingwebhookconfigurations,volumeattachments" |
Vedo messaggi di errore da Telegraf simili ai seguenti, ma Telegraf si avvia ed è in esecuzione: 11 ott 14:23:41 ip-172-31-39-47 systemd[1]: Avviato L'agente server basato su plugin per la segnalazione delle metriche in InfluxDB. 11 ott 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="impossibile creare la directory della cache. /etc/telegraf/.cache/snowflake, err: mkdir /etc/telegraf/.ca che: permesso negato. ignorato\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11 ott 14:23:41 ip-172-31-39-47 telegraf[1827]: time="2021-10-11T14:23:41Z" level=error msg="apertura non riuscita. Ignorato. Apri /etc/telegraf/.cache/snowflake/ocsp_response_cache.json: nessun file o directory\n" func="gosnowflake.(*defaultLogger).Errorf" file="log.go:120" 11 ott 14:23:41 ip-172-31-39-47 telegraf[1827]: 2021-10-11T14:23:41Z I! Avvio di Telegraf 1.19.3 |
Questo è un problema noto. Fare riferimento a"Questo articolo di GitHub" per maggiori dettagli. Finché Telegraf è attivo e funzionante, gli utenti possono ignorare questi messaggi di errore. |
Su Kubernetes, i miei pod Telegraf segnalano il seguente errore: "Errore nell'elaborazione delle informazioni mountstats: impossibile aprire il file mountstats: /hostfs/proc/1/mountstats, errore: apertura /hostfs/proc/1/mountstats: autorizzazione negata" |
Se SELinux è abilitato e applicato, è probabile che impedisca ai pod Telegraf di accedere al file /proc/1/mountstats sul nodo Kubernetes. Per superare questa restrizione, modificare agentconfiguration e abilitare l'impostazione runPrivileged. Per maggiori dettagli, fare riferimento alle istruzioni di OpenShift. |
Su Kubernetes, il mio pod Telegraf ReplicaSet segnala il seguente errore: [inputs.prometheus] Errore nel plugin: impossibile caricare la coppia di chiavi /etc/kubernetes/pki/etcd/server.crt:/etc/kubernetes/pki/etcd/server.key: aprire /etc/kubernetes/pki/etcd/server.crt: nessun file o directory del genere |
Il pod Telegraf ReplicaSet è progettato per essere eseguito su un nodo designato come master o per etcd. Se il pod ReplicaSet non è in esecuzione su uno di questi nodi, verranno visualizzati questi errori. Controlla se i tuoi nodi master/etcd presentano delle anomalie. In tal caso, aggiungere le tolleranze necessarie al Telegraf ReplicaSet, telegraf-rs. Ad esempio, modifica ReplicaSet… kubectl edit rs telegraf-rs …e aggiungi le tolleranze appropriate alla specifica. Quindi, riavviare il pod ReplicaSet. |
Ho un ambiente PSP/PSA. Ciò ha ripercussioni sul mio operatore di monitoraggio? |
Se il cluster Kubernetes è in esecuzione con Pod Security Policy (PSP) o Pod Security Admission (PSA), è necessario eseguire l'aggiornamento alla versione più recente di Kubernetes Monitoring Operator. Per effettuare l'aggiornamento all'operatore corrente con supporto per PSP/PSA, seguire questi passaggi: 1. Disinstallare l'operatore di monitoraggio precedente: kubectl delete agent agent-monitoring-netapp -n netapp-monitoring kubectl delete ns netapp-monitoring kubectl delete crd agents.monitoring.netapp.com kubectl delete clusterrole agent-manager-role agent-proxy-role agent-metrics-reader kubectl delete clusterrolebinding agent-manager-rolebinding agent-proxy-rolebinding agent-cluster-admin-rolebinding 2. Installare l'ultima versione dell'operatore di monitoraggio. |
Ho riscontrato problemi nel tentativo di distribuire l'Operatore e sto utilizzando PSP/PSA. |
1. Modificare l'agente utilizzando il seguente comando: kubectl -n <name-space> edit agent 2. Contrassegna 'security-policy-enabled' come 'false'. In questo modo verranno disattivati i criteri di sicurezza del Pod e l'ammissione di sicurezza del Pod e sarà consentito all'operatore di effettuare la distribuzione. Confermare utilizzando i seguenti comandi: kubectl get psp (dovrebbe mostrare che la politica di sicurezza del pod è stata rimossa) kubectl get all -n <namespace> |
grep -i psp (dovrebbe mostrare che non è stato trovato nulla) |
Errori "ImagePullBackoff" rilevati |
Questi errori potrebbero verificarsi se si dispone di un repository Docker personalizzato o privato e non è ancora stato configurato Kubernetes Monitoring Operator per riconoscerlo correttamente. Per saperne di più sulla configurazione per repository personalizzati/privati. |
Ho un problema con la distribuzione del mio operatore di monitoraggio e la documentazione attuale non mi aiuta a risolverlo. |
Acquisire o annotare in altro modo l'output dei seguenti comandi e contattare il team di supporto tecnico. kubectl -n netapp-monitoring get all kubectl -n netapp-monitoring describe all kubectl -n netapp-monitoring logs <monitoring-operator-pod> --all-containers=true kubectl -n netapp-monitoring logs <telegraf-pod> --all-containers=true |
I pod net-observer (Workload Map) nello spazio dei nomi Operator sono in CrashLoopBackOff |
Questi pod corrispondono al raccoglitore di dati Workload Map per Network Observability. Prova questi: • Controlla i log di uno dei pod per confermare la versione minima del kernel. Ad esempio: ---- {"ci-tenant-id":"your-tenant-id","collector-cluster":"your-k8s-cluster-name","environment":"prod","level":"error","msg":"fallimento nella convalida. Motivo: la versione del kernel 3.10.0 è inferiore alla versione minima del kernel 4.18.0","time":"2022-11-09T08:23:08Z"} ---- • I pod Net-observer richiedono che la versione del kernel Linux sia almeno 4.18.0. Controllare la versione del kernel utilizzando il comando "uname -r" e assicurarsi che sia >= 4.18.0 |
I pod sono in esecuzione nello spazio dei nomi Operatore (predefinito: netapp-monitoring), ma nell'interfaccia utente non vengono visualizzati dati per la mappa del carico di lavoro o metriche Kubernetes nelle query |
Controllare l'impostazione dell'ora sui nodi del cluster K8S. Per un audit e una segnalazione dei dati accurati, si consiglia vivamente di sincronizzare l'ora sulla macchina dell'agente utilizzando il protocollo NTP (Network Time Protocol) o il protocollo SNTP (Simple Network Time Protocol). |
Alcuni dei pod net-observer nello spazio dei nomi Operator sono nello stato In sospeso |
Net-observer è un DaemonSet ed esegue un pod in ogni nodo del cluster k8s. • Prendi nota del pod che si trova nello stato In sospeso e controlla se sta riscontrando un problema di risorse per la CPU o la memoria. Assicurarsi che nel nodo siano disponibili la memoria e la CPU richieste. |
Subito dopo aver installato Kubernetes Monitoring Operator, vedo quanto segue nei miei log: [inputs.prometheus] Errore nel plugin: errore durante la richiesta HTTP a http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics: Ottieni http://kube-state-metrics.<namespace>.svc.cluster.local:8080/metrics: dial tcp: cerca kube-state-metrics.<namespace>.svc.cluster.local: nessun host del genere |
In genere questo messaggio viene visualizzato solo quando viene installato un nuovo operatore e il pod telegraf-rs è attivo prima del pod ksm. Questi messaggi dovrebbero cessare una volta che tutti i pod saranno in esecuzione. |
Non vedo alcuna metrica raccolta per i CronJob di Kubernetes presenti nel mio cluster. |
Verifica la tua versione di Kubernetes (ad esempio |
Dopo aver installato l'operatore, i pod telegraf-ds entrano in CrashLoopBackOff e i log dei pod indicano "su: Authentication failure". |
Modificare la sezione telegraf in AgentConfiguration e impostare dockerMetricCollectionEnabled su false. Per maggiori dettagli fare riferimento al manuale dell'operatore"opzioni di configurazione" . … spec: … telegraf: … - nome: docker modalità di esecuzione: - sostituzioni DaemonSet: - chiave: DOCKER_UNIX_SOCK_PLACEHOLDER valore: unix:///run/docker.sock … … |
Nei miei registri di Telegraf vedo messaggi di errore ricorrenti simili ai seguenti: E! [agente] Errore durante la scrittura su output.http: Post "https://<tenant_url>/rest/v1/lake/ingest/influxdb": scadenza del contesto superata (Client.Timeout superato durante l'attesa delle intestazioni) |
Modificare la sezione telegraf in AgentConfiguration e aumentare outputTimeout a 10 s. Per maggiori dettagli fare riferimento al manuale dell'operatore"opzioni di configurazione" . |
Mancano i dati involvedobject per alcuni registri eventi. |
Assicurati di aver seguito i passaggi indicati in"Permessi" sezione sopra. |
Perché vedo due pod di operatori di monitoraggio in esecuzione, uno denominato netapp-ci-monitoring-operator-<pod> e l'altro denominato monitoring-operator-<pod>? |
A partire dal 12 ottobre 2023, Data Infrastructure Insights ha riorganizzato l'operatore per servire meglio i nostri utenti; affinché tali modifiche vengano adottate completamente, è necessariorimuovere il vecchio operatore Einstallare quello nuovo . |
I miei eventi Kubernetes hanno smesso inaspettatamente di segnalare a Data Infrastructure Insights. |
Recupera il nome del pod event-exporter: `kubectl -n netapp-monitoring get pods |
grep event-exporter |
awk '{print $1}' |
sed 's/event-exporter./event-exporter/'` |
Vedo che i pod distribuiti dal Kubernetes Monitoring Operator si bloccano a causa di risorse insufficienti. |
Fare riferimento all'operatore di monitoraggio Kubernetes"opzioni di configurazione" per aumentare i limiti della CPU e/o della memoria secondo necessità. |
Un'immagine mancante o una configurazione non valida hanno impedito l'avvio o la disponibilità dei pod netapp-ci-kube-state-metrics. Ora StatefulSet è bloccato e le modifiche alla configurazione non vengono applicate ai pod netapp-ci-kube-state-metrics. |
Lo StatefulSet è in un"rotto" stato. Dopo aver risolto eventuali problemi di configurazione, riavviare i pod netapp-ci-kube-state-metrics. |
I pod netapp-ci-kube-state-metrics non riescono ad avviarsi dopo aver eseguito un aggiornamento dell'operatore Kubernetes, generando l'errore ErrImagePull (impossibilità di estrarre l'immagine). |
Prova a reimpostare manualmente i pod. |
Durante l'analisi dei log, vengono visualizzati i messaggi "Evento scartato perché più vecchio di maxEventAgeSeconds" per il mio cluster Kubernetes. |
Modificare l'operatore agentconfiguration e aumentare event-exporter-maxEventAgeSeconds (ad esempio a 60 s), event-exporter-kubeQPS (ad esempio a 100) e event-exporter-kubeBurst (ad esempio a 500). Per maggiori dettagli su queste opzioni di configurazione, vedere"opzioni di configurazione" pagina. |
Telegraf avvisa o si blocca a causa di una memoria bloccabile insufficiente. |
Prova ad aumentare il limite di memoria bloccabile per Telegraf nel sistema operativo/nodo sottostante. Se aumentare il limite non è un'opzione, modificare la configurazione dell'agente NKMO e impostare unprotected su true. Ciò indicherà a Telegraf di non tentare di riservare pagine di memoria bloccate. Sebbene ciò possa rappresentare un rischio per la sicurezza, in quanto i segreti decrittati potrebbero essere trasferiti su disco, consente l'esecuzione in ambienti in cui non è possibile riservare memoria bloccata. Per maggiori dettagli sulle opzioni di configurazione non protette, fare riferimento a"opzioni di configurazione" pagina. |
Vedo messaggi di avviso da Telegraf simili ai seguenti: W! [inputs.diskio] Impossibile raccogliere il nome del disco per "vdc": errore durante la lettura di /dev/vdc: nessun file o directory del genere |
Per l'operatore di monitoraggio di Kubernetes, questi messaggi di avviso sono innocui e possono essere tranquillamente ignorati. In alternativa, modificare la sezione telegraf in AgentConfiguration e impostare runDsPrivileged su true. Per maggiori dettagli fare riferimento al"opzioni di configurazione dell'operatore" . |
Il mio pod fluent-bit non funziona con i seguenti errori: [2024/10/16 14:16:23] [errore] [/src/fluent-bit/plugins/in_tail/tail_fs_inotify.c:360 errno=24] Troppi file aperti [2024/10/16 14:16:23] [errore] inizializzazione input tail.0 non riuscita [2024/10/16 14:16:23] [errore] [motore] inizializzazione input non riuscita |
Prova a modificare le impostazioni fsnotify nel tuo cluster: sudo sysctl fs.inotify.max_user_instances (take note of setting) sudo sysctl fs.inotify.max_user_instances=<something larger than current setting> sudo sysctl fs.inotify.max_user_watches (take note of setting) sudo sysctl fs.inotify.max_user_watches=<something larger than current setting> Riavvia Fluent-bit. Nota: per rendere queste impostazioni persistenti tra i riavvii del nodo, è necessario inserire le seguenti righe in /etc/sysctl.conf fs.inotify.max_user_instances=<something larger than current setting> fs.inotify.max_user_watches=<something larger than current setting> |
I pod DS di Telegraf segnalano errori relativi al plugin di input Kubernetes che non riesce a effettuare richieste HTTP a causa dell'impossibilità di convalidare il certificato TLS. Ad esempio: E! [inputs.kubernetes] Errore nel plugin: errore durante la richiesta HTTP a"https://<kubelet_IP>:10250/stats/summary": Ottenere"https://<kubelet_IP>:10250/stats/summary": tls: impossibile verificare il certificato: x509: impossibile convalidare il certificato per <kubelet_IP> perché non contiene alcun IP SAN |
Ciò si verifica se il kubelet utilizza certificati autofirmati e/o il certificato specificato non include <kubelet_IP> nell'elenco Subject Alternative Name dei certificati. Per risolvere questo problema, l'utente può modificare il"configurazione dell'agente" e impostare telegraf:insecureK8sSkipVerify su true. In questo modo il plugin di input Telegraf verrà configurato per saltare la verifica. In alternativa, l'utente può configurare il kubelet per"serverTLSBootstrap" , che attiverà una richiesta di certificato dall'API 'certificates.k8s.io'. |
Ulteriori informazioni possono essere trovate presso"Supporto" pagina o nella"Matrice di supporto del raccoglitore dati" .