

TR-4931: Disaster Recovery con VMware Cloud su Amazon Web Services e Guest Connect
 Suggerisci modifiche
Suggerisci modifiche
Un ambiente e un piano di disaster recovery (DR) collaudati sono essenziali per le organizzazioni, per garantire che le applicazioni aziendali critiche possano essere ripristinate rapidamente in caso di un'interruzione importante. Questa soluzione si concentra sulla dimostrazione di casi d'uso DR con particolare attenzione alle tecnologie VMware e NetApp , sia in locale che con VMware Cloud su AWS.
Panoramica
NetApp vanta una lunga tradizione di integrazione con VMware, come dimostrano le decine di migliaia di clienti che hanno scelto NetApp come partner di storage per il loro ambiente virtualizzato. Questa integrazione continua anche con le opzioni connesse agli ospiti nel cloud e con le recenti integrazioni con i datastore NFS. Questa soluzione si concentra sul caso d'uso comunemente denominato storage connesso agli ospiti.
Nello storage connesso agli ospiti, il VMDK ospite viene distribuito su un datastore fornito da VMware e i dati dell'applicazione sono ospitati su iSCSI o NFS e mappati direttamente sulla VM. Per illustrare uno scenario DR, come mostrato nella figura seguente, vengono utilizzate le applicazioni Oracle e MS SQL.

Presupposti, prerequisiti e panoramica dei componenti
Prima di distribuire questa soluzione, rivedere la panoramica dei componenti, i prerequisiti richiesti per distribuire la soluzione e le ipotesi formulate nella documentazione di questa soluzione.
Esecuzione di DR con SnapCenter
In questa soluzione, SnapCenter fornisce snapshot coerenti con l'applicazione per i dati delle applicazioni SQL Server e Oracle. Questa configurazione, insieme alla tecnologia SnapMirror , garantisce la replicazione dei dati ad alta velocità tra il nostro cluster AFF locale e FSx ONTAP . Inoltre, Veeam Backup & Replication offre funzionalità di backup e ripristino per le nostre macchine virtuali.
In questa sezione, illustreremo la configurazione di SnapCenter, SnapMirror e Veeam sia per il backup che per il ripristino.
Le sezioni seguenti riguardano la configurazione e i passaggi necessari per completare un failover nel sito secondario:
Configurare le relazioni e le pianificazioni di conservazione SnapMirror
SnapCenter può aggiornare le relazioni SnapMirror all'interno del sistema di archiviazione primario (primario > mirror) e nei sistemi di archiviazione secondari (primario > vault) allo scopo di archiviazione e conservazione a lungo termine. Per fare ciò, è necessario stabilire e inizializzare una relazione di replica dei dati tra un volume di destinazione e un volume di origine utilizzando SnapMirror.
I sistemi ONTAP di origine e di destinazione devono trovarsi in reti peering tramite peering Amazon VPC, un gateway di transito, AWS Direct Connect o una VPN AWS.
Per impostare le relazioni SnapMirror tra un sistema ONTAP locale e FSx ONTAP sono necessari i seguenti passaggi:

|
Fare riferimento al "FSx ONTAP – Guida utente ONTAP" per ulteriori informazioni sulla creazione di relazioni SnapMirror con FSx. |
Registra le interfacce logiche Intercluster di origine e destinazione
Per il sistema ONTAP di origine residente in locale, è possibile recuperare le informazioni LIF inter-cluster da System Manager o dalla CLI.
-
In ONTAP System Manager, vai alla pagina Panoramica di rete e recupera gli indirizzi IP di tipo: Intercluster configurati per comunicare con l'AWS VPC in cui è installato FSx.
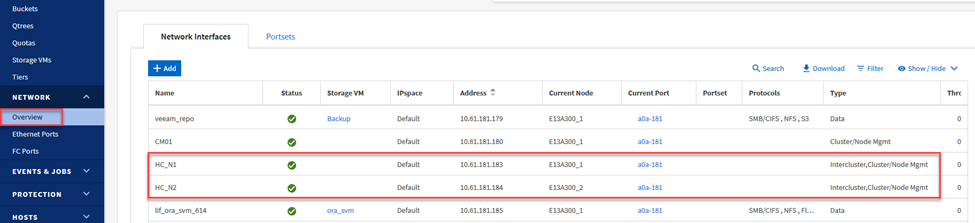
-
Per recuperare gli indirizzi IP Intercluster per FSx, accedere alla CLI ed eseguire il seguente comando:
FSx-Dest::> network interface show -role intercluster

Stabilire il peering del cluster tra ONTAP e FSx
Per stabilire il peering tra cluster ONTAP , è necessario che una passphrase univoca immessa nel cluster ONTAP di avvio venga confermata nell'altro cluster peer.
-
Impostare il peering sul cluster FSx di destinazione utilizzando
cluster peer createcomando. Quando richiesto, immettere una passphrase univoca che verrà utilizzata in seguito sul cluster di origine per finalizzare il processo di creazione.FSx-Dest::> cluster peer create -address-family ipv4 -peer-addrs source_intercluster_1, source_intercluster_2 Enter the passphrase: Confirm the passphrase:
-
Nel cluster di origine, è possibile stabilire la relazione peer del cluster utilizzando ONTAP System Manager o la CLI. Da ONTAP System Manager, vai a Protezione > Panoramica e seleziona Peer Cluster.
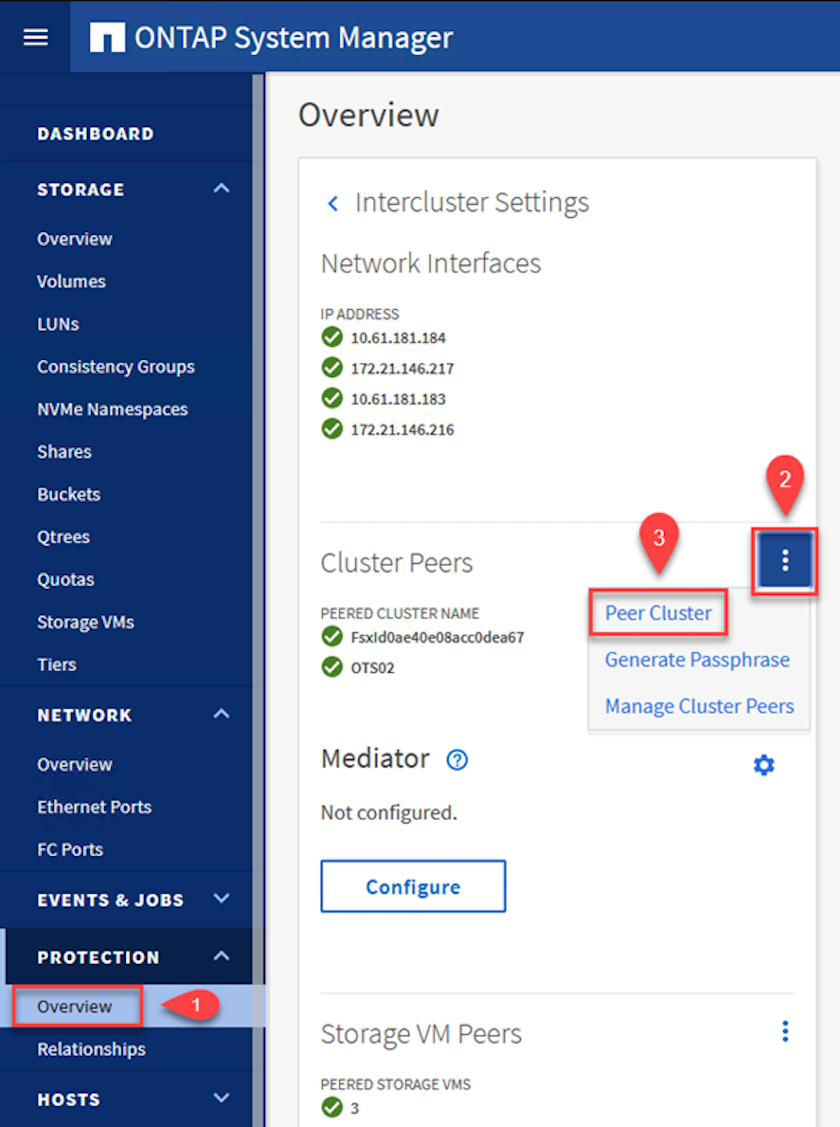
-
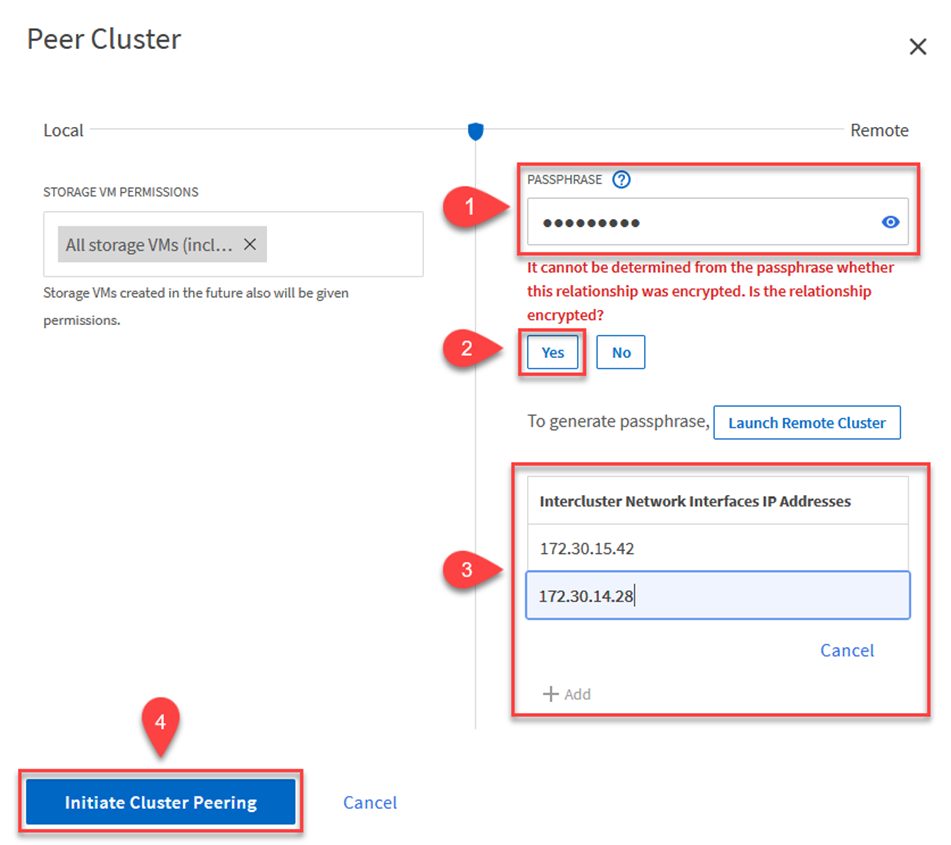
Nella finestra di dialogo Peer Cluster, compilare le informazioni richieste:
-
Immettere la passphrase utilizzata per stabilire la relazione del cluster peer sul cluster FSx di destinazione.
-
Selezionare
Yesper stabilire una relazione crittografata. -
Immettere l'indirizzo/gli indirizzi IP LIF intercluster del cluster FSx di destinazione.
-
Fare clic su Avvia peering cluster per finalizzare il processo.
-
-
Verificare lo stato della relazione peer del cluster dal cluster FSx con il seguente comando:
FSx-Dest::> cluster peer show

Stabilire una relazione di peering SVM
Il passaggio successivo consiste nell'impostare una relazione SVM tra le macchine virtuali di archiviazione di destinazione e di origine che contengono i volumi che saranno nelle relazioni SnapMirror .
-
Dal cluster FSx di origine, utilizzare il seguente comando dalla CLI per creare la relazione peer SVM:
FSx-Dest::> vserver peer create -vserver DestSVM -peer-vserver Backup -peer-cluster OnPremSourceSVM -applications snapmirror
-
Dal cluster ONTAP di origine, accettare la relazione di peering con ONTAP System Manager o con la CLI.
-
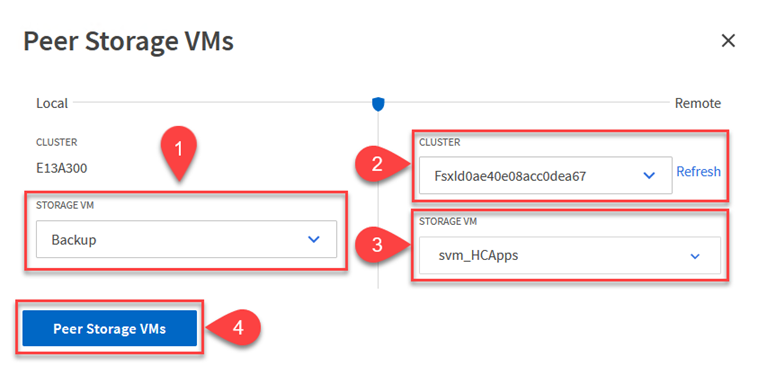
Da ONTAP System Manager, vai a Protezione > Panoramica e seleziona Peer Storage VM in Storage VM Peer.
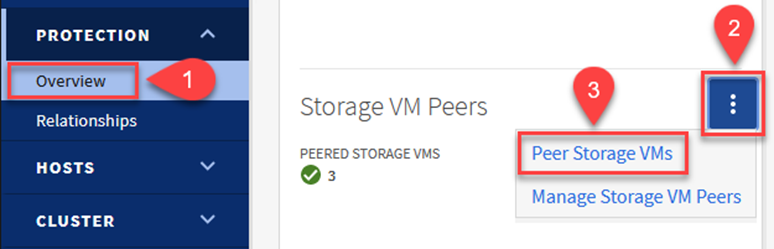
-
Nella finestra di dialogo della VM di archiviazione peer, compilare i campi obbligatori:
-
La VM di archiviazione di origine
-
Il cluster di destinazione
-
La VM di archiviazione di destinazione
-
-
Fare clic su Peer Storage VM per completare il processo di peering SVM.
Creare un criterio di conservazione degli snapshot
SnapCenter gestisce le pianificazioni di conservazione per i backup presenti come copie snapshot sul sistema di archiviazione primario. Ciò viene stabilito durante la creazione di una policy in SnapCenter. SnapCenter non gestisce i criteri di conservazione per i backup conservati su sistemi di archiviazione secondari. Queste policy vengono gestite separatamente tramite una policy SnapMirror creata sul cluster FSx secondario e associata ai volumi di destinazione che si trovano in una relazione SnapMirror con il volume di origine.
Quando si crea un criterio SnapCenter , è possibile specificare un'etichetta di criterio secondaria che viene aggiunta all'etichetta SnapMirror di ogni snapshot generato quando viene eseguito un backup SnapCenter .
|
|
Nell'archiviazione secondaria, queste etichette vengono abbinate alle regole dei criteri associati al volume di destinazione allo scopo di imporre la conservazione degli snapshot. |
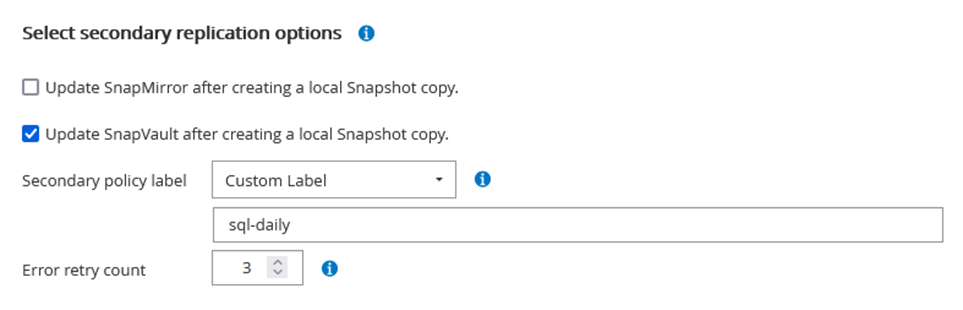
L'esempio seguente mostra un'etichetta SnapMirror presente su tutti gli snapshot generati come parte di un criterio utilizzato per i backup giornalieri del database SQL Server e dei volumi di registro.
Per ulteriori informazioni sulla creazione di criteri SnapCenter per un database SQL Server, vedere "Documentazione SnapCenter" .
Per prima cosa devi creare un criterio SnapMirror con regole che stabiliscano il numero di copie snapshot da conservare.
-
Creare la policy SnapMirror sul cluster FSx.
FSx-Dest::> snapmirror policy create -vserver DestSVM -policy PolicyName -type mirror-vault -restart always
-
Aggiungere regole alla policy con etichette SnapMirror che corrispondono alle etichette della policy secondaria specificate nelle policy SnapCenter .
FSx-Dest::> snapmirror policy add-rule -vserver DestSVM -policy PolicyName -snapmirror-label SnapMirrorLabelName -keep #ofSnapshotsToRetain
Lo script seguente fornisce un esempio di regola che potrebbe essere aggiunta a una policy:
FSx-Dest::> snapmirror policy add-rule -vserver sql_svm_dest -policy Async_SnapCenter_SQL -snapmirror-label sql-ondemand -keep 15
Creare regole aggiuntive per ogni etichetta SnapMirror e il numero di snapshot da conservare (periodo di conservazione).
Crea volumi di destinazione
Per creare un volume di destinazione su FSx che sarà il destinatario delle copie snapshot dai nostri volumi di origine, eseguire il seguente comando su FSx ONTAP:
FSx-Dest::> volume create -vserver DestSVM -volume DestVolName -aggregate DestAggrName -size VolSize -type DP
Creare le relazioni SnapMirror tra i volumi di origine e di destinazione
Per creare una relazione SnapMirror tra un volume di origine e uno di destinazione, eseguire il seguente comando su FSx ONTAP:
FSx-Dest::> snapmirror create -source-path OnPremSourceSVM:OnPremSourceVol -destination-path DestSVM:DestVol -type XDP -policy PolicyName
Inizializza le relazioni SnapMirror
Inizializza la relazione SnapMirror . Questo processo avvia un nuovo snapshot generato dal volume di origine e lo copia nel volume di destinazione.
FSx-Dest::> snapmirror initialize -destination-path DestSVM:DestVol
Distribuisci e configura il server Windows SnapCenter in locale.
Distribuisci Windows SnapCenter Server in locale
Questa soluzione utilizza NetApp SnapCenter per eseguire backup coerenti con le applicazioni dei database SQL Server e Oracle. In combinazione con Veeam Backup & Replication per il backup dei VMDK delle macchine virtuali, si ottiene una soluzione completa di disaster recovery per data center on-premise e basati su cloud.
Il SnapCenter software è disponibile sul sito di supporto NetApp e può essere installato sui sistemi Microsoft Windows che risiedono in un dominio o in un gruppo di lavoro. Una guida dettagliata alla pianificazione e alle istruzioni di installazione sono disponibili sul sito "Centro di documentazione NetApp" .
Il SnapCenter software può essere ottenuto presso "questo collegamento" .
Dopo l'installazione, è possibile accedere alla console SnapCenter da un browser Web utilizzando https://Virtual_Cluster_IP_or_FQDN:8146.
Dopo aver effettuato l'accesso alla console, è necessario configurare SnapCenter per il backup dei database SQL Server e Oracle.
Aggiungere controller di archiviazione a SnapCenter
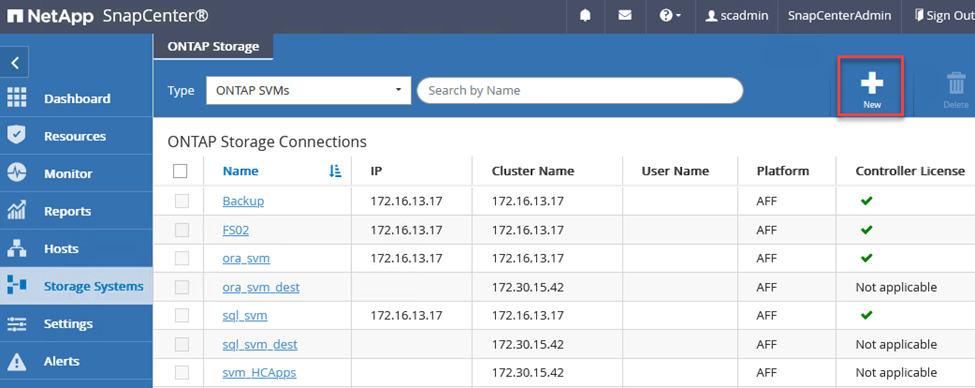
Per aggiungere controller di archiviazione a SnapCenter, completare i seguenti passaggi:
-
Dal menu a sinistra, seleziona Sistemi di archiviazione e poi fai clic su Nuovo per iniziare il processo di aggiunta dei controller di archiviazione a SnapCenter.
-
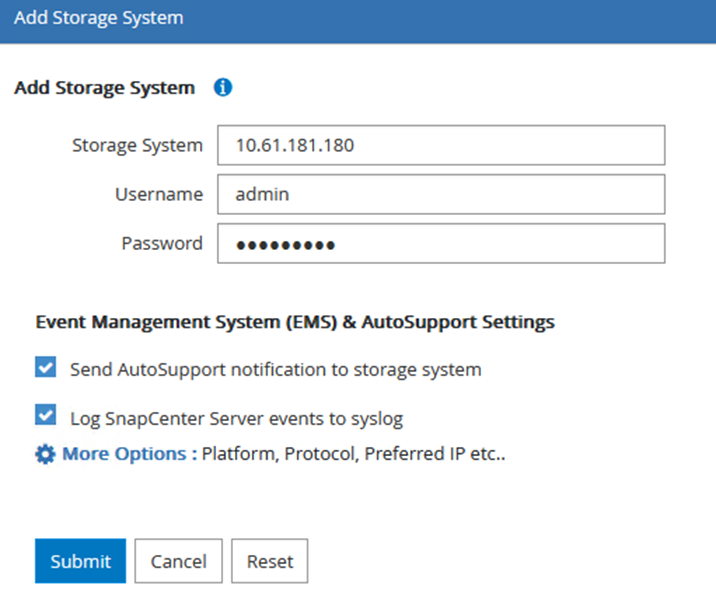
Nella finestra di dialogo Aggiungi sistema di archiviazione, aggiungere l'indirizzo IP di gestione per il cluster ONTAP locale, nonché il nome utente e la password. Quindi fare clic su Invia per iniziare l'individuazione del sistema di archiviazione.
-
Ripetere questa procedura per aggiungere il sistema FSx ONTAP a SnapCenter. In questo caso, seleziona Altre opzioni nella parte inferiore della finestra Aggiungi sistema di archiviazione e fai clic sulla casella di controllo Secondario per designare il sistema FSx come sistema di archiviazione secondario aggiornato con copie SnapMirror o con i nostri snapshot di backup primari.

Per ulteriori informazioni relative all'aggiunta di sistemi di archiviazione a SnapCenter, consultare la documentazione all'indirizzo "questo collegamento" .
Aggiungi host a SnapCenter
Il passaggio successivo consiste nell'aggiungere i server applicativi host a SnapCenter. Il processo è simile sia per SQL Server che per Oracle.
-
Dal menu a sinistra, seleziona Host e poi fai clic su Aggiungi per iniziare il processo di aggiunta dei controller di archiviazione a SnapCenter.
-
Nella finestra Aggiungi host, aggiungi il tipo di host, il nome host e le credenziali del sistema host. Seleziona il tipo di plug-in. Per SQL Server, selezionare il plug-in Microsoft Windows e Microsoft SQL Server.
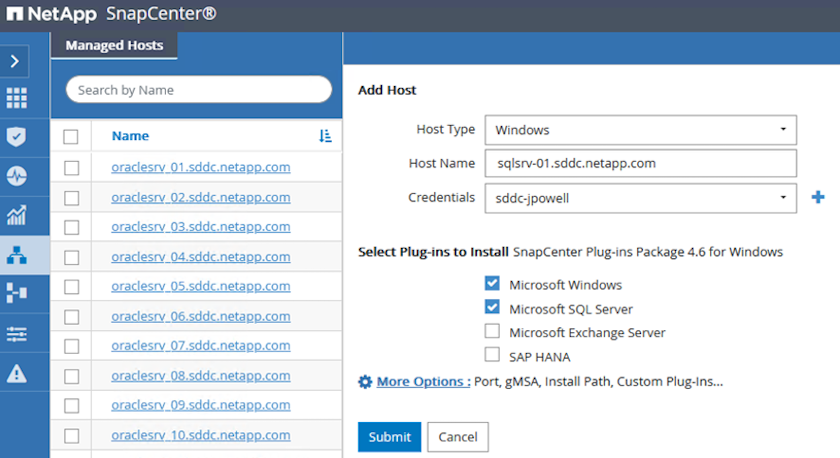
-
Per Oracle, compilare i campi obbligatori nella finestra di dialogo Aggiungi host e selezionare la casella di controllo per il plug-in Oracle Database. Quindi fare clic su Invia per avviare il processo di individuazione e aggiungere l'host a SnapCenter.
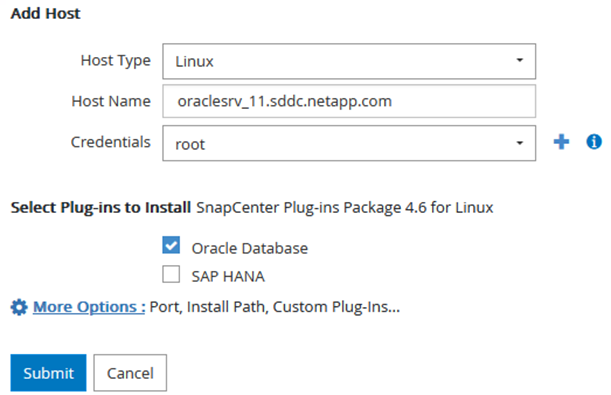
Crea criteri SnapCenter
Le policy stabiliscono le regole specifiche da seguire per un processo di backup. Includono, a titolo esemplificativo ma non esaustivo, la pianificazione del backup, il tipo di replica e il modo in cui SnapCenter gestisce il backup e il troncamento dei registri delle transazioni.
È possibile accedere ai criteri nella sezione Impostazioni del client Web SnapCenter .

Per informazioni complete sulla creazione di criteri per i backup di SQL Server, vedere "Documentazione SnapCenter" .
Per informazioni complete sulla creazione di policy per i backup di Oracle, vedere "Documentazione SnapCenter" .
Note:
-
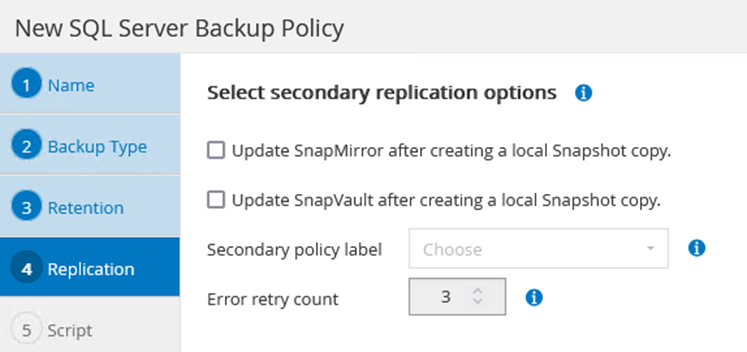
Durante la procedura guidata di creazione dei criteri, prestare particolare attenzione alla sezione Replica. In questa sezione puoi specificare i tipi di copie secondarie SnapMirror che desideri vengano eseguite durante il processo di backup.
-
L'impostazione "Aggiorna SnapMirror dopo aver creato una copia Snapshot locale" si riferisce all'aggiornamento di una relazione SnapMirror quando tale relazione esiste tra due macchine virtuali di archiviazione che risiedono sullo stesso cluster.
-
L'impostazione "Aggiorna SnapVault dopo aver creato una copia SnapShot locale" viene utilizzata per aggiornare una relazione SnapMirror esistente tra due cluster separati e tra un sistema ONTAP locale e Cloud Volumes ONTAP o FSx ONTAP.
L'immagine seguente mostra le opzioni precedenti e il loro aspetto nella procedura guidata dei criteri di backup.
Crea gruppi di risorse SnapCenter
I gruppi di risorse consentono di selezionare le risorse del database che si desidera includere nei backup e i criteri seguiti per tali risorse.
-
Vai alla sezione Risorse nel menu a sinistra.
-
Nella parte superiore della finestra, seleziona il tipo di risorsa con cui lavorare (in questo caso Microsoft SQL Server), quindi fai clic su Nuovo gruppo di risorse.
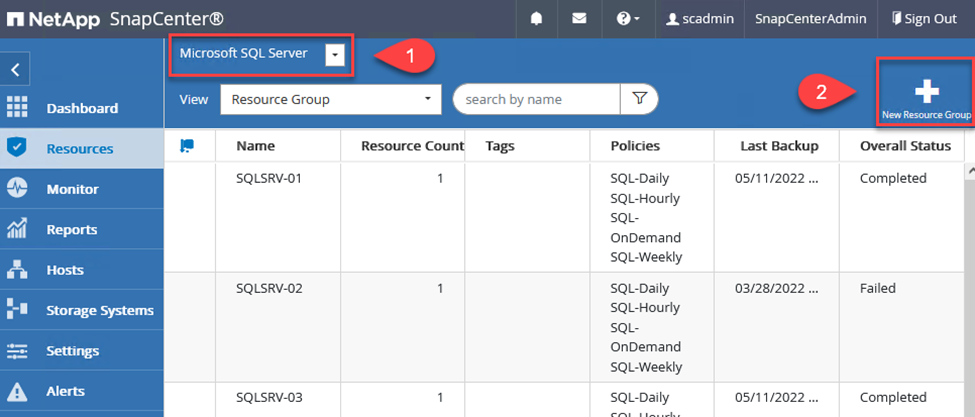
La documentazione SnapCenter illustra dettagliatamente la creazione di gruppi di risorse per i database SQL Server e Oracle.
Per eseguire il backup delle risorse SQL, seguire "questo collegamento" .
Per il backup delle risorse Oracle, seguire "questo collegamento" .
Distribuisci e configura Veeam Backup Server
Nella soluzione viene utilizzato il software Veeam Backup & Replication per eseguire il backup delle macchine virtuali delle nostre applicazioni e archiviare una copia dei backup in un bucket Amazon S3 utilizzando un repository di backup scale-out (SOBR) Veeam. In questa soluzione Veeam è distribuito su un server Windows. Per indicazioni specifiche sulla distribuzione di Veeam, vedere "Centro assistenza Veeam Documentazione tecnica" .
Configurare il repository di backup scalabile Veeam
Dopo aver distribuito e ottenuto la licenza del software, è possibile creare un repository di backup scalabile (SOBR) come archivio di destinazione per i processi di backup. Dovresti anche includere un bucket S3 come backup dei dati della VM fuori sede per il ripristino di emergenza.
Prima di iniziare, consultare i seguenti prerequisiti.
-
Crea una condivisione file SMB sul tuo sistema ONTAP locale come archivio di destinazione per i backup.
-
Creare un bucket Amazon S3 da includere nel SOBR. Questo è un repository per i backup fuori sede.
Aggiungi ONTAP Storage a Veeam
Per prima cosa, aggiungi il cluster di storage ONTAP e il file system SMB/NFS associato come infrastruttura di storage in Veeam.
-
Apri la console Veeam ed effettua l'accesso. Vai su Infrastruttura di storage e seleziona Aggiungi storage.
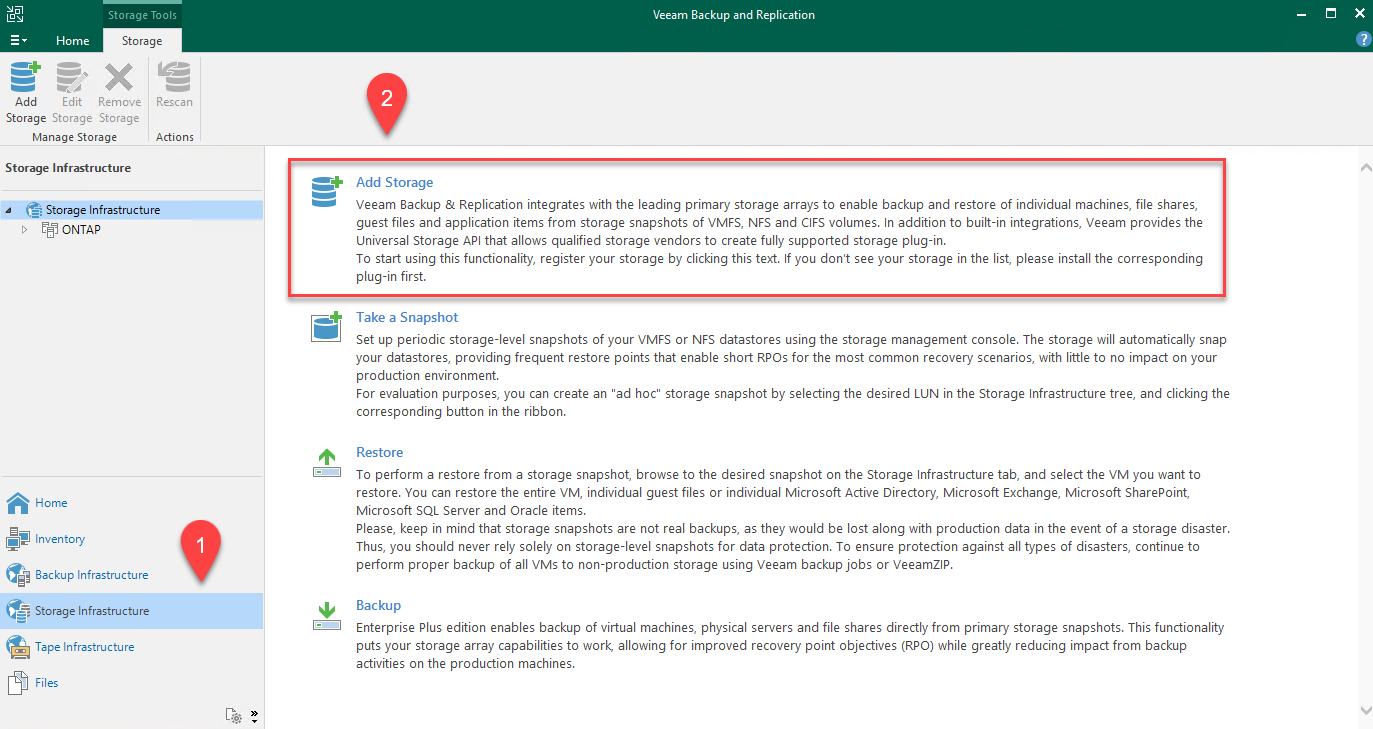
-
Nella procedura guidata Aggiungi storage, seleziona NetApp come fornitore di storage, quindi seleziona Data ONTAP.
-
Immettere l'indirizzo IP di gestione e selezionare la casella NAS Filer. Fare clic su Avanti.
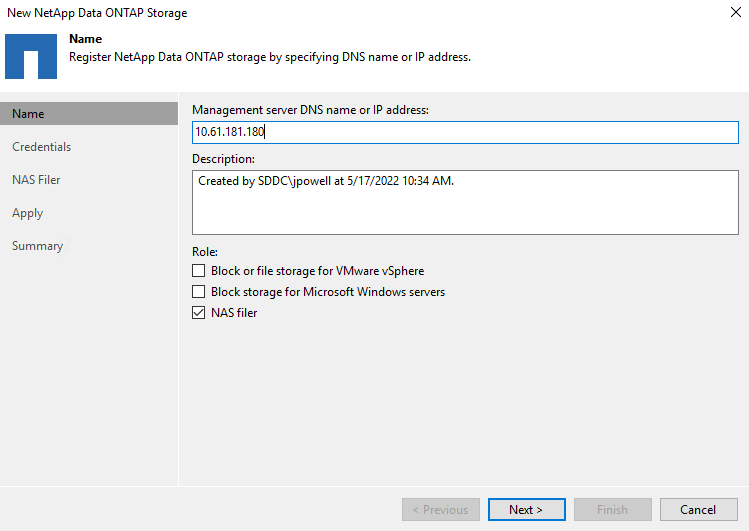
-
Aggiungi le tue credenziali per accedere al cluster ONTAP .
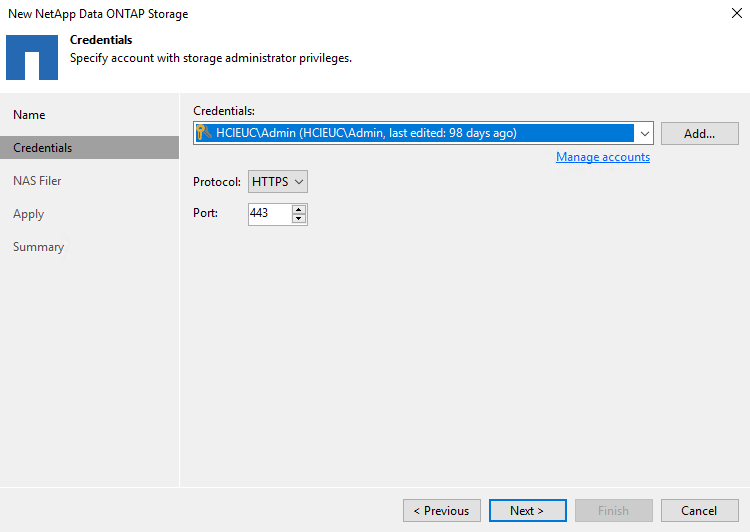
-
Nella pagina NAS Filer, selezionare i protocolli desiderati da analizzare e selezionare Avanti.

-
Completare le pagine Applica e Riepilogo della procedura guidata e fare clic su Fine per avviare il processo di individuazione dell'archiviazione. Una volta completata la scansione, il cluster ONTAP viene aggiunto insieme ai filer NAS come risorse disponibili.

-
Creare un repository di backup utilizzando le condivisioni NAS appena scoperte. Da Backup Infrastructure, seleziona Backup Repository e fai clic sulla voce di menu Aggiungi repository.

-
Seguire tutti i passaggi della procedura guidata Nuovo repository di backup per creare il repository. Per informazioni dettagliate sulla creazione di repository di backup Veeam, vedere "Documentazione Veeam" .
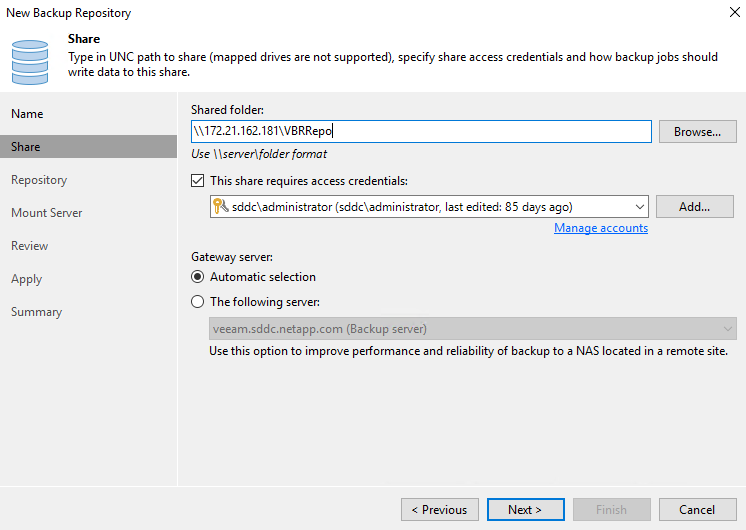
Aggiungi il bucket Amazon S3 come repository di backup
Il passaggio successivo consiste nell'aggiungere lo storage Amazon S3 come repository di backup.
-
Passare a Infrastruttura di backup > Repository di backup. Fare clic su Aggiungi repository.
-
Nella procedura guidata Aggiungi repository di backup, seleziona Object Storage e quindi Amazon S3. Verrà avviata la procedura guidata Nuovo repository di archiviazione oggetti.

-
Specifica un nome per il repository di archiviazione degli oggetti e fai clic su Avanti.
-
Nella sezione successiva, fornisci le tue credenziali. Sono necessarie una chiave di accesso AWS e una chiave segreta.
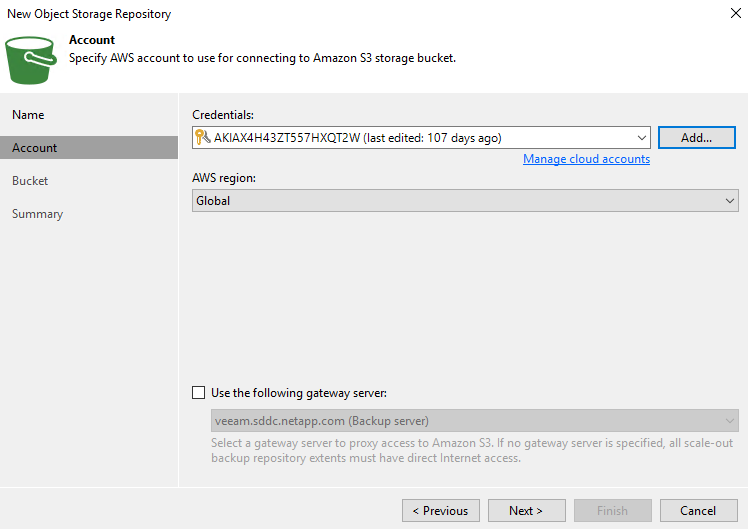
-
Dopo aver caricato la configurazione di Amazon, seleziona il data center, il bucket e la cartella e fai clic su Applica. Infine, fare clic su Fine per chiudere la procedura guidata.
Crea un repository di backup scalabile
Ora che abbiamo aggiunto i nostri repository di storage a Veeam, possiamo creare l'SOBR per suddividere automaticamente le copie di backup nel nostro storage di oggetti Amazon S3 offsite per il disaster recovery.
-
Da Backup Infrastructure, seleziona Scale-out Repositories e quindi fai clic sulla voce di menu Aggiungi Scale-out Repository.
-
Nel Nuovo repository di backup scalabile, immettere un nome per SOBR e fare clic su Avanti.
-
Per il livello di prestazioni, seleziona il repository di backup che contiene la condivisione SMB residente sul tuo cluster ONTAP locale.
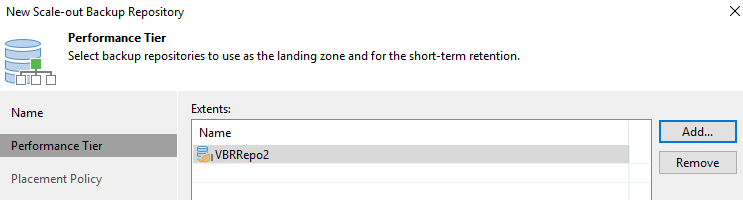
-
Per la politica di posizionamento, scegli Località dei dati o Prestazioni in base alle tue esigenze. Seleziona Avanti.
-
Per Capacity Tier estendiamo SOBR con l'archiviazione di oggetti Amazon S3. Ai fini del ripristino di emergenza, selezionare Copia backup in Object Storage non appena vengono creati per garantire la consegna tempestiva dei nostri backup secondari.
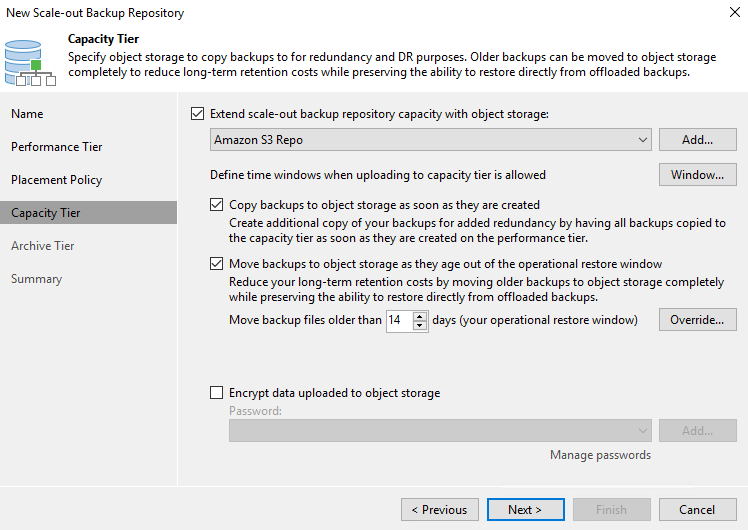
-
Infine, seleziona Applica e Fine per finalizzare la creazione del SOBR.
Creare i processi di repository di backup scalabili
Il passaggio finale per configurare Veeam consiste nel creare processi di backup utilizzando il SOBR appena creato come destinazione di backup. La creazione di processi di backup è una normale attività del repertorio di qualsiasi amministratore di storage e in questa sede non verranno illustrati i passaggi dettagliati. Per informazioni più complete sulla creazione di processi di backup in Veeam, vedere "Documentazione tecnica del Centro assistenza Veeam" .
Strumenti e configurazione BlueXP backup and recovery
Per eseguire un failover delle VM delle applicazioni e dei volumi del database sui servizi VMware Cloud Volume in esecuzione su AWS, è necessario installare e configurare un'istanza in esecuzione sia di SnapCenter Server che di Veeam Backup and Replication Server. Una volta completato il failover, è necessario configurare questi strumenti anche per riprendere le normali operazioni di backup finché non viene pianificato ed eseguito un failback nel data center locale.
Distribuisci il server Windows SnapCenter secondario
SnapCenter Server viene distribuito nel VMware Cloud SDDC o installato su un'istanza EC2 residente in una VPC con connettività di rete all'ambiente VMware Cloud.
Il SnapCenter software è disponibile sul sito di supporto NetApp e può essere installato sui sistemi Microsoft Windows che risiedono in un dominio o in un gruppo di lavoro. Una guida dettagliata alla pianificazione e alle istruzioni di installazione sono disponibili sul sito "Centro di documentazione NetApp" .
Puoi trovare il SnapCenter software su "questo collegamento" .
Configurare il server secondario Windows SnapCenter
Per eseguire un ripristino dei dati dell'applicazione sottoposti a mirroring su FSx ONTAP, è necessario prima eseguire un ripristino completo del database SnapCenter locale. Una volta completato questo processo, la comunicazione con le VM viene ristabilita e i backup delle applicazioni possono ora riprendere utilizzando FSx ONTAP come storage primario.
Per raggiungere questo obiettivo, è necessario completare le seguenti operazioni sul server SnapCenter :
-
Configurare il nome del computer in modo che sia identico al server SnapCenter locale originale.
-
Configurare la rete per comunicare con VMware Cloud e l'istanza FSx ONTAP .
-
Completare la procedura per ripristinare il database SnapCenter .
-
Verificare che SnapCenter sia in modalità Disaster Recovery per assicurarsi che FSx sia ora l'archivio primario per i backup.
-
Verificare che la comunicazione con le macchine virtuali ripristinate sia stata ristabilita.
Distribuisci il server Veeam Backup & Replication secondario
È possibile installare il server Veeam Backup & Replication su un server Windows nel VMware Cloud su AWS o su un'istanza EC2. Per una guida dettagliata all'implementazione, vedere "Documentazione tecnica del Centro assistenza Veeam" .
Configurare il server Veeam Backup & Replication secondario
Per eseguire un ripristino di macchine virtuali di cui è stato eseguito il backup nello storage Amazon S3, è necessario installare Veeam Server su un server Windows e configurarlo per comunicare con VMware Cloud, FSx ONTAP e il bucket S3 che contiene il repository di backup originale. Deve inoltre disporre di un nuovo repository di backup configurato su FSx ONTAP per eseguire nuovi backup delle VM dopo il loro ripristino.
Per eseguire questo processo, è necessario completare i seguenti elementi:
-
Configurare la rete per comunicare con VMware Cloud, FSx ONTAP e il bucket S3 contenente il repository di backup originale.
-
Configurare una condivisione SMB su FSx ONTAP come nuovo repository di backup.
-
Montare il bucket S3 originale utilizzato come parte del repository di backup scalabile in locale.
-
Dopo aver ripristinato la VM, stabilire nuovi processi di backup per proteggere le VM SQL e Oracle.
Per ulteriori informazioni sul ripristino delle VM tramite Veeam, consultare la sezione"Ripristina le VM delle applicazioni con Veeam Full Restore" .
Backup del database SnapCenter per il ripristino di emergenza
SnapCenter consente il backup e il ripristino del database MySQL sottostante e dei dati di configurazione allo scopo di ripristinare il server SnapCenter in caso di disastro. Per la nostra soluzione, abbiamo recuperato il database e la configurazione SnapCenter su un'istanza AWS EC2 residente nella nostra VPC. Per ulteriori informazioni sul ripristino di emergenza di SnapCenter, vedere "questo collegamento" .
Prerequisiti per il backup SnapCenter
Per il backup SnapCenter sono richiesti i seguenti prerequisiti:
-
Un volume e una condivisione SMB creati sul sistema ONTAP locale per individuare il database sottoposto a backup e i file di configurazione.
-
Una relazione SnapMirror tra il sistema ONTAP locale e FSx o CVO nell'account AWS. Questa relazione viene utilizzata per trasportare lo snapshot contenente il database SnapCenter sottoposto a backup e i file di configurazione.
-
Windows Server installato nell'account cloud, su un'istanza EC2 o su una macchina virtuale nel VMware Cloud SDDC.
-
SnapCenter installato sull'istanza Windows EC2 o sulla VM in VMware Cloud.
Riepilogo del processo di backup e ripristino SnapCenter
-
Creare un volume sul sistema ONTAP locale per ospitare il database di backup e i file di configurazione.
-
Impostare una relazione SnapMirror tra locale e FSx/CVO.
-
Montare la condivisione SMB.
-
Recupera il token di autorizzazione Swagger per eseguire attività API.
-
Avviare il processo di ripristino del database.
-
Utilizzare l'utilità xcopy per copiare la directory locale del database e del file di configurazione nella condivisione SMB.
-
Su FSx, creare un clone del volume ONTAP (copiato tramite SnapMirror da locale).
-
Montare la condivisione SMB da FSx a EC2/VMware Cloud.
-
Copiare la directory di ripristino dalla condivisione SMB a una directory locale.
-
Eseguire il processo di ripristino di SQL Server da Swagger.
Eseguire il backup del database e della configurazione SnapCenter
SnapCenter fornisce un'interfaccia client Web per l'esecuzione dei comandi REST API. Per informazioni sull'accesso alle API REST tramite Swagger, consultare la documentazione SnapCenter all'indirizzo "questo collegamento" .
Accedi a Swagger e ottieni il token di autorizzazione
Dopo aver navigato fino alla pagina Swagger, è necessario recuperare un token di autorizzazione per avviare il processo di ripristino del database.
-
Accedi alla pagina web dell'API SnapCenter Swagger all'indirizzo https://< SnapCenter Server IP>:8146/swagger/.
-
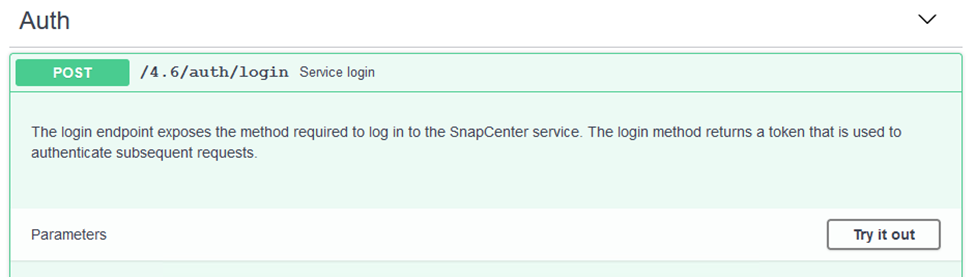
Espandi la sezione Autenticazione e fai clic su Provalo.
-
Nell'area UserOperationContext, compilare le credenziali e il ruolo SnapCenter e fare clic su Esegui.
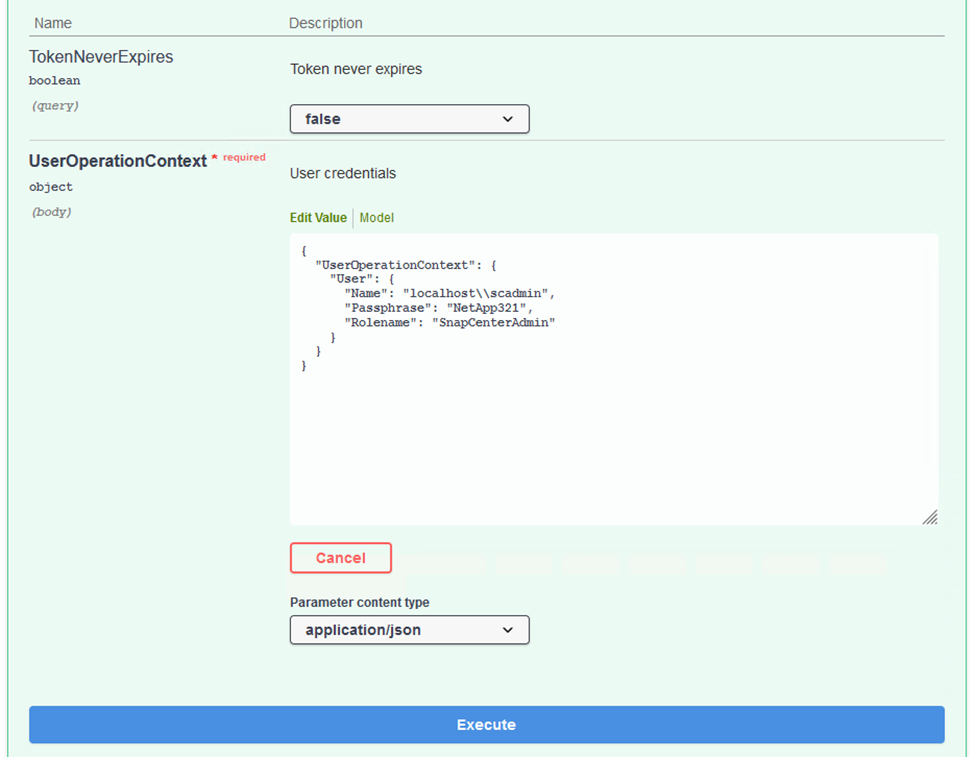
-
Nel corpo della risposta qui sotto puoi vedere il token. Copiare il testo del token per l'autenticazione durante l'esecuzione del processo di backup.
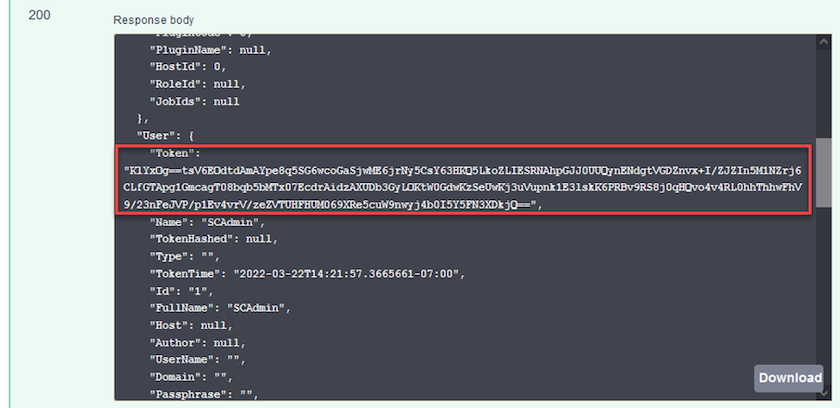
Eseguire un backup del database SnapCenter
Successivamente, vai all'area Disaster Recovery nella pagina Swagger per avviare il processo di backup SnapCenter .
-
Espandi l'area Disaster Recovery cliccandoci sopra.
-
Espandi il
/4.6/disasterrecovery/server/backupsezione e clicca su Provalo.
-
Nella sezione SmDRBackupRequest, aggiungere il percorso di destinazione locale corretto e selezionare Esegui per avviare il backup del database e della configurazione SnapCenter .
Il processo di backup non consente di eseguire il backup direttamente su una condivisione file NFS o CIFS. 
Monitorare il processo di backup da SnapCenter
Accedi a SnapCenter per rivedere i file di registro quando avvii il processo di ripristino del database. Nella sezione Monitor è possibile visualizzare i dettagli del backup di ripristino di emergenza del server SnapCenter .
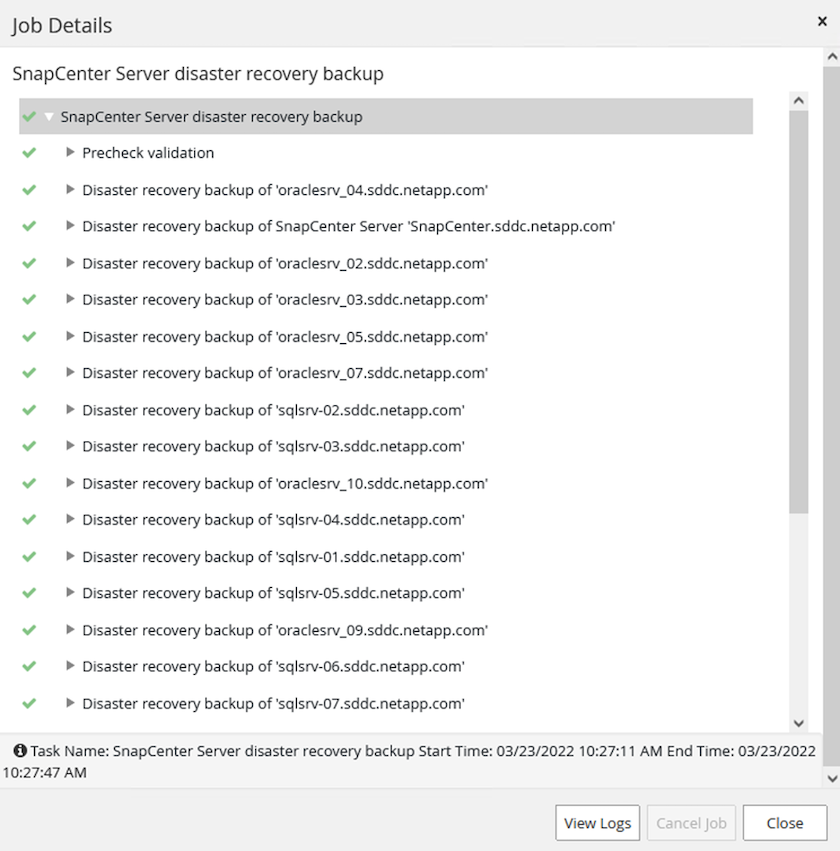
Utilizzare l'utilità XCOPY per copiare il file di backup del database nella condivisione SMB
Successivamente è necessario spostare il backup dall'unità locale sul server SnapCenter alla condivisione CIFS utilizzata per copiare i dati SnapMirror nella posizione secondaria situata sull'istanza FSx in AWS. Utilizzare xcopy con opzioni specifiche che mantengano le autorizzazioni dei file.
Aprire un prompt dei comandi come amministratore. Dal prompt dei comandi, immettere i seguenti comandi:
xcopy <Source_Path> \\<Destination_Server_IP>\<Folder_Path> /O /X /E /H /K xcopy c:\SC_Backups\SnapCenter_DR \\10.61.181.185\snapcenter_dr /O /X /E /H /K
Failover
Il disastro si verifica nel sito primario
In caso di disastro che si verifica nel data center principale in sede, il nostro scenario prevede il failover su un sito secondario residente sull'infrastruttura Amazon Web Services tramite VMware Cloud su AWS. Supponiamo che le macchine virtuali e il nostro cluster ONTAP locale non siano più accessibili. Inoltre, le macchine virtuali SnapCenter e Veeam non sono più accessibili e devono essere ricostruite presso il nostro sito secondario.
Questa sezione affronta il failover della nostra infrastruttura sul cloud e tratta i seguenti argomenti:
-
Ripristino del database SnapCenter . Dopo aver stabilito un nuovo server SnapCenter , ripristinare il database MySQL e i file di configurazione e attivare la modalità di ripristino di emergenza del database per consentire allo storage FSx secondario di diventare il dispositivo di storage primario.
-
Ripristinare le macchine virtuali dell'applicazione utilizzando Veeam Backup & Replication. Collegare l'archiviazione S3 che contiene i backup delle VM, importare i backup e ripristinarli su VMware Cloud su AWS.
-
Ripristinare i dati dell'applicazione SQL Server utilizzando SnapCenter.
-
Ripristinare i dati dell'applicazione Oracle utilizzando SnapCenter.
Processo di ripristino del database SnapCenter
SnapCenter supporta scenari di disaster recovery consentendo il backup e il ripristino del suo database MySQL e dei file di configurazione. Ciò consente a un amministratore di mantenere backup regolari del database SnapCenter nel data center locale e di ripristinare successivamente tale database in un database SnapCenter secondario.
Per accedere ai file di backup SnapCenter sul server SnapCenter remoto, completare i seguenti passaggi:
-
Interrompere la relazione SnapMirror dal cluster FSx, rendendo il volume di lettura/scrittura.
-
Creare un server CIFS (se necessario) e creare una condivisione CIFS che punti al percorso di giunzione del volume clonato.
-
Utilizzare xcopy per copiare i file di backup in una directory locale sul sistema SnapCenter secondario.
-
Installa SnapCenter v4.6.
-
Assicurarsi che il server SnapCenter abbia lo stesso FQDN del server originale. Ciò è necessario affinché il ripristino del database abbia esito positivo.
Per avviare il processo di ripristino, completare i seguenti passaggi:
-
Accedere alla pagina web dell'API Swagger per il server SnapCenter secondario e seguire le istruzioni precedenti per ottenere un token di autorizzazione.
-
Vai alla sezione Disaster Recovery della pagina Swagger, seleziona
/4.6/disasterrecovery/server/restoree fai clic su Provalo.
-
Incolla il token di autorizzazione e, nella sezione SmDRResterRequest, incolla il nome del backup e la directory locale sul server SnapCenter secondario.
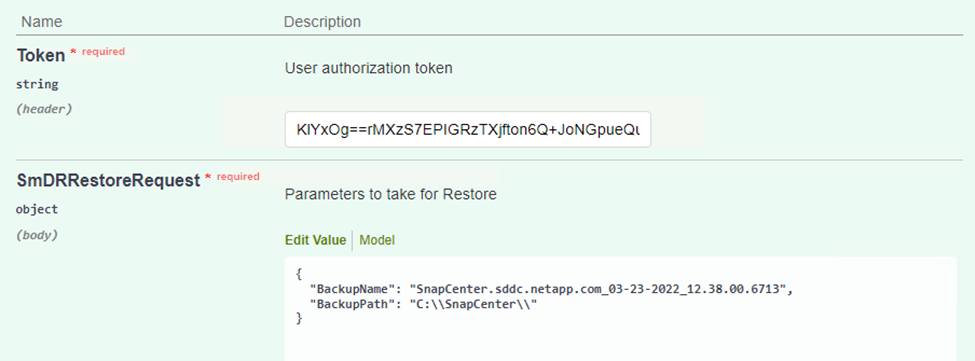
-
Selezionare il pulsante Esegui per avviare il processo di ripristino.
-
Da SnapCenter, vai alla sezione Monitor per visualizzare l'avanzamento del processo di ripristino.

-
Per abilitare i ripristini di SQL Server dall'archiviazione secondaria, è necessario impostare il database SnapCenter in modalità Disaster Recovery. Questa operazione viene eseguita separatamente e avviata sulla pagina web dell'API Swagger.
-
Passare alla sezione Disaster Recovery e fare clic su
/4.6/disasterrecovery/storage. -
Incolla il token di autorizzazione dell'utente.
-
Nella sezione SmSetDisasterRecoverySettingsRequest, modificare
EnableDisasterRecoverAtrue. -
Fare clic su Esegui per abilitare la modalità di ripristino di emergenza per SQL Server.
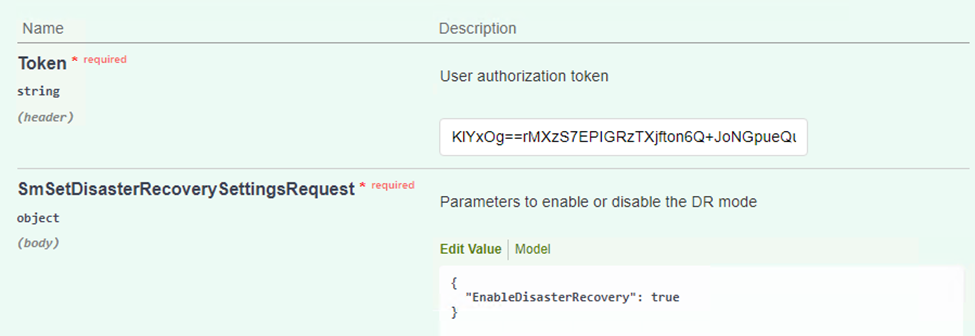
Vedere i commenti relativi alle procedure aggiuntive. -
Ripristina le VM delle applicazioni con il ripristino completo di Veeam
Crea un repository di backup e importa i backup da S3
Dal server Veeam secondario, importa i backup dallo storage S3 e ripristina le VM SQL Server e Oracle nel tuo cluster VMware Cloud.
Per importare i backup dall'oggetto S3 che faceva parte del repository di backup scalabile in locale, completare i seguenti passaggi:
-
Vai a Backup Repositories e fai clic su Aggiungi repository nel menu in alto per avviare la procedura guidata Aggiungi repository di backup. Nella prima pagina della procedura guidata, seleziona Object Storage come tipo di repository di backup.

-
Selezionare Amazon S3 come tipo di Object Storage.

-
Dall'elenco dei servizi di archiviazione cloud Amazon, seleziona Amazon S3.

-
Seleziona le credenziali pre-immesse dall'elenco a discesa oppure aggiungi una nuova credenziale per accedere alla risorsa di archiviazione cloud. Fare clic su Avanti per continuare.

-
Nella pagina Bucket, inserisci il data center, il bucket, la cartella e tutte le opzioni desiderate. Fare clic su Applica.
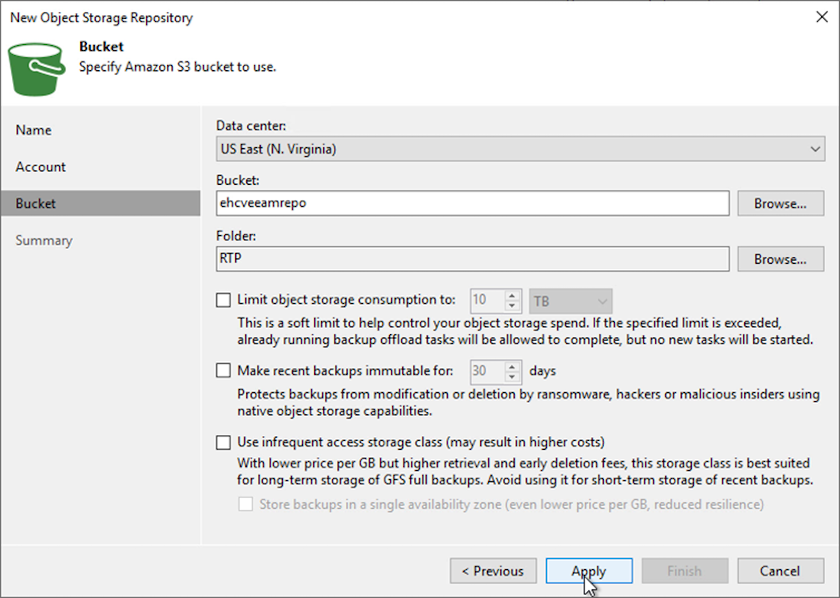
-
Infine, seleziona Fine per completare il processo e aggiungere il repository.
Importa backup dall'archiviazione di oggetti S3
Per importare i backup dal repository S3 aggiunto nella sezione precedente, completare i passaggi seguenti.
-
Dal repository di backup S3, seleziona Importa backup per avviare la procedura guidata Importa backup.

-
Dopo aver creato i record del database per l'importazione, selezionare Avanti e poi Fine nella schermata di riepilogo per avviare il processo di importazione.
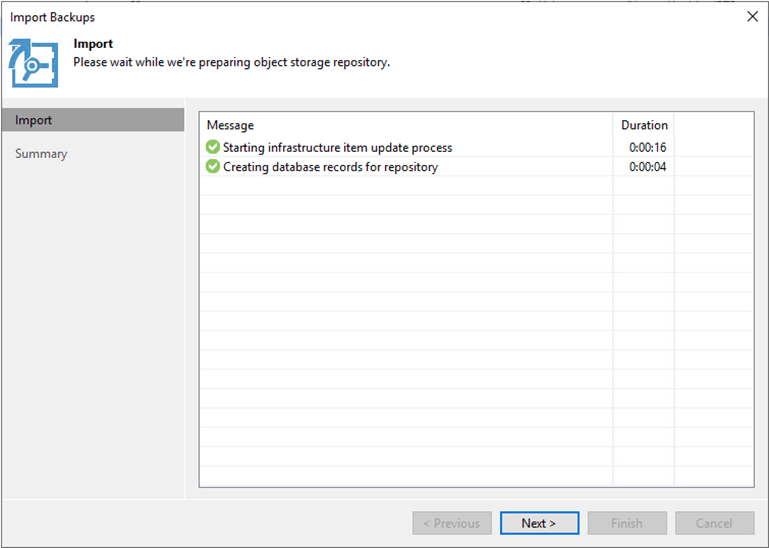
-
Una volta completata l'importazione, è possibile ripristinare le VM nel cluster VMware Cloud.
Ripristina le VM delle applicazioni con il ripristino completo di Veeam su VMware Cloud
Per ripristinare le macchine virtuali SQL e Oracle nel dominio/cluster del carico di lavoro VMware Cloud on AWS, completare i seguenti passaggi.
-
Dalla home page di Veeam, seleziona l'archivio oggetti contenente i backup importati, seleziona le VM da ripristinare, quindi fai clic con il pulsante destro del mouse e seleziona Ripristina intera VM.
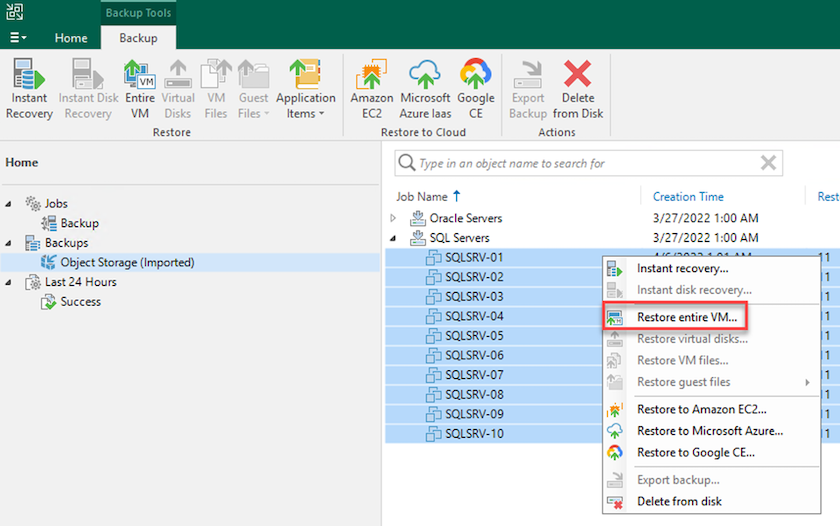
-
Nella prima pagina della procedura guidata Ripristino completo della VM, modificare le VM da sottoporre a backup, se desiderato, e selezionare Avanti.
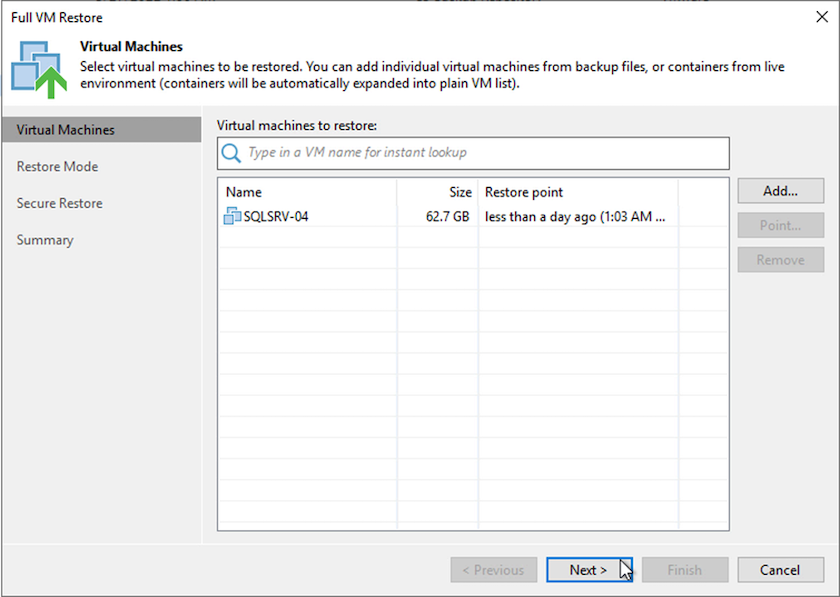
-
Nella pagina Modalità di ripristino, seleziona Ripristina in una nuova posizione o con impostazioni diverse.
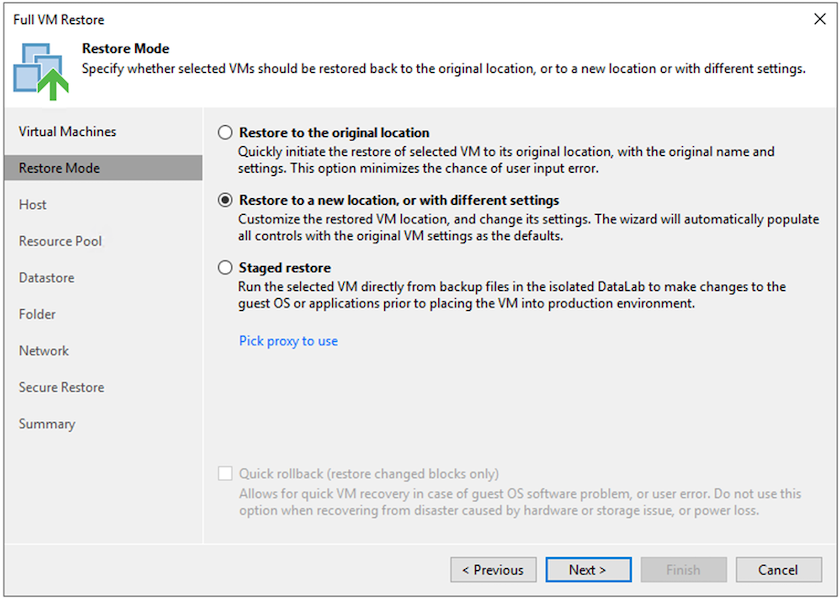
-
Nella pagina host, seleziona l'host o il cluster ESXi di destinazione su cui ripristinare la VM.
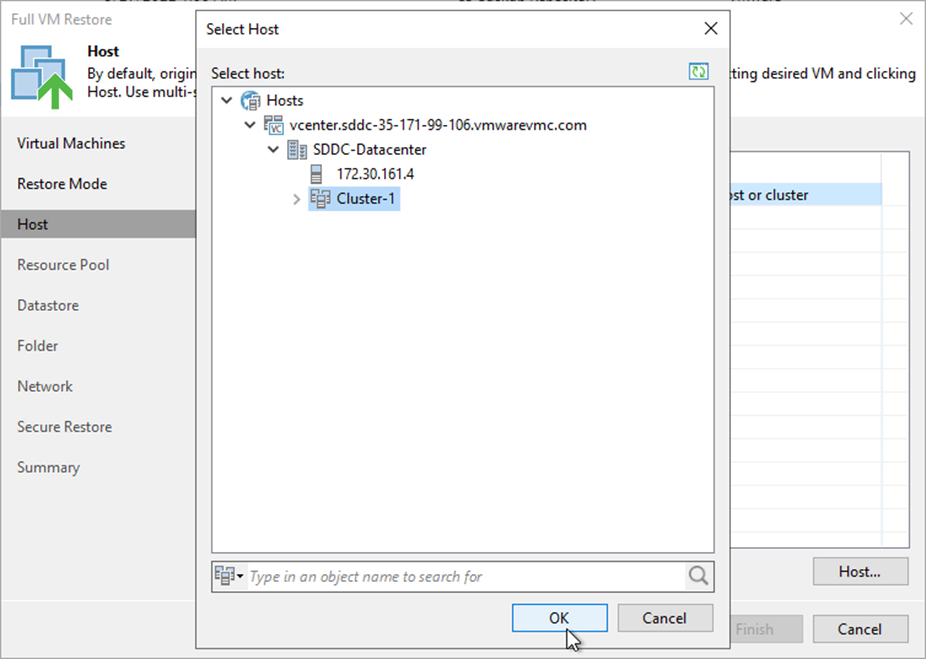
-
Nella pagina Datastore, selezionare la posizione del datastore di destinazione sia per i file di configurazione che per il disco rigido.

-
Nella pagina Rete, mappare le reti originali sulla VM alle reti nella nuova posizione di destinazione.
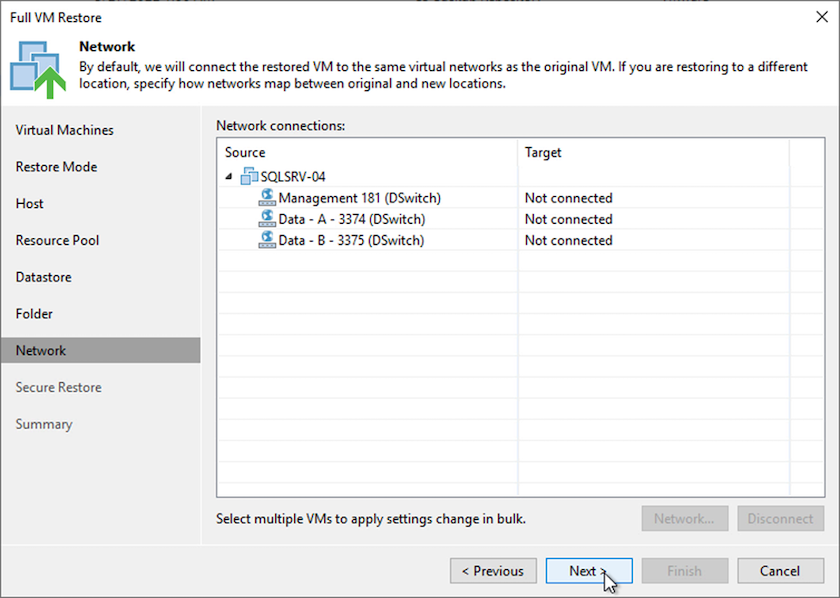
-
Selezionare se eseguire la scansione della VM ripristinata per rilevare eventuali malware, rivedere la pagina di riepilogo e fare clic su Fine per avviare il ripristino.
Ripristinare i dati dell'applicazione SQL Server
La seguente procedura fornisce istruzioni su come ripristinare un SQL Server in VMware Cloud Services in AWS in caso di un disastro che renda inutilizzabile il sito locale.
Per poter proseguire con le fasi di ripristino si presuppone che siano soddisfatti i seguenti prerequisiti:
-
La VM Windows Server è stata ripristinata su VMware Cloud SDDC tramite Veeam Full Restore.
-
È stato stabilito un server SnapCenter secondario e il ripristino e la configurazione del database SnapCenter sono stati completati utilizzando i passaggi descritti nella sezione"Riepilogo del processo di backup e ripristino SnapCenter ."
VM: configurazione post-ripristino per VM SQL Server
Una volta completato il ripristino della VM, è necessario configurare la rete e altri elementi in preparazione per il nuovo rilevamento della VM host in SnapCenter.
-
Assegnare nuovi indirizzi IP per la gestione e iSCSI o NFS.
-
Aggiungere l'host al dominio Windows.
-
Aggiungere i nomi host al DNS o al file hosts sul server SnapCenter .
|
|
Se il plug-in SnapCenter è stato distribuito utilizzando credenziali di dominio diverse da quelle del dominio corrente, è necessario modificare l'account di accesso per il plug-in per il servizio Windows sulla macchina virtuale di SQL Server. Dopo aver modificato l'account di accesso, riavviare i servizi SnapCenter SMCore, Plug-in per Windows e Plug-in per SQL Server. |
|
|
Per riscoprire automaticamente le VM ripristinate in SnapCenter, il nome di dominio completo (FQDN) deve essere identico alla VM originariamente aggiunta a SnapCenter in locale. |
Configurare l'archiviazione FSx per il ripristino di SQL Server
Per completare il processo di ripristino di emergenza per una macchina virtuale di SQL Server, è necessario interrompere la relazione SnapMirror esistente dal cluster FSx e concedere l'accesso al volume. Per farlo, completa i seguenti passaggi.
-
Per interrompere la relazione SnapMirror esistente per il database di SQL Server e i volumi di registro, eseguire il seguente comando dalla CLI di FSx:
FSx-Dest::> snapmirror break -destination-path DestSVM:DestVolName
-
Concedi l'accesso al LUN creando un gruppo di iniziatori contenente l'IQN iSCSI della VM Windows di SQL Server:
FSx-Dest::> igroup create -vserver DestSVM -igroup igroupName -protocol iSCSI -ostype windows -initiator IQN
-
Infine, mappa i LUN al gruppo di iniziatori appena creato:
FSx-Dest::> lun mapping create -vserver DestSVM -path LUNPath igroup igroupName
-
Per trovare il nome del percorso, eseguire il comando
lun showcomando.
Configurare la VM Windows per l'accesso iSCSI e scoprire i file system
-
Dalla VM di SQL Server, configura la scheda di rete iSCSI per comunicare sul gruppo di porte VMware stabilito con connettività alle interfacce di destinazione iSCSI sulla tua istanza FSx.
-
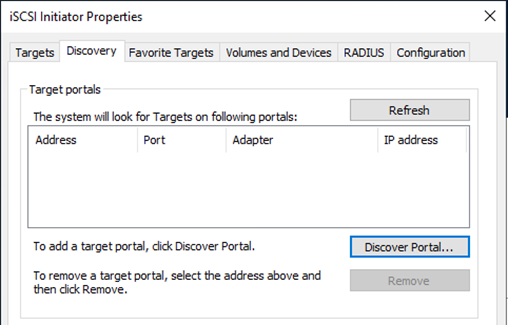
Aprire l'utilità Proprietà dell'iniziatore iSCSI e cancellare le vecchie impostazioni di connettività nelle schede Rilevamento, Destinazioni preferite e Destinazioni.
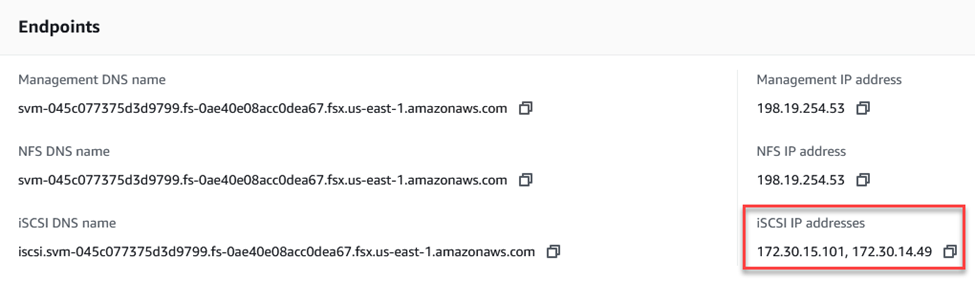
-
Individuare l'indirizzo/gli indirizzi IP per accedere all'interfaccia logica iSCSI sull'istanza/cluster FSx. Questa opzione è disponibile nella console AWS in Amazon FSx > ONTAP > Storage Virtual Machines.
-
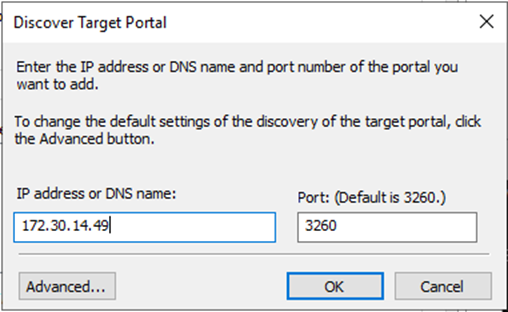
Dalla scheda Discovery, fare clic su Discover Portal e immettere gli indirizzi IP per le destinazioni iSCSI FSx.
-
Nella scheda Destinazione, fare clic su Connetti, selezionare Abilita multipercorso se appropriato per la configurazione, quindi fare clic su OK per connettersi alla destinazione.
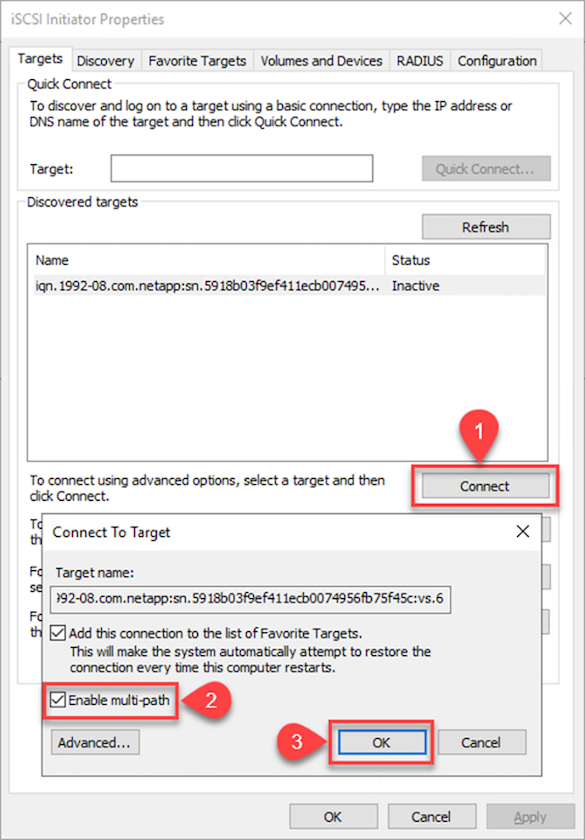
-
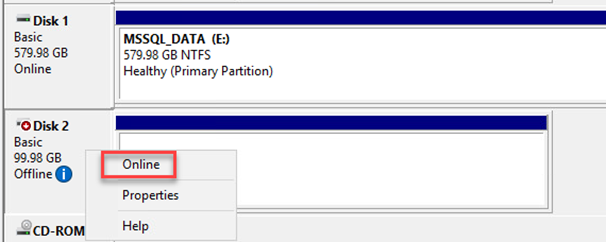
Aprire l'utilità Gestione computer e portare i dischi online. Verificare che mantengano le stesse lettere di unità assegnate in precedenza.
Collegare i database di SQL Server
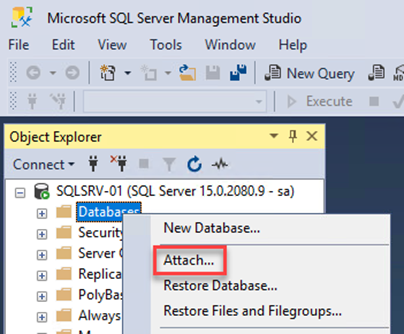
-
Dalla VM di SQL Server, aprire Microsoft SQL Server Management Studio e selezionare Collega per avviare il processo di connessione al database.
-
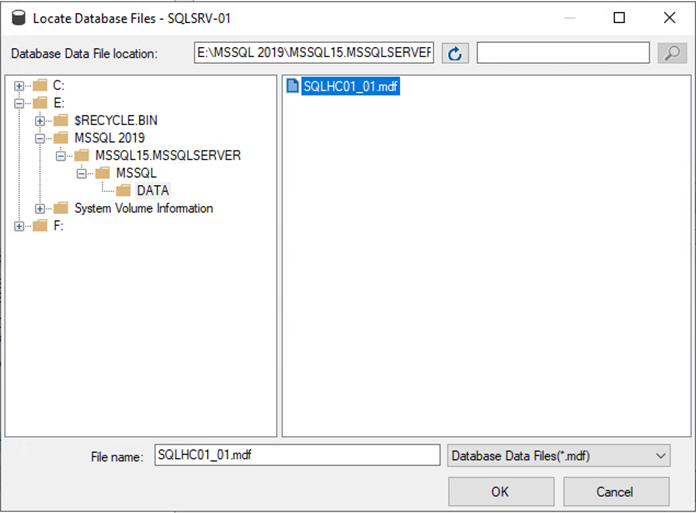
Fare clic su Aggiungi e andare alla cartella contenente il file del database primario di SQL Server, selezionarlo e fare clic su OK.
-
Se i registri delle transazioni si trovano su un'unità separata, selezionare la cartella che contiene il registro delle transazioni.
-
Al termine, fare clic su OK per allegare il database.
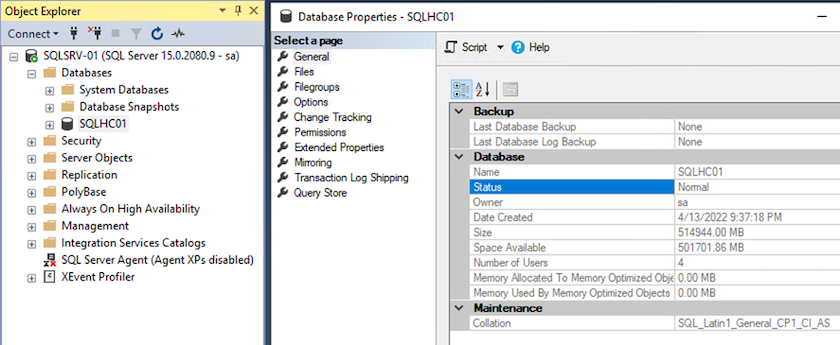
Conferma la comunicazione SnapCenter con il plug-in di SQL Server
Una volta ripristinato lo stato precedente del database SnapCenter , gli host di SQL Server vengono automaticamente rilevati. Per far funzionare tutto correttamente, tieni presente i seguenti prerequisiti:
-
SnapCenter deve essere impostato in modalità Disaster Recover. Questa operazione può essere eseguita tramite l'API Swagger o nelle Impostazioni globali in Disaster Recovery.
-
Il nome di dominio completo (FQDN) di SQL Server deve essere identico all'istanza in esecuzione nel data center locale.
-
La relazione SnapMirror originale deve essere interrotta.
-
I LUN contenenti il database devono essere montati sull'istanza di SQL Server e il database deve essere collegato.
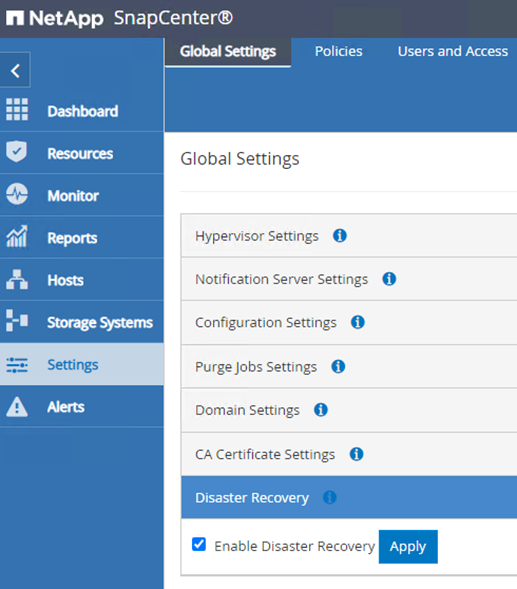
Per confermare che SnapCenter è in modalità Disaster Recovery, accedere a Impostazioni dal client Web SnapCenter . Vai alla scheda Impostazioni globali e poi fai clic su Ripristino di emergenza. Assicurarsi che la casella di controllo Abilita ripristino di emergenza sia abilitata.
Ripristinare i dati dell'applicazione Oracle
La seguente procedura fornisce istruzioni su come ripristinare i dati delle applicazioni Oracle in VMware Cloud Services in AWS in caso di un disastro che renda inutilizzabile il sito locale.
Per proseguire con i passaggi di ripristino, è necessario soddisfare i seguenti prerequisiti:
-
La VM del server Oracle Linux è stata ripristinata su VMware Cloud SDDC utilizzando Veeam Full Restore.
-
È stato stabilito un server SnapCenter secondario e il database SnapCenter e i file di configurazione sono stati ripristinati utilizzando i passaggi descritti in questa sezione"Riepilogo del processo di backup e ripristino SnapCenter ."
Configurare FSx per il ripristino di Oracle: interrompere la relazione SnapMirror
Per rendere accessibili ai server Oracle i volumi di archiviazione secondari ospitati sull'istanza FSx ONTAP , è necessario prima interrompere la relazione SnapMirror esistente.
-
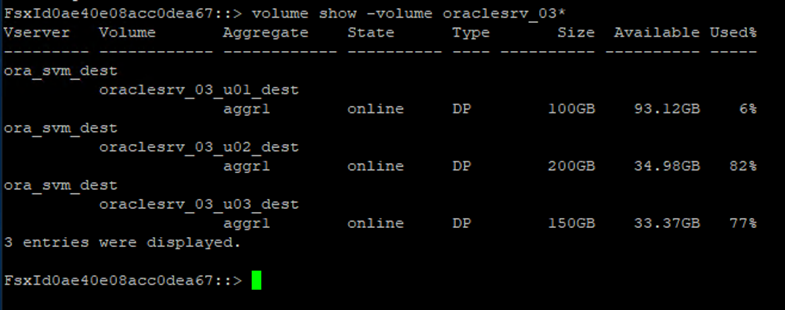
Dopo aver effettuato l'accesso alla CLI di FSx, eseguire il comando seguente per visualizzare i volumi filtrati in base al nome corretto.
FSx-Dest::> volume show -volume VolumeName*
-
Eseguire il comando seguente per interrompere le relazioni SnapMirror esistenti.
FSx-Dest::> snapmirror break -destination-path DestSVM:DestVolName

-
Aggiorna il percorso di giunzione nel client Web Amazon FSx :
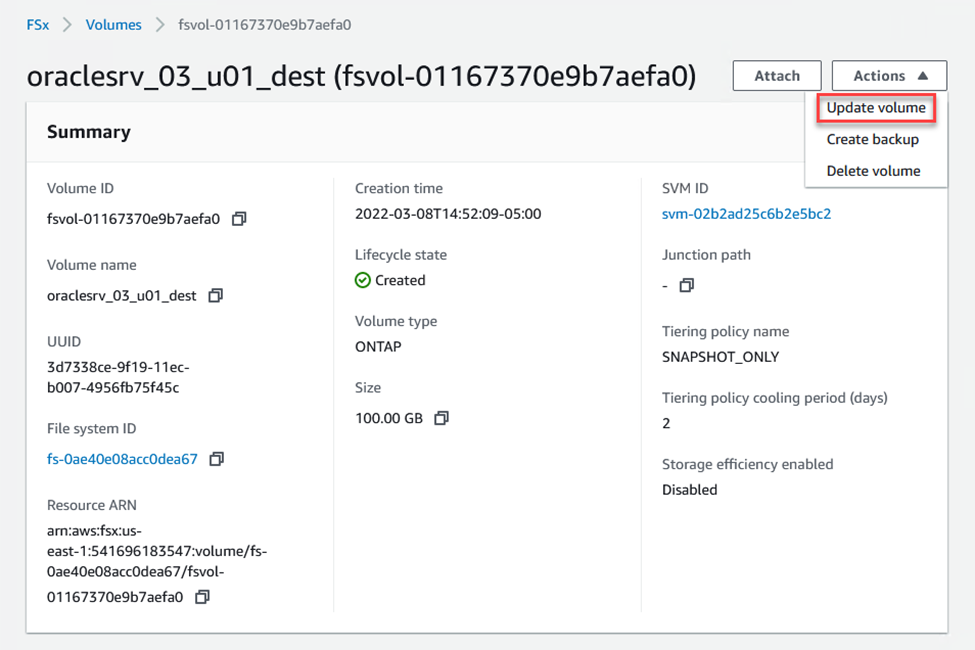
-
Aggiungere il nome del percorso di giunzione e fare clic su Aggiorna. Specificare questo percorso di giunzione quando si monta il volume NFS dal server Oracle.
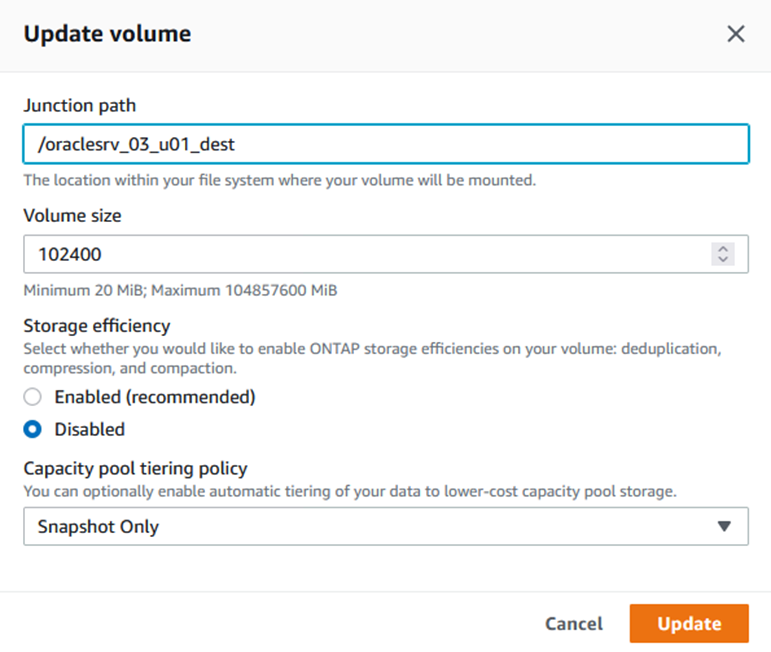
Montare volumi NFS su Oracle Server
In Cloud Manager, è possibile ottenere il comando mount con l'indirizzo IP LIF NFS corretto per montare i volumi NFS che contengono i file e i log del database Oracle.
-
In Cloud Manager, accedi all'elenco dei volumi per il tuo cluster FSx.
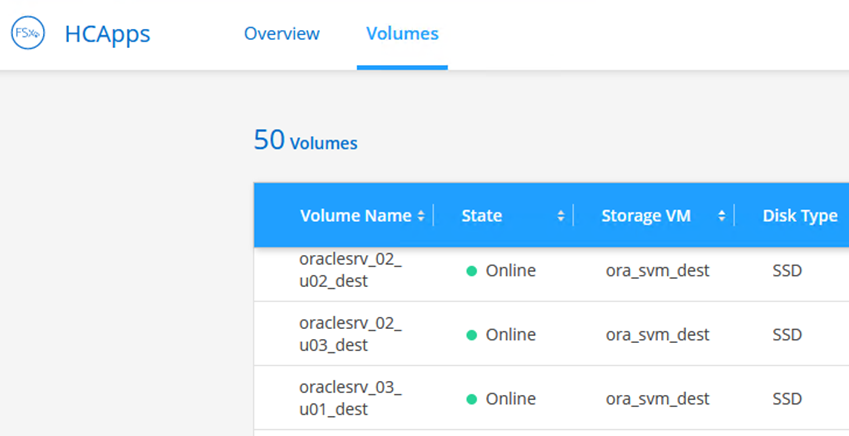
-
Dal menu Azione, seleziona Comando di montaggio per visualizzare e copiare il comando di montaggio da utilizzare sul nostro server Oracle Linux.
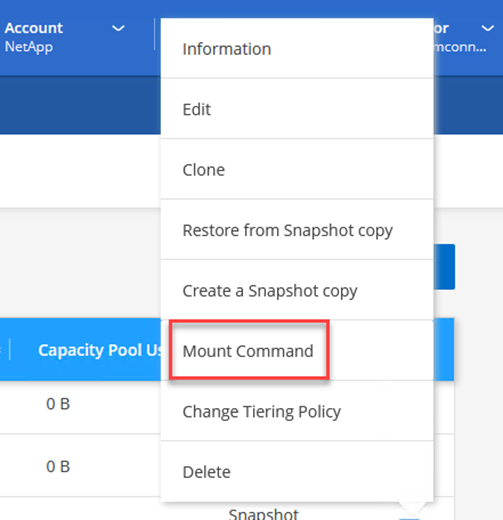
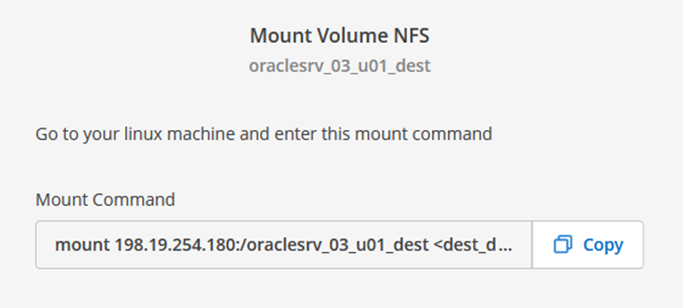
-
Montare il file system NFS su Oracle Linux Server. Le directory per il montaggio della condivisione NFS esistono già sull'host Oracle Linux.
-
Dal server Oracle Linux, utilizzare il comando mount per montare i volumi NFS.
FSx-Dest::> mount -t oracle_server_ip:/junction-path
Ripetere questo passaggio per ogni volume associato ai database Oracle.
Per rendere persistente il montaggio NFS al riavvio, modificare /etc/fstabfile per includere i comandi di montaggio. -
Riavviare il server Oracle. I database Oracle dovrebbero avviarsi normalmente ed essere disponibili per l'uso.
Rifasamento
Una volta completato con successo il processo di failover descritto in questa soluzione, SnapCenter e Veeam riprendono le loro funzioni di backup in esecuzione su AWS e FSx ONTAP viene ora designato come storage primario senza alcuna relazione SnapMirror esistente con il data center locale originale. Dopo aver ripreso il normale funzionamento in sede, è possibile utilizzare un processo identico a quello descritto in questa documentazione per eseguire il mirroring dei dati sul sistema di archiviazione ONTAP in sede.
Come descritto anche in questa documentazione, è possibile configurare SnapCenter per eseguire il mirroring dei volumi di dati dell'applicazione da FSx ONTAP a un sistema di archiviazione ONTAP residente in locale. Allo stesso modo, è possibile configurare Veeam per replicare le copie di backup su Amazon S3 utilizzando un repository di backup scalabile, in modo che tali backup siano accessibili a un server di backup Veeam residente nel data center locale.
Il failback esula dall'ambito di questa documentazione, ma differisce poco dal processo dettagliato qui descritto.
Conclusione
Il caso d'uso presentato in questa documentazione si concentra su tecnologie di disaster recovery comprovate che evidenziano l'integrazione tra NetApp e VMware. I sistemi di storage NetApp ONTAP forniscono tecnologie di data-mirroring comprovate che consentono alle organizzazioni di progettare soluzioni di disaster recovery che abbracciano tecnologie locali e ONTAP residenti presso i principali provider cloud.
FSx ONTAP su AWS è una di queste soluzioni che consente un'integrazione perfetta con SnapCenter e SyncMirror per replicare i dati delle applicazioni sul cloud. Veeam Backup & Replication è un'altra tecnologia ben nota che si integra bene con i sistemi di storage NetApp ONTAP e può fornire il failover allo storage nativo di vSphere.
Questa soluzione presentava una soluzione di disaster recovery che utilizzava l'archiviazione guest connect da un sistema ONTAP che ospitava dati di applicazioni SQL Server e Oracle. SnapCenter con SnapMirror fornisce una soluzione facile da gestire per proteggere i volumi delle applicazioni sui sistemi ONTAP e replicarli su FSx o CVO residenti nel cloud. SnapCenter è una soluzione abilitata al DR per il failover di tutti i dati delle applicazioni su VMware Cloud su AWS.