

Identificare e smontare i volumi di storage guasti
 Suggerisci modifiche
Suggerisci modifiche
Durante il ripristino di un nodo di storage con volumi di storage guasti, è necessario identificare e smontare i volumi guasti. È necessario verificare che solo i volumi di storage guasti vengano riformattati come parte della procedura di ripristino.
Hai effettuato l'accesso a Grid Manager utilizzando un "browser web supportato".
È necessario ripristinare i volumi di storage guasti il prima possibile.
La prima fase del processo di ripristino consiste nel rilevare i volumi che sono stati scollegati, che devono essere disinstallati o che presentano errori di i/O. Se i volumi guasti sono ancora collegati ma hanno un file system corrotto in modo casuale, il sistema potrebbe non rilevare alcun danneggiamento nelle parti del disco non utilizzate o non allocate.

|
È necessario completare questa procedura prima di eseguire la procedura manuale per ripristinare i volumi, ad esempio aggiungere o ricollegare i dischi, arrestare il nodo, avviare il nodo o riavviare. In caso contrario, quando si esegue reformat_storage_block_devices.rb script, potrebbe verificarsi un errore del file system che causa il blocco o l'errore dello script.
|
|
|
Riparare l'hardware e collegare correttamente i dischi prima di eseguire reboot comando.
|

|
Identificare con attenzione i volumi di storage guasti. Queste informazioni verranno utilizzate per verificare quali volumi devono essere riformattati. Una volta riformattato un volume, i dati sul volume non possono essere ripristinati. |
Per ripristinare correttamente i volumi di storage guasti, è necessario conoscere i nomi dei dispositivi dei volumi di storage guasti e i relativi ID dei volumi.
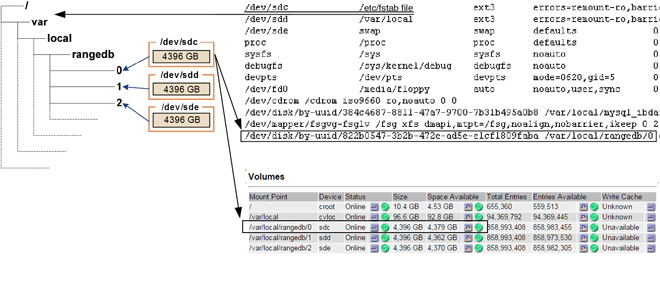
Al momento dell'installazione, a ciascun dispositivo di storage viene assegnato un UID (Universal Unique Identifier) del file system e viene montato in una directory rangedb sul nodo di storage utilizzando l'UID del file system assegnato. L'UUID del file system e la directory rangedb sono elencati in /etc/fstab file. Il nome del dispositivo, la directory rangedb e le dimensioni del volume montato vengono visualizzati in Grid Manager.
Nell'esempio seguente, dispositivo /dev/sdc Ha un volume di 4 TB, è montato su /var/local/rangedb/0, utilizzando il nome del dispositivo /dev/disk/by-uuid/822b0547-3b2b-472e-ad5e-e1cf1809faba in /etc/fstab file:
-
Completare i seguenti passaggi per registrare i volumi di storage guasti e i relativi nomi dei dispositivi:
-
Selezionare SUPPORT > Tools > Grid topology.
-
Selezionare sito > nodo di storage guasto > LDR > Storage > Panoramica > principale e cercare gli archivi di oggetti con allarmi.

-
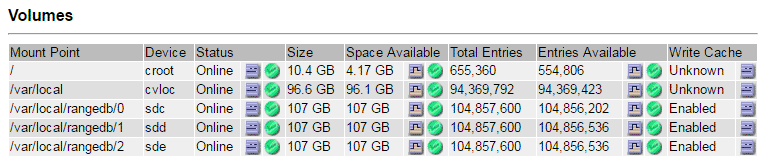
Selezionare sito > nodo storage guasto > SSM > risorse > Panoramica > principale. Determinare il punto di montaggio e le dimensioni del volume di ciascun volume di storage guasto identificato nel passaggio precedente.
Gli archivi di oggetti sono numerati in notazione esadecimale. Ad esempio, 0000 è il primo volume e 000F è il sedicesimo volume. Nell'esempio, l'archivio di oggetti con un ID di 0000 corrisponde a.
/var/local/rangedb/0Con nome periferica sdc e una dimensione di 107 GB.
-
-
Accedere al nodo di storage guasto:
-
Immettere il seguente comando:
ssh admin@grid_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile.
Una volta effettuato l'accesso come root, il prompt cambia da
$a.#. -
-
Eseguire il seguente script per smontare un volume di storage guasto:
sn-unmount-volume object_store_IDIl
object_store_IDÈ l'ID del volume di storage guasto. Ad esempio, specificare0Nel comando per un archivio di oggetti con ID 0000. -
Se richiesto, premere y per arrestare il servizio Cassandra a seconda del volume di storage 0.
Se il servizio Cassandra è già stato arrestato, non viene richiesto. Il servizio Cassandra viene arrestato solo per il volume 0. root@Storage-180:~/var/local/tmp/storage~ # sn-unmount-volume 0 Services depending on storage volume 0 (cassandra) aren't down. Services depending on storage volume 0 must be stopped before running this script. Stop services that require storage volume 0 [y/N]? y Shutting down services that require storage volume 0. Services requiring storage volume 0 stopped. Unmounting /var/local/rangedb/0 /var/local/rangedb/0 is unmounted.
In pochi secondi, il volume viene dismontato. Vengono visualizzati messaggi che indicano ogni fase del processo. Il messaggio finale indica che il volume è stato dismontato.
-
Se il dismount non riesce a causa di un volume occupato, è possibile forzare il dismount utilizzando
--use-umountofopzione:
Forzatura di uno smontaggio mediante --use-umountofl'opzione potrebbe causare un comportamento imprevisto o un blocco dei processi o dei servizi che utilizzano il volume.root@Storage-180:~ # sn-unmount-volume --use-umountof /var/local/rangedb/2 Unmounting /var/local/rangedb/2 using umountof /var/local/rangedb/2 is unmounted. Informing LDR service of changes to storage volumes