

FC から IP への移行を停止させる準備をしています
 変更を提案
変更を提案
移行プロセスを開始する前に、構成が要件を満たしていることを確認する必要があります。
コンソールログを有効にする
NetAppでは、使用しているデバイスでコンソールロギングをイネーブルにし、この手順を実行する際に次のアクションを実行することを強く推奨します。
-
メンテナンス中はAutoSupportを有効のままにします。
-
メンテナンスの前後にメンテナンスAutoSupportメッセージをトリガーして、メンテナンスアクティビティ中にケースの作成を無効にします。
ナレッジベースの記事を参照してください "スケジュールされたメンテナンス時間中にケースの自動作成を停止する方法"。
-
任意のCLIセッションのセッションロギングをイネーブルにします。セッションログを有効にする方法については、ナレッジベースの記事の「セッション出力のログ」セクションを参照してください "ONTAPシステムへの接続を最適化するためのPuTTYの設定方法"。
FC から IP への移行を停止するための一般的な要件
既存の MetroCluster FC 構成が次の要件を満たしている必要があります。
-
2 ノード構成であり、すべてのノードで ONTAP 9.8 以降が実行されている必要があります。
2 ノードのファブリック接続または拡張 MetroCluster です。
-
MetroCluster のインストールと設定の手順に記載されているすべての要件とケーブル接続を満たしている必要があります。
-
NetApp Storage Encryption ( NSE )では設定できません。
-
MDV ボリュームは暗号化できません。
MetroCluster サイトから 6 つのすべてのノードのリモートコンソールアクセスが必要です。または、手順で必要に応じてサイト間の移動を計画しておく必要があります。
FC から IP への移行を停止させるために、ドライブシェルフを再利用し、ドライブ要件を満たしておく必要があります
ストレージシェルフに利用可能な十分なスペアドライブとルートアグリゲートスペースがあることを確認する必要があります。
既存のストレージシェルフを再利用する
この手順を使用する場合、既存のストレージシェルフは新しい構成で使用できるように保持されます。node_A_1 - FC と node_B_1 - FC を削除した場合、既存のドライブシェルフは cluster_B の node_A_1 - IP と node_B_2 - IP に接続され、 node_B_1 - IP と node_B_2 の node_B_2 - IP に接続されます
-
既存のストレージシェルフ( node_A_1 の FC および node_B_1 に接続されたシェルフ)が新しいプラットフォームモデルでサポートされている必要があります。
既存のシェルフが新しいプラットフォームモデルでサポートされていない場合は、を参照してください "新しいコントローラで既存シェルフを使用できない場合の停止を伴う移行( ONTAP 9.8 以降)"。
-
プラットフォームについて、ドライブなどの制限を超えないようにする必要があります
追加のコントローラのストレージ要件
2 つのコントローラ( node_B_2 - IP と node_B_2 - IP )の構成が 2 ノードから 4 ノードに変更されるため、必要に応じてストレージを追加する必要があります。
-
既存のシェルフで使用可能なスペアドライブに応じて、追加のコントローラに対応するドライブを追加する必要があります。
この場合、次の図に示すように、追加のストレージシェルフが必要になることがあります。
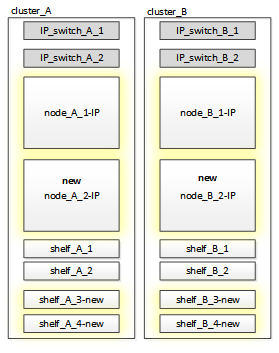
3 台目と 4 台目のコントローラ( node_B_2 - IP および node_B_2 - IP )のそれぞれに 14 ~ 18 本のドライブを追加する必要があります。
-
3 本のプール 0 ドライブ
-
プール 1 ドライブ × 3
-
2 本のスペアドライブ
-
システムボリューム用に 6 ~ 10 台のドライブ
-
-
新しいノードを含む構成が、ドライブ数、ルートアグリゲートのサイズ容量など、構成のプラットフォーム制限を超えないようにする必要があります
この情報は、各プラットフォームモデルの NetApp Hardware Universe _ で確認できます。
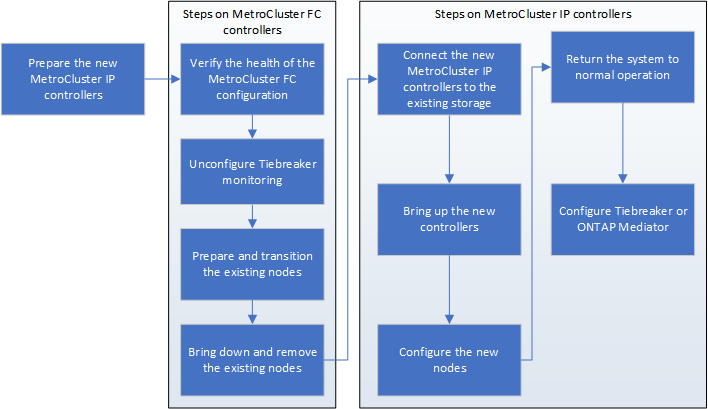
停止を伴う移行のワークフロー
移行を成功させるには、特定のワークフローに従う必要があります。
移行を準備する際は、サイト間の移動を計画します。リモートノードがラックに設置されてケーブル接続されたら、ノードへのシリアルターミナルアクセスが必要です。ノードが設定されるまでサービスプロセッサへのアクセスは許可されません。
MetroCluster FC ノードから MetroCluster IP ノードへのポートのマッピング
MetroCluster FC ノードのポートと LIF の設定を、交換する MetroCluster IP ノードと互換性があるように調整する必要があります。
アップグレードプロセスで最初に新しいノードがブートされると、各ノードは交換するノードの最新の設定を使用します。node_A_1 の IP をブートする際、 ONTAP は、 node_A_1 の FC で使用されていたポート上で LIF をホストしようとします。
移行手順では、クラスタ LIF 、管理 LIF 、およびデータ LIF の構成が正しくなるように、古いノードと新しいノードの両方で手順を実行します。
-
既存の MetroCluster FC ポートの用途と新しいノードでの MetroCluster IP インターフェイスのポートの用途が競合していないかを特定します。
次の表を使用して、新しい MetroCluster IP コントローラの MetroCluster IP ポートを特定する必要があります。次に、 MetroCluster FC ノードのそれらのポートにデータ LIF またはクラスタ LIF が存在するかどうかを確認して記録します。
これらの競合するデータ LIF または MetroCluster FC ノード上のクラスタ LIF は、移行手順の該当するステップで移動されます。
次の表に、 MetroCluster IP ポートをプラットフォームモデル別に示します。VLAN ID 列は無視してかまいません。
プラットフォームモデル
MetroCluster の IP ポート
VLAN ID
AFF A800
e0b
使用されません
e1b
AFF A700 および FAS9000
e5
e5b
AFF A320
e0g
E0h
AFF A300 および FAS8200
E1A
e1b
FAS8300 / A400 / FAS8700
E1A
10.
e1b
20
AFF A250 および FAS500f
e0c
10.
e0b
20
次の表に記入して、移行手順で後ほど参照できます。
ポート
対応する MetroCluster IP インターフェイスポート(上の表を参照)
MetroCluster FC ノードのこれらのポートで LIF が競合しています
node_A_1 の FC 上の最初の MetroCluster IP ポート
node_A_1 の FC 上の 2 番目の MetroCluster IP ポート
node_B_1 の最初の MetroCluster IP ポート: FC
node_B_1 の 2 つ目の MetroCluster IP ポート: FC
-
新しいコントローラで使用できる物理ポートとポートでホストできる LIF を確認します。
コントローラのポートの用途は、 MetroCluster IP 構成で使用するプラットフォームモデルと IP スイッチモデルによって異なります。新しいプラットフォームのポート使用量を NetApp Hardware Universe から収集できます。
-
必要に応じて、 node_A_1 の FC と node_A_1 の IP のポート情報を記録します。
この表は、移行手順を実行するときに参照します。
node_A_1 の列で、新しいコントローラモジュールの物理ポートを追加し、新しいノードの IPspace とブロードキャストドメインを計画します。
node_A_1 - FC
node_A_1 の IP
LIF
ポート
IPspace
ブロードキャストドメイン
ポート
IPspace
ブロードキャストドメイン
クラスタ 1
クラスタ 2
クラスタ 3
クラスタ 4
ノード管理
クラスタ管理
データ 1
データ 2.
データ 3
データ 4.
SAN
クラスタ間ポート
-
必要に応じて、 node_B_1 FC のすべてのポート情報を記録します。
この表は、アップグレード手順を実行するときに参照します。
node_B_1 の IP の列で、新しいコントローラモジュールの物理ポートを追加し、新しいノードの LIF ポートの使用、 IPspace 、およびブロードキャストドメインを計画します。
node_B_1 - FC
node_B_1 - IP
LIF
物理ポート
IPspace
ブロードキャストドメイン
物理ポート
IPspace
ブロードキャストドメイン
クラスタ 1
クラスタ 2
クラスタ 3
クラスタ 4
ノード管理
クラスタ管理
データ 1
データ 2.
データ 3
データ 4.
SAN
クラスタ間ポート
MetroCluster IP コントローラの準備
4 つの新しい MetroCluster IP ノードを準備し、正しいバージョンの ONTAP をインストールする必要があります。
このタスクは新しい各ノードで実行する必要があります。
-
node_A_1 の IP
-
Node_a_2-IP
-
node_B_1 - IP
-
node_B_2 - IP
ノードは新しい * ストレージシェルフに接続する必要があります。既存のストレージシェルフにデータを格納している状態は * 接続しないでください。
ここ手順で説明する手順は、コントローラとシェルフがラックに設置されたときに実行することも、あとで実行することもできます。いずれの場合も、構成をクリアし、ノードを既存のストレージシェルフに接続する前 * および MetroCluster FC ノードの構成を変更する前 * に、ノードを準備する必要があります。

|
MetroCluster FC コントローラに接続された既存のストレージシェルフに MetroCluster IP コントローラを接続した状態では、この手順を実行しないでください。 |
この手順では、ノードの設定をクリアし、新しいドライブのメールボックスのリージョンをクリアします。
-
コントローラモジュールを新しいストレージシェルフに接続します。
-
メンテナンスモードで、コントローラモジュールとシャーシの HA 状態を表示します。
「 ha-config show 」
すべてのコンポーネントの HA 状態は「 mccip 」である必要があります。
-
表示されたコントローラまたはシャーシのシステム状態が正しくない場合は、 HA 状態を設定します。
「 ha-config modify controller mccip 」「 ha-config modify chassis mccip 」
-
メンテナンスモードを終了します。
「 halt 」
コマンドの実行後、ノードが LOADER プロンプトで停止するまで待ちます。
-
4 つのすべてのノードで次の手順を繰り返して、設定をクリアします。
-
環境変数をデフォルト値に設定します。
「デフォルト設定」
-
環境を保存します。
'aveenv
さようなら
-
-
ブートメニューの 9a オプションを使用して、次の手順を繰り返して 4 つのノードをすべてブートします。
-
LOADER プロンプトで、ブートメニューを起動します。
「 boot_ontap menu
-
起動メニューでオプション [9a`] を選択して、コントローラを再起動します。
-
-
ブートメニューのオプション「 5 」を使用して、 4 つのノードのそれぞれをメンテナンスモードでブートします。
-
システム ID と 4 つの各ノードの ID を記録します。
「 sysconfig 」を使用できます
-
node_A_1 の IP と node_B_1 の IP について、次の手順を繰り返します。
-
各サイトのローカルなすべてのディスクの所有権を割り当てます。
「 disk assign adapter.xx.*` 」のように指定します
-
node_A_1 の IP と node_B_1 の IP でドライブシェルフが接続されている HBA ごとに、上記の手順を繰り返します。
-
-
node_A_1 の IP と node_B_1 の IP で次の手順を繰り返し、各ローカルディスクのメールボックス領域をクリアします。
-
各ディスクのメールボックス領域を破棄します。
「 mailbox destroy local 」「 mailbox destroy partner 」を実行します
-
-
4 台のコントローラをすべて停止します。
「 halt 」
-
各コントローラで、ブートメニューを表示します。
「 boot_ontap menu
-
4 台のコントローラのそれぞれで、設定をクリアします。
wipeconfig
wipeconfig 処理が完了すると、ノードは自動的にブートメニューに戻ります。
-
ブートメニューの 9a オプションを使用して、次の手順を繰り返して 4 つのノードをすべてブートします。
-
LOADER プロンプトで、ブートメニューを起動します。
「 boot_ontap menu
-
起動メニューでオプション [9a`] を選択して、コントローラを再起動します。
-
コントローラモジュールのブートが完了してから次のコントローラモジュールに移動します。
"9a`" が完了すると、ノードは自動的にブートメニューに戻ります。
-
-
コントローラの電源をオフにします。
MetroCluster FC 構成の健全性の確認
移行を実行する前に、 MetroCluster FC 構成の健全性と接続を確認する必要があります
このタスクは、 MetroCluster FC 構成上で実行します。
-
ONTAP で MetroCluster 構成の動作を確認します。
-
システムがマルチパスかどうかを確認します。
node run -node node-name sysconfig -a `
-
ヘルスアラートがないかどうかを両方のクラスタで確認します。
「 system health alert show 」というメッセージが表示されます
-
MetroCluster 構成と運用モードが正常な状態であることを確認します。
「 MetroCluster show 」
-
MetroCluster チェックを実行します。
「 MetroCluster check run 」のようになります
-
MetroCluster チェックの結果を表示します。
MetroCluster チェックショー
-
スイッチにヘルスアラートがないかどうかを確認します(ある場合)。
「 storage switch show 」と表示されます
-
Config Advisor を実行します。
-
Config Advisor の実行後、ツールの出力を確認し、推奨される方法で検出された問題に対処します。
-
-
ノードが非 HA モードになっていることを確認します。
「 storage failover show 」をクリックします
Tiebreaker またはその他の監視ソフトウェアから既存の設定を削除します
スイッチオーバーを開始できる MetroCluster Tiebreaker 構成や他社製アプリケーション( ClusterLion など)で既存の構成を監視している場合は、移行の前に Tiebreaker またはその他のソフトウェアから MetroCluster 構成を削除する必要があります。
-
Tiebreaker ソフトウェアから既存の MetroCluster 設定を削除します。
-
スイッチオーバーを開始できるサードパーティ製アプリケーションから既存の MetroCluster 構成を削除します。
アプリケーションのマニュアルを参照してください。