主要なAI、ML、DLのユースケースとアーキテクチャ
 変更を提案
変更を提案
主要な AI、ML、DL のユースケースと方法論は、次のセクションに分けられます。
Spark NLPパイプラインとTensorFlow分散推論
次のリストには、さまざまな開発レベルでデータ サイエンス コミュニティに採用されている最も人気のあるオープン ソース NLP ライブラリが含まれています。
-
"自然言語ツールキット(NLTK)" 。すべての NLP テクニックに対応する完全なツールキット。 2000年代初頭から維持されてきました。
-
"テキストブロブ" 。NLTK と Pattern をベースに構築された、使いやすい NLP ツール Python API。
-
"スタンフォード・コアNLP" 。スタンフォード NLP グループによって開発された Java の NLP サービスとパッケージ。
-
"ゲンシム" 。Topic Modelling for Humans は、チェコデジタル数学ライブラリ プロジェクト用の Python スクリプトのコレクションとして始まりました。
-
"スパシー" 。トランスフォーマー向け GPU アクセラレーションを備えた Python と Cython を使用したエンドツーエンドの産業用 NLP ワークフロー。
-
"ファストテキスト" 。Facebook の AI 研究 (FAIR) ラボによって作成された、単語埋め込みの学習と文分類のための無料の軽量オープンソース NLP ライブラリです。
Spark NLP は、すべての NLP タスクと要件に対応する単一の統合ソリューションであり、実際の運用ユースケースでスケーラブルで高性能、かつ高精度な NLP ベースのソフトウェアを実現します。転移学習を活用し、研究や業界全体で最新の最先端のアルゴリズムとモデルを実装します。 Sparkは上記のライブラリを完全にサポートしていないため、Spark NLPは "スパークML"ミッションクリティカルな本番ワークフロー向けのエンタープライズグレードの NLP ライブラリとして、Spark の汎用インメモリ分散データ処理エンジンを活用します。そのアノテーターは、ルールベースのアルゴリズム、機械学習、TensorFlow を活用して、ディープラーニングの実装を強化します。これには、トークン化、レマタイズ化、ステミング、品詞タグ付け、固有表現認識、スペルチェック、感情分析などを含む一般的な NLP タスクが含まれます。
BERT (Bidirectional Encoder Representations from Transformers) は、NLP 用のトランスフォーマー ベースの機械学習手法です。事前トレーニングと微調整の概念を普及させました。 BERT のトランスフォーマー アーキテクチャは機械翻訳から生まれたもので、リカレント ニューラル ネットワーク (RNN) ベースの言語モデルよりも長期的な依存関係をより適切にモデル化します。また、すべてのトークンのランダムな 15% がマスクされ、モデルがそれを予測することで真の双方向性を実現するマスク言語モデリング (MLM) タスクも導入されました。
金融感情分析は、専門的な言語とその分野のラベル付きデータが不足しているため、困難です。 FinBERTは、事前学習済みのBERTに基づく言語モデルであり、ドメイン適応された。 "ロイターTRC2" 、金融コーパス、ラベル付きデータで微調整された( "金融フレーズバンク" )を使用して金融センチメントを分類します。研究者らはニュース記事から金融用語を含む4,500の文を抽出した。その後、金融のバックグラウンドを持つ 16 人の専門家と修士課程の学生が、その文章を肯定的、中立的、否定的と分類しました。 FinBERTと他の2つの事前学習済みパイプラインを使用して、2016年から2020年までのNASDAQ上場企業トップ10社の決算説明会の記録の感情を分析するためのエンドツーエンドのSparkワークフローを構築しました。 "説明文書DL" ) を Spark NLP から取得します。
Spark NLP の基盤となるディープラーニング エンジンは TensorFlow です。これは、モデルの構築を容易にし、どこでも堅牢な ML を生成でき、研究のための強力な実験を可能にする、エンドツーエンドのオープンソース 機械学習プラットフォームです。したがって、Sparkでパイプラインを実行する場合 `yarn cluster`モードでは、基本的に、1 つのマスター ノードと複数のワーカー ノード、およびクラスターにマウントされたネットワーク接続ストレージにわたって、データとモデルの並列化を伴う分散 TensorFlow を実行していました。
Horovod分散トレーニング
MapReduce 関連のパフォーマンスに関するコア Hadoop 検証は、TeraGen、TeraSort、TeraValidate、および DFSIO (読み取りと書き込み) を使用して実行されます。 TeraGenとTeraSortの検証結果は、 "Hadoop向けNetApp Eシリーズソリューション" AFFの「ストレージ階層化」セクションを参照してください。
お客様のご要望に基づき、Spark を使用した分散トレーニングは、さまざまなユースケースの中でも最も重要なものの 1 つであると考えています。この文書では、 "SparkのHovorod" NetApp All Flash FAS (AFF) ストレージ コントローラー、 Azure NetApp Files、 StorageGRIDを使用して、 NetApp のオンプレミス、クラウド ネイティブ、ハイブリッド クラウド ソリューションで Spark のパフォーマンスを検証します。
Horovod on Spark パッケージは、Horovod の便利なラッパーを提供します。これにより、Spark クラスターでの分散トレーニング ワークロードの実行が簡単になり、データ処理、モデル トレーニング、モデル評価がすべてトレーニング データと推論データが存在する Spark で実行される、緊密なモデル設計ループが可能になります。
Spark で Horovod を実行するための API には、高レベルの Estimator API と低レベルの Run API の 2 つがあります。どちらも Spark 実行プログラムで Horovod を起動するために同じ基本メカニズムを使用しますが、Estimator API はデータ処理、モデル トレーニング ループ、モデル チェックポイント、メトリック収集、分散トレーニングを抽象化します。 Horovod Spark Estimators、TensorFlow、Kerasを使用して、エンドツーエンドのデータ準備と分散トレーニングワークフローを構築しました。 "Kaggle Rossmann ストア売上"競争。
脚本 `keras_spark_horovod_rossmann_estimator.py`セクションをご覧ください"それぞれの主要なユースケース向けの Python スクリプト。"3 つの部分から構成されます。
-
最初の部分では、Kaggle によって提供され、コミュニティによって収集された CSV ファイルの初期セットに対してさまざまなデータ前処理手順を実行します。入力データは、 `Validation`サブセットとテストデータセット。
-
2 番目の部分では、対数シグモイド活性化関数と Adam オプティマイザーを備えた Keras ディープ ニューラル ネットワーク (DNN) モデルを定義し、Spark 上の Horovod を使用してモデルの分散トレーニングを実行します。
-
3 番目の部分では、検証セット全体の平均絶対誤差を最小化する最適なモデルを使用して、テスト データセットの予測を実行します。次に、出力 CSV ファイルを作成します。
セクションを参照"機械学習"さまざまな実行時間の比較結果。
Keras を使用したマルチワーカー ディープラーニングによる CTR 予測
ML プラットフォームとアプリケーションの最近の進歩により、大規模な学習に多くの注目が集まっています。クリックスルー率 (CTR) は、オンライン広告の表示回数 100 回あたりの平均クリックスルー数 (パーセントで表されます) として定義されます。これは、デジタル マーケティング、小売、電子商取引、サービス プロバイダーなど、さまざまな業界の垂直分野やユース ケースで重要な指標として広く採用されています。 CTRと分散トレーニングのパフォーマンス結果の適用の詳細については、"CTR予測パフォーマンスのためのディープラーニングモデル"セクション。
この技術レポートでは、 "Criteo テラバイトクリックログデータセット" (TR-4904 を参照) Keras を使用してマルチワーカー分散ディープラーニングを実施し、Deep and Cross Network (DCN) モデルを含む Spark ワークフローを構築し、ログ損失エラー関数の観点からそのパフォーマンスをベースライン Spark ML ロジスティック回帰モデルと比較します。 DCN は、制限された次数の有効な特徴相互作用を効率的にキャプチャし、高度に非線形な相互作用を学習し、手動の特徴エンジニアリングや徹底的な検索を必要とせず、計算コストが低くなります。
Web 規模の推奨システムのデータは大部分が離散的かつカテゴリ化されているため、特徴空間が大きくまばらになり、特徴の探索が困難になります。このため、ほとんどの大規模システムはロジスティック回帰などの線形モデルに制限されています。ただし、頻繁に予測される特徴を識別し、同時に目に見えない、またはまれなクロス特徴を探索することが、適切な予測を行うための鍵となります。線形モデルはシンプルで解釈しやすく、拡張も容易ですが、表現力には限界があります。
一方、クロス特徴はモデルの表現力の向上に重要であることが示されています。残念ながら、このような特徴を識別するには、多くの場合、手動の特徴エンジニアリングや徹底的な検索が必要になります。目に見えない機能の相互作用を一般化することは、多くの場合困難です。 DCN のようなクロスニューラルネットワークを使用すると、特徴の交差を明示的に自動的に適用することで、タスク固有の特徴エンジニアリングを回避できます。クロス ネットワークは複数のレイヤーで構成されており、相互作用の最高度はレイヤーの深さによって決定されると考えられます。各レイヤーは、既存の相互作用に基づいて高次の相互作用を生成し、前のレイヤーからの相互作用を維持します。
ディープ ニューラル ネットワーク (DNN) は、機能間の非常に複雑な相互作用をキャプチャできる可能性を秘めています。ただし、DCN と比較すると、ほぼ 1 桁多くのパラメータが必要となり、クロス フィーチャを明示的に形成できず、一部の種類のフィーチャの相互作用を効率的に学習できない可能性があります。クロスネットワークはメモリ効率が高く、実装が簡単です。クロスコンポーネントと DNN コンポーネントを共同でトレーニングすることで、予測機能のインタラクションを効率的にキャプチャし、Criteo CTR データセットで最先端のパフォーマンスを実現します。
DCN モデルは、埋め込みおよびスタッキング レイヤーから始まり、クロス ネットワークとディープ ネットワークが並列に続きます。次に、2 つのネットワークからの出力を結合する最終結合レイヤーが続きます。入力データは、スパースな特徴と密な特徴を持つベクトルにすることができます。 Sparkでは、ライブラリには次のような型が含まれています SparseVector。したがって、ユーザーはこれら 2 つを区別し、それぞれの関数やメソッドを呼び出すときに注意することが重要です。 CTR予測のようなWebスケールのレコメンデーションシステムでは、入力は主にカテゴリ特徴であり、例えば 'country=usa'。このような特徴は、多くの場合、ワンホットベクトルとしてエンコードされます。たとえば、 '[0,1,0, …]' 。ワンホットエンコーディング(OHE) `SparseVector`常に変化し、増え続ける語彙を持つ現実世界のデータセットを扱うときに役立ちます。例を修正しました "ディープクリック率"大規模な語彙を処理し、DCN の埋め込みおよびスタッキング層に埋め込みベクトルを作成します。
その "Criteo ディスプレイ広告データセット"広告のクリック率を予測します。 13 個の整数特徴と 26 個のカテゴリ特徴があり、各カテゴリは高いカーディナリティを持っています。このデータセットでは、入力サイズが大きいため、logloss の 0.001 の改善は実質的に重要です。大規模なユーザーベースに対する予測精度のわずかな向上は、企業の収益の大幅な増加につながる可能性があります。データセットには、7 日間の 11 GB のユーザー ログが含まれており、これは約 4,100 万件のレコードに相当します。 Sparkを使用しました `dataFrame.randomSplit()function`データをランダムに分割し、トレーニング用(80%)、クロス検証用(10%)、残りの10%をテスト用にします。
DCN は、Keras を使用して TensorFlow に実装されました。 DCN を使用してモデル トレーニング プロセスを実装する場合、主なコンポーネントは 4 つあります。
-
*データの処理と埋め込み。*実数値の特徴は、対数変換を適用することによって正規化されます。カテゴリ特徴量の場合、特徴量を6×(カテゴリカーディナリティ)1/4次元の稠密ベクトルに埋め込みます。すべての埋め込みを連結すると、次元 1026 のベクトルが生成されます。
-
最適化。 Adam オプティマイザーを使用してミニバッチ確率最適化を適用しました。バッチサイズは 512 に設定されました。ディープ ネットワークにバッチ正規化が適用され、勾配クリップ ノルムは 100 に設定されました。
-
正規化。 L2 正則化またはドロップアウトは効果的ではないことが判明したため、早期停止を使用しました。
-
*ハイパーパラメータ*隠し層の数、隠し層のサイズ、初期学習率、およびクロス層の数に対するグリッド検索に基づいて結果を報告します。隠し層の数は 2 ~ 5 で、隠し層のサイズは 32 ~ 1024 でした。 DCN の場合、クロス レイヤーの数は 1 ~ 6 でした。初期学習率は 0.0001 から 0.001 まで 0.0001 ずつ増分して調整されました。すべての実験では、トレーニング ステップ 150,000 で早期停止が適用され、それを超えるとオーバーフィッティングが発生し始めました。
検証に使用されるアーキテクチャ
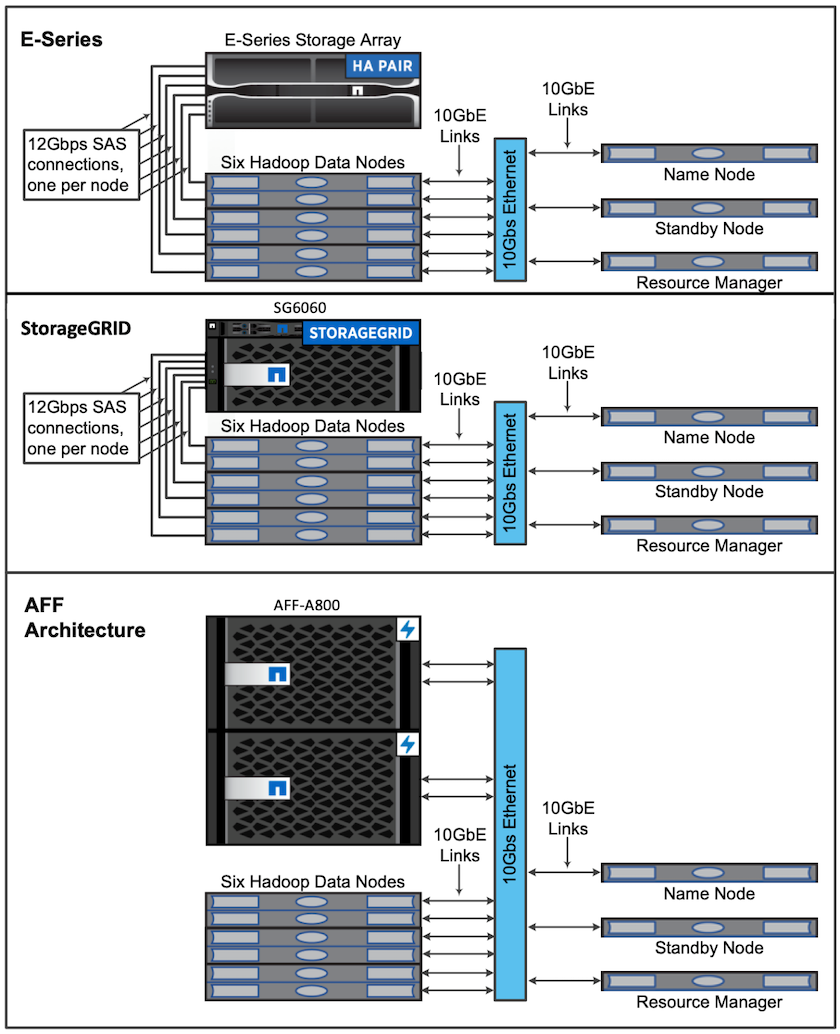
この検証では、 AFF-A800 HA ペアを持つ 4 つのワーカー ノードと 1 つのマスター ノードを使用しました。すべてのクラスター メンバーは 10GbE ネットワーク スイッチを介して接続されていました。
このNetApp Spark ソリューションの検証では、E5760、E5724、 AFF-A800 という 3 つの異なるストレージ コントローラを使用しました。 E シリーズ ストレージ コントローラは、12Gbps SAS 接続で 5 つのデータ ノードに接続されていました。 AFF HA ペア ストレージ コントローラは、10GbE 接続を介してエクスポートされた NFS ボリュームを Hadoop ワーカー ノードに提供します。 Hadoop クラスター メンバーは、E シリーズ、 AFF、およびStorageGRID Hadoop ソリューション内の 10GbE 接続を介して接続されていました。