

 MetroClusterリリースノート
MetroClusterリリースノート
新しいコントローラで既存シェルフを使用できない場合の停止を伴う移行( ONTAP 9.8 以降)
 変更を提案
変更を提案
ONTAP 9.8 以降では、 2 ノードの MetroCluster FC 構成を無停止で移行し、既存のストレージシェルフが新しい MetroCluster IP ノードでサポートされていない場合でも、既存のドライブシェルフからデータを移動できます。
-
この手順は、既存のストレージシェルフモデルが新しい MetroCluster IP プラットフォームモデルでサポートされていない場合にのみ使用してください。
-
この手順は、 ONTAP 9.8 以降を実行しているシステムでサポートされています。
-
この手順はシステムの停止を伴います。
-
この手順は、 2 ノード MetroCluster FC 構成にのみ適用されます。
4 ノード MetroCluster FC 構成の場合は、を参照してください "移行する手順を選択します"。
-
すべての要件を満たし、手順のすべての手順に従う必要があります。
新しいノードでシェルフがサポートされていない場合の移行の要件
移行プロセスを開始する前に、構成が要件を満たしていることを確認する必要があります。
-
既存の構成は 2 ノードのファブリック接続またはストレッチ MetroCluster 構成である必要があり、すべてのノードで ONTAP 9.8 以降が実行されている必要があります。
新しい MetroCluster IP コントローラモジュールは、同じバージョンの ONTAP 9.8 を実行している必要があります。
-
既存のプラットフォームと新しいプラットフォームの組み合わせは、移行対象としてサポートされている必要があります。
-
の説明に従って、すべての要件とケーブル配線を満たしている必要があります "ファブリック接続 MetroCluster のインストールと設定"。
-
新しいコントローラに付属する新しいストレージシェルフ( node_A_1 の IP 、 node_B_2 の IP 、 node_B_1 の IP 、および node_B_2 の IP )が古いコントローラ( node_A_1 の FC と node_B_1 の FC )でサポートされている必要があります。
-
古いストレージシェルフは、新しい MetroCluster IP プラットフォームモデルでは * サポートされていません。
-
既存のシェルフで使用可能なスペアディスクに応じて、ドライブを追加する必要があります。
必要なドライブシェルフがほかにもあります。
各コントローラに 14~18 本のドライブを追加する必要があります。
-
3 本のプール 0 ドライブ
-
プール 1 ドライブ × 3
-
2 本のスペアドライブ
-
システムボリューム用に 6 ~ 10 台のドライブ
-
-
新しいノードを含む構成が、ドライブ数、ルートアグリゲートのサイズ容量など、構成のプラットフォーム制限を超えないようにする必要があります
この情報は、各プラットフォームモデルの NetApp Hardware Universe _ で確認できます。
-
MetroCluster サイトから 6 つのすべてのノードのリモートコンソールアクセスが必要です。または、手順で必要に応じてサイト間の移動を計画しておく必要があります。
新しいコントローラでシェルフがサポートされない場合の停止を伴う移行のワークフロー
既存のシェルフモデルが新しいプラットフォームモデルでサポートされない場合は、新しいシェルフを古い構成に接続し、新しいシェルフにデータを移動して、新しい構成に移行する必要があります。
移行を準備する際は、サイト間の移動を計画します。リモートノードがラックに設置されてケーブル接続されたら、ノードへのシリアルターミナルアクセスが必要です。ノードが設定されるまでサービスプロセッサへのアクセスは許可されません。
新しいコントローラモジュールの準備を行います
新しいコントローラモジュールと新しいストレージシェルフの構成とディスク所有権をクリアする必要があります。
-
新しいストレージシェルフを新しい MetroCluster IP コントローラモジュールに接続して、のすべての手順を実行します "MetroCluster IP コントローラの準備"。
-
新しい MetroCluster IP コントローラモジュールから新しいストレージシェルフを切断します。
新しいディスクシェルフを既存の MetroCluster FC コントローラに接続
MetroCluster IP 構成に移行する前に、新しいドライブシェルフを既存のコントローラモジュールに接続する必要があります。
次の図は、 MetroCluster FC 構成に新しいシェルフが接続された状態を示しています。
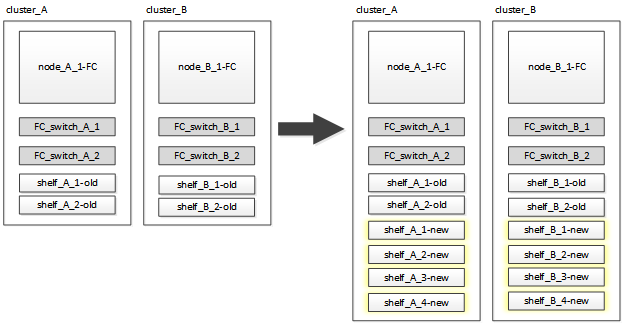
-
node_A_1 の FC と node_A_2 のディスク自動割り当てを無効にします。
disk option modify -node node_name autoassign off
このコマンドはノードごとに実行する必要があります。
ディスクの自動割り当ては、 node_A_1 に FC および node_B_1 に追加するシェルフの割り当てを回避するために無効になります。移行の一環として、ノード node_A_1 の IP と node_B_1 の IP にディスクを使用し、自動割り当てを許可した場合は、あとでディスク所有権を削除してから、 node_A_1 の IP と node_B_2 の IP にディスクを割り当てる必要があります。
-
必要に応じて FC-to-SAS ブリッジを使用し、新しいシェルフを既存の MetroCluster FC ノードに接続します。
の要件と手順を参照してください "MetroCluster FC 構成へのストレージのホットアド"
ルートアグリゲートを移行して、新しいディスクシェルフにデータを移動します
古いドライブシェルフから、 MetroCluster IP ノードで使用する新しいドライブシェルフにルートアグリゲートを移動する必要があります。
このタスクは、既存のノード( node_A_1 の FC と node_B_1 の FC )に移行する前に実行します。
-
コントローラ node_B_1 から FC からネゴシエートスイッチオーバーを実行します。
MetroCluster スイッチオーバー
-
node_B_1 から FC へのリカバリのアグリゲートの修復とルートの修復の手順を実行します。
「 MetroCluster heal-phase aggregates 」
「 MetroCluster heal-phase root-aggregates 」
-
ブートコントローラ node_A_1 - FC :
「 boot_ontap 」
-
新しいシェルフの未割り当てディスクをコントローラ node_A_1 の FC の適切なプールに割り当てます。
-
シェルフのディスクを特定します。
disk show -shelf pool_0_shelf-fields container-type 、 diskpathnames
disk show -shelf pool_1_shelf-fields container-type 、 diskpathnames
-
ローカルモードに切り替えて、ローカルノードでコマンドを実行します。
'run local' のように指定します
-
ディスクを割り当てます。
「 disk assign disk1disk2disk3disk… 」 -p 0`
「 disk assign disk4disk5disk6disk …」 -p 1`
-
ローカルモードを終了します。
「 exit
-
-
新しいミラーされたアグリゲートを作成してコントローラ node_A_1 の新しいルートアグリゲートにします。
-
権限モードを advanced に設定します。
'set priv advanced'
-
アグリゲートを作成します。
アグリゲート create -aggregate new_aggr-disklist disk1 、 disk2 、 disk3 、… -mirror-disklist disk4disk5 、 disk6 、… -raidtypese-as -exist-root-force-small-aggregate true aggr show -aggregate new_aggr-fields percent-snapshot-space を使用できます
percent-snapshot-space 値が 5% 未満の場合は、 5% を超える値にする必要があります。
aggr modify new_aggr-percent-snapshotSpace 5`
-
権限モードを admin に戻します。
'set priv admin' のように設定します
-
-
新しいアグリゲートが適切に作成されたことを確認します。
'node run -node local sysconfig -r を実行します
-
ノードレベルとクラスタレベルの構成バックアップを作成します。

スイッチオーバー中にバックアップが作成されると、クラスタはスイッチオーバーされたリカバリの状態を認識します。システム構成のバックアップとアップロードは、このバックアップがなければクラスタ間で MetroCluster 構成を再確立できないために成功する必要があります。 -
クラスタバックアップを作成します。
' system configuration backup create -node local-backup-type cluster -backup-name_cluster-backup-name_`
-
クラスタバックアップの作成を確認します
「 job show -id job-IDStatus 」のように入力します
-
ノードバックアップを作成します。
system configuration backup create -node local-backup-type node-backup-name_node-backup-name-name_`
-
クラスタとノードの両方のバックアップを確認します。
「 system configuration backup show 」を参照してください
出力に両方のバックアップが表示されるまで、コマンドを繰り返し実行できます。
-
-
バックアップのコピーを作成します。
バックアップは、新しいルート・ボリュームのブート時にローカルで失われるため、別の場所に保存する必要があります。
FTP または HTTP サーバにバックアップをアップロードしたり、「 scp 」コマンドを使用してバックアップをコピーしたりできます。
プロセス
手順
-
バックアップを FTP または HTTP サーバ * にアップロードします
-
クラスタバックアップをアップロードします。
'system configuration backup upload -node local-backup_cluster-backup-name_-destination url
-
ノードバックアップをアップロードします。
'system configuration backup upload -node local-backup_node-backup-name_-destination url
-
セキュアコピー * を使用して、バックアップをリモート・サーバにコピーします
リモートサーバから次の scp コマンドを使用します。
-
クラスタバックアップをコピーします。
`scp diagnode-mgmt -FC) :/mroot/etc/backup/config/cluster-backup-name.7z
-
ノードのバックアップをコピーします。
「 scp diag@node-mgmt -fc : /mroot/etc/backup/config/node-backup-name.7z 」を参照してください
-
-
node_A_1 の停止 - FC :
halt -node local-ignore-quorum -warnings true
-
node_A_1 のブート - FC をメンテナンスモードにします。
「 boot_ontap maint 」を使用してください
-
メンテナンスモードで、必要な変更を行ってアグリゲートを root として設定します。
-
HA ポリシーを CFO に設定します。
「 aggr options new_aggr ha_policy cfo 」を参照してください
続行するかどうかを確認するメッセージが表示されたら、「 yes 」と入力します。
Are you sure you want to proceed (y/n)?
-
新しいアグリゲートを root として設定します。
「 aggr options new_aggr root 」のように指定します
-
LOADER プロンプトに移動します。
「 halt 」
-
-
コントローラをブートして、システム構成をバックアップします。
新しいルートボリュームが検出されると、ノードはリカバリモードでブートします
-
コントローラをブートします。
「 boot_ontap 」
-
ログインし、設定をバックアップします。
ログインすると、次の警告が表示されます。
Warning: The correct cluster system configuration backup must be restored. If a backup from another cluster or another system state is used then the root volume will need to be recreated and NGS engaged for recovery assistance.
-
advanced 権限モードに切り替えます。
「 advanced 」の権限が必要です
-
クラスタ構成をサーバにバックアップします。
「 system configuration backup download -node local-source url of server/cluster-backup-name.7z
-
ノード構成をサーバにバックアップします。
「 system configuration backup download -node local-source url of server/node-backup-name.7z
-
admin モードに戻ります。
「特権管理者」
-
-
クラスタの健常性を確認します。
-
次のコマンドを問題に設定します。
「 cluster show 」を参照してください
-
権限モードを advanced に設定します。
「 advanced 」の権限が必要です
-
クラスタ構成の詳細を確認します。
「 cluster ring show 」を参照してください
-
admin 権限レベルに戻ります。
「特権管理者」
-
-
MetroCluster 構成の運用モードを確認し、 MetroCluster チェックを実行
-
MetroCluster 構成と運用モードが正常な状態であることを確認します。
「 MetroCluster show 」
-
想定されるすべてのノードが表示されることを確認します。
MetroCluster node show
-
次のコマンドを問題に設定します。
「 MetroCluster check run 」のようになります
-
MetroCluster チェックの結果を表示します。
MetroCluster チェックショー
-
-
コントローラ node_B_1 から FC にスイッチバックを実行します。
MetroCluster スイッチバック
-
MetroCluster 構成の動作を確認します。
-
MetroCluster 構成と運用モードが正常な状態であることを確認します。
「 MetroCluster show 」
-
MetroCluster チェックを実行します。
「 MetroCluster check run 」のようになります
-
MetroCluster チェックの結果を表示します。
MetroCluster チェックショー
-
-
新しいルートボリュームを Volume Location Database に追加します。
-
権限モードを advanced に設定します。
「 advanced 」の権限が必要です
-
ノードにボリュームを追加します。
volume add-other-volumes – node node_A_1 -FC
-
admin 権限レベルに戻ります。
「特権管理者」
-
-
ボリュームが認識され、 mroot であることを確認します。
-
アグリゲートを表示します。
「 storage aggregate show
-
ルートボリュームの mroot が使用されていることを確認します。
storage aggregate show -fields には -mroot があります
-
ボリュームを表示します。
volume show
-
-
新しいセキュリティ証明書を作成して System Manager へのアクセスを再度有効にします。
'security certificate create -common-name_-type server-size 2048
-
同じ手順を繰り返して、 node_A_1 の FC が所有するシェルフのアグリゲートを移行します。
-
クリーンアップを実行します。
古いルートボリュームとルートアグリゲートを削除するには、 node_A_1 の FC と node_B_1 の両方で次の手順を実行する必要があります。
-
古いルートボリュームを削除します。
'run local' のように指定します
vol offline old_vol0
「 vol destroy old_vol0 」のようになります
「 exit
volume remove-other-volume -vserver node_name -volume old_vol0
-
元のルートアグリゲートを削除します。
「 aggr offline -aggregate old_aggr0_cluster1_01 」のように表示されます
「 aggr delete -aggregate old_aggr0_cluster1_01 」のように表示されます
-
-
新しいコントローラ上のアグリゲートに、一度に 1 つのボリュームずつデータボリュームを移行します。
を参照してください "アグリゲートの作成と新しいノードへのボリュームの移動"
-
の手順をすべて実行して古いシェルフを撤去します "撤去するシェルフは node_A_1 から FC 、 node_A_1 から FC を移行"。
構成を移行しています
詳細な移行手順に従う必要があります。
以降の手順では、他のトピックに進んでいます。各トピックの手順は記載された順序で実行する必要があります。
-
ポートマッピングを計画
のすべての手順を実行します "MetroCluster FC ノードから MetroCluster IP ノードへのポートのマッピング"。
-
MetroCluster IP コントローラを準備
のすべての手順を実行します "MetroCluster IP コントローラの準備"。
-
MetroCluster 構成の健全性を確認
のすべての手順を実行します "MetroCluster FC 構成の健全性の確認"。
-
既存の MetroCluster FC ノードを準備して削除
のすべての手順を実行します "MetroCluster FC ノードを移行します"。
-
新しい MetroCluster IP ノードを追加します。
のすべての手順を実行します "MetroCluster IP コントローラモジュールを接続します"。
-
新しい MetroCluster IP ノードの移行と初期設定を完了します。
のすべての手順を実行します "新しいノードの設定と移行の完了"。