

Configurare il MetroCluster software FC in ONTAP
 Suggerisci modifiche
Suggerisci modifiche
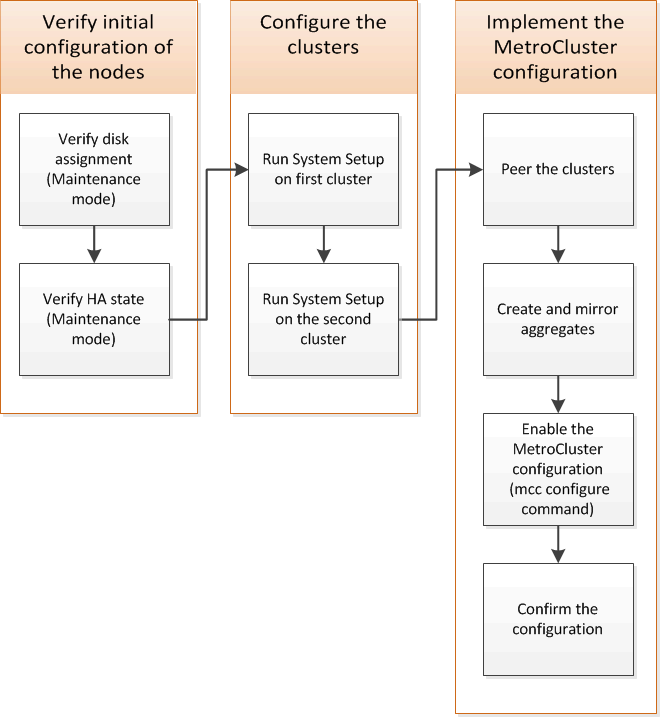
È necessario impostare ciascun nodo nella configurazione MetroCluster FC in ONTAP, incluse le configurazioni a livello di nodo e la configurazione dei nodi in due siti. È inoltre necessario implementare la relazione MetroCluster tra i due siti.
Raccolta delle informazioni richieste
Prima di iniziare il processo di configurazione, è necessario raccogliere gli indirizzi IP richiesti per i moduli controller.
Foglio di lavoro con le informazioni sulla rete IP per il sito A.
Prima di configurare il sistema, è necessario ottenere gli indirizzi IP e altre informazioni di rete per il primo sito MetroCluster (sito A) dall'amministratore di rete.
Informazioni sullo switch del sito A (cluster con switch)
Quando si collega il sistema, è necessario disporre di un nome host e di un indirizzo IP di gestione per ogni switch del cluster. Queste informazioni non sono necessarie se si utilizza un cluster senza switch a due nodi o se si dispone di una configurazione MetroCluster a due nodi (un nodo per ogni sito).
Switch del cluster |
Nome host |
Indirizzo IP |
Maschera di rete |
Gateway predefinito |
Interconnessione 1 |
||||
Interconnessione 2 |
||||
Gestione 1 |
||||
Gestione 2 |
Informazioni sulla creazione del cluster del sito A.
Quando si crea il cluster per la prima volta, sono necessarie le seguenti informazioni:
Tipo di informazione |
I tuoi valori |
Nome del cluster Esempio utilizzato in questa procedura: Site_A. |
|
Dominio DNS |
|
Server dei nomi DNS |
|
Posizione |
|
Password dell'amministratore |
Informazioni sul nodo del sito A.
Per ciascun nodo del cluster, sono necessari un indirizzo IP di gestione, una maschera di rete e un gateway predefinito.
Nodo |
Porta |
Indirizzo IP |
Maschera di rete |
Gateway predefinito |
Nodo 1 Esempio utilizzato in questa procedura: Controller_A_1 |
||||
Nodo 2 Non richiesto se si utilizza una configurazione MetroCluster a due nodi (un nodo per ogni sito). Esempio utilizzato in questa procedura: Controller_A_2 |
Porta e LIF del sito A per il peering del cluster
Per ciascun nodo del cluster, sono necessari gli indirizzi IP di due LIF intercluster, tra cui una maschera di rete e un gateway predefinito. Le LIF dell'intercluster vengono utilizzate per eseguire il peer dei cluster.
Nodo |
Porta |
Indirizzo IP della LIF dell'intercluster |
Maschera di rete |
Gateway predefinito |
Nodo 1 IC LIF 1 |
||||
Nodo 1 IC LIF 2 |
||||
Nodo 2 IC LIF 1 Non richiesto per configurazioni MetroCluster a due nodi (un nodo per sito). |
||||
Nodo 2 IC LIF 2 Non richiesto per configurazioni MetroCluster a due nodi (un nodo per sito). |
Informazioni sul server di riferimento orario del sito A.
È necessario sincronizzare l'ora, che richiede uno o più server di riferimento orario NTP.
Nodo |
Nome host |
Indirizzo IP |
Maschera di rete |
Gateway predefinito |
Server NTP 1 |
||||
Server NTP 2 |
Sito A nbsp; informazioni AutoSupport
È necessario configurare AutoSupport su ciascun nodo, che richiede le seguenti informazioni:
Tipo di informazione |
I tuoi valori |
|
Da indirizzo e-mail |
Mail host |
|
Indirizzi IP o nomi |
Protocollo di trasporto |
|
HTTP, HTTPS O SMTP |
Server proxy |
|
Indirizzi e-mail o liste di distribuzione del destinatario |
Messaggi completi |
|
Messaggi concisi |
||
Sito A nbsp; informazioni SP
È necessario abilitare l'accesso al Service Processor (SP) di ciascun nodo per la risoluzione dei problemi e la manutenzione, che richiede le seguenti informazioni di rete per ciascun nodo:
Nodo |
Indirizzo IP |
Maschera di rete |
Gateway predefinito |
Nodo 1 |
|||
Nodo 2 Non richiesto per configurazioni MetroCluster a due nodi (un nodo per sito). |
Foglio di lavoro con le informazioni della rete IP per il sito B
Prima di configurare il sistema, è necessario ottenere gli indirizzi IP e altre informazioni di rete per il secondo sito MetroCluster (sito B) dall'amministratore di rete.
Informazioni sullo switch del sito B (cluster con switch)
Quando si collega il sistema, è necessario disporre di un nome host e di un indirizzo IP di gestione per ogni switch del cluster. Queste informazioni non sono necessarie se si utilizza un cluster senza switch a due nodi o si dispone di una configurazione MetroCluster a due nodi (un nodo per ogni sito).
Switch del cluster |
Nome host |
Indirizzo IP |
Maschera di rete |
Gateway predefinito |
Interconnessione 1 |
||||
Interconnessione 2 |
||||
Gestione 1 |
||||
Gestione 2 |
Informazioni sulla creazione del cluster del sito B.
Quando si crea il cluster per la prima volta, sono necessarie le seguenti informazioni:
Tipo di informazione |
I tuoi valori |
Nome del cluster Esempio utilizzato in questa procedura: site_B |
|
Dominio DNS |
|
Server dei nomi DNS |
|
Posizione |
|
Password dell'amministratore |
Informazioni sul nodo del sito B.
Per ciascun nodo del cluster, sono necessari un indirizzo IP di gestione, una maschera di rete e un gateway predefinito.
Nodo |
Porta |
Indirizzo IP |
Maschera di rete |
Gateway predefinito |
Nodo 1 Esempio utilizzato in questa procedura: controller_B_1 |
||||
Nodo 2 Non richiesto per configurazioni MetroCluster a due nodi (un nodo per sito). Esempio utilizzato in questa procedura: controller_B_2 |
LIF e porte del sito B per il peering dei cluster
Per ciascun nodo del cluster, sono necessari gli indirizzi IP di due LIF intercluster, tra cui una maschera di rete e un gateway predefinito. Le LIF dell'intercluster vengono utilizzate per eseguire il peer dei cluster.
Nodo |
Porta |
Indirizzo IP della LIF dell'intercluster |
Maschera di rete |
Gateway predefinito |
Nodo 1 IC LIF 1 |
||||
Nodo 1 IC LIF 2 |
||||
Nodo 2 IC LIF 1 Non richiesto per configurazioni MetroCluster a due nodi (un nodo per sito). |
||||
Nodo 2 IC LIF 2 Non richiesto per configurazioni MetroCluster a due nodi (un nodo per sito). |
Informazioni sul server di riferimento orario del sito B.
È necessario sincronizzare l'ora, che richiede uno o più server di riferimento orario NTP.
Nodo |
Nome host |
Indirizzo IP |
Maschera di rete |
Gateway predefinito |
Server NTP 1 |
||||
Server NTP 2 |
Sito B nbsp;informazioni AutoSupport
È necessario configurare AutoSupport su ciascun nodo, che richiede le seguenti informazioni:
Tipo di informazione |
I tuoi valori |
|
Da indirizzo e-mail |
||
Mail host |
Indirizzi IP o nomi |
|
Protocollo di trasporto |
HTTP, HTTPS O SMTP |
|
Server proxy |
Indirizzi e-mail o liste di distribuzione del destinatario |
|
Messaggi completi |
Messaggi concisi |
|
Partner |
||
Sito B nbsp;informazioni SP
È necessario abilitare l'accesso al Service Processor (SP) di ciascun nodo per la risoluzione dei problemi e la manutenzione, che richiede le seguenti informazioni di rete per ciascun nodo:
Nodo |
Indirizzo IP |
Maschera di rete |
Gateway predefinito |
Nodo 1 (controller_B_1) |
|||
Nodo 2 (controller_B_2) Non richiesto per configurazioni MetroCluster a due nodi (un nodo per sito). |
Analogie e differenze tra cluster standard e configurazioni MetroCluster
La configurazione dei nodi in ciascun cluster in una configurazione MetroCluster è simile a quella dei nodi in un cluster standard.
La configurazione di MetroCluster si basa su due cluster standard. Fisicamente, la configurazione deve essere simmetrica, con ciascun nodo con la stessa configurazione hardware e tutti i componenti MetroCluster devono essere cablati e configurati. Tuttavia, la configurazione software di base per i nodi in una configurazione MetroCluster è uguale a quella per i nodi in un cluster standard.
Fase di configurazione |
Configurazione standard del cluster |
Configurazione di MetroCluster |
Configurare le LIF di gestione, cluster e dati su ciascun nodo. |
Lo stesso vale per entrambi i tipi di cluster |
|
Configurare l'aggregato root. |
Lo stesso vale per entrambi i tipi di cluster |
|
Configurare i nodi nel cluster come coppie ha |
Lo stesso vale per entrambi i tipi di cluster |
|
Impostare il cluster su un nodo del cluster. |
Lo stesso vale per entrambi i tipi di cluster |
|
Unire l'altro nodo al cluster. |
Lo stesso vale per entrambi i tipi di cluster |
|
Creare un aggregato root mirrorato. |
Opzionale |
Obbligatorio |
Peer dei cluster. |
Opzionale |
Obbligatorio |
Abilitare la configurazione MetroCluster. |
Non applicabile |
Obbligatorio |
Verifica e configurazione dello stato ha dei componenti in modalità manutenzione
Quando si configura un sistema di storage in una configurazione MetroCluster FC, è necessario assicurarsi che lo stato di alta disponibilità (ha) del modulo controller e dei componenti del telaio sia mcc o mcc-2n in modo che questi componenti si avviino correttamente. Sebbene questo valore debba essere preconfigurato nei sistemi ricevuti in fabbrica, è comunque necessario verificare l'impostazione prima di procedere.

|
Se lo stato ha del modulo controller e del telaio non è corretto, non è possibile configurare il MetroCluster senza reinizializzare il nodo. È necessario correggere l'impostazione utilizzando questa procedura, quindi inizializzare il sistema utilizzando una delle seguenti procedure:
|
Verificare che il sistema sia in modalità di manutenzione.
-
In modalità Maintenance (manutenzione), visualizzare lo stato ha del modulo controller e dello chassis:
ha-config showLo stato ha corretto dipende dalla configurazione di MetroCluster.
Tipo di configurazione di MetroCluster
Stato HA per tutti i componenti…
Configurazione FC MetroCluster a otto o quattro nodi
mcc
Configurazione MetroCluster FC a due nodi
mcc-2n
Configurazione IP MetroCluster a otto o quattro nodi
mccip
-
Se lo stato del sistema visualizzato del controller non è corretto, impostare lo stato ha corretto per la configurazione sul modulo controller:
Tipo di configurazione di MetroCluster
Comando
Configurazione FC MetroCluster a otto o quattro nodi
ha-config modify controller mccConfigurazione MetroCluster FC a due nodi
ha-config modify controller mcc-2nConfigurazione IP MetroCluster a otto o quattro nodi
ha-config modify controller mccip -
Se lo stato del sistema visualizzato del telaio non è corretto, impostare lo stato ha corretto per la configurazione sul telaio:
Tipo di configurazione di MetroCluster
Comando
Configurazione FC MetroCluster a otto o quattro nodi
ha-config modify chassis mccConfigurazione MetroCluster FC a due nodi
ha-config modify chassis mcc-2nConfigurazione IP MetroCluster a otto o quattro nodi
ha-config modify chassis mccip -
Avviare il nodo su ONTAP:
boot_ontap -
Ripetere l'intera procedura per verificare lo stato ha su ogni nodo nella configurazione MetroCluster.
Ripristino delle impostazioni predefinite del sistema e configurazione del tipo di HBA su un modulo controller
Per garantire una corretta installazione di MetroCluster, ripristinare le impostazioni predefinite dei moduli controller.
Questa attività è necessaria solo per le configurazioni stretch che utilizzano bridge FC-SAS.
-
Al prompt DEL CARICATORE, riportare le variabili ambientali alle impostazioni predefinite:
set-defaults -
Avviare il nodo in modalità manutenzione, quindi configurare le impostazioni per gli HBA nel sistema:
-
Avviare in modalità di manutenzione:
boot_ontap maint -
Verificare le impostazioni correnti delle porte:
ucadmin show -
Aggiornare le impostazioni della porta secondo necessità.
Se si dispone di questo tipo di HBA e della modalità desiderata…
Utilizzare questo comando…
FC CNA
ucadmin modify -m fc -t initiator adapter_nameEthernet CNA
ucadmin modify -mode cna adapter_nameDestinazione FC
fcadmin config -t target adapter_nameIniziatore FC
fcadmin config -t initiator adapter_name -
-
Uscire dalla modalità di manutenzione:
haltDopo aver eseguito il comando, attendere che il nodo si arresti al prompt DEL CARICATORE.
-
Riavviare il nodo in modalità Maintenance per rendere effettive le modifiche di configurazione:
boot_ontap maint -
Verificare le modifiche apportate:
Se si dispone di questo tipo di HBA…
Utilizzare questo comando…
CNA
ucadmin showFC
fcadmin show -
Uscire dalla modalità di manutenzione:
haltDopo aver eseguito il comando, attendere che il nodo si arresti al prompt DEL CARICATORE.
-
Avviare il nodo dal menu di boot:
boot_ontap menuDopo aver eseguito il comando, attendere che venga visualizzato il menu di avvio.
-
Cancellare la configurazione del nodo digitando “wipeconfig” al prompt del menu di avvio, quindi premere Invio.
La seguente schermata mostra il prompt del menu di avvio:
Please choose one of the following:
(1) Normal Boot.
(2) Boot without /etc/rc.
(3) Change password.
(4) Clean configuration and initialize all disks.
(5) Maintenance mode boot.
(6) Update flash from backup config.
(7) Install new software first.
(8) Reboot node.
(9) Configure Advanced Drive Partitioning.
Selection (1-9)? wipeconfig
This option deletes critical system configuration, including cluster membership.
Warning: do not run this option on a HA node that has been taken over.
Are you sure you want to continue?: yes
Rebooting to finish wipeconfig request.
Configurazione delle porte FC-VI su una scheda X1132A-R6 quad-port su sistemi FAS8020
Se si utilizza la scheda a quattro porte X1132A-R6 su un sistema FAS8020, è possibile accedere alla modalità di manutenzione per configurare le porte 1a e 1b per l'utilizzo di FC-VI e Initiator. Questa operazione non è necessaria sui sistemi MetroCluster ricevuti dalla fabbrica, in cui le porte sono impostate in modo appropriato per la configurazione.
Questa attività deve essere eseguita in modalità manutenzione.

|
La conversione di una porta FC in una porta FC-VI con il comando ucadmin è supportata solo sui sistemi FAS8020 e AFF 8020. La conversione delle porte FC in porte FCVI non è supportata su altre piattaforme. |
-
Disattivare le porte:
storage disable adapter 1astorage disable adapter 1b*> storage disable adapter 1a Jun 03 02:17:57 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1a. Host adapter 1a disable succeeded Jun 03 02:17:57 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1a is now offline. *> storage disable adapter 1b Jun 03 02:18:43 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1b. Host adapter 1b disable succeeded Jun 03 02:18:43 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1b is now offline. *>
-
Verificare che le porte siano disattivate:
ucadmin show*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - - offline 1b fc initiator - - offline 1c fc initiator - - online 1d fc initiator - - online -
Impostare le porte a e b sulla modalità FC-VI:
ucadmin modify -adapter 1a -type fcviIl comando imposta la modalità su entrambe le porte della coppia di porte, 1a e 1b (anche se solo 1a è specificata nel comando).
*> ucadmin modify -t fcvi 1a Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1a. Reboot the controller for the changes to take effect. Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1b. Reboot the controller for the changes to take effect.
-
Confermare che la modifica è in sospeso:
ucadmin show*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - fcvi offline 1b fc initiator - fcvi offline 1c fc initiator - - online 1d fc initiator - - online -
Spegnere il controller, quindi riavviarlo in modalità di manutenzione.
-
Confermare la modifica della configurazione:
ucadmin show localNode Adapter Mode Type Mode Type Status ------------ ------- ------- --------- ------- --------- ----------- ... controller_B_1 1a fc fcvi - - online controller_B_1 1b fc fcvi - - online controller_B_1 1c fc initiator - - online controller_B_1 1d fc initiator - - online 6 entries were displayed.
Verifica dell'assegnazione dei dischi in modalità Maintenance in una configurazione a otto o quattro nodi
Prima di avviare completamente il sistema su ONTAP, è possibile eseguire l'avvio in modalità manutenzione e verificare l'assegnazione dei dischi sui nodi. I dischi devono essere assegnati per creare una configurazione Active-Active completamente simmetrica, in cui ciascun pool ha un numero uguale di dischi assegnati.
I nuovi sistemi MetroCluster hanno completato l'assegnazione dei dischi prima della spedizione.
La tabella seguente mostra esempi di assegnazioni di pool per una configurazione MetroCluster. I dischi vengono assegnati ai pool in base allo shelf.
Shelf di dischi nel sito A
Shelf di dischi (nome_shelf_campione)… |
Appartiene a… |
E viene assegnato al nodo… |
Shelf di dischi 1 (shelf_A_1_1) |
Nodo A 1 |
Pool 0 |
Shelf di dischi 2 (shelf_A_1_3) |
||
Shelf di dischi 3 (shelf_B_1_1) |
Nodo B 1 |
Pool 1 |
Shelf di dischi 4 (shelf_B_1_3) |
||
Shelf di dischi 5 (shelf_A_2_1) |
Nodo A 2 |
Pool 0 |
Shelf di dischi 6 (shelf_A_2_3) |
||
Shelf di dischi 7 (shelf_B_2_1) |
Nodo B 2 |
Pool 1 |
Shelf di dischi 8 (shelf_B_2_3) |
||
Shelf di dischi 1 (shelf_A_3_1) |
Nodo A 3 |
Pool 0 |
Shelf di dischi 2 (shelf_A_3_3) |
||
Shelf di dischi 3 (shelf_B_3_1) |
Nodo B 3 |
Pool 1 |
Shelf di dischi 4 (shelf_B_3_3) |
||
Shelf di dischi 5 (shelf_A_4_1) |
Nodo A 4 |
Pool 0 |
Shelf di dischi 6 (shelf_A_4_3) |
||
Shelf di dischi 7 (shelf_B_4_1) |
Nodo B 4 |
Pool 1 |
Shelf di dischi 8 (shelf_B_4_3) |
Shelf di dischi nel sito B
Shelf di dischi (nome_shelf_campione)… |
Appartiene a… |
E viene assegnato al nodo… |
Shelf di dischi 9 (shelf_B_1_2) |
Nodo B 1 |
Pool 0 |
Shelf di dischi 10 (shelf_B_1_4) |
Shelf di dischi 11 (shelf_A_1_2) |
Nodo A 1 |
Pool 1 |
Shelf di dischi 12 (shelf_A_1_4) |
Shelf di dischi 13 (shelf_B_2_2) |
Nodo B 2 |
Pool 0 |
Shelf di dischi 14 (shelf_B_2_4) |
Shelf di dischi 15 (shelf_A_2_2) |
Nodo A 2 |
Pool 1 |
Shelf di dischi 16 (shelf_A_2_4) |
Shelf di dischi 1 (shelf_B_3_2) |
Nodo A 3 |
Pool 0 |
Shelf di dischi 2 (shelf_B_3_4) |
Shelf di dischi 3 (shelf_A_3_2) |
Nodo B 3 |
Pool 1 |
Shelf di dischi 4 (shelf_A_3_4) |
Shelf di dischi 5 (shelf_B_4_2) |
Nodo A 4 |
Pool 0 |
Shelf di dischi 6 (shelf_B_4_4) |
Shelf di dischi 7 (shelf_A_4_2) |
Nodo B 4 |
-
Confermare le assegnazioni degli shelf:
disk show –v -
Se necessario, assegnare esplicitamente i dischi sugli shelf di dischi collegati al pool appropriato:
disk assignL'utilizzo dei caratteri jolly nel comando consente di assegnare tutti i dischi su uno shelf di dischi con un unico comando. È possibile identificare gli ID e gli alloggiamenti degli shelf di dischi per ciascun disco con
storage show disk -xcomando.
Assegnazione della proprietà del disco in sistemi non AFF
Se i dischi non sono stati assegnati correttamente ai nodi MetroCluster o se si utilizzano shelf di dischi DS460C nella configurazione, è necessario assegnare i dischi a ciascuno dei nodi nella configurazione MetroCluster in base allo shelf-by-shelf. Verrà creata una configurazione in cui ciascun nodo ha lo stesso numero di dischi nei pool di dischi locali e remoti.
I controller dello storage devono essere in modalità Maintenance (manutenzione).
Se la configurazione non include shelf di dischi DS460C, questa attività non è necessaria se i dischi sono stati assegnati correttamente al momento della ricezione dalla fabbrica.
|
|
Il pool 0 contiene sempre i dischi che si trovano nello stesso sito del sistema di storage che li possiede. Il pool 1 contiene sempre i dischi remoti del sistema di storage proprietario. |
Se la configurazione include shelf di dischi DS460C, è necessario assegnare manualmente i dischi utilizzando le seguenti linee guida per ciascun cassetto da 12 dischi:
Assegnare questi dischi nel cassetto… |
A questo nodo e pool… |
0 - 2 |
Pool del nodo locale 0 |
3 - 5 |
Pool del nodo partner HA 0 |
6 - 8 |
Partner DR del pool del nodo locale 1 |
9 - 11 |
Partner DR del pool del partner ha 1 |
Questo schema di assegnazione dei dischi garantisce che un aggregato venga influenzato in modo minimo nel caso in cui un cassetto venga scollegato.
-
In caso contrario, avviare ciascun sistema in modalità di manutenzione.
-
Assegnare gli shelf di dischi ai nodi situati nel primo sito (sito A):
Gli shelf di dischi nello stesso sito del nodo vengono assegnati al pool 0 e gli shelf di dischi situati nel sito del partner vengono assegnati al pool 1.
È necessario assegnare un numero uguale di shelf a ciascun pool.
-
Sul primo nodo, assegnare sistematicamente gli shelf di dischi locali al pool 0 e gli shelf di dischi remoti al pool 1:
disk assign -shelf local-switch-name:shelf-name.port -p poolSe lo storage controller Controller Controller Controller_A_1 dispone di quattro shelf, eseguire i seguenti comandi:
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1
-
Ripetere la procedura per il secondo nodo nel sito locale, assegnando sistematicamente gli shelf di dischi locali al pool 0 e gli shelf di dischi remoti al pool 1:
disk assign -shelf local-switch-name:shelf-name.port -p poolSe lo storage controller Controller Controller Controller_A_2 dispone di quattro shelf, eseguire i seguenti comandi:
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1
-
-
Assegnare gli shelf di dischi ai nodi situati nel secondo sito (sito B):
Gli shelf di dischi nello stesso sito del nodo vengono assegnati al pool 0 e gli shelf di dischi situati nel sito del partner vengono assegnati al pool 1.
È necessario assegnare un numero uguale di shelf a ciascun pool.
-
Sul primo nodo del sito remoto, assegnare sistematicamente i propri shelf di dischi locali al pool 0 e i relativi shelf di dischi remoti al pool 1:
disk assign -shelf local-switch-nameshelf-name -p poolSe lo storage controller Controller Controller_B_1 dispone di quattro shelf, eseguire i seguenti comandi:
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1
-
Ripetere la procedura per il secondo nodo del sito remoto, assegnando sistematicamente i propri shelf di dischi locali al pool 0 e i relativi shelf di dischi remoti al pool 1:
disk assign -shelf shelf-name -p poolSe lo storage controller Controller Controller Controller_B_2 dispone di quattro shelf, eseguire i seguenti comandi:
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1
-
-
Confermare le assegnazioni degli shelf:
storage show shelf -
Uscire dalla modalità di manutenzione:
halt -
Visualizzare il menu di avvio:
boot_ontap menu -
Su ciascun nodo, selezionare l'opzione 4 per inizializzare tutti i dischi.
Assegnazione della proprietà del disco nei sistemi AFF
Se si utilizzano sistemi AFF in una configurazione con aggregati mirrorati e i nodi non hanno i dischi (SSD) assegnati correttamente, è necessario assegnare metà dei dischi su ogni shelf a un nodo locale e l'altra metà dei dischi al nodo partner ha. È necessario creare una configurazione in cui ciascun nodo abbia lo stesso numero di dischi nei pool di dischi locali e remoti.
I controller dello storage devono essere in modalità Maintenance (manutenzione).
Ciò non si applica alle configurazioni che hanno aggregati senza mirror, una configurazione attiva/passiva o che hanno un numero di dischi diverso nei pool locali e remoti.
Questa attività non è necessaria se i dischi sono stati assegnati correttamente al momento della ricezione dalla fabbrica.
|
|
Il pool 0 contiene sempre i dischi che si trovano nello stesso sito del sistema di storage che li possiede. Il pool 1 contiene sempre i dischi remoti del sistema di storage proprietario. |
-
In caso contrario, avviare ciascun sistema in modalità di manutenzione.
-
Assegnare i dischi ai nodi situati nel primo sito (sito A):
È necessario assegnare un numero uguale di dischi a ciascun pool.
-
Sul primo nodo, assegnare sistematicamente metà dei dischi su ogni shelf al pool 0 e l'altra metà al pool 0 del partner ha:
disk assign -shelf <shelf-name> -p <pool> -n <number-of-disks>Se lo storage controller Controller Controller Controller_A_1 ha quattro shelf, ciascuno con 8 SSD, devi eseguire i seguenti comandi:
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1 -n 4
-
Ripetere la procedura per il secondo nodo del sito locale, assegnando sistematicamente metà dei dischi su ogni shelf al pool 1 e l'altra metà al pool 1 del partner ha:
disk assign -disk disk-name -p poolSe lo storage controller Controller Controller Controller_A_1 ha quattro shelf, ciascuno con 8 SSD, devi eseguire i seguenti comandi:
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4
-
-
Assegnare i dischi ai nodi situati nel secondo sito (sito B):
È necessario assegnare un numero uguale di dischi a ciascun pool.
-
Sul primo nodo del sito remoto, assegnare sistematicamente metà dei dischi su ogni shelf al pool 0 e l'altra metà al pool del partner ha 0:
disk assign -disk disk-name -p poolSe lo storage controller Controller Controller_B_1 ha quattro shelf, ciascuno con 8 SSD, devi eseguire i seguenti comandi:
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1 -n 4
-
Ripetere la procedura per il secondo nodo del sito remoto, assegnando sistematicamente metà dei dischi su ogni shelf al pool 1 e l'altra metà al pool 1 del partner ha:
disk assign -disk disk-name -p poolSe lo storage controller Controller Controller Controller_B_2 dispone di quattro shelf, ciascuno con 8 SSD, devi eseguire i seguenti comandi:
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1 -n 4
-
-
Confermare le assegnazioni dei dischi:
storage show disk -
Uscire dalla modalità di manutenzione:
halt -
Visualizzare il menu di avvio:
boot_ontap menu -
Su ciascun nodo, selezionare l'opzione 4 per inizializzare tutti i dischi.
Verifica dell'assegnazione dei dischi in modalità manutenzione in una configurazione a due nodi
Prima di avviare completamente il sistema su ONTAP, è possibile avviare il sistema in modalità manutenzione e verificare l'assegnazione dei dischi sui nodi. I dischi devono essere assegnati in modo da creare una configurazione completamente simmetrica con entrambi i siti che possiedono i propri shelf di dischi e i dati di servizio, in cui a ciascun nodo e a ciascun pool è assegnato un numero uguale di dischi mirrorati.
Il sistema deve essere in modalità di manutenzione.
I nuovi sistemi MetroCluster hanno completato l'assegnazione dei dischi prima della spedizione.
La tabella seguente mostra esempi di assegnazioni di pool per una configurazione MetroCluster. I dischi vengono assegnati ai pool in base allo shelf.
Shelf di dischi (nome di esempio)… |
Sul sito… |
Appartiene a… |
E viene assegnato al nodo… |
Shelf di dischi 1 (shelf_A_1_1) |
Sito A |
Nodo A 1 |
Pool 0 |
Shelf di dischi 2 (shelf_A_1_3) |
|||
Shelf di dischi 3 (shelf_B_1_1) |
Nodo B 1 |
Pool 1 |
|
Shelf di dischi 4 (shelf_B_1_3) |
|||
Shelf di dischi 9 (shelf_B_1_2) |
Sito B |
Nodo B 1 |
Pool 0 |
Shelf di dischi 10 (shelf_B_1_4) |
|||
Shelf di dischi 11 (shelf_A_1_2) |
Nodo A 1 |
Pool 1 |
|
Shelf di dischi 12 (shelf_A_1_4) |
Se la configurazione include shelf di dischi DS460C, è necessario assegnare manualmente i dischi utilizzando le seguenti linee guida per ciascun cassetto da 12 dischi:
Assegnare questi dischi nel cassetto… |
A questo nodo e pool… |
1 - 6 |
Pool del nodo locale 0 |
7 - 12 |
Pool del partner DR 1 |
Questo schema di assegnazione dei dischi riduce al minimo l'effetto su un aggregato se un cassetto passa offline.
-
Se il sistema è stato ricevuto dalla fabbrica, confermare le assegnazioni degli shelf:
disk show –v -
Se necessario, è possibile assegnare esplicitamente i dischi sugli shelf di dischi collegati al pool appropriato utilizzando il comando disk assign.
Gli shelf di dischi nello stesso sito del nodo vengono assegnati al pool 0 e gli shelf di dischi situati nel sito del partner vengono assegnati al pool 1. È necessario assegnare un numero uguale di shelf a ciascun pool.
-
In caso contrario, avviare ciascun sistema in modalità di manutenzione.
-
Sul nodo del sito A, assegnare sistematicamente gli shelf di dischi locali al pool 0 e gli shelf di dischi remoti al pool 1:
disk assign -shelf disk_shelf_name -p poolSe lo storage controller node_A_1 dispone di quattro shelf, eseguire i seguenti comandi:
*> disk assign -shelf shelf_A_1_1 -p 0 *> disk assign -shelf shelf_A_1_3 -p 0 *> disk assign -shelf shelf_A_1_2 -p 1 *> disk assign -shelf shelf_A_1_4 -p 1
-
Sul nodo del sito remoto (sito B), assegnare sistematicamente i propri shelf di dischi locali al pool 0 e i relativi shelf di dischi remoti al pool 1:
disk assign -shelf disk_shelf_name -p poolSe lo storage controller node_B_1 dispone di quattro shelf, eseguire i seguenti comandi:
*> disk assign -shelf shelf_B_1_2 -p 0 *> disk assign -shelf shelf_B_1_4 -p 0 *> disk assign -shelf shelf_B_1_1 -p 1 *> disk assign -shelf shelf_B_1_3 -p 1
-
Mostrare gli ID e gli alloggiamenti degli shelf di dischi per ciascun disco:
disk show –v
-
Configurazione di ONTAP
È necessario impostare ONTAP su ciascun modulo controller.
Se è necessario eseguire il netboot dei nuovi controller, vedere "Avvio in rete dei nuovi moduli controller" Nella Guida all'aggiornamento, alla transizione e all'espansione di MetroCluster.
Impostazione di ONTAP in una configurazione MetroCluster a due nodi
In una configurazione MetroCluster a due nodi, su ciascun cluster è necessario avviare il nodo, uscire dalla procedura guidata di installazione del cluster e utilizzare il comando di installazione del cluster per configurare il nodo in un cluster a nodo singolo.
Non è necessario aver configurato il Service Processor.
Questa attività è destinata alle configurazioni MetroCluster a due nodi che utilizzano lo storage NetApp nativo.
Questa attività deve essere eseguita su entrambi i cluster nella configurazione MetroCluster.
Per ulteriori informazioni generali sulla configurazione di ONTAP, vedere "Configurare ONTAP".
-
Accendere il primo nodo.
Ripetere questo passaggio sul nodo del sito di disaster recovery (DR). Il nodo si avvia, quindi viene avviata la procedura guidata di configurazione del cluster sulla console, che informa che AutoSupport verrà attivato automaticamente.
::> Welcome to the cluster setup wizard. You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the cluster setup wizard. Any changes you made before quitting will be saved. You can return to cluster setup at any time by typing "cluster setup". To accept a default or omit a question, do not enter a value. This system will send event messages and periodic reports to NetApp Technical Support. To disable this feature, enter autosupport modify -support disable within 24 hours. Enabling AutoSupport can significantly speed problem determination and resolution, should a problem occur on your system. For further information on AutoSupport, see: http://support.netapp.com/autosupport/ Type yes to confirm and continue {yes}: yes Enter the node management interface port [e0M]: Enter the node management interface IP address [10.101.01.01]: Enter the node management interface netmask [101.010.101.0]: Enter the node management interface default gateway [10.101.01.0]: Do you want to create a new cluster or join an existing cluster? {create, join}: -
Creare un nuovo cluster:
create -
Scegliere se utilizzare il nodo come cluster a nodo singolo.
Do you intend for this node to be used as a single node cluster? {yes, no} [yes]: -
Accettare le impostazioni predefinite del sistema
yesPremendo Invio, oppure immettere i propri valori digitandono, Quindi premere Invio. -
Seguire le istruzioni per completare la procedura guidata Cluster Setup, premere Invio per accettare i valori predefiniti o digitare i propri valori, quindi premere Invio.
I valori predefiniti vengono determinati automaticamente in base alla piattaforma e alla configurazione di rete.
-
Dopo aver completato la procedura guidata Cluster Setup e aver chiuso, verificare che il cluster sia attivo e che il primo nodo funzioni correttamente: `
cluster showL'esempio seguente mostra un cluster in cui il primo nodo (cluster1-01) è integro e idoneo a partecipare:
cluster1::> cluster show Node Health Eligibility --------------------- ------- ------------ cluster1-01 true true
Se è necessario modificare una delle impostazioni immesse per l'SVM amministrativa o il nodo SVM, è possibile accedere alla procedura guidata di installazione del cluster utilizzando il comando di installazione del cluster.
Impostazione di ONTAP in una configurazione MetroCluster a otto o quattro nodi
Dopo aver avviato ciascun nodo, viene richiesto di eseguire il programma di installazione del sistema per eseguire la configurazione di base del nodo e del cluster. Dopo aver configurato il cluster, tornare alla CLI ONTAP per creare aggregati e creare la configurazione MetroCluster.
La configurazione MetroCluster deve essere cablata.
Questa attività è destinata alle configurazioni MetroCluster a otto o quattro nodi che utilizzano lo storage NetApp nativo.
I nuovi sistemi MetroCluster sono preconfigurati; non è necessario eseguire questa procedura. Tuttavia, è necessario configurare lo strumento AutoSupport.
Questa attività deve essere eseguita su entrambi i cluster nella configurazione MetroCluster.
Questa procedura utilizza lo strumento di configurazione del sistema. Se lo si desidera, è possibile utilizzare la configurazione guidata del cluster CLI.
-
Se non lo si è già fatto, accendere ciascun nodo e lasciarlo avviare completamente.
Se il sistema è in modalità manutenzione, eseguire il comando halt per uscire dalla modalità manutenzione, quindi eseguire il seguente comando dal prompt DEL CARICATORE:
boot_ontapL'output dovrebbe essere simile a quanto segue:
Welcome to node setup You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the setup wizard. Any changes you made before quitting will be saved. To accept a default or omit a question, do not enter a value. . . .
-
Attivare lo strumento AutoSupport seguendo le istruzioni fornite dal sistema.
-
Rispondere alle richieste per configurare l'interfaccia di gestione dei nodi.
I prompt sono simili ai seguenti:
Enter the node management interface port: [e0M]: Enter the node management interface IP address: 10.228.160.229 Enter the node management interface netmask: 225.225.252.0 Enter the node management interface default gateway: 10.228.160.1
-
Verificare che i nodi siano configurati in modalità ad alta disponibilità:
storage failover show -fields modeIn caso contrario, eseguire il seguente comando su ciascun nodo e riavviare il nodo:
storage failover modify -mode ha -node localhostQuesto comando configura la modalità di disponibilità elevata ma non attiva il failover dello storage. Il failover dello storage viene attivato automaticamente quando la configurazione MetroCluster viene eseguita successivamente nel processo di configurazione.
-
Verificare che siano configurate quattro porte come interconnessioni cluster:
network port showL'esempio seguente mostra l'output per cluster_A:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ node_A_1 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 node_A_2 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
Se si crea un cluster senza switch a due nodi (un cluster senza switch di interconnessione del cluster), attivare la modalità di rete senza switch del cluster:
-
Passare al livello di privilegio avanzato:
set -privilege advanced
Puoi rispondere
yquando viene richiesto di passare alla modalità avanzata. Viene visualizzato il prompt della modalità avanzata (*).-
Abilitare la modalità cluster senza switch:
network options switchless-cluster modify -enabled true -
Tornare al livello di privilegio admin:
set -privilege admin
-
-
Avviare il programma di installazione del sistema seguendo le istruzioni fornite dalle informazioni visualizzate sulla console del sistema dopo l'avvio iniziale.
-
Utilizzare lo strumento di configurazione del sistema per configurare ciascun nodo e creare il cluster, ma non per creare aggregati.
È possibile creare aggregati mirrorati nelle attività successive.
Tornare all'interfaccia della riga di comando di ONTAP e completare la configurazione di MetroCluster eseguendo le seguenti operazioni.
Configurazione dei cluster in una configurazione MetroCluster
È necessario eseguire il peer dei cluster, eseguire il mirroring degli aggregati root, creare un aggregato di dati mirrorati e quindi eseguire il comando per implementare le operazioni MetroCluster.
Prima di correre metrocluster configure, La modalità ha e il mirroring DR non sono abilitati e potrebbe essere visualizzato un messaggio di errore relativo a questo comportamento previsto. La modalità ha e il mirroring del DR vengono successivamente attivate quando si esegue il comando metrocluster configure per implementare la configurazione.
Peering dei cluster
I cluster nella configurazione di MetroCluster devono essere in una relazione peer in modo da poter comunicare tra loro ed eseguire il mirroring dei dati essenziale per il disaster recovery di MetroCluster.
Configurazione delle LIF tra cluster
È necessario creare LIF intercluster sulle porte utilizzate per la comunicazione tra i cluster di partner MetroCluster. È possibile utilizzare porte o porte dedicate che dispongono anche di traffico dati.
Configurazione di LIF intercluster su porte dedicate
È possibile configurare le LIF tra cluster su porte dedicate. In genere, aumenta la larghezza di banda disponibile per il traffico di replica.
-
Elencare le porte nel cluster:
network port showPer la sintassi completa dei comandi, vedere la pagina man.
L'esempio seguente mostra le porte di rete in "cluster01":
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
Determinare quali porte sono disponibili per la comunicazione tra cluster:
network interface show -fields home-port,curr-portPer la sintassi completa dei comandi, vedere la pagina man.
L'esempio seguente mostra che alle porte "e0e" e "e0f" non sono stati assegnati LIF:
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
Creare un gruppo di failover per le porte dedicate:
network interface failover-groups create -vserver system_SVM -failover-group failover_group -targets physical_or_logical_portsNell'esempio riportato di seguito vengono assegnate le porte "e0e" e "e0f" al gruppo di failover Intercluster01 sul sistema "SVMcluster01":
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
Verificare che il gruppo di failover sia stato creato:
network interface failover-groups showPer la sintassi completa dei comandi, vedere la pagina man.
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
Creare LIF intercluster sulla SVM di sistema e assegnarle al gruppo di failover.
ONTAP 9.6 e versioni successivenetwork interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmask -failover-group failover_groupONTAP 9.5 e versioni precedentinetwork interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmask -failover-group failover_groupPer la sintassi completa dei comandi, vedere la pagina man.
Nell'esempio seguente vengono create le LIF di intercluster "cluster01_icl01" e "cluster01_icl02" nel gruppo di failover "intercluster01":
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
Verificare che le LIF dell'intercluster siano state create:
ONTAP 9.6 e versioni successiveEseguire il comando:
network interface show -service-policy default-interclusterONTAP 9.5 e versioni precedentiEseguire il comando:
network interface show -role interclusterPer la sintassi completa dei comandi, vedere la pagina man.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
Verificare che le LIF dell'intercluster siano ridondanti:
ONTAP 9.6 e versioni successiveEseguire il comando:
network interface show -service-policy default-intercluster -failoverONTAP 9.5 e versioni precedentiEseguire il comando:
network interface show -role intercluster -failoverPer la sintassi completa dei comandi, vedere la pagina man.
L'esempio seguente mostra che le LIF dell'intercluster "cluster01_icl01" e "cluster01_icl02" sulla porta SVM "e0e" effettueranno il failover sulla porta "e0f".
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
Quando si determina se l'utilizzo di una porta dedicata per la replica tra cluster è la soluzione di rete tra cluster corretta, è necessario prendere in considerazione configurazioni e requisiti quali tipo di LAN, banda WAN disponibile, intervallo di replica, tasso di modifica e numero di porte.
Configurazione delle LIF tra cluster su porte dati condivise
È possibile configurare le LIF di intercluster sulle porte condivise con la rete dati. In questo modo si riduce il numero di porte necessarie per la rete tra cluster.
-
Elencare le porte nel cluster:
network port showPer la sintassi completa dei comandi, vedere la pagina man.
L'esempio seguente mostra le porte di rete nel cluster01:
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
Creazione di LIF intercluster sulla SVM di sistema:
ONTAP 9.6 e versioni successiveEseguire il comando:
network interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmaskONTAP 9.5 e versioni precedentiEseguire il comando:
network interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmaskPer la sintassi completa dei comandi, vedere la pagina man. Nell'esempio seguente vengono creati i LIF di intercluster cluster01_icl01 e cluster01_icl02:
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
Verificare che le LIF dell'intercluster siano state create:
ONTAP 9.6 e versioni successiveEseguire il comando:
network interface show -service-policy default-interclusterONTAP 9.5 e versioni precedentiEseguire il comando:
network interface show -role interclusterPer la sintassi completa dei comandi, vedere la pagina man.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
Verificare che le LIF dell'intercluster siano ridondanti:
ONTAP 9.6 e versioni successiveEseguire il comando:
network interface show –service-policy default-intercluster -failoverONTAP 9.5 e versioni precedentiEseguire il comando:
network interface show -role intercluster -failoverPer la sintassi completa dei comandi, vedere la pagina man.
L'esempio seguente mostra che i LIF dell'intercluster "cluster01_icl01" e "cluster01_icl02" sulla porta "e0c" effettueranno il failover sulla porta "e0d".
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
Creazione di una relazione peer del cluster
È necessario creare la relazione peer del cluster tra i cluster MetroCluster.
È possibile utilizzare cluster peer create per creare una relazione peer tra un cluster locale e remoto. Una volta creata la relazione peer, è possibile eseguire cluster peer create sul cluster remoto per autenticarlo nel cluster locale.
-
È necessario aver creato le LIF di intercluster su ogni nodo dei cluster che vengono sottoposti a peering.
-
I cluster devono eseguire ONTAP 9.3 o versione successiva.
-
Sul cluster di destinazione, creare una relazione peer con il cluster di origine:
cluster peer create -generate-passphrase -offer-expiration MM/DD/YYYY HH:MM:SS|1…7days|1…168hours -peer-addrs peer_LIF_IPs -ipspace ipspaceSe si specificano entrambi
-generate-passphrasee.-peer-addrs, Solo il cluster i cui LIF intercluster sono specificati in-peer-addrspuò utilizzare la password generata.È possibile ignorare
-ipspaceSe non si utilizza un IPSpace personalizzato. Per la sintassi completa dei comandi, vedere la pagina man.Nell'esempio seguente viene creata una relazione peer del cluster su un cluster remoto non specificato:
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
Nel cluster di origine, autenticare il cluster di origine nel cluster di destinazione:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspacePer la sintassi completa dei comandi, vedere la pagina man.
Nell'esempio seguente viene autenticato il cluster locale nel cluster remoto agli indirizzi IP LIF "192.140.112.101" e "192.140.112.102" dell'intercluster:
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.Inserire la passphrase per la relazione peer quando richiesto.
-
Verificare che la relazione peer del cluster sia stata creata:
cluster peer show -instancecluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster2 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Address Family of Relationship: ipv4 Authentication Status Administrative: no-authentication Authentication Status Operational: absent Last Update Time: 02/05 21:05:41 IPspace for the Relationship: Default -
Verificare la connettività e lo stato dei nodi nella relazione peer:
cluster peer health showcluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
Creazione di una relazione peer del cluster (ONTAP 9.2 e versioni precedenti)
È possibile utilizzare cluster peer create per avviare una richiesta di relazione di peering tra un cluster locale e remoto. Una volta richiesta la relazione peer dal cluster locale, è possibile eseguire cluster peer create sul cluster remoto per accettare la relazione.
-
È necessario aver creato le LIF di intercluster su ogni nodo dei cluster in fase di peering.
-
Gli amministratori del cluster devono aver concordato la passphrase utilizzata da ciascun cluster per autenticarsi con l'altro.
-
Nel cluster di destinazione per la protezione dei dati, creare una relazione peer con il cluster di origine per la protezione dei dati:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspaceSe non si utilizza un IPSpace personalizzato, è possibile ignorare l'opzione -ipspace. Per la sintassi completa dei comandi, vedere la pagina man.
Nell'esempio riportato di seguito viene creata una relazione peer del cluster con il cluster remoto agli indirizzi IP LIF dell'intercluster "192.168.2.201" e "192.168.2.202":
cluster02::> cluster peer create -peer-addrs 192.168.2.201,192.168.2.202 Enter the passphrase: Please enter the passphrase again:
Inserire la passphrase per la relazione peer quando richiesto.
-
Nel cluster di origine per la protezione dei dati, autenticare il cluster di origine nel cluster di destinazione:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspacePer la sintassi completa dei comandi, vedere la pagina man.
Nell'esempio seguente viene autenticato il cluster locale nel cluster remoto agli indirizzi IP LIF "192.140.112.203" e "192.140.112.204" dell'intercluster:
cluster01::> cluster peer create -peer-addrs 192.168.2.203,192.168.2.204 Please confirm the passphrase: Please confirm the passphrase again:
Inserire la passphrase per la relazione peer quando richiesto.
-
Verificare che la relazione peer del cluster sia stata creata:
cluster peer show –instancePer la sintassi completa dei comandi, vedere la pagina man.
cluster01::> cluster peer show –instance Peer Cluster Name: cluster01 Remote Intercluster Addresses: 192.168.2.201,192.168.2.202 Availability: Available Remote Cluster Name: cluster02 Active IP Addresses: 192.168.2.201,192.168.2.202 Cluster Serial Number: 1-80-000013
-
Verificare la connettività e lo stato dei nodi nella relazione peer:
cluster peer health show`Per la sintassi completa dei comandi, vedere la pagina man.
cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
Mirroring degli aggregati root
È necessario eseguire il mirroring degli aggregati root per garantire la protezione dei dati.
Per impostazione predefinita, l'aggregato root viene creato come aggregato di tipo RAID-DP. È possibile modificare l'aggregato root da RAID-DP a aggregato di tipo RAID4. Il seguente comando modifica l'aggregato root per l'aggregato di tipo RAID4:
storage aggregate modify –aggregate aggr_name -raidtype raid4
|
|
Nei sistemi non ADP, il tipo RAID dell'aggregato può essere modificato dal RAID-DP predefinito a RAID4 prima o dopo il mirroring dell'aggregato. |
-
Eseguire il mirroring dell'aggregato root:
storage aggregate mirror aggr_nameIl seguente comando esegue il mirroring dell'aggregato root per controller_A_1:
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
Questo esegue il mirroring dell'aggregato, quindi è costituito da un plex locale e da un plex remoto situati nel sito MetroCluster remoto.
-
Ripetere il passaggio precedente per ciascun nodo della configurazione MetroCluster.
Creazione di un aggregato di dati mirrorato su ciascun nodo
È necessario creare un aggregato di dati mirrorato su ciascun nodo del gruppo DR.
-
Devi sapere quali dischi verranno utilizzati nel nuovo aggregato.
-
Se nel sistema sono presenti più tipi di dischi (storage eterogeneo), è necessario comprendere come assicurarsi di selezionare il tipo di disco corretto.
-
I dischi sono di proprietà di un nodo specifico; quando si crea un aggregato, tutti i dischi in tale aggregato devono essere di proprietà dello stesso nodo, che diventa il nodo principale per quell'aggregato.
-
I nomi degli aggregati devono essere conformi allo schema di denominazione stabilito al momento della pianificazione della configurazione MetroCluster. Vedere "Gestione di dischi e aggregati".
-
I nomi degli aggregati devono essere univoci in tutti i siti MetroCluster. Ciò significa che non è possibile avere due aggregati diversi con lo stesso nome sul sito A e sul sito B.
-
Visualizzare un elenco delle parti di ricambio disponibili:
storage disk show -spare -owner node_name -
Creare l'aggregato utilizzando il comando storage aggregate create -mirror true.
Se si è connessi al cluster nell'interfaccia di gestione del cluster, è possibile creare un aggregato su qualsiasi nodo del cluster. Per assicurarsi che l'aggregato venga creato su un nodo specifico, utilizzare
-nodeo specificare i dischi di proprietà di quel nodo.È possibile specificare le seguenti opzioni:
-
Nodo principale dell'aggregato (ovvero, il nodo proprietario dell'aggregato durante il normale funzionamento)
-
Elenco dei dischi specifici da aggiungere all'aggregato
-
Numero di dischi da includere
Nella configurazione minima supportata, in cui è disponibile un numero limitato di dischi, è necessario utilizzare force-small-aggregateOpzione per consentire la creazione di un aggregato RAID-DP a tre dischi.-
Stile checksum da utilizzare per l'aggregato
-
Tipo di dischi da utilizzare
-
Dimensioni delle unità da utilizzare
-
Velocità del disco da utilizzare
-
Tipo RAID per i gruppi RAID sull'aggregato
-
Numero massimo di dischi che possono essere inclusi in un gruppo RAID
-
Se sono consentiti dischi con diversi RPM
Per ulteriori informazioni su queste opzioni, consultare
storage aggregate createpagina man.Il seguente comando crea un aggregato mirrorato con 10 dischi:
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Verificare il gruppo RAID e i dischi del nuovo aggregato:
storage aggregate show-status -aggregate aggregate-name
Creazione di aggregati di dati senza mirror
È possibile creare aggregati di dati senza mirroring per i dati che non richiedono il mirroring ridondante fornito dalle configurazioni MetroCluster.
-
Verificare di sapere quali unità verranno utilizzate nel nuovo aggregato.
-
Se nel sistema sono presenti più tipi di dischi (storage eterogeneo), è necessario comprendere come verificare che sia selezionato il tipo di disco corretto.

|
Nelle configurazioni MetroCluster FC, gli aggregati senza mirror saranno online solo dopo uno switchover se i dischi remoti nell'aggregato sono accessibili. In caso di errore degli ISL, il nodo locale potrebbe non essere in grado di accedere ai dati dei dischi remoti senza mirror. Il guasto di un aggregato può causare il riavvio del nodo locale. |
-
I dischi sono di proprietà di un nodo specifico; quando si crea un aggregato, tutti i dischi in tale aggregato devono essere di proprietà dello stesso nodo, che diventa il nodo principale per quell'aggregato.
|
|
Gli aggregati senza mirror devono essere locali rispetto al nodo che li possiede. |
-
I nomi degli aggregati devono essere conformi allo schema di denominazione stabilito al momento della pianificazione della configurazione MetroCluster.
-
Gestione di dischi e aggregati contiene ulteriori informazioni sugli aggregati di mirroring.
-
Visualizzare un elenco delle parti di ricambio disponibili:
storage disk show -spare -owner node_name -
Creare l'aggregato:
storage aggregate createSe si è connessi al cluster nell'interfaccia di gestione del cluster, è possibile creare un aggregato su qualsiasi nodo del cluster. Per verificare che l'aggregato sia creato su un nodo specifico, utilizzare
-nodeo specificare i dischi di proprietà di quel nodo.È possibile specificare le seguenti opzioni:
-
Nodo principale dell'aggregato (ovvero, il nodo proprietario dell'aggregato durante il normale funzionamento)
-
Elenco dei dischi specifici da aggiungere all'aggregato
-
Numero di dischi da includere
-
Stile checksum da utilizzare per l'aggregato
-
Tipo di dischi da utilizzare
-
Dimensioni delle unità da utilizzare
-
Velocità del disco da utilizzare
-
Tipo RAID per i gruppi RAID sull'aggregato
-
Numero massimo di dischi che possono essere inclusi in un gruppo RAID
-
Se sono consentiti dischi con diversi RPM
Per ulteriori informazioni su queste opzioni, consulta la pagina man di creazione dell'aggregato di storage.
Il seguente comando crea un aggregato senza mirror con 10 dischi:
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Verificare il gruppo RAID e i dischi del nuovo aggregato:
storage aggregate show-status -aggregate aggregate-name
Implementazione della configurazione MetroCluster
È necessario eseguire metrocluster configure Comando per avviare la protezione dei dati in una configurazione MetroCluster.
-
Su ciascun cluster devono essere presenti almeno due aggregati di dati mirrorati non root.
È possibile eseguire il mirroring o il mirroring di aggregati di dati aggiuntivi.
È possibile verificarlo con
storage aggregate showcomando.
Se si desidera utilizzare un singolo aggregato di dati mirrorato, vedere Fase 1 per istruzioni. -
Lo stato ha-config dei controller e dello chassis deve essere "mcc".
Si emette il metrocluster configure Per abilitare la configurazione MetroCluster, eseguire una sola volta il comando su uno dei nodi. Non è necessario eseguire il comando su ciascuno dei siti o nodi e non è importante il nodo o il sito su cui si sceglie di eseguire il comando.
Il metrocluster configure Command associa automaticamente i due nodi con gli ID di sistema più bassi in ciascuno dei due cluster come partner di disaster recovery (DR). In una configurazione MetroCluster a quattro nodi, esistono due coppie di partner DR. La seconda coppia di DR viene creata dai due nodi con ID di sistema superiori.
|
|
È necessario non configurare Onboard Key Manager (OKM) o la gestione delle chiavi esterne prima di eseguire il comando metrocluster configure.
|
-
Configura MetroCluster nel seguente formato:
Se la configurazione di MetroCluster dispone di…
Quindi…
Aggregati di dati multipli
Dal prompt di qualsiasi nodo, configurare MetroCluster:
metrocluster configure node-nameUn singolo aggregato di dati mirrorato
-
Dal prompt di qualsiasi nodo, passare al livello di privilegio avanzato:
set -privilege advancedDevi rispondere con
yquando viene richiesto di passare alla modalità avanzata e viene visualizzato il prompt della modalità avanzata (*). -
Configurare MetroCluster con
-allow-with-one-aggregate trueparametro:metrocluster configure -allow-with-one-aggregate true node-name -
Tornare al livello di privilegio admin:
set -privilege admin
La Best practice consiste nell'avere più aggregati di dati. Se il primo gruppo DR dispone di un solo aggregato e si desidera aggiungere un gruppo DR con un aggregato, è necessario spostare il volume di metadati dal singolo aggregato di dati. Per ulteriori informazioni su questa procedura, vedere "Spostamento di un volume di metadati nelle configurazioni MetroCluster". Il seguente comando abilita la configurazione MetroCluster su tutti i nodi del gruppo DR che contiene controller_A_1:
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
Verificare lo stato della rete sul sito A:
network port showL'esempio seguente mostra l'utilizzo della porta di rete in una configurazione MetroCluster a quattro nodi:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
Verificare la configurazione MetroCluster da entrambi i siti nella configurazione MetroCluster.
-
Verificare la configurazione dal sito A:
metrocluster showcluster_A::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
Verificare la configurazione dal sito B:
metrocluster show
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
Configurazione della consegna in-order o out-of-order dei frame sul software ONTAP
È necessario configurare la consegna in-order (IOD) o la consegna out-of-order (OOD) dei frame in base alla configurazione dello switch Fibre Channel (FC).
Se lo switch FC è configurato per IOD, il software ONTAP deve essere configurato per IOD. Analogamente, se lo switch FC è configurato per OOD, è necessario configurare ONTAP per OOD.
|
|
Riavviare il controller per modificare la configurazione. |
-
Configurare ONTAP per il funzionamento di IOD o OOD di frame.
-
Per impostazione predefinita, l'IOD dei frame è attivato in ONTAP. Per verificare i dettagli della configurazione:
-
Accedere alla modalità avanzata:
set advanced -
Verificare le impostazioni:
metrocluster interconnect adapter show
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
-
Per configurare l'OOD dei frame, è necessario eseguire le seguenti operazioni su ciascun nodo:
-
Accedere alla modalità avanzata:
set advanced -
Verificare le impostazioni di configurazione di MetroCluster:
metrocluster interconnect adapter showmcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
Abilitare OOOD sul nodo “mcc4-b1” e sul nodo “mcc4-b2”:
metrocluster interconnect adapter modify -node node_name -is-ood-enabled true
mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b1 -is-ood-enabled true mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b2 -is-ood-enabled true
-
Riavviare il controller eseguendo un takeover ad alta disponibilità (ha) in entrambe le direzioni.
-
Verificare le impostazioni:
metrocluster interconnect adapter show
-
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up true 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up true 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up true 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up true 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
Configurare SNMPv3 in una configurazione FC MetroCluster
I protocolli di autenticazione e privacy sugli switch e sul sistema ONTAP devono essere identici.
ONTAP attualmente supporta AES-128 per la privacy (crittografia) e SHA-256 per l'autenticazione.
|
|
|
-
Creare un utente SNMP per ogni switch dal prompt del controller:
security login createController_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10.10.10.10
-
Rispondere alle seguenti richieste in base alle esigenze della propria sede:
Per EngineID, premere INVIO per assegnare il valore predefinito. Enter the authoritative entity's EngineID [remote EngineID]: Which authentication protocol do you want to choose (none, md5, sha, sha2-256) [none]: sha Enter the authentication protocol password (minimum 8 characters long): Enter the authentication protocol password again: Which privacy protocol do you want to choose (none, des, aes128) [none]: aes128 Enter privacy protocol password (minimum 8 characters long): Enter privacy protocol password again:
Lo stesso nome utente può essere aggiunto a diversi switch con indirizzi IP diversi. -
Creare un utente SNMP per gli altri switch.
Nell'esempio seguente viene illustrato come creare un nome utente per uno switch con l'indirizzo IP 10.10.10.11.
Controller_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10. 10.10.11
-
Verificare che vi sia una voce di accesso per ogni switch:
security login showController_A_1::> security login show -user-or-group-name snmpv3user -fields remote-switch-ipaddress vserver user-or-group-name application authentication-method remote-switch-ipaddress ------------ ------------------ ----------- --------------------- ----------------------- node_A_1 SVM 1 snmpv3user snmp usm 10.10.10.10 node_A_1 SVM 2 snmpv3user snmp usm 10.10.10.11 node_A_1 SVM 3 snmpv3user snmp usm 10.10.10.12 node_A_1 SVM 4 snmpv3user snmp usm 10.10.10.13 4 entries were displayed.
-
Configurare SNMPv3 sugli switch dal prompt dello switch:
Switch Brocade (FOS 9.x)snmpconfig --add snmpv3 -index <index> -user <user_name> -groupname <rw/ro> -auth_proto <auth_protocol> -auth_passwd <auth_password> -priv_proto <priv_protocol> -priv_passwd <priv_password>Switch Brocade (FOS 8.x e precedenti)snmpconfig --set snmpv3L'esempio mostra come configurare un utente di sola lettura. Se necessario, è possibile modificare gli utenti RW. Se è necessario l'accesso RO, dopo "Utente (ro):" specificare "snmpv3user".
Switch-A1:admin> snmpconfig --set snmpv3 SNMP Informs Enabled (true, t, false, f): [false] true SNMPv3 user configuration(snmp user not configured in FOS user database will have physical AD and admin role as the default): User (rw): [snmpadmin1] Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [3] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [2] Engine ID: [00:00:00:00:00:00:00:00:00] User (ro): [snmpuser2] snmpv3user Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [2] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [3]
Switch Ciscosnmp-server user <user_name> auth [md5/sha/sha-256] <auth_password> priv (aes-128) <priv_password>
È inoltre necessario impostare le password degli account inutilizzati per proteggerli e utilizzare la migliore crittografia disponibile nella versione di ONTAP. -
Configurare la crittografia e le password per gli altri utenti dello switch in base alle esigenze del sito.
Configurazione dei componenti di MetroCluster per il monitoraggio dello stato di salute
Prima di monitorare i componenti in una configurazione MetroCluster, è necessario eseguire alcune procedure di configurazione speciali.
|
|
Per una maggiore sicurezza, NetApp consiglia di configurare SNMPv2 o SNMPv3 per monitorare lo stato dello switch. |
Queste attività si applicano solo ai sistemi con bridge FC-SAS.
A partire da Fabric OS 9.0.1, SNMPv2 non è supportato per il monitoraggio dello stato di salute sugli switch Brocade, devi usare SNMPv3. Se stai usando SNMPv3, devi configurare SNMPv3 in ONTAP prima di passare alla sezione seguente. Per maggiori dettagli, vedi Configurare SNMPv3 in una configurazione FC MetroCluster.
|
|
|
NetApp supporta solo i seguenti strumenti per monitorare i componenti in una configurazione FC MetroCluster:
-
Brocade Network Advisor (BNA)
-
Brocade SANnav
-
Active IQ Config Advisor
-
Monitoraggio dello stato di salute NetApp (ONTAP)
-
Raccolta dati MetroCluster (MC_DC)
Configurazione degli switch MetroCluster FC per il monitoraggio dello stato di salute
In una configurazione Fabric-Attached MetroCluster, è necessario eseguire alcune procedure di configurazione aggiuntive per monitorare gli switch FC.
|
|
A partire da ONTAP 9,8, il storage switch comando viene sostituito da system switch fibre-channel. La procedura seguente mostra il storage switch comando, ma se si esegue ONTAP 9,8 o versione successiva, il system switch fibre-channel comando è preferito.
|
-
Aggiungere uno switch con un indirizzo IP a ciascun nodo MetroCluster:
Il comando eseguito dipende dall'utilizzo di SNMPv2 o SNMPv3.
Aggiungere uno switch utilizzando SNMPv3:storage switch add -address <ip_adddress> -snmp-version SNMPv3 -snmp-community-or-username <SNMP_user_configured_on_the_switch>Aggiungere uno switch utilizzando SNMPv2:storage switch add -address ipaddressQuesto comando deve essere ripetuto su tutti e quattro gli switch nella configurazione MetroCluster.
Gli switch FC Brocade 7840 e tutti gli avvisi sono supportati nel monitoraggio dello stato di salute, ad eccezione di NoISLPresent_Alert. L'esempio seguente mostra il comando per aggiungere uno switch con indirizzo IP 10.10.10.10:
controller_A_1::> storage switch add -address 10.10.10.10
-
Verificare che tutti gli switch siano configurati correttamente:
storage switch showPotrebbero essere necessari fino a 15 minuti per riflettere tutti i dati a causa dell'intervallo di polling di 15 minuti.
L'esempio seguente mostra il comando fornito per verificare che gli switch FC MetroCluster siano configurati:
controller_A_1::> storage switch show Fabric Switch Name Vendor Model Switch WWN Status ---------------- --------------- ------- ------------ ---------------- ------ 1000000533a9e7a6 brcd6505-fcs40 Brocade Brocade6505 1000000533a9e7a6 OK 1000000533a9e7a6 brcd6505-fcs42 Brocade Brocade6505 1000000533d3660a OK 1000000533ed94d1 brcd6510-fcs44 Brocade Brocade6510 1000000533eda031 OK 1000000533ed94d1 brcd6510-fcs45 Brocade Brocade6510 1000000533ed94d1 OK 4 entries were displayed. controller_A_1::>
Se viene visualizzato il nome internazionale (WWN) dello switch, il monitor dello stato di salute ONTAP può contattare e monitorare lo switch FC.
Configurazione di bridge FC-SAS per il monitoraggio dello stato di salute
Nei sistemi con versioni di ONTAP precedenti alla 9.8, è necessario eseguire alcune procedure di configurazione speciali per monitorare i bridge FC-SAS nella configurazione di MetroCluster.
-
Gli strumenti di monitoraggio SNMP di terze parti non sono supportati per i bridge FibreBridge.
-
A partire da ONTAP 9.8, i bridge FC-SAS vengono monitorati per impostazione predefinita tramite connessioni in-band e non è necessaria alcuna configurazione aggiuntiva.
|
|
A partire da ONTAP 9.8, la storage bridge il comando viene sostituito con system bridge. La procedura riportata di seguito mostra storage bridge Ma se si utilizza ONTAP 9.8 o versione successiva, il comando system bridge è preferibile utilizzare il comando.
|
-
Dal prompt del cluster ONTAP, aggiungere il bridge al monitoraggio dello stato di salute:
-
Aggiungere il bridge utilizzando il comando per la versione di ONTAP in uso:
Versione di ONTAP
Comando
9.5 e versioni successive
storage bridge add -address 0.0.0.0 -managed-by in-band -name bridge-name9.4 e versioni precedenti
storage bridge add -address bridge-ip-address -name bridge-name -
Verificare che il bridge sia stato aggiunto e configurato correttamente:
storage bridge showA causa dell'intervallo di polling, potrebbero essere necessari 15 minuti per riflettere tutti i dati. Il monitor dello stato di ONTAP può contattare e monitorare il bridge se il valore nella colonna "Stato" è "ok" e vengono visualizzate altre informazioni, ad esempio il nome internazionale (WWN).
L'esempio seguente mostra che i bridge FC-SAS sono configurati:
controller_A_1::> storage bridge show Bridge Symbolic Name Is Monitored Monitor Status Vendor Model Bridge WWN ------------------ ------------- ------------ -------------- ------ ----------------- ---------- ATTO_10.10.20.10 atto01 true ok Atto FibreBridge 7500N 20000010867038c0 ATTO_10.10.20.11 atto02 true ok Atto FibreBridge 7500N 20000010867033c0 ATTO_10.10.20.12 atto03 true ok Atto FibreBridge 7500N 20000010867030c0 ATTO_10.10.20.13 atto04 true ok Atto FibreBridge 7500N 2000001086703b80 4 entries were displayed controller_A_1::>
-
Verifica della configurazione MetroCluster
È possibile verificare che i componenti e le relazioni nella configurazione di MetroCluster funzionino correttamente.
Dopo la configurazione iniziale e dopo aver apportato eventuali modifiche alla configurazione MetroCluster, è necessario eseguire un controllo. È inoltre necessario eseguire un controllo prima di un'operazione di switchover negoziata (pianificata) o di switchback.
Se il metrocluster check run il comando viene emesso due volte in un breve periodo di tempo su uno o entrambi i cluster, può verificarsi un conflitto e il comando potrebbe non raccogliere tutti i dati. Successivo metrocluster check show quindi non mostrerà l'output previsto.
-
Controllare la configurazione:
metrocluster check runIl comando viene eseguito come processo in background e potrebbe non essere completato immediatamente.
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
Visualizza risultati più dettagliati dei più recenti
metrocluster check runcomando:metrocluster check aggregate showmetrocluster check cluster showmetrocluster check config-replication showmetrocluster check lif showmetrocluster check node show
Il metrocluster check showi comandi mostrano i risultati dei più recentimetrocluster check runcomando. Eseguire sempre ilmetrocluster check runprima di utilizzaremetrocluster check showi comandi in modo che le informazioni visualizzate siano aggiornate.Nell'esempio riportato di seguito viene illustrato il
metrocluster check aggregate showOutput di comando per una configurazione MetroCluster a quattro nodi sana:cluster_A::> metrocluster check aggregate show Last Checked On: 8/5/2014 00:42:58 Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.Nell'esempio riportato di seguito viene illustrato il
metrocluster check cluster showOutput di comando per una configurazione MetroCluster a quattro nodi sana. Indica che i cluster sono pronti per eseguire uno switchover negoziato, se necessario.Last Checked On: 9/13/2017 20:47:04 Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
Verifica degli errori di configurazione di MetroCluster con Config Advisor
È possibile accedere al sito di supporto NetApp e scaricare lo strumento Config Advisor per verificare la presenza di errori di configurazione comuni.
Config Advisor è uno strumento per la convalida della configurazione e il controllo dello stato di salute. È possibile implementarlo sia in siti sicuri che in siti non sicuri per la raccolta di dati e l'analisi del sistema.
|
|
Il supporto per Config Advisor è limitato e disponibile solo online. |
-
Accedere alla pagina di download di Config Advisor e scaricare lo strumento.
-
Eseguire Config Advisor, esaminare l'output dello strumento e seguire le raccomandazioni nell'output per risolvere eventuali problemi rilevati.
Verifica del funzionamento locale di ha
Se si dispone di una configurazione MetroCluster a quattro nodi, verificare il funzionamento delle coppie ha locali nella configurazione MetroCluster. Questo non è necessario per le configurazioni a due nodi.
Le configurazioni MetroCluster a due nodi non sono costituite da coppie ha locali e questa attività non è applicabile.
Gli esempi di questa attività utilizzano le convenzioni di denominazione standard:
-
Cluster_A.
-
Controller_A_1
-
Controller_A_2
-
-
Cluster_B
-
Controller_B_1
-
Controller_B_2
-
-
Su cluster_A, eseguire un failover e un giveback in entrambe le direzioni.
-
Verificare che il failover dello storage sia attivato:
storage failover showL'output dovrebbe indicare che è possibile effettuare il takeover per entrambi i nodi:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed. -
Prendere il controllo controller_A_2 da controller_A_1:
storage failover takeover controller_A_2È possibile utilizzare
storage failover show-takeovercomando per monitorare l'avanzamento dell'operazione di takeover. -
Verificare che il rilevamento sia stato completato:
storage failover showL'output dovrebbe indicare che controller_A_1 è in stato di Takeover, il che significa che ha assunto il controllo del partner ha:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ----------------- controller_A_1 controller_A_2 false In takeover controller_A_2 controller_A_1 - Unknown 2 entries were displayed. -
Restituire controller_A_2:
storage failover giveback controller_A_2È possibile utilizzare
storage failover show-givebackcomando per monitorare l'avanzamento dell'operazione di giveback. -
Verificare che il failover dello storage sia tornato allo stato normale:
storage failover showL'output dovrebbe indicare che è possibile effettuare il takeover per entrambi i nodi:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed.-
Ripetere i passaggi precedenti, questa volta prendendo il controllo di controller_A_1 da controller_A_2.
-
-
Ripetere i passaggi precedenti su cluster_B.
Verifica dello switchover, della riparazione e dello switchback
Verificare le operazioni di switchover, riparazione e switchback della configurazione MetroCluster.
-
Utilizzare le procedure per lo switchover negoziato, la riparazione e lo switchback indicate in "Ripristino in caso di disastro".
Protezione dei file di backup della configurazione
È possibile fornire una protezione aggiuntiva per i file di backup della configurazione del cluster specificando un URL remoto (HTTP o FTP) in cui verranno caricati i file di backup della configurazione oltre alle posizioni predefinite nel cluster locale.
-
Impostare l'URL della destinazione remota per i file di backup della configurazione:
system configuration backup settings modify URL-of-destinationIl "Gestione dei cluster con la CLI" Contiene ulteriori informazioni nella sezione Gestione dei backup di configurazione.