AWS EC2 および FSx での Oracle 導入手順
 変更を提案
変更を提案
このセクションでは、FSx ストレージを使用して Oracle RDS カスタム データベースをデプロイする手順について説明します。
EC2 コンソール経由で Oracle 用の EC2 Linux インスタンスをデプロイする
AWS を初めて使用する場合は、まず AWS 環境をセットアップする必要があります。 AWS ウェブサイトのランディングページにあるドキュメントタブには、AWS EC2 コンソール経由で Oracle データベースをホストするために使用できる Linux EC2 インスタンスをデプロイする方法に関する EC2 手順リンクが提供されています。次のセクションでは、これらの手順の概要を説明します。詳細については、リンクされた AWS EC2 固有のドキュメントを参照してください。
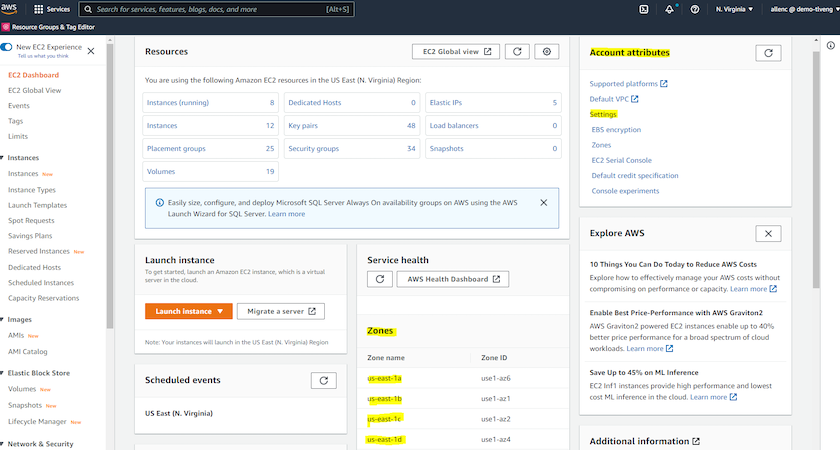
AWS EC2 環境の設定
EC2 および FSx サービスで Oracle 環境を実行するために必要なリソースをプロビジョニングするには、AWS アカウントを作成する必要があります。必要な詳細は、次の AWS ドキュメントに記載されています。
主なトピック:
-
AWS にサインアップします。
-
キーペアを作成します。
-
セキュリティ グループを作成します。
AWSアカウント属性で複数のアベイラビリティゾーンを有効にする
アーキテクチャ図に示されている Oracle の高可用性構成の場合、リージョン内で少なくとも 4 つの可用性ゾーンを有効にする必要があります。災害復旧に必要な距離を満たすために、複数のアベイラビリティーゾーンを異なるリージョンに配置することもできます。
Oracle データベースをホストするための EC2 インスタンスの作成と接続
チュートリアルを見る"Amazon EC2 Linuxインスタンスを使い始める"段階的な展開手順とベスト プラクティスについて説明します。
主なトピック:
-
概要。
-
前提条件。
-
ステップ 1: インスタンスを起動します。
-
ステップ 2: インスタンスに接続します。
-
ステップ 3: インスタンスをクリーンアップします。
次のスクリーンショットは、Oracle を実行するための EC2 コンソールを使用した m5 タイプの Linux インスタンスのデプロイメントを示しています。
-
EC2 ダッシュボードから黄色の [インスタンスの起動] ボタンをクリックして、EC2 インスタンスのデプロイ ワークフローを開始します。
-
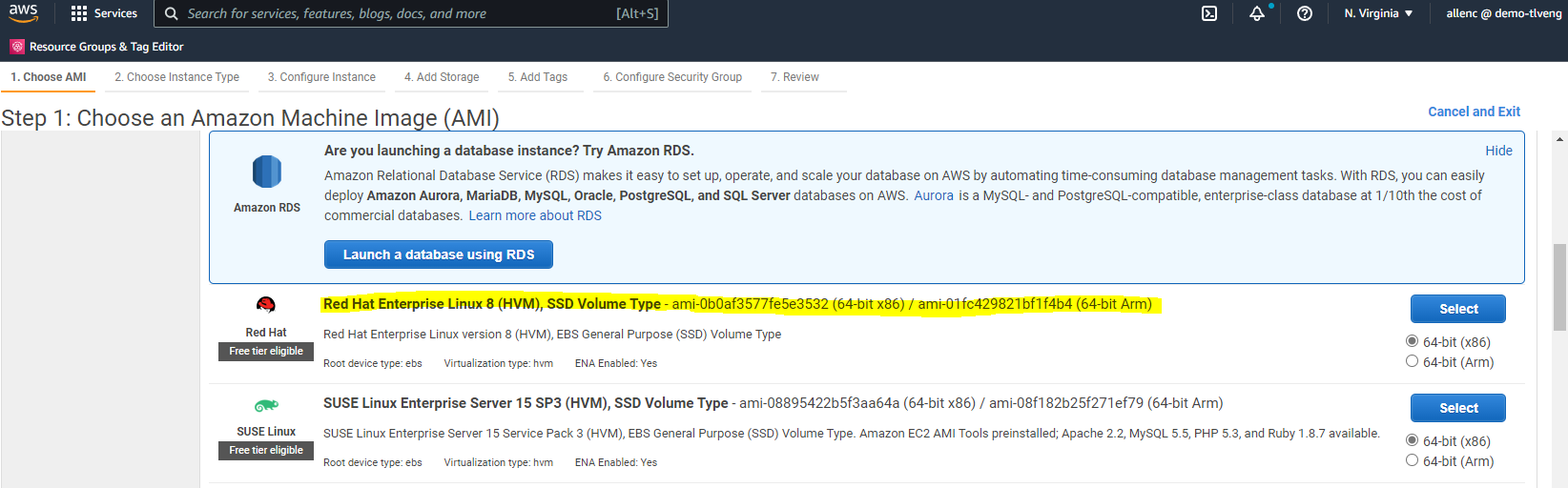
ステップ 1 で、「Red Hat Enterprise Linux 8 (HVM)、SSD ボリューム タイプ - ami-0b0af3577fe5e3532 (64 ビット x86) / ami-01fc429821bf1f4b4 (64 ビット Arm)」を選択します。
-
ステップ 2 では、Oracle データベースのワークロードに基づいて、適切な CPU とメモリ割り当てを持つ m5 インスタンス タイプを選択します。 「次へ: インスタンスの詳細を構成する」をクリックします。
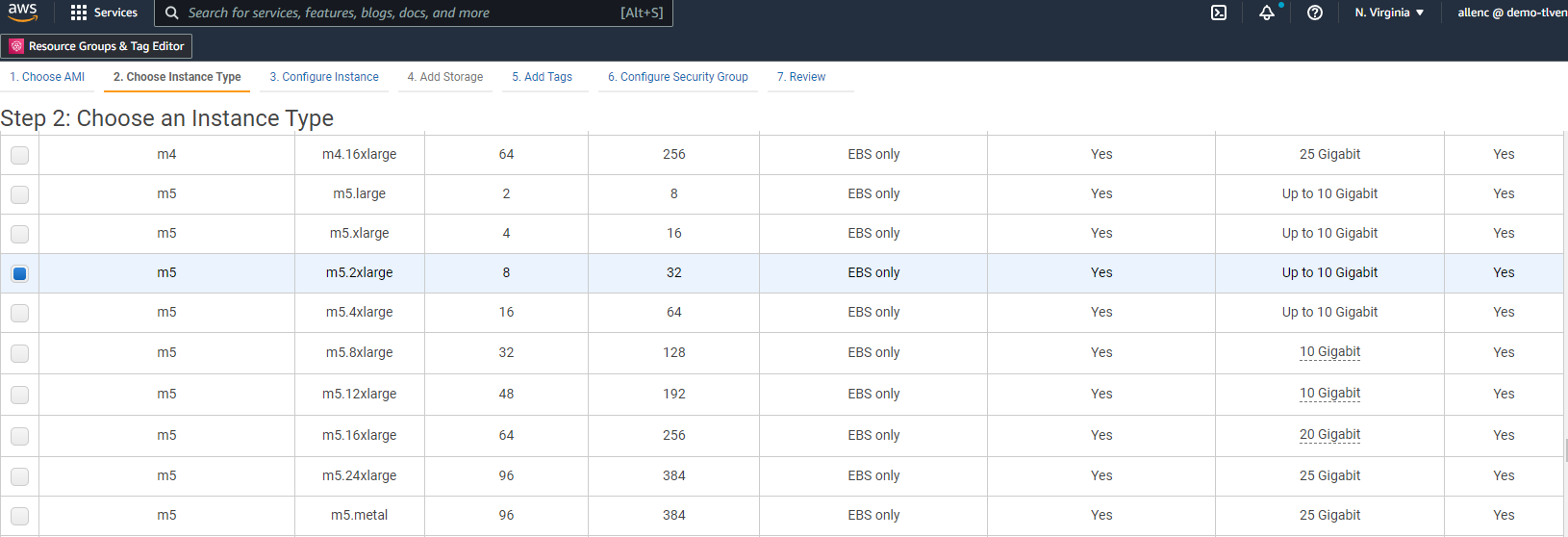
-
ステップ 3 では、インスタンスを配置する VPC とサブネットを選択し、パブリック IP の割り当てを有効にします。 「次へ: ストレージの追加」をクリックします。
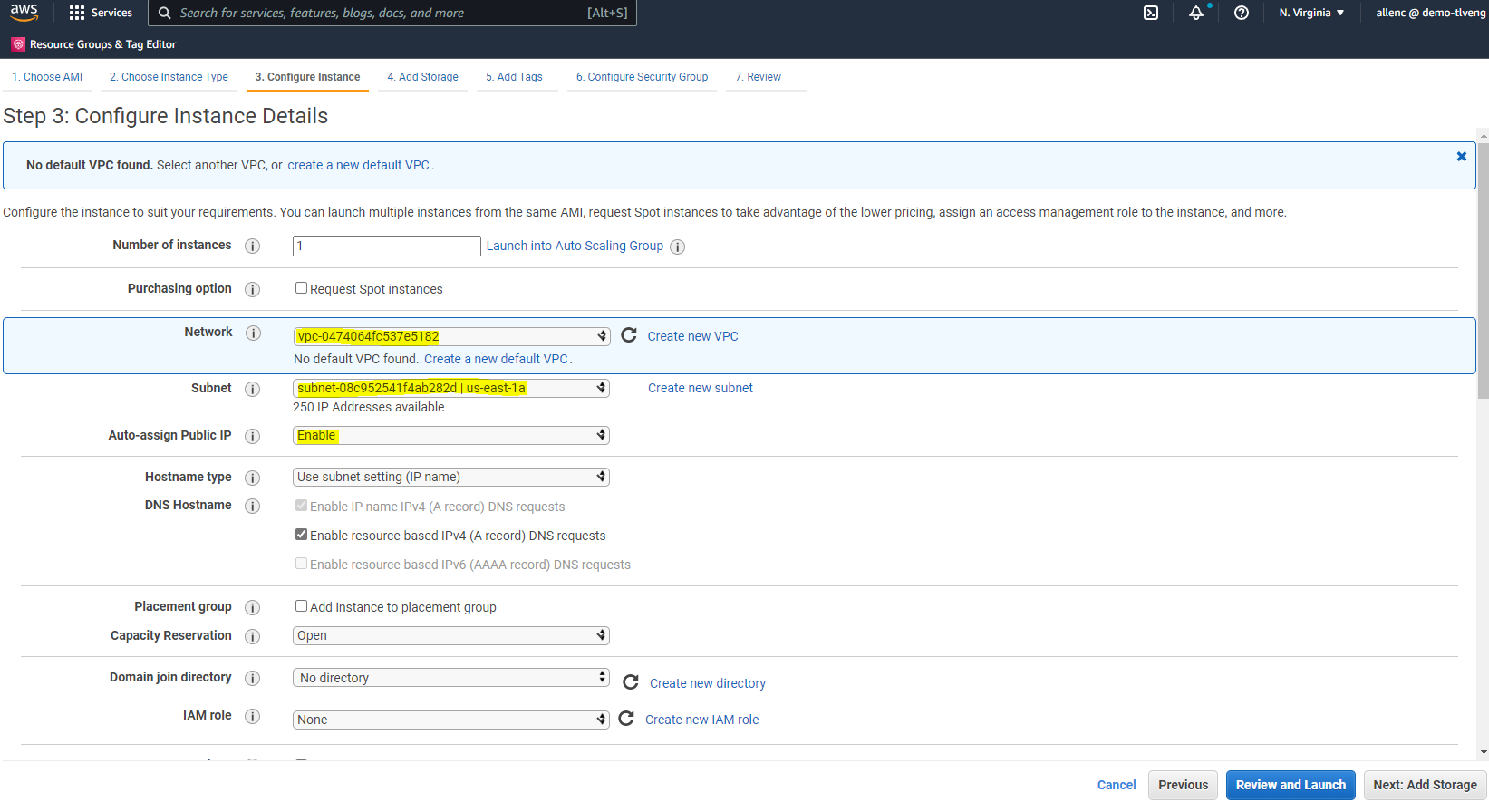
-
手順 4 では、ルート ディスクに十分な領域を割り当てます。スワップを追加するためのスペースが必要になる場合があります。デフォルトでは、EC2 インスタンスはゼロのスワップ領域を割り当てますが、これは Oracle の実行には最適ではありません。
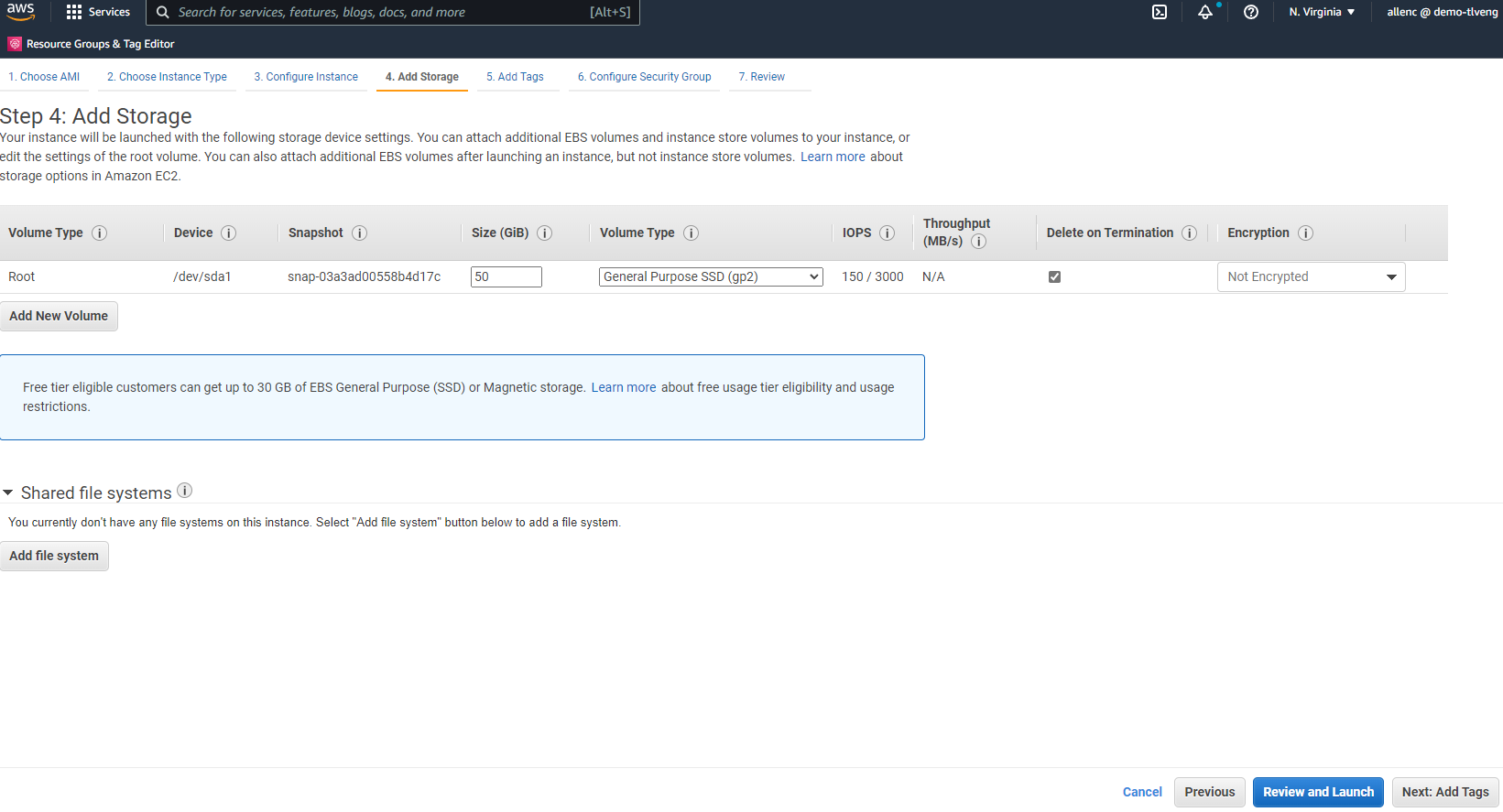
-
ステップ 5 では、必要に応じてインスタンス識別用のタグを追加します。
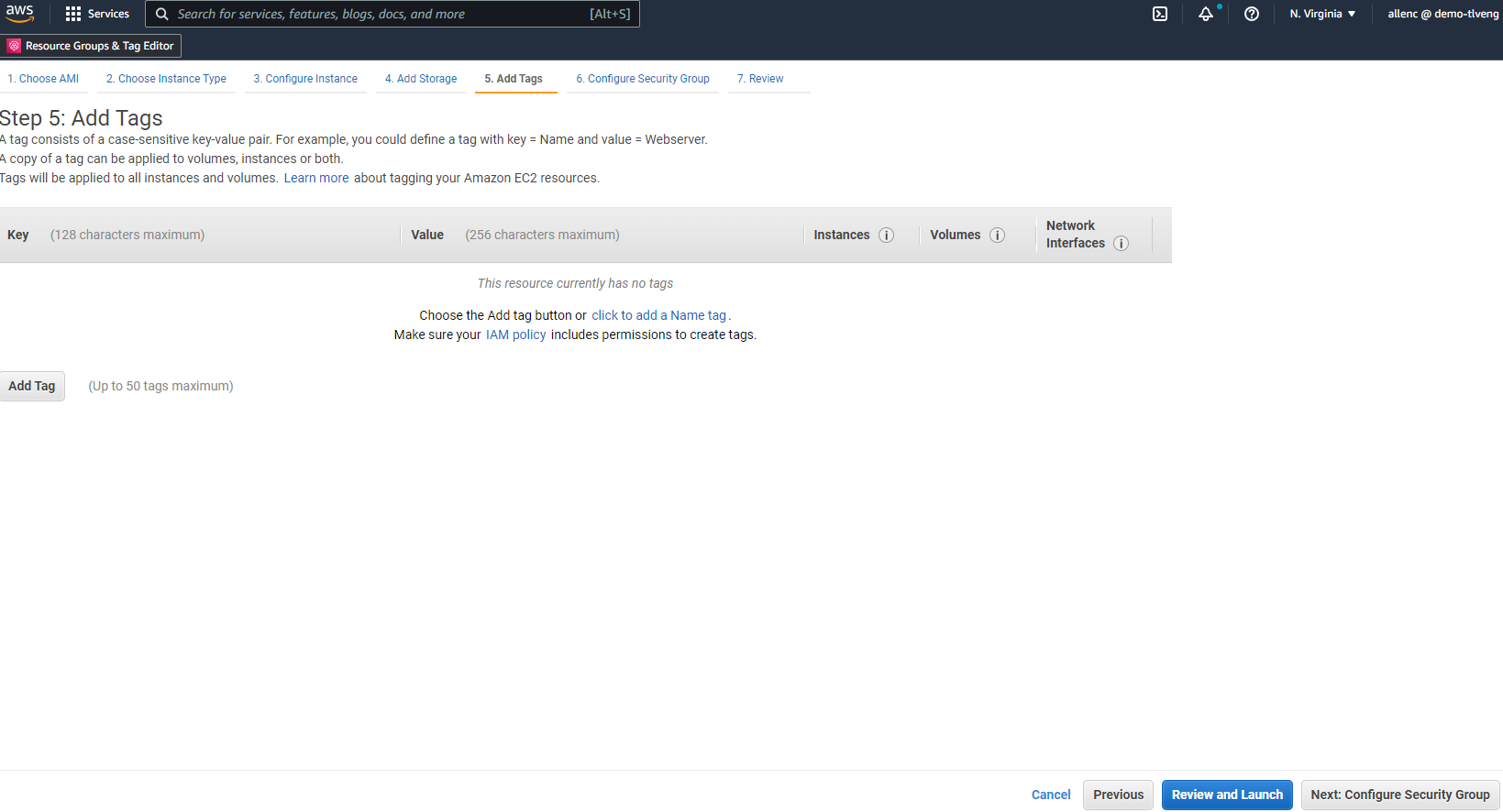
-
ステップ 6 で、既存のセキュリティ グループを選択するか、インスタンスに必要なインバウンドおよびアウトバウンド ポリシーを持つ新しいセキュリティ グループを作成します。
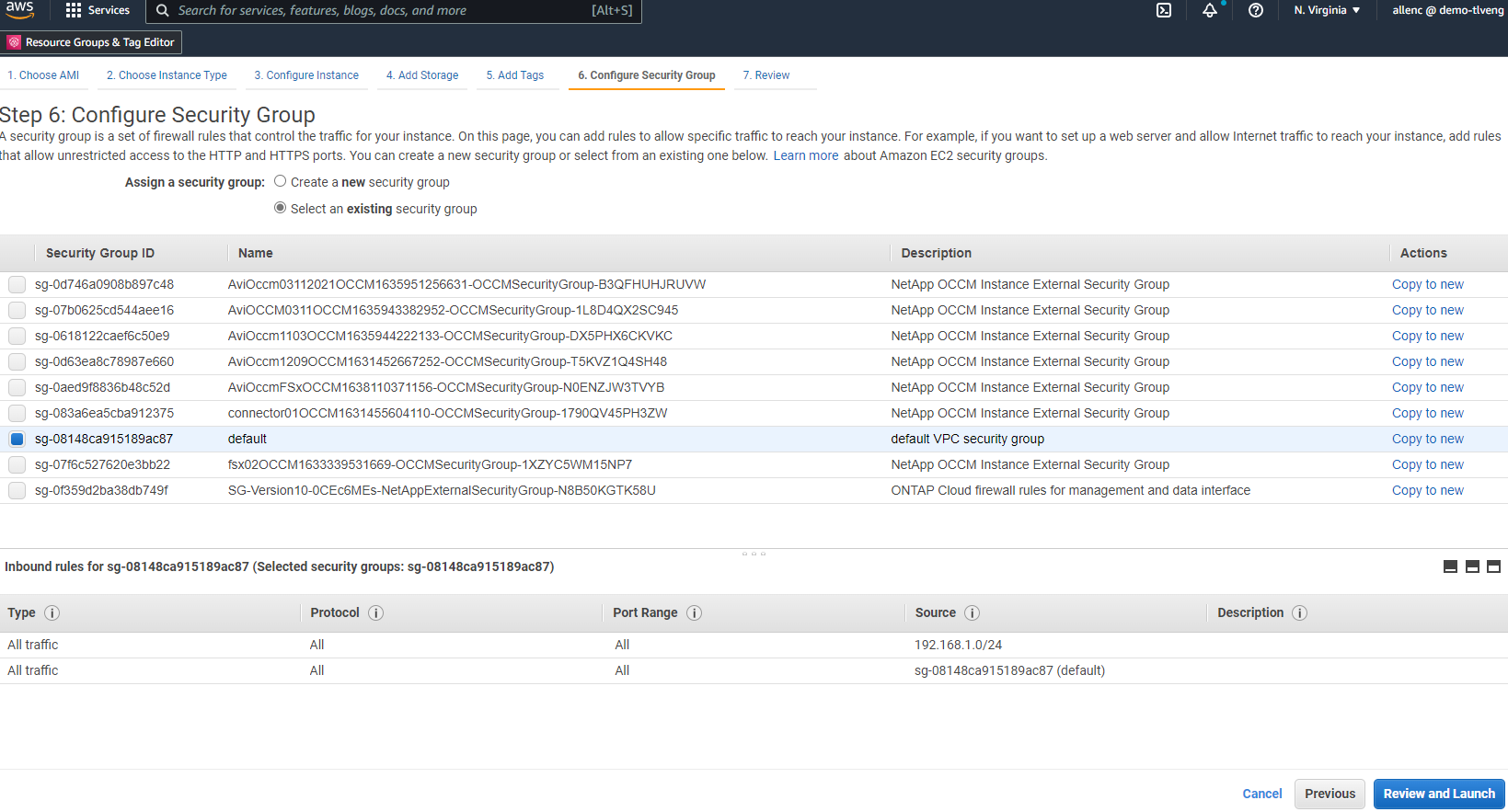
-
ステップ 7 で、インスタンス構成の概要を確認し、「起動」をクリックしてインスタンスのデプロイを開始します。インスタンスにアクセスするためのキー ペアを作成するか、キー ペアを選択するように求められます。
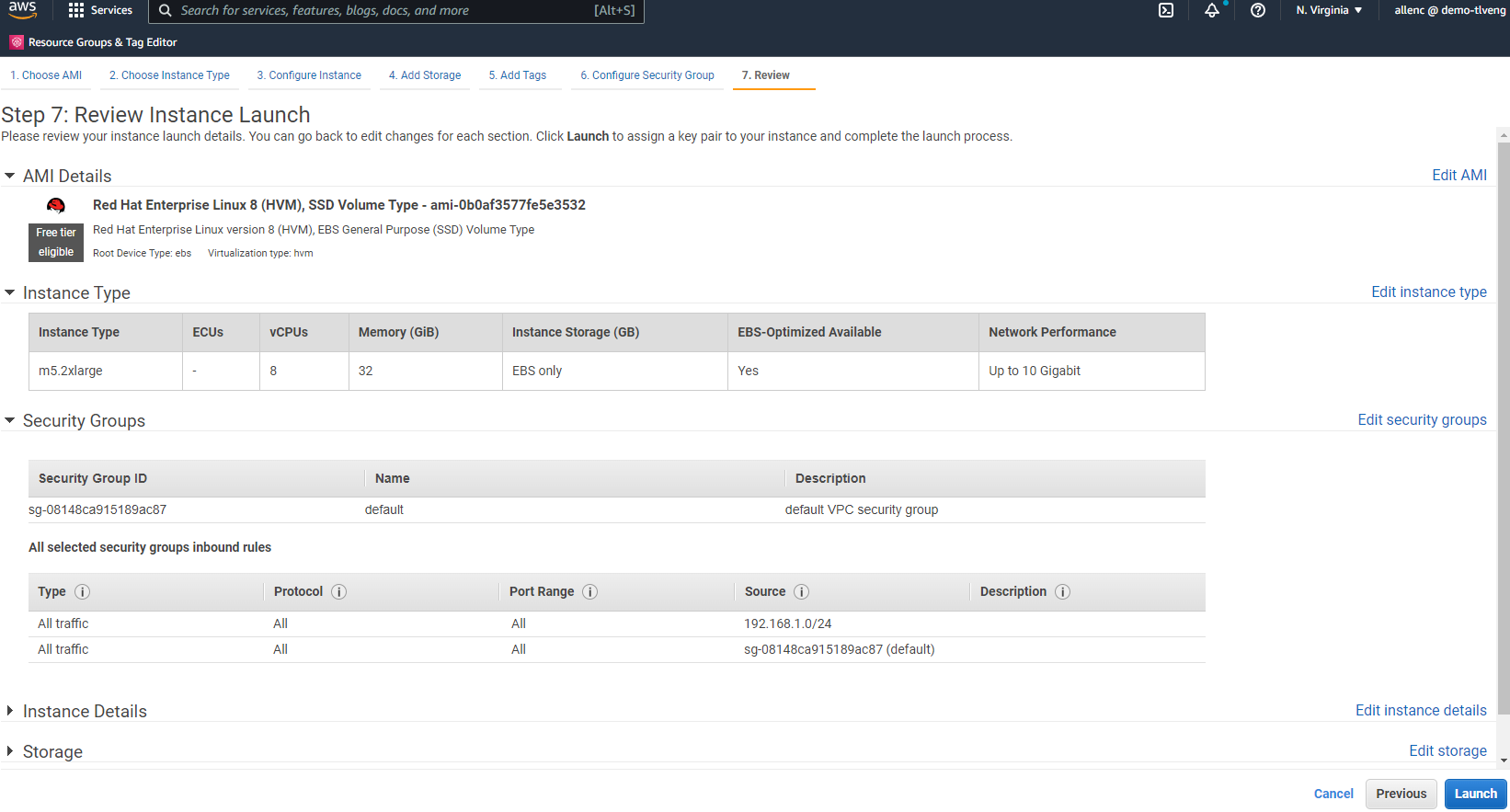
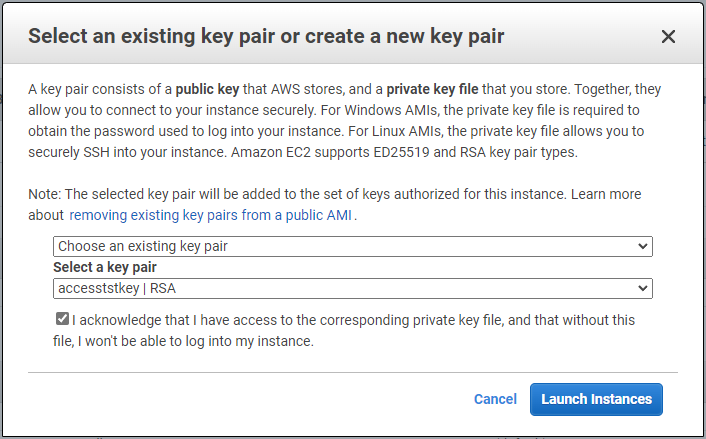
-
SSH キーペアを使用して EC2 インスタンスにログインします。必要に応じて、キー名とインスタンス IP アドレスを変更します。
ssh -i ora-db1v2.pem ec2-user@54.80.114.77
アーキテクチャ図に示されているように、指定されたアベイラビリティーゾーンにプライマリおよびスタンバイ Oracle サーバーとして 2 つの EC2 インスタンスを作成する必要があります。
Oracle データベース ストレージ用の FSx ONTAPファイル システムをプロビジョニングする
EC2 インスタンスのデプロイメントでは、OS に EBS ルート ボリュームが割り当てられます。 FSx ONTAPファイル システムは、Oracle バイナリ、データ、ログ ボリュームを含む Oracle データベース ストレージ ボリュームを提供します。 FSx ストレージ NFS ボリュームは、AWS FSx コンソールまたは Oracle インストールからプロビジョニングでき、自動化パラメータファイルでユーザーが構成したとおりにボリュームを割り当てる構成自動化が可能です。
FSx ONTAPファイルシステムの作成
このドキュメントを参照 "FSx ONTAPファイルシステムの管理"FSx ONTAPファイルシステムを作成します。
重要な考慮事項:
-
SSD ストレージ容量。最小 1024 GiB、最大 192 TiB。
-
プロビジョニングされた SSD IOPS。ワークロード要件に基づき、ファイル システムあたり最大 80,000 SSD IOPS。
-
スループット容量。
-
管理者 fsxadmin/vsadmin のパスワードを設定します。 FSx 構成の自動化に必要です。
-
バックアップとメンテナンス。毎日の自動バックアップを無効にします。データベース ストレージのバックアップは、 SnapCenter のスケジュール設定によって実行されます。
-
SVM 詳細ページから SVM 管理 IP アドレスとプロトコル固有のアクセス アドレスを取得します。 FSx 構成の自動化に必要です。
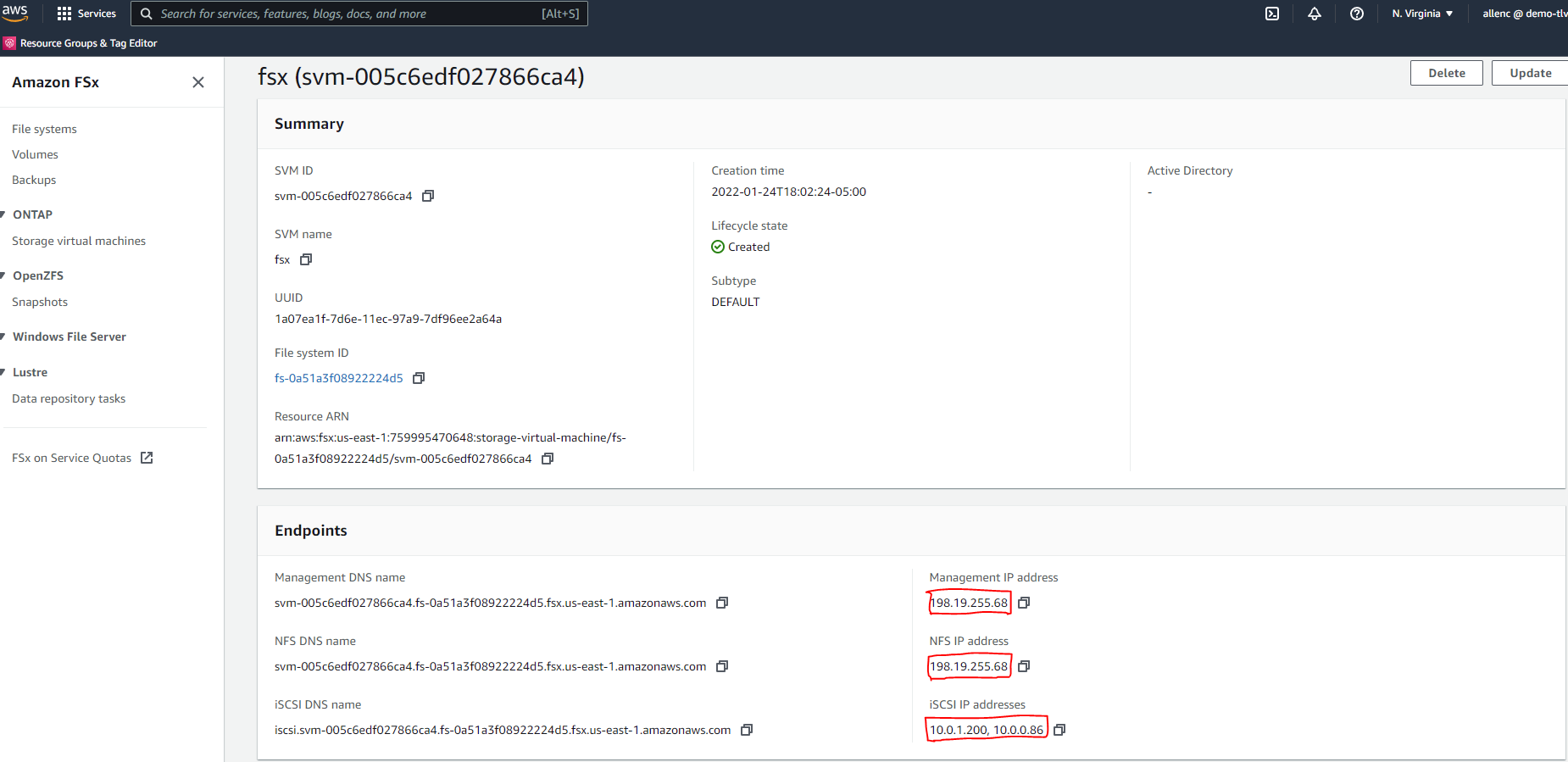
プライマリまたはスタンバイ HA FSx クラスターを設定するには、次の手順を参照してください。
-
FSx コンソールから、「ファイル システムの作成」をクリックして、FSx プロビジョニング ワークフローを開始します。
-
Amazon FSx ONTAPを選択します。次に「次へ」をクリックします。
-
[標準作成] を選択し、[ファイル システムの詳細] でファイル システムに「Multi-AZ HA」という名前を付けます。データベースのワークロードに基づいて、最大 80,000 SSD IOPS までの自動またはユーザー プロビジョニング IOPS を選択します。 FSx ストレージには、バックエンドに最大 2TiB の NVMe キャッシュが搭載されており、さらに高い IOPS を実現できます。
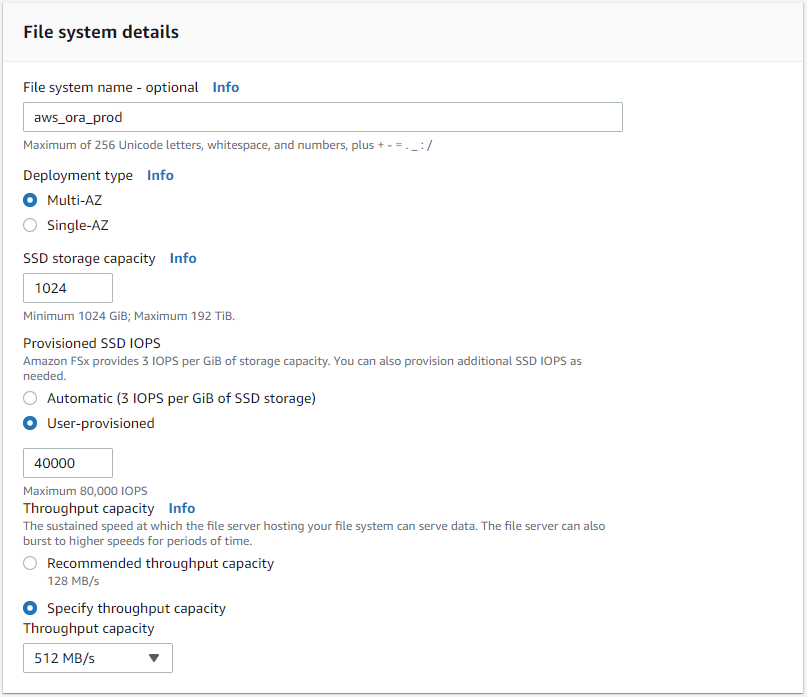
-
[ネットワークとセキュリティ] セクションで、VPC、セキュリティ グループ、サブネットを選択します。これらは FSx のデプロイメント前に作成する必要があります。 FSx クラスターのロール (プライマリまたはスタンバイ) に基づいて、FSx ストレージ ノードを適切なゾーンに配置します。
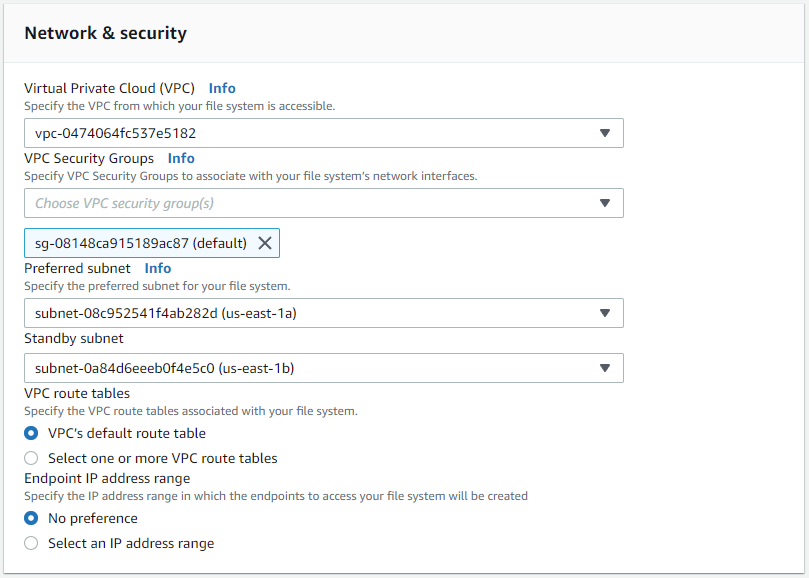
-
「セキュリティと暗号化」セクションで、デフォルトを受け入れ、fsxadmin パスワードを入力します。
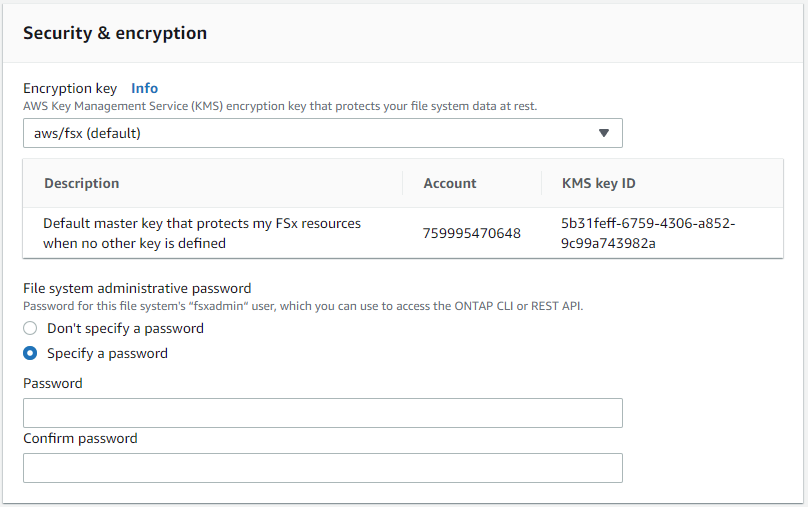
-
SVM 名と vsadmin パスワードを入力します。
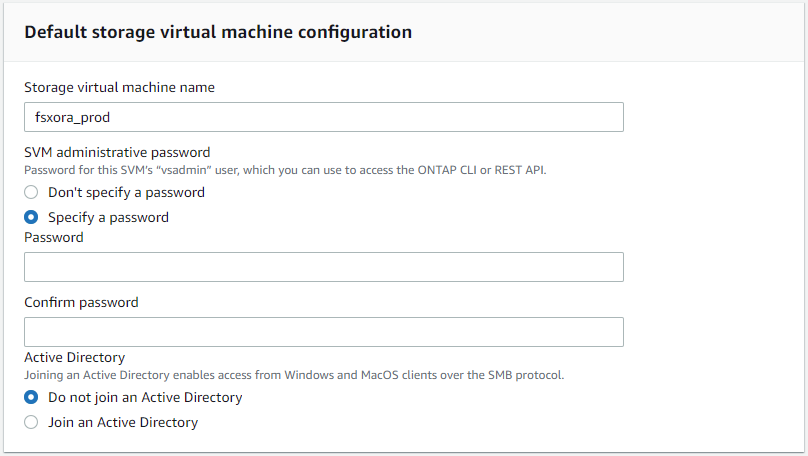
-
ボリューム構成は空白のままにしておきます。この時点ではボリュームを作成する必要はありません。
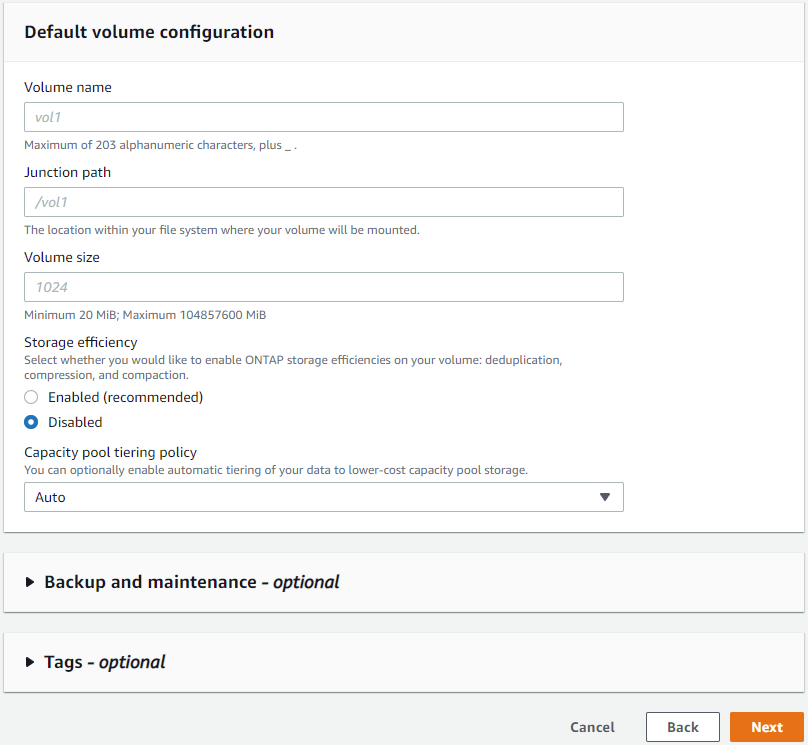
-
概要ページを確認し、「ファイル システムの作成」をクリックして、FSx ファイル システムのプロビジョニングを完了します。
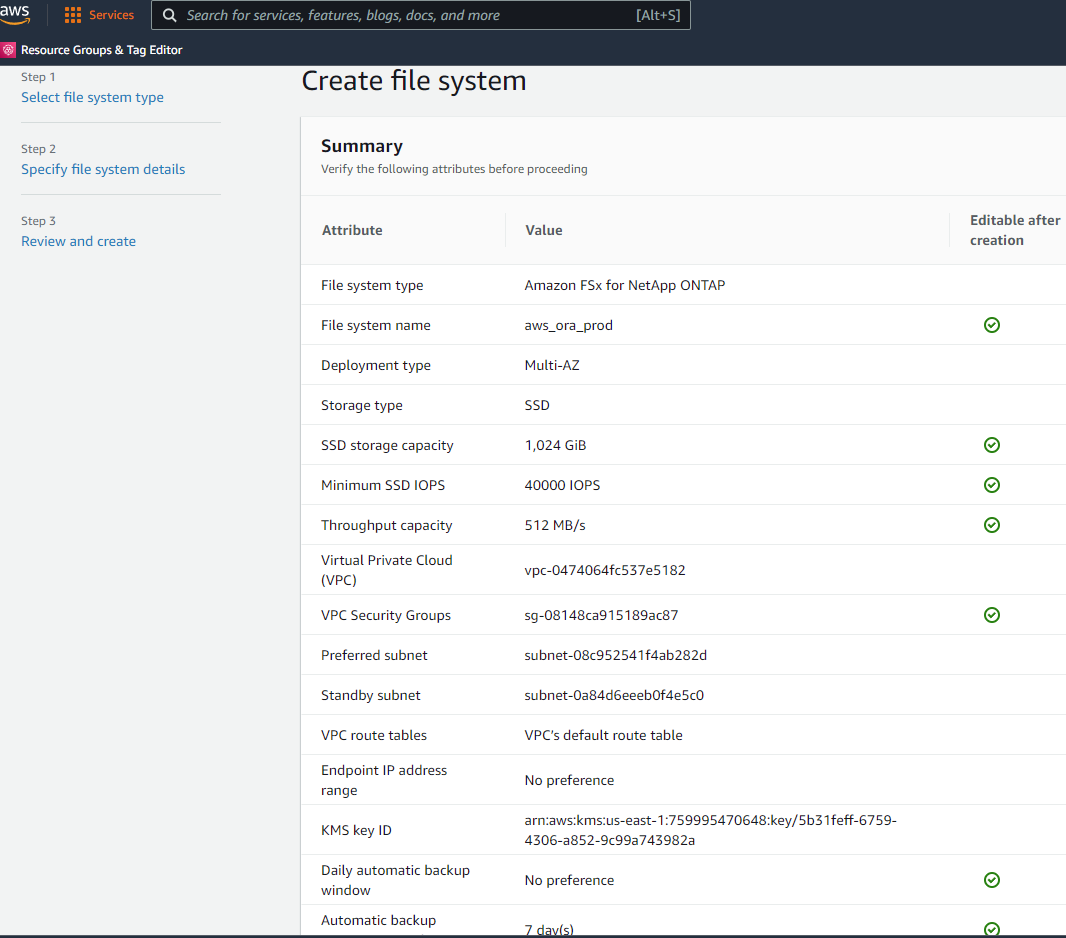
Oracleデータベースのデータベースボリュームのプロビジョニング
見る"FSx ONTAPボリュームの管理 - ボリュームの作成"詳細については。
重要な考慮事項:
-
データベース ボリュームのサイズを適切に設定します。
-
パフォーマンス構成の容量プール階層化ポリシーを無効にします。
-
NFS ストレージ ボリューム用に Oracle dNFS を有効にします。
-
iSCSI ストレージ ボリュームのマルチパスを設定します。
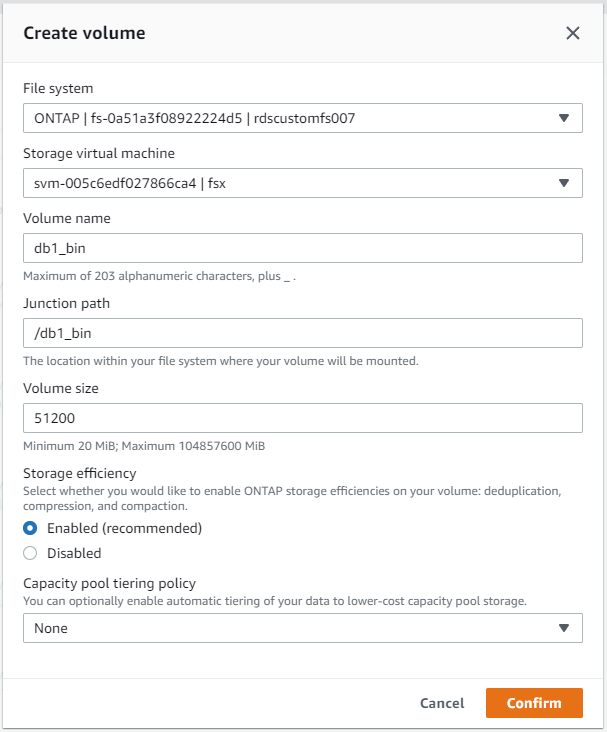
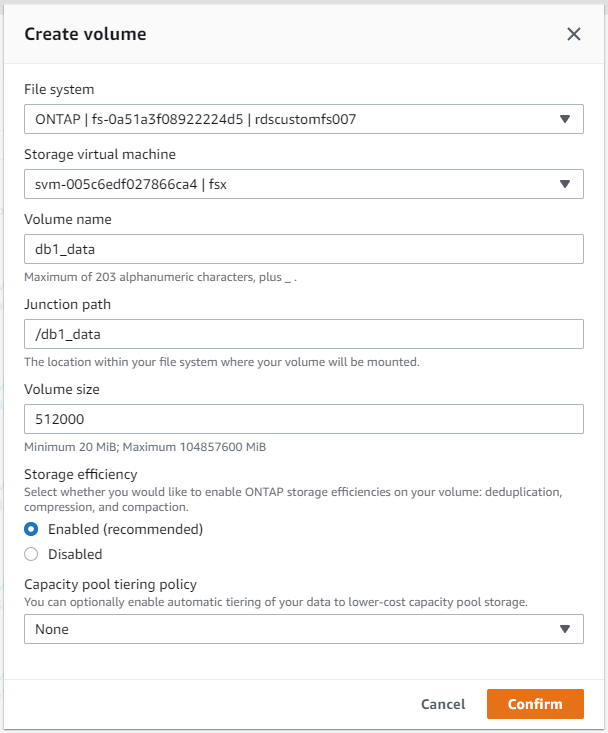
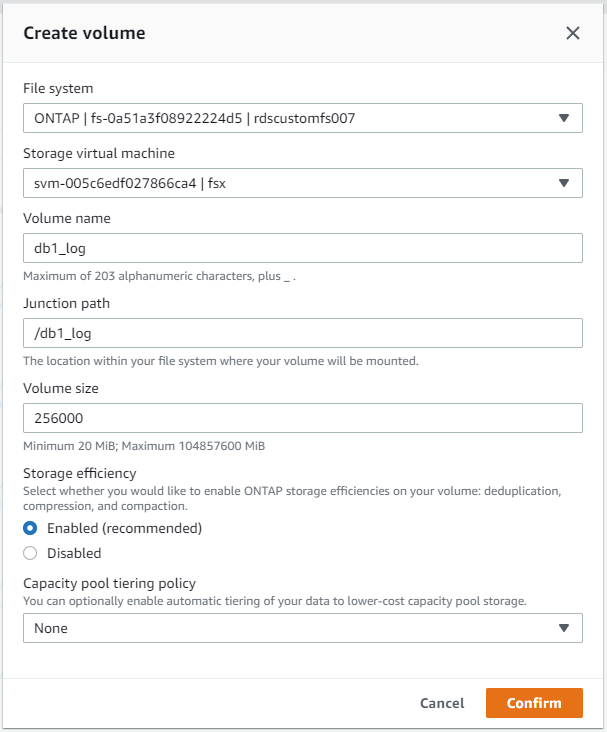
FSxコンソールからデータベースボリュームを作成する
AWS FSx コンソールから、Oracle データベースファイルストレージ用に 3 つのボリュームを作成できます。1 つは Oracle バイナリ用、1 つは Oracle データ用、1 つは Oracle ログ用です。適切に識別するために、ボリュームの命名が Oracle ホスト名 (自動化ツールキットのホスト ファイルで定義) と一致していることを確認します。この例では、EC2 インスタンスの一般的な IP アドレスベースのホスト名ではなく、EC2 Oracle ホスト名として db1 を使用します。

|
iSCSI LUN の作成は、現在 FSx コンソールではサポートされていません。 Oracle 用の iSCSI LUN の展開では、 NetApp Automation Toolkit を使用したONTAPの自動化を使用してボリュームと LUN を作成できます。 |
FSx データベースボリュームを使用して EC2 インスタンスに Oracle をインストールして設定する
NetApp自動化チームは、ベスト プラクティスに従って EC2 インスタンス上で Oracle のインストールと構成を実行するための自動化キットを提供しています。自動化キットの現在のバージョンは、デフォルトの RU パッチ 19.8 を使用して NFS 上の Oracle 19c をサポートしています。自動化キットは、必要に応じて他の RU パッチに簡単に適応できます。
自動化を実行するためのAnsibleコントローラーを準備する
「Oracle データベースをホストするための EC2 インスタンスの作成と接続 「Ansible コントローラーを実行するための小さな EC2 Linux インスタンスをプロビジョニングします。」 RedHat を使用する代わりに、2vCPU と 8G RAM を搭載した Amazon Linux t2.large で十分なはずです。
NetApp Oracle導入自動化ツールキットを取得する
ステップ1でプロビジョニングしたEC2 Ansibleコントローラインスタンスにec2-userとしてログインし、ec2-userのホームディレクトリから以下を実行します。 `git clone`自動化コードのコピーを複製するコマンド。
git clone https://github.com/NetApp-Automation/na_oracle19c_deploy.gitgit clone https://github.com/NetApp-Automation/na_rds_fsx_oranfs_config.git自動化ツールキットを使用して Oracle 19c の自動デプロイメントを実行する
詳細な説明をご覧ください"CLI デプロイメント Oracle 19c データベース"CLI 自動化を使用して Oracle 19c をデプロイします。ホスト アクセス認証にパスワードではなく SSH キー ペアを使用しているため、プレイブック実行のコマンド構文が少し変更されます。次のリストは概要です。
-
デフォルトでは、EC2 インスタンスはアクセス認証に SSH キー ペアを使用します。 Ansibleコントローラー自動化ルートディレクトリから
/home/ec2-user/na_oracle19c_deploy、 そして `/home/ec2-user/na_rds_fsx_oranfs_config`SSHキーのコピーを作成する `accesststkey.pem`ステップ「Oracle データベースをホストするための EC2 インスタンスの作成と接続 。" -
ec2-user として EC2 インスタンス DB ホストにログインし、python3 ライブラリをインストールします。
sudo yum install python3 -
ルート ディスク ドライブから 16G のスワップ領域を作成します。デフォルトでは、EC2 インスタンスはスワップ領域をゼロで作成します。次の AWS ドキュメントに従ってください。"スワップファイルを使用して、Amazon EC2 インスタンスでスワップ領域として機能するメモリを割り当てるにはどうすればよいですか?" 。
-
Ansibleコントローラーに戻る(
cd /home/ec2-user/na_rds_fsx_oranfs_config)、適切な要件と `linux_config`タグ。ansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t requirements_configansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t linux_config -
に切り替える `/home/ec2-user/na_oracle19c_deploy-master`ディレクトリを開き、READMEファイルを読んで、グローバル `vars.yml`関連するグローバルパラメータを含むファイル。
-
入力する `host_name.yml`関連するパラメータを含むファイル `host_vars`ディレクトリ。
-
Linux 用のプレイブックを実行し、vsadmin パスワードの入力を求められた場合は Enter キーを押します。
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t linux_config -e @vars/vars.yml -
Oracle のプレイブックを実行し、vsadmin パスワードの入力を求められた場合は Enter キーを押します。
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t oracle_config -e @vars/vars.yml
必要に応じて、SSH キー ファイルの権限ビットを 400 に変更します。 Oracleホストを変更する(`ansible_host`の中で `host_vars`ファイルの IP アドレスを EC2 インスタンスのパブリック アドレスに変更します。
プライマリとスタンバイの FSx HA クラスタ間のSnapMirror の設定
高可用性と災害復旧のために、プライマリ FSx ストレージ クラスターとスタンバイ FSx ストレージ クラスター間にSnapMirrorレプリケーションを設定できます。他のクラウド ストレージ サービスとは異なり、FSx を使用すると、ユーザーは希望する頻度とレプリケーション スループットでストレージ レプリケーションを制御および管理できます。また、可用性に影響を与えることなく HA/DR をテストすることもできます。
次の手順は、プライマリ FSx ストレージ クラスターとスタンバイ FSx ストレージ クラスター間のレプリケーションを設定する方法を示しています。
-
プライマリ クラスターとスタンバイ クラスターのピアリングを設定します。 fsxadmin ユーザーとしてプライマリ クラスターにログインし、次のコマンドを実行します。この相互作成プロセスでは、プライマリ クラスターとスタンバイ クラスターの両方で作成コマンドが実行されます。交換する `standby_cluster_name`ご使用の環境に適した名前を付けます。
cluster peer create -peer-addrs standby_cluster_name,inter_cluster_ip_address -username fsxadmin -initial-allowed-vserver-peers * -
プライマリ クラスターとスタンバイ クラスター間の vServer ピアリングを設定します。 vsadmin ユーザーとしてプライマリ クラスターにログインし、次のコマンドを実行します。交換する
primary_vserver_name、standby_vserver_name、 `standby_cluster_name`ご使用の環境に適した名前を付けてください。vserver peer create -vserver primary_vserver_name -peer-vserver standby_vserver_name -peer-cluster standby_cluster_name -applications snapmirror -
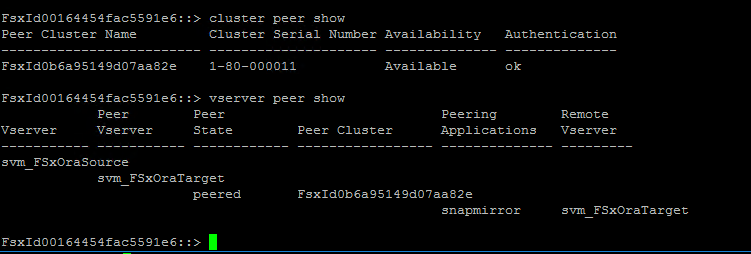
クラスターと vserver ピアリングが正しく設定されていることを確認します。
-
プライマリ FSx クラスターの各ソース ボリュームに対して、スタンバイ FSx クラスターにターゲット NFS ボリュームを作成します。環境に応じてボリューム名を置き換えます。
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -type DPvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -type DPvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -type DP -
データ アクセスに iSCSI プロトコルが採用されている場合は、Oracle バイナリ、Oracle データ、および Oracle ログ用の iSCSI ボリュームと LUN を作成することもできます。スナップショット用にボリュームに約 10% の空き領域を残します。
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_bin/dr_db1_bin_01 -size 45G -ostype linuxvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_data/dr_db1_data_01 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_02 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_03 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_04 -size 100G -ostype linuxボリューム作成 -ボリューム dr_db1_log -アグリゲート aggr1 -サイズ 250G -状態 online -ポリシー デフォルト -unix-permissions ---rwxr-xr-x -タイプ RW
lun create -path /vol/dr_db1_log/dr_db1_log_01 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_02 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_03 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_04 -size 45G -ostype linux -
iSCSI LUN の場合、バイナリ LUN を例として、各 LUN の Oracle ホスト イニシエーターのマッピングを作成します。 igroup を環境に適した名前に置き換え、追加の LUN ごとに lun-id を増分します。
lun mapping create -path /vol/dr_db1_bin/dr_db1_bin_01 -igroup ip-10-0-1-136 -lun-id 0lun mapping create -path /vol/dr_db1_data/dr_db1_data_01 -igroup ip-10-0-1-136 -lun-id 1 -
プライマリ データベース ボリュームとスタンバイ データベース ボリューム間にSnapMirror関係を作成します。ご使用の環境に適した SVM 名に置き換えてください。
snapmirror create -source-path svm_FSxOraSource:db1_bin -destination-path svm_FSxOraTarget:dr_db1_bin -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_data -destination-path svm_FSxOraTarget:dr_db1_data -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_log -destination-path svm_FSxOraTarget:dr_db1_log -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DP
このSnapMirrorセットアップは、NFS データベース ボリューム用のNetApp Automation Toolkit を使用して自動化できます。ツールキットは、NetApp のパブリック GitHub サイトからダウンロードできます。
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitセットアップとフェイルオーバーのテストを行う前に、README の手順をよくお読みください。
|
|
Oracle バイナリをプライマリ クラスターからスタンバイ クラスターに複製すると、Oracle ライセンスに影響が出る可能性があります。詳細については、Oracle ライセンス担当者にお問い合わせください。代替案としては、リカバリおよびフェイルオーバー時に Oracle をインストールして構成しておくことです。 |
SnapCenterの展開
SnapCenterのインストール
フォローする"SnapCenter Serverのインストール"SnapCenterサーバーをインストールします。このドキュメントでは、スタンドアロンのSnapCenterサーバーのインストール方法について説明します。 SnapCenterの SaaS バージョンはベータ版レビュー中であり、まもなく利用可能になる可能性があります。必要に応じて、 NetApp の担当者に可用性を確認してください。
EC2 Oracle ホスト用のSnapCenterプラグインを構成する
-
SnapCenter の自動インストールが完了したら、 SnapCenterサーバーがインストールされている Windows ホストの管理ユーザーとしてSnapCenterにログインします。

-
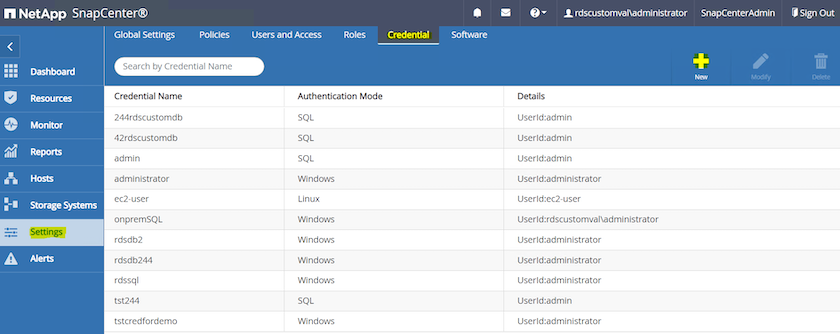
左側のメニューから、[設定] をクリックし、[資格情報と新規] をクリックして、 SnapCenterプラグインのインストール用の ec2-user 資格情報を追加します。
-
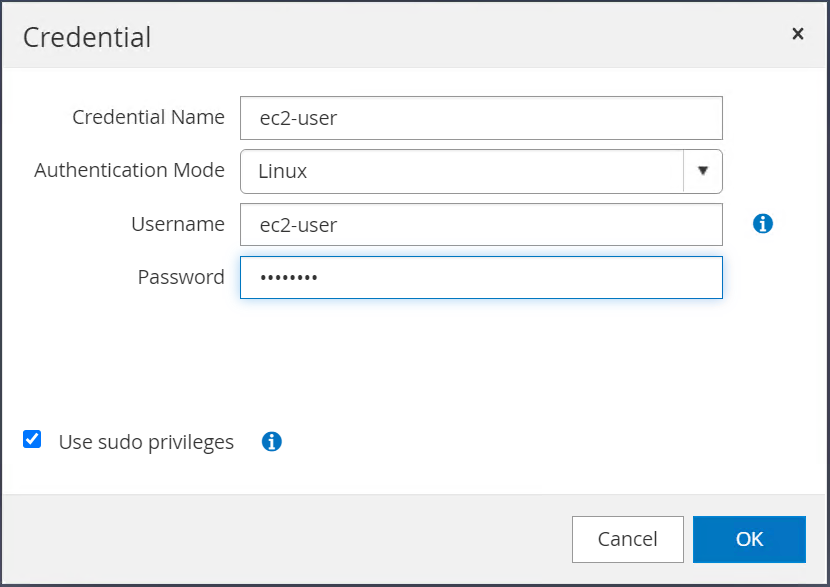
ec2-userのパスワードをリセットし、パスワードSSH認証を有効にするには、
/etc/ssh/sshd_configEC2 インスタンス ホスト上のファイル。 -
「sudo 権限を使用する」チェックボックスが選択されていることを確認します。前の手順で ec2-user のパスワードをリセットしました。
-
名前解決のために、 SnapCenterサーバー名と IP アドレスを EC2 インスタンス ホスト ファイルに追加します。
[ec2-user@ip-10-0-0-151 ~]$ sudo vi /etc/hosts [ec2-user@ip-10-0-0-151 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.1.233 rdscustomvalsc.rdscustomval.com rdscustomvalsc
-
SnapCenterサーバーのWindowsホストで、EC2インスタンスホストのIPアドレスをWindowsホストファイルに追加します。
C:\Windows\System32\drivers\etc\hosts。10.0.0.151 ip-10-0-0-151.ec2.internal
-
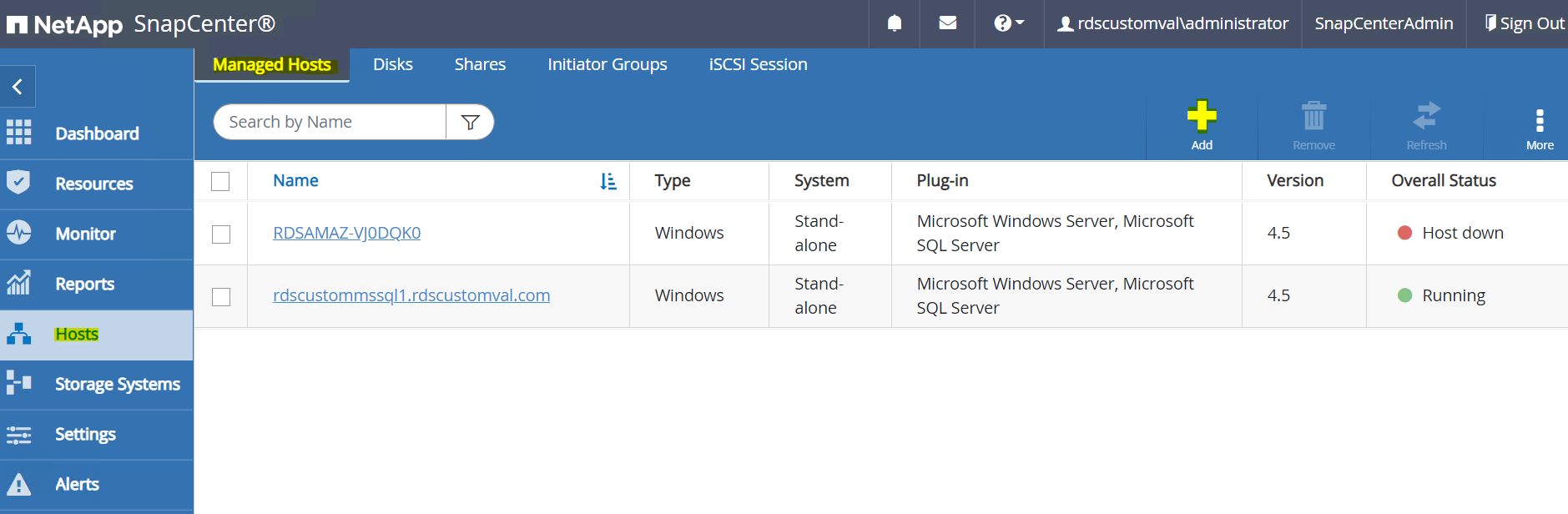
左側のメニューで、[ホスト] > [管理対象ホスト] を選択し、[追加] をクリックして EC2 インスタンス ホストをSnapCenterに追加します。
Oracle データベースをチェックし、送信する前に「詳細オプション」をクリックします。
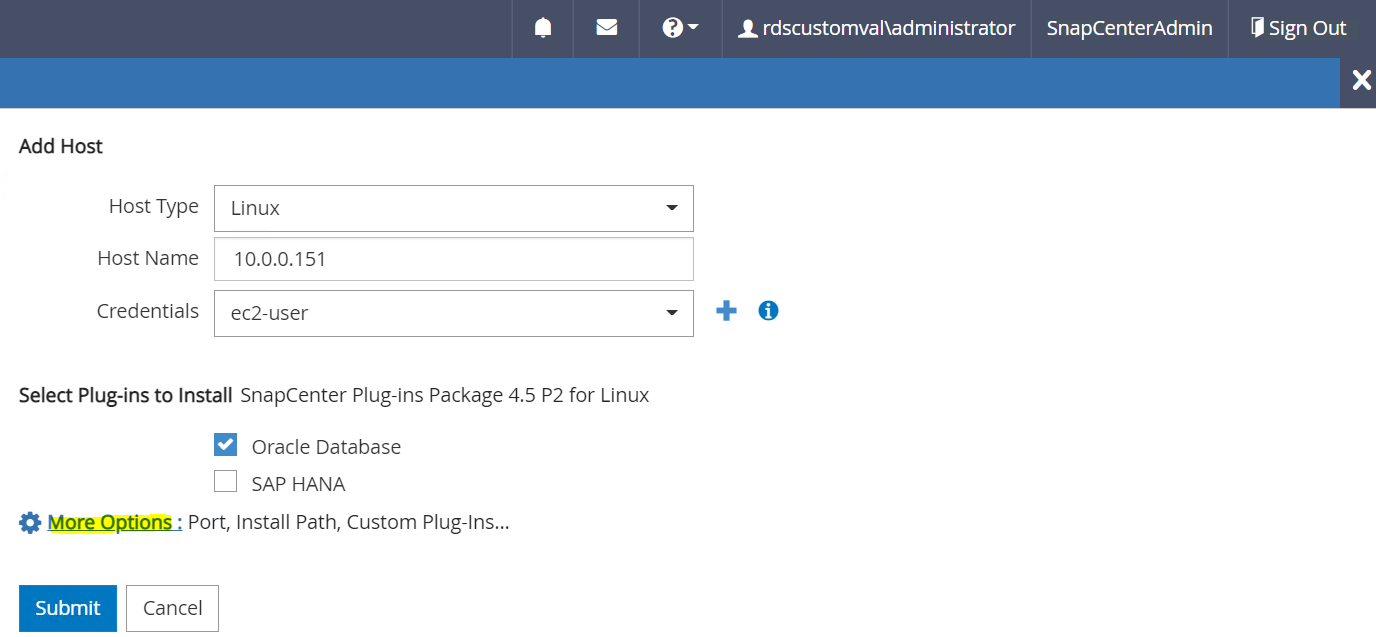
「インストール前チェックをスキップ」をチェックします。インストール前のチェックをスキップすることを確認し、「保存後に送信」をクリックします。
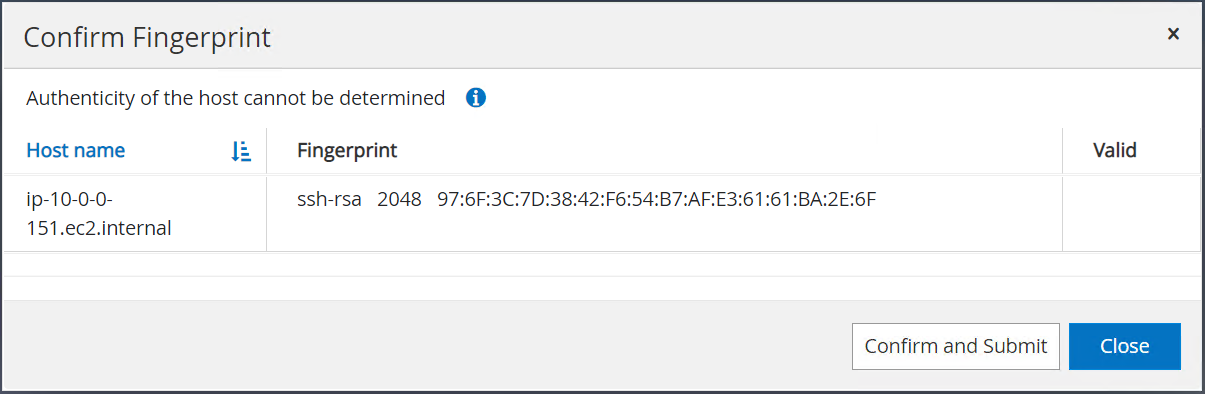
指紋の確認を求めるメッセージが表示されたら、「確認して送信」をクリックします。
プラグインの構成が成功すると、管理対象ホストの全体的なステータスが「実行中」と表示されます。

Oracle データベースのバックアップ ポリシーを構成する
このセクションを参照してください"SnapCenterでデータベースバックアップポリシーを設定する"Oracle データベース バックアップ ポリシーの構成の詳細。
通常、完全なスナップショット Oracle データベース バックアップ用のポリシーと、Oracle アーカイブ ログのみのスナップショット バックアップ用のポリシーを作成する必要があります。
|
|
バックアップ ポリシーで Oracle アーカイブ ログ プルーニングを有効にして、ログ アーカイブ領域を制御できます。 HA または DR のスタンバイ ロケーションにレプリケートする必要があるため、「セカンダリ レプリケーション オプションの選択」で「ローカル Snapshot コピーの作成後にSnapMirror を更新する」をオンにします。 |
Oracle データベースのバックアップとスケジュールを構成する
SnapCenterのデータベース バックアップはユーザーが構成可能で、個別に設定することも、リソース グループ内のグループとして設定することもできます。バックアップ間隔は、RTO と RPO の目標によって異なります。 NetApp、迅速なリカバリを実現するために、数時間ごとに完全なデータベース バックアップを実行し、10 ~ 15 分などのより高い頻度でログ バックアップをアーカイブすることを推奨しています。
Oracleのセクションを参照してください"データベースを保護するためのバックアップポリシーを実装する"セクションで作成したバックアップポリシーを実装するための詳細な手順については、Oracle データベースのバックアップ ポリシーを構成するバックアップ ジョブのスケジュール設定にも使用できます。
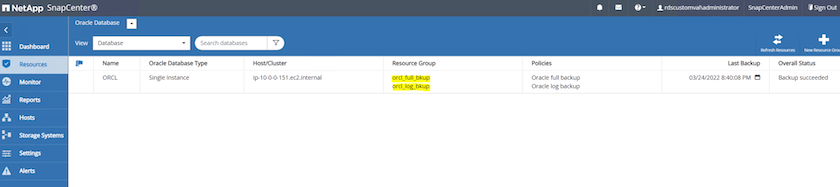
次の図は、Oracle データベースをバックアップするために設定されたリソース グループの例を示しています。